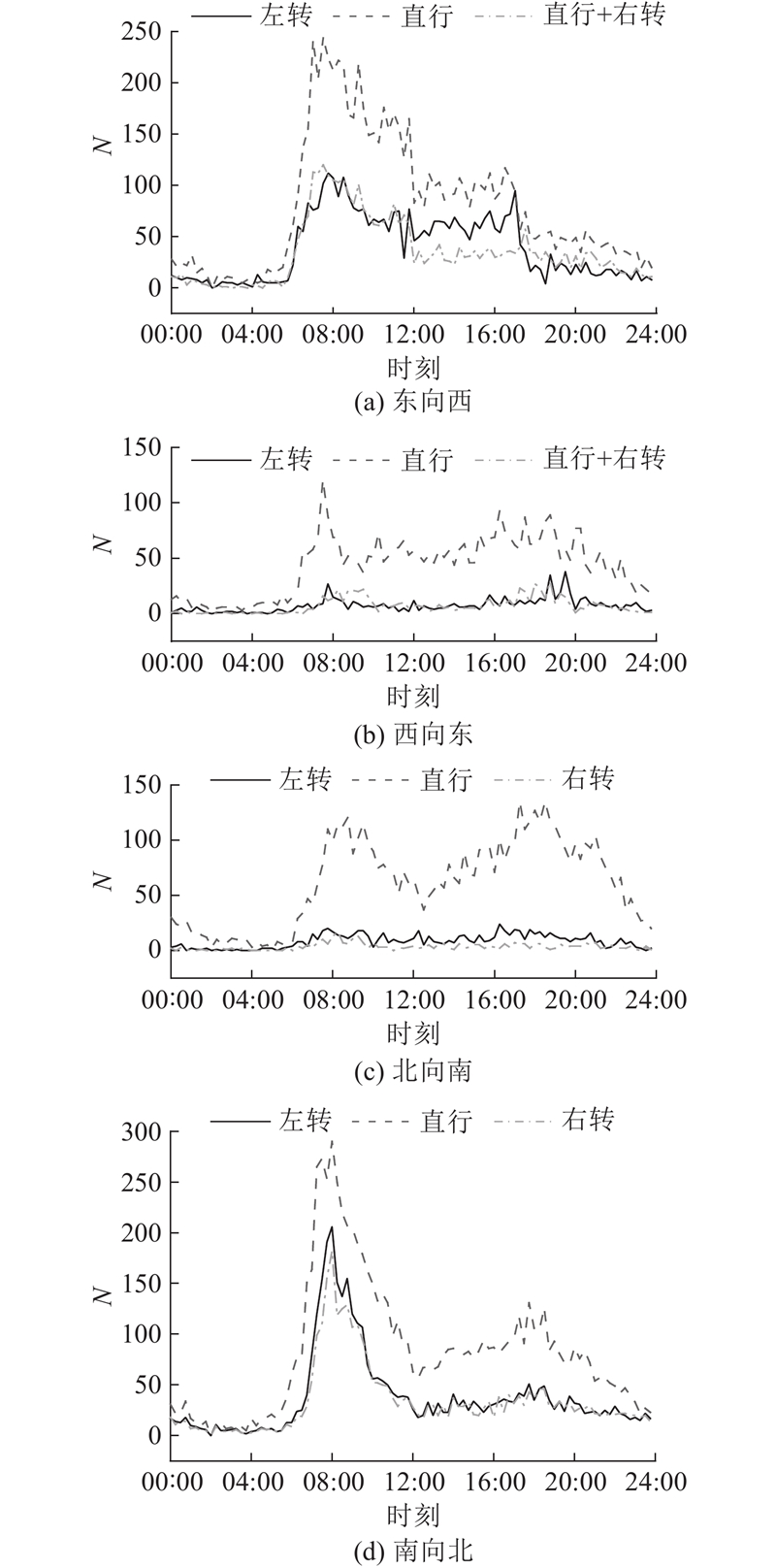
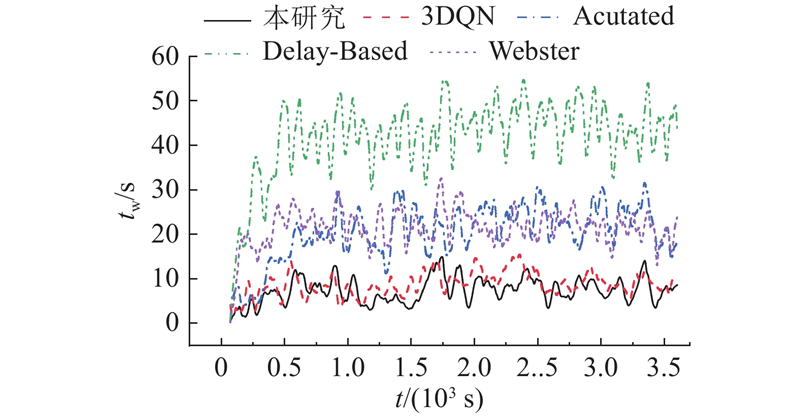
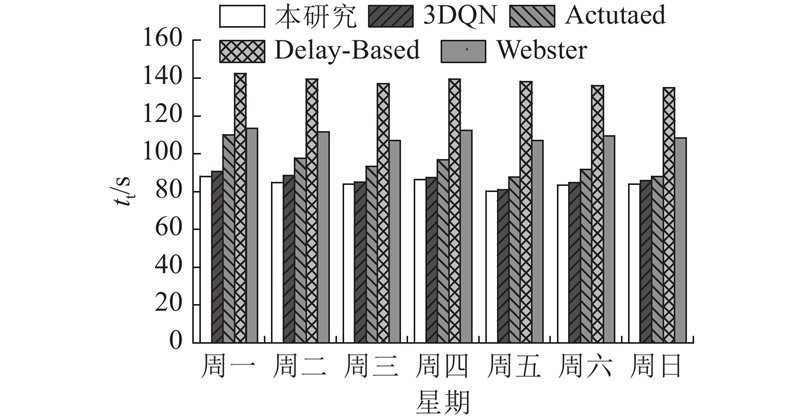
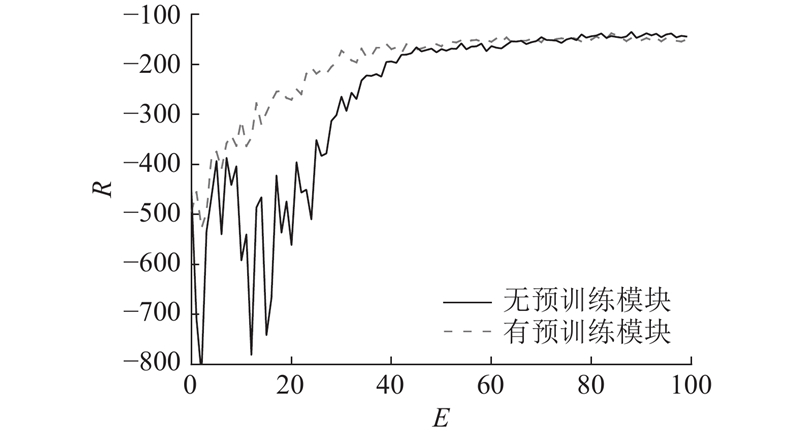
| 交通工程 |
|

|
|
|
| 结合领域经验的深度强化学习信号控制方法 |
张萌( ),王殿海,金盛*() ),王殿海,金盛*() |
| 浙江大学 建筑工程学院,浙江 杭州 310058 |
|
| Deep reinforcement learning approach to signal control combined with domain experience |
| Meng ZHANG(),Dian-hai WANG,Sheng JIN*() |
| College of Civil Engineering and Architecture, Zhejiang University, Hangzhou 310058, China |
| 1 |
WEBSTER F V. Traffic signal settings [R]. London: Road Research Laboratory, 1958.
|
| 2 |
罗小芹, 王殿海, 金盛 面向混合交通的感应式交通信号控制方法[J]. 吉林大学学报: 工学版, 2019, 49 (3): 695- 704
LUO Xiao-qin, WANG Dian-hai, JIN Sheng Traffic signal actuated control at isolated intersections for heterogeneous traffic[J]. Journal of Jilin University: Engineering and Technology Edition, 2019, 49 (3): 695- 704
|
| 3 |
HUNT P, ROBERTSON D, BRETHERTON R, et al The SCOOT on-line traffic signal optimisation technique[J]. Traffic Engineering and Control, 1982, 23 (4): 190- 192
|
| 4 |
GENDERS W, RAZAVI S. Using a deep reinforcement learning agent for traffic signal control [EB/OL]. (2016-11-03) [2023-03-12]. https://arxiv.org/pdf/1611.01142v1.pdf.
|
| 5 |
LI L, LV Y, WANG F Y Traffic signal timing via deep reinforcement learning[J]. IEEE/CAA Journal of Automatica Sinica, 2016, 3 (3): 247- 254
doi: 10.1109/JAS.2016.7508798
|
| 6 |
GAO J, SHEN Y, LIU J, et al. Adaptive traffic signal control: deep reinforcement learning algorithm with experience replay and target network [EB/OL]. (2017-05-08) [2023-03-12]. https://arxiv.org/pdf/1705.02755.pdf.
|
| 7 |
MOUSAVI S S, SCHUKAT M, HOWLEY E Traffic light control using deep policy-gradient and value-function-based reinforcement learning[J]. IET Intelligent Transport Systems, 2017, 11 (7): 417- 423
doi: 10.1049/iet-its.2017.0153
|
| 8 |
WEI H, ZHENG G, YAO H, et al. IntelliLight: a reinforcement learning approach for intelligent traffic light control [C]// Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. [S.l.]: ACM, 2018: 2496-2505.
|
| 9 |
LIANG X, DU X, WANG G, et al A deep reinforcement learning network for traffic light cycle control[J]. IEEE Transactions on Vehicular Technology, 2019, 68 (2): 1243- 1253
doi: 10.1109/TVT.2018.2890726
|
| 10 |
WANG Z, SCHAUL T, HESSEL M, et al. Dueling network architectures for deep reinforcement learning [C]// International Conference on Machine Learning. [S.l.]: Journal of Machine Learning Research, 2016: 1995-2003.
|
| 11 |
孙浩, 陈春林, 刘琼, 等 基于深度强化学习的交通信号控制方法[J]. 计算机科学, 2020, 47 (2): 169- 174
SUN Hao, CHEN Chun-lin, LIU Qiong, et al Traffic signal control method based on deep reinforcement learning[J]. Computer Science, 2020, 47 (2): 169- 174
|
| 12 |
刘志, 曹诗鹏, 沈阳, 等 基于改进深度强化学习方法的单交叉口信号控制[J]. 计算机科学, 2020, 47 (12): 226- 232
LIU Zhi, CAO Shi-peng, SHEN Yang, et al Signal control of single intersection based on improved deep reinforcement learning method[J]. Computer Science, 2020, 47 (12): 226- 232
|
| 13 |
刘智敏, 叶宝林, 朱耀东, 等 基于深度强化学习的交通信号控制方法[J]. 浙江大学学报: 工学版, 2022, 56 (6): 1249- 1256
LIU Zhi-min, YE Bao-lin, ZHU Yao-dong, et al Traffic signal control method based on deep reinforcement learning[J]. Journal of Zhejiang University: Engineering Science, 2022, 56 (6): 1249- 1256
|
| 14 |
赵乾, 张灵, 赵刚, 等 双环相位结构约束下的强化学习交通信号控制方法[J]. 交通运输工程与信息学报, 2023, 21 (1): 19- 28
ZHAO Qian, ZHANG Ling, ZHAO Gang, et al Reinforcement learning traffic signal control under double-loop phase-structure constraints[J]. Journal of Transportation Engineering and Information, 2023, 21 (1): 19- 28
doi: 10.19961/j.cnki.1672-4747.2022.05.010
|
| 15 |
CHU T, WANG J, CODECÀ L, et al Multi-agent deep reinforcement learning for large-scale traffic signal control[J]. IEEE Transactions on Intelligent Transportation Systems, 2019, 21 (3): 1086- 1095
|
| 16 |
LI Z, YU H, ZHANG G, et al Network-wide traffic signal control optimization using a multi-agent deep reinforcement learning[J]. Transportation Research Part C: Emerging Technologies, 2021, 125: 103059
doi: 10.1016/j.trc.2021.103059
|
| 17 |
ZHENG G, ZANG X, XU N, et al. Diagnosing reinforcement learning for traffic signal control [EB/OL]. (2019-05-12) [2023-03-12]. https://arxiv.org/pdf/1905.04716.pdf.
|
| 18 |
WEI H, CHEN C, ZHENG G, et al. PressLight: learning max pressure control to coordinate traffic signals in arterial network [C]// Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. [S.l.]: ACM, 2019: 1290-1298.
|
| 19 |
HESTER T, VECERIK M, PIETQUIN O, et al. Deep Q-learning from demonstrations [C]// Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence. [S.l.]: AAAI Press, 2018: 3223-3230.
|
| 20 |
VARAIYA P. The max-pressure controller for arbitrary networks of signalized intersections [M]// UKKUSURI S, OZBAY K. Advances in dynamic network modeling in complex transportation systems. [S.l.]: Springer, 2013: 27-66.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|