

随着社会老龄化的加剧,轮椅机器人的需求逐年增长. 为了实现高龄残障者的自主安全移动,有必要进一步研究轮椅机器人的智能操控方法.
在狭小环境中操控轮椅避免碰撞,对于高龄用户来说是挑战. 虽然路径规划的自动导航避障方法能够减少操作并预防碰撞[13-14],但完全依赖机器导航,无法满足自主性需求. 共享控制(shared control, SC)结合人类意图与机器导航来控制机器人,提升了人机交互质量[15]. 已有基于递归贝叶斯[16]、SC框架[17]、强化学习[18]、概率方法[19]的共享控制策略,这些策略考虑了用户意图、交互不确定性及避障距离等因素. 不同个体对避障距离的敏感度不同,距离过短会引发紧迫感和恐惧,距离过长则会导致不适并占用过多空间. 老年人或残障人士难以通过人工调整共享框架的参数来满足避障要求,产生巨大的试错成本,甚至可能引发危险[20]. 此外,电动轮椅的操作复杂,即使在相同条件下操作也可能不同[21]. 已有研究很少有关于机器人自主适应不同用户操作习惯的方法.
基于以上考虑,本文设计融合模糊强化学习的SC策略,采用基于座椅压力的模糊推理识别方向意图,通过高斯函数构建的奖励函数评估用户操作习惯和安全性,确保轮椅机器人能够适应个体操作习惯,提升用户的舒适性和安全性. 通过实验验证所提方法能够适应个体操作习惯,提升用户的舒适性并保证安全性.
1. 系统概述
以实验室自主研发的全方位移动轮椅机器人(wheelchair robot, WR)为研究对象. 如图1所示,WR底盘安装4个动力全向轮以实现全方向移动. WR底盘四周安装4个超声波传感器,以检测环境中的障碍物用于自动避障. 座椅下安装8个力传感器,以检测人坐下后的压力分布情况.
图 1

2. 方法概述
2.1. 方法介绍
本文的整体框架如图2所示. 基于距离型模糊推理,建立座椅压力分布与用户方向意图的映像关系,以实时检测用户意图指令βh. 利用超声波传感器并基于模糊规则1,建立机器人自动避障导航方法,以获得安全机器避障指令βa,并建立基于权重系数k的线性叠加机制共享控制框架. 在该框架中考虑用户的操作习惯,基于三重奖励的模糊强化学习策略,确定用户控制权重系数k. 具体而言,通过衡量用户意图方向与机器人实际方向的偏差度,基于高斯函数建立当前奖励函数作为第一重奖励,基于偏差率建立预测奖励函数作为第二重奖励,以估计用户操作习惯. 此外,基于边界距离建立任务奖励函数作为第三重奖励,以估计人机安全性. 将用户意图指令βh和机器避障指令βa加权融合,得到最终的运动方向βs,并将其发送给WR电机驱动器.
图 2
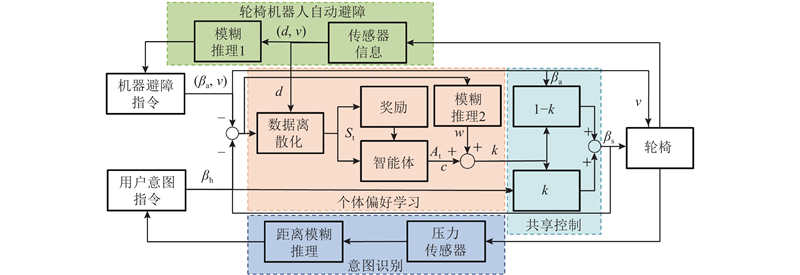
图 2 考虑个体操作习惯的人机共享避障方法框架
Fig.2 System flowchart of human-machine shared obstacle avoidance method considering individual operating habit
2.2. 人机协同共享控制框架
2.2.1. 用户意图指令识别
基于距离型模糊推理,对用户意图指令进行识别.
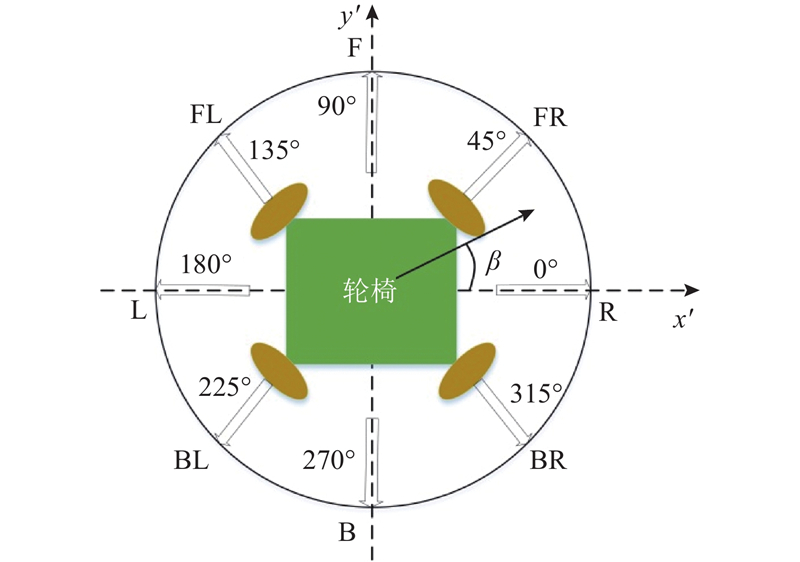
1) 数据库的建立. 基于预实验,建立方向意图识别数据库. 在测试实验中,要求用户有意识地朝8个方向倾斜,如图3所示:右(R)、前右(FR)、前(F)、前左(FL)、左(L)、后左(BL)、后面(B)和右后方(BR). 其中,β表示方向意图. 通过多次实验发现,当方向变化时,采用以下4个压力传感器进行压力检测:Sen.FR、Sen.FL、Sen.RF、Sen.LF. 其中,Sen.FR、Sen.FL、Sen.RF、和Sen.LF分别表示位于座垫下前侧靠右、前侧靠左、右侧靠前、左侧靠前的压力传感器(见图1). 每个受试者分别朝8个方向开展多次试验,对压力传感器的检测数据进行统计分析,建立包含8个方向数据的数据库. 计算每个方向上每个传感器输出的平均值和标准偏差,并标记为AMij和ASij. 其中,i = 1, 2
图 3
2) 模糊规则及隶属度函数的建立. 基于if-then规则,建立方向意图识别模糊规则,如表1所示. 表中,xk (k = 1, 2, 3, 4)为4个压力传感器的检测值,表示模糊推理的前件;β为模糊推理的后件,表示意图方向. 假设存在论域X,代表传感器输出的可能值集合. Aij∈X(i = 1, 2,
表 1 If-then 模糊规则
Tab.1
| 规则1:若x1=A11, x2=A12, x3=A13, x4=A14, 则 规则2:若x1= A21, x2= A22, x3=A23, x4=A24, 则 . . . . . . . . . . 规则8:若x1=A81, x2=A82, x3=A83, x4=A84, 则 前提:x1=A1, x2=A2, x3=A3, x4=A4 |
| 结论: |
图 4
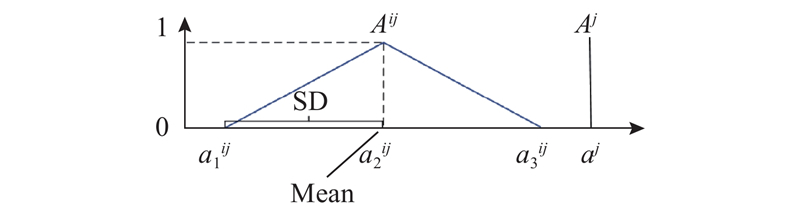
输入变量x1、x2、x3和x4之间的隶属关系由AND运算确定,当按照所描述的模糊规则定义时,可以使用距离型模糊推理方法,从力传感器的当前输出中推导得到用户的方向意图.
式中:
基于距离型模糊推理方法的方向意图识别方法包括以下3个步骤.
1)根据式(1)所示的距离计算公式,可以计算得到Aij与Aj之间的距离dij为
当事实与前件的分离程度增加时,计算得出的距离dij随之增大,当事实Aj与前件Aij完全重合时,dij为0.
2)由于输入变量x1、x2、x3、x4之间的隶属关系是通过AND运算表示的,距离可以表示为
式中:di反映了事实和第i条规则之间的相关性. 较小的di表示强相关性,意味着识别结果与第i个结果接近. 权重因子wj表示每个传感器在每个模糊规则中的重要性. 通过对传感器进行加权,能够提高模糊推理的精度.
3)通过以下推理计算得到方向意图角:
式中:bi为每个模糊规则的结果. 对于式(4),推理结果是所有模糊结果的空间平均值,因此βh为用户方向意图角.
2.2.2. 人机协同共享控制机制
为了既尊重用户的自主意愿,又能避免误操作引起的碰撞风险,采用状态融合式共享控制策略,如图5所示. 该策略通过仲裁机制(arbitration),将人类操作员给定的命令状态和机器人自主智能给定的命令状态进行协调,共同完成避障任务. 状态融合式共享控制策略的仲裁机制采用权重线性叠加机制,公式如下:
图 5
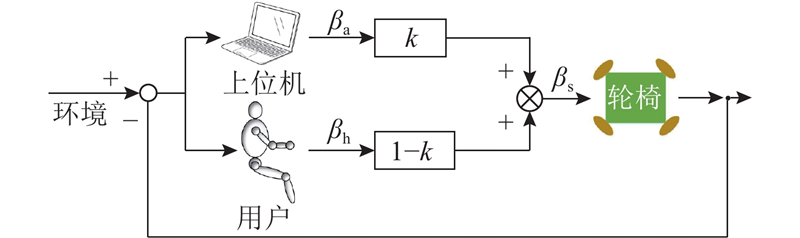
式中:βa为由前期研究成果自动避障规划器规划出的机器避障指令方向[24];1−k为人的意图权重参数,1−k∈[0, 1.0].
在权重线性叠加机制中,通过将意图方向指令角和机器避障指令角进行加权平均,获得轮椅机器人的最终命令输入. k为机器人自主智能控制的权重,表示机器人的自主水平:权重越高,机器人的自主水平越高. k的选择对共享控制的性能影响显著,本研究提出基于安全及个体操作习惯的智能权重选择法,即k由基于安全的权重w和基于个体操作习惯的权重c共同构成.
2.2.3. 基于安全考虑的共享权重w的选择
图 6
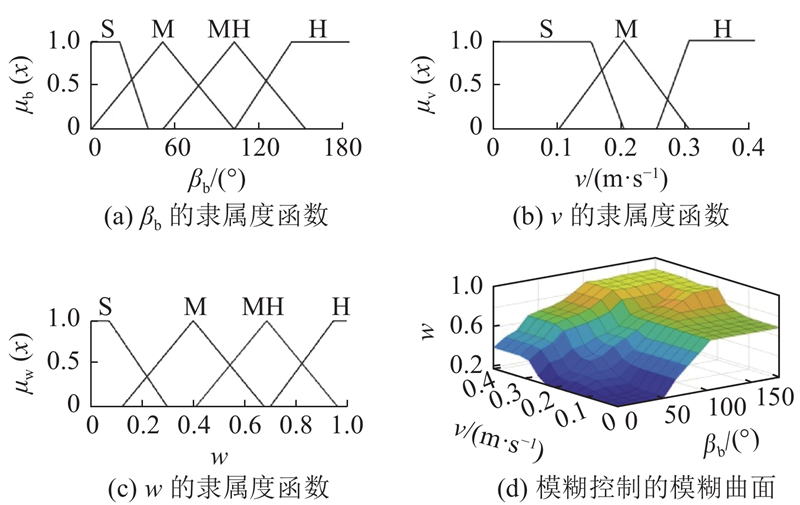
模糊推理中的输入变量和输出变量使用三角形的隶属函数进行描述. 如图6所示,这些模糊变量的隶属函数
2.2.4. 考虑个体操作习惯的补偿权重c的选择
设计模糊强化学习策略,在保证避障安全的基础上,将用户操作习惯引入共享控制框架中,提高用户的舒适度,基于如图7所示的强化学习模块求取补偿权重c. 强化学习策略中的智能体基于当前动作-状态值函数,采用寻求最大化累积奖励的策略来选择动作c=At,对共享控制权重w进行补偿,以加权求和的方式将其输出到轮椅. 通过循环进行在线学习和训练,直到训练策略达到最优.
图 7
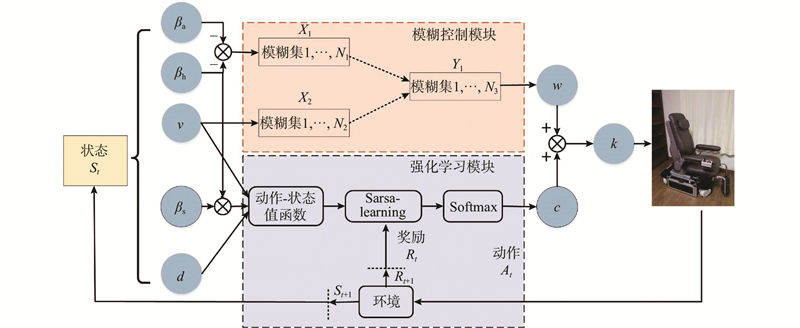
将共享控制公式(5)改为
1) 离散状态设计驾驶. WR是连续的过程,将连续数据转换为离散数据有助于降低算法的计算复杂度[25]. 当驾驶者和轮椅机器人之间发生交互时,机器人会在每个时间步长t内收集当前状态St = (|βh−βs|, v, d). 其中|βh−βs|为驾驶者的行驶方向意图与机器人的实际行驶方向差异的绝对值,v为轮椅机器人的当前行驶速度,d为与最近的障碍物之间的距离.
2) 奖励函数的设计. 当驾驶者觉得避障距离太近时,其意图指令会朝着远离障碍物的方向,反之亦然. 一般而言,在驾驶WR避障行进过程中,机器人的实际行驶方向与用户的操作指令越接近,则越能准确反映用户的操作习惯. 面向用户操作习惯建立奖励函数βc如下:
定义避障周期为从WR探测到障碍物执行避障操作开始,直至其绕开障碍物恢复正常前进的过程. 在每个完整的避障周期内,通过0.2 s的时钟周期来采集驾驶者的操作指令和实际行驶指令的离散数列. 三重奖励函数如下:
式中:Rc为任务奖励;p1、p2为常数;若d = [0,200],则Rc = ̶ 10,否则Rc = 0;
3) 在线强化学习算法. 选择采用Sarsa-learning算法,计算在不同状态下选择最佳用户控制权重的最优策略. 值函数估计的单步更新方程定义为
式中:α为学习率,γ为折扣因子.
4) 动作函数设计. 动作选择遵循一项规则:选择估计动作值最高的动作(或动作之一). 采用SoftMax方法进行动作选择,该方法通过将动作概率作为估计值的分级函数来选择,有效地平衡了强化学习中的探索和利用,公式如下:
式中:m为SoftMax的温度系数,可以调节输出概率分布的平滑程度;a、b为动作的序号.
3. 实验分析
3.1. 座椅压力映射方向意图的实验
为了验证所提方法的有效性,招募3名健康男性代号为A、B、C作为受试者进行实验. 涉及的人类受试者实验程序已获得沈阳工业大学的批准,取得了书面知情同意. 受试者的平均年龄为24岁,平均身高为175 cm,平均体重为65 kg. 所有参与者的健康状况良好. 基于预实验建立数据库,确定推理规则的隶属度函数. 具体过程如下:每个受试者被要求向每个方向倾斜身体20 s,每个方向进行10次试验. 当3个受试者有意识地朝如图3所示的8个方向角βi移动时,力传感器输出的总平均值和标准差构成模糊规则前件的隶属度函数,方向意向构成规则后件,建立模糊规则数据库.
为了进一步验证所提出的识别方法的可靠性,要求3名受试者有意控制轮椅机器人沿8个固定方向(R、FR、F、FL、L、BL、B、BR)直线移动. 根据式(4),将n设定为8,计算每位实验对象的识别误差的平均值Emin,具体结果如表3所示. 0°、45°、90°、135°、180°、225°、270°、315°方向的平均识别误差分别为4.47°、3.5°、5.3°、0.8°、2.4°、4.6°、1.8°、3.1°. 实验对象A在315°方向上的识别误差最大为4.7°,实验对象B在225°方向上的识别误差最大为−7.2°. 实验对象C在90°方向上的识别误差最大为9.8°. 考虑到人类不常倾斜向后运动,对于225°和315°方向的识别误差较大.
表 3 每个被试的识别误差
Tab.3
| βi/ (°) | Emin/ (°) | ||
| 实验对象A | 实验对象B | 实验对象C | |
| 0 | −1.5 | −3.8 | −8.1 |
| 45 | 0.5 | 4.9 | −5.1 |
| 90 | 1.9 | 4.3 | 9.8 |
| 135 | −1.2 | 0.5 | 0.7 |
| 180 | −0.5 | 0.3 | 6.4 |
| 225 | −0.7 | −7.2 | −5.9 |
| 270 | 2.9 | 2.5 | −0.22 |
| 315 | 4.7 | 2.9 | 1.7 |
3.2. 人机协同共享控制避障实验
3.2.1. 考虑安全性的人-轮椅状态融合式共享控制避障实验
在如图8所示实验室环境内对所提避障策略进行验证,考虑高龄者在狭小空间中的安全性和操作性,实验中的期望速度被设定为0.2 m/s和0.3 m/s两种情况. 选取2个测试进行对比实验. 测试1:在轮椅避障的过程中,不考虑用户的操作意图,WR按照竖直向前90°的方向行驶,通过自动避障导航,绕开2个障碍物安全行驶到达终点. 测试2:在轮椅机器人避障的过程中,考虑到用户会偏向障碍物的操作意图,这可能是误操作或者用户不需要很大的距离来避障. 为了记录行驶轨迹数据,采用超宽带 (ultra wide band, UWB)定位方法.
图 8

图 9
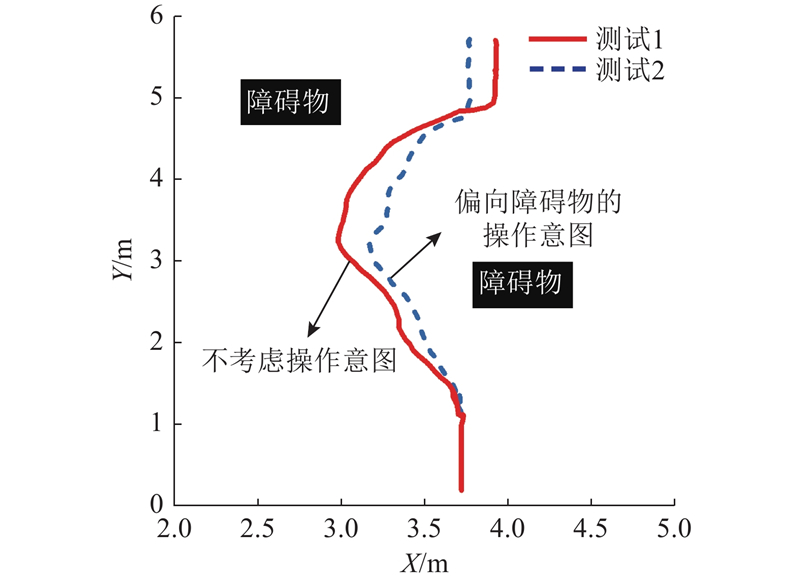
图 9 期望速度为0.2 m/s时的避障路径图
Fig.9 Obstacle avoidance path with desired speed of 0.2 m/s
图 10
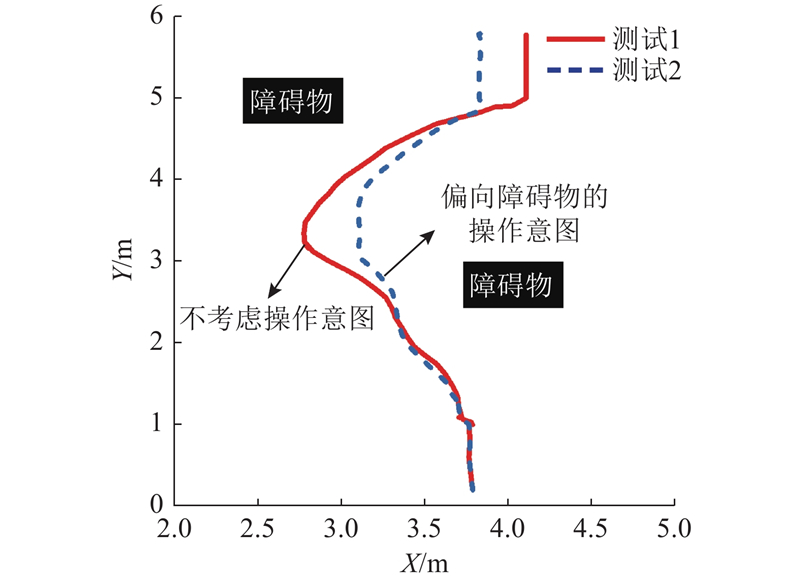
图 10 期望速度为0.3 m/s时的避障路径图
Fig.10 Obstacle avoidance path with desired speed of 0.3 m/s
图 11
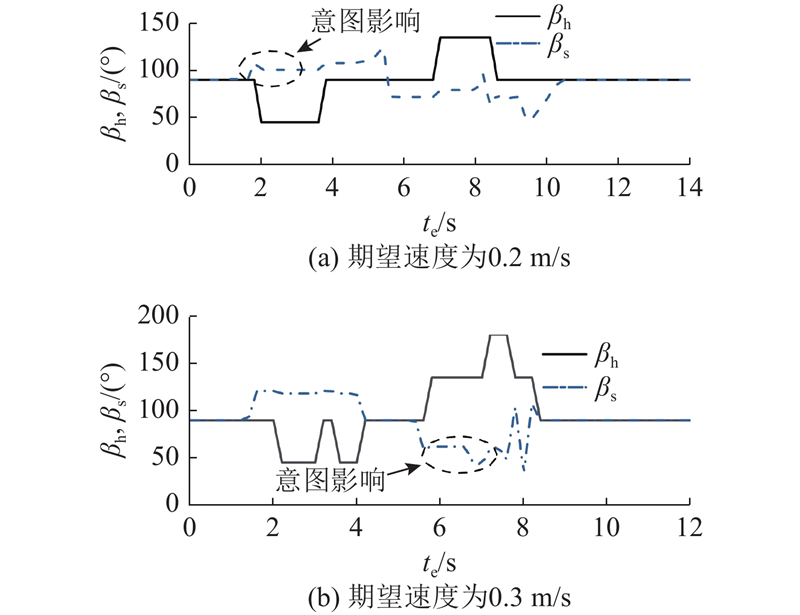
图 11 指令方向、实际行驶方向和操作权重的相关数据变化
Fig.11 Correlated data changes in command direction, actual travel direction and operational weight
为了对所提共享控制方法的有效性进行定量分析,将实验中机器人的最小转向角βmin、最小避障距离dmin及操作角误差的平均值Ma作为评价指标,共享控制前、后的定量对比结果如表4所示. 表中,Ma定义为将机器人实际行驶方向与前向方向90°之差的绝对值的平均值.
表 4 共享控制前、后的对比结果
Tab.4
| 期望速度/ (m·s−1) | 避障类型 | Ma/ (°) | βmin/ (°) | dmin/cm |
| 0.2 | 自动避障 | 23.7 | 45 | 32 |
| 0.2 | 共享避障 | 10.4 | 72 | 26 |
| 0.3 | 自动避障 | 27.2 | 14.4 | 47 |
| 0.3 | 共享避障 | 13.6 | 43.5 | 35 |
式中:l为采样序号,n为总采样次数,βs(l)为第l次采样时的机器人行驶方向.
如表4所示相较于自动避障,所提的共享控制算法在期望速度为0.2 m/s时,Ma减小了13.3°,βmin增加了27°,dmin减小了6 cm;当期望速度为0.3 m/s时,Ma减小了13.6°,βmin增加了29.1°,dmin减小了12 cm. 该算法考虑用户偏向障碍物的操作意图,减小了转弯半径,缩短了最小避障距离. 相较于0.2 m/s的情况,期望速度为0.3 m/s时的Ma和dmin更大,βmin更小. 随着速度的增大,共享控制器会减小用户控制权重,增大转弯半径,提高安全性,这验证了所提控制算法的有效性.
3.2.2. 考虑个体操作习惯的人-轮椅状态融合式共享智能避障实验
测试包括2种不同的实验环境,如图12、13所示. 依靠经验可以大致确定共享控制权重参数的调整范围,设置离散动作集A={−0.2, −0.1, 0, 0.1, 0.2}. 学习率α = 0.05,折扣因子γ = 0.9,温度系数m = 0.4,机器人每0.2 s记录一次数据. 招募4名测试人员,每个人至少完整地进行一次预实验,记录共享控制参数调整的在线训练过程. 一次避障实验即为一次完整的强化学习训练,直到模糊强化学习收敛至最优策略,此时考虑个体操作习惯的在线训练过程结束. 在避障过程中,测试人员根据个人的操作习惯,通过自己的操作指令调整避障转角,补偿WR的行驶状态. 为了便于观察WR行驶状态的变化,在相同的障碍物环境和初始位置下,以0.2 m/s和0.3 m/s的期望速度进行避障行驶,记录实际行驶的方向角度和共享控制权重的在线学习过程. 如图12所示为期望速度为0.2 m/s条件下的实验环境,如图14所示为第1次和第15次实验中测试人员a的指令方向与机器人行驶方向的比较. 如图15所示为避障过程中机器人实际方向和操作权重的在线学习过程. 如图13所示为期望速度为0.3 m/s条件下的实验环境,如图16所示为第1次和第15次实验中测试人员a的指令方向与机器人行驶方向的比较. 如图17所示为避障过程中机器人实际方向和操作权重的在线学习过程. 从实验结果可以看出,经过15次试验的学习过程,共享控制权重参数逐渐稳定,机器人的实际行驶方向变得相对稳定. 可知,当面对相同的障碍物情况时,机器人具有更大的避障转向角度,使得测试人员在避障行驶过程中感受到更大的安全距离,获得满意的行驶状态. 将测试人员指令方向与机器人行驶方向差的绝对值的平均值作为评估指标:
图 12

图 13

图 14
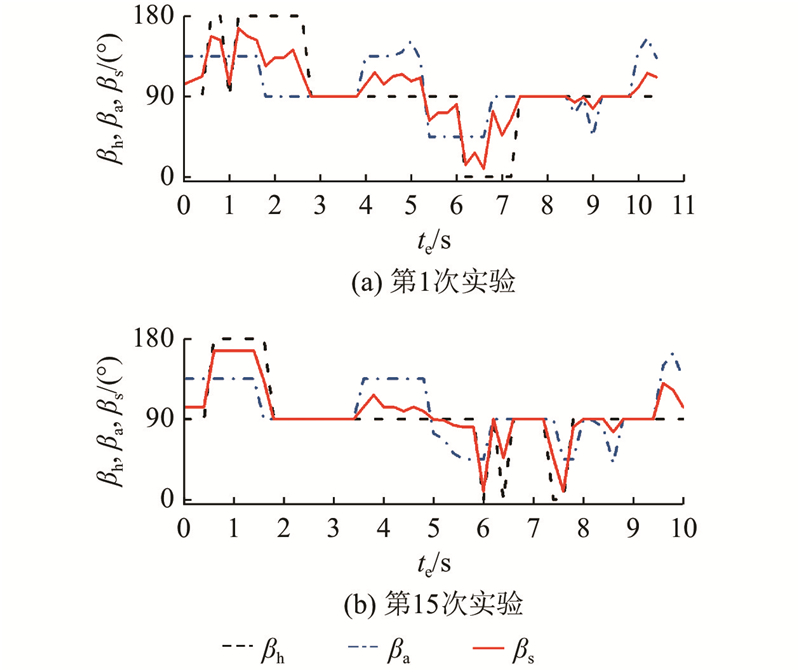
图 14 实验环境1机器人行驶方向的比较
Fig.14 Comparison of robot travel directions in experimental environment 1
图 15
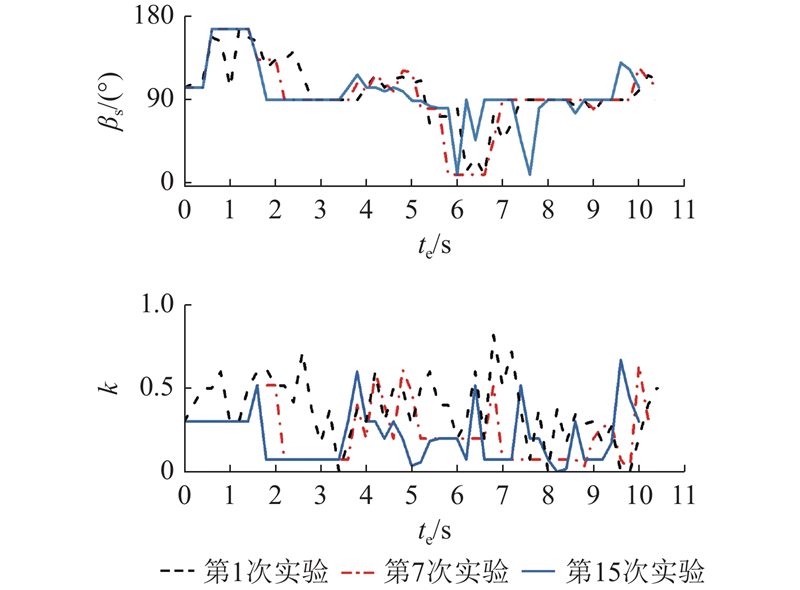
图 15 实验环境1相关数据的在线训练过程
Fig.15 Online training process of relevant data in experimental enviroment 1
图 16
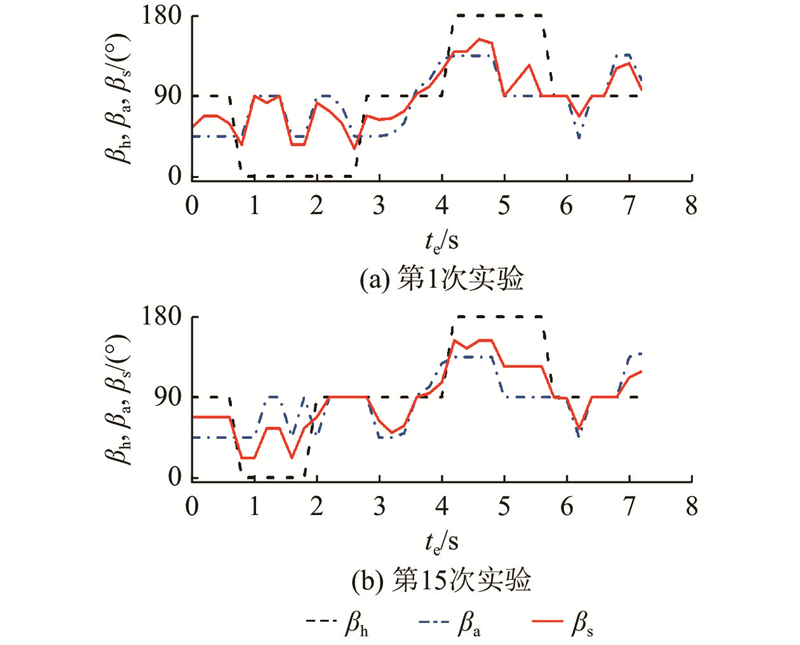
图 16 实验环境2机器人行驶方向的比较
Fig.16 Comparison of robot travel directions in experimental enviroment 2
图 17
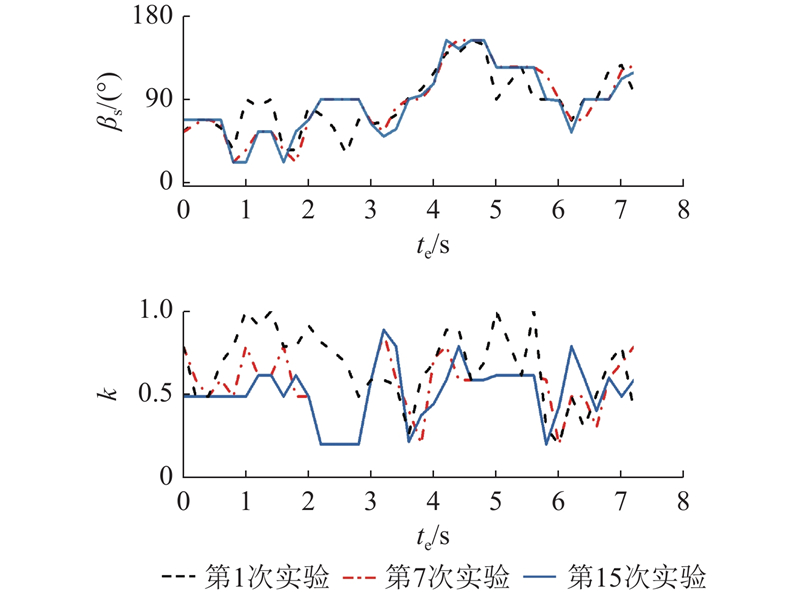
图 17 实验环境2相关数据的在线训练过程
Fig.17 Online training process of relevant data in experimental enviroment 2
图 18
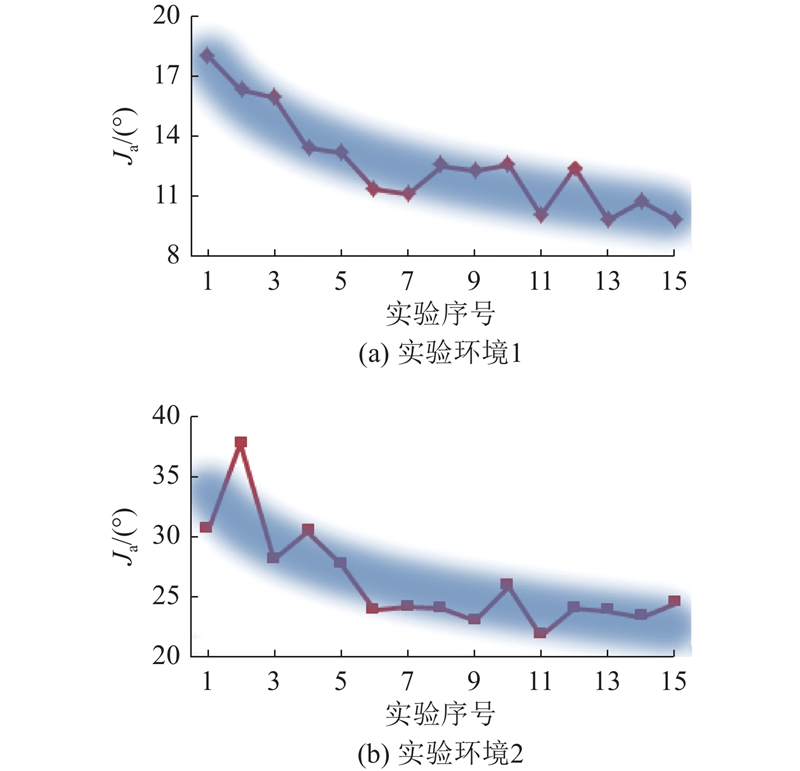
图 18 不同实验环境下同一实验对象评估指标的变化趋势
Fig.18 Changing trend of evaluation indicator of same subject in different experimental environment
图 19
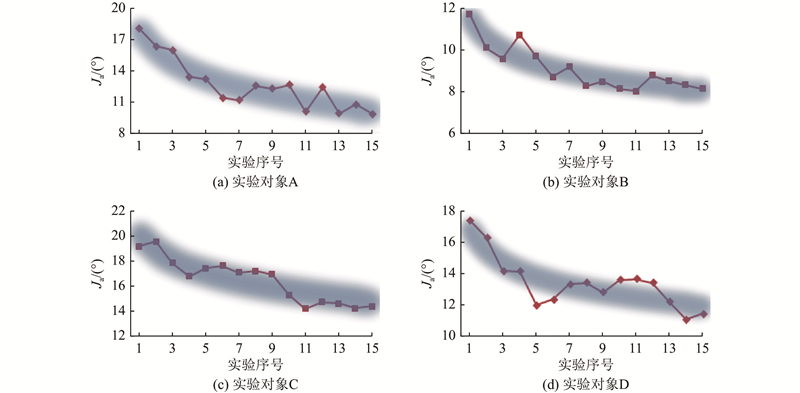
图 19 实验场景1下不同实验对象评估指标的变化趋势
Fig.19 Changing trend in evaluation criteria of different experimental subject in experimental scenario 1
在采用配对T检测来评估15次实验后,测试|βh−βs|的变化是否具有统计学显著性. 结果如表5所示. 配对T检验的零假设认为,在首次实验和最后一次实验之间,测试人员指令方向与机器人行驶方向差的绝对值的差异均值为零. 分析结果表明,在15次实验后,测试人员指令方向与机器人行驶方向差的绝对值发生了显著变化(P < 0.05),验证了提出的共享控制算法的有效性.
表 5 |βh−βs|的配对T检测结果
Tab.5
| 实验对象 | T | P |
| A | 2.28 | |
| B | 3.80 | |
| C | 3.26 | |
| D | 4.07 |
4. 结 语
本文提出基于个体操作习惯的轮椅共享智能避障方法,通过模糊推理和模糊强化学习,有效识别用户意图并优化避障控制,显著提高了用户的舒适度和安全性. 经过15次的在线训练,4位测试对象的操作偏差指标分别降低了8.2°、3.6°、3.9°和5.3°. 利用该算法,能够获取用户的操作习惯特征并自动适应用户的行为,从而提高用户的舒适度. 所提算法面向不同机型,只须更新数据库即可适用. 未来研究将重点提升算法在不同机型、个体和环境中的泛化能力,通过引入其他传感器,提高识别的准确性.
参考文献
Fuzzy logic control of a head-movement based semi-autonomous human–machine interface
[J].DOI:10.1007/s42235-022-00272-3 [本文引用: 1]
Wheelchair control for disabled patients using EMG/EOG based human machine interface: a review
[J].DOI:10.1080/03091902.2020.1853838 [本文引用: 1]
基于稳态视觉诱发电位的智能轮椅半自主导航控制
[J].
Semi-autonomous navigation control of intelligent wheelchair based on steady state visual evoked potential
[J].
A flexible bio-signal based HMI for hands-free control of an electric powered wheelchair
[J].DOI:10.4018/ijalr.2014010105 [本文引用: 1]
Design and development of an assistive system based on eye tracking
[J].DOI:10.3390/electronics11040535 [本文引用: 1]
Control of speed and direction of electric wheelchair using seat pressure mapping
[J].DOI:10.1016/j.bbe.2018.04.007 [本文引用: 1]
Road area detection method based on DBNN for robot navigation using single camera in outdoor environments
[J].DOI:10.1108/IR-08-2017-0139 [本文引用: 1]
An optimized path tracking approach considering obstacle avoidance and comfort
[J].DOI:10.1007/s10846-022-01636-x [本文引用: 1]
基于临场感的遥操作机器人共享控制研究综述
[J].
Telerobotic shared control strategy based on telepresence: a review
[J].
Self-adaptive shared control with brain state evaluation network for human-wheelchair cooperation
[J].DOI:10.1088/1741-2552/ab937e [本文引用: 1]
Shared control design methodologies of an electric wheelchair for individuals with severe disabilities using reinforcement learning
[J].DOI:10.15748/jasse.7.300 [本文引用: 1]
A new directional-intent recognition method for walking training using an omnidirectional robot
[J].DOI:10.1007/s10846-017-0503-z [本文引用: 1]
Linear time distances between fuzzy sets with applications to pattern matching and classification
[J].
Intelligent obstacle avoidance wheelchair based on fuzzy reasoning
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}