A method based on dynamic position encoding and multi-domain attention feature enhancement was proposed to fully exploit the positional information between the template and search region and harness the feature representation capabilities. Firstly, a position encoding module with convolutional operations was embedded within the attention module. Position encoding was updated with attention calculations to enhance the utilization of spatial structural information. Next, a multi-domain attention enhancement module was introduced. Sampling was conducted in the spatial dimension using parallel convolutions with different dilation rates and strides to cope with targets of different sizes and aggregate the enhanced channel attention features. Finally, a spatial domain attention enhancement module was incorporated into the decoder to provide accurate classification and regression features for the prediction head. The proposed algorithm achieved an average overlap (AO) of 73.9% on the GOT-10K dataset. It attained area under the curve (AUC) scores of 82.7%, 69.3%, and 70.9% on the TrackingNet, UAV123, and OTB100 datasets, respectively. Comparative results with state-of-the-art algorithms demonstrated that the tracking model, which integrated dynamic position encoding as well as channel and spatial attention enhancement, effectively enhanced the interaction of information between the template and search region, leading to improved tracking accuracy.
Changzhen XIONG,Chuanxi GUO,Cong WANG. Target tracking algorithm based on dynamic position encoding and attention enhancement. Journal of ZheJiang University (Engineering Science), 2024, 58(12): 2427-2437.
Fig.3Self-attention feature enhancement and cross-attention feature fusion module with dynamic positional encoding
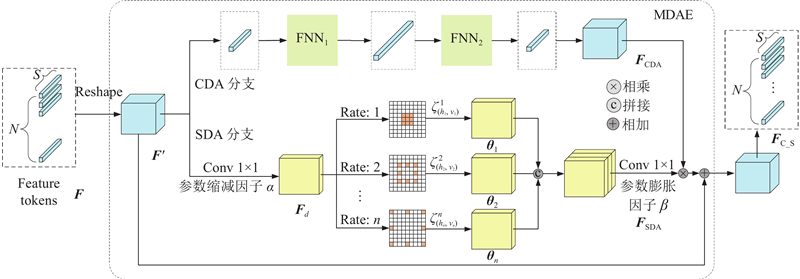
Fig.4Multi-domain attention enhancement module
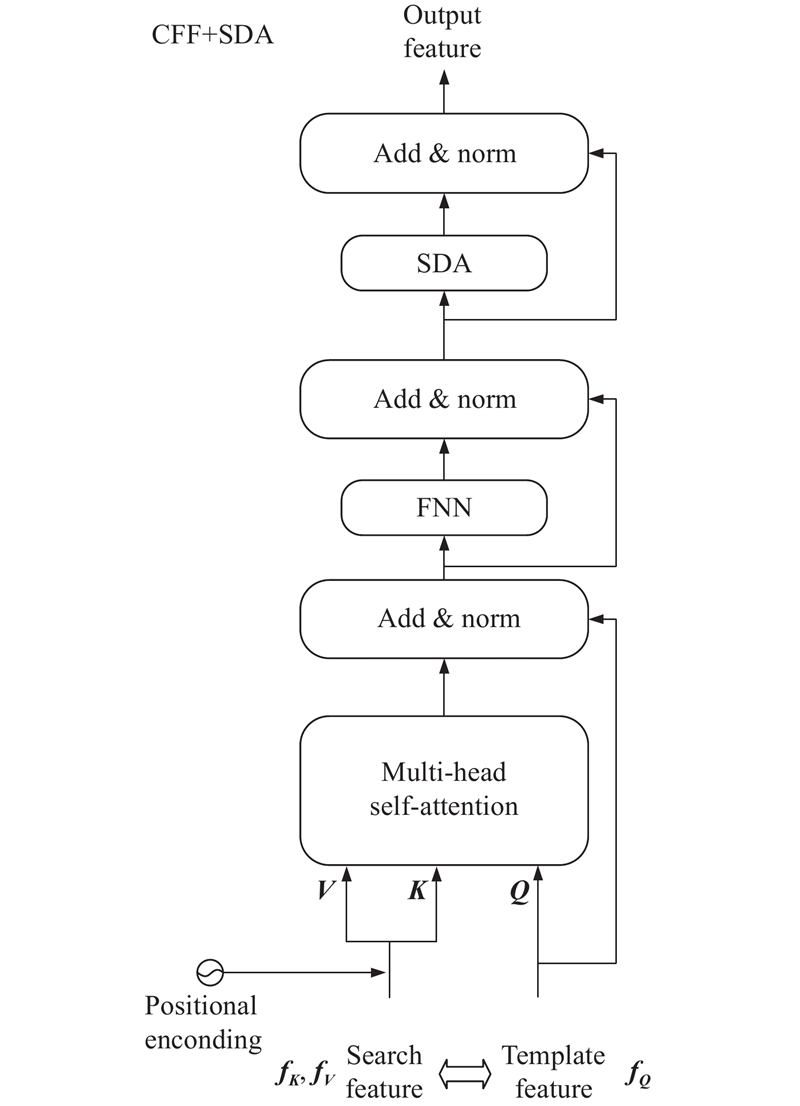
Fig.5Decoder module
Trackers
GOT-10K
TrackingNet
UAV123
AO/%
SR0.50/%
SR0.75/%
AUC/%
PNorm/%
P/%
AUC/%
P/%
SiamFC[3]
34.8
35.3
9.8
57.1
66.3
53.3
48.5
69.3
SiamPRN++[21]
51.7
61.6
32.5
73.3
80.0
69.4
64.2
84.0
ATOM[22]
55.6
63.4
40.2
70.3
77.1
64.8
64.3
—
Ocean[7]
61.1
72.1
47.3
—
—
—
62.1
82.3
DiMP[23]
61.1
71.7
49.2
74.0
80.1
68.7
65.4
85.8
KYS[24]
63.6
75.1
51.5
74.0
80.0
68.8
—
—
DTT[25]
63.4
74.9
51.4
79.6
85.0
78.9
—
—
PrDiMP[26]
63.4
73.8
54.3
75.8
81.6
70.4
66.9
87.8
TrSiam[9]
66.0
76.6
57.1
78.1
82.9
72.7
—
—
TrDimp[9]
67.1
77.7
58.3
78.4
83.3
73.1
67.5
—
KeepTrack[13]
68.3
79.3
61.0
78.1
83.5
73.8
69.7
—
STARK[27]
68.8
78.1
64.1
82.0
86.9
—
—
—
TransT[10]
72.3
82.4
68.2
81.4
86.7
80.3
69.1
—
CTT[28]
—
—
—
81.4
86.4
—
—
—
TCTrack[12]
—
—
—
—
—
—
60.4
80.0
AiATrack[11]
69.6
77.7
63.2
82.7
87.8
80.4
69.3
90.7
ToMP[14]
73.5
85.6
66.5
81.5
86.4
78.9
65.9
85.2
MixFormer[15]
73.2
83.2
70.2
82.6
87.7
81.2
68.7
89.5
本研究算法
73.9
83.3
68.6
82.7
87.7
80.8
69.3
90.5
Tab.1Comparison of different algorithms on GOT-10K, TrackingNet and UAV123
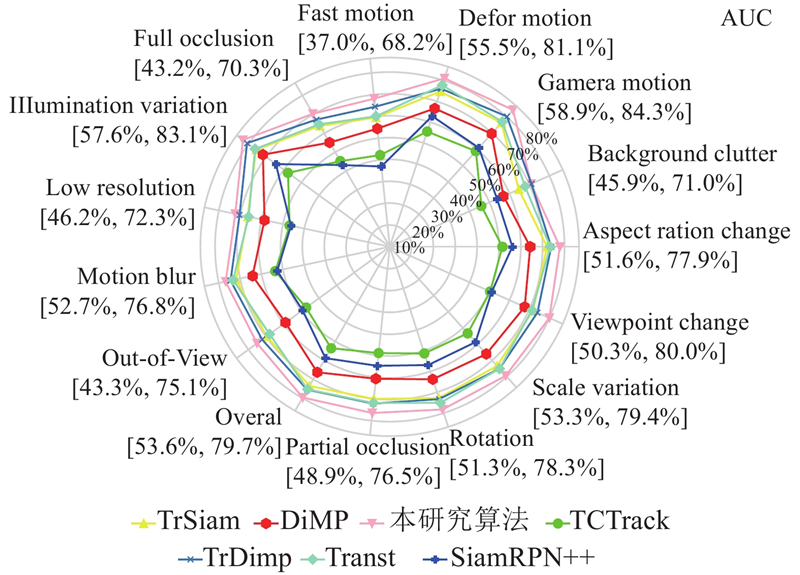
Fig.6AUC performance of different attributes on LaSOT dataset
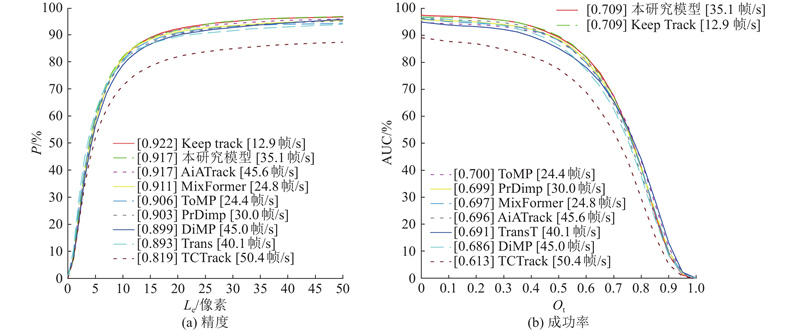
Fig.7Success rates, accuracy, and execution speeds of different algorithms on OTB100 dataset
Fig.8Performance of different algorithms in four scenarios
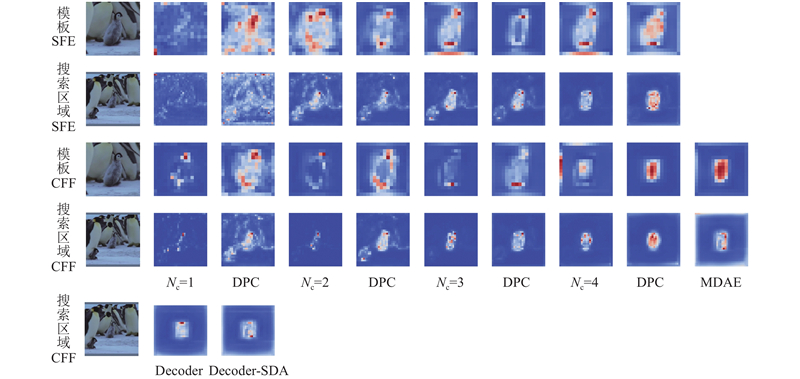
Fig.9Feature map visualization of feature fusion and feature decoding
模块
AO/%
SR0.50/%
SR0.75/%
ToMP[14]
71.9
83.1
66.7
ToMP[14]+DPE
72.5
83.4
66.8
OSTrack[29]
73.1
82.5
70.9
OSTrack[29]+DPE
73.6
82.8
70.8
Tab.2Performance of ToMP and OSTrack with DPE embedded on GOT-10K
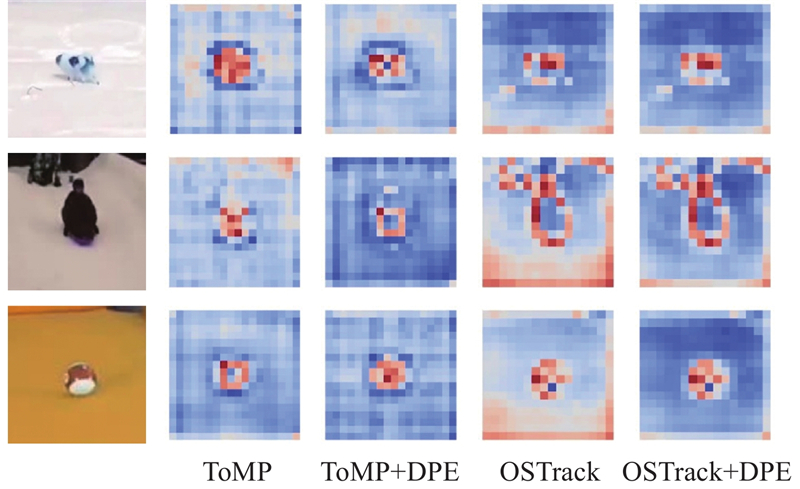
Fig.10Feature map visualization of ToMP, OSTrack with DPE embedded
Base
DPE
MDAE
Decoder
AO/%
fps/(帧·s?1)
SDA
CDA
√
—
—
—
—
71.7
40.1
√
√
—
—
—
72.8
36.7
√
√
√
—
—
73.4
35.7
√
—
√
√
—
72.6
38.6
√
√
√
√
√
73.9
34.5
√
√
√
√
—
73.9
35.1
Tab.3Results of ablation experiment on GOT-10K
[1]
韩瑞泽, 冯伟, 郭青, 等 视频单目标跟踪研究进展综述[J]. 计算机学报, 2022, 45 (9): 1877- 1907 HAN Ruize, FENG Wei, GUO Qing, et al Single object tracking research: a survey[J]. Chinese Journal of Computers, 2022, 45 (9): 1877- 1907
doi: 10.11897/SP.J.1016.2022.01877
[2]
卢湖川, 李佩霞, 王栋 目标跟踪算法综述[J]. 模式识别与人工智能, 2018, 31 (1): 61- 76 LU Huchuan, LI Peixia, WANG Dong Visual object tracking: a survey[J]. Pattern Recognition and Artificial Intelligence, 2018, 31 (1): 61- 76
[3]
BERTINETTO L, VALMADRE J, HENRIQUES J F, et al. Fully-convolutional siamese networks for object tracking [C]// 14th European Conference on Computer Vision . Amsterdam: Springer, 2016: 850–865.
[4]
陈志旺, 张忠新, 宋娟, 等 基于目标感知特征筛选的孪生网络跟踪算法[J]. 光学学报, 2020, 40 (9): 110- 126 CHEN Zhiwang, ZHANG Zhongxin, SONG Juan, et al Tracking algorithm for siamese network based on target-aware feature selection[J]. Acta Optica Sinica, 2020, 40 (9): 110- 126
[5]
陈法领, 丁庆海, 罗海波, 等 基于自适应多层卷积特征决策融合的目标跟踪[J]. 光学学报, 2020, 40 (23): 175- 187 CHEN Faling, DING Qinghai, LUO Haibo, et al Target tracking based on adaptive multilayer convolutional feature decision fusion[J]. Acta Optica Sinica, 2020, 40 (23): 175- 187
[6]
LI B, YAN J, WU W, et al. High performance visual tracking with Siamese region proposal network [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . New York: IEEE, 2018: 8971–8980.
[7]
ZHANG Z, PENG H, FU J, et al. ocean: object-aware anchor-free tracking [C]// 16th European Conference on Computer Vision . Glasgow : Springer, 2020: 771–787.
[8]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// 31st Annual Conference on Neural Information Processing Systems . Long Beach: IEEE, 2017: 5998–6010.
[9]
WANG N, ZHOU W, WANG J, et al. Transformer meets tracker: exploiting temporal context for robust visual tracking [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . [s.l.]: IEEE, 2021: 1571–1580.
[10]
CHEN X, YAN B, ZHU J, et al. Transformer tracking [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . [s.l.]: IEEE, 2021: 8126–8135.
[11]
GAO S, ZHOU C, MA C, et al. Aiatrack: attention in attention for transformer visual tracking [C]// 17th European Conference on Computer Vision . Tel Aviv: Springer, 2022: 146–164.
[12]
CAO Z, HUANG Z, PAN L, et al. TCTrack: temporal contexts for aerial tracking [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 14798–14808.
[13]
MAYER C, DANELLJAN M, PAUDEL D P, et al. Learning target candidate association to keep track of what not to track [C]// 18th IEEE/CVF International Conference on Computer Vision . [s.l.]: IEEE, 2021: 13444–1345.
[14]
MAYER C, DANELLJAN M, BHAT G, et al. Transforming model prediction for tracking [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 8731–8740.
[15]
CUI Y, JIANG C, WANG L, et al. Mixformer: end-to-end tracking with iterative mixed attention [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 13608–13618.
[16]
WU Q, YANG T, LIU Z, et al. Dropmae: masked autoencoders with spatial-attention dropout for tracking tasks [C]// 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition . New York: IEEE, 2023: 14561–14571.
[17]
CHEN X, PENG H, WANG D, et al. Seqtrack: sequence to sequence learning for visual object tracking [C]// 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition . New York: IEEE, 2023: 14572–14581.
[18]
CHU X, TIAN Z, ZHANG B, et al. Conditional positional encodings for vision transformers. (2021-02-22)[2023-10-10]. https://www.arxiv.org/abs/2102.10882v2.
[19]
WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// 15th European Conference on Computer Vision . Munich: Springer, 2018: 3–19.
[20]
WANG C, XU H, ZHANG X, et al. Convolutional embedding makes hierarchical vision transformer stronger [C]// 17th European Conference on Computer Vision . Tel Aviv: Springer, 2022: 739–756.
[21]
LI B, WU W, WANG Q, et al. Siamrpn++: evolution of siamese visual tracking with very deep networks [C]// 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 15–20.
[22]
DANELLJAN M, BHAT G, KHAN F S, et al. ATOM: accurate tracking by overlap maximization [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 4660–4669.
[23]
BHAT G, DANELLJAN M, GOOL L V, et al. Learning discriminative model prediction for tracking [C]// IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 6182–6191.
[24]
BHAT G, DANELLJAN M, VAN G L, et al. Know your surroundings: exploiting scene information for object tracking [C]// 16th European Conference on Computer Vision . Glasgow: Springer, 2020: 205–221.
[25]
YU B, TANG M, ZHENG L, et al. High-performance discriminative tracking with transformers [C]// 18th IEEE/CVF International Conference on Computer Vision . [s.l.]: IEEE, 2021: 9856–9865.
[26]
DANELLJAN M, GOOL L V, TIMOFTE R. Probabilistic regression for visual tracking [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . [s.l.]: IEEE, 2020: 7183–7192.
[27]
YAN B, PENG H, FU J, et al. Learning spatio-temporal transformer for visual tracking [C]// 18th IEEE/CVF International Conference on Computer Vision . [s.l.]: IEEE, 2021: 10448–10457.
[28]
ZHONG M, CHEN F, XU J, et al. Correlation-based transformer tracking [C]// 31st International Conference on Artificial Neural Networks . Bristol: European Neural Networks Soc, 2022: 85–96.