1. College of Data Science and Applications, Inner Mongolia University of Technology, Hohhot 010051, China 2. Inner Mongolia Autonomous Region Engineering Technology Research Center of Big Data Based Software Service, Hohhot 010000, China 3. Faculty of Information Technology, Beijing University of Technology, Beijing 100124, China
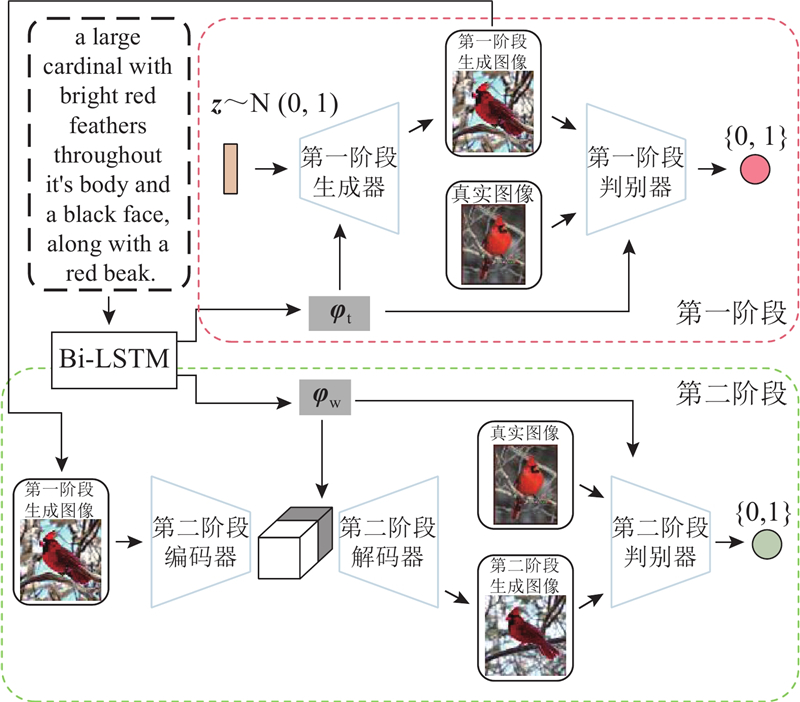
A generative adversarial network with deep fusion attention (DFA-GAN) was proposed, using multiple loss functions as constraints, to address the issues of poor image quality and inconsistency between text descriptions and generated images in traditional text-to-image generation methods. A two-stage image generation process was employed with a single-level generative adversarial network (GAN) as the backbone. An initial blurry image which was generated in the first stage was fed into the second stage, and high-quality image regeneration was achieved to enhance the overall image generation quality. During the first stage, a visual-text fusion module was designed to deeply integrate text features and image features, and text information was adequately fused during the image sampling process at different scales. In the second stage, an image generator with an improved Vision Transformer as the encoder was proposed to fully fuse image features with text description word features. Quantitative and qualitative experimental results showed that the proposed method outperformed other mainstream models in terms of image quality improvement and alignment with text descriptions.
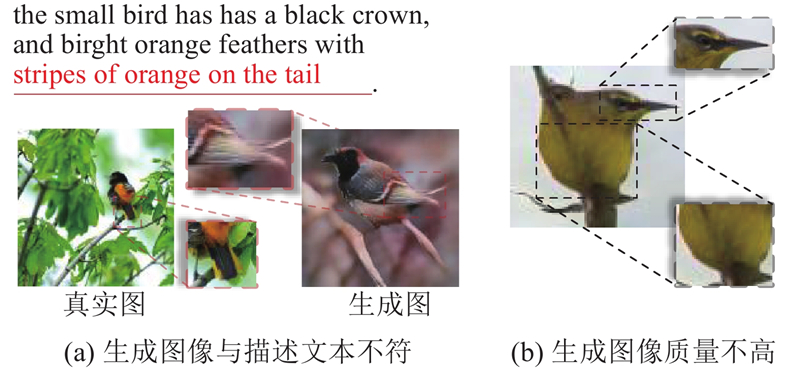
Fig.1Problems with mainstream methods of generating images
Fig.2Model architecture diagram of proposed method
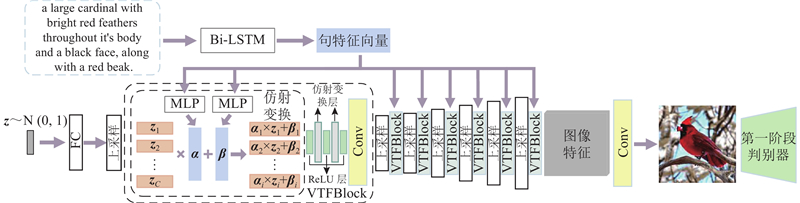
Fig.3Architecture diagram for image generation stage of deep fusion of text features
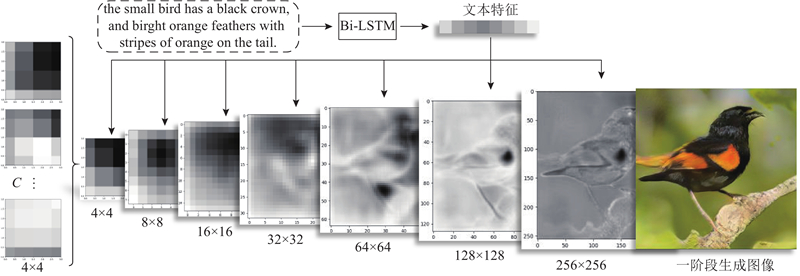
Fig.4Multi-scale fusion of text features and image features
Fig.5Architecture diagram for image generation stage of attention mechanism optimization
模型
CUB
COCO
IS
FID
FID
StackGAN[6]
3.70
35.51
74.05
StackGAN++[6]
3.84
—
—
AttnGAN[2]
4.36
24.37
35.49
MirrorGAN[8]
4.56
18.34
34.71
textStyleGAN[28]
4.78
—
—
DM-GAN[29]
4.75
16.09
32.64
SD-GAN[30]
4.67
—
—
DF-GAN[8]
5.10
14.81
19.32
SSA-GAN[31]
5.17
15.61
19.37
RAT-GAN[32]
5.36
13.91
14.60
CogView2[33]
—
—
17.70
KNN-Diffusion[16]
—
—
16.66
DFA-GAN-第一阶段
4.53
16.07
25.09
DFA-GAN-第二阶段
5.34
10.96
19.17
Tab.1Comparison of evaluation indexes of text-to-image generation methods in two datasets
模型
IS
RP
AttnGAN
4.36
67.83
AttnGAN+DFA-GAN第二阶段
5.11
70.06
DF-GAN
5.10
44.83
DF-GAN+ DFA-GAN第二阶段
5.32
70.80
DFA-GAN
5.34
72.67
Tab.2Ablation experiments of different models in CUB datasets
Fig.6Comparison of generated images of different models in CUB dataset
Fig.7Comparison of generated images of different models in COCO dataset
Fig.8Comparison of generated images in two stages of proposed model in different datasets
[1]
GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets [C]// Proceedings of the 27th International Conference on Neural Information Processing Systems . Cambridge: MIT Press, 2014: 2672–2680.
[2]
XU T, ZHANG P, HUANG Q, et al. AttnGAN: fine-grained text to image generation with attentional generative adversarial networks [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 1316–1324.
[3]
韩爽. 基于生成对抗网络的文本到图像生成技术研究[D]. 大庆: 东北石油大学, 2022. HAN Shuang. Research on text-to-image generation techniques based on generative adversarial networks [D]. Daqing: Northeast Petroleum University, 2022.
[4]
QIAO T, ZHANG J, XU D, et al. Learn, imagine and create: text-to-image generation from prior knowledge [C]// Proceeding of the 33rd Conference on Neural Information Processing Systems . Vancouver: [s. n.], 2019: 887–897.
[5]
LIANG J, PEI W, LU F. CPGAN: content-parsing generative adversarial networks for text-to-image synthesis [C]// Proceeding of the 16th European Conference on Computer Vision . [S. l.]: Springer, 2020: 491–508.
[6]
ZHANG H, XU T, LI H, et al. StackGAN: text to photo-realistic image synthesis with stacked generative adversarial networks [C]// 2017 IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 5908–5916.
[7]
ZHANG H, XU T, LI H, et al StackGAN++: realistic image synthesis with stacked generative adversarial networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 41 (8): 1947- 1962
[8]
QIAO T, ZHANG J, XU D, et al. MirrorGAN: learning text-to-image generation by redescription [C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 1505–1514.
[9]
TAO M, TANG H, WU F, et al. Df-GAN: a simple and effective baseline for text-to-image synthesis [C]// 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans, 2022: 16515–16525.
[10]
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale [EB/OL]. (2021-06-03)[2023-09-17]. https://arxiv.org/pdf/2010.11929.pdf.
[11]
REED S, AKATA Z, YAN X, et al. Generative adversarial text to image synthesis [C]// Proceedings of the 33rd International Conference on Machine Learning . New York: ACM, 2016: 1060–1069.
[12]
ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks [C]// 2017 IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2223–2232.
[13]
贺小峰, 毛琳, 杨大伟 文本生成图像中语义-空间特征增强算法[J]. 大连民族大学学报, 2022, 24 (5): 401- 406 HE Xiaofeng, MAO Lin, YANG Dawei Semantic-spatial feature enhancement algorithm for text-to-image generation[J]. Journal of Dalian Minzu University, 2022, 24 (5): 401- 406
[14]
薛志杭, 许喆铭, 郎丛妍, 等 基于图像-文本语义一致性的文本生成图像方法[J]. 计算机研究与发展, 2023, 60 (9): 2180- 2190 XUE Zhihang, XU Zheming, LANG Congyan, et al Text-to-image generation method based on image-text semantic consistency[J]. Journal of Computer Research and Development, 2023, 60 (9): 2180- 2190
SHEYNIN S, ASHUAL O, POLYAK A, et al. KNN-diffusion: image generation via large-scale retrieval [EB/OL]. (2022-10-02)[2023-09-17]. https://arxiv.org/pdf/2204.02849.pdf.
[17]
NICHOL A Q, DHARIWAL P, RAMESH A, et al. GLIDE: towards photorealistic image generation and editing with text-guided diffusion models [C]// International Conference on Machine Learning . Long Beach: IEEE, 2022: 16784–16804.
[18]
田枫, 孙小强, 刘芳, 等 融合双注意力与多标签的图像中文描述生成方法[J]. 计算机系统应用, 2021, 30 (7): 32- 40 TIAN Feng, SUN Xiaoqiang, LIU Fang, et al Chinese image caption with dual attention and multi-label image[J]. Computer Systems and Applications, 2021, 30 (7): 32- 40
[19]
HUANG Z, XU W, YU K. Bidirectional LSTM-CRF models for sequence tagging [EB/OL]. (2015-08-09)[2023-09-17]. https://arxiv.org/pdf/1508.01991.pdf.
[20]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceeding of the 31st International Conference on Neural Information Processing Systems . Long Beach: [s.n.], 2017: 6000–6010.
[21]
MIRZA M, OSINDERO S. Conditional generative adversarial nets [EB/OL]. (2014-11-06)[2023-09-17]. https://arxiv.org/pdf/1411.1784.pdf.
[22]
WAH C, BRANSON S, WELINDER P, et al. The Caltech-UCSD Birds-200-2011 dataset [EB/OL]. (2022-08-12)[2023-09-17]. https://authors.library.caltech.edu/27452/1/CUB_200_2011.pdf.
[23]
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [C]// European Conference on Computer Vision . [S. l.]: Springer, 2014: 740–755.
[24]
SALIMANS T, GOODFELLOW I, ZAREMBA W, et al. Improved techniques for training GANs [J]. Proceedings of the 30th International Conference on Neural Information Processing Systems . Barcelona: [s. n.], 2016: 2234–2242.
[25]
HEUSEL M, RAMSAUER H, UNTERTHINER T, et al. GANs trained by a two time-scale update rule converge to a local nash equilibrium [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems . Long Beach: [s.n.], 2017: 6629–6640.
[26]
王家喻. 基于生成对抗网络的图像生成研究[D]. 合肥: 中国科学技术大学, 2021. WANG Jiayu. Image generation based on generative adversarial networks [D]. Hefei: University of Science and Technology of China, 2021.
[27]
王蕾. 基于关联语义挖掘的文本生成图像算法研究[D]. 西安: 西安电子科技大学, 2020. WANG Lei. Text-to-image synthesis based on semantic correlation mining [D]. Xi’an: Xidian University, 2020.
[28]
STAP D, BLEEKER M, IBRAHIMI S, et al. Conditional image generation and manipulation for user-specified content [EB/OL]. (2020-05-11)[2023-09-17]. https://arxiv.org/pdf/2005.04909.pdf.
[29]
ZHU M, PAN P, CHEN W, et al. DM-GAN: dynamic memory generative adversarial networks for text-to-image synthesis [C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 5802–5810.
[30]
YIN G, LIU B, SHENG L, et al. Semantics disentangling for text-to-image generation [C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 2327–2336.
[31]
LIAO W, HU K, YANG M Y, et al. Text to image generation with semantic-spatial aware GAN [C]// 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 18187–18196.
[32]
YE S, WANG H, TAN M, et al Recurrent affine transformation for text-to-image synthesis[J]. IEEE Transactions on Multimedia, 2023, 26: 462- 473
[1]
Yin CAO,Junping QIN,Qianli MA,Hao SUN,Kai YAN,Lei WANG,Jiaqi REN. Survey of text-to-image synthesis[J]. Journal of ZheJiang University (Engineering Science), 2024, 58(2): 219-238.