| 计算机技术、控制工程、通信技术 |
|

|
|
|
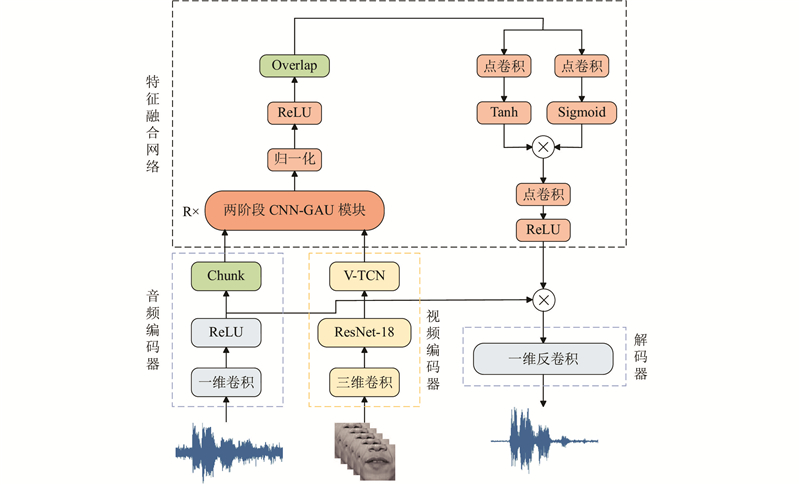
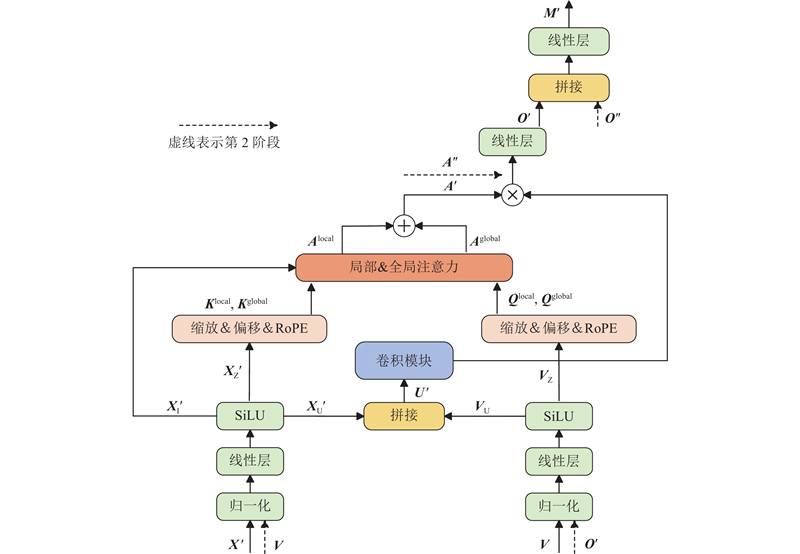
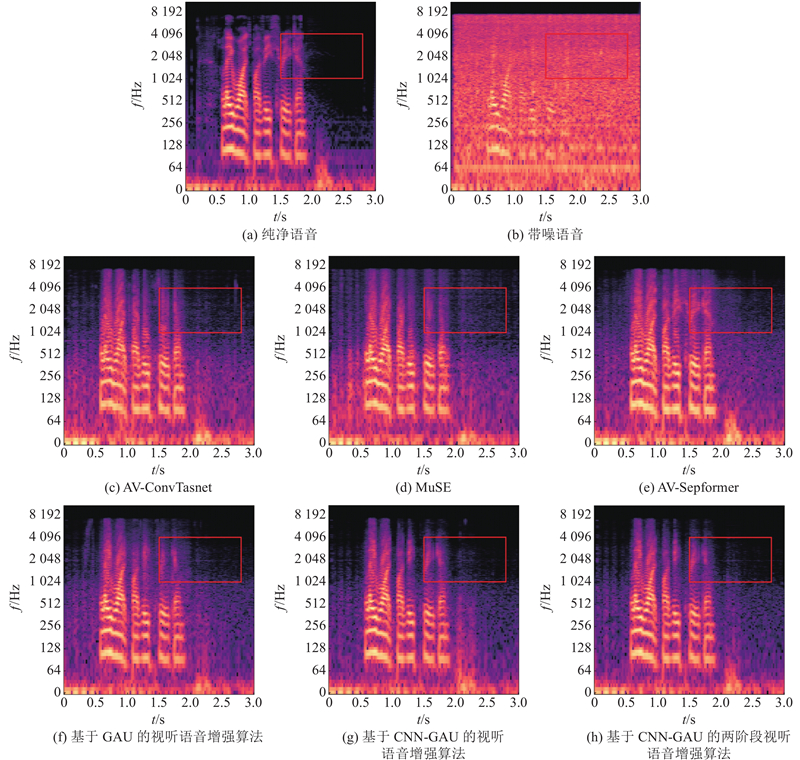
| 基于卷积和门控注意的两阶段视听语音增强算法 |
王盼蓉1( ),贾海蓉2,*(),段淑斐2 ),贾海蓉2,*(),段淑斐2 |
1. 太原理工大学 集成电路学院,山西 太原 030024
2. 太原理工大学 电子信息工程学院,山西 太原 030024 |
|
| Two-stage audio-visual speech enhancement algorithm based on convolution and gated attention |
| Panrong WANG1(),Hairong JIA2,*(),Shufei DUAN2 |
1. College of Integrated Circuits, Taiyuan University of Technology, Taiyuan 030024, China
2. College of Electronic Information Engineering, Taiyuan University of Technology, Taiyuan 030024, China |
| 1 |
张睿, 张鹏云, 孙超利 基于多域融合及神经架构搜索的语音增强方法[J]. 通信学报, 2024, 45 (2): 225- 239
ZHANG Rui, ZHANG Pengyun, SUN Chaoli Speech enhancement method based on multidomain fusion and neural architecture search[J]. Journal on Communications, 2024, 45 (2): 225- 239
doi: 10.11959/j.issn.1000-436x.2024018
|
| 2 |
纪鹏威, 全海燕 基于双生成器与频域判别器GAN语音增强算法[J]. 云南大学学报: 自然科学版, 2024, 46 (5): 871- 880
JI Pengwei, QUAN Haiyan GAN speech enhancement algorithm based on twin synthesizer and frequency domain discriminator[J]. Journal of Yunnan University: Natural Sciences Edition, 2024, 46 (5): 871- 880
|
| 3 |
AFOURAS T, CHUNG J S, ZISSERMAN A. The conversation: deep audio-visual speech enhancement [C]// Interspeech. Hyderabad: Curran Associates, 2018: 3244-3248.
|
| 4 |
AFOURAS T, CHUNG J S, ZISSERMAN A. My lips are concealed: audio-visual speech enhancement through obstructions [C]// Interspeech. Hyderabad: Curran Associates, 2019: 4295-4299.
|
| 5 |
MICHELSANTI D, TAN Z H, SIGURDSSON S, et al Deep-learning-based audio-visual speech enhancement in presence of Lombard effect[J]. Speech Communication, 2019, 115: 38- 50
doi: 10.1016/j.specom.2019.10.006
|
| 6 |
GOGATE M, DASHTIPOUR K, ADEEL A, et al CochleaNet: a robust language-independent audio-visual model for real-time speech enhancement[J]. Information Fusion, 2020, 63 (1): 273- 285
|
| 7 |
HOU J C, WANG S S, LAI Y H, et al Audio-visual speech enhancement using multimodal deep convolutional neural networks[J]. IEEE Transactions on Emerging Topics in Computational Intelligence, 2018, 2 (2): 117- 128
doi: 10.1109/TETCI.2017.2784878
|
| 8 |
GABBAY A, SHAMIR A, PELEG S. Visual speech enhancement [C]// Interspeech. Hyderabad: Curran Associates, 2018: 1170-1174.
|
| 9 |
WU J, XU Y, ZHANG S X, et al. Time domain audio visual speech separation [C]//IEEE Automatic Speech Recognition and Understanding Workshop. Singapore: IEEE, 2019: 667-673.
|
| 10 |
PAN Z, TAO R, XU C, et al. Muse: multi-modal target speaker extraction with visual cues [C]// IEEE International Conference on Acoustics, Speech and Signal Processing. Toronto: IEEE, 2021: 6678-6682.
|
| 11 |
LIN J, CAI X, DINKEL H, et al. Av-Sepformer: cross-attention Sepformer for audio-visual target speaker extraction [C]//IEEE International Conference on Acoustics, Speech and Signal Processing. Rhodes Island: IEEE, 2023: 1-5.
|
| 12 |
HUA W, DAI Z, LIU H, et al. Transformer quality in linear time [C]// International Conference on Machine Learning. Baltimore: [s. n. ], 2022: 9099-9117.
|
| 13 |
LUO Y, CHEN Z, YOSHIOKA T. Dual-path rnn: efficient long sequence modeling for time-domain single-channel speech separation [C]// IEEE International Conference on Acoustics, Speech and Signal Processing. Barcelona: IEEE, 2020: 46-50.
|
| 14 |
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778.
|
| 15 |
ZHAO S, MA B. Mossformer: pushing the performance limit of monaural speech separation using gated single-head transformer with convolution-augmented joint self-attentions [C]//IEEE International Conference on Acoustics, Speech and Signal Processing. Rhodes Island: IEEE, 2023: 1-5.
|
| 16 |
VASWANI A, SHAZEER N, PARMAR N, et al Attention is all you need[J]. Advances in Neural Information Processing System, 2017, 30 (1): 261- 272
|
| 17 |
SHAZEER N. Glu variants improve transformer [EB/OL]. (2020-02-12)[2024-07-15]. https://arxiv.org/pdf/2002.05202.
|
| 18 |
SU J, AHMED M, LU Y, et al Roformer: enhanced transformer with rotary position embedding[J]. Neurocomputing, 2024, 568: 127063
doi: 10.1016/j.neucom.2023.127063
|
| 19 |
PENG Y, DALMIA S, LANE I, et al. Branchformer: parallel mlp-attention architectures to capture local and global context for speech recognition and understanding [C]// International Conference on Machine Learning. Baltimore: [s. n. ], 2022: 17627-17643.
|
| 20 |
MU Z, YANG X. Separate in the speech chain: cross-modal conditional audio-visual target speech extraction [EB/OL]. (2024-05-05)[2024-07-15]. https://arxiv.org/pdf/2404.12725.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|