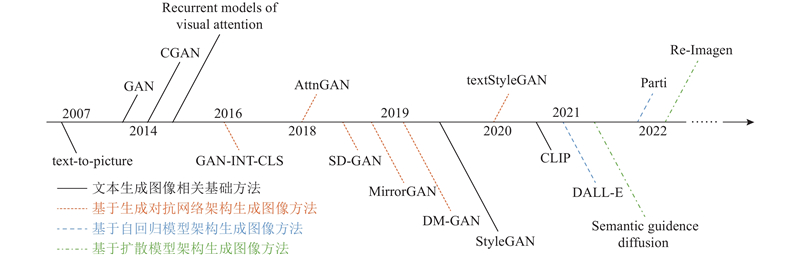
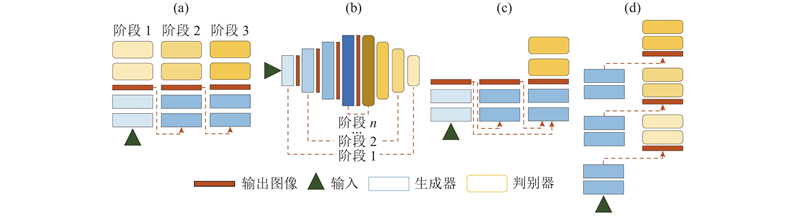
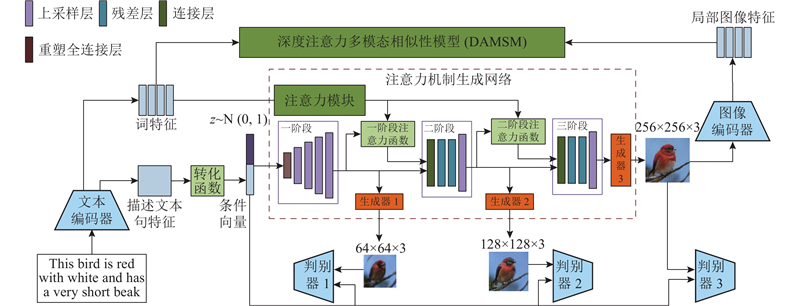
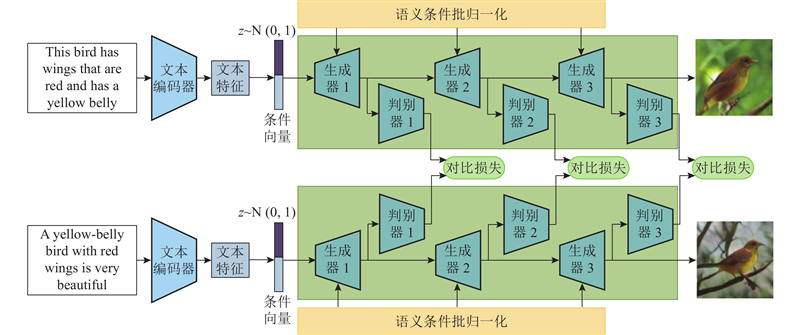
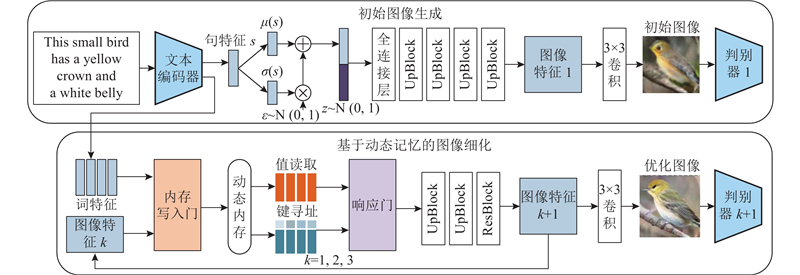
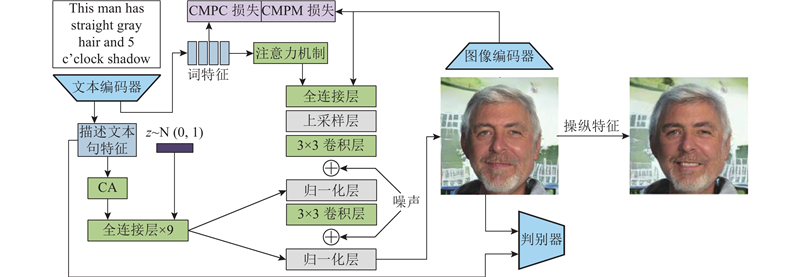
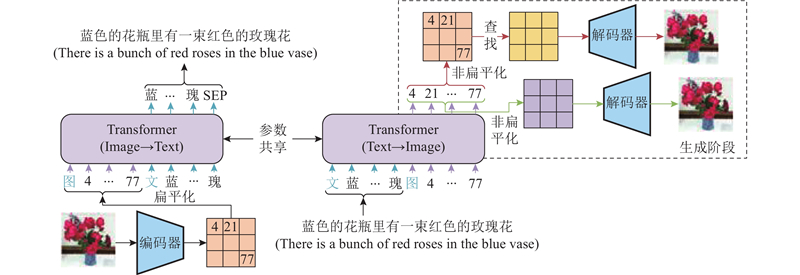
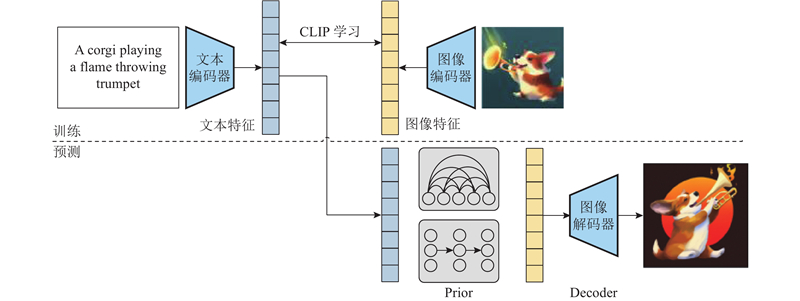
|
|
|
| 文本生成图像研究综述 |
曹寅1,2( ),秦俊平1,2,*(),马千里1,2,孙昊1,2,闫凯1,2,王磊1,2,任家琪1,2 ),秦俊平1,2,*(),马千里1,2,孙昊1,2,闫凯1,2,王磊1,2,任家琪1,2 |
1. 内蒙古工业大学 数据科学与应用学院,内蒙古 呼和浩特 010000
2. 内蒙古自治区基于大数据的软件服务工程技术研究中心,内蒙古 呼和浩特 010000 |
|
| Survey of text-to-image synthesis |
| Yin CAO1,2(),Junping QIN1,2,*(),Qianli MA1,2,Hao SUN1,2,Kai YAN1,2,Lei WANG1,2,Jiaqi REN1,2 |
1. College of Data Science and Applications, Inner Mongolia University of Technology, Hohhot 010000, China
2. Inner Mongolia Autonomous Region Engineering Technology Research Center of Big Data Based Software Service, Hohhot 010000, China |
引用本文:
曹寅,秦俊平,马千里,孙昊,闫凯,王磊,任家琪. 文本生成图像研究综述[J]. 浙江大学学报(工学版), 2024, 58(2): 219-238.
Yin CAO,Junping QIN,Qianli MA,Hao SUN,Kai YAN,Lei WANG,Jiaqi REN. Survey of text-to-image synthesis. Journal of ZheJiang University (Engineering Science), 2024, 58(2): 219-238.
链接本文:
https://www.zjujournals.com/eng/CN/10.3785/j.issn.1008-973X.2024.02.001
或
https://www.zjujournals.com/eng/CN/Y2024/V58/I2/219
|
| 1 |
ZHU X, GOLDBERG A B, ELDAWY M, et al. A text-to-picture synthesis system for augmenting communication [C]// Proceedings of the AAAI Conference on Artificial Intelligence . British Columbia: AAAI, 2007, 7: 1590-1595.
|
| 2 |
REED S, AKATA Z, YAN X, et al. Generative adversarial text to image synthesis [C]// International Conference on Machine Learning . New York: ACM, 2016: 1060-1069.
|
| 3 |
GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al Generative adversarial networks[J]. Communications of the ACM, 2020, 63 (11): 139- 144
doi: 10.1145/3422622
|
| 4 |
MIRZA M, OSINDERO S. Conditional generative adversarial nets [EB/OL]. [2014-11-06]. https://arxiv.org/pdf/1411. 1784.pdf.
|
| 5 |
RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]// International Conference on Machine Learning . [S. l. ]: ACM, 2021: 8748-8763.
|
| 6 |
ISOLA P, ZHU J Y, ZHOU T, et al. Image-to-image translation with conditional adversarial networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 1125-1134.
|
| 7 |
ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks [C]// Proceedings of the IEEE International Conference on Computer Vision . Honolulu: IEEE, 2017: 2223-2232.
|
| 8 |
WANG T, ZHANG T, LIU L, et al. CannyGAN: edge-preserving image translation with disentangled features [C]// IEEE International Conference on Image Processing . Taipei: IEEE, 2019: 514-518.
|
| 9 |
ZHANG T, WILIEM A, YANG S, et al. TV-GAN: generative adversarial network based thermal to visible face recognition [C]// International Conference on Biometrics . Gold Coast: IEEE, 2018: 174-181.
|
| 10 |
ZHANG H, XU T, LI H, et al. StackGAN: text to photo-realistic image synthesis with stacked generative adversarial networks [C]// Proceedings of the IEEE International Conference on Computer Vision . Honolulu: IEEE, 2017: 5907-5915.
|
| 11 |
XU T, ZHANG P, HUANG Q, et al. AttnGAN: fine-grained text to image generation with attentional generative adversarial networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 1316-1324.
|
| 12 |
LEE D D, PHAM P, LARGMAN Y, et al. Advances in neural information processing systems 22 [R]. Long Beach: IEEE, 2009.
|
| 13 |
贺小峰, 毛琳, 杨大伟 文本生成图像中语义-空间特征增强算法[J]. 大连民族大学学报, 2022, 24 (5): 401- 406
HE Xiaofeng, MAO Lin, YANG Dawei Semantic-spatial feature enhancement algorithm for text-to-image generation[J]. Journal of Dalian Minzu University, 2022, 24 (5): 401- 406
|
| 14 |
SHI X, CHEN Z, WANG H, et al Convolutional LSTM network: a machine learning approach for precipitation nowcasting[J]. Advances in Neural Information Processing Systems, 2015, 28 (18): 156- 167
|
| 15 |
RAMESH A, PAVLOV M, GOH G, et al. Zero-shot text-to-image generation [C]// International Conference on Machine Learning . [S. l. ]: ACM, 2021: 8821-8831.
|
| 16 |
DING M, YANG Z, HONG W, et al Cogview: mastering text-to-image generation via transformers[J]. Advances in Neural Information Processing Systems, 2021, 34 (18): 19822- 19835
|
| 17 |
DING M, ZHENG W, HONG W, et al. Cogview2: faster and better text-to-image generation via hierarchical transformers [EB/OL]. [2022-05-27]. https://arxiv.org/pdf/2204.14217.
|
| 18 |
YU J, XU Y, KOH J Y, et al. Scaling autoregressive models for content-rich text-to-image generation [EB/OL]. [2022-06-22]. https://arxiv.org/pdf/2206.10789.
|
| 19 |
CHEN W, HU H, SAHARIA C, et al. Re-imagen: retrieval-augmented text-to-image generator [EB/OL]. [2022-11-22]. https://arxiv.org/pdf/2209.14491.
|
| 20 |
HO J, JAIN A, ABBEEL P Denoising diffusion probabilistic models[J]. Advances in Neural Information Processing Systems, 2020, 33 (18): 6840- 6851
|
| 21 |
DHARIWAL P, NICHOL A Diffusion models beat GANs on image synthesis[J]. Advances in Neural Information Processing Systems, 2021, 34 (18): 8780- 8794
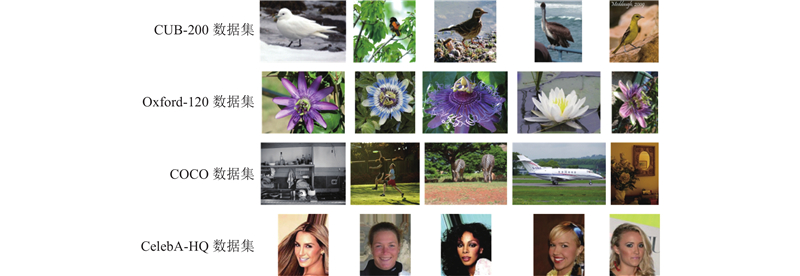
|
| 22 |
DEVLIN J, CHANG M W, LEE K, et al. Bert: pre-training of deep bidirectional transformers for language understanding [EB/OL]. [2019-05-24]. https://arxiv.org/pdf/ 1810.04805.
|
| 23 |
KARRAS T, LAINE S, AILA T. A style-based generator architecture for generative adversarial networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 4401-4410.
|
| 24 |
REED S, AKATA Z, LEE H, et al. Learning deep representations of fine-grained visual descriptions [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 49-58.
|
| 25 |
ZHANG H, XU T, LI H, et al StackGAN++: realistic image synthesis with stacked generative adversarial networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 41 (8): 1947- 1962
|
| 26 |
ZHANG Z, XIE Y, YANG L. Photographic text-to-image synthesis with a hierarchically-nested adversarial network [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE 2018: 6199-6208.
|
| 27 |
HUANG X, WANG M, GONG M. Hierarchically-fused generative adversarial network for text to realistic image synthesis [C]// 16th Conference on Computer and Robot Vision . Kingston: IEEE, 2019: 73-80.
|
| 28 |
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770-778.
|
| 29 |
GAO L, CHEN D, SONG J, et al. Perceptual pyramid adversarial networks for text-to-image synthesis [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Honolulu: AAAI, 2019, 33(1): 8312-8319.
|
| 30 |
LAI W S, HUANG J B, AHUJA N, et al. Deep Aplacian pyramid networks for fast and accurate super-resolution [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 624-632.
|
| 31 |
韩爽. 基于生成对抗网络的文本到图像生成技术研究[D]. 大庆: 东北石油大学, 2022.
HAN Shuang. Research on text-to-image generation techniques based on generative adversarial networks [D]. Daqing: Northeast Petroleum University, 2022.
|
| 32 |
王家喻. 基于生成对抗网络的图像生成研究[D]. 合肥: 中国科学技术大学, 2021.
WANG Jiayu. Research on image generation based on generative adversarial networks [D]. Hefei: University of Science and Technology of China, 2021.
|
| 33 |
田枫, 孙小强, 刘芳, 等 融合双注意力与多标签的图像中文描述生成方法[J]. 计算机系统应用, 2021, 30 (7): 32- 40
TIAN Feng, SUN Xiaoqiang, LIU Fang, et al Image caption generation method combining dual attention and multi-labels[J]. Computer Systems and Applications, 2021, 30 (7): 32- 40
doi: 10.15888/j.cnki.csa.008010
|
| 34 |
TAN H, LIU X, LI X, et al. Semantics-enhanced adversarial nets for text-to-image synthesis [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Long Beach: IEEE, 2019: 10501-10510.
|
| 35 |
HUANG W, DA XU R Y, OPPERMANN I. Realistic image generation using region-phrase attention [C]// Asian Conference on Machine Learning . Nagoya: ACM, 2019: 284-299.
|
| 36 |
LI B, QI X, LUKASIEWICZ T, et al. Controllable text-to-image generation [J]. Advances in Neural Information Processing Systems , 2019, 32(18): 2065-2075.
|
| 37 |
ZHANG Z, SCHOMAKER L DiverGAN: an efficient and effective single-stage framework for diverse text-to-image generation[J]. Neurocomputing, 2022, 473 (18): 182- 198
|
| 38 |
YIN G, LIU B, SHENG L, et al. Semantics disentangling for text-to-image generation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 2327-2336.
|
| 39 |
HADSELL R, CHOPRA S, LECUN Y. Dimensionality reduction by learning an invariant mapping [C]// IEEE Computer Society Conference on Computer Vision and Pattern Recognition . New York: IEEE, 2006: 1735-1742.
|
| 40 |
CHEN Z, LUO Y. Cycle-consistent diverse image synthesis from natural language [C]// IEEE International Conference on Multimedia and Expo Workshops . Shanghai: IEEE, 2019: 459-464.
|
| 41 |
QIAO T, ZHANG J, XU D, et al. MirrorGAN: learning text-to-image generation by redescription [C]/ /Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 1505-1514.
|
| 42 |
KARPATHY A, FEI-FEI L. Deep visual-semantic alignments for generating image descriptions [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2015: 3128-3137.
|
| 43 |
VINYALS O, TOSHEV A, BENGIO S, et al. Show and tell: a neural image caption generator [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2015: 3156-3164.
|
| 44 |
DUMOULIN V, BELGHAZI I, POOLE B, et al. Adversarially learned inference [EB/OL]. [2017-02-21]. https://arxiv.org/pdf/1606.00704.pdf.
|
| 45 |
LAO Q, HAVAEI M, PESARANGHADER A, et al. Dual adversarial inference for text-to-image synthesis [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Long Beach: IEEE, 2019: 7567-7576.
|
| 46 |
王蕾. 基于关联语义挖掘的文本生成图像算法研究[D]. 西安: 西安电子科技大学, 2020.
WANG Lei. Research on text-to-image generation algorithm based on semantic association mining [D]. Xi’an: Xidian University, 2020.
|
| 47 |
吕文涵, 车进, 赵泽纬. 等. 基于动态卷积与文本数据增强的图像生成方法[EB/OL]. [2023-07-01]. https://kns.cnki.net/kcms2/article/abstract?v=sSXGFc3NEDIAReRhgp48uNl5G2T_5G24IJmVa17AFT4XZFr932Jmsa2EZrM7rxoIWSwHni_2CiKpa4phSwe9hcwvepEs3fO1pcWCTfWKZ7gIU_jFpQgmgw==&uniplatform=NZKPT.
|
| 48 |
薛志杭, 许喆铭, 郎丛妍, 等. 基于图像-文本语义一致性的文本生成图像方法[J]. 计算机研究与发展, 2023, 60(9): 2180-2190.
XUE Zhihang, XU Zheming, LANG Congyan, et al. Text-to-image generation method based on image-text semantic consistency [J]. Journal of Computer Research and Development , 2023, 60(9): 2180-2190.
|
| 49 |
吴春燕, 潘龙越, 杨有 基于特征增强生成对抗网络的文本生成图像方法[J]. 微电子学与计算机, 2023, (6): 51- 61
WU Chunyan, PAN Longyue, YANG You Text generated images based on feature enhancement generated against network approach[J]. Microelectronics and Computers, 2023, (6): 51- 61
doi: 10.19304/J.ISSN1000-7180.2022.0629
|
| 50 |
王威, 李玉洁, 郭富林, 等. 生成对抗网络及其文本图像合成综述[J]. 计算机工程与应用, 2022, 58(19): 14-36.
WANG Wei, LI Yujie, GUO Fulin, et al. A survey on generative adversarial networks and text-image synthesis [J]. Computer Engineering and Applications , 2012, 58(19): 14-36.
|
| 51 |
李欣炜. 基于多深度神经网络的文本生成图像研究[D]. 大连: 大连理工大学, 2022.
LI Xinwei. Research on text-generated image based on multi-deep neural network [D]. Dalian: Dalian University of Technology, 2022.
|
| 52 |
叶龙, 王正勇, 何小海. 基于多模态融合的文本生成图像[J]. 智能计算机与应用, 2022, 12(11): 9-17.
YE Long, WANG Zhengyong, HE Xiaohai. Image generation from text based on multi-modal fusion [J]. Intelligent Computer and Application , 2012, 12(11): 9-17.
|
| 53 |
ZHU M, PAN P, CHEN W, et al. Dm-GAN: dynamic memory generative adversarial networks for text-to-image synthesis [C]/ /Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 5802-5810.
|
| 54 |
GULCEHRE C, CHANDAR S, CHO K, et al Dynamic neural turing machine with continuous and discrete addressing schemes[J]. Neural Computation, 2018, 30 (4): 857- 884
doi: 10.1162/neco_a_01060
|
| 55 |
SUKHBAATAR S, WESTON J, FERGUS R End-to-end memory networks[J]. Advances in Neural Information Processing Systems, 2015, 28 (18): 576- 575
|
| 56 |
TAI K S, SOCHER R, MANNING C D. Improved semantic representations from tree-structured long short-term memory networks [EB/OL]. [2015-05-30]. https:// arxiv.org/pdf/1503.00075.pdf.
|
| 57 |
TAO M, TANG H, WU F, et al. DF-GAN: a simple and effective baseline for text-to-image synthesis [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2022: 16515- 16525.
|
| 58 |
LIAO W, HU K, YANG M Y, et al. Text to image generation with semantic-spatial aware GAN [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2022: 18187-18196.
|
| 59 |
WU X, ZHAO H, ZHENG L, et al. Adma-GAN: attribute-driven memory augmented GANs for text-to-image generation [C]// Proceedings of the 30th ACM International Conference on Multimedia . Lisboa: ACM, 2022: 1593-1602.
|
| 60 |
ZHANG H, KOH J Y, BALDRIDGE J, et al. Crossmodal contrastive learning for text-to-image generation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2021: 833-842.
|
| 61 |
HUANG M, MAO Z, WANG P, et al. DSE-GAN: dynamic semantic evolution generative adversarial network for text-to-image generation [C]// Proceedings of the 30th ACM International Conference on Multimedia . Long Beach: IEEE, 2022: 4345- 4354.
|
| 62 |
BROCK A, DONAHUE J, SIMONYAN K. Large scale GAN training for high fidelity natural image synthesis [EB/OL]. [2019-02-25]. https://arxiv.org/pdf/1809.11096.pdf.
|
| 63 |
STAP D, BLEEKER M, IBRAHIMI S, et al. Conditional image generation and manipulation for user-specified content [EB/OL]. [2020-05-11]. https://arxiv.org/pdf/2005.04909.pdf.
|
| 64 |
ZHANG Y, LU H. Deep cross-modal projection learning for image-text matching [C]// Proceedings of the European Conference on Computer Vision . Long Beach: IEEE, 2018: 686-701.
|
| 65 |
LEDIG C, THEIS L, HUSZÁR F, et al. Photo-realistic single image super-resolution using a generative adversarial network [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2017: 4681-4690.
|
| 66 |
WANG H, LIN G, HOI S C H, et al. Cycle-consistent inverse GAN for text-to-image synthesis [C]// Proceedings of the 29th ACM International Conference on Multimedia . [S. l.]: ACM, 2021: 630-638.
|
| 67 |
SOUZA D M, WEHRMANN J, RUIZ D D. Efficient neural architecture for text-to-image synthesis [C]// International Joint Conference on Neural Networks . Long Beach: IEEE, 2020: 1-8.
|
| 68 |
ROMBACH R, ESSER P, OMMER B Network-to-network translation with conditional invertible neural networks[J]. Advances in Neural Information Processing Systems, 2020, 33 (18): 2784- 2797
|
| 69 |
DINH L, KRUEGER D, BENGIO Y. Nice: non-linear independent components estimation [EB/OL]. [2015-04-10]. https://arxiv.org/pdf/1410.8516.
|
| 70 |
DINH L, SOHL-DICKSTEIN J, BENGIO S. Density estimation using real nvp [EB/OL]. [2017-02-27]. https://arxiv.org/pdf/1605.08803.
|
| 71 |
WANG Z, QUAN Z, WANG Z J, et al. Text to image synthesis with bidirectional generative adversarial network [C]// IEEE International Conference on Multimedia and Expo . Long Beach: IEEE, 2020: 1-6.
|
| 72 |
DONAHUE J, KRÄHENBÜHL P, DARRELL T. Adversarial feature learning [EB/OL]. [2017-04-03]. https://arxiv.org/pdf/1605.09782.pdf.
|
| 73 |
ZHANG H, YIN W, FANG Y, et al. ERNIE-ViLG: unified generative pre-training for bidirectional vision-language generation [EB/OL]. [2023-07-01]. https://arxiv.org/abs/2112.15283.
|
| 74 |
LIU X, PARK D H, AZADI S, et al. More control for free! image synthesis with semantic diffusion guidance [C]// Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision . Long Beach: IEEE, 2023: 289-299.
|
| 75 |
SHEYNIN S, ASHUAL O, POLYAK A, et al. Knn-diffusion: image generation via large-scale retrieval [EB/OL]. [2022-10-02]. https://arxiv.org/pdf/2204.02849.
|
| 76 |
NICHOL A Q, DHARIWAL P, RAMESH A, et al. GLIDE: towards photorealistic image generation and editing with text-guided diffusion models [C]// International Conference on Machine Learning . Long Beach: IEEE, 2022: 16784-16804.
|
| 77 |
RAMESH A, DHARIWAL P, NICHOL A, et al. Hierarchical text-conditional image generation with clip latents [EB/OL]. [2022-04-13]. https://arxiv.org/pdf/2204.06125.
|
| 78 |
SAHARIA C, CHAN W, SAXENA S, et al Photorealistic text-to-image diffusion models with deep language understanding[J]. Advances in Neural Information Processing Systems, 2022, 35 (18): 36479- 36494
|
| 79 |
ROMBACH R, BLATTMANN A, LORENZ D, et al. High-resolution image synthesis with latent diffusion models [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2022: 10684-10695.
|
| 80 |
RUIZ N, LI Y, JAMPANI V, et al. Dreambooth: fine tuning text-to-image diffusion models for subject-driven generation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2023: 22500-22510.
|
| 81 |
ZHANG L, AGRAWALA M. Adding conditional control to text-to-image diffusion models [EB/OL]. [2023-02-10]. https://arxiv.org/pdf/2302.05543.
|
| 82 |
CHEFER H, ALALUF Y, VINKER Y, et al Attend-and-excite: attention-based semantic guidance for text-to-image diffusion models[J]. ACM Transactions on Graphics, 2023, 42 (4): 1- 10
|
| 83 |
MOU C, WANG X, XIE L, et al. T2i-adapter: learning adapters to dig out more controllable ability for text-to-image diffusion models [EB/OL]. [2023-03-20]. https://arxiv.org/pdf/2302.08453.
|
| 84 |
NILSBACK M E, ZISSERMAN A. Automated flower classification over a large number of classes [C]// 6th Indian Conference on Computer Vision, Graphics and Image Processing . Long Beach: IEEE, 2008: 722-729.
|
| 85 |
WAH C, BRANSON S, WELINDER P, et al. The caltech-ucsd birds-200-2011 dataset [EB/OL]. [2023-07-06]. https://authors.library.caltech.edu/27452/1/CUB_200_2011.pdf.
|
| 86 |
GUO Y, ZHANG L, HU Y, et al. Ms-celeb-1m: a dataset and benchmark for large-scale face recognition [C]// European Conference on Computer Vision . Amsterdam: [s. n.], 2016: 87-102.
|
| 87 |
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft coco: common objects in context [C]// European Conference on Computer Vision . Zurich: [s. n.], 2014: 740-755.
|
| 88 |
FROLOV S, HINZ T, RAUE F, et al Adversarial text-to-image synthesis: a review[J]. Neural Networks, 2021, 144 (18): 187- 209
|
| 89 |
SALIMANS T, GOODFELLOW I, ZAREMBA W, et al. Improved techniques for training GANs [C]// Proceeding of the 29th Advances in Neural Information Processing Systems. Hangzhou: IEEE, 2016: 2226-2234.
|
| 90 |
HEUSEL M, RAMSAUER H, UNTERTHINER T, et al. GANs trained by a two time-scale update rule converge to a local Nash equilibrium [C]// Proceeding of the 30th Advances in Neural Information Processing Systems. Long Beach: IEEE, 2017: 6626-6637.
|
| 91 |
XU T, ZHANG P, HUANG Q, et al. AttnGAN: finegrained text to image generation with attentional generative adversarial networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2018: 1316-1324.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|