|
|
|
| Video object detection algorithm based on multi-level feature aggregation under mixed sampler |
Siyi QIN1,2( ),Shaoyan GAI1,2,*(),Feipeng DA1,2 ),Shaoyan GAI1,2,*(),Feipeng DA1,2 |
1. School of Automation, Southeast University, Nanjing 210096, China
2. Key Laboratory of Measurement and Control of Complex Engineering Systems, Ministry of Education, Southeast University, Nanjing 210096, China |
|
|
|
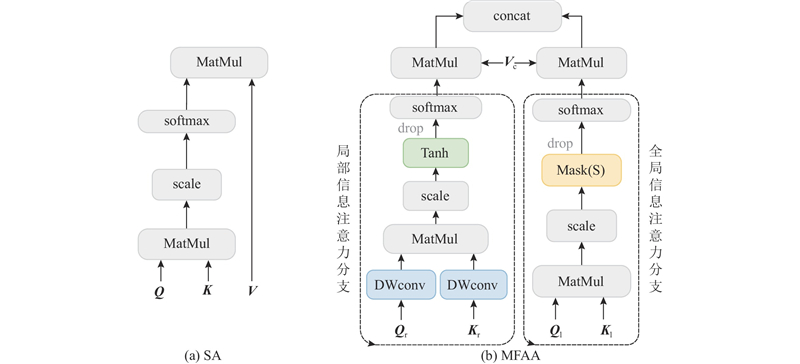
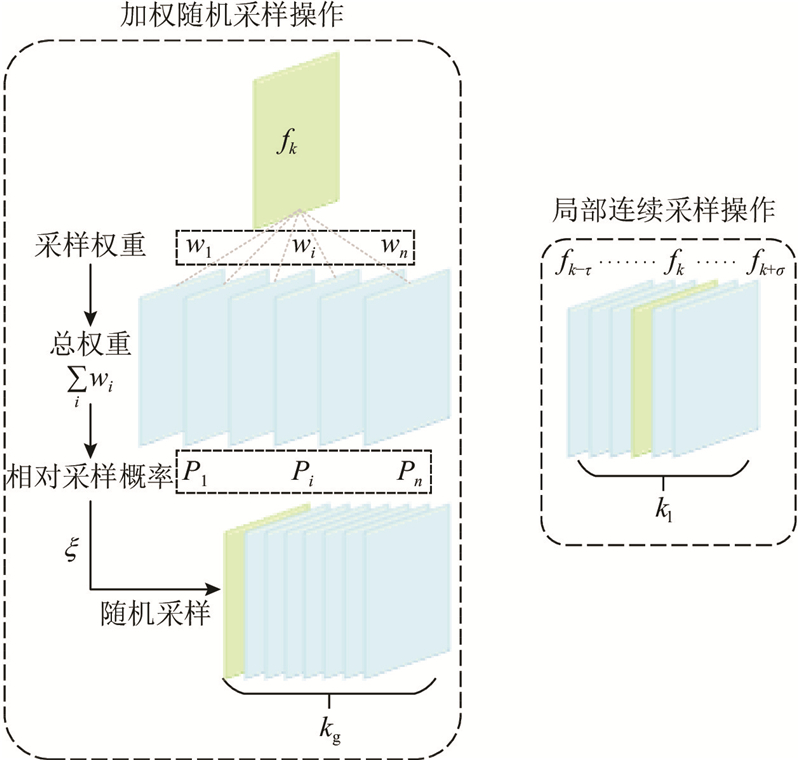
Abstract A video object detection algorithm which was built upon the YOLOX-S single-stage detector based on mixed weighted reference-frame sampler and multi-level feature aggregation attention was proposed aiming at the problems of existing deep learning-based video object detection algorithms failing to simultaneously meet accuracy and efficiency requirements. Mixed weighted reference-frame sampler (MWRS) included weighted random sampling and local consecutive sampling to fully utilize effective global information and inter-frame local information. Multi-level feature aggregation attention (MFAA) module refined the classification features extracted by YOLOX-S based on self-attention mechanism, encouraging the network to learn richer feature information from multi-level features. The experimental results demonstrated that the proposed algorithm achieved an average precision AP50 of 77.8% on the ImageNet VID dataset with an average detection speed of 11.5 milliseconds per frame. The object classification and location performance are significantly better than that of YOLOX-S, indicating that the proposed algorithm achieves higher accuracy and faster detection speed.
|
|
Received: 13 June 2023
Published: 07 November 2023
|
|
|
| Fund: 江苏省前沿引领技术基础研究专项项目(BK20192004C);江苏省高校优势学科建设工程资助项目 |
|
Corresponding Authors:
Shaoyan GAI
E-mail: qin.siyi@foxmail.com;qxxymm@163.com
|
混合采样下多级特征聚合的视频目标检测算法
针对现有基于深度学习的视频目标检测算法无法同时满足精度和效率要求的问题,在单阶段检测器YOLOX-S的基础上,提出基于混合加权采样和多级特征聚合注意力的视频目标检测算法. 混合加权参考帧采样(MWRS)策略采用加权随机采样操作和局部连续采样操作,充分利用有效的全局信息与帧间局部信息. 多级特征聚合注意力模块(MFAA)基于自注意力机制,对YOLOX-S提取的分类特征进行细化,使得网络从不同层次的特征中学到更加丰富的特征信息. 实验结果表明,所提算法在ImageNet VID数据集上的检测精度均值AP50达到77.8%,平均检测速度为11.5 ms/帧,在检测图片上的目标分类和定位效果明显优于YOLOX-S,表明所提算法达到了较高的精度,具有较快的检测速度.
关键词:
机器视觉,
视频目标检测,
特征聚合,
注意力机制,
YOLOX
|
|
| [1] |
史钰祜, 张起贵 基于局部注意的快速视频目标检测方法[J]. 计算机工程, 2022, 48 (5): 314- 320
SHI Yuhu, ZHANG Qigui Method for fast video object detection based on local attention[J]. Computer Engineering, 2022, 48 (5): 314- 320
|
|
|
| [2] |
ZHU X, WANG Y, DAI J, et al. Flow-guided feature aggregation for video object detection [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Venice: IEEE, 2017: 408-417.
|
|
|
| [3] |
ZHU X, XIONG Y, DAI J, et al. Deep feature flow for video recognition [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 2349-2358.
|
|
|
| [4] |
FEICHTENHOFER C, PINZ A, ZISSERMAN A. Detect to track and track to detect [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Venice: IEEE, 2017: 3038-3046.
|
|
|
| [5] |
KANG K, LI H, YAN J, et al T-CNN: tubelets with convolutional neural networks for object detection from videos[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2017, 28 (10): 2896- 2907
|
|
|
| [6] |
HAN M, WANG Y, CHANG X, et al. Mining inter-video proposal relations for video object detection [C]// Proceedings of the European Conference on Computer Vision. Glasgow: Springer, 2020: 431-446.
|
|
|
| [7] |
HE F, GAO N, JIA J, et al. QueryProp: object query propagation for high-performance video object detection [C]// Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI, 2022, 36(1): 834-842.
|
|
|
| [8] |
JIAO L, ZHANG R, LIU F, et al New generation deep learning for video object detection: a survey[J]. IEEE Transactions on Neural Networks and Learning Systems, 2022, 33 (8): 3195- 3215
doi: 10.1109/TNNLS.2021.3053249
|
|
|
| [9] |
WU H, CHEN Y, WANG N, et al. Sequence level semantics aggregation for video object detection [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 9217-9225.
|
|
|
| [10] |
CHEN Y, CAO Y, HU H, et al. Memory enhanced global-local aggregation for video object detection [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 10337-10346.
|
|
|
| [11] |
JIANG Z, LIU Y, YANG C, et al. Learning where to focus for efficient video object detection [C]// Proceedings of European Conference on Computer Vision. Berlin: Springer, 2020: 18-34.
|
|
|
| [12] |
RUSSAKOVSKY O, DENG J, SU H, et al Imagenet large scale visual recognition challenge[J]. International Journal of Computer Vision, 2015, 115 (3): 211- 252
doi: 10.1007/s11263-015-0816-y
|
|
|
| [13] |
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Columbus: IEEE, 2014: 580-587.
|
|
|
| [14] |
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2016: 779-788.
|
|
|
| [15] |
李凯, 林宇舜, 吴晓琳, 等 基于多尺度融合与注意力机制的小目标车辆检测[J]. 浙江大学学报: 工学版, 2022, 56 (11): 2241- 2250
LI Kai, LIN Yushun, WU Xiaolin, et al Small target vehicle detection based on multi-scale fusion technology and attention mechanism[J]. Journal of ZheJiang University: Engineering Science, 2022, 56 (11): 2241- 2250
|
|
|
| [16] |
REDMON J, FARHADI A. YOLO9000: better, faster, stronger [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Honolulu: IEEE, 2017: 6517–6525.
|
|
|
| [17] |
REDMON J, FARHADI A. YOLOv3: an incremental improvement [EB/OL]. (2018-04-08)[2023-07-31]. https://arxiv.org/abs/1804.02767.
|
|
|
| [18] |
LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C]// Proceedings of the European Conference on Computer Vision. [S. l. ]: Springer, 2016: 21-37.
|
|
|
| [19] |
YAN B, FAN P, LEI X, et al A real-time apple targets detection method for picking robot based on improved YOLOv5[J]. Remote Sensing, 2021, 13 (9): 1619- 1627
doi: 10.3390/rs13091619
|
|
|
| [20] |
GE Z, LIU S, WANG F, et al. Yolox: exceeding yolo series in 2021 [EB/OL]. (2021-08-06)[2023-07-31]. https://arxiv.org/abs/2107.08430.
|
|
|
| [21] |
于楠晶, 范晓飚, 邓天民, 等 基于多头自注意力的复杂背景船舶检测算法[J]. 浙江大学学报: 工学版, 2022, 56 (12): 2392- 2402
YU Nanjing, FAN Xiaobiao, DENG Tianmin, et al Ship detection algorithm in complex backgrounds via multi-head self-attention[J]. Journal of ZheJiang University: Engineering Science, 2022, 56 (12): 2392- 2402
|
|
|
| [22] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// In Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc. , 2017: 6000–6010.
|
|
|
| [23] |
NEUBECK A, VAN G L. Efficient non-maximum suppression [C]// 18th International Conference on Pattern Recognition. Hong Kong: IEEE, 2006: 850-855.
|
|
|
| [24] |
张娜, 戚旭磊, 包晓安, 等 基于25预测定位的单阶段目标检测算法[J]. 浙江大学学报: 工学版, 2022, 56 (4): 783- 794
ZHANG Na, QI Xulei, BAO Xiaoan, et al Single-stage object detection algorithm based on optimizing position prediction[J]. Journal of ZheJiang University: Engineering Science, 2022, 56 (4): 783- 794
|
|
|
| [25] |
SUN G, HUA Y, HU G, et al. Mamba: multi-level aggregation via memory bank for video object detection [C]// Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI, 2021: 2620-2627.
|
|
|
| [26] |
WANG H, TANG J, LIU X, et al. PTSEFormer: progressive temporal-spatial enhanced TransFormer towards video object detection [C]// Proceedings of the European Conference on Computer Vision. Tel Aviv: Springer, 2022: 732-747.
|
|
|
| [27] |
EFRAIMIDIS P S, SPIRAKIS P G Weighted random sampling with a reservoir[J]. Information Processing Letters, 2006, 97 (5): 181- 185
doi: 10.1016/j.ipl.2005.11.003
|
|
|
| [28] |
TAN M, LE Q. Efficientnet: rethinking model scaling for convolutional neural networks [C]// International Conference on Machine Learning. Long Beach: [s. n.], 2019: 6105-6114.
|
|
|
| [29] |
ZHENG Z, WANG P, LIU W, et al. Distance-IoU loss: faster and better learning for bounding box regression [C]// Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI, 2020: 12993-13000.
|
|
|
| [30] |
KIM J, KOH J, LEE B, et al. Video object detection using object's motion context and spatio-temporal feature aggregation [C]// 25th International Conference on Pattern Recognition. Milan: IEEE, 2021: 1604-1610.
|
|
|
| [31] |
蔡强, 李韩玉, 李楠, 等 基于时序信息和注意力机制的视频目标检测[J]. 计算机仿真, 2021, 38 (12): 380- 385
CAI Qiang, LI Hanyu, LI Nan, et al Video object detection with temporal information and attention mechanism[J]. Computer Simulation, 2021, 38 (12): 380- 385
doi: 10.3969/j.issn.1006-9348.2021.12.078
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|