

目前,针对AVSE提出的主流深度学习方法通常涉及具有特定模式编码器、特征融合和解码器的模型. 编-解码器模型将语音增强定义为回归预测任务,模型以监督的方式进行端到端的训练,训练目标是学习适合语音增强的视听表示. Gabbay等[8]提出编-解码器模型的架构,将语音频谱图和视频帧作为输入,实现语音增强,验证了视听语音增强模型相较于纯音频模型的优越性. Wu等[9]提出时域视听架构(AV-ConvTasnet),该架构基于时域语音分离网络(TasNet)进行改进以支持多模态学习,将经典的视听语音任务从频域扩展到时域,避免了频域中相位的精确重构这一难题. Pan等[10]提出多模态说话人提取网络(MuSE),采用基于掩码的说话人提取器,较AV-ConvTasnet取得了更好的效果. Lin等[11]提出基于双尺度Transformer的模型(AV-Sepformer),利用交叉和自注意对音视频特征进行融合和建模,在语音信号质量和感知质量方面始终优于其他现有的AVSE模型. 由于Transformer的复杂度高,AV-Sepformer需要消耗大量的计算资源,导致远程全局上下文建模低效,没有很好地利用卷积来学习局部特征,模型不是最优. 此外,由于视频模态包含的语音信息没有音频模态丰富,AVSE模型在训练过程中会自动聚焦音频模态,导致视频模态没有被充分利用. 视频模态中含有干净语音的频谱信息,一项关于McGurk效应的研究表明,嘴唇的形状在语音处理中发挥着重要作用,因此必须充分考虑视频模态的重要性.
本文针对视听语音增强模型复杂度高、远程全局上下文进行建模低效以及缺乏局部特征建模,模态失衡的问题,提出基于卷积和门控注意的两阶段视听语音增强算法. 该算法采用分块混合的门控注意单元(gated attention unit,GAU)[12],允许使用简化的单头注意力,通过块内二次注意和块间线性注意,对远程全局上下文进行高效的建模. 将卷积模块集成到GAU中,利用逐深度卷积和点卷积,对块内和块间细粒度的局部特征进行建模. 将语音增强分为2个阶段:第1阶段以音频为主导模态,视频作为条件模态;第2阶段以视频为主导模态,第1阶段提取的音频作为条件模态,旨在充分利用音视频模态信息. 结果表明,该算法的性能优于AV-Sepformer,能够在复杂度较低的同时提升语音增强效果.
1. 本文算法
利用时域AVSE模型,提出基于卷积和门控注意的两阶段视听语音增强模型. 该模型采用音频编码器、视频编码器、解码器和特征融合网络,整体结构如图1所示.
图 1
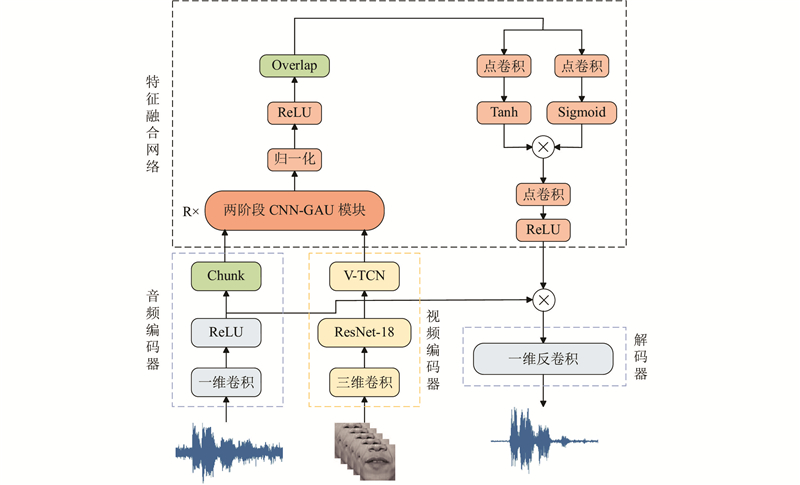
图 1 基于卷积和门控注意的两阶段视听语音增强算法的框架图
Fig.1 Framework diagram of two-stage audio-visual speech enhancement algorithm based on convolution and gated attention
在时域语音增强中,带噪语音通常可以表示为
式中:
1.1. 音频编码器
音频编码器使用一维卷积和整流线性单元,对带噪语音
式中:
式中:
1.2. 视频编码器
视频编码器由三维卷积层、ResNet-18模块[14]、视频时间卷积模块(video time convolution module,VTCN)组成. 三维卷积层和ResNet-18模块是从唇读任务中预训练出来的,权值在训练过程中是固定的. VTCN由5个残差连接的激活函数、批归一化、深度可分离卷积组成. VTCN的输出被上采样,以匹配音频特征的分辨率.
视频编码器的输入是以嘴唇区域为中心的灰度图像序列(该图像是原始视频通过人脸关键点检测获得的),每个图像被编码为一个
1.3. 特征融合网络
将音视频编码器提取的音视频特征分别作为特征融合网络的输入,网络的输出为目标音频的掩码. 在两阶段CNN-GAU模块中,音视频特征由卷积模块和门控注意机制处理[15]. 卷积模块使用点卷积和逐深度卷积提取局部特征. 门控注意机制执行块内和块间的联合注意,捕获全局上下文依赖关系. 将两阶段CNN-GAU模块的输出和视频特征作为下一个两阶段CNN-GAU模块的输入,过程重复R次. 通过归一化、激活函数、点卷积操作、Overlap(chunk的逆操作)、一个输出门控,最后通过点卷积和激活函数得到掩码
1.3.1. 复杂度分析
Transformer[16]作为最先进的深度学习模型,在语言处理任务上取得了很大的成功. 由于参数量高,需要大量的计算资源,这一限制导致Transformer模型在处理大规模数据时效率很低. 如何使用更有效的模型来代替Transformer成为关键问题.
标准的Transformer是多头注意力机制,由多头注意力层(multi-head attention)和前馈层(FFN)组成,参数量为权重矩阵的大小,即12d2(其中d为隐藏层维度).
GAU[12]的计算公式如下.
式中:
GAU是新的Transformer变体,本质是融入了注意力的门控线性单元(GLU)[17],可以在有效减少参数量的同时提升质量. 选择使用GAU作为特征融合网络的主体结构.
1.3.2. 分块混合多模态GAU
提出GAU以代替自注意(self-attention),将GAU应用在视听模态上,验证GAU在跨模态任务中的有效性. 本文证明了GAU可以应用于交叉注意(cross-attention).
将分块音频特征
选择块内-块间联合注意的方式,对音视频特征进行高效的远程建模. 在语音增强任务中,主要关注的特征集中在短上下文,远程关联虽然存在,但不是主导地位. 对块内执行能学习复杂关联的二次注意,对块间执行简单的线性注意. 在保证模型对短上下文特征重点关注的同时,有效降低了远程建模的复杂度,提升整体的建模效率. 对
将局部键和查询及
每个块的局部注意为
跨块的全局注意为
式中:
将整个序列的注意
1.3.3. CNN-GAU模块
提出卷积模块,对音视频序列的局部特征进行建模. 将卷积模块有效集成到GAU中,充分发挥卷积和注意力提取特征的优势,提升模型性能.
卷积和注意力机制是提取特征的2种不同方法. 卷积操作在局部区域上进行权重计算,可以捕捉到局部上下文信息. 注意力机制可以根据输入来自适应地对不同位置的特征进行加权,捕获全局上下文信息. 将卷积模块和GAU有机地结合起来,通过注意力机制捕获音视频序列的全局依赖关系,利用卷积捕获局部相关性. 卷积模块的结构如图2所示.
图 2

将输入通过线性层进行投影,按特征维度平分,得到
GAU通过局部-全局注意力对远程全局上下文进行建模,本文通过卷积模块来增强GAU中的一路特征,为GAU提供局部特征建模. 式(14)转变为
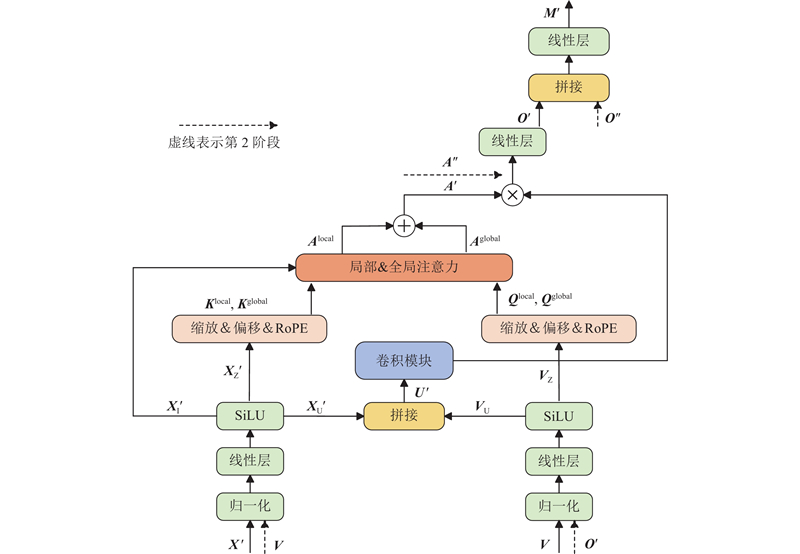
1.3.4. 两阶段CNN-GAU模块
现有的AVSE模型都忽视了视频模态的重要性[20]. 视频特征一般是从说话人的嘴唇图像帧提取出来的,感知者可以通过观察说话人的嘴唇运动来推断语音内容,且视频信息不受噪声环境的干扰,因此视频模态包含丰富的纯净语音信息,在视听语音增强任务中必须充分利用. 为了平衡2种模态,采用两阶段算法,第1阶段音频作为主导模态,视频作为条件模态. 第2阶段视频作为主导模态,第1阶段提取的音频作为条件模态.
在跨模态注意力机制中,通常由一个模态提供查询(query),另一个模态提供键(key)和值(value). 查询模态的主要作用是指导注意力机制去关注另一个模态中的信息. 通过查询向量与键向量之间的相似性计算生成注意力权重,对值向量进行加权以生成最终输出. 在语音增强任务中,通常由音频模态提供键和值,为注意力机制提供权重计算和生成输出所需的核心信息,作为主导模态. 视频模态提供查询向量,指导了如何从音频模态中提取信息,作为条件模态. 在本文中增加将视频作为主导模态,音频作为条件模态的阶段.
将
将
两阶段CNN-GAU模块的整体框架如图3所示.
图 3
1.4. 解码器
解码器采用一维转置卷积层重建目标语音,它和音频编码器具有相同的核大小和步幅. 解码器的输入是掩码
2. 实验验证
2.1. 实验设置
选用GRID视听数据集评估模型. 训练集、验证集、测试集语音没有重叠,所有语音和视频时长均为3 s,训练集、验证集、测试集分别包含4 000、500、500条干净语音和视频. 噪声为生活中常见的一些噪声,如闹钟、马路鸣笛、风雨、救护车、煮水等10种噪声. 将噪声以随机的信噪比(SNR)与干净语音混合,训练集的信噪比设置为−10~10 dB的整数值. 测试集在5个典型信噪比(−10、−5、0、5、10 dB)下生成.
表 1 基于卷积和门控注意的两阶段视听语音增强算法的实验参数设置
Tab.1
| 参数 | 数值 |
| Conv1D卷积核大小L | 16 |
| 块长度P | 80 |
| 双阶段CNN-GAU模块个数R | 8 |
| 512 | |
| 128 |
表 2 基于卷积和门控注意的两阶段视听语音增强算法的实验环境
Tab.2
| 环境 | 配置参数 | 环境 | 配置参数 | |
| CPU | AMD Ryzen 7 3800X | 显存 | 10 GB | |
| 主频 | 3.89 GHz | IDE环境 | Pycharm | |
| 内存 | 48 GB | 编译语言 | Python 3.8 | |
| GPU | NVIDIA GeForce RTX 3080 | — | — |
在评价指标中,分别采用信噪比和语音感知质量测评(PESQ)来评估语音增强的效果. 其中SNR是信号功率与噪声功率的比值,较直观地表现出信号中噪声的抑制程度. SNR越高,说明信号中的噪声越少. PESQ通过比较增强语音与干净语音之间的感知差异,对语音质量进行打分,得分为−0.5~4.5,分值越高说明被测试语音的听觉感知质量越好.
2.2. 实验结果
表 3 风雨噪声5种信噪比下各模型的语音增强效果对比
Tab.3
| 模型 | PESQ | SNR/dB | |||||||||
| −10 dB | −5 dB | 0 dB | 5 dB | 10 dB | −10 dB | −5 dB | 0 dB | 5 dB | 10 dB | ||
| Noisy | 1.54 | 1.67 | 1.86 | 2.15 | 2.47 | −10 | −5 | 0 | 5 | 10 | |
| AV-ConvTasnet | 2.13 | 2.17 | 2.32 | 2.36 | 2.40 | 3.98 | 4.26 | 4.44 | 4.42 | 4.31 | |
| MuSE | 2.19 | 2.25 | 2.37 | 2.42 | 2.46 | 4.57 | 5.76 | 6.35 | 6.41 | 6.29 | |
| AV-Sepformer | 2.53 | 2.59 | 2.75 | 2.82 | 2.88 | 6.47 | 6.58 | 6.83 | 6.89 | 6.78 | |
| 本文模型 | 2.77 | 2.79 | 3.01 | 3.16 | 3.25 | 12.29 | 13.09 | 14.11 | 14.54 | 14.55 | |
表 4 救护车噪声5种信噪比下各模型的语音增强效果对比
Tab.4
| 模型 | PESQ | SNR/dB | |||||||||
| −10 dB | −5 dB | 0 dB | 5 dB | 10 dB | −10 dB | −5 dB | 0 dB | 5 dB | 10 dB | ||
| Noisy | 1.76 | 2.09 | 2.28 | 2.37 | 2.55 | −10 | −5 | 0 | 5 | 10 | |
| AV-ConvTasnet | 2.27 | 2.33 | 2.42 | 2.47 | 2.52 | 3.97 | 3.96 | 4.20 | 4.04 | 4.06 | |
| MuSE | 2.32 | 2.42 | 2.54 | 2.62 | 2.67 | 5.92 | 6.13 | 6.47 | 6.24 | 6.17 | |
| AV-Sepformer | 2.69 | 2.74 | 2.84 | 2.90 | 2.93 | 6.75 | 6.58 | 6.89 | 6.77 | 6.81 | |
| 本文模型 | 2.96 | 3.10 | 3.28 | 3.39 | 3.47 | 13.93 | 14.07 | 14.80 | 14.58 | 14.68 | |
表 5 闹钟噪声5种信噪比下各模型的语音增强效果对比
Tab.5
| 模型 | PESQ | SNR/dB | |||||||||
| −10 dB | −5 dB | 0 dB | 5 dB | 10 dB | −10 dB | −5 dB | 0 dB | 5 dB | 10 dB | ||
| Noisy | 1.70 | 1.92 | 2.25 | 2.42 | 2.64 | −10 | −5 | 0 | 5 | 10 | |
| AV-ConvTasnet | 2.35 | 2.32 | 2.55 | 2.60 | 2.65 | 4.39 | 4.50 | 4.50 | 4.29 | 4.32 | |
| MuSE | 2.35 | 2.55 | 2.65 | 2.69 | 2.73 | 6.27 | 6.80 | 6.91 | 6.47 | 6.38 | |
| AV-Sepformer | 2.67 | 2.81 | 2.86 | 2.92 | 2.93 | 6.77 | 6.79 | 6.82 | 6.62 | 6.76 | |
| 本文模型 | 2.88 | 3.08 | 3.25 | 3.35 | 3.45 | 12.89 | 13.57 | 14.33 | 14.12 | 14.39 | |
在风雨噪声下,相较于次优的AV-Sepformer基线,本文方法在PESQ指标上最高提升了0.37,在SNR指标上最高提升了7.77 dB. 在救护车噪声下,本文方法在PESQ上较AV-Sepformer最高提升了0.54,在SNR指标上最高提升了7.91 dB. 在闹钟噪声下,本文方法在PESQ上较AV-Sepformer最高提升了0.52,在SNR指标上最高提升了7.63 dB. 实验表明,本文方法在不同噪声、不同信噪比干扰下均保持最优的性能.
为了研究所提模型的不同模块对增强效果的影响,开展如下消融实验.
实验1:基于双尺度Transformer的模型(AV-Sepformer).
实验2:基于GAU的视听语音增强算法,在AV-Sepformer的基础上用分块混合的GAU替换分块的Transformer.
实验3:基于CNN-GAU的视听语音增强算法,在实验2的基础上添加了卷积模块.
实验4:基于卷积和门控注意的两阶段视听语音增强算法,在实验3的基础上增加了以视频模态为主导的阶段.
如表6~8所示为不同干扰噪声的5种信噪比下4个消融实验的语音增强效果比较. 测试集的实验结果表明,各个模块在不同程度上提升了对语音增强的效果. 从表6~8可知,AV-Sepformer由于局部特征建模的缺乏,PESQ和SI-SNR相对较低. 基于GAU的视听语音增强算法采用分块混合的门控注意单元以提供高效的远程建模,逐步提升了增强效果. 基于CNN-GAU的视听语音增强模型包含有效的远程建模和局部特征建模,进一步改善了增强效果. 基于卷积和门控注意的两阶段视听语音增强算法充分利用了音视频模态,PESQ达到最优. SNR相较于实验3略有下降,这是由于加入了视频模态为主导的阶段可能会引入一些伪影,导致信噪比略有下降,但语音的感知质量有所提高.
表 6 风雨噪声下不同模块对增强语音PESQ和SNR的影响
Tab.6
| 模型 | PESQ | SNR/dB | |||||||||
| −10 dB | −5 dB | 0 dB | 5 dB | 10 dB | −10 dB | −5 dB | 0 dB | 5 dB | 10 dB | ||
| 实验1 | 2.53 | 2.59 | 2.75 | 2.82 | 2.88 | 6.47 | 6.58 | 6.83 | 6.89 | 6.78 | |
| 实验2 | 2.56 | 2.63 | 2.78 | 2.93 | 2.98 | 10.52 | 11.73 | 12.33 | 13.33 | 13.80 | |
| 实验3 | 2.70 | 2.75 | 2.97 | 3.13 | 3.22 | 11.84 | 12.95 | 14.03 | 14.64 | 14.68 | |
| 实验4 | 2.77 | 2.79 | 3.01 | 3.16 | 3.25 | 12.29 | 13.09 | 14.11 | 14.54 | 14.55 | |
表 7 救护车噪声下不同模块对增强语音PESQ和SNR的影响
Tab.7
| 模型 | PESQ | SNR/dB | |||||||||
| −10 dB | −5 dB | 0 dB | 5 dB | 10 dB | −10 dB | −5 dB | 0 dB | 5 dB | 10 dB | ||
| 实验1 | 2.69 | 2.74 | 2.84 | 2.90 | 2.93 | 6.75 | 6.58 | 6.89 | 6.77 | 6.81 | |
| 实验2 | 2.88 | 2.98 | 3.18 | 3.27 | 3.39 | 13.77 | 13.68 | 14.77 | 14.66 | 14.81 | |
| 实验3 | 2.94 | 3.06 | 3.26 | 3.38 | 3.47 | 14.06 | 14.23 | 14.97 | 14.76 | 14.89 | |
| 实验4 | 2.96 | 3.10 | 3.28 | 3.39 | 3.47 | 13.93 | 14.07 | 14.80 | 14.58 | 14.68 | |
表 8 闹钟噪声下不同模块对增强语音PESQ和SNR的影响
Tab.8
| 模型 | PESQ | SNR/dB | |||||||||
| −10 dB | −5 dB | 0 dB | 5 dB | 10 dB | −10 dB | −5 dB | 0 dB | 5 dB | 10 dB | ||
| 实验1 | 2.67 | 2.81 | 2.86 | 2.92 | 2.93 | 6.77 | 6.79 | 6.82 | 6.62 | 6.76 | |
| 实验2 | 2.81 | 2.99 | 3.15 | 3.24 | 3.29 | 12.88 | 13.39 | 13.99 | 13.99 | 14.27 | |
| 实验3 | 2.85 | 3.05 | 3.22 | 3.31 | 3.42 | 12.83 | 13.67 | 14.48 | 14.27 | 14.54 | |
| 实验4 | 2.88 | 3.08 | 3.25 | 3.35 | 3.45 | 12.89 | 13.57 | 14.33 | 14.12 | 14.39 | |
如表9所示为各个模型的复杂度,包含参数量、计算量. 可以看出,AV-Sepformer的复杂度最高,基于卷积和门控注意的两阶段视听语音增强算法(实验4)的效果最优,与次优的AV-Sepformer相比,复杂度较低.
表 9 各个模型的复杂度对比
Tab.9
| 模型 | 参数量/106 | 计算量/109 |
| AV-ConvTasnet | 11.03 | 22.08 |
| MuSE | 15.01 | 25.88 |
| AV-Sepformer | 29.63 | 141.83 |
| 实验2 | 5.22 | 36.71 |
| 实验3 | 10.52 | 68.27 |
| 实验4 | 13.16 | 78.63 |
分析各个方法在语音增强方面的效果. 如图4所示为信噪比为−5 dB的带噪语音(风雨噪声)经过不同方法增强后的语谱图.
图 4
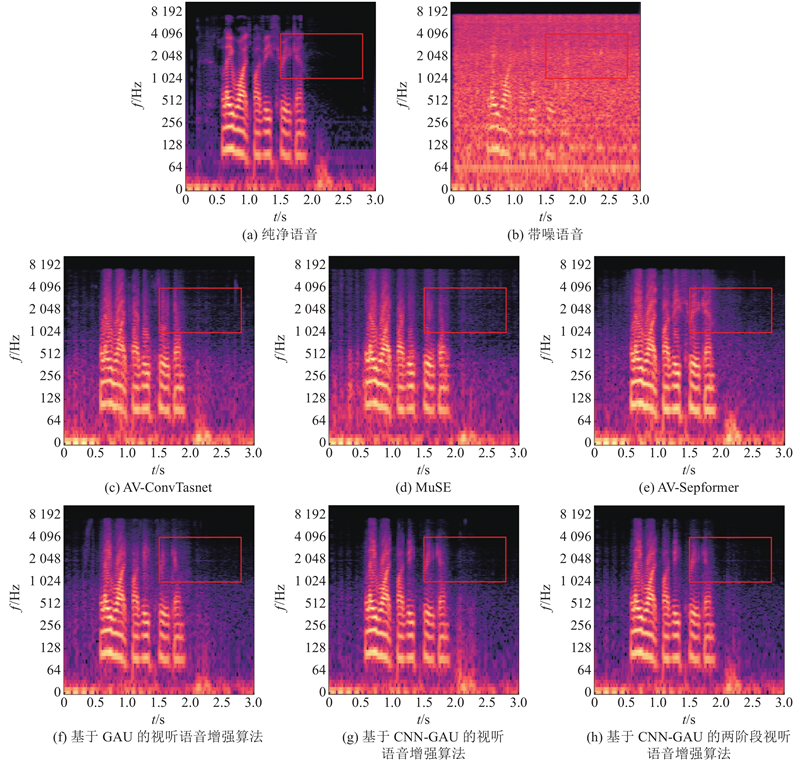
图 4 不同模型在−5 dB风雨噪声上的增强语音语谱图对比
Fig.4 Comparison of enhanced speech spectrogram of different models on −5 dB wind and rain noise
从图4可以看出,AV-ConvTasnet和MuSE语音增强效果较差,无法还原原本的语谱信息,噪声残留很多. 相比而言,AV-Sepformer基本还原了语音的语谱信息,但噪声残留仍旧很多. 与AV-Sepformer相比,基于GAU的视听语音增强算法的噪声残留少,但语谱信息有所丢失. 利用基于CNN-GAU的视听语音增强算法,还原了语音的语谱信息且残留的噪声少. 基于卷积和门控注意的两阶段视听语音增强算法残留的噪声最少,语音增强效果显著.
综上所述,利用本文方法,较大幅度地提升了PESQ和SNR,减小了复杂度,证明利用所提方法能够更有效地抑制噪声干扰,提升增强效果.
3. 结 语
为了解决视听语音增强模型复杂度高、性能不佳的问题,本文提出基于卷积和门控注意的两阶段视听语音增强算法. 使用分块混合GAU解决复杂度的问题,通过块内二次注意和块间线性注意捕获全局依赖关系. 在GAU的基础上添加卷积模块,对局部特征进行建模,捕获局部依赖关系. 分别将音频模态和视频模态作为主导模态,充分利用音视频模态包含的语音信息. 为了验证所提方法的有效性,在GRID数据集上进行评估对比实验. 结果表明,相较于现有方法,所提方法在增强效果方面表现更优,复杂度较低,各项评价指标的得分均有显著提升,证明了本文算法的有效性. 此外,所提方法还有待改进,如何增强模型的泛化性,使其能够自适应地处理不同的语音增强子任务,例如不同采样率的带噪语音,推进面向更真实场景的语音增强模型的研究.
参考文献
基于多域融合及神经架构搜索的语音增强方法
[J].DOI:10.11959/j.issn.1000-436x.2024018 [本文引用: 1]
Speech enhancement method based on multidomain fusion and neural architecture search
[J].DOI:10.11959/j.issn.1000-436x.2024018 [本文引用: 1]
基于双生成器与频域判别器GAN语音增强算法
[J].
GAN speech enhancement algorithm based on twin synthesizer and frequency domain discriminator
[J].
Deep-learning-based audio-visual speech enhancement in presence of Lombard effect
[J].DOI:10.1016/j.specom.2019.10.006
CochleaNet: a robust language-independent audio-visual model for real-time speech enhancement
[J].
Audio-visual speech enhancement using multimodal deep convolutional neural networks
[J].DOI:10.1109/TETCI.2017.2784878 [本文引用: 1]
Attention is all you need
[J].
Roformer: enhanced transformer with rotary position embedding
[J].DOI:10.1016/j.neucom.2023.127063 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}