|
|
|
| Image caption based on relational reasoning and context gate mechanism |
Qiao-hong CHEN( ),Hao-lei PEI,Qi SUN ),Hao-lei PEI,Qi SUN |
| School of Informatics Science and Technology, Zhejiang Sci-Tech University, Hangzhou 310018, China |
|
|
|
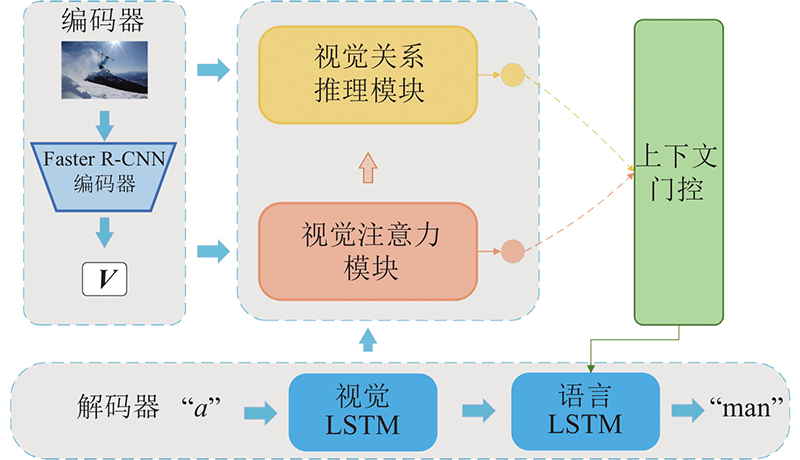
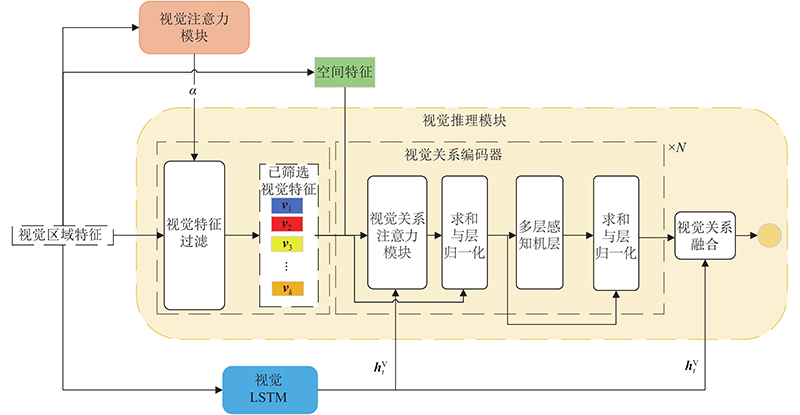
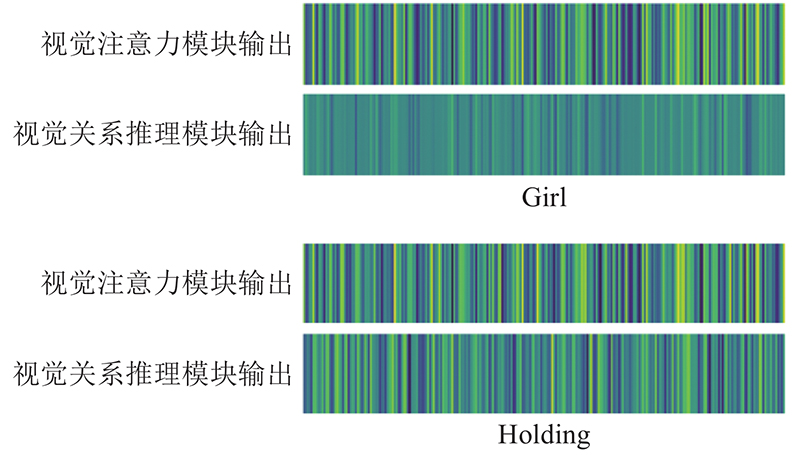
Abstract A visual relationship reasoning module was proposed in order to explore the modeling and reasoning of the relationship between visual regions needed for image scene understanding. The relationship patterns between the two related visual objects were encoded dynamically based on different semantic and spatial context information, and the most relevant feature output of the currently generated relationship words was inferred by using the module. In addition, the contributions between the visual attention module and the visual relational reasoning module were controlled dynamically according to the different types of words by introducing the context gate mechanism. Experimental results show that the method has better performance than other state-of-the-art methods based on attention mechanism. By using the module a model is established dynamically, the most relevant features of different types for the generated words are inferred, and the quality of image caption is improved.
|
|
Received: 25 April 2021
Published: 29 March 2022
|
|
|
基于视觉关系推理与上下文门控机制的图像描述
为了探索图像场景理解所需要的视觉区域间关系的建模与推理,提出视觉关系推理模块. 该模块基于图像中不同的语义和空间上下文信息,对相关视觉对象间的关系模式进行动态编码,并推断出与当前生成的关系词最相关的语义特征输出. 通过引入上下文门控机制,以根据不同类型的单词动态地权衡视觉注意力模块和视觉关系推理模块的贡献. 实验结果表明,对比以往基于注意力机制的图像描述方法,基于视觉关系推理与上下文门控机制的图像描述方法更好;所提模块可以动态建模和推理不同类型生成单词的最相关特征,对输入图像中物体关系的描述更加准确.
关键词:
图像语义描述,
视觉关系推理,
多模态编码,
上下文门控机制,
注意力机制
|
|
| [1] |
HEIKKIL? M, PIETIK?INEN M, SCHMID C Description of interest regions with local binary patterns[J]. Pattern Recognition, 2009, 42 (3): 425- 436
doi: 10.1016/j.patcog.2008.08.014
|
|
|
| [2] |
LINDEBERG T. Scale invariant feature transform [M]. 2012: 10491.
|
|
|
| [3] |
DALAL N, TRIGGS B. Histograms of oriented gradients for human detection [C]// 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Diego: IEEE, 2005: 886-893.
|
|
|
| [4] |
SUYKENS J A, VANDEWALLE J Least squares support vector machine classifiers[J]. Neural processing letters, 1999, 9 (3): 293- 300
doi: 10.1023/A:1018628609742
|
|
|
| [5] |
FARHADI A, HEJRATI M, SADEGHI M A, et al. Every picture tells a story: generating sentences from images [M]// DANIILIDIS K, MARAGOS P, PARAGIOS N. Computer vision: ECCV 2010. [S. l.]: Springer, 2010: 15-29.
|
|
|
| [6] |
KIROS R, SALAKHUTDINOV R, ZEMEL R S. Unifying visual-semantic embeddings with multimodal neural language models [EB/OL].[2021-03-05]. https://arxiv.org/pdf/1411.2539.pdf.
|
|
|
| [7] |
HOCHREITER S, SCHMIDHUBER J Long short-term memory[J]. Neural computation, 1997, 9 (8): 1735- 1780
doi: 10.1162/neco.1997.9.8.1735
|
|
|
| [8] |
XU K, BA J L, KIROS R, et al. Show, attend and tell: neural image caption generation with visual attention [EB/OL]. [2021-03-05]. https://arxiv.org/pdf/1502.03044.pdf.
|
|
|
| [9] |
LU J, XIONG C, PARIKH D, et al. Knowing when to look: adaptive attention via a visual sentinel for image captioning [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 375-383.
|
|
|
| [10] |
ANDERSON P, HE X, BUEHLER C, et al. Bottom-up and top-down attention for image captioning and visual question answering [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 6077-6086.
|
|
|
| [11] |
GU J, CAI J, WANG G, et al. Stack-captioning: coarse-to-fine learning for image captioning [C]// Thirty-Second AAAI Conference on Artificial Intelligence, 2018: 12266.
|
|
|
| [12] |
WANG W, CHEN Z, HU H. Hierarchical attention network for image captioning [C]// Proceedings of the AAAI Conference on Artificial Intelligence. Hawaii: EI, 2019: 8957-8964.
|
|
|
| [13] |
赵小虎, 尹良飞, 赵成龙 基于全局-局部特征和自适应注意力机制的图像语义描述算法[J]. 浙江大学学报:工学版, 2020, 54 (1): 126- 134
ZHAO Xiao-hu, YIN Liang-fei, ZHAO Cheng-long Image captioning based on global-local feature and adaptive-attention[J]. Journal of Zhejiang University: Engineering Science, 2020, 54 (1): 126- 134
|
|
|
| [14] |
WANG J, WANG W, WANG L, et al Learning visual relationship and context-aware attention for image captioning[J]. Pattern Recognition, 2020, 98: 107075
doi: 10.1016/j.patcog.2019.107075
|
|
|
| [15] |
KE L, PEI W, LI R, et al. Reflective decoding network for image captioning [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 8888-8897.
|
|
|
| [16] |
ZHOU Y, WANG M, LIU D, et al. More grounded image captioning by distilling image-text matching model [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Venice: IEEE, 2020: 4777-4786.
|
|
|
| [17] |
HOU J, WU X, ZHANG X, et al. Joint commonsense and relation reasoning for image and video captioning [C]// Proceedings of the AAAI Conference on Artificial Intelligence. New York: [s. n.], 2020: 10973-10980.
|
|
|
| [18] |
REN S, HE K, GIRSHICK R, et al Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39 (6): 1137- 1149
doi: 10.1109/TPAMI.2016.2577031
|
|
|
| [19] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [EB/OL].[2021-03-05]. https://arxiv.org/pdf/1706.03762.pdf.
|
|
|
| [20] |
WANG J, JIANG W, MA L, et al. Bidirectional attentive fusion with context gating for dense video captioning [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 7190-7198.
|
|
|
| [21] |
VEDANTAM R, LAWRENCE ZITNICK C, PARIKH D. Cider: consensus-based image description evaluation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 4566-4575.
|
|
|
| [22] |
LIN T-Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [M]// FLEET D, PAJDLA T, SCHIELE B, et al. Computer vision: ECCV 2014. [S.l.]: Springer, 2014: 740-755.
|
|
|
| [23] |
PLUMMER B A, WANG L, CERVANTES C M, et al. Flickr30k entities: collecting region-to-phrase correspondences for richer image-to-sentence models [J] International Journal of Computer Vision, 2017, 123: 74-93.
|
|
|
| [24] |
JOHNSON J, KARPATHY A, LI F-F. DenseCap: fully convolutional localization networks for dense captioning [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 4565-4574.
|
|
|
| [25] |
PAPINENI K, ROUKOS S, WARD T, et al. BLEU: a method for automatic evaluation of machine translation [C]// Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. Philadelphia: IEEE, 2002: 311-318.
|
|
|
| [26] |
DENKOWSKI M, LAVIE A. Meteor 1.3: automatic metric for reliable optimization and evaluation of machine translation systems [C]// Proceedings of the Sixth Workshop on Statistical Machine Translation. Scotland: IEEE, 2011: 85-91.
|
|
|
| [27] |
LIN C Y. Rouge: a package for automatic evaluation of summaries [C]// Proceedings of Workshop on Text Summarization Branches Out, Post-Conference Workshop of ACL 2004. Barcelona: [s. n.], 2004: 1-10.
|
|
|
| [28] |
ANDERSON P, FERNANDO B, JOHNSON M, et al. Spice: semantic propositional image caption evaluation [M]// LEIBE B, MATAS J, SEBE N, et al. Computer vision: ECCV 2016. [S. l.]: Springer, 2016: 382-398.
|
|
|
| [29] |
KRISHNA R, ZHU Y, GROTH O, et al Visual genome: connecting language and vision using crowdsourced dense image annotations[J]. International Journal of Computer Vision, 2017, 123 (1): 32- 73
doi: 10.1007/s11263-016-0981-7
|
|
|
| [30] |
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE conference on computer vision and pattern recognition. Las Vegas: IEEE, 2016: 770-778.
|
|
|
| [31] |
PENNINGTON J, SOCHER R, MANNING C D. Glove: global vectors for word representation [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. [S. l.]: ACL, 2014: 1532-1543.
|
|
|
| [32] |
KINGMA D P, BA J L. Adam: a method for stochastic optimization [EB/OL].[2021-03-05]. https://arxiv.org/pdf/1412.6980.pdf.
|
|
|
| [33] |
RENNIE S J, MARCHERET E, MROUEH Y, et al. Self-critical sequence training for image captioning [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 7008-7024.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|