|
|
|
| Visual question answering method based on relational reasoning and gating mechanism |
Xin WANG( ),Qiao-hong CHEN*(),Qi SUN,Yu-bo JIA ),Qiao-hong CHEN*(),Qi SUN,Yu-bo JIA |
| School of Information Science and Technology, Zhejiang Sci-Tech University, Hangzhou 310018, China |
|
|
|
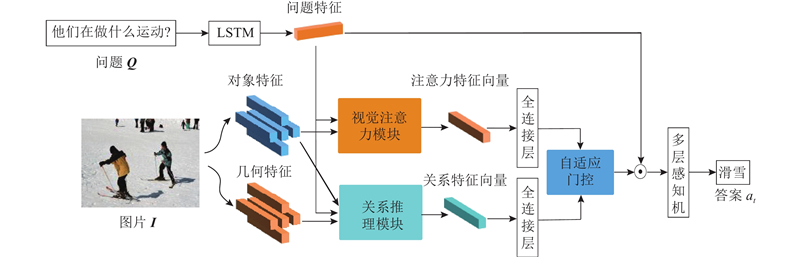
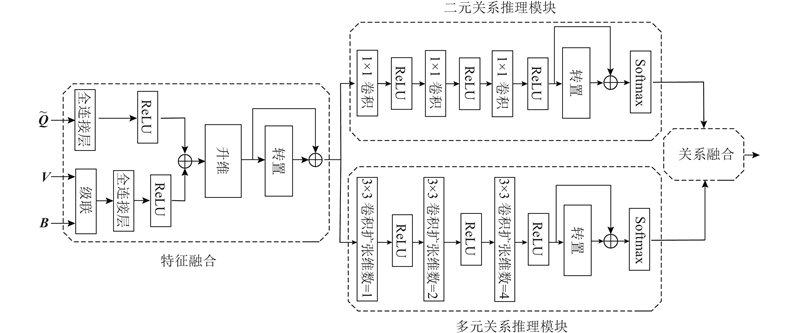
Abstract A relational reasoning module and an adaptive gating mechanism were added based on the attention mechanism aiming at the problems that the existing attention mechanism lacks understanding of the relationship between visual objects and has low accuracy. The attention mechanism was used to focus on multiple visual regions related to the question. The dual relational reasoning and multiple relational reasoning in the relational reasoning module were used to strengthen the connection between the visual regions. The obtained visual attention feature and visual relationship feature were input into adaptive gating, and the contribution of the two features to the predicted answer was dynamically controlled. The experimental results on the VQA1.0 and VQA2.0 data sets showed that the overall accuracy of the model was improved by about 2% compared with advanced models such as DCN, MFB, MFH and MCB. The model based on relational reasoning and gating mechanism can better understand the image content and effectively improve the accuracy of visual question and answer.
|
|
Received: 19 March 2021
Published: 05 January 2022
|
|
|
| Fund: 浙江省自然科学基金资助项目(LY17E050028) |
|
Corresponding Authors:
Qiao-hong CHEN
E-mail: xinwang952021@163.com;chen_lisa@zstu.edu.cn
|
基于关系推理与门控机制的视觉问答方法
针对现有的注意力机制存在缺乏对视觉对象间关系的理解能力及准确度较差的问题,在注意力机制的基础上增加关系推理模块与自适应门控机制. 该方法利用注意力机制关注多个与问题相关的视觉区域,利用关系推理模块中的二元关系推理与多元关系推理加强视觉区域间的联系. 将分别得到的视觉注意力特征与视觉关系特征输入到自适应门控中,动态控制2种特征对预测答案的贡献. 在VQA1.0及VQA2.0数据集上的实验结果表明:该模型与DCN、MFB、MFH及MCB等先进模型相比,在总体精度上均有约2%的提升;利用基于关系推理与门控机制的模型能够更好地理解图像内容,有效地提升视觉问答的准确率.
关键词:
视觉问答(VQA),
注意力机制,
视觉区域,
关系推理,
自适应门控
|
|
| [1] |
牛玉磊, 张含望 视觉问答与对话综述[J]. 计算机科学, 2021, 48 (3): 10
NIU Yu-lei, ZHANG Han-wang Visual question answering and dialogue summary[J]. Computer Science, 2021, 48 (3): 10
|
|
|
| [2] |
REN M, KIROS R, ZEMEL R. Exploring models and data for image question answering [C]// Advances in Neural Information Processing Systems. Montreal: [s. n.], 2015: 2953–2961.
|
|
|
| [3] |
ANDERSON P, HE X, BUEHLER C, et al. Bottom-up and top-down attention for image captioning and visual question answering [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 6077-6086.
|
|
|
| [4] |
CHEN F, MENG F, XU J, et al. Dmrm: a dual-channel multi-hop reasoning model for visual dialog [C]// Proceedings of the AAAI Conference on Artificial Intelligence. New York: AAAI, 2020, 34(5): 7504-7511.
|
|
|
| [5] |
YU Z, YU J, CUI Y, et al. Deep modular co-attention networks for visual question answering [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 6281-6290.
|
|
|
| [6] |
ZHU Z, YU J, WANG Y, et al. Mucko: multi-layer cross-modal knowledge reasoning for fact-based visual question answering [EB/OL]. (2020-11-04)[2021-03-19]. https://arxiv.org/abs/2006.09073.
|
|
|
| [7] |
JOHNSON J, HARIHARAN B, VAN DER MAATEN L, et al. Inferring and executing programs for visual reasoning [C]// Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 2989-2998.
|
|
|
| [8] |
邱真娜, 张丽红, 陶云松 基于物体检测及关系推理的视觉问答方法研究[J]. 测试技术学报, 2020, 34 (5): 8
QIU Zhen-na, ZHANG Li-hong, TAO Yun-song Research on visual question answering method based on object detection and relational reasoning[J]. Journal of Testing Technology, 2020, 34 (5): 8
|
|
|
| [9] |
SANTORO A, RAPOSO D, BARRETT D G T, et al. A simple neural network module for relational reasoning [EB/OL]. (2017-06-05)[2021-03-19]. https://arxiv.org/abs/1706.01427.
|
|
|
| [10] |
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778.
|
|
|
| [11] |
REN S, HE K, GIRSHICK R, et al Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 39 (6): 1137- 1149
|
|
|
| [12] |
TENEY D, ANDERSON P, HE X, et al. Tips and tricks for visual question answering: learnings from the 2017 challenge [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 4223-4232.
|
|
|
| [13] |
PENNINGTON J, SOCHER R, MANNING C D. Glove: global vectors for word representation [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha, Qatar: ACL, 2014: 1532-1543.
|
|
|
| [14] |
HOCHREITER S, SCHMIDHUBER J Long short-term memory[J]. Neural computation, 1997, 9 (8): 1735- 1780
doi: 10.1162/neco.1997.9.8.1735
|
|
|
| [15] |
PIRSIAVASH H, RAMANAN D, FOWLKES C C. Bilinear classifiers for visual recognition [C]// Advances in Neural Information Processing Systems. Denver, USA: Curran Associates, 2009: 3.
|
|
|
| [16] |
PEI H, CHEN Q, WANG J, et al. Visual relational reasoning for image caption [C]// 2020 International Joint Conference on Neural Networks. Glasgow, UK: IEEE, 2020: 1-8.
|
|
|
| [17] |
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft coco: common objects in context [C]// European Conference on Computer Vision. Cham: Springer, 2014: 740-755.
|
|
|
| [18] |
ANTOL S, AGRAWAL A, LU J, et al. Vqa: visual question answering [C]// Proceedings of the IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015: 2425-2433.
|
|
|
| [19] |
MA C, SHEN C, DICK A, et al. Visual question answering with memory-augmented networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 6975-6984.
|
|
|
| [20] |
NAM H, HA J W, KIM J. Dual attention networks for multimodal reasoning and matching [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 299-307.
|
|
|
| [21] |
YU Z, YU J, FAN J, et al. Multi-modal factorized bilinear pooling with co-attention learning for visual question answering [C]// Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 1821-1830.
|
|
|
| [22] |
YU Z, YU J, XIANG C, et al Beyond bilinear: generalized multimodal factorized high-order pooling for visual question answering[J]. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29 (12): 5947- 5959
doi: 10.1109/TNNLS.2018.2817340
|
|
|
| [23] |
NGUYEN D K, OKATANI T. Improved fusion of visual and language representations by dense symmetric co-attention for visual question answering [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 6087-6096.
|
|
|
| [24] |
GOYAL Y, KHOT T, SUMMER-STAY D, et al. Making the v in vqa matter: elevating the role of image understanding in visual question answering [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 6904-6913.
|
|
|
| [25] |
CADENE R, BEN-YOUNES H, CORD M, et al. Murel: multimodal relational reasoning for visual question answering [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 1989-1998.
|
|
|
| [26] |
GAO P, JIANG Z, YOU H, et al. Dynamic fusion with intra-and inter-modality attention flow for visual question answering[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 6639-6648.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|