|
|
|
| Policy gradient algorithm and its convergence analysis for two-player zero-sum Markov games |
Zhuo WANG,Yongqiang LI*( ),Yu FENG,Yuanjing FENG ),Yu FENG,Yuanjing FENG |
| 1. School of Information Engineering, Zhejiang University of Technology, Hangzhou 310000, China |
|
|
|
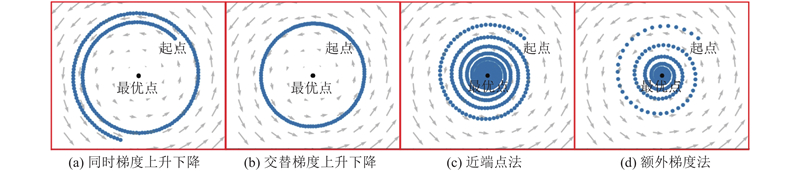
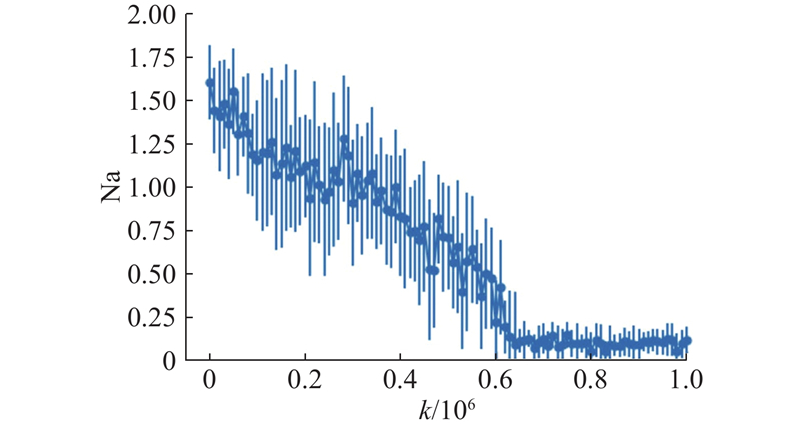
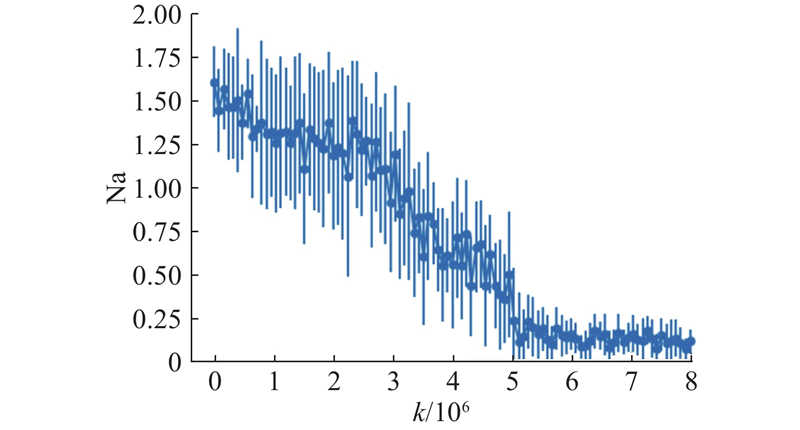
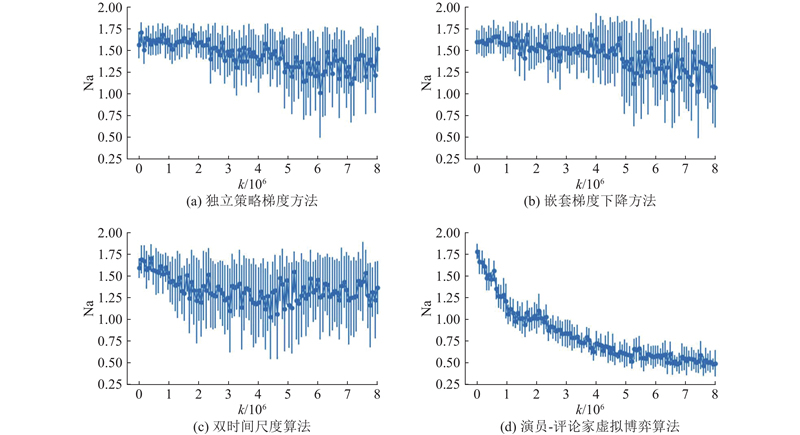
Abstract An approximate Nash equilibrium policy optimization algorithm that simultaneously updated the policy of both players was proposed, in order to resolve the problem of low learning efficiency of the policy-based reinforcement learning method in the two-player zero-sum Markov game. The two-player zero-sum Markov game problem was described as a maximum-minimum optimization problem. The policy gradient theorem of the Markov game was given for the parameterized policy, and it provided a feasibility basis for algorithm implementation through the derivation of the approximate stochastic policy gradient. Different gradient update methods for the maximum-minimum problem were compared and analyzed, and it was found that the extragradient had better convergence performance than other methods. An approximate Nash equilibrium policy optimization algorithm based on the extragradient was proposed based on this finding, and the convergence proof of the algorithm was given. The tabular softmax parameterized policy and the neural network were used as parameterized policy on the Oshi-Zumo game, to verify the effectiveness of the algorithm in different game scale scenarios. The convergence and superiority of the algorithm compared to other methods were verified through comparative experiments.
|
|
Received: 13 April 2023
Published: 05 March 2024
|
|
|
| Fund: 国家自然科学基金资助项目(62073294);浙江省自然科学基金资助项目(LZ21F030003). |
|
Corresponding Authors:
Yongqiang LI
E-mail: yqli@zjut.edu.cn
|
两方零和马尔科夫博弈策略梯度算法及收敛性分析
为了解决基于策略的强化学习方法在两方零和马尔科夫博弈中学习效率低下的问题, 提出同时更新双方玩家策略的近似纳什均衡策略优化算法. 将两方零和马尔科夫博弈问题描述为最大最小优化问题, 针对参数化策略, 给出马尔科夫博弈的策略梯度定理, 并通过近似随机策略梯度的推导, 为算法实施提供可行性基础. 通过比较分析不同的最大最小问题梯度更新方法, 发现额外梯度相较于其他方法具有更好的收敛性能. 基于这一发现, 提出基于额外梯度的近似纳什均衡策略优化算法, 并给出算法的收敛性证明. 在Oshi-Zumo游戏上, 使用表格式softmax参数化策略以及神经网络作为参数化策略, 验证不同游戏规模场景下算法的有效性. 通过对比实验, 验证算法相对于其他方法的收敛性和优越性.
关键词:
两方零和马尔科夫博弈,
强化学习,
策略优化,
额外梯度,
纳什均衡,
神经网络
|
|
| [1] |
SILVER D, HUANG A, MADDISON C J, et al Mastering the game of Go with deep neural networks and tree search[J]. Nature, 2016, 529 (7587): 484- 489
doi: 10.1038/nature16961
|
|
|
| [2] |
BROWN N, SANDHOLM T Superhuman AI for multiplayer poker[J]. Science, 2019, 365 (6456): 885- 890
doi: 10.1126/science.aay2400
|
|
|
| [3] |
OWEN G. Game theory [M]. Bradford: Emerald Group Publishing, 2013.
|
|
|
| [4] |
吴哲, 李凯, 徐航, 等 一种用于两人零和博弈对手适应的元策略演化学习算法[J]. 自动化学报, 2022, 48 (10): 2462- 2473
WU Zhe, LI Kai, XU Hang, et al A meta-evolutionary learning algorithm for opponent adaptation in two-player zero-sum games[J]. Acta Automatica Sinica, 2022, 48 (10): 2462- 2473
|
|
|
| [5] |
LITTMAN M L. Markov games as a framework for multi-agent reinforcement learning [C]// Proceedings of the 11th International Conference on Machine Learning . New Brunswick: Morgan Kaufmann Publishers Inc, 1994: 157−163.
|
|
|
| [6] |
WATKINS C J, DAYAN P Q-learning[J]. Machine Learning, 1992, 8 (1): 279- 292
|
|
|
| [7] |
FAN J, WANG Z, XIE Y, et al. A theoretical analysis of deep Q-learning [C]// Proceedings of the 2nd Learning for Dynamics and Control . Zürich: PMLR, 2020: 486−489.
|
|
|
| [8] |
JIA Z, YANG L F, WANG M. Feature-based q-learning for two-player stochastic games [EB/OL]. (2019−01−02) [2023−12−20]. https://arxiv.org/abs/1906.00423.pdf.
|
|
|
| [9] |
SIDFORD A, WANG M, YANG L, et al. Solving discounted stochastic two-player games with near-optimal time and sample complexity [C]// Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics . [s.l.]: PMLR, 2020: 2992−3002.
|
|
|
| [10] |
SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms [EB/OL]. (2017-08-28) [2023-12-20]. https://arxiv.org/pdf/1707.06347.pdf.
|
|
|
| [11] |
HAARNOJA T, ZHOU A, ABBEEL P, et al. Soft actor-critic: off-policy maximum entropy deep reinforcement learning with a stochastic actor [C]// Proceedings of the 35th International Conference on Machine Learning . Stockholmsmässan: PMLR, 2018: 1861-1870.
|
|
|
| [12] |
MAZUMDAR E V, JORDAN M I, SASTRY S S. On finding local nash equilibria (and only local nash equilibria) in zero-sum games [EB/OL]. (2019-01-25) [2023-12-21]. https://arxiv.org/pdf/1901.00838.pdf.
|
|
|
| [13] |
BU J, RATLIFF L J, MESBAHI M. Global convergence of policy gradient for sequential zero-sum linear quadratic dynamic games [EB/OL]. (2019-09-12) [2023-12-21]. https://arxiv.org/pdf/1911.04672.pdf.
|
|
|
| [14] |
DASKALAKIS C, FOSTER D J, GOLOWICH N. Independent policy gradient methods for competitive reinforcement learning [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems . Vancouver: Curran Associates Inc, 2020: 5527−5540.
|
|
|
| [15] |
NOUIEHED M, SANJABI M, HUANG T, et al. Solving a class of non-convex min-max games using iterative first order methods [C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems . Vancouver: Curran Associates Inc, 2019: 14905−14916.
|
|
|
| [16] |
FIEZ T, CHASNOV B, RATLIFF L J. Convergence of learning dynamics in stackelberg games [EB/OL]. (2019-09-06) [2023-12-23]. https://arxiv.org/pdf/1906.01217.pdf.
|
|
|
| [17] |
PEROLAT J, PIOT B, PIETQUIN O. Actor-critic fictitious play in simultaneous move multistage games [C]// Proceedings of the 21st International Conference on Artificial Intelligence and Statistics . Playa Blanca: PMLR, 2018: 919−928.
|
|
|
| [18] |
PETHICK T, PATRINOS P, FERCOQ O, et al. Escaping limit cycles: global convergence for constrained nonconvex-nonconcave minimax problems [C]// The 10th International Conference on Learning Representations . France: Online, 2022: 03602455.
|
|
|
| [19] |
LAGOUDAKIS M, PARR R. Value function approximation in zero-sum markov games [EB/OL]. (2012-12-12) [2023-12-23]. https://arxiv.org/pdf/1301.0580.pdf.
|
|
|
| [20] |
FUDENBERG D, DREW F, LEVINE D K, et al. The theory of learning in games [M]. Massachusetts: MIT Press, 1998.
|
|
|
| [21] |
NASH JR J F Equilibrium points in n-person games[J]. National Academy of Sciences, 1950, 36 (1): 48- 49
doi: 10.1073/pnas.36.1.48
|
|
|
| [22] |
VAMVOUDAKIS K G, WAN Y, LEWIS F L, et al. Handbook of reinforcement learning and control [M]. Berlin: Springer, 2021.
|
|
|
| [23] |
PEROLAT J, SCHERRER B, PIOT B, et al. Approximate dynamic programming for two-player zero-sum Markov games [C]// Proceedings of the 32nd International Conference on Machine Learning . Lille: PMLR, 2015: 1321-1329.
|
|
|
| [24] |
LANCTOT M, LOCKHART E, LESPIAU J-B, et al. OpenSpiel: a framework for reinforcement learning in games [EB/OL]. (2020-09-26) [2023-12-24]. https://arxiv.org/pdf/1908.09453.pdf.
|
|
|
| [25] |
PéROLAT J, PIOT B, GEIST M, et al. Softened approximate policy iteration for Markov games [C]// Proceedings of the the 33rd International Conference on Machine Learning . New York: PMLR, 2016: 1860−1868.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|