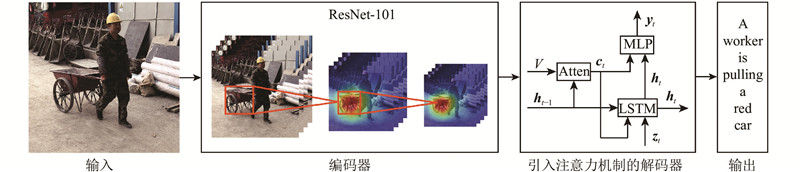
A construction scene image caption method based on attention mechanism and encoding-decoding architecture was proposed, in order to realize the image caption in the complex construction scenes such as poor light, night construction, long-distance dense small targets and so on. Convolutional neural network was used to construct encoder to extract rich visual features in construction images. Long short-term memory network was used to construct decoder to capture semantic features of words in sentences and learn mapping relationship between image features and semantic features of words. Attention mechanism was introduced to focus on significant features, suppress non-significant features and reduce interference of noise information. An image caption data set containing ten common construction scenes was constructed in order to verify the effectiveness of the proposed method. Experimental results show that the proposed method achieves high accuracy, has good image caption performance in complex construction scenes such as poor light, night construction, long-distance dense small targets and so on, and has strong generalization and adaptability.
Yuan-jun NONG,Jun-jie WANG,Hong CHEN,Wen-han SUN,Hui GENG,Shu-yue LI. A image caption method of construction scene based on attention mechanism and encoding-decoding architecture. Journal of ZheJiang University (Engineering Science), 2022, 56(2): 236-244.
Fig.1System framework of construction scene image caption model
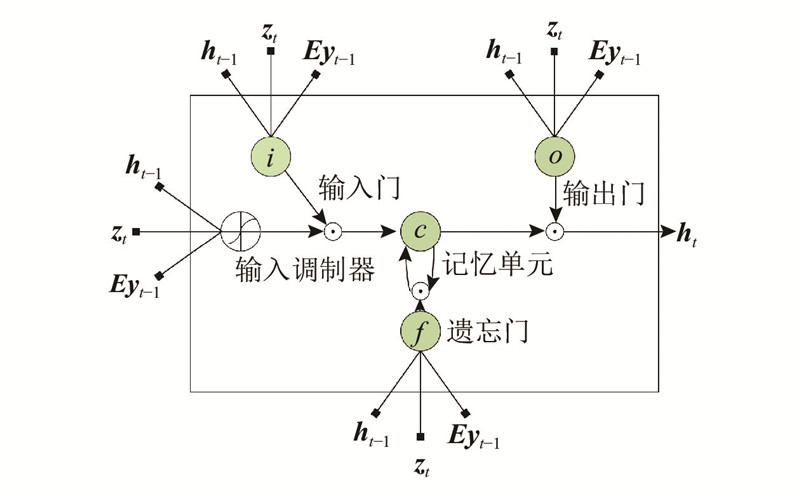
Fig.2LSTM cell structure
Fig.3Visualization of attention mechanism
施工场景
数量
施工场景
数量
工人推/拉手推车
115
工人爬梯子作业
120
挖掘机挖土
120
工人佩戴安全帽
120
工人焊接铁制品
125
工人砌砖
130
工人拿电钻机作业
120
工人绑钢筋
120
工人在脚手架上作业
120
工人浇筑混凝土
110
Tab.1Ten common construction scenarios and corresponding number of images
Fig.4Example of data set of construction scene image caption
方法
主干网络
BLEU-1
BLEU-2
BLEU-3
BLEU-4
METEOR
ROUGE_L
CIDEr
NIC[17]
VGG-16
0.725
0.542
0.386
0.295
0.248
0.531
0.854
Adaptive[18]
VGG-16
0.738
0.556
0.403
0.319
0.259
0.545
0.887
Self-critic[19]
ResNet-101
0.751
0.573
0.437
0.332
0.266
0.558
0.913
Up-down[20]
ResNet-101
0.764
0.587
0.455
0.344
0.271
0.572
0.946
本研究方法
ResNet-101
0.783
0.608
0.469
0.357
0.293
0.586
0.962
Tab.2Experiment results of different methods in image caption data set of construction scene
注意力机制
BLEU-1
METEOR
ROUGE_L
CIDEr
×
0.758
0.264
0.562
0.921
√
0.783
0.293
0.586
0.962
Tab.3Ablation study results
Fig.5Visualization of detection results
Fig.6Generalization test results
Fig.7Visualization of attention mechanism results
[1]
WU J, CAI N, CHEN W, et al Automatic detection of hardhats worn by construction personnel: a deep learning approach and benchmark dataset[J]. Automation in Construction, 2019, 106: 102894
doi: 10.1016/j.autcon.2019.102894
[2]
NATH N D, BEHZADAN A H, PAAL S G Deep learning for site safety: real-time detection of personal protective equipment[J]. Automation in Construction, 2020, 112: 103085
doi: 10.1016/j.autcon.2020.103085
[3]
GUO Y, XU Y, LI S Dense construction vehicle detection based on orientation-aware feature fusion convolutional neural network[J]. Automation in Construction, 2020, 112: 103124
doi: 10.1016/j.autcon.2020.103124
[4]
LI Y, LU Y, CHEN J A deep learning approach for real-time rebar counting on the construction site based on YOLOv3 detector[J]. Automation in Construction, 2021, 124: 103602
doi: 10.1016/j.autcon.2021.103602
[5]
徐守坤, 倪楚涵, 吉晨晨, 等 一种基于安全帽佩戴检测的图像描述方法研究[J]. 小型微型计算机系统, 2020, 41 (4): 812- 819 XU Shou-kun, NI Chu-han, JI Chen-chen, et al Research on image caption method based on safety helmet wearing detection[J]. Journal of Chinese Computer Systems, 2020, 41 (4): 812- 819
doi: 10.3969/j.issn.1000-1220.2020.04.025
[6]
BANG S, KIM H Context-based information generation for managing UAV-acquired data using image captioning[J]. Automation in Construction, 2020, 112: 103116
doi: 10.1016/j.autcon.2020.103116
[7]
LIU H, WANG G, HUANG T, et al Manifesting construction activity scenes via image captioning[J]. Automation in Construction, 2020, 119: 103334
doi: 10.1016/j.autcon.2020.103334
[8]
XU K, BA J L, KIROS R, et al. Show, attend and tell: neural image caption generation with visual attention [C]// International Conference on Machine Learning. Cambridge: MIT, 2015: 2048-2057.
[9]
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [C]// European Conference on Computer Vision. Berlin: Springer, 2014: 740-755.
[10]
HODOSH M, YOUNG P, HOCKENMAIER J Framing image description as a ranking task: data, models and evaluation metrics[J]. Journal of Artificial Intelligence Research, 2013, 47: 853- 899
doi: 10.1613/jair.3994
[11]
YOUNG P, LAI A, HODOSH M, et al From image descriptions to visual denotations: new similarity metrics for semantic inference over event descriptions[J]. Transactions of the Association for Computational Linguistics, 2014, 2: 67- 78
doi: 10.1162/tacl_a_00166
[12]
DUTTA A, ZISSERMAN A. The VIA annotation software for images, audio and video [EB/OL]. (2019-04-24)[2021-04-08]. https://arxiv.org/abs/1904.10699.
[13]
PAPINENI K, ROUKOS S, WARD T, et al. BLEU: a method for automatic evaluation of machine translation [C]// Annual Meeting on Association for Computational Linguistics. Stroudsburg: ACL, 2002: 311-318.
[14]
BANERJEE S, LAVIE A. METEOR: an automatic metric for MT evaluation with improved correlation with human judgments [C]// ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. Stroudsburg: ACL, 2005: 65-72.
[15]
LIN C Y. ROUGE: a package for automatic evaluation of summaries[C]// ACL Workshop on Text Summarization Branches Out. Stroudsburg: ACL, 2004: 74-81.
[16]
VEDANTAM R, ZITNICK C L, PARIKH D. CIDEr: consensus-based image description evaluation [C]// IEEE Conference on Computer Vision and Pattern Recognition. Los Alamitos: IEEE, 2015: 4566-4575.
[17]
VINYALS O, TOSHEV A, BENGIO S, et al. Show and tell: a neural image caption generator [C]// IEEE Conference on Computer Vision and Pattern Recognition. Los Alamitos: IEEE, 2015: 3156-3164.
[18]
LU J, XIONG C, PARIKH D, et al. Knowing when to look: adaptive attention via a visual sentinel for image captioning [C]// IEEE Conference on Computer Vision and Pattern Recognition. Los Alamitos: IEEE, 2017: 3242-3250.
[19]
RENNIE S J, MARCHERET E, MROUEH Y, et al. Self-critical sequence training for image captioning [C]// IEEE Conference on Computer Vision and Pattern Recognition. Los Alamitos: IEEE, 2017: 1179-1195.