[1]
ZHU X, GOLDBERG A B, ELDAWY M, et al. A text-to-picture synthesis system for augmenting communication [C]// Proceedings of the AAAI Conference on Artificial Intelligence . British Columbia: AAAI, 2007, 7: 1590-1595.
[本文引用: 1]
[2]
REED S, AKATA Z, YAN X, et al. Generative adversarial text to image synthesis [C]// International Conference on Machine Learning . New York: ACM, 2016: 1060-1069.
[本文引用: 3]
[3]
GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al Generative adversarial networks
[J]. Communications of the ACM 2020 , 63 (11 ): 139 - 144
DOI:10.1145/3422622
[本文引用: 1]
[4]
MIRZA M, OSINDERO S. Conditional generative adversarial nets [EB/OL]. [2014-11-06]. https://arxiv.org/pdf/1411. 1784.pdf.
[本文引用: 2]
[5]
RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]// International Conference on Machine Learning . [S. l. ]: ACM, 2021: 8748-8763.
[本文引用: 1]
[6]
ISOLA P, ZHU J Y, ZHOU T, et al. Image-to-image translation with conditional adversarial networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 1125-1134.
[本文引用: 1]
[7]
ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks [C]// Proceedings of the IEEE International Conference on Computer Vision . Honolulu: IEEE, 2017: 2223-2232.
[本文引用: 1]
[8]
WANG T, ZHANG T, LIU L, et al. CannyGAN: edge-preserving image translation with disentangled features [C]// IEEE International Conference on Image Processing . Taipei: IEEE, 2019: 514-518.
[9]
ZHANG T, WILIEM A, YANG S, et al. TV-GAN: generative adversarial network based thermal to visible face recognition [C]// International Conference on Biometrics . Gold Coast: IEEE, 2018: 174-181.
[10]
ZHANG H, XU T, LI H, et al. StackGAN: text to photo-realistic image synthesis with stacked generative adversarial networks [C]// Proceedings of the IEEE International Conference on Computer Vision . Honolulu: IEEE, 2017: 5907-5915.
[本文引用: 2]
[11]
XU T, ZHANG P, HUANG Q, et al. AttnGAN: fine-grained text to image generation with attentional generative adversarial networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 1316-1324.
[本文引用: 3]
[12]
LEE D D, PHAM P, LARGMAN Y, et al. Advances in neural information processing systems 22 [R]. Long Beach: IEEE, 2009.
[本文引用: 1]
[13]
贺小峰, 毛琳, 杨大伟 文本生成图像中语义-空间特征增强算法
[J]. 大连民族大学学报 , 2022 , 24 (5 ): 401 - 406
[本文引用: 1]
HE Xiaofeng, MAO Lin, YANG Dawei Semantic-spatial feature enhancement algorithm for text-to-image generation
[J]. Journal of Dalian Minzu University 2022 , 24 (5 ): 401 - 406
[本文引用: 1]
[14]
SHI X, CHEN Z, WANG H, et al Convolutional LSTM network: a machine learning approach for precipitation nowcasting
[J]. Advances in Neural Information Processing Systems 2015 , 28 (18 ): 156 - 167
[本文引用: 1]
[15]
RAMESH A, PAVLOV M, GOH G, et al. Zero-shot text-to-image generation [C]// International Conference on Machine Learning . [S. l. ]: ACM, 2021: 8821-8831.
[本文引用: 3]
[16]
DING M, YANG Z, HONG W, et al Cogview: mastering text-to-image generation via transformers
[J]. Advances in Neural Information Processing Systems 2021 , 34 (18 ): 19822 - 19835
[本文引用: 2]
[17]
DING M, ZHENG W, HONG W, et al. Cogview2: faster and better text-to-image generation via hierarchical transformers [EB/OL]. [2022-05-27]. https://arxiv.org/pdf/2204.14217.
[本文引用: 2]
[18]
YU J, XU Y, KOH J Y, et al. Scaling autoregressive models for content-rich text-to-image generation [EB/OL]. [2022-06-22]. https://arxiv.org/pdf/2206.10789.
[本文引用: 4]
[19]
CHEN W, HU H, SAHARIA C, et al. Re-imagen: retrieval-augmented text-to-image generator [EB/OL]. [2022-11-22]. https://arxiv.org/pdf/2209.14491.
[本文引用: 3]
[20]
HO J, JAIN A, ABBEEL P Denoising diffusion probabilistic models
[J]. Advances in Neural Information Processing Systems 2020 , 33 (18 ): 6840 - 6851
[本文引用: 1]
[21]
DHARIWAL P, NICHOL A Diffusion models beat GANs on image synthesis
[J]. Advances in Neural Information Processing Systems 2021 , 34 (18 ): 8780 - 8794
[本文引用: 1]
[22]
DEVLIN J, CHANG M W, LEE K, et al. Bert: pre-training of deep bidirectional transformers for language understanding [EB/OL]. [2019-05-24]. https://arxiv.org/pdf/ 1810.04805.
[本文引用: 1]
[23]
KARRAS T, LAINE S, AILA T. A style-based generator architecture for generative adversarial networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 4401-4410.
[本文引用: 3]
[24]
REED S, AKATA Z, LEE H, et al. Learning deep representations of fine-grained visual descriptions [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 49-58.
[本文引用: 1]
[25]
ZHANG H, XU T, LI H, et al StackGAN++: realistic image synthesis with stacked generative adversarial networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence 2018 , 41 (8 ): 1947 - 1962
[本文引用: 4]
[26]
ZHANG Z, XIE Y, YANG L. Photographic text-to-image synthesis with a hierarchically-nested adversarial network [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE 2018: 6199-6208.
[本文引用: 2]
[27]
HUANG X, WANG M, GONG M. Hierarchically-fused generative adversarial network for text to realistic image synthesis [C]// 16th Conference on Computer and Robot Vision . Kingston: IEEE, 2019: 73-80.
[本文引用: 2]
[28]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770-778.
[本文引用: 1]
[29]
GAO L, CHEN D, SONG J, et al. Perceptual pyramid adversarial networks for text-to-image synthesis [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Honolulu: AAAI, 2019, 33(1): 8312-8319.
[本文引用: 2]
[30]
LAI W S, HUANG J B, AHUJA N, et al. Deep Aplacian pyramid networks for fast and accurate super-resolution [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 624-632.
[本文引用: 1]
[31]
韩爽. 基于生成对抗网络的文本到图像生成技术研究[D]. 大庆: 东北石油大学, 2022.
[本文引用: 1]
HAN Shuang. Research on text-to-image generation techniques based on generative adversarial networks [D]. Daqing: Northeast Petroleum University, 2022.
[本文引用: 1]
[32]
王家喻. 基于生成对抗网络的图像生成研究[D]. 合肥: 中国科学技术大学, 2021.
WANG Jiayu. Research on image generation based on generative adversarial networks [D]. Hefei: University of Science and Technology of China, 2021.
[33]
田枫, 孙小强, 刘芳, 等 融合双注意力与多标签的图像中文描述生成方法
[J]. 计算机系统应用 , 2021 , 30 (7 ): 32 - 40
DOI:10.15888/j.cnki.csa.008010
[本文引用: 1]
TIAN Feng, SUN Xiaoqiang, LIU Fang, et al Image caption generation method combining dual attention and multi-labels
[J]. Computer Systems and Applications 2021 , 30 (7 ): 32 - 40
DOI:10.15888/j.cnki.csa.008010
[本文引用: 1]
[34]
TAN H, LIU X, LI X, et al. Semantics-enhanced adversarial nets for text-to-image synthesis [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Long Beach: IEEE, 2019: 10501-10510.
[本文引用: 3]
[35]
HUANG W, DA XU R Y, OPPERMANN I. Realistic image generation using region-phrase attention [C]// Asian Conference on Machine Learning . Nagoya: ACM, 2019: 284-299.
[本文引用: 1]
[36]
LI B, QI X, LUKASIEWICZ T, et al. Controllable text-to-image generation [J]. Advances in Neural Information Processing Systems , 2019, 32(18): 2065-2075.
[本文引用: 2]
[37]
ZHANG Z, SCHOMAKER L DiverGAN: an efficient and effective single-stage framework for diverse text-to-image generation
[J]. Neurocomputing 2022 , 473 (18 ): 182 - 198
[本文引用: 3]
[38]
YIN G, LIU B, SHENG L, et al. Semantics disentangling for text-to-image generation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 2327-2336.
[本文引用: 2]
[39]
HADSELL R, CHOPRA S, LECUN Y. Dimensionality reduction by learning an invariant mapping [C]// IEEE Computer Society Conference on Computer Vision and Pattern Recognition . New York: IEEE, 2006: 1735-1742.
[本文引用: 1]
[40]
CHEN Z, LUO Y. Cycle-consistent diverse image synthesis from natural language [C]// IEEE International Conference on Multimedia and Expo Workshops . Shanghai: IEEE, 2019: 459-464.
[本文引用: 1]
[41]
QIAO T, ZHANG J, XU D, et al. MirrorGAN: learning text-to-image generation by redescription [C]/ /Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 1505-1514.
[本文引用: 3]
[42]
KARPATHY A, FEI-FEI L. Deep visual-semantic alignments for generating image descriptions [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2015: 3128-3137.
[本文引用: 1]
[43]
VINYALS O, TOSHEV A, BENGIO S, et al. Show and tell: a neural image caption generator [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2015: 3156-3164.
[本文引用: 1]
[44]
DUMOULIN V, BELGHAZI I, POOLE B, et al. Adversarially learned inference [EB/OL]. [2017-02-21]. https://arxiv.org/pdf/1606.00704.pdf.
[本文引用: 1]
[45]
LAO Q, HAVAEI M, PESARANGHADER A, et al. Dual adversarial inference for text-to-image synthesis [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Long Beach: IEEE, 2019: 7567-7576.
[本文引用: 2]
[46]
王蕾. 基于关联语义挖掘的文本生成图像算法研究[D]. 西安: 西安电子科技大学, 2020.
[本文引用: 1]
WANG Lei. Research on text-to-image generation algorithm based on semantic association mining [D]. Xi’an: Xidian University, 2020.
[本文引用: 1]
[47]
吕文涵, 车进, 赵泽纬. 等. 基于动态卷积与文本数据增强的图像生成方法[EB/OL]. [2023-07-01]. https://kns.cnki.net/kcms2/article/abstract?v=sSXGFc3NEDIAReRhgp48uNl5G2T_5G24IJmVa17AFT4XZFr932Jmsa2EZrM7rxoIWSwHni_2CiKpa4phSwe9hcwvepEs3fO1pcWCTfWKZ7gIU_jFpQgmgw==&uniplatform=NZKPT.
[48]
薛志杭, 许喆铭, 郎丛妍, 等. 基于图像-文本语义一致性的文本生成图像方法[J]. 计算机研究与发展, 2023, 60(9): 2180-2190.
XUE Zhihang, XU Zheming, LANG Congyan, et al. Text-to-image generation method based on image-text semantic consistency [J]. Journal of Computer Research and Development , 2023, 60(9): 2180-2190.
[50]
王威, 李玉洁, 郭富林, 等. 生成对抗网络及其文本图像合成综述[J]. 计算机工程与应用, 2022, 58(19): 14-36.
WANG Wei, LI Yujie, GUO Fulin, et al. A survey on generative adversarial networks and text-image synthesis [J]. Computer Engineering and Applications , 2012, 58(19): 14-36.
[51]
李欣炜. 基于多深度神经网络的文本生成图像研究[D]. 大连: 大连理工大学, 2022.
LI Xinwei. Research on text-generated image based on multi-deep neural network [D]. Dalian: Dalian University of Technology, 2022.
[52]
叶龙, 王正勇, 何小海. 基于多模态融合的文本生成图像[J]. 智能计算机与应用, 2022, 12(11): 9-17.
[本文引用: 1]
YE Long, WANG Zhengyong, HE Xiaohai. Image generation from text based on multi-modal fusion [J]. Intelligent Computer and Application , 2012, 12(11): 9-17.
[本文引用: 1]
[53]
ZHU M, PAN P, CHEN W, et al. Dm-GAN: dynamic memory generative adversarial networks for text-to-image synthesis [C]/ /Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 5802-5810.
[本文引用: 2]
[54]
GULCEHRE C, CHANDAR S, CHO K, et al Dynamic neural turing machine with continuous and discrete addressing schemes
[J]. Neural Computation 2018 , 30 (4 ): 857 - 884
DOI:10.1162/neco_a_01060
[本文引用: 1]
[55]
SUKHBAATAR S, WESTON J, FERGUS R End-to-end memory networks
[J]. Advances in Neural Information Processing Systems 2015 , 28 (18 ): 576 - 575
[56]
TAI K S, SOCHER R, MANNING C D. Improved semantic representations from tree-structured long short-term memory networks [EB/OL]. [2015-05-30]. https:// arxiv.org/pdf/1503.00075.pdf.
[本文引用: 1]
[57]
TAO M, TANG H, WU F, et al. DF-GAN: a simple and effective baseline for text-to-image synthesis [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2022: 16515- 16525.
[本文引用: 2]
[58]
LIAO W, HU K, YANG M Y, et al. Text to image generation with semantic-spatial aware GAN [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2022: 18187-18196.
[本文引用: 2]
[59]
WU X, ZHAO H, ZHENG L, et al. Adma-GAN: attribute-driven memory augmented GANs for text-to-image generation [C]// Proceedings of the 30th ACM International Conference on Multimedia . Lisboa: ACM, 2022: 1593-1602.
[本文引用: 2]
[60]
ZHANG H, KOH J Y, BALDRIDGE J, et al. Crossmodal contrastive learning for text-to-image generation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2021: 833-842.
[本文引用: 2]
[61]
HUANG M, MAO Z, WANG P, et al. DSE-GAN: dynamic semantic evolution generative adversarial network for text-to-image generation [C]// Proceedings of the 30th ACM International Conference on Multimedia . Long Beach: IEEE, 2022: 4345- 4354.
[本文引用: 2]
[62]
BROCK A, DONAHUE J, SIMONYAN K. Large scale GAN training for high fidelity natural image synthesis [EB/OL]. [2019-02-25]. https://arxiv.org/pdf/1809.11096.pdf.
[本文引用: 2]
[63]
STAP D, BLEEKER M, IBRAHIMI S, et al. Conditional image generation and manipulation for user-specified content [EB/OL]. [2020-05-11]. https://arxiv.org/pdf/2005.04909.pdf.
[本文引用: 2]
[64]
ZHANG Y, LU H. Deep cross-modal projection learning for image-text matching [C]// Proceedings of the European Conference on Computer Vision . Long Beach: IEEE, 2018: 686-701.
[本文引用: 1]
[65]
LEDIG C, THEIS L, HUSZÁR F, et al. Photo-realistic single image super-resolution using a generative adversarial network [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2017: 4681-4690.
[本文引用: 1]
[66]
WANG H, LIN G, HOI S C H, et al. Cycle-consistent inverse GAN for text-to-image synthesis [C]// Proceedings of the 29th ACM International Conference on Multimedia . [S. l.]: ACM, 2021: 630-638.
[本文引用: 2]
[67]
SOUZA D M, WEHRMANN J, RUIZ D D. Efficient neural architecture for text-to-image synthesis [C]// International Joint Conference on Neural Networks . Long Beach: IEEE, 2020: 1-8.
[本文引用: 2]
[68]
ROMBACH R, ESSER P, OMMER B Network-to-network translation with conditional invertible neural networks
[J]. Advances in Neural Information Processing Systems 2020 , 33 (18 ): 2784 - 2797
[本文引用: 1]
[69]
DINH L, KRUEGER D, BENGIO Y. Nice: non-linear independent components estimation [EB/OL]. [2015-04-10]. https://arxiv.org/pdf/1410.8516.
[本文引用: 1]
[70]
DINH L, SOHL-DICKSTEIN J, BENGIO S. Density estimation using real nvp [EB/OL]. [2017-02-27]. https://arxiv.org/pdf/1605.08803.
[本文引用: 1]
[71]
WANG Z, QUAN Z, WANG Z J, et al. Text to image synthesis with bidirectional generative adversarial network [C]// IEEE International Conference on Multimedia and Expo . Long Beach: IEEE, 2020: 1-6.
[本文引用: 2]
[72]
DONAHUE J, KRÄHENBÜHL P, DARRELL T. Adversarial feature learning [EB/OL]. [2017-04-03]. https://arxiv.org/pdf/1605.09782.pdf.
[本文引用: 1]
[73]
ZHANG H, YIN W, FANG Y, et al. ERNIE-ViLG: unified generative pre-training for bidirectional vision-language generation [EB/OL]. [2023-07-01]. https://arxiv.org/abs/2112.15283.
[本文引用: 2]
[74]
LIU X, PARK D H, AZADI S, et al. More control for free! image synthesis with semantic diffusion guidance [C]// Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision . Long Beach: IEEE, 2023: 289-299.
[本文引用: 1]
[75]
SHEYNIN S, ASHUAL O, POLYAK A, et al. Knn-diffusion: image generation via large-scale retrieval [EB/OL]. [2022-10-02]. https://arxiv.org/pdf/2204.02849.
[本文引用: 2]
[76]
NICHOL A Q, DHARIWAL P, RAMESH A, et al. GLIDE: towards photorealistic image generation and editing with text-guided diffusion models [C]// International Conference on Machine Learning . Long Beach: IEEE, 2022: 16784-16804.
[本文引用: 2]
[77]
RAMESH A, DHARIWAL P, NICHOL A, et al. Hierarchical text-conditional image generation with clip latents [EB/OL]. [2022-04-13]. https://arxiv.org/pdf/2204.06125.
[本文引用: 2]
[78]
SAHARIA C, CHAN W, SAXENA S, et al Photorealistic text-to-image diffusion models with deep language understanding
[J]. Advances in Neural Information Processing Systems 2022 , 35 (18 ): 36479 - 36494
[本文引用: 2]
[79]
ROMBACH R, BLATTMANN A, LORENZ D, et al. High-resolution image synthesis with latent diffusion models [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2022: 10684-10695.
[本文引用: 2]
[80]
RUIZ N, LI Y, JAMPANI V, et al. Dreambooth: fine tuning text-to-image diffusion models for subject-driven generation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2023: 22500-22510.
[本文引用: 1]
[81]
ZHANG L, AGRAWALA M. Adding conditional control to text-to-image diffusion models [EB/OL]. [2023-02-10]. https://arxiv.org/pdf/2302.05543.
[82]
CHEFER H, ALALUF Y, VINKER Y, et al Attend-and-excite: attention-based semantic guidance for text-to-image diffusion models
[J]. ACM Transactions on Graphics 2023 , 42 (4 ): 1 - 10
[83]
MOU C, WANG X, XIE L, et al. T2i-adapter: learning adapters to dig out more controllable ability for text-to-image diffusion models [EB/OL]. [2023-03-20]. https://arxiv.org/pdf/2302.08453.
[本文引用: 1]
[84]
NILSBACK M E, ZISSERMAN A. Automated flower classification over a large number of classes [C]// 6th Indian Conference on Computer Vision, Graphics and Image Processing . Long Beach: IEEE, 2008: 722-729.
[本文引用: 1]
[85]
WAH C, BRANSON S, WELINDER P, et al. The caltech-ucsd birds-200-2011 dataset [EB/OL]. [2023-07-06]. https://authors.library.caltech.edu/27452/1/CUB_200_2011.pdf.
[本文引用: 1]
[86]
GUO Y, ZHANG L, HU Y, et al. Ms-celeb-1m: a dataset and benchmark for large-scale face recognition [C]// European Conference on Computer Vision . Amsterdam: [s. n.], 2016: 87-102.
[本文引用: 1]
[87]
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft coco: common objects in context [C]// European Conference on Computer Vision . Zurich: [s. n.], 2014: 740-755.
[本文引用: 1]
[88]
FROLOV S, HINZ T, RAUE F, et al Adversarial text-to-image synthesis: a review
[J]. Neural Networks 2021 , 144 (18 ): 187 - 209
[本文引用: 1]
[89]
SALIMANS T, GOODFELLOW I, ZAREMBA W, et al. Improved techniques for training GANs [C]// Proceeding of the 29th Advances in Neural Information Processing Systems. Hangzhou: IEEE, 2016: 2226-2234.
[本文引用: 1]
[90]
HEUSEL M, RAMSAUER H, UNTERTHINER T, et al. GANs trained by a two time-scale update rule converge to a local Nash equilibrium [C]// Proceeding of the 30th Advances in Neural Information Processing Systems. Long Beach: IEEE, 2017: 6626-6637.
[本文引用: 1]
[91]
XU T, ZHANG P, HUANG Q, et al. AttnGAN: finegrained text to image generation with attentional generative adversarial networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2018: 1316-1324.
[本文引用: 1]
[92]
YUAN M, PENG Y Bridge-GAN: interpretable representation learning for text-to-image synthesis
[J]. IEEE Transactions on Circuits and Systems for Video Technology 2019 , 30 (11 ): 4258 - 4268
[本文引用: 1]
1
... 文本生成图像是指输入一段文字描述,由计算机生成一张或多张相关描述的图. 在早期,当人们需要文本描述获取相应的图像时,更多关注的是信息的检索和遍历,即从已经存在的图像中找到合适的内容. Zhu等[1 ] 提出文字到图片(text-to-picture)的合成系统,通过句中关键字从谷歌图片中检索出最相关的前15张图像,利用文字和图像之间的相关性筛选出最可能的图像. 真正意义上的文本生成图像方法由Reed等[2 ] 借助生成对抗网络[3 ] (generative adversarial network,GAN)实现,该方法将脑海中想象的画面转变为现实图像,与之前检索图像的方法相比,这是更加高级的表现形态. 文本生成图像领域中的工作旨在建立图像空间和文本语义空间之间的可解释映射,将文字低维语义信息转换为高维图像信息,是具有挑战性的跨模态任务. 文本生成图像任务技术的进步标志着计算机视觉和自然语言处理领域的交叉融合趋势,为进一步探索和创新提供了新的方向. 文本生成图像任务的前景充满希望,为其他领域的多模态融合提供了创新思路,为AIGC领域带来了新的可能性. ...
3
... 文本生成图像是指输入一段文字描述,由计算机生成一张或多张相关描述的图. 在早期,当人们需要文本描述获取相应的图像时,更多关注的是信息的检索和遍历,即从已经存在的图像中找到合适的内容. Zhu等[1 ] 提出文字到图片(text-to-picture)的合成系统,通过句中关键字从谷歌图片中检索出最相关的前15张图像,利用文字和图像之间的相关性筛选出最可能的图像. 真正意义上的文本生成图像方法由Reed等[2 ] 借助生成对抗网络[3 ] (generative adversarial network,GAN)实现,该方法将脑海中想象的画面转变为现实图像,与之前检索图像的方法相比,这是更加高级的表现形态. 文本生成图像领域中的工作旨在建立图像空间和文本语义空间之间的可解释映射,将文字低维语义信息转换为高维图像信息,是具有挑战性的跨模态任务. 文本生成图像任务技术的进步标志着计算机视觉和自然语言处理领域的交叉融合趋势,为进一步探索和创新提供了新的方向. 文本生成图像任务的前景充满希望,为其他领域的多模态融合提供了创新思路,为AIGC领域带来了新的可能性. ...
... CGAN模型在极大程度上满足了不同任务的基本需求,有很多在不同任务场景下基于CGAN模型的新方法[6 -11 ] 不断被提出. 在文本生成图像任务中,最早GAN-INT-CLS[2 ] 方法采用CGAN模型,在生成器和判别器中引入文本描述,使GAN-INT-CLS方法可以通过文本描述指导图像的生成过程,如图1 (b) 所示. AttnGAN[11 ] 方法发现,单一的CGAN模型无法保证生成的图像质量,所以自AttnGAN方法起,基于GAN架构的文本生成图像方法损失函数都加入了CGAN损失函数. 在文本生成图像任务中,CGAN的生成器损失函数$ L_G^\text{con} $ $ L_D^\text{con} $
... Comparison of various metrics for GAN-based text-to-image generation methods on different datasets
Tab.1 方法 CUB鸟类数据集 Oxford-120花卉数据集 COCO数据集 IS FID R-precision IS FID IS FID R-precision GAN-INT-CLS[2 ] 2.32 68.79 — 2.66 79.55 7.95 60.62 — StackGAN[10 ] 3.70 51.89 — 3.20 55.28 8.45 74.65 — StackGAN++[25 ] 4.04 15.30 — 3.26 48.68 8.30 — — AttnGAN[11 ] 4.36 23.98 67.83 — — 25.89 35.49 85.47 DM-GAN[53 ] 4.75 16.09 72.31 — — 30.49 32.62 88.56 ControlGAN[36 ] 4.58 — 39.33 — — 24.06 — 82.43 SEGAN[34 ] 4.67 18.16 — — — 27.86 32.28 — MirrorGAN[41 ] 4.56 — 57.67 — — 26.47 — 74.52 XMC-GAN[60 ] — — — — — 30.45 9.33 71.00 CI-GAN[66 ] 5.72 9.78 — — — — — — DF-GAN[57 ] 5.10 14.81 44.83 — — — 21.42 67.97 DiverGAN[37 ] 4.98 15.63 — 3.99 — — 20.52 — SSA-GAN[58 ] 5.17 15.61 75.9 — — — 19.37 90.60 Adam-GAN[59 ] 5.28 8.57 55.94 — — 29.07 12.39 88.74 TVBi-GAN[71 ] 5.03 11.83 — — — 31.01 31.97 — 文献[67 ]方法 4.23 11.17 — 3.71 16.47 — — — Bridge-GAN[92 ] 4.74 — — — — 16.40 — — textStyleGAN[63 ] 4.78 — 49.56 — — 33.00 — 88.23 文献[45 ]方法 3.58 18.14 — 2.90 34.97 8.94 27.07 — SD-GAN[38 ] 4.67 — — — — 35.69 — — PPAN[29 ] 4.38 — — 3.52 — — — — HfGAN[27 ] 4.48 — — 3.57 — 27.53 — — HDGAN[26 ] 4.15 — — 3.45 — 11.86 — — DSE-GAN[61 ] 5.13 13.23 53.25 — — 26.71 15.30 76.31
由于采用自回归模型和扩散模型的文本生成图像方法比采用GAN的文本生成图像方法性能优异,采用自回归模型和扩散模型的文本生成图像方法更换了新的评价指标. 如表2 所示,采用自回归模型和扩散模型的方法,在MS-COCO数据集上对FID评价指标及Zero-shot FID评价指标进行评判,这些评价指标仅在某种程度上反映各个模型的性能高低. 对于文本生成图像任务,人工评判生成图像的质量以及文本与图像的语义一致性有更高的可信度,但由于人工评价指标不统一、个人评价意见不统一,人工评判不能作为定性评价文本生成图像模型的标准. ...
Generative adversarial networks
1
2020
... 文本生成图像是指输入一段文字描述,由计算机生成一张或多张相关描述的图. 在早期,当人们需要文本描述获取相应的图像时,更多关注的是信息的检索和遍历,即从已经存在的图像中找到合适的内容. Zhu等[1 ] 提出文字到图片(text-to-picture)的合成系统,通过句中关键字从谷歌图片中检索出最相关的前15张图像,利用文字和图像之间的相关性筛选出最可能的图像. 真正意义上的文本生成图像方法由Reed等[2 ] 借助生成对抗网络[3 ] (generative adversarial network,GAN)实现,该方法将脑海中想象的画面转变为现实图像,与之前检索图像的方法相比,这是更加高级的表现形态. 文本生成图像领域中的工作旨在建立图像空间和文本语义空间之间的可解释映射,将文字低维语义信息转换为高维图像信息,是具有挑战性的跨模态任务. 文本生成图像任务技术的进步标志着计算机视觉和自然语言处理领域的交叉融合趋势,为进一步探索和创新提供了新的方向. 文本生成图像任务的前景充满希望,为其他领域的多模态融合提供了创新思路,为AIGC领域带来了新的可能性. ...
2
... 对文本生成图像领域的方法所采用的基础网络架构进行概述,包括基于GAN的文本生成图像方法普遍采用的GAN模型、条件生成对抗网络[4 ] (conditional generative adversarial network,CGAN)和自编码器架构、基于自回归模型架构的方法所采用的AR模型架构和对比模型[5 ] (contrastive language-image pre-training, CLIP)、基于扩散模型架构生成图像方法所采用的扩散模型架构. ...
... 式中:$ \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{x} $ $ x $ $ E[ \cdot ] $ ${P_{{G}}}$ ${P_{\text{data}}}$ [4 ] . ...
1
... 对文本生成图像领域的方法所采用的基础网络架构进行概述,包括基于GAN的文本生成图像方法普遍采用的GAN模型、条件生成对抗网络[4 ] (conditional generative adversarial network,CGAN)和自编码器架构、基于自回归模型架构的方法所采用的AR模型架构和对比模型[5 ] (contrastive language-image pre-training, CLIP)、基于扩散模型架构生成图像方法所采用的扩散模型架构. ...
1
... CGAN模型在极大程度上满足了不同任务的基本需求,有很多在不同任务场景下基于CGAN模型的新方法[6 -11 ] 不断被提出. 在文本生成图像任务中,最早GAN-INT-CLS[2 ] 方法采用CGAN模型,在生成器和判别器中引入文本描述,使GAN-INT-CLS方法可以通过文本描述指导图像的生成过程,如图1 (b) 所示. AttnGAN[11 ] 方法发现,单一的CGAN模型无法保证生成的图像质量,所以自AttnGAN方法起,基于GAN架构的文本生成图像方法损失函数都加入了CGAN损失函数. 在文本生成图像任务中,CGAN的生成器损失函数$ L_G^\text{con} $ $ L_D^\text{con} $
1
... 文本生成图像与图像生成文字被看作是一对相互的任务,受CycleGAN[7 ] 的启发,循环一致性文本生成图像的任务通过重新描述架构[40 -41 ] ,即在生成图像网络后附加生成图像标题的网络,学习文本和图像之间的语义一致性表示,提升输入文本和根据合成图像再生成的文本描述之间的相似性,促使神经网络能够更好地理解并融合文字特征和图像特征,提高网络学习到的文字特征和图像特征的一致性. 该类方法采用的模型大多是文本特征提取网络加图像生成网络,再加入字幕生成网络,网络结构复杂,需要设计精密的整体网络模型和损失函数,该类改进方法有巨大的改进空间. ...
2
... 为了解决GAN-INT-CLS低分辨率的问题,Zhang等[10 ] 提出StackGAN模型,该方法用2个层次嵌套的GAN网络,提升了分辨率. 第1阶段在给定随机噪声向量和文本条件向量的情况下生成64×64像素的粗图像. 将初始图像和嵌入的文本输入到第2个生成器,该生成器输出256×256像素的图像. 在该方法中提出条件增强(conditioning augmentation,CA)技术,将文本特征输入到独立的高斯分布中进行随机采样,得到隐含变量,再将隐含变量作为生成图像的条件输入生成网络中生成图像. 由于高斯分布是连续且独立的,很大程度上解决了由于文本数据有限而造成的特征空间不连续的问题,被往后的文本生成图像方法普遍应用. ...
... Comparison of various metrics for GAN-based text-to-image generation methods on different datasets
Tab.1 方法 CUB鸟类数据集 Oxford-120花卉数据集 COCO数据集 IS FID R-precision IS FID IS FID R-precision GAN-INT-CLS[2 ] 2.32 68.79 — 2.66 79.55 7.95 60.62 — StackGAN[10 ] 3.70 51.89 — 3.20 55.28 8.45 74.65 — StackGAN++[25 ] 4.04 15.30 — 3.26 48.68 8.30 — — AttnGAN[11 ] 4.36 23.98 67.83 — — 25.89 35.49 85.47 DM-GAN[53 ] 4.75 16.09 72.31 — — 30.49 32.62 88.56 ControlGAN[36 ] 4.58 — 39.33 — — 24.06 — 82.43 SEGAN[34 ] 4.67 18.16 — — — 27.86 32.28 — MirrorGAN[41 ] 4.56 — 57.67 — — 26.47 — 74.52 XMC-GAN[60 ] — — — — — 30.45 9.33 71.00 CI-GAN[66 ] 5.72 9.78 — — — — — — DF-GAN[57 ] 5.10 14.81 44.83 — — — 21.42 67.97 DiverGAN[37 ] 4.98 15.63 — 3.99 — — 20.52 — SSA-GAN[58 ] 5.17 15.61 75.9 — — — 19.37 90.60 Adam-GAN[59 ] 5.28 8.57 55.94 — — 29.07 12.39 88.74 TVBi-GAN[71 ] 5.03 11.83 — — — 31.01 31.97 — 文献[67 ]方法 4.23 11.17 — 3.71 16.47 — — — Bridge-GAN[92 ] 4.74 — — — — 16.40 — — textStyleGAN[63 ] 4.78 — 49.56 — — 33.00 — 88.23 文献[45 ]方法 3.58 18.14 — 2.90 34.97 8.94 27.07 — SD-GAN[38 ] 4.67 — — — — 35.69 — — PPAN[29 ] 4.38 — — 3.52 — — — — HfGAN[27 ] 4.48 — — 3.57 — 27.53 — — HDGAN[26 ] 4.15 — — 3.45 — 11.86 — — DSE-GAN[61 ] 5.13 13.23 53.25 — — 26.71 15.30 76.31
由于采用自回归模型和扩散模型的文本生成图像方法比采用GAN的文本生成图像方法性能优异,采用自回归模型和扩散模型的文本生成图像方法更换了新的评价指标. 如表2 所示,采用自回归模型和扩散模型的方法,在MS-COCO数据集上对FID评价指标及Zero-shot FID评价指标进行评判,这些评价指标仅在某种程度上反映各个模型的性能高低. 对于文本生成图像任务,人工评判生成图像的质量以及文本与图像的语义一致性有更高的可信度,但由于人工评价指标不统一、个人评价意见不统一,人工评判不能作为定性评价文本生成图像模型的标准. ...
3
... CGAN模型在极大程度上满足了不同任务的基本需求,有很多在不同任务场景下基于CGAN模型的新方法[6 -11 ] 不断被提出. 在文本生成图像任务中,最早GAN-INT-CLS[2 ] 方法采用CGAN模型,在生成器和判别器中引入文本描述,使GAN-INT-CLS方法可以通过文本描述指导图像的生成过程,如图1 (b) 所示. AttnGAN[11 ] 方法发现,单一的CGAN模型无法保证生成的图像质量,所以自AttnGAN方法起,基于GAN架构的文本生成图像方法损失函数都加入了CGAN损失函数. 在文本生成图像任务中,CGAN的生成器损失函数$ L_G^\text{con} $ $ L_D^\text{con} $
... [11 ]方法发现,单一的CGAN模型无法保证生成的图像质量,所以自AttnGAN方法起,基于GAN架构的文本生成图像方法损失函数都加入了CGAN损失函数. 在文本生成图像任务中,CGAN的生成器损失函数$ L_G^\text{con} $ $ L_D^\text{con} $
... Comparison of various metrics for GAN-based text-to-image generation methods on different datasets
Tab.1 方法 CUB鸟类数据集 Oxford-120花卉数据集 COCO数据集 IS FID R-precision IS FID IS FID R-precision GAN-INT-CLS[2 ] 2.32 68.79 — 2.66 79.55 7.95 60.62 — StackGAN[10 ] 3.70 51.89 — 3.20 55.28 8.45 74.65 — StackGAN++[25 ] 4.04 15.30 — 3.26 48.68 8.30 — — AttnGAN[11 ] 4.36 23.98 67.83 — — 25.89 35.49 85.47 DM-GAN[53 ] 4.75 16.09 72.31 — — 30.49 32.62 88.56 ControlGAN[36 ] 4.58 — 39.33 — — 24.06 — 82.43 SEGAN[34 ] 4.67 18.16 — — — 27.86 32.28 — MirrorGAN[41 ] 4.56 — 57.67 — — 26.47 — 74.52 XMC-GAN[60 ] — — — — — 30.45 9.33 71.00 CI-GAN[66 ] 5.72 9.78 — — — — — — DF-GAN[57 ] 5.10 14.81 44.83 — — — 21.42 67.97 DiverGAN[37 ] 4.98 15.63 — 3.99 — — 20.52 — SSA-GAN[58 ] 5.17 15.61 75.9 — — — 19.37 90.60 Adam-GAN[59 ] 5.28 8.57 55.94 — — 29.07 12.39 88.74 TVBi-GAN[71 ] 5.03 11.83 — — — 31.01 31.97 — 文献[67 ]方法 4.23 11.17 — 3.71 16.47 — — — Bridge-GAN[92 ] 4.74 — — — — 16.40 — — textStyleGAN[63 ] 4.78 — 49.56 — — 33.00 — 88.23 文献[45 ]方法 3.58 18.14 — 2.90 34.97 8.94 27.07 — SD-GAN[38 ] 4.67 — — — — 35.69 — — PPAN[29 ] 4.38 — — 3.52 — — — — HfGAN[27 ] 4.48 — — 3.57 — 27.53 — — HDGAN[26 ] 4.15 — — 3.45 — 11.86 — — DSE-GAN[61 ] 5.13 13.23 53.25 — — 26.71 15.30 76.31
由于采用自回归模型和扩散模型的文本生成图像方法比采用GAN的文本生成图像方法性能优异,采用自回归模型和扩散模型的文本生成图像方法更换了新的评价指标. 如表2 所示,采用自回归模型和扩散模型的方法,在MS-COCO数据集上对FID评价指标及Zero-shot FID评价指标进行评判,这些评价指标仅在某种程度上反映各个模型的性能高低. 对于文本生成图像任务,人工评判生成图像的质量以及文本与图像的语义一致性有更高的可信度,但由于人工评价指标不统一、个人评价意见不统一,人工评判不能作为定性评价文本生成图像模型的标准. ...
1
... 自编码器(auto-encoder,AE)是根据数据底层信息特征进行新数据生成的编码器-解码器模型对. 这种模型的典型架构包括2个子网络:编码器(encoder)和解码器(decoder). 编码器将输入的数据编码成若干向量,以描述潜在的低维特征信息,解码器的作用是将特征变量还原为原始数据的维度. 自编码器提取目标特征向量以及将特征向量还原为数据的能力,使自编码器被广泛用于提取数据底层信息及生成图像的工作[12 -13 ] . ...
文本生成图像中语义-空间特征增强算法
1
2022
... 自编码器(auto-encoder,AE)是根据数据底层信息特征进行新数据生成的编码器-解码器模型对. 这种模型的典型架构包括2个子网络:编码器(encoder)和解码器(decoder). 编码器将输入的数据编码成若干向量,以描述潜在的低维特征信息,解码器的作用是将特征变量还原为原始数据的维度. 自编码器提取目标特征向量以及将特征向量还原为数据的能力,使自编码器被广泛用于提取数据底层信息及生成图像的工作[12 -13 ] . ...
文本生成图像中语义-空间特征增强算法
1
2022
... 自编码器(auto-encoder,AE)是根据数据底层信息特征进行新数据生成的编码器-解码器模型对. 这种模型的典型架构包括2个子网络:编码器(encoder)和解码器(decoder). 编码器将输入的数据编码成若干向量,以描述潜在的低维特征信息,解码器的作用是将特征变量还原为原始数据的维度. 自编码器提取目标特征向量以及将特征向量还原为数据的能力,使自编码器被广泛用于提取数据底层信息及生成图像的工作[12 -13 ] . ...
Convolutional LSTM network: a machine learning approach for precipitation nowcasting
1
2015
... 在文本生成图像方法中,通常采用编码器提取图像特征和文本特征. 在该领域中,最早是GAN-INT-CLS方法将LSTM[14 ] 作为文本编码器提取文本特征,该方法也是最早采用图像自编码器作为GAN的生成器生成图像的文本生成图像方法,如图2 所示. ...
3
... 对比模型是OpenAI 公司在2021年初提出的用于匹配文本和图像的多模态的预训练神经网络模型. 该模型的推出在一定程度上解决了文本生成图像任务中2个模态对齐的问题,通过在4亿个图像文本对上训练,使得CLIP获得了极强的鲁棒性和泛化能力. 基于自回归模型架构和扩散模型的大部分文本生成图像方法[15 -18 ] 都使用CLIP,取得了优异的效果. 具体的CLIP学习流程如图3 所示. 通过预训练对比模型,将文本和图像送入对应的编码器中提取特征向量,在多模态空间中比较计算文本特征和图像特征的相似度,使模型学习到文本与图像的特征. 通过标签文本创建数据集分类器,将数据集的所有类别都转换为文本,例如A photo of a dog,将这些文本编码得到文本向量. 零样本预测中将需要分类的图像进行图像编码,计算图像向量和文本向量的评分,与图像越相近的文本评分越高. ...
... 在2.5亿个文本图像对上,通过120亿参数模型的训练,OpenAI公司在2021年发布了DALL-E[15 ] 模型. 得益于该模型的精妙设计与庞大的训练数据,DALL-E模型生成图像的质量和速度彻底超越了当时已有的文本生成图像的任务. 自此,文本生成图像任务开始频繁应用于各行各业中,基于DALL-E模型的各类改进方法开始不断涌现. ...
... Comparison of text-to-image generation methods based on autoregressive model architecture and diffusion model architecture
Tab.2 方法 MS-COCO数据集 FID Zero-shot FID DALL-E[15 ] — 28.0 ERNIE-ViLG[73 ] — 14.7 CogView [16 ] — 27.1 CogView2[17 ] 17.7 24.0 Parti[18 ] 3.22 7.23 KNN-Diffusion[75 ] 16.66 — GLIDE[76 ] — 12.24 DALL-E 2[77 ] — 10.39 Imagen[78 ] — 7.27 Stable Diffusion[79 ] — 12.63 Re-Imagen[19 ] 5.25 6.88
5. 结 语 本文介绍了近年来各类文本生成图像方法、数据集和评价指标,探讨了当前本领域所面临的挑战. 将文本生成图像现有方法划分为以下3类:基于生成对抗网络、自回归模型和扩散模型的方法. 将基于生成对抗网络的方法归类为6个方面的技术改进总结. 详细分析了各种方法,使用常见的评估方法评价这些方法. ...
Cogview: mastering text-to-image generation via transformers
2
2021
... 尽管采用自回归模型进行文本生成图像任务已经取得了很好的成绩,但如何在一般领域采用可泛化的模型是待解决的问题. CogView[16 ] 在文本生成图像的领域和其他领域中展现出极强的能力,将生成与理解自然语言任务中基于注意力模型的自回归方法扩展到生成高质量图像任务. 如图16 所示,该方法将文本信息转换为文本特征向量,再将图像输入到离散化的AE中提取图像特征向量. 将文本特征向量和图像特征向量拼接后输入到注意力模型Transformer(GPT)中,学习图像与文本之间的关联,通过解码器生成图像后,对生成图像进行打分,选出最匹配的结果. 在CogView中,对比了多种将图像转化为图像特征的方法,在维护训练过程中提出了很多技巧. 利用该方法能够生成高质量且符合文本描述的图像,在图像的超分辨率重建和图像风格学习生成任务上取得了优异的成绩. 该方法的生成速度较慢,难以生成复杂的图像,易于被恶意使用. ...
... Comparison of text-to-image generation methods based on autoregressive model architecture and diffusion model architecture
Tab.2 方法 MS-COCO数据集 FID Zero-shot FID DALL-E[15 ] — 28.0 ERNIE-ViLG[73 ] — 14.7 CogView [16 ] — 27.1 CogView2[17 ] 17.7 24.0 Parti[18 ] 3.22 7.23 KNN-Diffusion[75 ] 16.66 — GLIDE[76 ] — 12.24 DALL-E 2[77 ] — 10.39 Imagen[78 ] — 7.27 Stable Diffusion[79 ] — 12.63 Re-Imagen[19 ] 5.25 6.88
5. 结 语 本文介绍了近年来各类文本生成图像方法、数据集和评价指标,探讨了当前本领域所面临的挑战. 将文本生成图像现有方法划分为以下3类:基于生成对抗网络、自回归模型和扩散模型的方法. 将基于生成对抗网络的方法归类为6个方面的技术改进总结. 详细分析了各种方法,使用常见的评估方法评价这些方法. ...
2
... 清华团队为了探索自回归模型在文本生成图像领域能否生成质量更好的图像,对CogView模型进行进一步的改进,提出CogView2[17 ] 模型. 该模型将学习图像特征和文本特征的注意力模型Transformer(GPT)更改为分层Transformer,以理解不同维度的文本信息和图像信息;分层Transformer滑动窗口的设计使得相邻维度的信息相互交互,极大地降低了整体计算复杂度,提升了生成图像的速度. 为了生成更加复杂的图像,CogView2将自回归模型和双向掩码相结合. 采用以下2种策略一起训练:1)遮挡一部分图像特征向量和全部的文本特征向量,使模型深入理解学习图像特征;2)遮挡所有的图像特征向量,学习文本特征和图像特征之间的关联. 这2种主要的改进方法比CogView 模型生成图像的质量好,在参数量剧增的基础上减少了生成图像的时间. ...
... Comparison of text-to-image generation methods based on autoregressive model architecture and diffusion model architecture
Tab.2 方法 MS-COCO数据集 FID Zero-shot FID DALL-E[15 ] — 28.0 ERNIE-ViLG[73 ] — 14.7 CogView [16 ] — 27.1 CogView2[17 ] 17.7 24.0 Parti[18 ] 3.22 7.23 KNN-Diffusion[75 ] 16.66 — GLIDE[76 ] — 12.24 DALL-E 2[77 ] — 10.39 Imagen[78 ] — 7.27 Stable Diffusion[79 ] — 12.63 Re-Imagen[19 ] 5.25 6.88
5. 结 语 本文介绍了近年来各类文本生成图像方法、数据集和评价指标,探讨了当前本领域所面临的挑战. 将文本生成图像现有方法划分为以下3类:基于生成对抗网络、自回归模型和扩散模型的方法. 将基于生成对抗网络的方法归类为6个方面的技术改进总结. 详细分析了各种方法,使用常见的评估方法评价这些方法. ...
4
... 对比模型是OpenAI 公司在2021年初提出的用于匹配文本和图像的多模态的预训练神经网络模型. 该模型的推出在一定程度上解决了文本生成图像任务中2个模态对齐的问题,通过在4亿个图像文本对上训练,使得CLIP获得了极强的鲁棒性和泛化能力. 基于自回归模型架构和扩散模型的大部分文本生成图像方法[15 -18 ] 都使用CLIP,取得了优异的效果. 具体的CLIP学习流程如图3 所示. 通过预训练对比模型,将文本和图像送入对应的编码器中提取特征向量,在多模态空间中比较计算文本特征和图像特征的相似度,使模型学习到文本与图像的特征. 通过标签文本创建数据集分类器,将数据集的所有类别都转换为文本,例如A photo of a dog,将这些文本编码得到文本向量. 零样本预测中将需要分类的图像进行图像编码,计算图像向量和文本向量的评分,与图像越相近的文本评分越高. ...
... 文本生成图像中的自回归模型是用于将文本数据转化为图像数据的模型,效果最好的是谷歌公司提出的Parti[18 ] 模型. 如图4 所示,自回归模型可以根据输入的文本描述,采用逐个像素或逐个单元的方式,生成与描述相匹配的图像. 具体而言,自回归模型在生成过程中逐步生成图像的每个像素或图像单元. 模型从文本描述开始, 根据当前生成的像素或图像单元,预测下一个像素或图像单元的值. 该预测过程可以使用循环神经网络或类似的结构来建模,其中每个时间或步骤都负责生成一个像素或图像单元. 对于每个像素位置,模型会考虑之前生成的像素和上文信息,预测当前像素的条件概率分布. 从概率分布中采样得到像素,将生成的像素作为下一个像素的输入,继续生成下一个像素,直到整个图像生成完毕. 该类方法在文本生成图像任务中搭配CLIP,生成与文本描述匹配的图像,结合2种方法,解决图像的连续性问题和图像与文本的对齐问题. ...
... 谷歌公司在采用扩散模型完成文本生成图像任务的同时,提出自回归模型Parti[18 ] ,对该任务进行再次优化生成. 研究人员设计4种不同规模的Parti,分别是3.5亿参数、7.5亿参数、30亿参数以及200亿参数的模型,用于不同场景的比较使用. 随着模型参数的增多,Parti生成的图像更加真实清晰,200亿参数的Parti甚至可以在保持高质量生成图像的基础上,在图像中加入一串特定的无意义字符,利用其他方法很难实现这样的效果. Parti生成图像的质量及对文本描述的理解能力超越了大部分模型,对于自回归模型文本生成图像方法来说,Parti模型取得了最好的成绩. ...
... Comparison of text-to-image generation methods based on autoregressive model architecture and diffusion model architecture
Tab.2 方法 MS-COCO数据集 FID Zero-shot FID DALL-E[15 ] — 28.0 ERNIE-ViLG[73 ] — 14.7 CogView [16 ] — 27.1 CogView2[17 ] 17.7 24.0 Parti[18 ] 3.22 7.23 KNN-Diffusion[75 ] 16.66 — GLIDE[76 ] — 12.24 DALL-E 2[77 ] — 10.39 Imagen[78 ] — 7.27 Stable Diffusion[79 ] — 12.63 Re-Imagen[19 ] 5.25 6.88
5. 结 语 本文介绍了近年来各类文本生成图像方法、数据集和评价指标,探讨了当前本领域所面临的挑战. 将文本生成图像现有方法划分为以下3类:基于生成对抗网络、自回归模型和扩散模型的方法. 将基于生成对抗网络的方法归类为6个方面的技术改进总结. 详细分析了各种方法,使用常见的评估方法评价这些方法. ...
3
... 扩散模型利用深层网络结构和参数学习,实现对复杂数据的建模和理解. 扩散模型学习的过程分为2步,分别是前向过程和逆向过程. 通过不断调整模型每一层的参数,最大程度地优化模型的性能,再经过逐层的传播和变换,使得扩散模型能够从原始数据中提取并学习到更抽象、更高级的特征表示. 谷歌公司提出基于扩散模型架构的Re-Imagen[19 ] 模型,即当前文本生成图像任务中效果最优异的方法. ...
... 之前的种种改进使得现有模型可以对普通物体的描述文本生成超高质量图像,但无法使这些模型生成罕见物体,它们生成图像的内容显得十分杂乱. 谷歌公司发现了这个问题,提出Re-Imagen[19 ] ,通过检索信息的方式来生成稀少物体的图像,甚至是模型从未见过的物体图像. 在该模型中,主体的生成架构延用Imagen模型. 该模型添加了额外的外部数据库用以检索相关的文本图像对,这些信息被当成文本描述的参考信息一起生成图像. 为了平衡检索到的信息和文本描述信息,该方法定义了新的采样方式,用2个不同的权重参数决定文本描述和检索信息对生成图像的影响程度.在采样时以选定的比例轮换使用2个参数,通过调节比例,平衡文本条件和检索信息的重要性. 通过一系列细节上的微调,Re-Imagen成为当前文本生成图像任务中效果最好的模型,不论是生成图像的质量还是图像与文本的一致性,Re-Imagen都取得了当前最优异的成绩. Ruiz等[80 -83 ] 采用大模型的方法,采取扩大网络模型或采用更大规模的数据集的策略以提升性能,改进不大. ...
... Comparison of text-to-image generation methods based on autoregressive model architecture and diffusion model architecture
Tab.2 方法 MS-COCO数据集 FID Zero-shot FID DALL-E[15 ] — 28.0 ERNIE-ViLG[73 ] — 14.7 CogView [16 ] — 27.1 CogView2[17 ] 17.7 24.0 Parti[18 ] 3.22 7.23 KNN-Diffusion[75 ] 16.66 — GLIDE[76 ] — 12.24 DALL-E 2[77 ] — 10.39 Imagen[78 ] — 7.27 Stable Diffusion[79 ] — 12.63 Re-Imagen[19 ] 5.25 6.88
5. 结 语 本文介绍了近年来各类文本生成图像方法、数据集和评价指标,探讨了当前本领域所面临的挑战. 将文本生成图像现有方法划分为以下3类:基于生成对抗网络、自回归模型和扩散模型的方法. 将基于生成对抗网络的方法归类为6个方面的技术改进总结. 详细分析了各种方法,使用常见的评估方法评价这些方法. ...
Denoising diffusion probabilistic models
1
2020
... 如图5 所示,扩散模型[20 ] 通过前向过程$ P\left( {\left. {{x_{t - 1}}} \right|{x_t}} \right) $ $ P\left( {\left. {{x_t}} \right|{x_{t - 1}}} \right) $
Diffusion models beat GANs on image synthesis
1
2021
... 类别引导扩散模型[21 ] (classifier guidance diffusion model)的提出,使得扩散模型更好地应用在文本生成图像方法中. 该方法在原有训练好的扩散模型基础上,添加外部的分类器来引导生成期望的图像,修改了高斯分布的均值中心,在逆向过程中期望图像逐渐靠近条件的引导. 随着类别引导扩散模型的推出,越来越多的研究者将改进的扩散模型方法应用到文本生成图像领域. 自此,扩散模型在文本生成图像领域开始飞速发展,涌现出大量的高质量文本生成图像模型. ...
1
... 如图6 所示,文本生成图像任务的核心目标是建立可解释的映射,将图像空间和文本语义空间联系起来,通过文本语义来引导图像的生成过程. 基本思想是通过训练模型来理解文本描述的含义,并与图像内容的含义对应,实现通过文本描述生成相应图像. 虽然该思想相对简单易懂,但实际上实现从文本到图像的生成仍然具有挑战性. 如图7 所示,多次关键技术的革新后,文本生成图像任务逐渐成熟. 自2007年起,该任务的方法通过词语匹配来对应图像,利用关键词检索来生成图像. 到2014年,随着CGAN模型的提出,在生成图像时引入简单的文本条件控制. 随后,注意力机制、大型文本编码器(如BERT[22 ] )网络的出现,以及2019年无条件生成图像模型StyleGAN[23 ] 的推出,使得图像的生成质量大幅提升,尤其是在随机生成超高质量图像方面. 在此后的发展中,基于GAN的文本生成图像方法通过不断改进无条件模型,取得了更加卓越的成果. 自2021年提出基于自回归模型和扩散模型的文本生成图像方法,这2种方法凭借先进的模型获得了更高的图像生成质量. 这些方法在2022年继续被拓展和优化,它们在文本生成图像领域取得了令人惊叹的成就. ...
3
... 如图6 所示,文本生成图像任务的核心目标是建立可解释的映射,将图像空间和文本语义空间联系起来,通过文本语义来引导图像的生成过程. 基本思想是通过训练模型来理解文本描述的含义,并与图像内容的含义对应,实现通过文本描述生成相应图像. 虽然该思想相对简单易懂,但实际上实现从文本到图像的生成仍然具有挑战性. 如图7 所示,多次关键技术的革新后,文本生成图像任务逐渐成熟. 自2007年起,该任务的方法通过词语匹配来对应图像,利用关键词检索来生成图像. 到2014年,随着CGAN模型的提出,在生成图像时引入简单的文本条件控制. 随后,注意力机制、大型文本编码器(如BERT[22 ] )网络的出现,以及2019年无条件生成图像模型StyleGAN[23 ] 的推出,使得图像的生成质量大幅提升,尤其是在随机生成超高质量图像方面. 在此后的发展中,基于GAN的文本生成图像方法通过不断改进无条件模型,取得了更加卓越的成果. 自2021年提出基于自回归模型和扩散模型的文本生成图像方法,这2种方法凭借先进的模型获得了更高的图像生成质量. 这些方法在2022年继续被拓展和优化,它们在文本生成图像领域取得了令人惊叹的成就. ...
... 随着无条件图像生成[23 ,62 ] 的效果越来越突出,多项工作提出将这些无条件模型的架构改进用于有条件的文本生成图像任务. 由于利用无条件图像生成方法能够生成高质量的图像,该类型的改进方法关注如何融合文字特征和图像特征以及使用图像编辑的原理,在生成的图像上按照文字描述修改图像生成. 这些改进后的文本生成图像方法普遍都具有生成图像分辨率高的优点,但是有十分明显的缺点,即使用模型架构大,训练环境要求高,训练速度慢,文字图像匹配度低. ...
... textStyleGAN[63 ] 对StyleGAN[23 ] 模型进行调整改进,使得该任务不仅保留了StyleGAN允许进行语义操作的特性,还保留了StyleGAN模型生成超高分辨率图像的优点. 如图14 所示,该方法使用预训练的图像文本匹配网络,将句子和词特征融合到图像特征中,在生成器中利用词特征和图像特征进行注意力引导. 除了判别器中的无条件和条件损失外,该方法还使用跨模态投影匹配(CMPM)和跨模态投影分类(CMPC)损失[64 ] ,引导文字与生成的图像对齐. 作为早期采用改进无条件模型的文本生成图像任务,该方法模型架构大,训练环境要求高,训练速度慢,与文本描述不能保持语义一致性. 如何克服无条件模型的随机性,更好地融合文本特征是早期改进无条件模型进行文本生成图像任务的首要改进方向. ...
1
... 首个文本生成图像的任务是由Reed等提出的 GAN-INT-CLS,通过预训练混合RNN的字符级ConvNet网络[24 ] 从文本描述中以语义向量的形式获得文本嵌入,将文本嵌入向量作为CGAN中的条件,控制图像的生成,达到文本生成图像的效果. 在该方法中所提出的2个技巧被往后的文本生成图像方法频繁使用,分别为匹配感知的判别器(GAN-CLS)和流形插值学习法(GAN-INT). ...
StackGAN++: realistic image synthesis with stacked generative adversarial networks
4
2018
... StackGAN++[25 ] 将StackGAN改进为端到端的架构,该方法嵌套了3个生成器和判别器,通过联合训练的方式,以实现近似生成多尺度、有条件和无条件图像分布的目的,如图8 (a)所示. Zhang等[25 ] 提出从平滑流形的高斯分布中抽取文本嵌入,不使用固定的文本嵌入. 为了鼓励网络学习并统一在不同尺度图像中的基本结构和颜色,Zhang等[25 ] 还提出颜色一致性正则化项,旨在最小化不同生成器输出的颜色和结构差异,提升生成图像的质量. StackGAN++虽然比StackGAN生成的图像更加合理且生动,但类似五官、建筑的门窗和鸟的羽毛等细节的生成十分模糊和抽象. ...
... [25 ]提出从平滑流形的高斯分布中抽取文本嵌入,不使用固定的文本嵌入. 为了鼓励网络学习并统一在不同尺度图像中的基本结构和颜色,Zhang等[25 ] 还提出颜色一致性正则化项,旨在最小化不同生成器输出的颜色和结构差异,提升生成图像的质量. StackGAN++虽然比StackGAN生成的图像更加合理且生动,但类似五官、建筑的门窗和鸟的羽毛等细节的生成十分模糊和抽象. ...
... [25 ]还提出颜色一致性正则化项,旨在最小化不同生成器输出的颜色和结构差异,提升生成图像的质量. StackGAN++虽然比StackGAN生成的图像更加合理且生动,但类似五官、建筑的门窗和鸟的羽毛等细节的生成十分模糊和抽象. ...
... Comparison of various metrics for GAN-based text-to-image generation methods on different datasets
Tab.1 方法 CUB鸟类数据集 Oxford-120花卉数据集 COCO数据集 IS FID R-precision IS FID IS FID R-precision GAN-INT-CLS[2 ] 2.32 68.79 — 2.66 79.55 7.95 60.62 — StackGAN[10 ] 3.70 51.89 — 3.20 55.28 8.45 74.65 — StackGAN++[25 ] 4.04 15.30 — 3.26 48.68 8.30 — — AttnGAN[11 ] 4.36 23.98 67.83 — — 25.89 35.49 85.47 DM-GAN[53 ] 4.75 16.09 72.31 — — 30.49 32.62 88.56 ControlGAN[36 ] 4.58 — 39.33 — — 24.06 — 82.43 SEGAN[34 ] 4.67 18.16 — — — 27.86 32.28 — MirrorGAN[41 ] 4.56 — 57.67 — — 26.47 — 74.52 XMC-GAN[60 ] — — — — — 30.45 9.33 71.00 CI-GAN[66 ] 5.72 9.78 — — — — — — DF-GAN[57 ] 5.10 14.81 44.83 — — — 21.42 67.97 DiverGAN[37 ] 4.98 15.63 — 3.99 — — 20.52 — SSA-GAN[58 ] 5.17 15.61 75.9 — — — 19.37 90.60 Adam-GAN[59 ] 5.28 8.57 55.94 — — 29.07 12.39 88.74 TVBi-GAN[71 ] 5.03 11.83 — — — 31.01 31.97 — 文献[67 ]方法 4.23 11.17 — 3.71 16.47 — — — Bridge-GAN[92 ] 4.74 — — — — 16.40 — — textStyleGAN[63 ] 4.78 — 49.56 — — 33.00 — 88.23 文献[45 ]方法 3.58 18.14 — 2.90 34.97 8.94 27.07 — SD-GAN[38 ] 4.67 — — — — 35.69 — — PPAN[29 ] 4.38 — — 3.52 — — — — HfGAN[27 ] 4.48 — — 3.57 — 27.53 — — HDGAN[26 ] 4.15 — — 3.45 — 11.86 — — DSE-GAN[61 ] 5.13 13.23 53.25 — — 26.71 15.30 76.31
由于采用自回归模型和扩散模型的文本生成图像方法比采用GAN的文本生成图像方法性能优异,采用自回归模型和扩散模型的文本生成图像方法更换了新的评价指标. 如表2 所示,采用自回归模型和扩散模型的方法,在MS-COCO数据集上对FID评价指标及Zero-shot FID评价指标进行评判,这些评价指标仅在某种程度上反映各个模型的性能高低. 对于文本生成图像任务,人工评判生成图像的质量以及文本与图像的语义一致性有更高的可信度,但由于人工评价指标不统一、个人评价意见不统一,人工评判不能作为定性评价文本生成图像模型的标准. ...
2
... 为了对生成图像中的模糊部分细节化,Zhang等[26 ] 提出HDGAN,在生成器多尺度中间层采用分层嵌套的判别器来生成512×512像素的图像,如图8 (d)所示. 图像的分辨率在生成器的深度上逐渐提升,不同级别的分辨率都有不同的判别器去辨别图像的真实性、图像文字的匹配度和图像中的小区域是否真实. 该方法提出低分辨率生成器用于学习与文本语义一致的图像结构,而高分辨率生成器一般用于细粒度生成图像. 该模型判别器采用分层嵌套的结构,并由端到端的方式生成图像,因此低分辨率生成器可以学习来自高分辨率判别器的知识经验,该方法能够在不同尺度下生成更加一致的图像. ...
... Comparison of various metrics for GAN-based text-to-image generation methods on different datasets
Tab.1 方法 CUB鸟类数据集 Oxford-120花卉数据集 COCO数据集 IS FID R-precision IS FID IS FID R-precision GAN-INT-CLS[2 ] 2.32 68.79 — 2.66 79.55 7.95 60.62 — StackGAN[10 ] 3.70 51.89 — 3.20 55.28 8.45 74.65 — StackGAN++[25 ] 4.04 15.30 — 3.26 48.68 8.30 — — AttnGAN[11 ] 4.36 23.98 67.83 — — 25.89 35.49 85.47 DM-GAN[53 ] 4.75 16.09 72.31 — — 30.49 32.62 88.56 ControlGAN[36 ] 4.58 — 39.33 — — 24.06 — 82.43 SEGAN[34 ] 4.67 18.16 — — — 27.86 32.28 — MirrorGAN[41 ] 4.56 — 57.67 — — 26.47 — 74.52 XMC-GAN[60 ] — — — — — 30.45 9.33 71.00 CI-GAN[66 ] 5.72 9.78 — — — — — — DF-GAN[57 ] 5.10 14.81 44.83 — — — 21.42 67.97 DiverGAN[37 ] 4.98 15.63 — 3.99 — — 20.52 — SSA-GAN[58 ] 5.17 15.61 75.9 — — — 19.37 90.60 Adam-GAN[59 ] 5.28 8.57 55.94 — — 29.07 12.39 88.74 TVBi-GAN[71 ] 5.03 11.83 — — — 31.01 31.97 — 文献[67 ]方法 4.23 11.17 — 3.71 16.47 — — — Bridge-GAN[92 ] 4.74 — — — — 16.40 — — textStyleGAN[63 ] 4.78 — 49.56 — — 33.00 — 88.23 文献[45 ]方法 3.58 18.14 — 2.90 34.97 8.94 27.07 — SD-GAN[38 ] 4.67 — — — — 35.69 — — PPAN[29 ] 4.38 — — 3.52 — — — — HfGAN[27 ] 4.48 — — 3.57 — 27.53 — — HDGAN[26 ] 4.15 — — 3.45 — 11.86 — — DSE-GAN[61 ] 5.13 13.23 53.25 — — 26.71 15.30 76.31
由于采用自回归模型和扩散模型的文本生成图像方法比采用GAN的文本生成图像方法性能优异,采用自回归模型和扩散模型的文本生成图像方法更换了新的评价指标. 如表2 所示,采用自回归模型和扩散模型的方法,在MS-COCO数据集上对FID评价指标及Zero-shot FID评价指标进行评判,这些评价指标仅在某种程度上反映各个模型的性能高低. 对于文本生成图像任务,人工评判生成图像的质量以及文本与图像的语义一致性有更高的可信度,但由于人工评价指标不统一、个人评价意见不统一,人工评判不能作为定性评价文本生成图像模型的标准. ...
2
... 与HDGAN相比,HfGAN[27 ] 在多生成器层次融合的体系结构下,只用一个判别器判别真实度和匹配程度,如图8 (c)所示. 受ResNet[28 ] 的启发,该方法将多个不同阶段的生成器以标识加法、权重加法和快速连接的方式连接,将不同阶段提取的多尺度特征自适应融合在一起,利用包含生成图像整体语义结构的低分辨率特征指导高分辨率的细节生成. ...
... Comparison of various metrics for GAN-based text-to-image generation methods on different datasets
Tab.1 方法 CUB鸟类数据集 Oxford-120花卉数据集 COCO数据集 IS FID R-precision IS FID IS FID R-precision GAN-INT-CLS[2 ] 2.32 68.79 — 2.66 79.55 7.95 60.62 — StackGAN[10 ] 3.70 51.89 — 3.20 55.28 8.45 74.65 — StackGAN++[25 ] 4.04 15.30 — 3.26 48.68 8.30 — — AttnGAN[11 ] 4.36 23.98 67.83 — — 25.89 35.49 85.47 DM-GAN[53 ] 4.75 16.09 72.31 — — 30.49 32.62 88.56 ControlGAN[36 ] 4.58 — 39.33 — — 24.06 — 82.43 SEGAN[34 ] 4.67 18.16 — — — 27.86 32.28 — MirrorGAN[41 ] 4.56 — 57.67 — — 26.47 — 74.52 XMC-GAN[60 ] — — — — — 30.45 9.33 71.00 CI-GAN[66 ] 5.72 9.78 — — — — — — DF-GAN[57 ] 5.10 14.81 44.83 — — — 21.42 67.97 DiverGAN[37 ] 4.98 15.63 — 3.99 — — 20.52 — SSA-GAN[58 ] 5.17 15.61 75.9 — — — 19.37 90.60 Adam-GAN[59 ] 5.28 8.57 55.94 — — 29.07 12.39 88.74 TVBi-GAN[71 ] 5.03 11.83 — — — 31.01 31.97 — 文献[67 ]方法 4.23 11.17 — 3.71 16.47 — — — Bridge-GAN[92 ] 4.74 — — — — 16.40 — — textStyleGAN[63 ] 4.78 — 49.56 — — 33.00 — 88.23 文献[45 ]方法 3.58 18.14 — 2.90 34.97 8.94 27.07 — SD-GAN[38 ] 4.67 — — — — 35.69 — — PPAN[29 ] 4.38 — — 3.52 — — — — HfGAN[27 ] 4.48 — — 3.57 — 27.53 — — HDGAN[26 ] 4.15 — — 3.45 — 11.86 — — DSE-GAN[61 ] 5.13 13.23 53.25 — — 26.71 15.30 76.31
由于采用自回归模型和扩散模型的文本生成图像方法比采用GAN的文本生成图像方法性能优异,采用自回归模型和扩散模型的文本生成图像方法更换了新的评价指标. 如表2 所示,采用自回归模型和扩散模型的方法,在MS-COCO数据集上对FID评价指标及Zero-shot FID评价指标进行评判,这些评价指标仅在某种程度上反映各个模型的性能高低. 对于文本生成图像任务,人工评判生成图像的质量以及文本与图像的语义一致性有更高的可信度,但由于人工评价指标不统一、个人评价意见不统一,人工评判不能作为定性评价文本生成图像模型的标准. ...
1
... 与HDGAN相比,HfGAN[27 ] 在多生成器层次融合的体系结构下,只用一个判别器判别真实度和匹配程度,如图8 (c)所示. 受ResNet[28 ] 的启发,该方法将多个不同阶段的生成器以标识加法、权重加法和快速连接的方式连接,将不同阶段提取的多尺度特征自适应融合在一起,利用包含生成图像整体语义结构的低分辨率特征指导高分辨率的细节生成. ...
2
... Gao等[29 ] 提出PPAN,只使用1个金字塔框架[30 ] 的生成器和3个不同的判别器,如图8 (b)所示. 通过横向连接和自上而下的路径,结合不同分辨率下强弱不同的语义特征,使得网络在所有级别下都具有丰富的语义信息,可以从单一输入图像尺度快速构建网络. ...
... Comparison of various metrics for GAN-based text-to-image generation methods on different datasets
Tab.1 方法 CUB鸟类数据集 Oxford-120花卉数据集 COCO数据集 IS FID R-precision IS FID IS FID R-precision GAN-INT-CLS[2 ] 2.32 68.79 — 2.66 79.55 7.95 60.62 — StackGAN[10 ] 3.70 51.89 — 3.20 55.28 8.45 74.65 — StackGAN++[25 ] 4.04 15.30 — 3.26 48.68 8.30 — — AttnGAN[11 ] 4.36 23.98 67.83 — — 25.89 35.49 85.47 DM-GAN[53 ] 4.75 16.09 72.31 — — 30.49 32.62 88.56 ControlGAN[36 ] 4.58 — 39.33 — — 24.06 — 82.43 SEGAN[34 ] 4.67 18.16 — — — 27.86 32.28 — MirrorGAN[41 ] 4.56 — 57.67 — — 26.47 — 74.52 XMC-GAN[60 ] — — — — — 30.45 9.33 71.00 CI-GAN[66 ] 5.72 9.78 — — — — — — DF-GAN[57 ] 5.10 14.81 44.83 — — — 21.42 67.97 DiverGAN[37 ] 4.98 15.63 — 3.99 — — 20.52 — SSA-GAN[58 ] 5.17 15.61 75.9 — — — 19.37 90.60 Adam-GAN[59 ] 5.28 8.57 55.94 — — 29.07 12.39 88.74 TVBi-GAN[71 ] 5.03 11.83 — — — 31.01 31.97 — 文献[67 ]方法 4.23 11.17 — 3.71 16.47 — — — Bridge-GAN[92 ] 4.74 — — — — 16.40 — — textStyleGAN[63 ] 4.78 — 49.56 — — 33.00 — 88.23 文献[45 ]方法 3.58 18.14 — 2.90 34.97 8.94 27.07 — SD-GAN[38 ] 4.67 — — — — 35.69 — — PPAN[29 ] 4.38 — — 3.52 — — — — HfGAN[27 ] 4.48 — — 3.57 — 27.53 — — HDGAN[26 ] 4.15 — — 3.45 — 11.86 — — DSE-GAN[61 ] 5.13 13.23 53.25 — — 26.71 15.30 76.31
由于采用自回归模型和扩散模型的文本生成图像方法比采用GAN的文本生成图像方法性能优异,采用自回归模型和扩散模型的文本生成图像方法更换了新的评价指标. 如表2 所示,采用自回归模型和扩散模型的方法,在MS-COCO数据集上对FID评价指标及Zero-shot FID评价指标进行评判,这些评价指标仅在某种程度上反映各个模型的性能高低. 对于文本生成图像任务,人工评判生成图像的质量以及文本与图像的语义一致性有更高的可信度,但由于人工评价指标不统一、个人评价意见不统一,人工评判不能作为定性评价文本生成图像模型的标准. ...
1
... Gao等[29 ] 提出PPAN,只使用1个金字塔框架[30 ] 的生成器和3个不同的判别器,如图8 (b)所示. 通过横向连接和自上而下的路径,结合不同分辨率下强弱不同的语义特征,使得网络在所有级别下都具有丰富的语义信息,可以从单一输入图像尺度快速构建网络. ...
1
... 注意力机制的出现使得深度学习领域的研究迈上了一个新的阶段,同时对文本生成图像领域产生了重要的影响, 这种改进方法一般应用在多层次体系嵌套方法之中. 改进原理是允许网络通过对重要的部分和不重要的部分加权来关注输入的特定方面,从而达到更好的融合文字与图像特征的效果. 在文本生成图像中,由于要关注每一个词和图像中每一个部分的联系,该类方法[31 -33 ] 通过改进注意力机制实现提高文本-图像语义一致性的效果. 最经典的方法是AttnGAN模型,如图9 所示,该模型在StackGAN的基础上加入注意力模型(attention models),大幅提升了合成图像和文字的匹配程度,对往后基于GAN的文本生成图像方法产生了深远的影响. ...
1
... 注意力机制的出现使得深度学习领域的研究迈上了一个新的阶段,同时对文本生成图像领域产生了重要的影响, 这种改进方法一般应用在多层次体系嵌套方法之中. 改进原理是允许网络通过对重要的部分和不重要的部分加权来关注输入的特定方面,从而达到更好的融合文字与图像特征的效果. 在文本生成图像中,由于要关注每一个词和图像中每一个部分的联系,该类方法[31 -33 ] 通过改进注意力机制实现提高文本-图像语义一致性的效果. 最经典的方法是AttnGAN模型,如图9 所示,该模型在StackGAN的基础上加入注意力模型(attention models),大幅提升了合成图像和文字的匹配程度,对往后基于GAN的文本生成图像方法产生了深远的影响. ...
融合双注意力与多标签的图像中文描述生成方法
1
2021
... 注意力机制的出现使得深度学习领域的研究迈上了一个新的阶段,同时对文本生成图像领域产生了重要的影响, 这种改进方法一般应用在多层次体系嵌套方法之中. 改进原理是允许网络通过对重要的部分和不重要的部分加权来关注输入的特定方面,从而达到更好的融合文字与图像特征的效果. 在文本生成图像中,由于要关注每一个词和图像中每一个部分的联系,该类方法[31 -33 ] 通过改进注意力机制实现提高文本-图像语义一致性的效果. 最经典的方法是AttnGAN模型,如图9 所示,该模型在StackGAN的基础上加入注意力模型(attention models),大幅提升了合成图像和文字的匹配程度,对往后基于GAN的文本生成图像方法产生了深远的影响. ...
融合双注意力与多标签的图像中文描述生成方法
1
2021
... 注意力机制的出现使得深度学习领域的研究迈上了一个新的阶段,同时对文本生成图像领域产生了重要的影响, 这种改进方法一般应用在多层次体系嵌套方法之中. 改进原理是允许网络通过对重要的部分和不重要的部分加权来关注输入的特定方面,从而达到更好的融合文字与图像特征的效果. 在文本生成图像中,由于要关注每一个词和图像中每一个部分的联系,该类方法[31 -33 ] 通过改进注意力机制实现提高文本-图像语义一致性的效果. 最经典的方法是AttnGAN模型,如图9 所示,该模型在StackGAN的基础上加入注意力模型(attention models),大幅提升了合成图像和文字的匹配程度,对往后基于GAN的文本生成图像方法产生了深远的影响. ...
3
... SEGAN[34 ] 和AttnGAN方法不同,该方法引入注意力正则化模块,增大了对影响图像真实度相对重要的词的注意力权重. Huang等[35 ] 提出基于网格的注意力机制,用辅助边界框定义对象网格区域和单词短语之间的联系. ...
... SEGAN方法[34 ] 使用孪生网络的思路,训练利用真实图像进行语义对齐的连体结构. 该方法通过最小化生成的图像和相应的真实图像之间的特征距离,同时最大化特征距离,达到提升生成图像真实度的效果. ...
... Comparison of various metrics for GAN-based text-to-image generation methods on different datasets
Tab.1 方法 CUB鸟类数据集 Oxford-120花卉数据集 COCO数据集 IS FID R-precision IS FID IS FID R-precision GAN-INT-CLS[2 ] 2.32 68.79 — 2.66 79.55 7.95 60.62 — StackGAN[10 ] 3.70 51.89 — 3.20 55.28 8.45 74.65 — StackGAN++[25 ] 4.04 15.30 — 3.26 48.68 8.30 — — AttnGAN[11 ] 4.36 23.98 67.83 — — 25.89 35.49 85.47 DM-GAN[53 ] 4.75 16.09 72.31 — — 30.49 32.62 88.56 ControlGAN[36 ] 4.58 — 39.33 — — 24.06 — 82.43 SEGAN[34 ] 4.67 18.16 — — — 27.86 32.28 — MirrorGAN[41 ] 4.56 — 57.67 — — 26.47 — 74.52 XMC-GAN[60 ] — — — — — 30.45 9.33 71.00 CI-GAN[66 ] 5.72 9.78 — — — — — — DF-GAN[57 ] 5.10 14.81 44.83 — — — 21.42 67.97 DiverGAN[37 ] 4.98 15.63 — 3.99 — — 20.52 — SSA-GAN[58 ] 5.17 15.61 75.9 — — — 19.37 90.60 Adam-GAN[59 ] 5.28 8.57 55.94 — — 29.07 12.39 88.74 TVBi-GAN[71 ] 5.03 11.83 — — — 31.01 31.97 — 文献[67 ]方法 4.23 11.17 — 3.71 16.47 — — — Bridge-GAN[92 ] 4.74 — — — — 16.40 — — textStyleGAN[63 ] 4.78 — 49.56 — — 33.00 — 88.23 文献[45 ]方法 3.58 18.14 — 2.90 34.97 8.94 27.07 — SD-GAN[38 ] 4.67 — — — — 35.69 — — PPAN[29 ] 4.38 — — 3.52 — — — — HfGAN[27 ] 4.48 — — 3.57 — 27.53 — — HDGAN[26 ] 4.15 — — 3.45 — 11.86 — — DSE-GAN[61 ] 5.13 13.23 53.25 — — 26.71 15.30 76.31
由于采用自回归模型和扩散模型的文本生成图像方法比采用GAN的文本生成图像方法性能优异,采用自回归模型和扩散模型的文本生成图像方法更换了新的评价指标. 如表2 所示,采用自回归模型和扩散模型的方法,在MS-COCO数据集上对FID评价指标及Zero-shot FID评价指标进行评判,这些评价指标仅在某种程度上反映各个模型的性能高低. 对于文本生成图像任务,人工评判生成图像的质量以及文本与图像的语义一致性有更高的可信度,但由于人工评价指标不统一、个人评价意见不统一,人工评判不能作为定性评价文本生成图像模型的标准. ...
1
... SEGAN[34 ] 和AttnGAN方法不同,该方法引入注意力正则化模块,增大了对影响图像真实度相对重要的词的注意力权重. Huang等[35 ] 提出基于网格的注意力机制,用辅助边界框定义对象网格区域和单词短语之间的联系. ...
2
... ControlGAN[36 ] 可以通过描述,在不影响其他图像内容的情况下对视觉属性(如类别、纹理或颜色) 进行修改生成. 该方法在AttnGAN的基础上提出词级的空间注意力(spatial attention)和通道注意力(channel-wise attention)驱动的生成器,这种改进使生成器能够生成与最相关的词相对应的图像区域. 与AttnGAN主要关注颜色信息的空间注意力相比,ControlGAN使语义上有意义的部分与相应的词的联系更加紧密. 词级判别器为生成器提供了细粒度的训练信号,利用词和图像子区域之间的相关性来拆分不同的视觉属性. ...
... Comparison of various metrics for GAN-based text-to-image generation methods on different datasets
Tab.1 方法 CUB鸟类数据集 Oxford-120花卉数据集 COCO数据集 IS FID R-precision IS FID IS FID R-precision GAN-INT-CLS[2 ] 2.32 68.79 — 2.66 79.55 7.95 60.62 — StackGAN[10 ] 3.70 51.89 — 3.20 55.28 8.45 74.65 — StackGAN++[25 ] 4.04 15.30 — 3.26 48.68 8.30 — — AttnGAN[11 ] 4.36 23.98 67.83 — — 25.89 35.49 85.47 DM-GAN[53 ] 4.75 16.09 72.31 — — 30.49 32.62 88.56 ControlGAN[36 ] 4.58 — 39.33 — — 24.06 — 82.43 SEGAN[34 ] 4.67 18.16 — — — 27.86 32.28 — MirrorGAN[41 ] 4.56 — 57.67 — — 26.47 — 74.52 XMC-GAN[60 ] — — — — — 30.45 9.33 71.00 CI-GAN[66 ] 5.72 9.78 — — — — — — DF-GAN[57 ] 5.10 14.81 44.83 — — — 21.42 67.97 DiverGAN[37 ] 4.98 15.63 — 3.99 — — 20.52 — SSA-GAN[58 ] 5.17 15.61 75.9 — — — 19.37 90.60 Adam-GAN[59 ] 5.28 8.57 55.94 — — 29.07 12.39 88.74 TVBi-GAN[71 ] 5.03 11.83 — — — 31.01 31.97 — 文献[67 ]方法 4.23 11.17 — 3.71 16.47 — — — Bridge-GAN[92 ] 4.74 — — — — 16.40 — — textStyleGAN[63 ] 4.78 — 49.56 — — 33.00 — 88.23 文献[45 ]方法 3.58 18.14 — 2.90 34.97 8.94 27.07 — SD-GAN[38 ] 4.67 — — — — 35.69 — — PPAN[29 ] 4.38 — — 3.52 — — — — HfGAN[27 ] 4.48 — — 3.57 — 27.53 — — HDGAN[26 ] 4.15 — — 3.45 — 11.86 — — DSE-GAN[61 ] 5.13 13.23 53.25 — — 26.71 15.30 76.31
由于采用自回归模型和扩散模型的文本生成图像方法比采用GAN的文本生成图像方法性能优异,采用自回归模型和扩散模型的文本生成图像方法更换了新的评价指标. 如表2 所示,采用自回归模型和扩散模型的方法,在MS-COCO数据集上对FID评价指标及Zero-shot FID评价指标进行评判,这些评价指标仅在某种程度上反映各个模型的性能高低. 对于文本生成图像任务,人工评判生成图像的质量以及文本与图像的语义一致性有更高的可信度,但由于人工评价指标不统一、个人评价意见不统一,人工评判不能作为定性评价文本生成图像模型的标准. ...
DiverGAN: an efficient and effective single-stage framework for diverse text-to-image generation
3
2022
... DiverGAN[37 ] 主要解决了其他文本生成图像方法经常出现生成图像类型单一的问题. 导致这种问题的原因是噪声向量仅经过简单处理后,直接拼接到文本特征送入卷积处理,模型无法在初始阶段学习到足够的特征[37 ] . 对噪声向量学习,将其拉平为4×4×256的特征图后,再将文本特征拼接至图像特征中. 通过该方法提出的通道注意力模块和像素注意力模块捕捉文本特征和图像特征之间的语义关联,使得图像更好地学习到关键词特征表示,排除语义前后不相关和冗余信息的影响,有效解耦文本描述的属性,达到精确控制生成图像不同区域的效果. ...
... [37 ]. 对噪声向量学习,将其拉平为4×4×256的特征图后,再将文本特征拼接至图像特征中. 通过该方法提出的通道注意力模块和像素注意力模块捕捉文本特征和图像特征之间的语义关联,使得图像更好地学习到关键词特征表示,排除语义前后不相关和冗余信息的影响,有效解耦文本描述的属性,达到精确控制生成图像不同区域的效果. ...
... Comparison of various metrics for GAN-based text-to-image generation methods on different datasets
Tab.1 方法 CUB鸟类数据集 Oxford-120花卉数据集 COCO数据集 IS FID R-precision IS FID IS FID R-precision GAN-INT-CLS[2 ] 2.32 68.79 — 2.66 79.55 7.95 60.62 — StackGAN[10 ] 3.70 51.89 — 3.20 55.28 8.45 74.65 — StackGAN++[25 ] 4.04 15.30 — 3.26 48.68 8.30 — — AttnGAN[11 ] 4.36 23.98 67.83 — — 25.89 35.49 85.47 DM-GAN[53 ] 4.75 16.09 72.31 — — 30.49 32.62 88.56 ControlGAN[36 ] 4.58 — 39.33 — — 24.06 — 82.43 SEGAN[34 ] 4.67 18.16 — — — 27.86 32.28 — MirrorGAN[41 ] 4.56 — 57.67 — — 26.47 — 74.52 XMC-GAN[60 ] — — — — — 30.45 9.33 71.00 CI-GAN[66 ] 5.72 9.78 — — — — — — DF-GAN[57 ] 5.10 14.81 44.83 — — — 21.42 67.97 DiverGAN[37 ] 4.98 15.63 — 3.99 — — 20.52 — SSA-GAN[58 ] 5.17 15.61 75.9 — — — 19.37 90.60 Adam-GAN[59 ] 5.28 8.57 55.94 — — 29.07 12.39 88.74 TVBi-GAN[71 ] 5.03 11.83 — — — 31.01 31.97 — 文献[67 ]方法 4.23 11.17 — 3.71 16.47 — — — Bridge-GAN[92 ] 4.74 — — — — 16.40 — — textStyleGAN[63 ] 4.78 — 49.56 — — 33.00 — 88.23 文献[45 ]方法 3.58 18.14 — 2.90 34.97 8.94 27.07 — SD-GAN[38 ] 4.67 — — — — 35.69 — — PPAN[29 ] 4.38 — — 3.52 — — — — HfGAN[27 ] 4.48 — — 3.57 — 27.53 — — HDGAN[26 ] 4.15 — — 3.45 — 11.86 — — DSE-GAN[61 ] 5.13 13.23 53.25 — — 26.71 15.30 76.31
由于采用自回归模型和扩散模型的文本生成图像方法比采用GAN的文本生成图像方法性能优异,采用自回归模型和扩散模型的文本生成图像方法更换了新的评价指标. 如表2 所示,采用自回归模型和扩散模型的方法,在MS-COCO数据集上对FID评价指标及Zero-shot FID评价指标进行评判,这些评价指标仅在某种程度上反映各个模型的性能高低. 对于文本生成图像任务,人工评判生成图像的质量以及文本与图像的语义一致性有更高的可信度,但由于人工评价指标不统一、个人评价意见不统一,人工评判不能作为定性评价文本生成图像模型的标准. ...
2
... SD-GAN[38 ] 是最早使用经典孪生网络架构的文本生成图像方法. 如图10 所示,该方法需要分别输入2个文本至2个模型参数相同的网络,使用对比损失[39 ] (contrastive loss)来最小化或最大化2个分支特征之间的距离,以学习有语义的表征. 最大化还是最小化取决于2个文本是来自2个不同的类别还是来自相同的类别. 该方法虽然可以更快地提炼出文本中的共性,但是会降低生成图像的多样性. 为了提升生成图像的多样性,该方法提出语义条件批归一化(semantic-conditioned batch normalization),根据句子和单词的语义特征调整图像特征,生成多样的图像. ...
... Comparison of various metrics for GAN-based text-to-image generation methods on different datasets
Tab.1 方法 CUB鸟类数据集 Oxford-120花卉数据集 COCO数据集 IS FID R-precision IS FID IS FID R-precision GAN-INT-CLS[2 ] 2.32 68.79 — 2.66 79.55 7.95 60.62 — StackGAN[10 ] 3.70 51.89 — 3.20 55.28 8.45 74.65 — StackGAN++[25 ] 4.04 15.30 — 3.26 48.68 8.30 — — AttnGAN[11 ] 4.36 23.98 67.83 — — 25.89 35.49 85.47 DM-GAN[53 ] 4.75 16.09 72.31 — — 30.49 32.62 88.56 ControlGAN[36 ] 4.58 — 39.33 — — 24.06 — 82.43 SEGAN[34 ] 4.67 18.16 — — — 27.86 32.28 — MirrorGAN[41 ] 4.56 — 57.67 — — 26.47 — 74.52 XMC-GAN[60 ] — — — — — 30.45 9.33 71.00 CI-GAN[66 ] 5.72 9.78 — — — — — — DF-GAN[57 ] 5.10 14.81 44.83 — — — 21.42 67.97 DiverGAN[37 ] 4.98 15.63 — 3.99 — — 20.52 — SSA-GAN[58 ] 5.17 15.61 75.9 — — — 19.37 90.60 Adam-GAN[59 ] 5.28 8.57 55.94 — — 29.07 12.39 88.74 TVBi-GAN[71 ] 5.03 11.83 — — — 31.01 31.97 — 文献[67 ]方法 4.23 11.17 — 3.71 16.47 — — — Bridge-GAN[92 ] 4.74 — — — — 16.40 — — textStyleGAN[63 ] 4.78 — 49.56 — — 33.00 — 88.23 文献[45 ]方法 3.58 18.14 — 2.90 34.97 8.94 27.07 — SD-GAN[38 ] 4.67 — — — — 35.69 — — PPAN[29 ] 4.38 — — 3.52 — — — — HfGAN[27 ] 4.48 — — 3.57 — 27.53 — — HDGAN[26 ] 4.15 — — 3.45 — 11.86 — — DSE-GAN[61 ] 5.13 13.23 53.25 — — 26.71 15.30 76.31
由于采用自回归模型和扩散模型的文本生成图像方法比采用GAN的文本生成图像方法性能优异,采用自回归模型和扩散模型的文本生成图像方法更换了新的评价指标. 如表2 所示,采用自回归模型和扩散模型的方法,在MS-COCO数据集上对FID评价指标及Zero-shot FID评价指标进行评判,这些评价指标仅在某种程度上反映各个模型的性能高低. 对于文本生成图像任务,人工评判生成图像的质量以及文本与图像的语义一致性有更高的可信度,但由于人工评价指标不统一、个人评价意见不统一,人工评判不能作为定性评价文本生成图像模型的标准. ...
1
... SD-GAN[38 ] 是最早使用经典孪生网络架构的文本生成图像方法. 如图10 所示,该方法需要分别输入2个文本至2个模型参数相同的网络,使用对比损失[39 ] (contrastive loss)来最小化或最大化2个分支特征之间的距离,以学习有语义的表征. 最大化还是最小化取决于2个文本是来自2个不同的类别还是来自相同的类别. 该方法虽然可以更快地提炼出文本中的共性,但是会降低生成图像的多样性. 为了提升生成图像的多样性,该方法提出语义条件批归一化(semantic-conditioned batch normalization),根据句子和单词的语义特征调整图像特征,生成多样的图像. ...
1
... 文本生成图像与图像生成文字被看作是一对相互的任务,受CycleGAN[7 ] 的启发,循环一致性文本生成图像的任务通过重新描述架构[40 -41 ] ,即在生成图像网络后附加生成图像标题的网络,学习文本和图像之间的语义一致性表示,提升输入文本和根据合成图像再生成的文本描述之间的相似性,促使神经网络能够更好地理解并融合文字特征和图像特征,提高网络学习到的文字特征和图像特征的一致性. 该类方法采用的模型大多是文本特征提取网络加图像生成网络,再加入字幕生成网络,网络结构复杂,需要设计精密的整体网络模型和损失函数,该类改进方法有巨大的改进空间. ...
3
... 文本生成图像与图像生成文字被看作是一对相互的任务,受CycleGAN[7 ] 的启发,循环一致性文本生成图像的任务通过重新描述架构[40 -41 ] ,即在生成图像网络后附加生成图像标题的网络,学习文本和图像之间的语义一致性表示,提升输入文本和根据合成图像再生成的文本描述之间的相似性,促使神经网络能够更好地理解并融合文字特征和图像特征,提高网络学习到的文字特征和图像特征的一致性. 该类方法采用的模型大多是文本特征提取网络加图像生成网络,再加入字幕生成网络,网络结构复杂,需要设计精密的整体网络模型和损失函数,该类改进方法有巨大的改进空间. ...
... MirrorGAN[41 ] 方法如图11 所示,先提取文本向量,再通过关注整个句子和每个词来指导生成图像. 基于编码器-解码器的图像字幕网络[42 -43 ] ,生成描述字幕. 除了利用GAN损失函数和CGAN损失函数判别图像文本是否匹配和图像是否真实外,还使用基于交叉熵的文本重建损失,对输入文本和重新生成的字幕进行比较,使得网络深度理解文本语义,生成与文本语义一致的图像. ...
... Comparison of various metrics for GAN-based text-to-image generation methods on different datasets
Tab.1 方法 CUB鸟类数据集 Oxford-120花卉数据集 COCO数据集 IS FID R-precision IS FID IS FID R-precision GAN-INT-CLS[2 ] 2.32 68.79 — 2.66 79.55 7.95 60.62 — StackGAN[10 ] 3.70 51.89 — 3.20 55.28 8.45 74.65 — StackGAN++[25 ] 4.04 15.30 — 3.26 48.68 8.30 — — AttnGAN[11 ] 4.36 23.98 67.83 — — 25.89 35.49 85.47 DM-GAN[53 ] 4.75 16.09 72.31 — — 30.49 32.62 88.56 ControlGAN[36 ] 4.58 — 39.33 — — 24.06 — 82.43 SEGAN[34 ] 4.67 18.16 — — — 27.86 32.28 — MirrorGAN[41 ] 4.56 — 57.67 — — 26.47 — 74.52 XMC-GAN[60 ] — — — — — 30.45 9.33 71.00 CI-GAN[66 ] 5.72 9.78 — — — — — — DF-GAN[57 ] 5.10 14.81 44.83 — — — 21.42 67.97 DiverGAN[37 ] 4.98 15.63 — 3.99 — — 20.52 — SSA-GAN[58 ] 5.17 15.61 75.9 — — — 19.37 90.60 Adam-GAN[59 ] 5.28 8.57 55.94 — — 29.07 12.39 88.74 TVBi-GAN[71 ] 5.03 11.83 — — — 31.01 31.97 — 文献[67 ]方法 4.23 11.17 — 3.71 16.47 — — — Bridge-GAN[92 ] 4.74 — — — — 16.40 — — textStyleGAN[63 ] 4.78 — 49.56 — — 33.00 — 88.23 文献[45 ]方法 3.58 18.14 — 2.90 34.97 8.94 27.07 — SD-GAN[38 ] 4.67 — — — — 35.69 — — PPAN[29 ] 4.38 — — 3.52 — — — — HfGAN[27 ] 4.48 — — 3.57 — 27.53 — — HDGAN[26 ] 4.15 — — 3.45 — 11.86 — — DSE-GAN[61 ] 5.13 13.23 53.25 — — 26.71 15.30 76.31
由于采用自回归模型和扩散模型的文本生成图像方法比采用GAN的文本生成图像方法性能优异,采用自回归模型和扩散模型的文本生成图像方法更换了新的评价指标. 如表2 所示,采用自回归模型和扩散模型的方法,在MS-COCO数据集上对FID评价指标及Zero-shot FID评价指标进行评判,这些评价指标仅在某种程度上反映各个模型的性能高低. 对于文本生成图像任务,人工评判生成图像的质量以及文本与图像的语义一致性有更高的可信度,但由于人工评价指标不统一、个人评价意见不统一,人工评判不能作为定性评价文本生成图像模型的标准. ...
1
... MirrorGAN[41 ] 方法如图11 所示,先提取文本向量,再通过关注整个句子和每个词来指导生成图像. 基于编码器-解码器的图像字幕网络[42 -43 ] ,生成描述字幕. 除了利用GAN损失函数和CGAN损失函数判别图像文本是否匹配和图像是否真实外,还使用基于交叉熵的文本重建损失,对输入文本和重新生成的字幕进行比较,使得网络深度理解文本语义,生成与文本语义一致的图像. ...
1
... MirrorGAN[41 ] 方法如图11 所示,先提取文本向量,再通过关注整个句子和每个词来指导生成图像. 基于编码器-解码器的图像字幕网络[42 -43 ] ,生成描述字幕. 除了利用GAN损失函数和CGAN损失函数判别图像文本是否匹配和图像是否真实外,还使用基于交叉熵的文本重建损失,对输入文本和重新生成的字幕进行比较,使得网络深度理解文本语义,生成与文本语义一致的图像. ...
1
... 受对抗性推理方法[44 ] 的启发,Lao等[45 ] 提出以无监督的方式通过文本嵌入描述生成图像,该方法有额外的编码器,该编码器可以接收真实图像并推断出生成图像的特征向量和文本特征向量. ...
2
... 受对抗性推理方法[44 ] 的启发,Lao等[45 ] 提出以无监督的方式通过文本嵌入描述生成图像,该方法有额外的编码器,该编码器可以接收真实图像并推断出生成图像的特征向量和文本特征向量. ...
... Comparison of various metrics for GAN-based text-to-image generation methods on different datasets
Tab.1 方法 CUB鸟类数据集 Oxford-120花卉数据集 COCO数据集 IS FID R-precision IS FID IS FID R-precision GAN-INT-CLS[2 ] 2.32 68.79 — 2.66 79.55 7.95 60.62 — StackGAN[10 ] 3.70 51.89 — 3.20 55.28 8.45 74.65 — StackGAN++[25 ] 4.04 15.30 — 3.26 48.68 8.30 — — AttnGAN[11 ] 4.36 23.98 67.83 — — 25.89 35.49 85.47 DM-GAN[53 ] 4.75 16.09 72.31 — — 30.49 32.62 88.56 ControlGAN[36 ] 4.58 — 39.33 — — 24.06 — 82.43 SEGAN[34 ] 4.67 18.16 — — — 27.86 32.28 — MirrorGAN[41 ] 4.56 — 57.67 — — 26.47 — 74.52 XMC-GAN[60 ] — — — — — 30.45 9.33 71.00 CI-GAN[66 ] 5.72 9.78 — — — — — — DF-GAN[57 ] 5.10 14.81 44.83 — — — 21.42 67.97 DiverGAN[37 ] 4.98 15.63 — 3.99 — — 20.52 — SSA-GAN[58 ] 5.17 15.61 75.9 — — — 19.37 90.60 Adam-GAN[59 ] 5.28 8.57 55.94 — — 29.07 12.39 88.74 TVBi-GAN[71 ] 5.03 11.83 — — — 31.01 31.97 — 文献[67 ]方法 4.23 11.17 — 3.71 16.47 — — — Bridge-GAN[92 ] 4.74 — — — — 16.40 — — textStyleGAN[63 ] 4.78 — 49.56 — — 33.00 — 88.23 文献[45 ]方法 3.58 18.14 — 2.90 34.97 8.94 27.07 — SD-GAN[38 ] 4.67 — — — — 35.69 — — PPAN[29 ] 4.38 — — 3.52 — — — — HfGAN[27 ] 4.48 — — 3.57 — 27.53 — — HDGAN[26 ] 4.15 — — 3.45 — 11.86 — — DSE-GAN[61 ] 5.13 13.23 53.25 — — 26.71 15.30 76.31
由于采用自回归模型和扩散模型的文本生成图像方法比采用GAN的文本生成图像方法性能优异,采用自回归模型和扩散模型的文本生成图像方法更换了新的评价指标. 如表2 所示,采用自回归模型和扩散模型的方法,在MS-COCO数据集上对FID评价指标及Zero-shot FID评价指标进行评判,这些评价指标仅在某种程度上反映各个模型的性能高低. 对于文本生成图像任务,人工评判生成图像的质量以及文本与图像的语义一致性有更高的可信度,但由于人工评价指标不统一、个人评价意见不统一,人工评判不能作为定性评价文本生成图像模型的标准. ...
1
... 在文本生成图像任务中,利用深度融合文本特征加强图像生成这一类型的方法更多地关注如何使模型充分融合文本特征和图像特征,生成符合文本描述的图像. 在该类型的方法中,有些用“门”机制判别更新图像特征生成图像,也有些用多个仿射变换融合文本特征和图像特征以生成图像[46 -52 ] . 这类改进方法为文本生成图像领域的进步提供了多种改进的思路,在先前工作的基础上获得了不少成果.DM-GAN[53 ] 在AttnGAN模型的基础上,应用动态记忆网络[54 -56 ] 架构实现文本生成图像的方法. 在初始图像生成阶段,提取文本特征合成64×64像素的低分辨率图像. 在第2阶段应用的动态记忆网络主要包含2个部分:内存写入门和响应门. 如图12 所示,内存写入门将初始阶段生成的图像和词级文本特征作为输入,结合词特征和图像特征,计算每个词的重要性权重并写入内存插槽. 执行键寻址和值读取操作,通过计算内存槽和图像特征之间的相似性概率来检索相关的内存槽;根据相似性概率,通过对值存储器的加权求和来计算输出存储器表示. 响应门动态地控制输出表示的信息流以更新图像特征,网络根据更新的图像特征细化初始阶段生成的图像. DM-GAN除了采用无条件的对抗性图像和条件性图像文本匹配损失,还使用DAMSM损失函数和CA损失函数. ...
1
... 在文本生成图像任务中,利用深度融合文本特征加强图像生成这一类型的方法更多地关注如何使模型充分融合文本特征和图像特征,生成符合文本描述的图像. 在该类型的方法中,有些用“门”机制判别更新图像特征生成图像,也有些用多个仿射变换融合文本特征和图像特征以生成图像[46 -52 ] . 这类改进方法为文本生成图像领域的进步提供了多种改进的思路,在先前工作的基础上获得了不少成果.DM-GAN[53 ] 在AttnGAN模型的基础上,应用动态记忆网络[54 -56 ] 架构实现文本生成图像的方法. 在初始图像生成阶段,提取文本特征合成64×64像素的低分辨率图像. 在第2阶段应用的动态记忆网络主要包含2个部分:内存写入门和响应门. 如图12 所示,内存写入门将初始阶段生成的图像和词级文本特征作为输入,结合词特征和图像特征,计算每个词的重要性权重并写入内存插槽. 执行键寻址和值读取操作,通过计算内存槽和图像特征之间的相似性概率来检索相关的内存槽;根据相似性概率,通过对值存储器的加权求和来计算输出存储器表示. 响应门动态地控制输出表示的信息流以更新图像特征,网络根据更新的图像特征细化初始阶段生成的图像. DM-GAN除了采用无条件的对抗性图像和条件性图像文本匹配损失,还使用DAMSM损失函数和CA损失函数. ...
基于特征增强生成对抗网络的文本生成图像方法
0
2023
基于特征增强生成对抗网络的文本生成图像方法
0
2023
1
... 在文本生成图像任务中,利用深度融合文本特征加强图像生成这一类型的方法更多地关注如何使模型充分融合文本特征和图像特征,生成符合文本描述的图像. 在该类型的方法中,有些用“门”机制判别更新图像特征生成图像,也有些用多个仿射变换融合文本特征和图像特征以生成图像[46 -52 ] . 这类改进方法为文本生成图像领域的进步提供了多种改进的思路,在先前工作的基础上获得了不少成果.DM-GAN[53 ] 在AttnGAN模型的基础上,应用动态记忆网络[54 -56 ] 架构实现文本生成图像的方法. 在初始图像生成阶段,提取文本特征合成64×64像素的低分辨率图像. 在第2阶段应用的动态记忆网络主要包含2个部分:内存写入门和响应门. 如图12 所示,内存写入门将初始阶段生成的图像和词级文本特征作为输入,结合词特征和图像特征,计算每个词的重要性权重并写入内存插槽. 执行键寻址和值读取操作,通过计算内存槽和图像特征之间的相似性概率来检索相关的内存槽;根据相似性概率,通过对值存储器的加权求和来计算输出存储器表示. 响应门动态地控制输出表示的信息流以更新图像特征,网络根据更新的图像特征细化初始阶段生成的图像. DM-GAN除了采用无条件的对抗性图像和条件性图像文本匹配损失,还使用DAMSM损失函数和CA损失函数. ...
1
... 在文本生成图像任务中,利用深度融合文本特征加强图像生成这一类型的方法更多地关注如何使模型充分融合文本特征和图像特征,生成符合文本描述的图像. 在该类型的方法中,有些用“门”机制判别更新图像特征生成图像,也有些用多个仿射变换融合文本特征和图像特征以生成图像[46 -52 ] . 这类改进方法为文本生成图像领域的进步提供了多种改进的思路,在先前工作的基础上获得了不少成果.DM-GAN[53 ] 在AttnGAN模型的基础上,应用动态记忆网络[54 -56 ] 架构实现文本生成图像的方法. 在初始图像生成阶段,提取文本特征合成64×64像素的低分辨率图像. 在第2阶段应用的动态记忆网络主要包含2个部分:内存写入门和响应门. 如图12 所示,内存写入门将初始阶段生成的图像和词级文本特征作为输入,结合词特征和图像特征,计算每个词的重要性权重并写入内存插槽. 执行键寻址和值读取操作,通过计算内存槽和图像特征之间的相似性概率来检索相关的内存槽;根据相似性概率,通过对值存储器的加权求和来计算输出存储器表示. 响应门动态地控制输出表示的信息流以更新图像特征,网络根据更新的图像特征细化初始阶段生成的图像. DM-GAN除了采用无条件的对抗性图像和条件性图像文本匹配损失,还使用DAMSM损失函数和CA损失函数. ...
2
... 在文本生成图像任务中,利用深度融合文本特征加强图像生成这一类型的方法更多地关注如何使模型充分融合文本特征和图像特征,生成符合文本描述的图像. 在该类型的方法中,有些用“门”机制判别更新图像特征生成图像,也有些用多个仿射变换融合文本特征和图像特征以生成图像[46 -52 ] . 这类改进方法为文本生成图像领域的进步提供了多种改进的思路,在先前工作的基础上获得了不少成果.DM-GAN[53 ] 在AttnGAN模型的基础上,应用动态记忆网络[54 -56 ] 架构实现文本生成图像的方法. 在初始图像生成阶段,提取文本特征合成64×64像素的低分辨率图像. 在第2阶段应用的动态记忆网络主要包含2个部分:内存写入门和响应门. 如图12 所示,内存写入门将初始阶段生成的图像和词级文本特征作为输入,结合词特征和图像特征,计算每个词的重要性权重并写入内存插槽. 执行键寻址和值读取操作,通过计算内存槽和图像特征之间的相似性概率来检索相关的内存槽;根据相似性概率,通过对值存储器的加权求和来计算输出存储器表示. 响应门动态地控制输出表示的信息流以更新图像特征,网络根据更新的图像特征细化初始阶段生成的图像. DM-GAN除了采用无条件的对抗性图像和条件性图像文本匹配损失,还使用DAMSM损失函数和CA损失函数. ...
... Comparison of various metrics for GAN-based text-to-image generation methods on different datasets
Tab.1 方法 CUB鸟类数据集 Oxford-120花卉数据集 COCO数据集 IS FID R-precision IS FID IS FID R-precision GAN-INT-CLS[2 ] 2.32 68.79 — 2.66 79.55 7.95 60.62 — StackGAN[10 ] 3.70 51.89 — 3.20 55.28 8.45 74.65 — StackGAN++[25 ] 4.04 15.30 — 3.26 48.68 8.30 — — AttnGAN[11 ] 4.36 23.98 67.83 — — 25.89 35.49 85.47 DM-GAN[53 ] 4.75 16.09 72.31 — — 30.49 32.62 88.56 ControlGAN[36 ] 4.58 — 39.33 — — 24.06 — 82.43 SEGAN[34 ] 4.67 18.16 — — — 27.86 32.28 — MirrorGAN[41 ] 4.56 — 57.67 — — 26.47 — 74.52 XMC-GAN[60 ] — — — — — 30.45 9.33 71.00 CI-GAN[66 ] 5.72 9.78 — — — — — — DF-GAN[57 ] 5.10 14.81 44.83 — — — 21.42 67.97 DiverGAN[37 ] 4.98 15.63 — 3.99 — — 20.52 — SSA-GAN[58 ] 5.17 15.61 75.9 — — — 19.37 90.60 Adam-GAN[59 ] 5.28 8.57 55.94 — — 29.07 12.39 88.74 TVBi-GAN[71 ] 5.03 11.83 — — — 31.01 31.97 — 文献[67 ]方法 4.23 11.17 — 3.71 16.47 — — — Bridge-GAN[92 ] 4.74 — — — — 16.40 — — textStyleGAN[63 ] 4.78 — 49.56 — — 33.00 — 88.23 文献[45 ]方法 3.58 18.14 — 2.90 34.97 8.94 27.07 — SD-GAN[38 ] 4.67 — — — — 35.69 — — PPAN[29 ] 4.38 — — 3.52 — — — — HfGAN[27 ] 4.48 — — 3.57 — 27.53 — — HDGAN[26 ] 4.15 — — 3.45 — 11.86 — — DSE-GAN[61 ] 5.13 13.23 53.25 — — 26.71 15.30 76.31
由于采用自回归模型和扩散模型的文本生成图像方法比采用GAN的文本生成图像方法性能优异,采用自回归模型和扩散模型的文本生成图像方法更换了新的评价指标. 如表2 所示,采用自回归模型和扩散模型的方法,在MS-COCO数据集上对FID评价指标及Zero-shot FID评价指标进行评判,这些评价指标仅在某种程度上反映各个模型的性能高低. 对于文本生成图像任务,人工评判生成图像的质量以及文本与图像的语义一致性有更高的可信度,但由于人工评价指标不统一、个人评价意见不统一,人工评判不能作为定性评价文本生成图像模型的标准. ...
Dynamic neural turing machine with continuous and discrete addressing schemes
1
2018
... 在文本生成图像任务中,利用深度融合文本特征加强图像生成这一类型的方法更多地关注如何使模型充分融合文本特征和图像特征,生成符合文本描述的图像. 在该类型的方法中,有些用“门”机制判别更新图像特征生成图像,也有些用多个仿射变换融合文本特征和图像特征以生成图像[46 -52 ] . 这类改进方法为文本生成图像领域的进步提供了多种改进的思路,在先前工作的基础上获得了不少成果.DM-GAN[53 ] 在AttnGAN模型的基础上,应用动态记忆网络[54 -56 ] 架构实现文本生成图像的方法. 在初始图像生成阶段,提取文本特征合成64×64像素的低分辨率图像. 在第2阶段应用的动态记忆网络主要包含2个部分:内存写入门和响应门. 如图12 所示,内存写入门将初始阶段生成的图像和词级文本特征作为输入,结合词特征和图像特征,计算每个词的重要性权重并写入内存插槽. 执行键寻址和值读取操作,通过计算内存槽和图像特征之间的相似性概率来检索相关的内存槽;根据相似性概率,通过对值存储器的加权求和来计算输出存储器表示. 响应门动态地控制输出表示的信息流以更新图像特征,网络根据更新的图像特征细化初始阶段生成的图像. DM-GAN除了采用无条件的对抗性图像和条件性图像文本匹配损失,还使用DAMSM损失函数和CA损失函数. ...
End-to-end memory networks
0
2015
1
... 在文本生成图像任务中,利用深度融合文本特征加强图像生成这一类型的方法更多地关注如何使模型充分融合文本特征和图像特征,生成符合文本描述的图像. 在该类型的方法中,有些用“门”机制判别更新图像特征生成图像,也有些用多个仿射变换融合文本特征和图像特征以生成图像[46 -52 ] . 这类改进方法为文本生成图像领域的进步提供了多种改进的思路,在先前工作的基础上获得了不少成果.DM-GAN[53 ] 在AttnGAN模型的基础上,应用动态记忆网络[54 -56 ] 架构实现文本生成图像的方法. 在初始图像生成阶段,提取文本特征合成64×64像素的低分辨率图像. 在第2阶段应用的动态记忆网络主要包含2个部分:内存写入门和响应门. 如图12 所示,内存写入门将初始阶段生成的图像和词级文本特征作为输入,结合词特征和图像特征,计算每个词的重要性权重并写入内存插槽. 执行键寻址和值读取操作,通过计算内存槽和图像特征之间的相似性概率来检索相关的内存槽;根据相似性概率,通过对值存储器的加权求和来计算输出存储器表示. 响应门动态地控制输出表示的信息流以更新图像特征,网络根据更新的图像特征细化初始阶段生成的图像. DM-GAN除了采用无条件的对抗性图像和条件性图像文本匹配损失,还使用DAMSM损失函数和CA损失函数. ...
2
... DF-GAN[57 ] 的提出打破了文本生成图像领域方法的惯有思维,大部分的文本生成图像方法通过以AttnGAN为基线模型进行改进时,DF-GAN方法采用单级GAN为主干网络. 该方法主要有以下3点改进. 1)如图13 所示,该方法在生成器中的每个上采样层后,以文本特征为条件对图像特征进行仿射变换. 在图像特征多尺度中融合文本特征,以增强文本与图像的语义一致性. 2)在判别器中加入匹配感知梯度惩罚损失函数,通过加入该项损失函数,判别器能够更好地收敛到文本匹配的真实数据上. 3)定义该方法的判别器为单向输出. 以往方法的判别器不仅要判断生成图像是否真实,还要判断生成图像是否与文本一致,所以该方法提出将图像特征和句子向量连接起来,直接在判别器中鉴别该生成的数据是否真实,以此加速训练至最优结果. 实验结果证明,利用该方法生成的图像不仅真实,而且文本与图像的语义一致性较强. 该方法的缺陷十分明显,即没有融合词级的文本特征,生成图像的细节不能与文本保持语义一致性. ...
... Comparison of various metrics for GAN-based text-to-image generation methods on different datasets
Tab.1 方法 CUB鸟类数据集 Oxford-120花卉数据集 COCO数据集 IS FID R-precision IS FID IS FID R-precision GAN-INT-CLS[2 ] 2.32 68.79 — 2.66 79.55 7.95 60.62 — StackGAN[10 ] 3.70 51.89 — 3.20 55.28 8.45 74.65 — StackGAN++[25 ] 4.04 15.30 — 3.26 48.68 8.30 — — AttnGAN[11 ] 4.36 23.98 67.83 — — 25.89 35.49 85.47 DM-GAN[53 ] 4.75 16.09 72.31 — — 30.49 32.62 88.56 ControlGAN[36 ] 4.58 — 39.33 — — 24.06 — 82.43 SEGAN[34 ] 4.67 18.16 — — — 27.86 32.28 — MirrorGAN[41 ] 4.56 — 57.67 — — 26.47 — 74.52 XMC-GAN[60 ] — — — — — 30.45 9.33 71.00 CI-GAN[66 ] 5.72 9.78 — — — — — — DF-GAN[57 ] 5.10 14.81 44.83 — — — 21.42 67.97 DiverGAN[37 ] 4.98 15.63 — 3.99 — — 20.52 — SSA-GAN[58 ] 5.17 15.61 75.9 — — — 19.37 90.60 Adam-GAN[59 ] 5.28 8.57 55.94 — — 29.07 12.39 88.74 TVBi-GAN[71 ] 5.03 11.83 — — — 31.01 31.97 — 文献[67 ]方法 4.23 11.17 — 3.71 16.47 — — — Bridge-GAN[92 ] 4.74 — — — — 16.40 — — textStyleGAN[63 ] 4.78 — 49.56 — — 33.00 — 88.23 文献[45 ]方法 3.58 18.14 — 2.90 34.97 8.94 27.07 — SD-GAN[38 ] 4.67 — — — — 35.69 — — PPAN[29 ] 4.38 — — 3.52 — — — — HfGAN[27 ] 4.48 — — 3.57 — 27.53 — — HDGAN[26 ] 4.15 — — 3.45 — 11.86 — — DSE-GAN[61 ] 5.13 13.23 53.25 — — 26.71 15.30 76.31
由于采用自回归模型和扩散模型的文本生成图像方法比采用GAN的文本生成图像方法性能优异,采用自回归模型和扩散模型的文本生成图像方法更换了新的评价指标. 如表2 所示,采用自回归模型和扩散模型的方法,在MS-COCO数据集上对FID评价指标及Zero-shot FID评价指标进行评判,这些评价指标仅在某种程度上反映各个模型的性能高低. 对于文本生成图像任务,人工评判生成图像的质量以及文本与图像的语义一致性有更高的可信度,但由于人工评价指标不统一、个人评价意见不统一,人工评判不能作为定性评价文本生成图像模型的标准. ...
2
... 在DF-GAN的基础上,SSA-GAN[58 ] 提出在编码器仿射变换融合文本特征时,通过无监督的方式生成图像掩码,将经过批归一化层的图像特征都乘以同分辨率的掩码,指出当前图像特征图中需要文本增强的部分. 该方法提出的掩码生成器与整个网络共同训练,没有额外的掩码注释和设定的损失函数,仅通过判别器监督掩码生成. 该方法在一定程度上弥补了DF-GAN模型无法融合词级文本特征的缺陷,实现了将文本语义特征充分融合到对应图像特征中的目的,生成语义准确的图像. ...
... Comparison of various metrics for GAN-based text-to-image generation methods on different datasets
Tab.1 方法 CUB鸟类数据集 Oxford-120花卉数据集 COCO数据集 IS FID R-precision IS FID IS FID R-precision GAN-INT-CLS[2 ] 2.32 68.79 — 2.66 79.55 7.95 60.62 — StackGAN[10 ] 3.70 51.89 — 3.20 55.28 8.45 74.65 — StackGAN++[25 ] 4.04 15.30 — 3.26 48.68 8.30 — — AttnGAN[11 ] 4.36 23.98 67.83 — — 25.89 35.49 85.47 DM-GAN[53 ] 4.75 16.09 72.31 — — 30.49 32.62 88.56 ControlGAN[36 ] 4.58 — 39.33 — — 24.06 — 82.43 SEGAN[34 ] 4.67 18.16 — — — 27.86 32.28 — MirrorGAN[41 ] 4.56 — 57.67 — — 26.47 — 74.52 XMC-GAN[60 ] — — — — — 30.45 9.33 71.00 CI-GAN[66 ] 5.72 9.78 — — — — — — DF-GAN[57 ] 5.10 14.81 44.83 — — — 21.42 67.97 DiverGAN[37 ] 4.98 15.63 — 3.99 — — 20.52 — SSA-GAN[58 ] 5.17 15.61 75.9 — — — 19.37 90.60 Adam-GAN[59 ] 5.28 8.57 55.94 — — 29.07 12.39 88.74 TVBi-GAN[71 ] 5.03 11.83 — — — 31.01 31.97 — 文献[67 ]方法 4.23 11.17 — 3.71 16.47 — — — Bridge-GAN[92 ] 4.74 — — — — 16.40 — — textStyleGAN[63 ] 4.78 — 49.56 — — 33.00 — 88.23 文献[45 ]方法 3.58 18.14 — 2.90 34.97 8.94 27.07 — SD-GAN[38 ] 4.67 — — — — 35.69 — — PPAN[29 ] 4.38 — — 3.52 — — — — HfGAN[27 ] 4.48 — — 3.57 — 27.53 — — HDGAN[26 ] 4.15 — — 3.45 — 11.86 — — DSE-GAN[61 ] 5.13 13.23 53.25 — — 26.71 15.30 76.31
由于采用自回归模型和扩散模型的文本生成图像方法比采用GAN的文本生成图像方法性能优异,采用自回归模型和扩散模型的文本生成图像方法更换了新的评价指标. 如表2 所示,采用自回归模型和扩散模型的方法,在MS-COCO数据集上对FID评价指标及Zero-shot FID评价指标进行评判,这些评价指标仅在某种程度上反映各个模型的性能高低. 对于文本生成图像任务,人工评判生成图像的质量以及文本与图像的语义一致性有更高的可信度,但由于人工评价指标不统一、个人评价意见不统一,人工评判不能作为定性评价文本生成图像模型的标准. ...
2
... Adam-GAN对DF-GAN模型进行改进[59 ] ,不同于SSA-GAN的是该方法提出使用额外的属性信息补充文本特征的方法,弥补DF-GAN模型对词级文本信息融合不足的缺陷. 具体来说,该方法是将文本生成图像任务看作属性-句子联合条件生成图像任务. 将数据集中所有可能的属性描述集合作为新数据库,使用对比学习将对应的图像特征与文本特征和属性在公共空间中拉近,通过属性-句子联合条件生成器生成图像. ...
... Comparison of various metrics for GAN-based text-to-image generation methods on different datasets
Tab.1 方法 CUB鸟类数据集 Oxford-120花卉数据集 COCO数据集 IS FID R-precision IS FID IS FID R-precision GAN-INT-CLS[2 ] 2.32 68.79 — 2.66 79.55 7.95 60.62 — StackGAN[10 ] 3.70 51.89 — 3.20 55.28 8.45 74.65 — StackGAN++[25 ] 4.04 15.30 — 3.26 48.68 8.30 — — AttnGAN[11 ] 4.36 23.98 67.83 — — 25.89 35.49 85.47 DM-GAN[53 ] 4.75 16.09 72.31 — — 30.49 32.62 88.56 ControlGAN[36 ] 4.58 — 39.33 — — 24.06 — 82.43 SEGAN[34 ] 4.67 18.16 — — — 27.86 32.28 — MirrorGAN[41 ] 4.56 — 57.67 — — 26.47 — 74.52 XMC-GAN[60 ] — — — — — 30.45 9.33 71.00 CI-GAN[66 ] 5.72 9.78 — — — — — — DF-GAN[57 ] 5.10 14.81 44.83 — — — 21.42 67.97 DiverGAN[37 ] 4.98 15.63 — 3.99 — — 20.52 — SSA-GAN[58 ] 5.17 15.61 75.9 — — — 19.37 90.60 Adam-GAN[59 ] 5.28 8.57 55.94 — — 29.07 12.39 88.74 TVBi-GAN[71 ] 5.03 11.83 — — — 31.01 31.97 — 文献[67 ]方法 4.23 11.17 — 3.71 16.47 — — — Bridge-GAN[92 ] 4.74 — — — — 16.40 — — textStyleGAN[63 ] 4.78 — 49.56 — — 33.00 — 88.23 文献[45 ]方法 3.58 18.14 — 2.90 34.97 8.94 27.07 — SD-GAN[38 ] 4.67 — — — — 35.69 — — PPAN[29 ] 4.38 — — 3.52 — — — — HfGAN[27 ] 4.48 — — 3.57 — 27.53 — — HDGAN[26 ] 4.15 — — 3.45 — 11.86 — — DSE-GAN[61 ] 5.13 13.23 53.25 — — 26.71 15.30 76.31
由于采用自回归模型和扩散模型的文本生成图像方法比采用GAN的文本生成图像方法性能优异,采用自回归模型和扩散模型的文本生成图像方法更换了新的评价指标. 如表2 所示,采用自回归模型和扩散模型的方法,在MS-COCO数据集上对FID评价指标及Zero-shot FID评价指标进行评判,这些评价指标仅在某种程度上反映各个模型的性能高低. 对于文本生成图像任务,人工评判生成图像的质量以及文本与图像的语义一致性有更高的可信度,但由于人工评价指标不统一、个人评价意见不统一,人工评判不能作为定性评价文本生成图像模型的标准. ...
2
... 针对复杂场景图像的生成,XMC-GAN[60 ] 利用对比学习的思想最大化图像区域和文本描述词、生成图像和整个文本描述、生成图像和真实图像之间的一致性,利用添加注意力机制的生成器增强图像特征与文本描述的一致性. 利用对比学习思想构建判别器,监督生成器生成质量更高、真实性更强的图像. 利用该方法不能生成有复杂场景的图像,需要进一步调整更细致、合理的正负样本对及更精细的损失函数. ...
... Comparison of various metrics for GAN-based text-to-image generation methods on different datasets
Tab.1 方法 CUB鸟类数据集 Oxford-120花卉数据集 COCO数据集 IS FID R-precision IS FID IS FID R-precision GAN-INT-CLS[2 ] 2.32 68.79 — 2.66 79.55 7.95 60.62 — StackGAN[10 ] 3.70 51.89 — 3.20 55.28 8.45 74.65 — StackGAN++[25 ] 4.04 15.30 — 3.26 48.68 8.30 — — AttnGAN[11 ] 4.36 23.98 67.83 — — 25.89 35.49 85.47 DM-GAN[53 ] 4.75 16.09 72.31 — — 30.49 32.62 88.56 ControlGAN[36 ] 4.58 — 39.33 — — 24.06 — 82.43 SEGAN[34 ] 4.67 18.16 — — — 27.86 32.28 — MirrorGAN[41 ] 4.56 — 57.67 — — 26.47 — 74.52 XMC-GAN[60 ] — — — — — 30.45 9.33 71.00 CI-GAN[66 ] 5.72 9.78 — — — — — — DF-GAN[57 ] 5.10 14.81 44.83 — — — 21.42 67.97 DiverGAN[37 ] 4.98 15.63 — 3.99 — — 20.52 — SSA-GAN[58 ] 5.17 15.61 75.9 — — — 19.37 90.60 Adam-GAN[59 ] 5.28 8.57 55.94 — — 29.07 12.39 88.74 TVBi-GAN[71 ] 5.03 11.83 — — — 31.01 31.97 — 文献[67 ]方法 4.23 11.17 — 3.71 16.47 — — — Bridge-GAN[92 ] 4.74 — — — — 16.40 — — textStyleGAN[63 ] 4.78 — 49.56 — — 33.00 — 88.23 文献[45 ]方法 3.58 18.14 — 2.90 34.97 8.94 27.07 — SD-GAN[38 ] 4.67 — — — — 35.69 — — PPAN[29 ] 4.38 — — 3.52 — — — — HfGAN[27 ] 4.48 — — 3.57 — 27.53 — — HDGAN[26 ] 4.15 — — 3.45 — 11.86 — — DSE-GAN[61 ] 5.13 13.23 53.25 — — 26.71 15.30 76.31
由于采用自回归模型和扩散模型的文本生成图像方法比采用GAN的文本生成图像方法性能优异,采用自回归模型和扩散模型的文本生成图像方法更换了新的评价指标. 如表2 所示,采用自回归模型和扩散模型的方法,在MS-COCO数据集上对FID评价指标及Zero-shot FID评价指标进行评判,这些评价指标仅在某种程度上反映各个模型的性能高低. 对于文本生成图像任务,人工评判生成图像的质量以及文本与图像的语义一致性有更高的可信度,但由于人工评价指标不统一、个人评价意见不统一,人工评判不能作为定性评价文本生成图像模型的标准. ...
2
... Huang等[61 ] 提出动态语义进化(DSE)模块,该模块旨在生成图像时能够动态地调整语义. 具体而言,DSE模块根据生成反馈来聚合每一阶段的图像特征,根据每个阶段的生成需求动态选择需要重新组合的单词,通过动态增强或抑制不同粒度子空间的语义来重新组合这些单词. 该方法还提出新的单一对抗性多阶段架构(SAMA),它通过消除多个复杂的对抗性训练需求来扩展之前的结构. 这使得模型能够进行更多的文本-图像交互,为DSE模块的学习提供更多的机会. ...
... Comparison of various metrics for GAN-based text-to-image generation methods on different datasets
Tab.1 方法 CUB鸟类数据集 Oxford-120花卉数据集 COCO数据集 IS FID R-precision IS FID IS FID R-precision GAN-INT-CLS[2 ] 2.32 68.79 — 2.66 79.55 7.95 60.62 — StackGAN[10 ] 3.70 51.89 — 3.20 55.28 8.45 74.65 — StackGAN++[25 ] 4.04 15.30 — 3.26 48.68 8.30 — — AttnGAN[11 ] 4.36 23.98 67.83 — — 25.89 35.49 85.47 DM-GAN[53 ] 4.75 16.09 72.31 — — 30.49 32.62 88.56 ControlGAN[36 ] 4.58 — 39.33 — — 24.06 — 82.43 SEGAN[34 ] 4.67 18.16 — — — 27.86 32.28 — MirrorGAN[41 ] 4.56 — 57.67 — — 26.47 — 74.52 XMC-GAN[60 ] — — — — — 30.45 9.33 71.00 CI-GAN[66 ] 5.72 9.78 — — — — — — DF-GAN[57 ] 5.10 14.81 44.83 — — — 21.42 67.97 DiverGAN[37 ] 4.98 15.63 — 3.99 — — 20.52 — SSA-GAN[58 ] 5.17 15.61 75.9 — — — 19.37 90.60 Adam-GAN[59 ] 5.28 8.57 55.94 — — 29.07 12.39 88.74 TVBi-GAN[71 ] 5.03 11.83 — — — 31.01 31.97 — 文献[67 ]方法 4.23 11.17 — 3.71 16.47 — — — Bridge-GAN[92 ] 4.74 — — — — 16.40 — — textStyleGAN[63 ] 4.78 — 49.56 — — 33.00 — 88.23 文献[45 ]方法 3.58 18.14 — 2.90 34.97 8.94 27.07 — SD-GAN[38 ] 4.67 — — — — 35.69 — — PPAN[29 ] 4.38 — — 3.52 — — — — HfGAN[27 ] 4.48 — — 3.57 — 27.53 — — HDGAN[26 ] 4.15 — — 3.45 — 11.86 — — DSE-GAN[61 ] 5.13 13.23 53.25 — — 26.71 15.30 76.31
由于采用自回归模型和扩散模型的文本生成图像方法比采用GAN的文本生成图像方法性能优异,采用自回归模型和扩散模型的文本生成图像方法更换了新的评价指标. 如表2 所示,采用自回归模型和扩散模型的方法,在MS-COCO数据集上对FID评价指标及Zero-shot FID评价指标进行评判,这些评价指标仅在某种程度上反映各个模型的性能高低. 对于文本生成图像任务,人工评判生成图像的质量以及文本与图像的语义一致性有更高的可信度,但由于人工评价指标不统一、个人评价意见不统一,人工评判不能作为定性评价文本生成图像模型的标准. ...
2
... 随着无条件图像生成[23 ,62 ] 的效果越来越突出,多项工作提出将这些无条件模型的架构改进用于有条件的文本生成图像任务. 由于利用无条件图像生成方法能够生成高质量的图像,该类型的改进方法关注如何融合文字特征和图像特征以及使用图像编辑的原理,在生成的图像上按照文字描述修改图像生成. 这些改进后的文本生成图像方法普遍都具有生成图像分辨率高的优点,但是有十分明显的缺点,即使用模型架构大,训练环境要求高,训练速度慢,文字图像匹配度低. ...
... Souza等[67 ] 提出的方法改进了BigGAN[62 ] 模型,用于文本生成图像的合成. 他们提出新颖的句插值法(SI),即利用所有与特定图像相对应的文本来创建插值句,用于增大文本数据量. 与StackGAN所提出的CA相比,SI是确定性的函数,该方法加强了插值文本的随机性,优化了服从高斯分布的Kullback-Leibler(KL)散度. Rombach等[68 ] 训练可逆网络[69 -70 ] 来融合预训练好的BERT和BigGAN,在两个网络之间进行对齐并重用于文本到图像的合成. 这是非常有前景的研究方向, 可以重用训练成本较高的专家网络,用于其他任务. ...
2
... textStyleGAN[63 ] 对StyleGAN[23 ] 模型进行调整改进,使得该任务不仅保留了StyleGAN允许进行语义操作的特性,还保留了StyleGAN模型生成超高分辨率图像的优点. 如图14 所示,该方法使用预训练的图像文本匹配网络,将句子和词特征融合到图像特征中,在生成器中利用词特征和图像特征进行注意力引导. 除了判别器中的无条件和条件损失外,该方法还使用跨模态投影匹配(CMPM)和跨模态投影分类(CMPC)损失[64 ] ,引导文字与生成的图像对齐. 作为早期采用改进无条件模型的文本生成图像任务,该方法模型架构大,训练环境要求高,训练速度慢,与文本描述不能保持语义一致性. 如何克服无条件模型的随机性,更好地融合文本特征是早期改进无条件模型进行文本生成图像任务的首要改进方向. ...
... Comparison of various metrics for GAN-based text-to-image generation methods on different datasets
Tab.1 方法 CUB鸟类数据集 Oxford-120花卉数据集 COCO数据集 IS FID R-precision IS FID IS FID R-precision GAN-INT-CLS[2 ] 2.32 68.79 — 2.66 79.55 7.95 60.62 — StackGAN[10 ] 3.70 51.89 — 3.20 55.28 8.45 74.65 — StackGAN++[25 ] 4.04 15.30 — 3.26 48.68 8.30 — — AttnGAN[11 ] 4.36 23.98 67.83 — — 25.89 35.49 85.47 DM-GAN[53 ] 4.75 16.09 72.31 — — 30.49 32.62 88.56 ControlGAN[36 ] 4.58 — 39.33 — — 24.06 — 82.43 SEGAN[34 ] 4.67 18.16 — — — 27.86 32.28 — MirrorGAN[41 ] 4.56 — 57.67 — — 26.47 — 74.52 XMC-GAN[60 ] — — — — — 30.45 9.33 71.00 CI-GAN[66 ] 5.72 9.78 — — — — — — DF-GAN[57 ] 5.10 14.81 44.83 — — — 21.42 67.97 DiverGAN[37 ] 4.98 15.63 — 3.99 — — 20.52 — SSA-GAN[58 ] 5.17 15.61 75.9 — — — 19.37 90.60 Adam-GAN[59 ] 5.28 8.57 55.94 — — 29.07 12.39 88.74 TVBi-GAN[71 ] 5.03 11.83 — — — 31.01 31.97 — 文献[67 ]方法 4.23 11.17 — 3.71 16.47 — — — Bridge-GAN[92 ] 4.74 — — — — 16.40 — — textStyleGAN[63 ] 4.78 — 49.56 — — 33.00 — 88.23 文献[45 ]方法 3.58 18.14 — 2.90 34.97 8.94 27.07 — SD-GAN[38 ] 4.67 — — — — 35.69 — — PPAN[29 ] 4.38 — — 3.52 — — — — HfGAN[27 ] 4.48 — — 3.57 — 27.53 — — HDGAN[26 ] 4.15 — — 3.45 — 11.86 — — DSE-GAN[61 ] 5.13 13.23 53.25 — — 26.71 15.30 76.31
由于采用自回归模型和扩散模型的文本生成图像方法比采用GAN的文本生成图像方法性能优异,采用自回归模型和扩散模型的文本生成图像方法更换了新的评价指标. 如表2 所示,采用自回归模型和扩散模型的方法,在MS-COCO数据集上对FID评价指标及Zero-shot FID评价指标进行评判,这些评价指标仅在某种程度上反映各个模型的性能高低. 对于文本生成图像任务,人工评判生成图像的质量以及文本与图像的语义一致性有更高的可信度,但由于人工评价指标不统一、个人评价意见不统一,人工评判不能作为定性评价文本生成图像模型的标准. ...
1
... textStyleGAN[63 ] 对StyleGAN[23 ] 模型进行调整改进,使得该任务不仅保留了StyleGAN允许进行语义操作的特性,还保留了StyleGAN模型生成超高分辨率图像的优点. 如图14 所示,该方法使用预训练的图像文本匹配网络,将句子和词特征融合到图像特征中,在生成器中利用词特征和图像特征进行注意力引导. 除了判别器中的无条件和条件损失外,该方法还使用跨模态投影匹配(CMPM)和跨模态投影分类(CMPC)损失[64 ] ,引导文字与生成的图像对齐. 作为早期采用改进无条件模型的文本生成图像任务,该方法模型架构大,训练环境要求高,训练速度慢,与文本描述不能保持语义一致性. 如何克服无条件模型的随机性,更好地融合文本特征是早期改进无条件模型进行文本生成图像任务的首要改进方向. ...
1
... TediGAN[65 ] 是由文本指导的反演GAN,该方法将图像属性特征和相应的文本特征映射至预训练StyleGAN样式空间中,通过拉近它们之间的距离,使得网络学习到对应的图像和文本特征,以生成符合文本描述的图像,利用预训练的StyleGAN保证生成图像的多样性. 相对于基于循环神经网络和卷积神经网络的跨模态对齐方式,TediGAN的方法更简洁且易于训练. 它将文本和真实图像投影到预训练的样式空间中,避免了复杂的模态对齐过程. TediGAN的生成能力受限于预训练的StyleGAN模型. 该方法在小数据集上进行预训练,可能导致反演模型的泛化能力不足的问题. ...
2
... Wang等[66 ] 提出将文本转化为适应潜在空间的向量表示,利用这些向量来调整StyleGAN模型的潜在向量,生成具有所需语义属性的图像. 通过优化潜在向量,CI-GAN能够在生成图像时更好地控制图像的语义特征,使生成的图像更加符合输入文本所描述的语义属性. ...
... Comparison of various metrics for GAN-based text-to-image generation methods on different datasets
Tab.1 方法 CUB鸟类数据集 Oxford-120花卉数据集 COCO数据集 IS FID R-precision IS FID IS FID R-precision GAN-INT-CLS[2 ] 2.32 68.79 — 2.66 79.55 7.95 60.62 — StackGAN[10 ] 3.70 51.89 — 3.20 55.28 8.45 74.65 — StackGAN++[25 ] 4.04 15.30 — 3.26 48.68 8.30 — — AttnGAN[11 ] 4.36 23.98 67.83 — — 25.89 35.49 85.47 DM-GAN[53 ] 4.75 16.09 72.31 — — 30.49 32.62 88.56 ControlGAN[36 ] 4.58 — 39.33 — — 24.06 — 82.43 SEGAN[34 ] 4.67 18.16 — — — 27.86 32.28 — MirrorGAN[41 ] 4.56 — 57.67 — — 26.47 — 74.52 XMC-GAN[60 ] — — — — — 30.45 9.33 71.00 CI-GAN[66 ] 5.72 9.78 — — — — — — DF-GAN[57 ] 5.10 14.81 44.83 — — — 21.42 67.97 DiverGAN[37 ] 4.98 15.63 — 3.99 — — 20.52 — SSA-GAN[58 ] 5.17 15.61 75.9 — — — 19.37 90.60 Adam-GAN[59 ] 5.28 8.57 55.94 — — 29.07 12.39 88.74 TVBi-GAN[71 ] 5.03 11.83 — — — 31.01 31.97 — 文献[67 ]方法 4.23 11.17 — 3.71 16.47 — — — Bridge-GAN[92 ] 4.74 — — — — 16.40 — — textStyleGAN[63 ] 4.78 — 49.56 — — 33.00 — 88.23 文献[45 ]方法 3.58 18.14 — 2.90 34.97 8.94 27.07 — SD-GAN[38 ] 4.67 — — — — 35.69 — — PPAN[29 ] 4.38 — — 3.52 — — — — HfGAN[27 ] 4.48 — — 3.57 — 27.53 — — HDGAN[26 ] 4.15 — — 3.45 — 11.86 — — DSE-GAN[61 ] 5.13 13.23 53.25 — — 26.71 15.30 76.31
由于采用自回归模型和扩散模型的文本生成图像方法比采用GAN的文本生成图像方法性能优异,采用自回归模型和扩散模型的文本生成图像方法更换了新的评价指标. 如表2 所示,采用自回归模型和扩散模型的方法,在MS-COCO数据集上对FID评价指标及Zero-shot FID评价指标进行评判,这些评价指标仅在某种程度上反映各个模型的性能高低. 对于文本生成图像任务,人工评判生成图像的质量以及文本与图像的语义一致性有更高的可信度,但由于人工评价指标不统一、个人评价意见不统一,人工评判不能作为定性评价文本生成图像模型的标准. ...
2
... Souza等[67 ] 提出的方法改进了BigGAN[62 ] 模型,用于文本生成图像的合成. 他们提出新颖的句插值法(SI),即利用所有与特定图像相对应的文本来创建插值句,用于增大文本数据量. 与StackGAN所提出的CA相比,SI是确定性的函数,该方法加强了插值文本的随机性,优化了服从高斯分布的Kullback-Leibler(KL)散度. Rombach等[68 ] 训练可逆网络[69 -70 ] 来融合预训练好的BERT和BigGAN,在两个网络之间进行对齐并重用于文本到图像的合成. 这是非常有前景的研究方向, 可以重用训练成本较高的专家网络,用于其他任务. ...
... Comparison of various metrics for GAN-based text-to-image generation methods on different datasets
Tab.1 方法 CUB鸟类数据集 Oxford-120花卉数据集 COCO数据集 IS FID R-precision IS FID IS FID R-precision GAN-INT-CLS[2 ] 2.32 68.79 — 2.66 79.55 7.95 60.62 — StackGAN[10 ] 3.70 51.89 — 3.20 55.28 8.45 74.65 — StackGAN++[25 ] 4.04 15.30 — 3.26 48.68 8.30 — — AttnGAN[11 ] 4.36 23.98 67.83 — — 25.89 35.49 85.47 DM-GAN[53 ] 4.75 16.09 72.31 — — 30.49 32.62 88.56 ControlGAN[36 ] 4.58 — 39.33 — — 24.06 — 82.43 SEGAN[34 ] 4.67 18.16 — — — 27.86 32.28 — MirrorGAN[41 ] 4.56 — 57.67 — — 26.47 — 74.52 XMC-GAN[60 ] — — — — — 30.45 9.33 71.00 CI-GAN[66 ] 5.72 9.78 — — — — — — DF-GAN[57 ] 5.10 14.81 44.83 — — — 21.42 67.97 DiverGAN[37 ] 4.98 15.63 — 3.99 — — 20.52 — SSA-GAN[58 ] 5.17 15.61 75.9 — — — 19.37 90.60 Adam-GAN[59 ] 5.28 8.57 55.94 — — 29.07 12.39 88.74 TVBi-GAN[71 ] 5.03 11.83 — — — 31.01 31.97 — 文献[67 ]方法 4.23 11.17 — 3.71 16.47 — — — Bridge-GAN[92 ] 4.74 — — — — 16.40 — — textStyleGAN[63 ] 4.78 — 49.56 — — 33.00 — 88.23 文献[45 ]方法 3.58 18.14 — 2.90 34.97 8.94 27.07 — SD-GAN[38 ] 4.67 — — — — 35.69 — — PPAN[29 ] 4.38 — — 3.52 — — — — HfGAN[27 ] 4.48 — — 3.57 — 27.53 — — HDGAN[26 ] 4.15 — — 3.45 — 11.86 — — DSE-GAN[61 ] 5.13 13.23 53.25 — — 26.71 15.30 76.31
由于采用自回归模型和扩散模型的文本生成图像方法比采用GAN的文本生成图像方法性能优异,采用自回归模型和扩散模型的文本生成图像方法更换了新的评价指标. 如表2 所示,采用自回归模型和扩散模型的方法,在MS-COCO数据集上对FID评价指标及Zero-shot FID评价指标进行评判,这些评价指标仅在某种程度上反映各个模型的性能高低. 对于文本生成图像任务,人工评判生成图像的质量以及文本与图像的语义一致性有更高的可信度,但由于人工评价指标不统一、个人评价意见不统一,人工评判不能作为定性评价文本生成图像模型的标准. ...
Network-to-network translation with conditional invertible neural networks
1
2020
... Souza等[67 ] 提出的方法改进了BigGAN[62 ] 模型,用于文本生成图像的合成. 他们提出新颖的句插值法(SI),即利用所有与特定图像相对应的文本来创建插值句,用于增大文本数据量. 与StackGAN所提出的CA相比,SI是确定性的函数,该方法加强了插值文本的随机性,优化了服从高斯分布的Kullback-Leibler(KL)散度. Rombach等[68 ] 训练可逆网络[69 -70 ] 来融合预训练好的BERT和BigGAN,在两个网络之间进行对齐并重用于文本到图像的合成. 这是非常有前景的研究方向, 可以重用训练成本较高的专家网络,用于其他任务. ...
1
... Souza等[67 ] 提出的方法改进了BigGAN[62 ] 模型,用于文本生成图像的合成. 他们提出新颖的句插值法(SI),即利用所有与特定图像相对应的文本来创建插值句,用于增大文本数据量. 与StackGAN所提出的CA相比,SI是确定性的函数,该方法加强了插值文本的随机性,优化了服从高斯分布的Kullback-Leibler(KL)散度. Rombach等[68 ] 训练可逆网络[69 -70 ] 来融合预训练好的BERT和BigGAN,在两个网络之间进行对齐并重用于文本到图像的合成. 这是非常有前景的研究方向, 可以重用训练成本较高的专家网络,用于其他任务. ...
1
... Souza等[67 ] 提出的方法改进了BigGAN[62 ] 模型,用于文本生成图像的合成. 他们提出新颖的句插值法(SI),即利用所有与特定图像相对应的文本来创建插值句,用于增大文本数据量. 与StackGAN所提出的CA相比,SI是确定性的函数,该方法加强了插值文本的随机性,优化了服从高斯分布的Kullback-Leibler(KL)散度. Rombach等[68 ] 训练可逆网络[69 -70 ] 来融合预训练好的BERT和BigGAN,在两个网络之间进行对齐并重用于文本到图像的合成. 这是非常有前景的研究方向, 可以重用训练成本较高的专家网络,用于其他任务. ...
2
... Wang等[71 ] 采用BigGAN[72 ] 的架构,使用改进后的DM-GAN的门机制,即在应用注意机制前计算词特征和文本特征间的重要性权重. 此外,提出类似于SD-GAN的语义增强批归一化,通过注入随机噪声来减小文本特征对生成图像细节的调整力度. ...
... Comparison of various metrics for GAN-based text-to-image generation methods on different datasets
Tab.1 方法 CUB鸟类数据集 Oxford-120花卉数据集 COCO数据集 IS FID R-precision IS FID IS FID R-precision GAN-INT-CLS[2 ] 2.32 68.79 — 2.66 79.55 7.95 60.62 — StackGAN[10 ] 3.70 51.89 — 3.20 55.28 8.45 74.65 — StackGAN++[25 ] 4.04 15.30 — 3.26 48.68 8.30 — — AttnGAN[11 ] 4.36 23.98 67.83 — — 25.89 35.49 85.47 DM-GAN[53 ] 4.75 16.09 72.31 — — 30.49 32.62 88.56 ControlGAN[36 ] 4.58 — 39.33 — — 24.06 — 82.43 SEGAN[34 ] 4.67 18.16 — — — 27.86 32.28 — MirrorGAN[41 ] 4.56 — 57.67 — — 26.47 — 74.52 XMC-GAN[60 ] — — — — — 30.45 9.33 71.00 CI-GAN[66 ] 5.72 9.78 — — — — — — DF-GAN[57 ] 5.10 14.81 44.83 — — — 21.42 67.97 DiverGAN[37 ] 4.98 15.63 — 3.99 — — 20.52 — SSA-GAN[58 ] 5.17 15.61 75.9 — — — 19.37 90.60 Adam-GAN[59 ] 5.28 8.57 55.94 — — 29.07 12.39 88.74 TVBi-GAN[71 ] 5.03 11.83 — — — 31.01 31.97 — 文献[67 ]方法 4.23 11.17 — 3.71 16.47 — — — Bridge-GAN[92 ] 4.74 — — — — 16.40 — — textStyleGAN[63 ] 4.78 — 49.56 — — 33.00 — 88.23 文献[45 ]方法 3.58 18.14 — 2.90 34.97 8.94 27.07 — SD-GAN[38 ] 4.67 — — — — 35.69 — — PPAN[29 ] 4.38 — — 3.52 — — — — HfGAN[27 ] 4.48 — — 3.57 — 27.53 — — HDGAN[26 ] 4.15 — — 3.45 — 11.86 — — DSE-GAN[61 ] 5.13 13.23 53.25 — — 26.71 15.30 76.31
由于采用自回归模型和扩散模型的文本生成图像方法比采用GAN的文本生成图像方法性能优异,采用自回归模型和扩散模型的文本生成图像方法更换了新的评价指标. 如表2 所示,采用自回归模型和扩散模型的方法,在MS-COCO数据集上对FID评价指标及Zero-shot FID评价指标进行评判,这些评价指标仅在某种程度上反映各个模型的性能高低. 对于文本生成图像任务,人工评判生成图像的质量以及文本与图像的语义一致性有更高的可信度,但由于人工评价指标不统一、个人评价意见不统一,人工评判不能作为定性评价文本生成图像模型的标准. ...
1
... Wang等[71 ] 采用BigGAN[72 ] 的架构,使用改进后的DM-GAN的门机制,即在应用注意机制前计算词特征和文本特征间的重要性权重. 此外,提出类似于SD-GAN的语义增强批归一化,通过注入随机噪声来减小文本特征对生成图像细节的调整力度. ...
2
... 百度公司研究人员设计的自回归双向生成模型ERNIE-ViLG[73 ] 可以完成文本生成图像任务,也可以开展图像生成文本任务. 具体的实现过程如图15 所示. 图中,前半部分($\text{Image} \to \text{Text}$ $\text{Text} \to \text{Image}$
... Comparison of text-to-image generation methods based on autoregressive model architecture and diffusion model architecture
Tab.2 方法 MS-COCO数据集 FID Zero-shot FID DALL-E[15 ] — 28.0 ERNIE-ViLG[73 ] — 14.7 CogView [16 ] — 27.1 CogView2[17 ] 17.7 24.0 Parti[18 ] 3.22 7.23 KNN-Diffusion[75 ] 16.66 — GLIDE[76 ] — 12.24 DALL-E 2[77 ] — 10.39 Imagen[78 ] — 7.27 Stable Diffusion[79 ] — 12.63 Re-Imagen[19 ] 5.25 6.88
5. 结 语 本文介绍了近年来各类文本生成图像方法、数据集和评价指标,探讨了当前本领域所面临的挑战. 将文本生成图像现有方法划分为以下3类:基于生成对抗网络、自回归模型和扩散模型的方法. 将基于生成对抗网络的方法归类为6个方面的技术改进总结. 详细分析了各种方法,使用常见的评估方法评价这些方法. ...
1
... 在推出引导扩散模型后,为了使图像能够按照更细致的信息进行细粒度生成,Liu等[74 ] 提出将分类器更换为其他判别器,根据不同语义信息引导扩散模型去噪. 这种方法不需要额外训练扩散模型,直接在原有的扩散模型上通过额外判别器引导生成期望的图像. 在该方法中利用文本条件引导图像生成部分,采用CLIP模型衡量生成的图像与文本语义的一致性,通过余弦距离度量文本与图像之间的相似性. 该方法还对送入扩散模型逆向过程的图像进行微调,使得模型更适应CLIP编码网络. ...
2
... 鉴于扩散模型需要大量的图像文本对进行预训练,若要进一步提升模型生成图像的质量和文本一致性,则需要更多的数据或者更高效的文本特征和图像特征提取并匹配的算法. Sheynin等[75 ] 提出在扩散模型中引入大规模检索方法,帮助模型学习更丰富的文本特征和图像特征. 不论是训练阶段还是推理阶段,该方法都采用CLIP模型作为多模态文本图像编码器,还加入K-近邻算法(K-nearest-neighbors,KNN)以检索拥有相近特征的图像,将检索到的图像与文本图像对一起输入到模型中学习. 该方法通过大量实验证明,使用额外知识库可以减小模型学习新知识的难度,快速得到新模型. ...
... Comparison of text-to-image generation methods based on autoregressive model architecture and diffusion model architecture
Tab.2 方法 MS-COCO数据集 FID Zero-shot FID DALL-E[15 ] — 28.0 ERNIE-ViLG[73 ] — 14.7 CogView [16 ] — 27.1 CogView2[17 ] 17.7 24.0 Parti[18 ] 3.22 7.23 KNN-Diffusion[75 ] 16.66 — GLIDE[76 ] — 12.24 DALL-E 2[77 ] — 10.39 Imagen[78 ] — 7.27 Stable Diffusion[79 ] — 12.63 Re-Imagen[19 ] 5.25 6.88
5. 结 语 本文介绍了近年来各类文本生成图像方法、数据集和评价指标,探讨了当前本领域所面临的挑战. 将文本生成图像现有方法划分为以下3类:基于生成对抗网络、自回归模型和扩散模型的方法. 将基于生成对抗网络的方法归类为6个方面的技术改进总结. 详细分析了各种方法,使用常见的评估方法评价这些方法. ...
2
... Nichol等[76 ] 受类别引导扩散模型的影响,将控制生成图像的条件更换为文本信息. 通过训练海量的图像文本对,将输入的文本描述等价为原本模型中的标签. 与Semantic Guidance Diffusion模型不同的是,GLIDE加强了Semantic Guidance Diffusion模型中的文本生成图像任务,舍弃了其他与文本图像相关的多模态任务. 与其他的改进扩散模型方法相比,GLIDE模型花费了更多的训练成本和时间,拥有了更可观的图像生成结果. ...
... Comparison of text-to-image generation methods based on autoregressive model architecture and diffusion model architecture
Tab.2 方法 MS-COCO数据集 FID Zero-shot FID DALL-E[15 ] — 28.0 ERNIE-ViLG[73 ] — 14.7 CogView [16 ] — 27.1 CogView2[17 ] 17.7 24.0 Parti[18 ] 3.22 7.23 KNN-Diffusion[75 ] 16.66 — GLIDE[76 ] — 12.24 DALL-E 2[77 ] — 10.39 Imagen[78 ] — 7.27 Stable Diffusion[79 ] — 12.63 Re-Imagen[19 ] 5.25 6.88
5. 结 语 本文介绍了近年来各类文本生成图像方法、数据集和评价指标,探讨了当前本领域所面临的挑战. 将文本生成图像现有方法划分为以下3类:基于生成对抗网络、自回归模型和扩散模型的方法. 将基于生成对抗网络的方法归类为6个方面的技术改进总结. 详细分析了各种方法,使用常见的评估方法评价这些方法. ...
2
... OpenAI团队在扩散模型的影响下,推出了效果更加优秀的DALL-E 2[77 ] 模型,该模型利用CLIP文本和图像的特征生成图像,可以看作是CLIP的逆过程,所以该模型被称为unCLIP模型. 该方法如图17 所示. 图中,上半部分是CLIP,通过编码器编码成对的文本图像对,获取相对应的真实图像特征和文本特征;下半部分是DALL-E 2的主体部分,由prior和decoder 2个阶段构成. 在prior阶段,DALL-E 2会根据得到的文本特征生成对应的图像特征,在训练过程中,该模型会与上半部分的真实图像文本对进行比较调整. 在decoder阶段,通过解码器解码图像特征,生成对应的图像. 具体的DALL-E 2细节还有很多,但本质上大型的模型和海量的数据使得该模型能够生成高清优质图像. ...
... Comparison of text-to-image generation methods based on autoregressive model architecture and diffusion model architecture
Tab.2 方法 MS-COCO数据集 FID Zero-shot FID DALL-E[15 ] — 28.0 ERNIE-ViLG[73 ] — 14.7 CogView [16 ] — 27.1 CogView2[17 ] 17.7 24.0 Parti[18 ] 3.22 7.23 KNN-Diffusion[75 ] 16.66 — GLIDE[76 ] — 12.24 DALL-E 2[77 ] — 10.39 Imagen[78 ] — 7.27 Stable Diffusion[79 ] — 12.63 Re-Imagen[19 ] 5.25 6.88
5. 结 语 本文介绍了近年来各类文本生成图像方法、数据集和评价指标,探讨了当前本领域所面临的挑战. 将文本生成图像现有方法划分为以下3类:基于生成对抗网络、自回归模型和扩散模型的方法. 将基于生成对抗网络的方法归类为6个方面的技术改进总结. 详细分析了各种方法,使用常见的评估方法评价这些方法. ...
Photorealistic text-to-image diffusion models with deep language understanding
2
2022
... Saharia等[78 ] 提出应该更加关注扩散模型的文本编码器,Imagen模型发现更好地理解文本特征对于文本生成图像任务十分重要. 采用预训练好的大型语言模型会产生更优质的效果,该模型在不增加图像生成模型大小的基础上增加文本编码模型,提高生成图像的质量. 与DALL-E 2模型相比,Imagen模型生成图像的正确率更高. 谷歌公司由于伦理道德的原因,未开源该模型,但他们提出的改进方向对后续文本生成图像任务方法的进一步优化提供了帮助. ...
... Comparison of text-to-image generation methods based on autoregressive model architecture and diffusion model architecture
Tab.2 方法 MS-COCO数据集 FID Zero-shot FID DALL-E[15 ] — 28.0 ERNIE-ViLG[73 ] — 14.7 CogView [16 ] — 27.1 CogView2[17 ] 17.7 24.0 Parti[18 ] 3.22 7.23 KNN-Diffusion[75 ] 16.66 — GLIDE[76 ] — 12.24 DALL-E 2[77 ] — 10.39 Imagen[78 ] — 7.27 Stable Diffusion[79 ] — 12.63 Re-Imagen[19 ] 5.25 6.88
5. 结 语 本文介绍了近年来各类文本生成图像方法、数据集和评价指标,探讨了当前本领域所面临的挑战. 将文本生成图像现有方法划分为以下3类:基于生成对抗网络、自回归模型和扩散模型的方法. 将基于生成对抗网络的方法归类为6个方面的技术改进总结. 详细分析了各种方法,使用常见的评估方法评价这些方法. ...
2
... Stable Diffusion在2022年8月由慕尼黑大学推出[79 ] ,该模型在低维的隐式特征空间中应用扩散模型,使得生成图像的速度更快. 不同于DALL-E 2和Imagen直接编辑图像像素生成图像,Stable Diffusion使用变分自编码器将图像压缩到潜空间中,减小图像的特征表示. 在训练过程中,该模型不像传统的扩散模型添加噪声,而是在潜空间中随机生成张量,直接对图像特征进行扩散重构. 真实的自然图像在一定程度上有着很强的规律性,每类图像都有特定的空间关系,所以直接对潜空间采用扩散模型生成图像特征,使得该方法不会丢失图像的特征;由于图像需要学习的形状减少,生成图像的速度大幅度提升. ...
... Comparison of text-to-image generation methods based on autoregressive model architecture and diffusion model architecture
Tab.2 方法 MS-COCO数据集 FID Zero-shot FID DALL-E[15 ] — 28.0 ERNIE-ViLG[73 ] — 14.7 CogView [16 ] — 27.1 CogView2[17 ] 17.7 24.0 Parti[18 ] 3.22 7.23 KNN-Diffusion[75 ] 16.66 — GLIDE[76 ] — 12.24 DALL-E 2[77 ] — 10.39 Imagen[78 ] — 7.27 Stable Diffusion[79 ] — 12.63 Re-Imagen[19 ] 5.25 6.88
5. 结 语 本文介绍了近年来各类文本生成图像方法、数据集和评价指标,探讨了当前本领域所面临的挑战. 将文本生成图像现有方法划分为以下3类:基于生成对抗网络、自回归模型和扩散模型的方法. 将基于生成对抗网络的方法归类为6个方面的技术改进总结. 详细分析了各种方法,使用常见的评估方法评价这些方法. ...
1
... 之前的种种改进使得现有模型可以对普通物体的描述文本生成超高质量图像,但无法使这些模型生成罕见物体,它们生成图像的内容显得十分杂乱. 谷歌公司发现了这个问题,提出Re-Imagen[19 ] ,通过检索信息的方式来生成稀少物体的图像,甚至是模型从未见过的物体图像. 在该模型中,主体的生成架构延用Imagen模型. 该模型添加了额外的外部数据库用以检索相关的文本图像对,这些信息被当成文本描述的参考信息一起生成图像. 为了平衡检索到的信息和文本描述信息,该方法定义了新的采样方式,用2个不同的权重参数决定文本描述和检索信息对生成图像的影响程度.在采样时以选定的比例轮换使用2个参数,通过调节比例,平衡文本条件和检索信息的重要性. 通过一系列细节上的微调,Re-Imagen成为当前文本生成图像任务中效果最好的模型,不论是生成图像的质量还是图像与文本的一致性,Re-Imagen都取得了当前最优异的成绩. Ruiz等[80 -83 ] 采用大模型的方法,采取扩大网络模型或采用更大规模的数据集的策略以提升性能,改进不大. ...
Attend-and-excite: attention-based semantic guidance for text-to-image diffusion models
0
2023
1
... 之前的种种改进使得现有模型可以对普通物体的描述文本生成超高质量图像,但无法使这些模型生成罕见物体,它们生成图像的内容显得十分杂乱. 谷歌公司发现了这个问题,提出Re-Imagen[19 ] ,通过检索信息的方式来生成稀少物体的图像,甚至是模型从未见过的物体图像. 在该模型中,主体的生成架构延用Imagen模型. 该模型添加了额外的外部数据库用以检索相关的文本图像对,这些信息被当成文本描述的参考信息一起生成图像. 为了平衡检索到的信息和文本描述信息,该方法定义了新的采样方式,用2个不同的权重参数决定文本描述和检索信息对生成图像的影响程度.在采样时以选定的比例轮换使用2个参数,通过调节比例,平衡文本条件和检索信息的重要性. 通过一系列细节上的微调,Re-Imagen成为当前文本生成图像任务中效果最好的模型,不论是生成图像的质量还是图像与文本的一致性,Re-Imagen都取得了当前最优异的成绩. Ruiz等[80 -83 ] 采用大模型的方法,采取扩大网络模型或采用更大规模的数据集的策略以提升性能,改进不大. ...
1
... 在文本生成图像的应用中,数据集的构成分为图像集和对应文本描述集. 图像集主要存放编有编号的图片,图片的名称即为图像对应的编号;文本集主要存放对应编号图像的文本描述句子,对应图像描述文本名称为图像编号. 该任务常用的数据集有Oxford-120[84 ] 花卉数据集、CUB-200[85 ] 鸟类数据集、CelebA-HQ[86 ] 人像数据集及COCO[87 ] 场景数据集,具体示例如图18 所示. ...
1
... 在文本生成图像的应用中,数据集的构成分为图像集和对应文本描述集. 图像集主要存放编有编号的图片,图片的名称即为图像对应的编号;文本集主要存放对应编号图像的文本描述句子,对应图像描述文本名称为图像编号. 该任务常用的数据集有Oxford-120[84 ] 花卉数据集、CUB-200[85 ] 鸟类数据集、CelebA-HQ[86 ] 人像数据集及COCO[87 ] 场景数据集,具体示例如图18 所示. ...
1
... 在文本生成图像的应用中,数据集的构成分为图像集和对应文本描述集. 图像集主要存放编有编号的图片,图片的名称即为图像对应的编号;文本集主要存放对应编号图像的文本描述句子,对应图像描述文本名称为图像编号. 该任务常用的数据集有Oxford-120[84 ] 花卉数据集、CUB-200[85 ] 鸟类数据集、CelebA-HQ[86 ] 人像数据集及COCO[87 ] 场景数据集,具体示例如图18 所示. ...
1
... 在文本生成图像的应用中,数据集的构成分为图像集和对应文本描述集. 图像集主要存放编有编号的图片,图片的名称即为图像对应的编号;文本集主要存放对应编号图像的文本描述句子,对应图像描述文本名称为图像编号. 该任务常用的数据集有Oxford-120[84 ] 花卉数据集、CUB-200[85 ] 鸟类数据集、CelebA-HQ[86 ] 人像数据集及COCO[87 ] 场景数据集,具体示例如图18 所示. ...
Adversarial text-to-image synthesis: a review
1
2021
... CelebA-HQ人像数据集是大型人脸图像高清数据集[88 ] ,有大约30 000张高清的名人人脸图像,每张图像有对应的草图、描述文本及分割掩码,被用于有关人脸图像的多种不同任务. 与Oxford-120花卉数据集、CUB-200鸟类数据集和COCO数据集相比,该数据集被少数方法应用. ...
1
... 在早期基于GAN的文本生成图像任务中,通常采用初始分数[89 ] (inception score,IS)、Fréchet初始距离[90 ] (Fréchet inception distance, FID)以及R-precision[91 ] 指标,定性评估不同文本生成图像模型的生成效果. 在基于自回归模型架构和扩散模型架构的文本生成图像任务中,通常采用FID评价指标和零样本Fréchet初始距离(Zero-shot FID),为评价模型性能的优劣提供参考意见. ...
1
... 在早期基于GAN的文本生成图像任务中,通常采用初始分数[89 ] (inception score,IS)、Fréchet初始距离[90 ] (Fréchet inception distance, FID)以及R-precision[91 ] 指标,定性评估不同文本生成图像模型的生成效果. 在基于自回归模型架构和扩散模型架构的文本生成图像任务中,通常采用FID评价指标和零样本Fréchet初始距离(Zero-shot FID),为评价模型性能的优劣提供参考意见. ...
1
... 在早期基于GAN的文本生成图像任务中,通常采用初始分数[89 ] (inception score,IS)、Fréchet初始距离[90 ] (Fréchet inception distance, FID)以及R-precision[91 ] 指标,定性评估不同文本生成图像模型的生成效果. 在基于自回归模型架构和扩散模型架构的文本生成图像任务中,通常采用FID评价指标和零样本Fréchet初始距离(Zero-shot FID),为评价模型性能的优劣提供参考意见. ...
Bridge-GAN: interpretable representation learning for text-to-image synthesis
1
2019
... Comparison of various metrics for GAN-based text-to-image generation methods on different datasets
Tab.1 方法 CUB鸟类数据集 Oxford-120花卉数据集 COCO数据集 IS FID R-precision IS FID IS FID R-precision GAN-INT-CLS[2 ] 2.32 68.79 — 2.66 79.55 7.95 60.62 — StackGAN[10 ] 3.70 51.89 — 3.20 55.28 8.45 74.65 — StackGAN++[25 ] 4.04 15.30 — 3.26 48.68 8.30 — — AttnGAN[11 ] 4.36 23.98 67.83 — — 25.89 35.49 85.47 DM-GAN[53 ] 4.75 16.09 72.31 — — 30.49 32.62 88.56 ControlGAN[36 ] 4.58 — 39.33 — — 24.06 — 82.43 SEGAN[34 ] 4.67 18.16 — — — 27.86 32.28 — MirrorGAN[41 ] 4.56 — 57.67 — — 26.47 — 74.52 XMC-GAN[60 ] — — — — — 30.45 9.33 71.00 CI-GAN[66 ] 5.72 9.78 — — — — — — DF-GAN[57 ] 5.10 14.81 44.83 — — — 21.42 67.97 DiverGAN[37 ] 4.98 15.63 — 3.99 — — 20.52 — SSA-GAN[58 ] 5.17 15.61 75.9 — — — 19.37 90.60 Adam-GAN[59 ] 5.28 8.57 55.94 — — 29.07 12.39 88.74 TVBi-GAN[71 ] 5.03 11.83 — — — 31.01 31.97 — 文献[67 ]方法 4.23 11.17 — 3.71 16.47 — — — Bridge-GAN[92 ] 4.74 — — — — 16.40 — — textStyleGAN[63 ] 4.78 — 49.56 — — 33.00 — 88.23 文献[45 ]方法 3.58 18.14 — 2.90 34.97 8.94 27.07 — SD-GAN[38 ] 4.67 — — — — 35.69 — — PPAN[29 ] 4.38 — — 3.52 — — — — HfGAN[27 ] 4.48 — — 3.57 — 27.53 — — HDGAN[26 ] 4.15 — — 3.45 — 11.86 — — DSE-GAN[61 ] 5.13 13.23 53.25 — — 26.71 15.30 76.31
由于采用自回归模型和扩散模型的文本生成图像方法比采用GAN的文本生成图像方法性能优异,采用自回归模型和扩散模型的文本生成图像方法更换了新的评价指标. 如表2 所示,采用自回归模型和扩散模型的方法,在MS-COCO数据集上对FID评价指标及Zero-shot FID评价指标进行评判,这些评价指标仅在某种程度上反映各个模型的性能高低. 对于文本生成图像任务,人工评判生成图像的质量以及文本与图像的语义一致性有更高的可信度,但由于人工评价指标不统一、个人评价意见不统一,人工评判不能作为定性评价文本生成图像模型的标准. ...


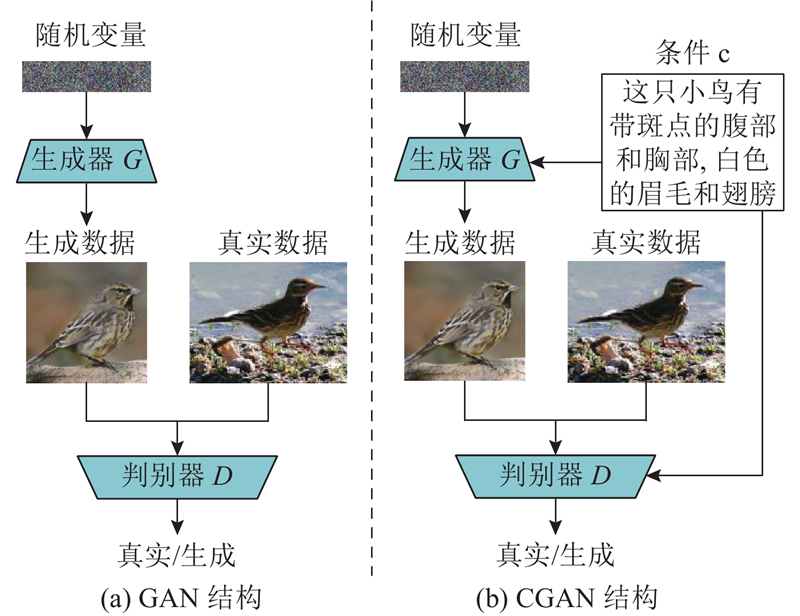

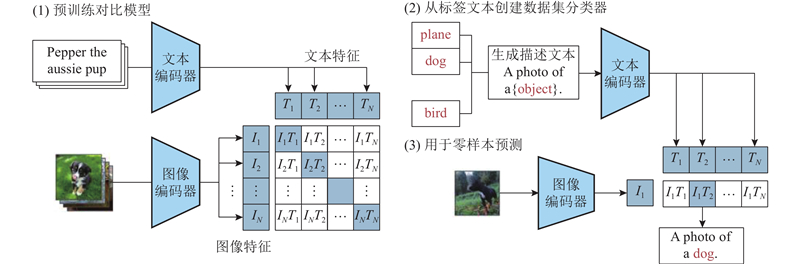
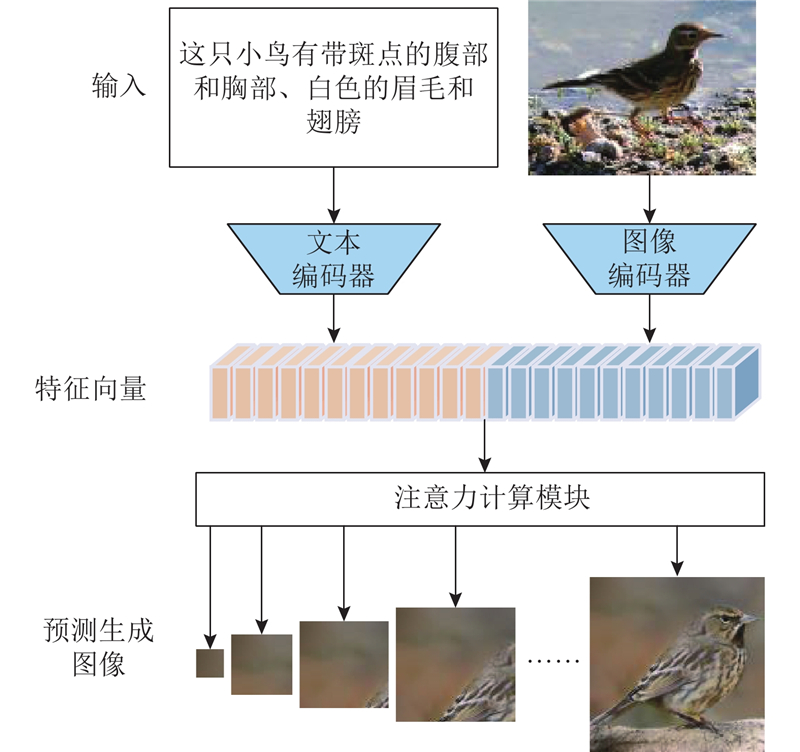

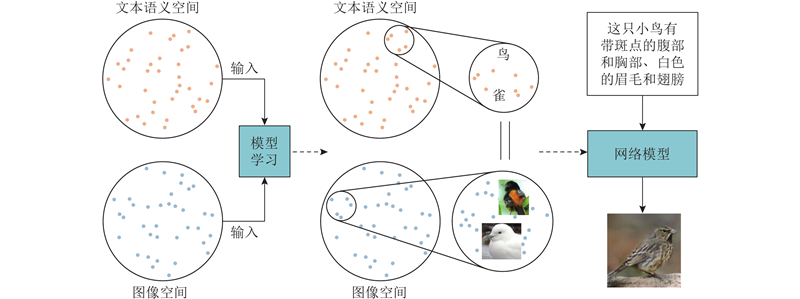
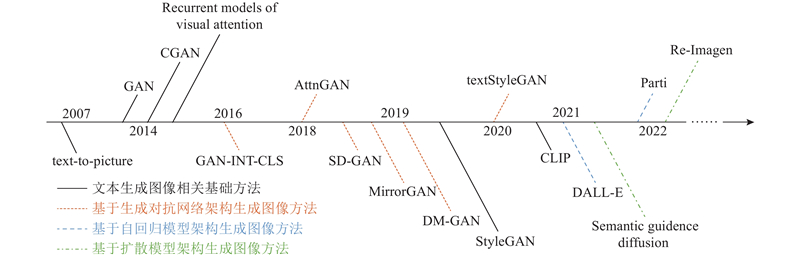
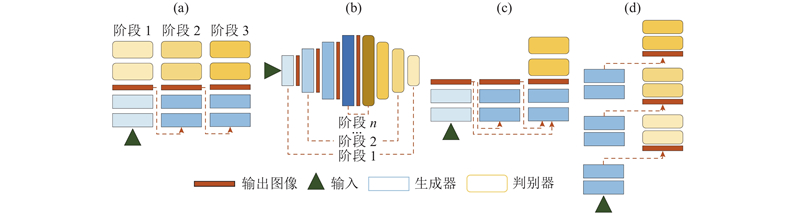
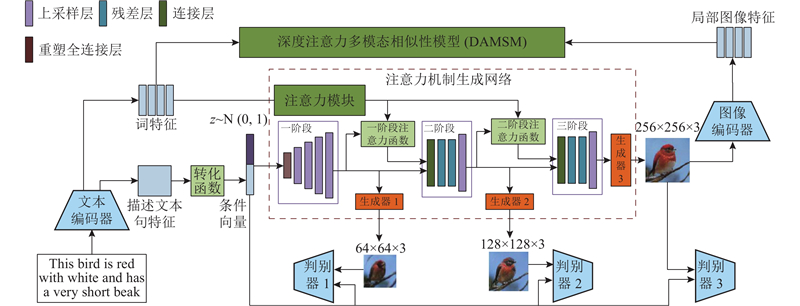
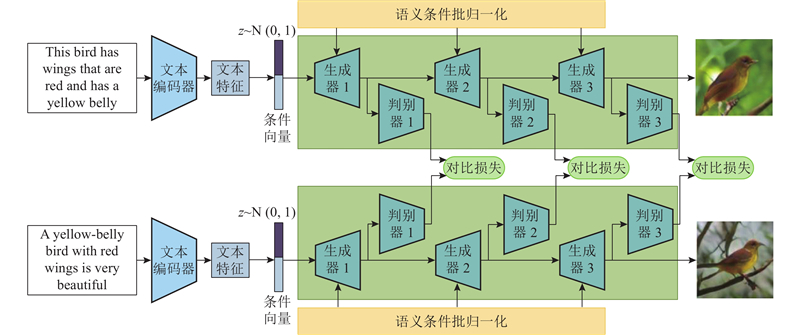
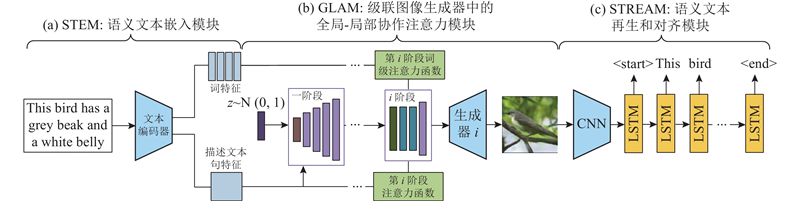
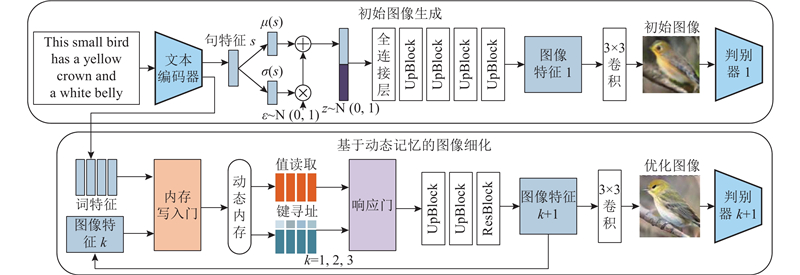
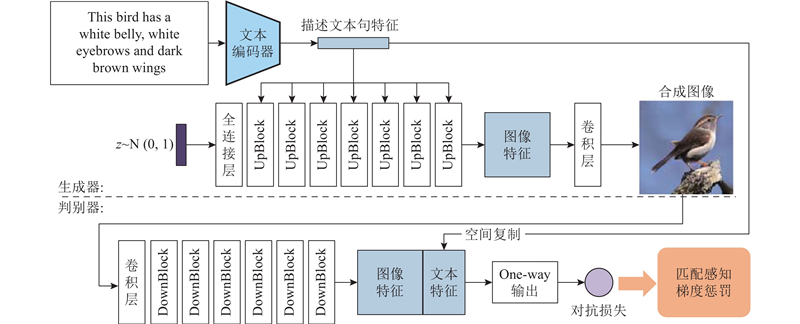
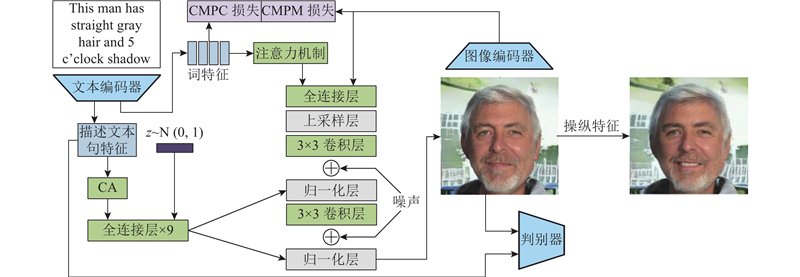
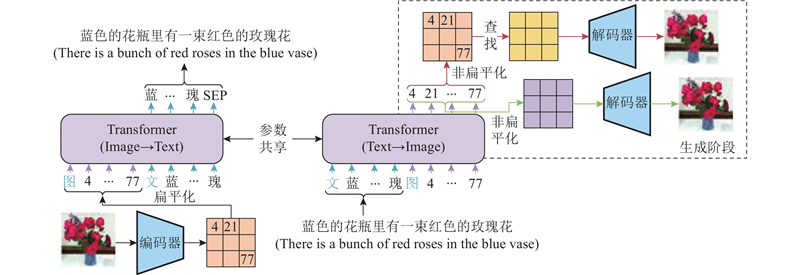
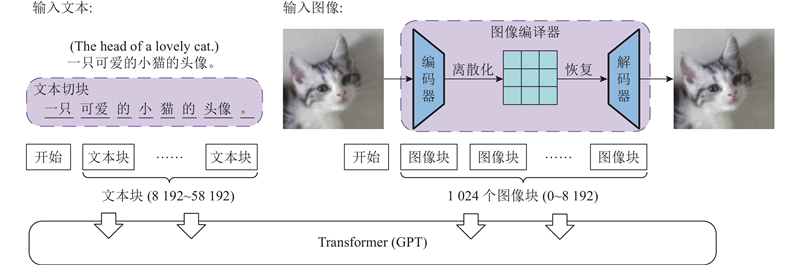
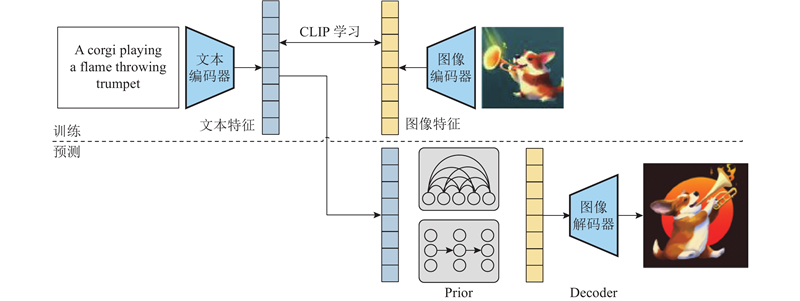

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}