|
|
|
| Learning query optimization method based on multi model outside database |
Guang-long LI( ),De-rong SHEN*(),Tie-zheng NIE,Yue KOU ),De-rong SHEN*(),Tie-zheng NIE,Yue KOU |
| School of Computer Science and Engineering, Northeastern University, Shenyang 110169, China |
|
|
|
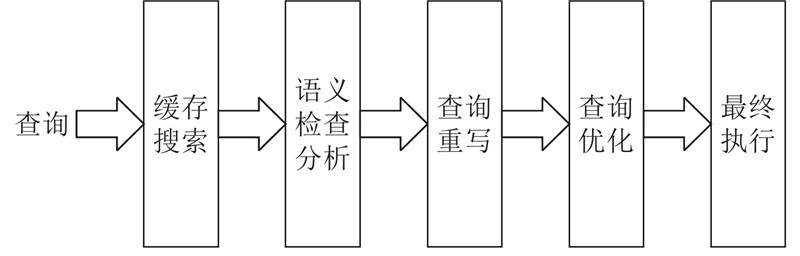
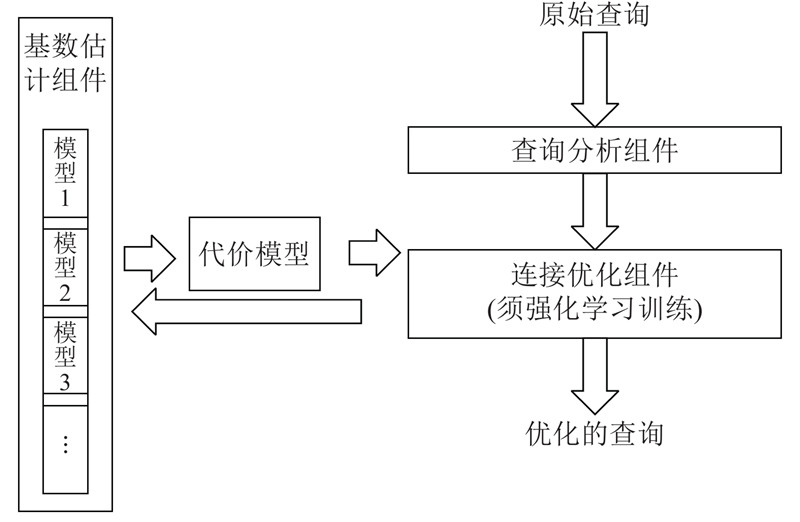
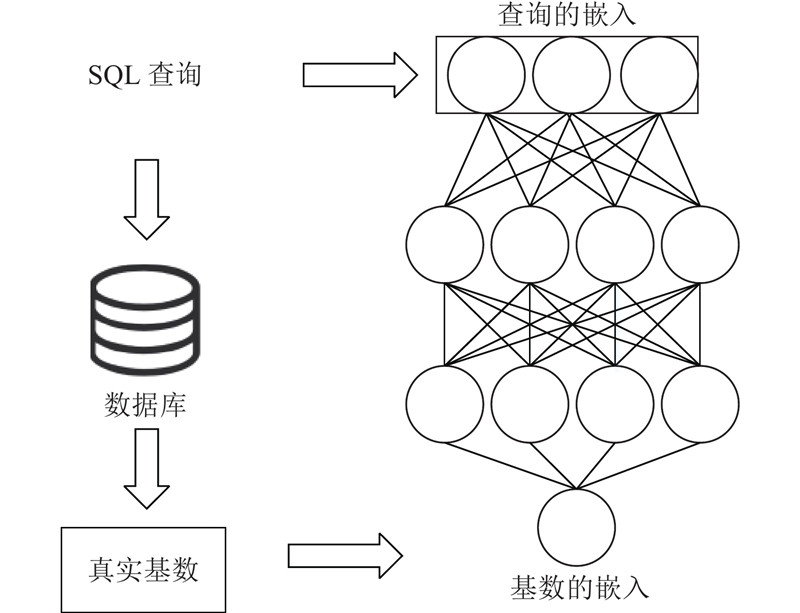
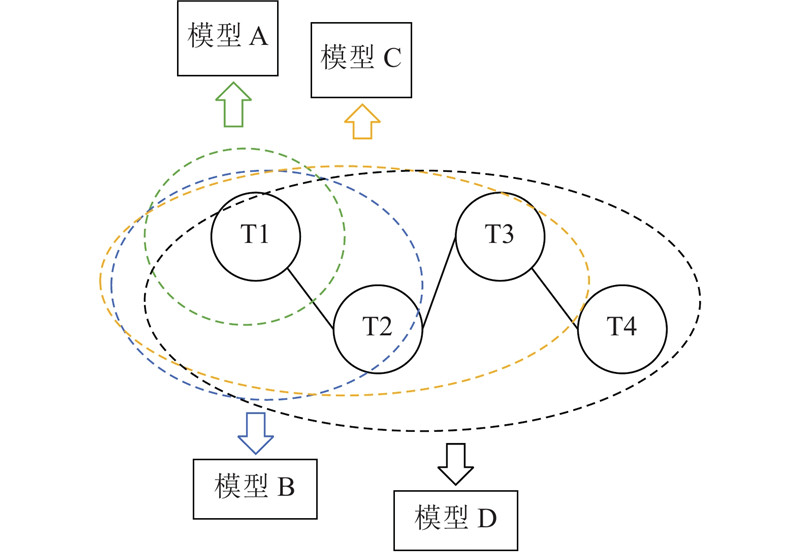
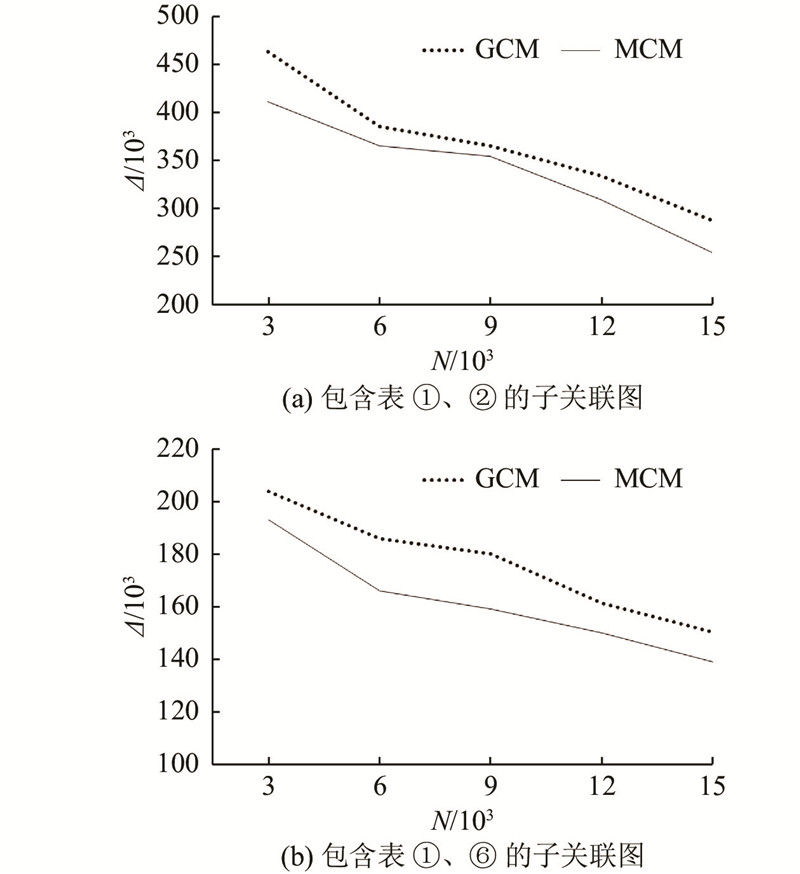
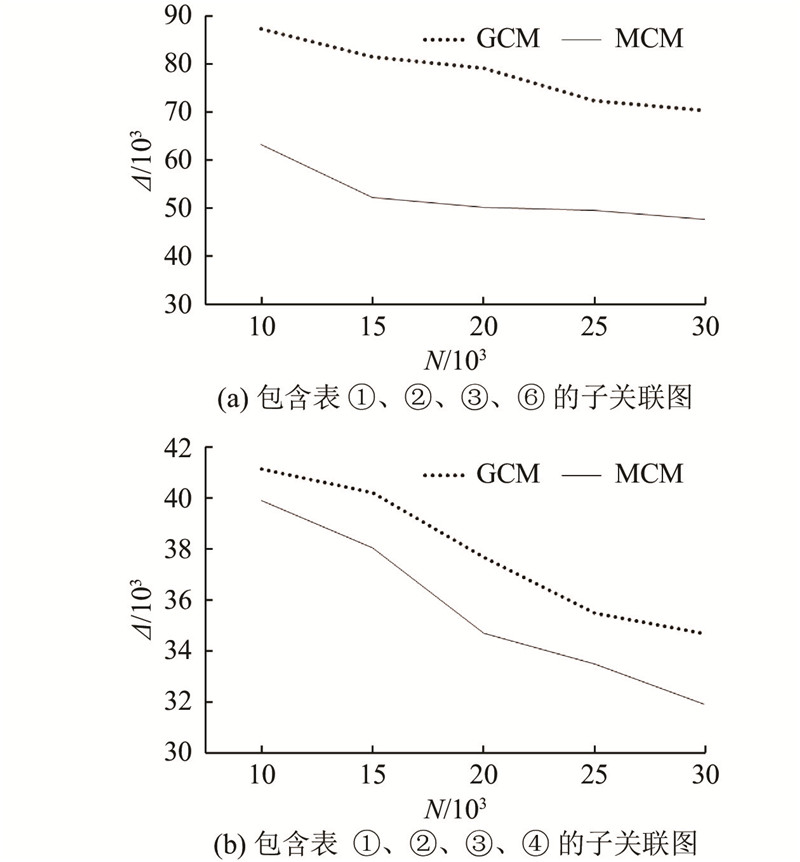
Abstract For AI and database optimization problems, existing technologies need to change the bottom layer of database, which affects the application of research results and lacks scalability. A learning query optimization method for non-embedded database was proposed. In the cardinality estimation stage, the multi-model method is used to establish a neural network for specific sub queries and train different sub models independently, which solves the problem of too many training sets and poor scalability. In the join optimization stage, cost-based reinforcement learning is applied to improve the query optimization performance. For each query, the optimization processes from cardinality estimation to connection sorting are executed outside the database. The query is rewritten according to the obtained optimization strategy, and the rewriting results are returned to the database. The query is executed according to the specified plan by setting parameters. Experimental verification was carried out on the data set containing eight tables. Compared with the query not optimized, the optimization method of non-embedded database has good optimization effect.
|
|
Received: 19 July 2021
Published: 03 March 2022
|
|
|
|
Corresponding Authors:
De-rong SHEN
E-mail: liguanglong1996@163.com;shenderong@cse.neu.edu.cn
|
数据库外基于多模型的学习式查询优化方法
对于AI与数据库优化问题,现有技术均须改动数据库底层,影响研究成果的应用且缺乏可扩展性. 提出一种非嵌入数据库的学习式查询优化方法. 在基数估计阶段,使用多模型的方法,对特定的子查询建立神经网络,独立训练不同的子模型,解决需要训练集过多且可扩展性差的问题;在连接优化阶段,应用基于代价的强化学习方法,提高查询优化性能. 针对每个查询,从基数估计到连接排序的优化过程都在数据库外执行,按照得到的优化策略对查询重写,并将重写结果返回到数据库中,通过设置参数使该查询按照指定的计划执行. 在包含8个表的数据集上进行实验验证,与未进行优化的查询进行比较,非嵌入数据库的优化方法具有良好的优化效果.
关键词:
查询优化,
基数估计,
连接排序,
神经网络,
强化学习
|
|
| [1] |
ARMSTRONG K Big data: a revolution that will transform how we live, work, and think[J]. Mathematics and Computer Education, 2014, 47 (10): 181- 183
|
|
|
| [2] |
李国良, 周煊赫, 孙佶, 等 基于机器学习的数据库技术综述[J]. 计算机学报, 2020, 43 (11): 2019- 2049
LI Guo-liang, ZHOU Xuan-he, SUN Ji, et al A survey of machine learning based database techniques[J]. Chinese Journal of Computers, 2020, 43 (11): 2019- 2049
|
|
|
| [3] |
DURAND M, FLAJOLET P. Loglog counting of large cardinalities [C]// 11th Annual European Symposium on Algorithms. Budapest: Springer, 2003.
|
|
|
| [4] |
FLAJOLET P, FUSY É, GANDOUET O, et al. Hyperloglog: the analysis of a near-optimal cardinality estimation algorithm [C]// Discrete Mathematics and Theoretical Computer Science. Nancy: [s.n.], 2007: 137-156.
|
|
|
| [5] |
WU C, JINDAL A, AMIZADEH S, et al Towards a learning optimizer for shared clouds[J]. Proceedings of the VLDB Endowment, 2018, 12 (3): 210- 222
doi: 10.14778/3291264.3291267
|
|
|
| [6] |
LAKSHMI M S , ZHOU S. Selectivity estimation in extensible databases: a neural network approach [C]// Proceedings of 24th International Conference on Very Large Data Bases. New York: DBLP, 1998.
|
|
|
| [7] |
DUTT A, WANG C, NAZI A, et al Selectivity estimation for range predicates using lightweight models[J]. Proceedings of the VLDB Endowment, 2019, 12 (9): 1044- 1057
doi: 10.14778/3329772.3329780
|
|
|
| [8] |
HASAN S, THIRUMURUGANATHAN S, AUGUSTINE J, et al. Multi-attribute selectivity estimation using deep learning [EB/OL]. (2019-06-17). https://arxiv.org/abs/1903.09999.
|
|
|
| [9] |
KIPF A, KIPF T, RADKE B, et al. Learned cardinalities: estimating correlated joins with deep learning [EB/OL]. (2018-12-08). https://arxiv.org/abs/1809.00677.
|
|
|
| [10] |
SUN, LI G An end-to-end learning-based cost estimator[J]. Proceedings of the VLDB Endowment, 2019, 13 (3): 307- 319
doi: 10.14778/3368289.3368296
|
|
|
| [11] |
SELINGER P G, ASTRAHAN M M, CHAMBERLIN D D, et al. Access path selection in a relational database management system [C]// International Conference on Management of Data (SIGMOD). Boston: ACM, 1979: 23-34.
|
|
|
| [12] |
VANCE B, MAIER D. Rapid bushy join-order optimization with cartesian products [C]// International Conference on Management of Data. Montreal: ACM, 1996:35-46.
|
|
|
| [13] |
WAAS F, PELLENKOFT A. Join order selection (good enough is easy) [C]// British National Conference on Databases: Advances in Databases. Exeter: Springer, 2000: 51-67.
|
|
|
| [14] |
NEUMANN T. Query simplification: graceful degradation for join-order optimization [C]// International Conference on Management of Data (SIGMOD). Providence: ACM, 2009: 403-414.
|
|
|
| [15] |
KRISHNAN S, YANG Z, GOLDBERG K, et al. Deep reinforcement learning for join order enumeration [EB/OL]. (2018-02-28). https://arxiv.org/abs/1808.03196.
|
|
|
| [16] |
RYAN M, OLGA P, et al. Learned cardinalities: estimating correlated joins with deep learning [EB/OL]. (2018-12-08). https://arxiv.org/abs/1803.00055.
|
|
|
| [17] |
TRUMMER I, WANG J, MARAM D, et al. Skinnerdb: regret-bounded query evaluation via reinforcement learning[EB/OL]. (2019-01-16). https://arxiv.org/abs/1901.05152.
|
|
|
| [18] |
LEIS V, GUBICHEV A, MIRCHEV A, et al How good are query optimizers, really?[J]. Proceedings of the VLDB Endowment, 2015, 9 (3): 204- 215
doi: 10.14778/2850583.2850594
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|