|
|
|
| 3D hand pose estimation method based on monocular RGB images |
Bing YANG1,2( ),Chuyang XU1,2,Jinliang YAO1,2,Xueqin XIANG3 ),Chuyang XU1,2,Jinliang YAO1,2,Xueqin XIANG3 |
1. School of Computer Science, Hangzhou Dianzi University, Hangzhou 310018, China
2. Key Laboratory of Brain Machine Collaborative Intelligence of Zhejiang Province, Hangzhou Dianzi University, Hangzhou 310018, China
3. Hangzhou Lingban Technology Limited Company, Hangzhou 311121, China |
|
|
|
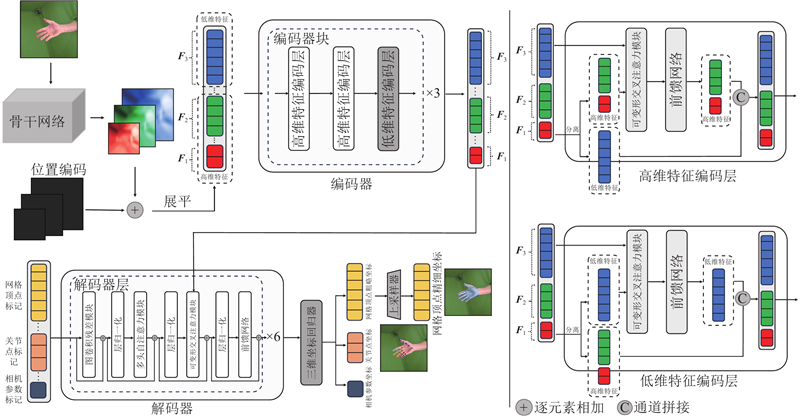
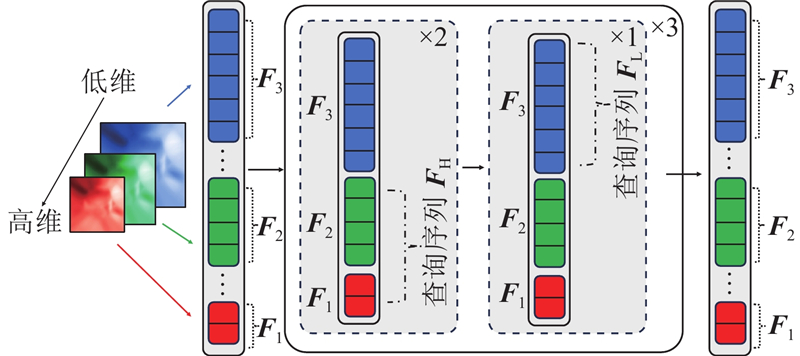
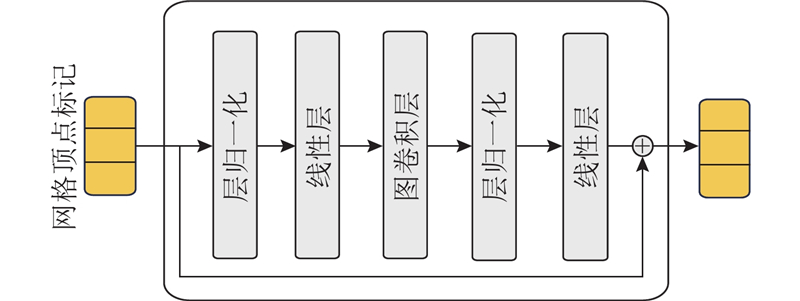
Abstract A 3D hand pose estimation method based on improved FastMETRO was proposed for most of the existing 3D hand pose estimation methods are based on Transformer technology and do not fully consider the local spatial information at high resolution. By introducing deformable attention, the design of the encoder was not limited by the length of the image feature sequence. The interleaved update multi-scale feature encoder was employed to fuse multi-scale features and enhance the generation of hand pose, and the graph convolution residual module was employed to exploit the explicit semantic connections between mesh vertices. To validate the effectiveness of the proposed method, the training and experiments were conducted in the datasets FreiHAND, HO3D V2 and HO3D V3. Results showed that the regression accuracy of the proposed method was better than existing advanced methods with Procrustes aligned - average joints error of 5.8, 10.0, and 10.5 mm in FreiHAND, HO3D V2, and HO3D V3, respectively.
|
|
Received: 22 January 2024
Published: 18 January 2025
|
|
|
| Fund: 浙江省基础公益研究计划(LGG22F020027). |
基于单目RGB图像的三维手部姿态估计方法
现有的三维手部姿态估计方法大多基于Transformer技术,未充分利用高分辨率下的局部空间信息,为此提出基于改进FastMETRO的三维手部姿态估计方法. 引入可变形注意力机制,使得编码器的设计不再受限于图像特征序列长度;引入交错更新多尺度特征编码器来融合多尺度特征,强化生成手部姿态;引入图卷积残差模块来挖掘网格顶点间的显式语义联系. 为了验证所提方法的有效性,在数据集FreiHAND、HO3D V2和HO3D V3上开展训练及评估实验. 结果表明,所提方法的回归精度优于现有先进方法,在FreiHAND、HO3D V2、HO3D V3上的普鲁克对齐-平均关节点误差分别为5.8、10.0、10.5 mm.
关键词:
三维手部姿态估计,
Transformer,
可变形注意力机制,
交错更新多尺度特征编码器,
神经网络
|
|
| [1] |
LI R, LIU Z, TAN J A survey on 3D hand pose estimation: cameras, methods, and datasets[J]. Pattern Recognition, 2019, 93: 251- 272
doi: 10.1016/j.patcog.2019.04.026
|
|
|
| [2] |
LIU Y, JIANG J, SUN J. Hand pose estimation from RGB images based on deep learning: a survey [C]// 2021 IEEE 7th International Conference on Virtual Reality . Foshan: IEEE, 2021: 82−89.
|
|
|
| [3] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems . [S.l.]: Curran Associates, 2017: 6000−6010.
|
|
|
| [4] |
LIN K, WANG L, LIU Z. End-to-end human pose and mesh reconstruction with transformers [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 1954−1963.
|
|
|
| [5] |
CHO J, KIM Y, OH T H. Cross-attention of disentangled modalities for 3D human mesh recovery with transformers [C]// European Conference on Computer Vision . [S.l.]: Springer, 2022: 342−359.
|
|
|
| [6] |
ZHENG C, WU W, CHEN C, et al Deep learning-based human pose estimation: a survey[J]. ACM Computing Surveys, 2023, 56 (1): 11
|
|
|
| [7] |
ROMERO J, TZIONAS D, BLACK M J Embodied hands: modeling and capturing hands and bodies together[J]. ACM Transactions on Graphics, 2017, 36 (6): 245
|
|
|
| [8] |
ZHANG X, LI Q, MO H, et al. End-to-end hand mesh recovery from a monocular RGB image [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 2354−2364.
|
|
|
| [9] |
BAEK S, KIM K I, KIM T K. Pushing the envelope for RGB-based dense 3D hand pose estimation via neural rendering [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 1067−1076.
|
|
|
| [10] |
BOUKHAYMA A, DE BEM R, TORR P H S. 3D hand shape and pose from images in the wild [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 10835−10844.
|
|
|
| [11] |
ZIMMERMANN C, BROX T. Learning to estimate 3D hand pose from single RGB images [C]// Proceedings of the IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 4913−4921.
|
|
|
| [12] |
IQBAL U, MOLCHANOV P, BREUEL T, et al. Hand pose estimation via latent 2.5D heatmap regression [C]// Proceedings of the European Conference on Computer Vision . Munich: Springer, 2018: 125−143.
|
|
|
| [13] |
KULON D, GÜLER R A, KOKKINOS I, et al. Weakly-supervised mesh-convolutional hand reconstruction in the wild [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 4989−4999.
|
|
|
| [14] |
GE L, REN Z, LI Y, et al. 3D hand shape and pose estimation from a single RGB image [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 10825−10834.
|
|
|
| [15] |
CHEN X, LIU Y, MA C, et al. Camera-space hand mesh recovery via semantic aggregation and adaptive 2D-1D registration [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 13269−13278.
|
|
|
| [16] |
ZHU X, SU W, LU L, et al. Deformable DETR: deformable transformers for end-to-end object detection [EB/OL]. (2021−03−18)[2023−11−20]. https://arxiv.org/abs/2010.04159.
|
|
|
| [17] |
LIN K, WANG L, LIU Z. Mesh graphormer [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 12919−12928.
|
|
|
| [18] |
ZIMMERMANN C, CEYLAN D, YANG J, et al. FreiHAND: a dataset for markerless capture of hand pose and shape from single RGB images [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 813−822.
|
|
|
| [19] |
HAMPALI S, RAD M, OBERWEGER M, et al. HOnnotate: a method for 3D annotation of hand and object poses [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 3193−3203.
|
|
|
| [20] |
HAMPALI S, SARKAR S D, LEPETIT V. HO-3D_v3: improving the accuracy of hand-object annotations of the HO-3D dataset [EB/OL]. (2021−07−02)[2024−03−17]. https://arxiv.org/abs/2107.00887.
|
|
|
| [21] |
GOWER J C Generalized procrustes analysis[J]. Psychometrika, 1975, 40: 33- 51
doi: 10.1007/BF02291478
|
|
|
| [22] |
LIM G M, JATESIKTAT P, ANG W T. Mobilehand: real-time 3D hand shape and pose estimation from color image [C]// International Conference on Neural Information Processing . [S.l.]: Springer, 2020: 450−459.
|
|
|
| [23] |
CHOI H, MOON G, LEE K M. Pose2Mesh: graph convolutional network for 3D human pose and mesh recovery from a 2D human pose [C]// European Conference on Computer Vision . [S.l.]: Springer, 2020: 769−787.
|
|
|
| [24] |
MOON G, LEE K M. I2l-MeshNet: image-to-lixel prediction network for accurate 3D human pose and mesh estimation from a single RGB image [C]// European Conference on Computer Vision . [S.l.]: Springer, 2020: 752−768.
|
|
|
| [25] |
CHEN P, CHEN Y, YANG D, et al. I2UV-HandNet: image-to-UV prediction network for accurate and high-fidelity 3D hand mesh modeling [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 12909−12918.
|
|
|
| [26] |
SEEBER M, PORANNE R, POLLEYFEYS M, et al. Realistichands: a hybrid model for 3D hand reconstruction [C]// 2021 International Conference on 3D Vision . London: IEEE, 2021: 22−31.
|
|
|
| [27] |
YU T, BIDULKA L, MCKEOWN M J, et al PA-Tran: learning to estimate 3D hand pose with partial annotation[J]. Sensors, 2023, 23 (3): 1555
doi: 10.3390/s23031555
|
|
|
| [28] |
VASU P K A, GABRIEL J, ZHU J, et al. FastViT: a fast hybrid vision Transformer using structural reparameterization [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Paris: IEEE, 2023: 5762−5772.
|
|
|
| [29] |
YANG L, LI K, ZHAN X, et al. ArtiBoost: boosting articulated 3D hand-object pose estimation via online exploration and synthesis [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 2740−2750.
|
|
|
| [30] |
HAMPALI S, SARKAR S D, RAD M, et al. Keypoint Transformer: solving joint identification in challenging hands and object interactions for accurate 3D pose estimation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 11080−11090.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|