|
|
|
| Based on improved Transformer for super-resolution reconstruction of lung CT images |
Jie LIU1( ),You WU1,Jiahe TIAN2,Ke HAN3 ),You WU1,Jiahe TIAN2,Ke HAN3 |
1. School of Measurement-Control Technology and Communications Engineering, Harbin University of Science and Technology, Harbin 150080, China
2. Rongcheng Campus, Harbin University of Science and Technology, Weihai 264300, China
3. School of Computer and Information Engineering, Harbin University of Commerce, Harbin 150028, China |
|
|
|
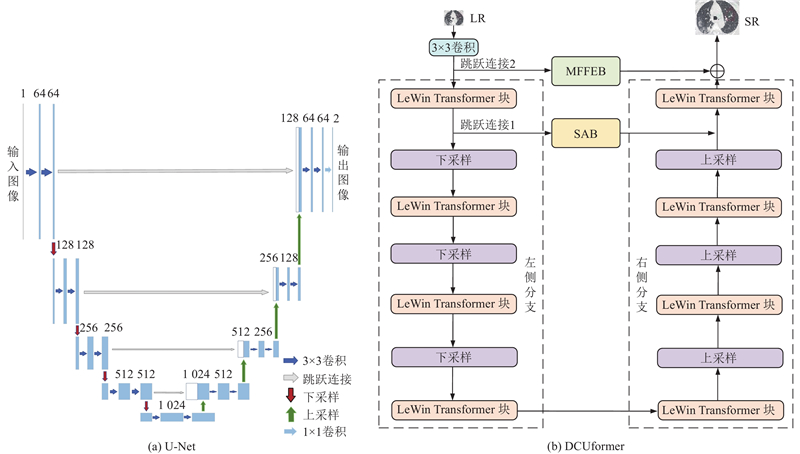
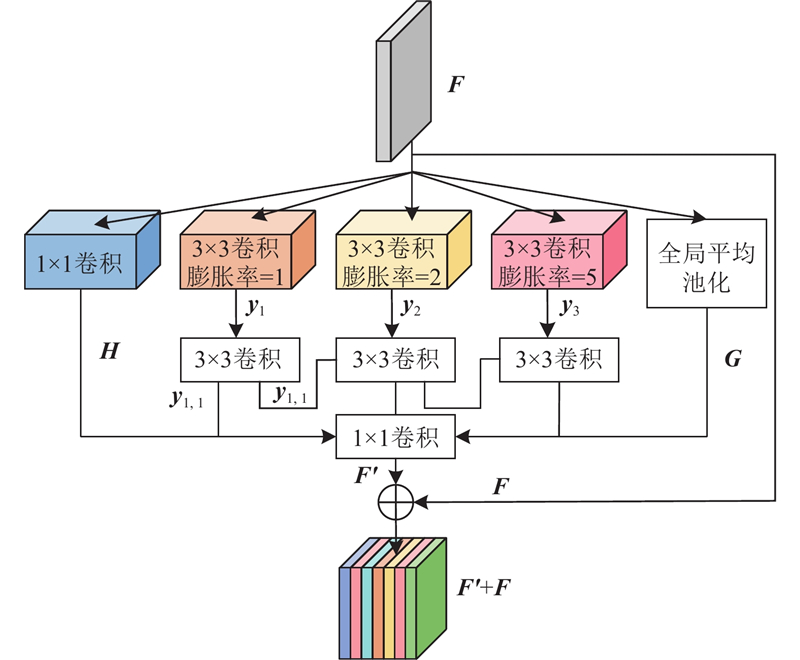
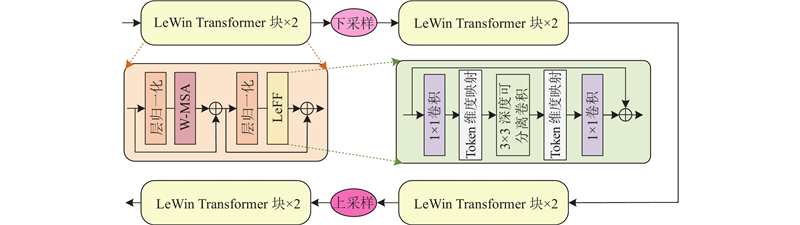
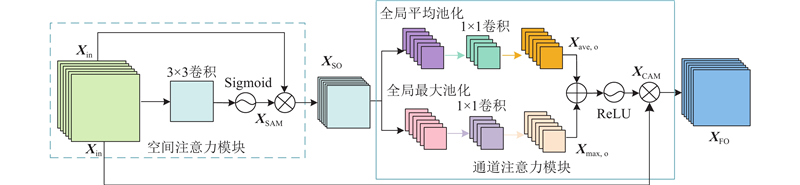
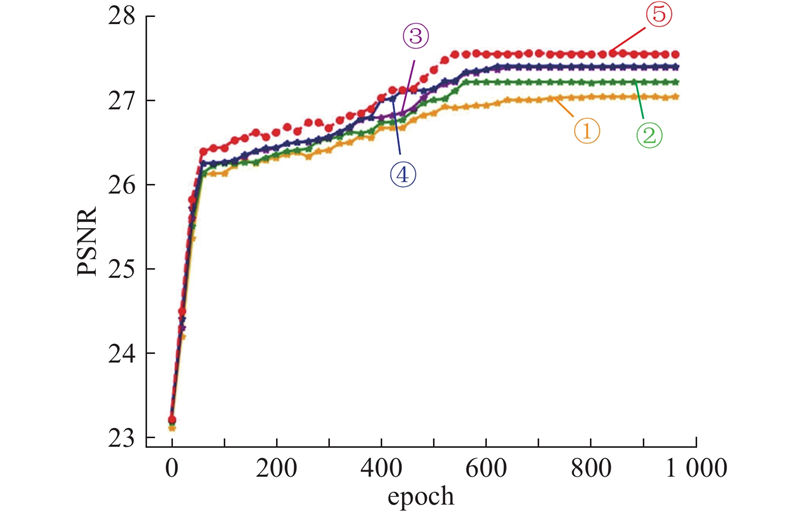
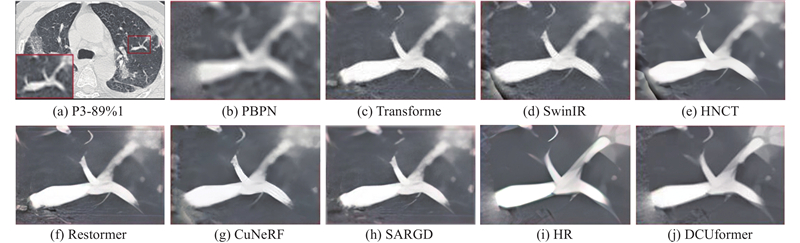
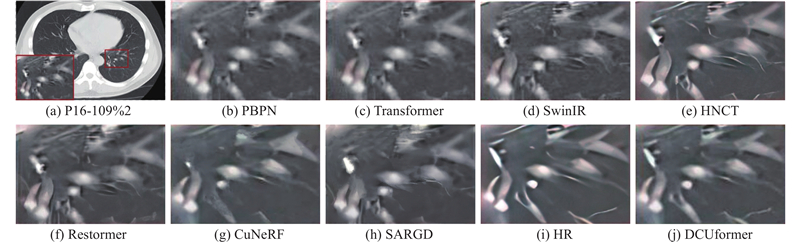
Abstract A super-resolution reconstruction network for lung CT images based on a locally enhanced Transformer and U-Net was proposed for the rich grey scale of the lung CT images leading to insufficient feature extraction and poor reconstruction details. The dilated convolution was used for deep feature extraction in multiple receptive fields, the global image information was obtained under the dilated convolution layers with different dilation rates, and the feature information under these different receptive fields was fused. The original features were obtained through the 3×3 convolutional layers, which were sent to the coding and decoding structure combining the proposed network, and the local enhancement window module reduced the computation and captured the local information. In the decoding stage, a skip connection was utilized, along with a segmentation attention block that fused spatial and channel attention to discard irrelevant information and utilize useful information, in order to obtain high-quality reconstructed images. Experimental results showed that, on the SARS-CoV-2 dataset, compared with the Transformer network, the proposed network improved the structural similarity index measure and the peak signal-to-noise ratio for 4-fold super-resolution by 0.029 and 0.186 dB, respectively.
|
|
Received: 02 September 2024
Published: 25 July 2025
|
|
|
| Fund: 黑龙江省自然科学基金资助项目(LH2023E086);黑龙江省交通运输厅科技项目(HJK2024B002). |
改进Transformer的肺部CT图像超分辨率重建
肺部CT图像灰度级别丰富,导致特征提取不充分、重建细节较差,为此提出基于局部增强Transformer和U-Net的肺部CT图像超分辨率重建网络. 采用空洞卷积进行多感受野的深层特征提取,在不同膨胀率的空洞卷积层下获得全局图像信息,进行不同感受野下的特征信息融合. 将通过3×3卷积层获得的原始特征送入结合所提网络的编解码结构中,在局部增强窗口模块的作用下减小计算量并捕获局部信息. 在解码阶段,为了提高重建图像的质量,使用跳跃连接并加入融合空间注意力和通道注意力的分割注意模块,进行无用信息丢弃和有用信息利用. 实验结果表明,在SARS-CoV-2数据集中,所提网络与Transformer网络相比,4倍超分辨率的结构相似性和峰值信噪比分别提高了0.029和0.186 dB.
关键词:
肺部CT图像,
超分辨率重建,
Transformer,
空洞卷积,
分割注意力
|
|
| [1] |
范金河. 基于深度学习的超分辨率CT图像重建算法研究[D]. 绵阳: 西南科技大学, 2023: 1–66.
FAN Jinhe. Research on super-resolution CT image reconstruction algorithm based on deep learning [D]. Mianyang: Southwest University of Science and Technology, 2023: 1–66.
|
|
|
| [2] |
赵小强, 王泽, 宋昭漾, 等 基于动态注意力网络的图像超分辨率重建[J]. 浙江大学学报: 工学版, 2023, 57 (8): 1487- 1494
ZHAO Xiaoqiang, WANG Ze, SONG Zhaoyang, et al Image super-resolution reconstruction based on dynamic attention network[J]. Journal of Zhejiang University: Engineering Science, 2023, 57 (8): 1487- 1494
|
|
|
| [3] |
郑跃坤, 葛明锋, 常智敏, 等 基于残差网络的结直肠内窥镜图像超分辨率重建方法[J]. 中国光学(中英文), 2023, 16 (5): 1022- 1033
ZHENG Yuekun, GE Mingfeng, CHANG Zhimin, et al Super-resolution reconstruction for colorectal endoscopic images based on a residual network[J]. Chinese Optics, 2023, 16 (5): 1022- 1033
doi: 10.37188/CO.2022-0247
|
|
|
| [4] |
李嫣, 任文琦, 张长青, 等 基于真实退化估计与高频引导的内窥镜图像超分辨率重建[J]. 自动化学报, 2024, 50 (2): 334- 347
LI Yan, REN Wenqi, ZHANG Changqing, et al Super-resolution of endoscopic images based on real degradation estimation and high-frequency guidance[J]. Acta Automatica Sinica, 2024, 50 (2): 334- 347
|
|
|
| [5] |
宋全博, 李扬科, 范业莹, 等 先验GAN的CBCT牙齿图像超分辨率方法[J]. 计算机辅助设计与图形学学报, 2023, 35 (11): 1751- 1759
SONG Quanbo, LI Yangke, FAN Yeying, et al CBCT tooth images super-resolution method based on GAN prior[J]. Journal of Computer-Aided Design and Computer Graphics, 2023, 35 (11): 1751- 1759
|
|
|
| [6] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Conference on Neural Information Processing Systems. Long Beach: MIT Press, 2017: 6000–6010.
|
|
|
| [7] |
LIANG J, CAO J, SUN G, et al. SwinIR: image restoration using swin transformer [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops. Montreal: IEEE, 2021: 1833–1844.
|
|
|
| [8] |
吕鑫栋, 李娇, 邓真楠, 等 基于改进Transformer的结构化图像超分辨网络[J]. 浙江大学学报: 工学版, 2023, 57 (5): 865- 874
LV Xindong, LI Jiao, DENG Zhennan, et al Structured image super-resolution network based on improved Transformer[J]. Journal of Zhejiang University: Engineering Science, 2023, 57 (5): 865- 874
|
|
|
| [9] |
YU P, ZHANG H, KANG H, et al. RPLHR-CT dataset and transformer baseline for volumetric super-resolution from CT scans [C]// Medical Image Computing and Computer Assisted Intervention. [S. l.]: Springer, 2022: 344–353.
|
|
|
| [10] |
赵凯光. 基于深度学习的肺部CT图像超分辨率重建[D]. 长春: 长春理工大学, 2022: 1–55.
ZHAO Kaiguang. Deep learning based on super-resolution reconstruction of lung CT images [D]. Changchun: Changchun University of Science and Technology, 2022: 1–55.
|
|
|
| [11] |
刘伟. 基于深度学习的三维头部MRI超分辨率重建[D]. 桂林: 桂林电子科技大学, 2022: 1–54.
LIU Wei. 3D Head MRI super-resolution reconstruction based on deep learning [D]. Guilin: Guilin University of Electronic Technology, 2023: 1–54.
|
|
|
| [12] |
李光远. 基于深度学习的磁共振成像超分辨率重建[D]. 烟台: 烟台大学, 2023: 1–77.
LI Guangyuan. Deep learning-based magnetic resonance imaging super-resolution reconstruction [D]. Yantai: Yantai University, 2023: 1–77.
|
|
|
| [13] |
李众, 王雅婧, 马巧梅 基于空洞卷积的医学图像超分辨率重建算法[J]. 计算机应用, 2023, 43 (9): 2940- 2947
LI Zhong, WANG Yajing, MA Qiaomei Super-resolution reconstruction algorithm of medical images based on dilated convolution[J]. Journal of Computer Applications, 2023, 43 (9): 2940- 2947
|
|
|
| [14] |
YANG X, HE X, ZHAO J, et al. COVID-CT-dataset: a CT scan dataset about COVID-19 [EB/OL]. (2020−06−17)[2024−07−18]. https://arxiv.org/pdf/2003.13865.
|
|
|
| [15] |
SOARES E, ANGELOV P, BIASO S, et al. SARS-CoV-2 CT-scan dataset: a large dataset of real patients CT scans for SARS-CoV-2 identification [EB/OL]. (2020−05−14)[2024−07−18]. https://www.medrxiv.org/content/10.1101/2020.04.24.20078584v3.full.pdf.
|
|
|
| [16] |
WANG C, LV X, SHAO M, et al A novel fuzzy hierarchical fusion attention convolution neural network for medical image super-resolution reconstruction[J]. Information Sciences, 2023, 622: 424- 436
doi: 10.1016/j.ins.2022.11.140
|
|
|
| [17] |
WANG Z, BOVIK A C, SHEIKH H R, et al Image quality assessment: from error visibility to structural similarity[J]. IEEE Transactions on Image Processing, 2004, 13 (4): 600- 612
doi: 10.1109/TIP.2003.819861
|
|
|
| [18] |
WANG P, CHEN P, YUAN Y, et al. Understanding convolution for semantic segmentation [C]// Proceedings of the IEEE Winter Conference on Applications of Computer Vision. Lake Tahoe: IEEE, 2018: 1451–1460.
|
|
|
| [19] |
SONG Z, ZHAO X, HUI Y, et al Progressive back-projection network for COVID-CT super-resolution[J]. Computer Methods and Programs in Biomedicine, 2021, 208: 106193
doi: 10.1016/j.cmpb.2021.106193
|
|
|
| [20] |
ZAMIR S W, ARORA A, KHAN S, et al. Restormer: efficient transformer for high-resolution image restoration [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 5718–5729.
|
|
|
| [21] |
FANG J, LIN H, CHEN X, et al. A hybrid network of CNN and transformer for lightweight image super-resolution [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. New Orleans: IEEE, 2022: 1102–1111.
|
|
|
| [22] |
CHEN Z, YANG L, LAI J H, et al. CuNeRF: cube-based neural radiance field for zero-shot medical image arbitrary-scale super resolution [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Paris: IEEE, 2023: 21128–21138.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|