|
|
|
| Text-to-image generation method based on single stage generative adversarial network |
Bing YANG1,2( ),Wei NA1,2,Xue-qin XIANG3 ),Wei NA1,2,Xue-qin XIANG3 |
1. School of Computer Science and Technology, Hangzhou Dianzi University, Hangzhou 310018, China
2. Key Laboratory of Brain Machine Collaborative Intelligence of Zhejiang Province, Hangzhou Dianzi University, Hangzhou 310018, China
3. Hangzhou Lingban Technology Limited Company, Hangzhou 311121, China |
|
|
|
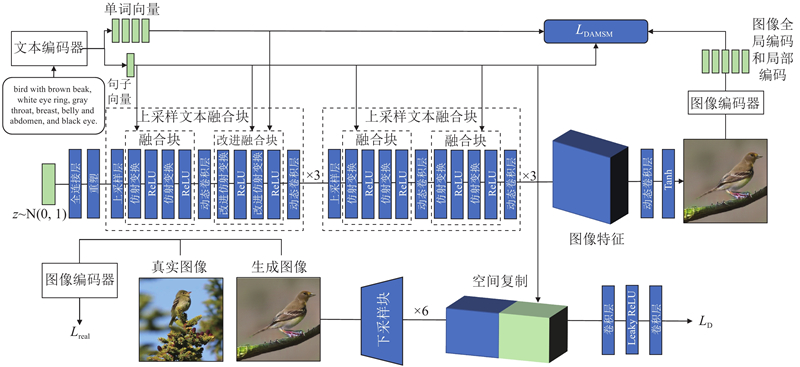
Abstract A novel text-to-image generation method was proposed to enhance the quality of generated images, utilizing single-stage text-to-image generation backbone. On the basis of the original model that exclusively used sentence information for image generation, an attention mechanism was employed to integrate word information into image features. The quality of generated images was improved by judiciously incorporating additional textual information in a reasonable manner. The introduction of contrast loss makes the same semantic images closer and different semantic images more distant, so as to better ensure the semantic consistency between the text and the generated image. Dynamic convolution was used in the generator to enhance the expression ability of the generator. Experimental results illustrate that the proposed method obtains substantial performance improvements in both the CUB (Fréchet inception distance (FID) from 12.10 to 10.36) and COCO (FID from 15.41 to 12.74) datasets.
|
|
Received: 05 March 2023
Published: 27 December 2023
|
|
|
| Fund: 浙江省基础公益研究计划(LGG22F020027);国家自然科学基金资助项目(61633010, U1909202) |
基于单阶段生成对抗网络的文本生成图像方法
为了提高生成图像质量,提出新的文本生成图像方法,整体框架采用单阶段文本生成图像主干. 在原有模型只使用句子信息生成图像的基础上,使用注意力机制把单词信息融入图像特征,采用合理地融入更多文本信息的方式提高生成图像的质量.引入对比损失,使相同语义图像之间更加接近,不同语义图像之间更加疏远,从而更好地保证文本与生成图像之间的语义一致性.在生成器中采用动态卷积来增强生成器的表达能力. 实验结果表明,所提方法在数据集CUB (Fréchet inception distance (FID)从12.10提升到10.36)和数据集COCO (FID从15.41提升到12.74)上都获得了较好的性能提升.
关键词:
文本生成图像,
注意力机制,
对比损失,
语义一致性,
动态卷积
|
|
| [1] |
GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets [C]// Proceedings of the 27th International Conference on Neural Information Processing Systems. [S.l.]: MIT Press, 2014: 2672-2680.
|
|
|
| [2] |
王凯, 岳泊暄, 傅骏伟, 等 基于生成对抗网络的图像恢复与SLAM容错研究[J]. 浙江大学学报: 工学版, 2019, 53 (1): 115- 125
WANG Kai, YUE Bo-xuan, FU Jun-wei, et al Image restoration and fault tolerance of stereo SLAM based on generative adversarial net[J]. Journal of Zhejiang University: Engineering Science, 2019, 53 (1): 115- 125
|
|
|
| [3] |
XU T, ZHANG P, HUANG Q, et al. AttnGAN: fine-grained text to image generation with attentional generative adversarial networks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 1316-1324.
|
|
|
| [4] |
LI B, QI X, LUKASIEWICZ T, et al. ManiGAN: text-guided image manipulation[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 7877-7886.
|
|
|
| [5] |
TAO M, TANG H, WU F, et al. DF-GAN: a simple and effective baseline for text-to-image synthesis[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 16494-16504.
|
|
|
| [6] |
HAN J, SHOEIBY M, PETERSSON L, et al. Dual contrastive learning for unsupervised image-to-image translation[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Nashville: IEEE, 2021: 746-755.
|
|
|
| [7] |
REED S, AKATA Z, YAN X, et al. Generative adversarial text to image synthesis[C]// Proceedings of the 33rd International Conference on International Conference on Machine Learning. [S.l.]: JMLR, 2016: 49-58.
|
|
|
| [8] |
ZHANG H, XU T, LI H, et al. StackGAN: text to photo-realistic image synthesis with stacked generative adversarial networks[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 5907-5915.
|
|
|
| [9] |
TAN H, LIU X, LI X, et al. Semantics-enhanced adversarial nets for text-to-image synthesis[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 10500-10509.
|
|
|
| [10] |
LIAO W, HU K, YANG M Y, et al. Text to image generation with semantic-spatial aware GAN[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 18166-18175.
|
|
|
| [11] |
YE S, LIU F, TAN M. Recurrent affine transformation for text-to-image synthesis [EB/OL]. (2022-04-01)[2022-12-01]. https://arxiv.org/pdf/2204.10482.pdf.
|
|
|
| [12] |
KUMARI N, ZHANG B, ZHANG R, et al. Multi-concept customization of text-to-image diffusion[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 1931-1941.
|
|
|
| [13] |
QIAO T, ZHANG J, XU D, et al. MirrorGAN: learning text-to-image generation by redescription[C]// Proceedings of the 2019 Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 1505-1514.
|
|
|
| [14] |
YIN G, LIU B, SHENG L, et al. Semantics disentangling for text-to-image generation[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 2322-2331.
|
|
|
| [15] |
YE H, YANG X, TAKAC M, et al. Improving text-to-image synthesis using contrastive learning [EB/OL]. (2021-07-01)[2022-12-01]. https://arxiv.org/pdf/2107.02423.pdf.
|
|
|
| [16] |
HE K, FAN H, WU Y, et al. Momentum contrast for unsupervised visual representation learning[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 9726-9735.
|
|
|
| [17] |
ZHU M, PAN P, CHEN W, et al. DM-GAN: dynamic memory generative adversarial networks for text-to-image synthesis[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 5795-5803.
|
|
|
| [18] |
ZHANG H, KOH J Y, BALDRIDGE J, et al. Cross-modal contrastive learning for text-to-image generation[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 833-842.
|
|
|
| [19] |
CHEN Y, DAI X, LIU M, et al. Dynamic convolution: attention over convolution kernels[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 11027-11036.
|
|
|
| [20] |
SCHUSTER M, PALIWAL K K Bidirectional recurrent neural networks[J]. IEEE Transactions on Signal Processing, 1997, 45 (11): 2673- 2681
doi: 10.1109/78.650093
|
|
|
| [21] |
RUSSAKOVSKY O, DENG J, SU H, et al Imagenet large scale visual recognition challenge[J]. International Journal of Computer Vision, 2015, 115 (3): 211- 252
doi: 10.1007/s11263-015-0816-y
|
|
|
| [22] |
SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 2818-2826.
|
|
|
| [23] |
LIN TY, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[C]// Proceedings of the ECCV 2014. [S.l.]: Springer, 2014: 740-755.
|
|
|
| [24] |
WAH C, BRANSON S, WELINDER P, et al. The caltech-ucsd birds-200-2011 dataset [R]. Pasadena: California Institute of Technology, 2011.
|
|
|
| [25] |
HEUSEL M, RAMSAUER H, UNTERTHINER T, et al. GANs trained by a two time-scale update rule converge to a local nash equilibrium[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach: Curran Associates, 2017: 6629–6640.
|
|
|
| [26] |
KINGMA D P, BA J L. ADAM: a method for stochastic optimization [EB/OL]. (2014-12-01)[2022-12-01]. https://arxiv.org/pdf/1412.6980.pdf.
|
|
|
| [27] |
HAN S C, LONG S, LUO S, et al. VICTR: visual information captured text representation for text-to-image multimodal tasks [EB/OL]. (2020-10-01)[2022-12-01]. https://arxiv.org/pdf/2010.03182.pdf.
|
|
|
| [28] |
HINZ T, HEINRICH S, WERMTER S. Semantic object accuracy for generative text-to-image synthesis [EB/OL]. (2019-10-01)[2022-12-01]. https://arxiv.org/pdf/1910.13321.pdf.
|
|
|
| [29] |
RUAN S, ZHANG Y, ZHANG K, et al. DAE-GAN: dynamic aspect-aware GAN for text-to-image synthesis[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 13940-13949.
|
|
|
| [30] |
FENG F, NIU T, LI R, et al Modality disentangled discriminator for text-to-image synthesis[J]. IEEE Transactions on Multimedia, 2022, 24: 2112- 2124
doi: 10.1109/TMM.2021.3075997
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|