| Computer Technology, Information Engineering |
|


|
|
|
| Image captioning based on global-local feature and adaptive-attention |
Xiao-hu ZHAO1,2( ),Liang-fei YIN1,2(),Cheng-long ZHAO1,2 ),Liang-fei YIN1,2(),Cheng-long ZHAO1,2 |
1. National and Local Joint Engineering Laboratory of Internet Application Technology on Mine, China University of Mining and Technology, Xuzhou 221008, China
2. School of Information and Control Engineering, China University of Mining and Technology, Xuzhou 221116, China |
|
|
|
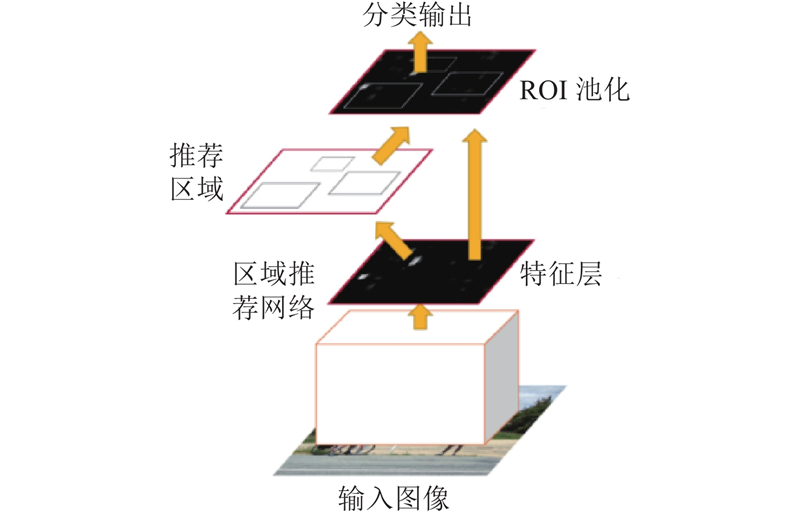
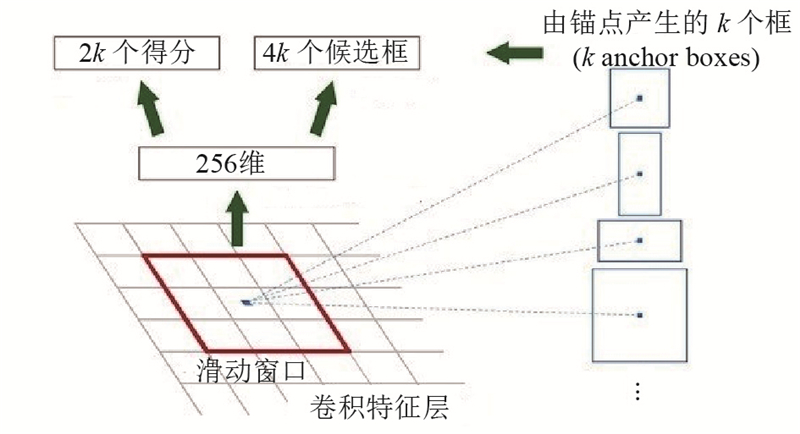
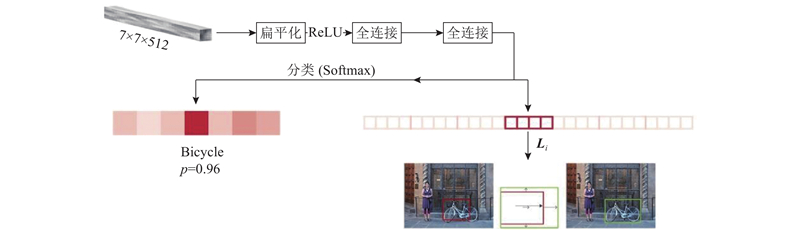
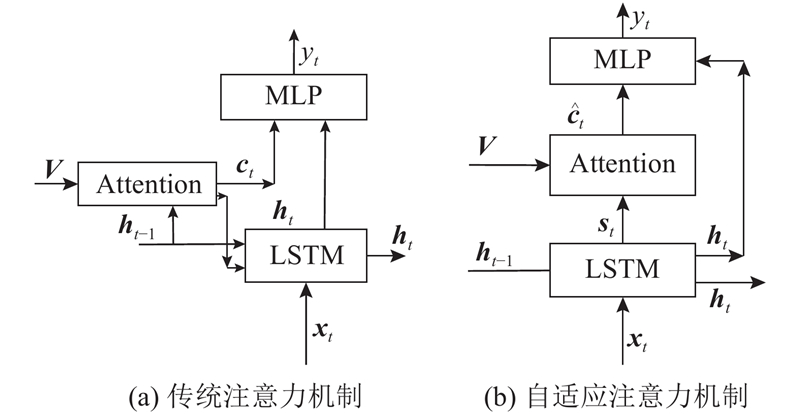
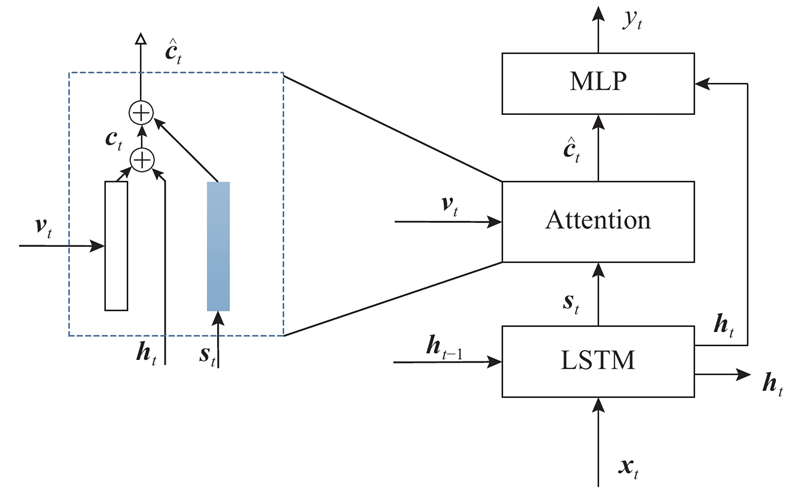
Abstract The image captioning algorithm was proposed in order to explore the difference of the image visual features and the upper layer semantic concept. The algorithm can determine the image focus, mine higher-level semantic information, and improve the description details. Local features were added for the image visual feature extraction, and the global-local feature of the input image was combined with the global features and local features for visual information. Then the focus of the image at different time was determined, and more details of the image were caught. The attention mechanism was added to weight the image feature during decoding, so that the dependence of the text words on the visual information and the semantic information at the current moment could be adaptively adjusted, and the performance of image captioning was effectively improved. The experimental results show that the proposed method can acquire competitive captioning results than other image captioning algorithms. The method can describe the image more accurately and more comprehensively, and the recognition accuracy of tiny objects is higher than others.
|
|
Received: 29 April 2019
Published: 05 January 2020
|
|
|
基于全局?局部特征和自适应注意力机制的图像语义描述算法
为了探究图像底层视觉特征与高层语义概念存在的差异,提出可以确定图像关注重点、挖掘更高层语义信息以及完善描述句子的细节信息的图像语义描述算法. 在图像视觉特征提取时提取输入图像的全局-局部特征作为视觉信息输入,确定不同时刻对图像的关注点,对图像细节的描述更加完善;在解码时加入注意力机制对图像特征加权输入,可以自适应选择当前时刻输出的文本单词对视觉信息与语义信息的依赖权重,有效地提高对图像语义描述的性能. 实验结果表明,该方法相对于其他语义描述算法效果更有竞争力,可以更准确、更细致地识别图片中的物体,对输入图像进行更全面地描述;对于微小的物体的识别准确率更高.
关键词:
图像语义描述,
图像关注点,
高层语义信息,
描述句子细节,
全局-局部特征提取,
自适应注意力机制
|
|
| [1] |
FARHADI A, HEJRATI M, SADEGHI M A, et al. Every picture tells a story: generating sentences from images [C] // International Conference on Computer Vision. Heraklion: Springer, 2010: 15-29.
|
|
|
| [2] |
MAO J, XU W, YANG Y, et al. Deep captioning with multimodal recurrent neural networks(m-RNN) [EB/OL]. [2014-12-20]. https://arxiv.org/abs/1412.6632.
|
|
|
| [3] |
VINYALS O, TOSHEV A, BENGIO S, et al. Show and tell: a neural image caption generator [C] // IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 3156-3164.
|
|
|
| [4] |
WU Q, SHEN C, LIU L, et al What value do explicit high level concepts have in vision to language problems[J]. Computer Science, 2016, 12 (1): 1640- 1649
|
|
|
| [5] |
ZHOU L, XU C, KOCH P, et al. Watch what you just said: image captioning with text-conditional attention [C] // Proceedings of the on Thematic Workshops of ACM Multimedia. [S.l]: Association for Computing Machinery, 2017: 305-313.
|
|
|
| [6] |
RENNIE S J, MARCHERET E, ROUEH Y, et al. Self-critical sequence training for image captioning [C] // IEEE Conference on Computer Vision and Pattern Recognition. Maryland: IEEE, 2017: 1179-1195.
|
|
|
| [7] |
SIMONYAN K, ZISSERMAN A Very deep convolutional networks for large-scale image recognition[J]. Computer Science, 2014, 32 (2): 67- 85
|
|
|
| [8] |
REN S, HE K, GIRSHICK R, et al Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 39 (6): 1137- 1149
|
|
|
| [9] |
XU K, BA J, KIROS R, et al. Show, attend and tell: neural image caption generation with visual attention [C]// Computer Science. Lille: IMLS, 2015: 2048-2057.
|
|
|
| [10] |
FANG H, GUPTA S, IANDOLA F, et al. From captions to visual concepts and back [C] // IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 1473-1482.
|
|
|
| [11] |
DONAHUE J, HENDRICKS L A, ROHRBACH M, et al Long-term recurrent convolutional networks for visual recognition and description[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 39 (4): 677- 691
|
|
|
| [12] |
WU Q, SHEN C, WANG P, et al Image captioning and visual question answering based on attributes and external knowledge[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 40 (6): 1367- 1381
|
|
|
| [13] |
YAO T, PAN Y, LI Y, et al. Boosting image captioning with attributes [C]// IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017: 4904- 4912.
|
|
|
| [14] |
YOU Q, JIN H, WANG Z, et al. Image captioning with semantic attention [C] // IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 4651- 4659.
|
|
|
| [15] |
JIN J, FU K, CUI R, et al Aligning where to see and what to tell: image caption with region-based attention and scene factorization[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 39 (12): 2321- 2334
|
|
|
| [16] |
YANG Z, YUAN Y, WU Y, et al. Encode, review, and decode: reviewer module for caption generation [C] // International Conference on Neural Image Processing System. Barcelona: [s. n.], 2016.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|