[1]
WEBSTER F V. Traffic signal settings [R]. London: Road Research Laboratory, 1958.
[本文引用: 1]
[2]
罗小芹, 王殿海, 金盛 面向混合交通的感应式交通信号控制方法
[J]. 吉林大学学报: 工学版 , 2019 , 49 (3 ): 695 - 704
[本文引用: 1]
LUO Xiao-qin, WANG Dian-hai, JIN Sheng Traffic signal actuated control at isolated intersections for heterogeneous traffic
[J]. Journal of Jilin University: Engineering and Technology Edition , 2019 , 49 (3 ): 695 - 704
[本文引用: 1]
[3]
HUNT P, ROBERTSON D, BRETHERTON R, et al The SCOOT on-line traffic signal optimisation technique
[J]. Traffic Engineering and Control , 1982 , 23 (4 ): 190 - 192
[本文引用: 1]
[4]
GENDERS W, RAZAVI S. Using a deep reinforcement learning agent for traffic signal control [EB/OL]. (2016-11-03) [2023-03-12]. https://arxiv.org/pdf/1611.01142v1.pdf.
[本文引用: 2]
[5]
LI L, LV Y, WANG F Y Traffic signal timing via deep reinforcement learning
[J]. IEEE/CAA Journal of Automatica Sinica , 2016 , 3 (3 ): 247 - 254
DOI:10.1109/JAS.2016.7508798
[本文引用: 1]
[6]
GAO J, SHEN Y, LIU J, et al. Adaptive traffic signal control: deep reinforcement learning algorithm with experience replay and target network [EB/OL]. (2017-05-08) [2023-03-12]. https://arxiv.org/pdf/1705.02755.pdf.
[本文引用: 1]
[7]
MOUSAVI S S, SCHUKAT M, HOWLEY E Traffic light control using deep policy-gradient and value-function-based reinforcement learning
[J]. IET Intelligent Transport Systems , 2017 , 11 (7 ): 417 - 423
DOI:10.1049/iet-its.2017.0153
[本文引用: 1]
[8]
WEI H, ZHENG G, YAO H, et al. IntelliLight: a reinforcement learning approach for intelligent traffic light control [C]// Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining . [S.l.]: ACM, 2018: 2496-2505.
[本文引用: 1]
[9]
LIANG X, DU X, WANG G, et al A deep reinforcement learning network for traffic light cycle control
[J]. IEEE Transactions on Vehicular Technology , 2019 , 68 (2 ): 1243 - 1253
DOI:10.1109/TVT.2018.2890726
[本文引用: 1]
[10]
WANG Z, SCHAUL T, HESSEL M, et al. Dueling network architectures for deep reinforcement learning [C]// International Conference on Machine Learning . [S.l.]: Journal of Machine Learning Research, 2016: 1995-2003.
[本文引用: 1]
[11]
孙浩, 陈春林, 刘琼, 等 基于深度强化学习的交通信号控制方法
[J]. 计算机科学 , 2020 , 47 (2 ): 169 - 174
[本文引用: 1]
SUN Hao, CHEN Chun-lin, LIU Qiong, et al Traffic signal control method based on deep reinforcement learning
[J]. Computer Science , 2020 , 47 (2 ): 169 - 174
[本文引用: 1]
[12]
刘志, 曹诗鹏, 沈阳, 等 基于改进深度强化学习方法的单交叉口信号控制
[J]. 计算机科学 , 2020 , 47 (12 ): 226 - 232
[本文引用: 1]
LIU Zhi, CAO Shi-peng, SHEN Yang, et al Signal control of single intersection based on improved deep reinforcement learning method
[J]. Computer Science , 2020 , 47 (12 ): 226 - 232
[本文引用: 1]
[13]
刘智敏, 叶宝林, 朱耀东, 等 基于深度强化学习的交通信号控制方法
[J]. 浙江大学学报: 工学版 , 2022 , 56 (6 ): 1249 - 1256
[本文引用: 2]
LIU Zhi-min, YE Bao-lin, ZHU Yao-dong, et al Traffic signal control method based on deep reinforcement learning
[J]. Journal of Zhejiang University: Engineering Science , 2022 , 56 (6 ): 1249 - 1256
[本文引用: 2]
[14]
赵乾, 张灵, 赵刚, 等 双环相位结构约束下的强化学习交通信号控制方法
[J]. 交通运输工程与信息学报 , 2023 , 21 (1 ): 19 - 28
DOI:10.19961/j.cnki.1672-4747.2022.05.010
[本文引用: 1]
ZHAO Qian, ZHANG Ling, ZHAO Gang, et al Reinforcement learning traffic signal control under double-loop phase-structure constraints
[J]. Journal of Transportation Engineering and Information , 2023 , 21 (1 ): 19 - 28
DOI:10.19961/j.cnki.1672-4747.2022.05.010
[本文引用: 1]
[15]
CHU T, WANG J, CODECÀ L, et al Multi-agent deep reinforcement learning for large-scale traffic signal control
[J]. IEEE Transactions on Intelligent Transportation Systems , 2019 , 21 (3 ): 1086 - 1095
[本文引用: 1]
[16]
LI Z, YU H, ZHANG G, et al Network-wide traffic signal control optimization using a multi-agent deep reinforcement learning
[J]. Transportation Research Part C: Emerging Technologies , 2021 , 125 : 103059
DOI:10.1016/j.trc.2021.103059
[本文引用: 1]
[17]
ZHENG G, ZANG X, XU N, et al. Diagnosing reinforcement learning for traffic signal control [EB/OL]. (2019-05-12) [2023-03-12]. https://arxiv.org/pdf/1905.04716.pdf.
[本文引用: 3]
[18]
WEI H, CHEN C, ZHENG G, et al. PressLight: learning max pressure control to coordinate traffic signals in arterial network [C]// Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining . [S.l.]: ACM, 2019: 1290-1298.
[本文引用: 1]
[19]
HESTER T, VECERIK M, PIETQUIN O, et al. Deep Q-learning from demonstrations [C]// Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence . [S.l.]: AAAI Press, 2018: 3223-3230.
[本文引用: 1]
[20]
VARAIYA P. The max-pressure controller for arbitrary networks of signalized intersections [M]// UKKUSURI S, OZBAY K. Advances in dynamic network modeling in complex transportation systems . [S.l.]: Springer, 2013: 27-66.
[本文引用: 1]
[21]
OERTEL R, WAGNER P. Delay-time actuated traffic signal control for an isolated intersection [C]// Proceedings 90th Annual Meeting Transportation Research Board . Washington: [s.n.], 2011.
[本文引用: 1]
1
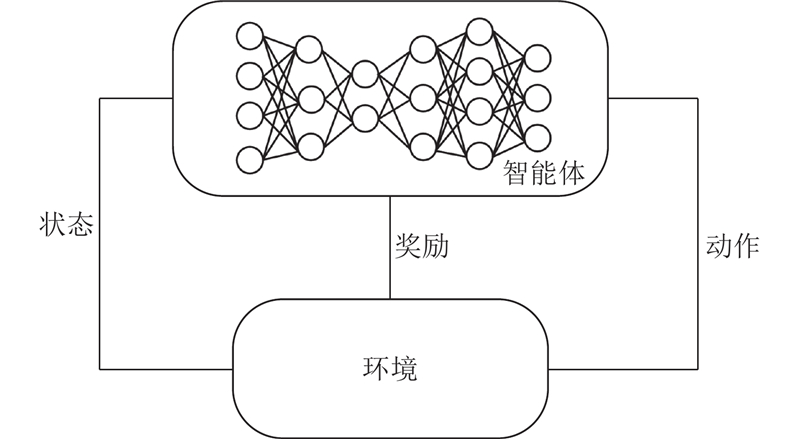
... 针对交叉口信号优化控制的研究按照控制方法可划分为3类:基于历史交通流数据的预定时信号控制[1 ] ,基于实时交通状态的响应控制(包括感应控制[2 ] 、自适应控制[3 ] )以及基于模型的协调控制. 采用上述方法进行优化交叉口信号控制存在一定的理想假设,具有一定的局限性. 随着人工智能技术和交通信息采集技术的发展,通过数据驱动实现信号控制成为交叉口信号优化的新发展方向. ...
面向混合交通的感应式交通信号控制方法
1
2019
... 针对交叉口信号优化控制的研究按照控制方法可划分为3类:基于历史交通流数据的预定时信号控制[1 ] ,基于实时交通状态的响应控制(包括感应控制[2 ] 、自适应控制[3 ] )以及基于模型的协调控制. 采用上述方法进行优化交叉口信号控制存在一定的理想假设,具有一定的局限性. 随着人工智能技术和交通信息采集技术的发展,通过数据驱动实现信号控制成为交叉口信号优化的新发展方向. ...
面向混合交通的感应式交通信号控制方法
1
2019
... 针对交叉口信号优化控制的研究按照控制方法可划分为3类:基于历史交通流数据的预定时信号控制[1 ] ,基于实时交通状态的响应控制(包括感应控制[2 ] 、自适应控制[3 ] )以及基于模型的协调控制. 采用上述方法进行优化交叉口信号控制存在一定的理想假设,具有一定的局限性. 随着人工智能技术和交通信息采集技术的发展,通过数据驱动实现信号控制成为交叉口信号优化的新发展方向. ...
The SCOOT on-line traffic signal optimisation technique
1
1982
... 针对交叉口信号优化控制的研究按照控制方法可划分为3类:基于历史交通流数据的预定时信号控制[1 ] ,基于实时交通状态的响应控制(包括感应控制[2 ] 、自适应控制[3 ] )以及基于模型的协调控制. 采用上述方法进行优化交叉口信号控制存在一定的理想假设,具有一定的局限性. 随着人工智能技术和交通信息采集技术的发展,通过数据驱动实现信号控制成为交叉口信号优化的新发展方向. ...
2
... 强化学习属于人工智能技术,以马尔可夫决策为基础,通过反馈机制进行学习,适用于具有顺序决策特征的交通信号控制问题. 由于交通状态的随机性、复杂性和动态性,传统强化学习在表达交通状态时存在局限. 将深度学习与强化学习结合的深度强化学习方法使得强化学习应用于交通信号控制的研究有了新的突破. 学者开始应用深度强化学习方法解决交叉口信号控制问题. Genders等[4 ] 提出使用离散状态编码表示交叉口的交通状态,并使用深度学习中的卷积神经网络提取车辆速度和位置特征. 与使用排队车辆数为特征的浅层神经网络相比,Genders等[4 ] 的方法控制效果更佳,证明了深度卷积神经网络的有效性. Li等[5 ] 将堆叠自编码器(stacked auto-encoder, SAE)引入强化学习,证明了在减少排队长度上,结合深度学习网络与强化学习的信号控制方法相比于传统的强化学习信号控制方法更有优势. Gao等[6 ] 基于离散状态编码和深度Q网络 (deep Q network, DQN)算法进行仿真实验,证明了深度强化学习方法在车辆延误指标上优于最长队列优先 (longest queue first, LQF)算法和定时信号控制方法. Mousavi等[7 ] 使用基于策略和基于值函数的深度强化学习方法控制信号灯;与定时信号控制方法相比,2种深度强化学习方法均能够显著降低车辆的延误. Wei等[8 ] 在DQN算法的基础上提出分区记忆和相位门控机制,在仿真交通流数据和真实交通流数据上验证了所提方法的优越性. Liang等[9 ] 基于双决斗深度Q网络(double-dueling deep Q network, 3DQN) [10 ] 算法进行信号优化,采用离散状态编码表示交叉口状态,动作空间为延长5 s或缩短5 s某个相位的持续时间;奖励函数采用动作执行前后交叉口内车辆等待时间的差值. 孙浩等[11 ] 提出基于深度分布强化学习单交叉口信号控制方法. 刘志等[12 ] 通过设计优先级序列经验回放和动作奖惩系数改进深度强化学习算法的性能,所提算法在车辆平均等待时间和路口总排队长度上优于实际配时策略和传统的DQN算法. 刘智敏等[13 ] 构建基于相邻采样时间步实时车辆数变化量的奖励函数,使用改进的DQN算法进行信号控制. 赵乾等[14 ] 基于近端策略优化 (proximal policy optimization, PPO)算法进行单交叉口信号控制并设计NEMA双环相位结构的动作空间,通过设置低中高交通需求实验验证了所提算法在控制排队长度和车均延误方面优于固定配时方案. ...
... [4 ]的方法控制效果更佳,证明了深度卷积神经网络的有效性. Li等[5 ] 将堆叠自编码器(stacked auto-encoder, SAE)引入强化学习,证明了在减少排队长度上,结合深度学习网络与强化学习的信号控制方法相比于传统的强化学习信号控制方法更有优势. Gao等[6 ] 基于离散状态编码和深度Q网络 (deep Q network, DQN)算法进行仿真实验,证明了深度强化学习方法在车辆延误指标上优于最长队列优先 (longest queue first, LQF)算法和定时信号控制方法. Mousavi等[7 ] 使用基于策略和基于值函数的深度强化学习方法控制信号灯;与定时信号控制方法相比,2种深度强化学习方法均能够显著降低车辆的延误. Wei等[8 ] 在DQN算法的基础上提出分区记忆和相位门控机制,在仿真交通流数据和真实交通流数据上验证了所提方法的优越性. Liang等[9 ] 基于双决斗深度Q网络(double-dueling deep Q network, 3DQN) [10 ] 算法进行信号优化,采用离散状态编码表示交叉口状态,动作空间为延长5 s或缩短5 s某个相位的持续时间;奖励函数采用动作执行前后交叉口内车辆等待时间的差值. 孙浩等[11 ] 提出基于深度分布强化学习单交叉口信号控制方法. 刘志等[12 ] 通过设计优先级序列经验回放和动作奖惩系数改进深度强化学习算法的性能,所提算法在车辆平均等待时间和路口总排队长度上优于实际配时策略和传统的DQN算法. 刘智敏等[13 ] 构建基于相邻采样时间步实时车辆数变化量的奖励函数,使用改进的DQN算法进行信号控制. 赵乾等[14 ] 基于近端策略优化 (proximal policy optimization, PPO)算法进行单交叉口信号控制并设计NEMA双环相位结构的动作空间,通过设置低中高交通需求实验验证了所提算法在控制排队长度和车均延误方面优于固定配时方案. ...
Traffic signal timing via deep reinforcement learning
1
2016
... 强化学习属于人工智能技术,以马尔可夫决策为基础,通过反馈机制进行学习,适用于具有顺序决策特征的交通信号控制问题. 由于交通状态的随机性、复杂性和动态性,传统强化学习在表达交通状态时存在局限. 将深度学习与强化学习结合的深度强化学习方法使得强化学习应用于交通信号控制的研究有了新的突破. 学者开始应用深度强化学习方法解决交叉口信号控制问题. Genders等[4 ] 提出使用离散状态编码表示交叉口的交通状态,并使用深度学习中的卷积神经网络提取车辆速度和位置特征. 与使用排队车辆数为特征的浅层神经网络相比,Genders等[4 ] 的方法控制效果更佳,证明了深度卷积神经网络的有效性. Li等[5 ] 将堆叠自编码器(stacked auto-encoder, SAE)引入强化学习,证明了在减少排队长度上,结合深度学习网络与强化学习的信号控制方法相比于传统的强化学习信号控制方法更有优势. Gao等[6 ] 基于离散状态编码和深度Q网络 (deep Q network, DQN)算法进行仿真实验,证明了深度强化学习方法在车辆延误指标上优于最长队列优先 (longest queue first, LQF)算法和定时信号控制方法. Mousavi等[7 ] 使用基于策略和基于值函数的深度强化学习方法控制信号灯;与定时信号控制方法相比,2种深度强化学习方法均能够显著降低车辆的延误. Wei等[8 ] 在DQN算法的基础上提出分区记忆和相位门控机制,在仿真交通流数据和真实交通流数据上验证了所提方法的优越性. Liang等[9 ] 基于双决斗深度Q网络(double-dueling deep Q network, 3DQN) [10 ] 算法进行信号优化,采用离散状态编码表示交叉口状态,动作空间为延长5 s或缩短5 s某个相位的持续时间;奖励函数采用动作执行前后交叉口内车辆等待时间的差值. 孙浩等[11 ] 提出基于深度分布强化学习单交叉口信号控制方法. 刘志等[12 ] 通过设计优先级序列经验回放和动作奖惩系数改进深度强化学习算法的性能,所提算法在车辆平均等待时间和路口总排队长度上优于实际配时策略和传统的DQN算法. 刘智敏等[13 ] 构建基于相邻采样时间步实时车辆数变化量的奖励函数,使用改进的DQN算法进行信号控制. 赵乾等[14 ] 基于近端策略优化 (proximal policy optimization, PPO)算法进行单交叉口信号控制并设计NEMA双环相位结构的动作空间,通过设置低中高交通需求实验验证了所提算法在控制排队长度和车均延误方面优于固定配时方案. ...
1
... 强化学习属于人工智能技术,以马尔可夫决策为基础,通过反馈机制进行学习,适用于具有顺序决策特征的交通信号控制问题. 由于交通状态的随机性、复杂性和动态性,传统强化学习在表达交通状态时存在局限. 将深度学习与强化学习结合的深度强化学习方法使得强化学习应用于交通信号控制的研究有了新的突破. 学者开始应用深度强化学习方法解决交叉口信号控制问题. Genders等[4 ] 提出使用离散状态编码表示交叉口的交通状态,并使用深度学习中的卷积神经网络提取车辆速度和位置特征. 与使用排队车辆数为特征的浅层神经网络相比,Genders等[4 ] 的方法控制效果更佳,证明了深度卷积神经网络的有效性. Li等[5 ] 将堆叠自编码器(stacked auto-encoder, SAE)引入强化学习,证明了在减少排队长度上,结合深度学习网络与强化学习的信号控制方法相比于传统的强化学习信号控制方法更有优势. Gao等[6 ] 基于离散状态编码和深度Q网络 (deep Q network, DQN)算法进行仿真实验,证明了深度强化学习方法在车辆延误指标上优于最长队列优先 (longest queue first, LQF)算法和定时信号控制方法. Mousavi等[7 ] 使用基于策略和基于值函数的深度强化学习方法控制信号灯;与定时信号控制方法相比,2种深度强化学习方法均能够显著降低车辆的延误. Wei等[8 ] 在DQN算法的基础上提出分区记忆和相位门控机制,在仿真交通流数据和真实交通流数据上验证了所提方法的优越性. Liang等[9 ] 基于双决斗深度Q网络(double-dueling deep Q network, 3DQN) [10 ] 算法进行信号优化,采用离散状态编码表示交叉口状态,动作空间为延长5 s或缩短5 s某个相位的持续时间;奖励函数采用动作执行前后交叉口内车辆等待时间的差值. 孙浩等[11 ] 提出基于深度分布强化学习单交叉口信号控制方法. 刘志等[12 ] 通过设计优先级序列经验回放和动作奖惩系数改进深度强化学习算法的性能,所提算法在车辆平均等待时间和路口总排队长度上优于实际配时策略和传统的DQN算法. 刘智敏等[13 ] 构建基于相邻采样时间步实时车辆数变化量的奖励函数,使用改进的DQN算法进行信号控制. 赵乾等[14 ] 基于近端策略优化 (proximal policy optimization, PPO)算法进行单交叉口信号控制并设计NEMA双环相位结构的动作空间,通过设置低中高交通需求实验验证了所提算法在控制排队长度和车均延误方面优于固定配时方案. ...
Traffic light control using deep policy-gradient and value-function-based reinforcement learning
1
2017
... 强化学习属于人工智能技术,以马尔可夫决策为基础,通过反馈机制进行学习,适用于具有顺序决策特征的交通信号控制问题. 由于交通状态的随机性、复杂性和动态性,传统强化学习在表达交通状态时存在局限. 将深度学习与强化学习结合的深度强化学习方法使得强化学习应用于交通信号控制的研究有了新的突破. 学者开始应用深度强化学习方法解决交叉口信号控制问题. Genders等[4 ] 提出使用离散状态编码表示交叉口的交通状态,并使用深度学习中的卷积神经网络提取车辆速度和位置特征. 与使用排队车辆数为特征的浅层神经网络相比,Genders等[4 ] 的方法控制效果更佳,证明了深度卷积神经网络的有效性. Li等[5 ] 将堆叠自编码器(stacked auto-encoder, SAE)引入强化学习,证明了在减少排队长度上,结合深度学习网络与强化学习的信号控制方法相比于传统的强化学习信号控制方法更有优势. Gao等[6 ] 基于离散状态编码和深度Q网络 (deep Q network, DQN)算法进行仿真实验,证明了深度强化学习方法在车辆延误指标上优于最长队列优先 (longest queue first, LQF)算法和定时信号控制方法. Mousavi等[7 ] 使用基于策略和基于值函数的深度强化学习方法控制信号灯;与定时信号控制方法相比,2种深度强化学习方法均能够显著降低车辆的延误. Wei等[8 ] 在DQN算法的基础上提出分区记忆和相位门控机制,在仿真交通流数据和真实交通流数据上验证了所提方法的优越性. Liang等[9 ] 基于双决斗深度Q网络(double-dueling deep Q network, 3DQN) [10 ] 算法进行信号优化,采用离散状态编码表示交叉口状态,动作空间为延长5 s或缩短5 s某个相位的持续时间;奖励函数采用动作执行前后交叉口内车辆等待时间的差值. 孙浩等[11 ] 提出基于深度分布强化学习单交叉口信号控制方法. 刘志等[12 ] 通过设计优先级序列经验回放和动作奖惩系数改进深度强化学习算法的性能,所提算法在车辆平均等待时间和路口总排队长度上优于实际配时策略和传统的DQN算法. 刘智敏等[13 ] 构建基于相邻采样时间步实时车辆数变化量的奖励函数,使用改进的DQN算法进行信号控制. 赵乾等[14 ] 基于近端策略优化 (proximal policy optimization, PPO)算法进行单交叉口信号控制并设计NEMA双环相位结构的动作空间,通过设置低中高交通需求实验验证了所提算法在控制排队长度和车均延误方面优于固定配时方案. ...
1
... 强化学习属于人工智能技术,以马尔可夫决策为基础,通过反馈机制进行学习,适用于具有顺序决策特征的交通信号控制问题. 由于交通状态的随机性、复杂性和动态性,传统强化学习在表达交通状态时存在局限. 将深度学习与强化学习结合的深度强化学习方法使得强化学习应用于交通信号控制的研究有了新的突破. 学者开始应用深度强化学习方法解决交叉口信号控制问题. Genders等[4 ] 提出使用离散状态编码表示交叉口的交通状态,并使用深度学习中的卷积神经网络提取车辆速度和位置特征. 与使用排队车辆数为特征的浅层神经网络相比,Genders等[4 ] 的方法控制效果更佳,证明了深度卷积神经网络的有效性. Li等[5 ] 将堆叠自编码器(stacked auto-encoder, SAE)引入强化学习,证明了在减少排队长度上,结合深度学习网络与强化学习的信号控制方法相比于传统的强化学习信号控制方法更有优势. Gao等[6 ] 基于离散状态编码和深度Q网络 (deep Q network, DQN)算法进行仿真实验,证明了深度强化学习方法在车辆延误指标上优于最长队列优先 (longest queue first, LQF)算法和定时信号控制方法. Mousavi等[7 ] 使用基于策略和基于值函数的深度强化学习方法控制信号灯;与定时信号控制方法相比,2种深度强化学习方法均能够显著降低车辆的延误. Wei等[8 ] 在DQN算法的基础上提出分区记忆和相位门控机制,在仿真交通流数据和真实交通流数据上验证了所提方法的优越性. Liang等[9 ] 基于双决斗深度Q网络(double-dueling deep Q network, 3DQN) [10 ] 算法进行信号优化,采用离散状态编码表示交叉口状态,动作空间为延长5 s或缩短5 s某个相位的持续时间;奖励函数采用动作执行前后交叉口内车辆等待时间的差值. 孙浩等[11 ] 提出基于深度分布强化学习单交叉口信号控制方法. 刘志等[12 ] 通过设计优先级序列经验回放和动作奖惩系数改进深度强化学习算法的性能,所提算法在车辆平均等待时间和路口总排队长度上优于实际配时策略和传统的DQN算法. 刘智敏等[13 ] 构建基于相邻采样时间步实时车辆数变化量的奖励函数,使用改进的DQN算法进行信号控制. 赵乾等[14 ] 基于近端策略优化 (proximal policy optimization, PPO)算法进行单交叉口信号控制并设计NEMA双环相位结构的动作空间,通过设置低中高交通需求实验验证了所提算法在控制排队长度和车均延误方面优于固定配时方案. ...
A deep reinforcement learning network for traffic light cycle control
1
2019
... 强化学习属于人工智能技术,以马尔可夫决策为基础,通过反馈机制进行学习,适用于具有顺序决策特征的交通信号控制问题. 由于交通状态的随机性、复杂性和动态性,传统强化学习在表达交通状态时存在局限. 将深度学习与强化学习结合的深度强化学习方法使得强化学习应用于交通信号控制的研究有了新的突破. 学者开始应用深度强化学习方法解决交叉口信号控制问题. Genders等[4 ] 提出使用离散状态编码表示交叉口的交通状态,并使用深度学习中的卷积神经网络提取车辆速度和位置特征. 与使用排队车辆数为特征的浅层神经网络相比,Genders等[4 ] 的方法控制效果更佳,证明了深度卷积神经网络的有效性. Li等[5 ] 将堆叠自编码器(stacked auto-encoder, SAE)引入强化学习,证明了在减少排队长度上,结合深度学习网络与强化学习的信号控制方法相比于传统的强化学习信号控制方法更有优势. Gao等[6 ] 基于离散状态编码和深度Q网络 (deep Q network, DQN)算法进行仿真实验,证明了深度强化学习方法在车辆延误指标上优于最长队列优先 (longest queue first, LQF)算法和定时信号控制方法. Mousavi等[7 ] 使用基于策略和基于值函数的深度强化学习方法控制信号灯;与定时信号控制方法相比,2种深度强化学习方法均能够显著降低车辆的延误. Wei等[8 ] 在DQN算法的基础上提出分区记忆和相位门控机制,在仿真交通流数据和真实交通流数据上验证了所提方法的优越性. Liang等[9 ] 基于双决斗深度Q网络(double-dueling deep Q network, 3DQN) [10 ] 算法进行信号优化,采用离散状态编码表示交叉口状态,动作空间为延长5 s或缩短5 s某个相位的持续时间;奖励函数采用动作执行前后交叉口内车辆等待时间的差值. 孙浩等[11 ] 提出基于深度分布强化学习单交叉口信号控制方法. 刘志等[12 ] 通过设计优先级序列经验回放和动作奖惩系数改进深度强化学习算法的性能,所提算法在车辆平均等待时间和路口总排队长度上优于实际配时策略和传统的DQN算法. 刘智敏等[13 ] 构建基于相邻采样时间步实时车辆数变化量的奖励函数,使用改进的DQN算法进行信号控制. 赵乾等[14 ] 基于近端策略优化 (proximal policy optimization, PPO)算法进行单交叉口信号控制并设计NEMA双环相位结构的动作空间,通过设置低中高交通需求实验验证了所提算法在控制排队长度和车均延误方面优于固定配时方案. ...
1
... 强化学习属于人工智能技术,以马尔可夫决策为基础,通过反馈机制进行学习,适用于具有顺序决策特征的交通信号控制问题. 由于交通状态的随机性、复杂性和动态性,传统强化学习在表达交通状态时存在局限. 将深度学习与强化学习结合的深度强化学习方法使得强化学习应用于交通信号控制的研究有了新的突破. 学者开始应用深度强化学习方法解决交叉口信号控制问题. Genders等[4 ] 提出使用离散状态编码表示交叉口的交通状态,并使用深度学习中的卷积神经网络提取车辆速度和位置特征. 与使用排队车辆数为特征的浅层神经网络相比,Genders等[4 ] 的方法控制效果更佳,证明了深度卷积神经网络的有效性. Li等[5 ] 将堆叠自编码器(stacked auto-encoder, SAE)引入强化学习,证明了在减少排队长度上,结合深度学习网络与强化学习的信号控制方法相比于传统的强化学习信号控制方法更有优势. Gao等[6 ] 基于离散状态编码和深度Q网络 (deep Q network, DQN)算法进行仿真实验,证明了深度强化学习方法在车辆延误指标上优于最长队列优先 (longest queue first, LQF)算法和定时信号控制方法. Mousavi等[7 ] 使用基于策略和基于值函数的深度强化学习方法控制信号灯;与定时信号控制方法相比,2种深度强化学习方法均能够显著降低车辆的延误. Wei等[8 ] 在DQN算法的基础上提出分区记忆和相位门控机制,在仿真交通流数据和真实交通流数据上验证了所提方法的优越性. Liang等[9 ] 基于双决斗深度Q网络(double-dueling deep Q network, 3DQN) [10 ] 算法进行信号优化,采用离散状态编码表示交叉口状态,动作空间为延长5 s或缩短5 s某个相位的持续时间;奖励函数采用动作执行前后交叉口内车辆等待时间的差值. 孙浩等[11 ] 提出基于深度分布强化学习单交叉口信号控制方法. 刘志等[12 ] 通过设计优先级序列经验回放和动作奖惩系数改进深度强化学习算法的性能,所提算法在车辆平均等待时间和路口总排队长度上优于实际配时策略和传统的DQN算法. 刘智敏等[13 ] 构建基于相邻采样时间步实时车辆数变化量的奖励函数,使用改进的DQN算法进行信号控制. 赵乾等[14 ] 基于近端策略优化 (proximal policy optimization, PPO)算法进行单交叉口信号控制并设计NEMA双环相位结构的动作空间,通过设置低中高交通需求实验验证了所提算法在控制排队长度和车均延误方面优于固定配时方案. ...
基于深度强化学习的交通信号控制方法
1
2020
... 强化学习属于人工智能技术,以马尔可夫决策为基础,通过反馈机制进行学习,适用于具有顺序决策特征的交通信号控制问题. 由于交通状态的随机性、复杂性和动态性,传统强化学习在表达交通状态时存在局限. 将深度学习与强化学习结合的深度强化学习方法使得强化学习应用于交通信号控制的研究有了新的突破. 学者开始应用深度强化学习方法解决交叉口信号控制问题. Genders等[4 ] 提出使用离散状态编码表示交叉口的交通状态,并使用深度学习中的卷积神经网络提取车辆速度和位置特征. 与使用排队车辆数为特征的浅层神经网络相比,Genders等[4 ] 的方法控制效果更佳,证明了深度卷积神经网络的有效性. Li等[5 ] 将堆叠自编码器(stacked auto-encoder, SAE)引入强化学习,证明了在减少排队长度上,结合深度学习网络与强化学习的信号控制方法相比于传统的强化学习信号控制方法更有优势. Gao等[6 ] 基于离散状态编码和深度Q网络 (deep Q network, DQN)算法进行仿真实验,证明了深度强化学习方法在车辆延误指标上优于最长队列优先 (longest queue first, LQF)算法和定时信号控制方法. Mousavi等[7 ] 使用基于策略和基于值函数的深度强化学习方法控制信号灯;与定时信号控制方法相比,2种深度强化学习方法均能够显著降低车辆的延误. Wei等[8 ] 在DQN算法的基础上提出分区记忆和相位门控机制,在仿真交通流数据和真实交通流数据上验证了所提方法的优越性. Liang等[9 ] 基于双决斗深度Q网络(double-dueling deep Q network, 3DQN) [10 ] 算法进行信号优化,采用离散状态编码表示交叉口状态,动作空间为延长5 s或缩短5 s某个相位的持续时间;奖励函数采用动作执行前后交叉口内车辆等待时间的差值. 孙浩等[11 ] 提出基于深度分布强化学习单交叉口信号控制方法. 刘志等[12 ] 通过设计优先级序列经验回放和动作奖惩系数改进深度强化学习算法的性能,所提算法在车辆平均等待时间和路口总排队长度上优于实际配时策略和传统的DQN算法. 刘智敏等[13 ] 构建基于相邻采样时间步实时车辆数变化量的奖励函数,使用改进的DQN算法进行信号控制. 赵乾等[14 ] 基于近端策略优化 (proximal policy optimization, PPO)算法进行单交叉口信号控制并设计NEMA双环相位结构的动作空间,通过设置低中高交通需求实验验证了所提算法在控制排队长度和车均延误方面优于固定配时方案. ...
基于深度强化学习的交通信号控制方法
1
2020
... 强化学习属于人工智能技术,以马尔可夫决策为基础,通过反馈机制进行学习,适用于具有顺序决策特征的交通信号控制问题. 由于交通状态的随机性、复杂性和动态性,传统强化学习在表达交通状态时存在局限. 将深度学习与强化学习结合的深度强化学习方法使得强化学习应用于交通信号控制的研究有了新的突破. 学者开始应用深度强化学习方法解决交叉口信号控制问题. Genders等[4 ] 提出使用离散状态编码表示交叉口的交通状态,并使用深度学习中的卷积神经网络提取车辆速度和位置特征. 与使用排队车辆数为特征的浅层神经网络相比,Genders等[4 ] 的方法控制效果更佳,证明了深度卷积神经网络的有效性. Li等[5 ] 将堆叠自编码器(stacked auto-encoder, SAE)引入强化学习,证明了在减少排队长度上,结合深度学习网络与强化学习的信号控制方法相比于传统的强化学习信号控制方法更有优势. Gao等[6 ] 基于离散状态编码和深度Q网络 (deep Q network, DQN)算法进行仿真实验,证明了深度强化学习方法在车辆延误指标上优于最长队列优先 (longest queue first, LQF)算法和定时信号控制方法. Mousavi等[7 ] 使用基于策略和基于值函数的深度强化学习方法控制信号灯;与定时信号控制方法相比,2种深度强化学习方法均能够显著降低车辆的延误. Wei等[8 ] 在DQN算法的基础上提出分区记忆和相位门控机制,在仿真交通流数据和真实交通流数据上验证了所提方法的优越性. Liang等[9 ] 基于双决斗深度Q网络(double-dueling deep Q network, 3DQN) [10 ] 算法进行信号优化,采用离散状态编码表示交叉口状态,动作空间为延长5 s或缩短5 s某个相位的持续时间;奖励函数采用动作执行前后交叉口内车辆等待时间的差值. 孙浩等[11 ] 提出基于深度分布强化学习单交叉口信号控制方法. 刘志等[12 ] 通过设计优先级序列经验回放和动作奖惩系数改进深度强化学习算法的性能,所提算法在车辆平均等待时间和路口总排队长度上优于实际配时策略和传统的DQN算法. 刘智敏等[13 ] 构建基于相邻采样时间步实时车辆数变化量的奖励函数,使用改进的DQN算法进行信号控制. 赵乾等[14 ] 基于近端策略优化 (proximal policy optimization, PPO)算法进行单交叉口信号控制并设计NEMA双环相位结构的动作空间,通过设置低中高交通需求实验验证了所提算法在控制排队长度和车均延误方面优于固定配时方案. ...
基于改进深度强化学习方法的单交叉口信号控制
1
2020
... 强化学习属于人工智能技术,以马尔可夫决策为基础,通过反馈机制进行学习,适用于具有顺序决策特征的交通信号控制问题. 由于交通状态的随机性、复杂性和动态性,传统强化学习在表达交通状态时存在局限. 将深度学习与强化学习结合的深度强化学习方法使得强化学习应用于交通信号控制的研究有了新的突破. 学者开始应用深度强化学习方法解决交叉口信号控制问题. Genders等[4 ] 提出使用离散状态编码表示交叉口的交通状态,并使用深度学习中的卷积神经网络提取车辆速度和位置特征. 与使用排队车辆数为特征的浅层神经网络相比,Genders等[4 ] 的方法控制效果更佳,证明了深度卷积神经网络的有效性. Li等[5 ] 将堆叠自编码器(stacked auto-encoder, SAE)引入强化学习,证明了在减少排队长度上,结合深度学习网络与强化学习的信号控制方法相比于传统的强化学习信号控制方法更有优势. Gao等[6 ] 基于离散状态编码和深度Q网络 (deep Q network, DQN)算法进行仿真实验,证明了深度强化学习方法在车辆延误指标上优于最长队列优先 (longest queue first, LQF)算法和定时信号控制方法. Mousavi等[7 ] 使用基于策略和基于值函数的深度强化学习方法控制信号灯;与定时信号控制方法相比,2种深度强化学习方法均能够显著降低车辆的延误. Wei等[8 ] 在DQN算法的基础上提出分区记忆和相位门控机制,在仿真交通流数据和真实交通流数据上验证了所提方法的优越性. Liang等[9 ] 基于双决斗深度Q网络(double-dueling deep Q network, 3DQN) [10 ] 算法进行信号优化,采用离散状态编码表示交叉口状态,动作空间为延长5 s或缩短5 s某个相位的持续时间;奖励函数采用动作执行前后交叉口内车辆等待时间的差值. 孙浩等[11 ] 提出基于深度分布强化学习单交叉口信号控制方法. 刘志等[12 ] 通过设计优先级序列经验回放和动作奖惩系数改进深度强化学习算法的性能,所提算法在车辆平均等待时间和路口总排队长度上优于实际配时策略和传统的DQN算法. 刘智敏等[13 ] 构建基于相邻采样时间步实时车辆数变化量的奖励函数,使用改进的DQN算法进行信号控制. 赵乾等[14 ] 基于近端策略优化 (proximal policy optimization, PPO)算法进行单交叉口信号控制并设计NEMA双环相位结构的动作空间,通过设置低中高交通需求实验验证了所提算法在控制排队长度和车均延误方面优于固定配时方案. ...
基于改进深度强化学习方法的单交叉口信号控制
1
2020
... 强化学习属于人工智能技术,以马尔可夫决策为基础,通过反馈机制进行学习,适用于具有顺序决策特征的交通信号控制问题. 由于交通状态的随机性、复杂性和动态性,传统强化学习在表达交通状态时存在局限. 将深度学习与强化学习结合的深度强化学习方法使得强化学习应用于交通信号控制的研究有了新的突破. 学者开始应用深度强化学习方法解决交叉口信号控制问题. Genders等[4 ] 提出使用离散状态编码表示交叉口的交通状态,并使用深度学习中的卷积神经网络提取车辆速度和位置特征. 与使用排队车辆数为特征的浅层神经网络相比,Genders等[4 ] 的方法控制效果更佳,证明了深度卷积神经网络的有效性. Li等[5 ] 将堆叠自编码器(stacked auto-encoder, SAE)引入强化学习,证明了在减少排队长度上,结合深度学习网络与强化学习的信号控制方法相比于传统的强化学习信号控制方法更有优势. Gao等[6 ] 基于离散状态编码和深度Q网络 (deep Q network, DQN)算法进行仿真实验,证明了深度强化学习方法在车辆延误指标上优于最长队列优先 (longest queue first, LQF)算法和定时信号控制方法. Mousavi等[7 ] 使用基于策略和基于值函数的深度强化学习方法控制信号灯;与定时信号控制方法相比,2种深度强化学习方法均能够显著降低车辆的延误. Wei等[8 ] 在DQN算法的基础上提出分区记忆和相位门控机制,在仿真交通流数据和真实交通流数据上验证了所提方法的优越性. Liang等[9 ] 基于双决斗深度Q网络(double-dueling deep Q network, 3DQN) [10 ] 算法进行信号优化,采用离散状态编码表示交叉口状态,动作空间为延长5 s或缩短5 s某个相位的持续时间;奖励函数采用动作执行前后交叉口内车辆等待时间的差值. 孙浩等[11 ] 提出基于深度分布强化学习单交叉口信号控制方法. 刘志等[12 ] 通过设计优先级序列经验回放和动作奖惩系数改进深度强化学习算法的性能,所提算法在车辆平均等待时间和路口总排队长度上优于实际配时策略和传统的DQN算法. 刘智敏等[13 ] 构建基于相邻采样时间步实时车辆数变化量的奖励函数,使用改进的DQN算法进行信号控制. 赵乾等[14 ] 基于近端策略优化 (proximal policy optimization, PPO)算法进行单交叉口信号控制并设计NEMA双环相位结构的动作空间,通过设置低中高交通需求实验验证了所提算法在控制排队长度和车均延误方面优于固定配时方案. ...
基于深度强化学习的交通信号控制方法
2
2022
... 强化学习属于人工智能技术,以马尔可夫决策为基础,通过反馈机制进行学习,适用于具有顺序决策特征的交通信号控制问题. 由于交通状态的随机性、复杂性和动态性,传统强化学习在表达交通状态时存在局限. 将深度学习与强化学习结合的深度强化学习方法使得强化学习应用于交通信号控制的研究有了新的突破. 学者开始应用深度强化学习方法解决交叉口信号控制问题. Genders等[4 ] 提出使用离散状态编码表示交叉口的交通状态,并使用深度学习中的卷积神经网络提取车辆速度和位置特征. 与使用排队车辆数为特征的浅层神经网络相比,Genders等[4 ] 的方法控制效果更佳,证明了深度卷积神经网络的有效性. Li等[5 ] 将堆叠自编码器(stacked auto-encoder, SAE)引入强化学习,证明了在减少排队长度上,结合深度学习网络与强化学习的信号控制方法相比于传统的强化学习信号控制方法更有优势. Gao等[6 ] 基于离散状态编码和深度Q网络 (deep Q network, DQN)算法进行仿真实验,证明了深度强化学习方法在车辆延误指标上优于最长队列优先 (longest queue first, LQF)算法和定时信号控制方法. Mousavi等[7 ] 使用基于策略和基于值函数的深度强化学习方法控制信号灯;与定时信号控制方法相比,2种深度强化学习方法均能够显著降低车辆的延误. Wei等[8 ] 在DQN算法的基础上提出分区记忆和相位门控机制,在仿真交通流数据和真实交通流数据上验证了所提方法的优越性. Liang等[9 ] 基于双决斗深度Q网络(double-dueling deep Q network, 3DQN) [10 ] 算法进行信号优化,采用离散状态编码表示交叉口状态,动作空间为延长5 s或缩短5 s某个相位的持续时间;奖励函数采用动作执行前后交叉口内车辆等待时间的差值. 孙浩等[11 ] 提出基于深度分布强化学习单交叉口信号控制方法. 刘志等[12 ] 通过设计优先级序列经验回放和动作奖惩系数改进深度强化学习算法的性能,所提算法在车辆平均等待时间和路口总排队长度上优于实际配时策略和传统的DQN算法. 刘智敏等[13 ] 构建基于相邻采样时间步实时车辆数变化量的奖励函数,使用改进的DQN算法进行信号控制. 赵乾等[14 ] 基于近端策略优化 (proximal policy optimization, PPO)算法进行单交叉口信号控制并设计NEMA双环相位结构的动作空间,通过设置低中高交通需求实验验证了所提算法在控制排队长度和车均延误方面优于固定配时方案. ...
... 传统信号控制领域已总结出较多的交通指标来评价交叉口处车辆的通行效率,比如排队长度、吞吐量、车辆延误等. 交叉口信号控制的目标是降低所有通行者的平均旅行时间. 在强化学习处理信号控制问题当中,奖励函数一般通过动作执行前后某些指标的变化来给予智能体反馈,比如排队长度的变化[18 ] 、延误时间的差值[13 ] . 由于不考虑行人过街,本研究将降低交叉口所有车辆的平均旅行时间作为优化目标. 在仿真过程中,车辆的旅行时间无法通过直接测量得到,Zheng等[17 ] 指出使用交叉口的排队长度作为奖励函数与优化车辆的旅行时间具有较强的相关性,因此本研究使用动作执行前后的排队强度之差 $\Delta L$ ${W_{\max }}$
基于深度强化学习的交通信号控制方法
2
2022
... 强化学习属于人工智能技术,以马尔可夫决策为基础,通过反馈机制进行学习,适用于具有顺序决策特征的交通信号控制问题. 由于交通状态的随机性、复杂性和动态性,传统强化学习在表达交通状态时存在局限. 将深度学习与强化学习结合的深度强化学习方法使得强化学习应用于交通信号控制的研究有了新的突破. 学者开始应用深度强化学习方法解决交叉口信号控制问题. Genders等[4 ] 提出使用离散状态编码表示交叉口的交通状态,并使用深度学习中的卷积神经网络提取车辆速度和位置特征. 与使用排队车辆数为特征的浅层神经网络相比,Genders等[4 ] 的方法控制效果更佳,证明了深度卷积神经网络的有效性. Li等[5 ] 将堆叠自编码器(stacked auto-encoder, SAE)引入强化学习,证明了在减少排队长度上,结合深度学习网络与强化学习的信号控制方法相比于传统的强化学习信号控制方法更有优势. Gao等[6 ] 基于离散状态编码和深度Q网络 (deep Q network, DQN)算法进行仿真实验,证明了深度强化学习方法在车辆延误指标上优于最长队列优先 (longest queue first, LQF)算法和定时信号控制方法. Mousavi等[7 ] 使用基于策略和基于值函数的深度强化学习方法控制信号灯;与定时信号控制方法相比,2种深度强化学习方法均能够显著降低车辆的延误. Wei等[8 ] 在DQN算法的基础上提出分区记忆和相位门控机制,在仿真交通流数据和真实交通流数据上验证了所提方法的优越性. Liang等[9 ] 基于双决斗深度Q网络(double-dueling deep Q network, 3DQN) [10 ] 算法进行信号优化,采用离散状态编码表示交叉口状态,动作空间为延长5 s或缩短5 s某个相位的持续时间;奖励函数采用动作执行前后交叉口内车辆等待时间的差值. 孙浩等[11 ] 提出基于深度分布强化学习单交叉口信号控制方法. 刘志等[12 ] 通过设计优先级序列经验回放和动作奖惩系数改进深度强化学习算法的性能,所提算法在车辆平均等待时间和路口总排队长度上优于实际配时策略和传统的DQN算法. 刘智敏等[13 ] 构建基于相邻采样时间步实时车辆数变化量的奖励函数,使用改进的DQN算法进行信号控制. 赵乾等[14 ] 基于近端策略优化 (proximal policy optimization, PPO)算法进行单交叉口信号控制并设计NEMA双环相位结构的动作空间,通过设置低中高交通需求实验验证了所提算法在控制排队长度和车均延误方面优于固定配时方案. ...
... 传统信号控制领域已总结出较多的交通指标来评价交叉口处车辆的通行效率,比如排队长度、吞吐量、车辆延误等. 交叉口信号控制的目标是降低所有通行者的平均旅行时间. 在强化学习处理信号控制问题当中,奖励函数一般通过动作执行前后某些指标的变化来给予智能体反馈,比如排队长度的变化[18 ] 、延误时间的差值[13 ] . 由于不考虑行人过街,本研究将降低交叉口所有车辆的平均旅行时间作为优化目标. 在仿真过程中,车辆的旅行时间无法通过直接测量得到,Zheng等[17 ] 指出使用交叉口的排队长度作为奖励函数与优化车辆的旅行时间具有较强的相关性,因此本研究使用动作执行前后的排队强度之差 $\Delta L$ ${W_{\max }}$
双环相位结构约束下的强化学习交通信号控制方法
1
2023
... 强化学习属于人工智能技术,以马尔可夫决策为基础,通过反馈机制进行学习,适用于具有顺序决策特征的交通信号控制问题. 由于交通状态的随机性、复杂性和动态性,传统强化学习在表达交通状态时存在局限. 将深度学习与强化学习结合的深度强化学习方法使得强化学习应用于交通信号控制的研究有了新的突破. 学者开始应用深度强化学习方法解决交叉口信号控制问题. Genders等[4 ] 提出使用离散状态编码表示交叉口的交通状态,并使用深度学习中的卷积神经网络提取车辆速度和位置特征. 与使用排队车辆数为特征的浅层神经网络相比,Genders等[4 ] 的方法控制效果更佳,证明了深度卷积神经网络的有效性. Li等[5 ] 将堆叠自编码器(stacked auto-encoder, SAE)引入强化学习,证明了在减少排队长度上,结合深度学习网络与强化学习的信号控制方法相比于传统的强化学习信号控制方法更有优势. Gao等[6 ] 基于离散状态编码和深度Q网络 (deep Q network, DQN)算法进行仿真实验,证明了深度强化学习方法在车辆延误指标上优于最长队列优先 (longest queue first, LQF)算法和定时信号控制方法. Mousavi等[7 ] 使用基于策略和基于值函数的深度强化学习方法控制信号灯;与定时信号控制方法相比,2种深度强化学习方法均能够显著降低车辆的延误. Wei等[8 ] 在DQN算法的基础上提出分区记忆和相位门控机制,在仿真交通流数据和真实交通流数据上验证了所提方法的优越性. Liang等[9 ] 基于双决斗深度Q网络(double-dueling deep Q network, 3DQN) [10 ] 算法进行信号优化,采用离散状态编码表示交叉口状态,动作空间为延长5 s或缩短5 s某个相位的持续时间;奖励函数采用动作执行前后交叉口内车辆等待时间的差值. 孙浩等[11 ] 提出基于深度分布强化学习单交叉口信号控制方法. 刘志等[12 ] 通过设计优先级序列经验回放和动作奖惩系数改进深度强化学习算法的性能,所提算法在车辆平均等待时间和路口总排队长度上优于实际配时策略和传统的DQN算法. 刘智敏等[13 ] 构建基于相邻采样时间步实时车辆数变化量的奖励函数,使用改进的DQN算法进行信号控制. 赵乾等[14 ] 基于近端策略优化 (proximal policy optimization, PPO)算法进行单交叉口信号控制并设计NEMA双环相位结构的动作空间,通过设置低中高交通需求实验验证了所提算法在控制排队长度和车均延误方面优于固定配时方案. ...
双环相位结构约束下的强化学习交通信号控制方法
1
2023
... 强化学习属于人工智能技术,以马尔可夫决策为基础,通过反馈机制进行学习,适用于具有顺序决策特征的交通信号控制问题. 由于交通状态的随机性、复杂性和动态性,传统强化学习在表达交通状态时存在局限. 将深度学习与强化学习结合的深度强化学习方法使得强化学习应用于交通信号控制的研究有了新的突破. 学者开始应用深度强化学习方法解决交叉口信号控制问题. Genders等[4 ] 提出使用离散状态编码表示交叉口的交通状态,并使用深度学习中的卷积神经网络提取车辆速度和位置特征. 与使用排队车辆数为特征的浅层神经网络相比,Genders等[4 ] 的方法控制效果更佳,证明了深度卷积神经网络的有效性. Li等[5 ] 将堆叠自编码器(stacked auto-encoder, SAE)引入强化学习,证明了在减少排队长度上,结合深度学习网络与强化学习的信号控制方法相比于传统的强化学习信号控制方法更有优势. Gao等[6 ] 基于离散状态编码和深度Q网络 (deep Q network, DQN)算法进行仿真实验,证明了深度强化学习方法在车辆延误指标上优于最长队列优先 (longest queue first, LQF)算法和定时信号控制方法. Mousavi等[7 ] 使用基于策略和基于值函数的深度强化学习方法控制信号灯;与定时信号控制方法相比,2种深度强化学习方法均能够显著降低车辆的延误. Wei等[8 ] 在DQN算法的基础上提出分区记忆和相位门控机制,在仿真交通流数据和真实交通流数据上验证了所提方法的优越性. Liang等[9 ] 基于双决斗深度Q网络(double-dueling deep Q network, 3DQN) [10 ] 算法进行信号优化,采用离散状态编码表示交叉口状态,动作空间为延长5 s或缩短5 s某个相位的持续时间;奖励函数采用动作执行前后交叉口内车辆等待时间的差值. 孙浩等[11 ] 提出基于深度分布强化学习单交叉口信号控制方法. 刘志等[12 ] 通过设计优先级序列经验回放和动作奖惩系数改进深度强化学习算法的性能,所提算法在车辆平均等待时间和路口总排队长度上优于实际配时策略和传统的DQN算法. 刘智敏等[13 ] 构建基于相邻采样时间步实时车辆数变化量的奖励函数,使用改进的DQN算法进行信号控制. 赵乾等[14 ] 基于近端策略优化 (proximal policy optimization, PPO)算法进行单交叉口信号控制并设计NEMA双环相位结构的动作空间,通过设置低中高交通需求实验验证了所提算法在控制排队长度和车均延误方面优于固定配时方案. ...
Multi-agent deep reinforcement learning for large-scale traffic signal control
1
2019
... 状态的设计对于深度强化学习模型的学习有至关重要的作用. 状态的设计可以分为2类:1)采用如交通评价指标的统计值来刻画交叉口每条车道内的交通需求以及交通状态(如每条车道的排队长度[15 ] 、交通流量[16 ] 、车流密度[17 ] 等);2)使用图像表示方法对交叉口的每条车道进行离散化编码,即将每条车道划分为长宽固定的元胞,当元胞中含有车辆时,使用与元胞对应的速度矩阵和位置矩阵表示车辆的信息,进而利用卷积神经网络处理矩阵. 考虑到状态的维度不宜过大,且使用如交通评价指标的统计值可以达到与图像表示方法同等的控制效果[17 ] ,本研究采用状态1)表示方法. 结合交叉口的时空因素,采用与交叉口相连的进口道的排队强度 ${I_{{\text{q,in}}}}$ ${I_{{\text{D,in}}}}$ ${I_{{\text{w,in}}}}$ ${I_{{\text{q,out}}}}$ ${I_{{\text{D,out}}}}$ $i$ ${I_{\text{q}}}$ ${I_{\text{D}}}$ ${I_{\text{w}}}$
Network-wide traffic signal control optimization using a multi-agent deep reinforcement learning
1
2021
... 状态的设计对于深度强化学习模型的学习有至关重要的作用. 状态的设计可以分为2类:1)采用如交通评价指标的统计值来刻画交叉口每条车道内的交通需求以及交通状态(如每条车道的排队长度[15 ] 、交通流量[16 ] 、车流密度[17 ] 等);2)使用图像表示方法对交叉口的每条车道进行离散化编码,即将每条车道划分为长宽固定的元胞,当元胞中含有车辆时,使用与元胞对应的速度矩阵和位置矩阵表示车辆的信息,进而利用卷积神经网络处理矩阵. 考虑到状态的维度不宜过大,且使用如交通评价指标的统计值可以达到与图像表示方法同等的控制效果[17 ] ,本研究采用状态1)表示方法. 结合交叉口的时空因素,采用与交叉口相连的进口道的排队强度 ${I_{{\text{q,in}}}}$ ${I_{{\text{D,in}}}}$ ${I_{{\text{w,in}}}}$ ${I_{{\text{q,out}}}}$ ${I_{{\text{D,out}}}}$ $i$ ${I_{\text{q}}}$ ${I_{\text{D}}}$ ${I_{\text{w}}}$
3
... 状态的设计对于深度强化学习模型的学习有至关重要的作用. 状态的设计可以分为2类:1)采用如交通评价指标的统计值来刻画交叉口每条车道内的交通需求以及交通状态(如每条车道的排队长度[15 ] 、交通流量[16 ] 、车流密度[17 ] 等);2)使用图像表示方法对交叉口的每条车道进行离散化编码,即将每条车道划分为长宽固定的元胞,当元胞中含有车辆时,使用与元胞对应的速度矩阵和位置矩阵表示车辆的信息,进而利用卷积神经网络处理矩阵. 考虑到状态的维度不宜过大,且使用如交通评价指标的统计值可以达到与图像表示方法同等的控制效果[17 ] ,本研究采用状态1)表示方法. 结合交叉口的时空因素,采用与交叉口相连的进口道的排队强度 ${I_{{\text{q,in}}}}$ ${I_{{\text{D,in}}}}$ ${I_{{\text{w,in}}}}$ ${I_{{\text{q,out}}}}$ ${I_{{\text{D,out}}}}$ $i$ ${I_{\text{q}}}$ ${I_{\text{D}}}$ ${I_{\text{w}}}$
... [17 ],本研究采用状态1)表示方法. 结合交叉口的时空因素,采用与交叉口相连的进口道的排队强度 ${I_{{\text{q,in}}}}$ ${I_{{\text{D,in}}}}$ ${I_{{\text{w,in}}}}$ ${I_{{\text{q,out}}}}$ ${I_{{\text{D,out}}}}$ $i$ ${I_{\text{q}}}$ ${I_{\text{D}}}$ ${I_{\text{w}}}$
... 传统信号控制领域已总结出较多的交通指标来评价交叉口处车辆的通行效率,比如排队长度、吞吐量、车辆延误等. 交叉口信号控制的目标是降低所有通行者的平均旅行时间. 在强化学习处理信号控制问题当中,奖励函数一般通过动作执行前后某些指标的变化来给予智能体反馈,比如排队长度的变化[18 ] 、延误时间的差值[13 ] . 由于不考虑行人过街,本研究将降低交叉口所有车辆的平均旅行时间作为优化目标. 在仿真过程中,车辆的旅行时间无法通过直接测量得到,Zheng等[17 ] 指出使用交叉口的排队长度作为奖励函数与优化车辆的旅行时间具有较强的相关性,因此本研究使用动作执行前后的排队强度之差 $\Delta L$ ${W_{\max }}$
1
... 传统信号控制领域已总结出较多的交通指标来评价交叉口处车辆的通行效率,比如排队长度、吞吐量、车辆延误等. 交叉口信号控制的目标是降低所有通行者的平均旅行时间. 在强化学习处理信号控制问题当中,奖励函数一般通过动作执行前后某些指标的变化来给予智能体反馈,比如排队长度的变化[18 ] 、延误时间的差值[13 ] . 由于不考虑行人过街,本研究将降低交叉口所有车辆的平均旅行时间作为优化目标. 在仿真过程中,车辆的旅行时间无法通过直接测量得到,Zheng等[17 ] 指出使用交叉口的排队长度作为奖励函数与优化车辆的旅行时间具有较强的相关性,因此本研究使用动作执行前后的排队强度之差 $\Delta L$ ${W_{\max }}$
1
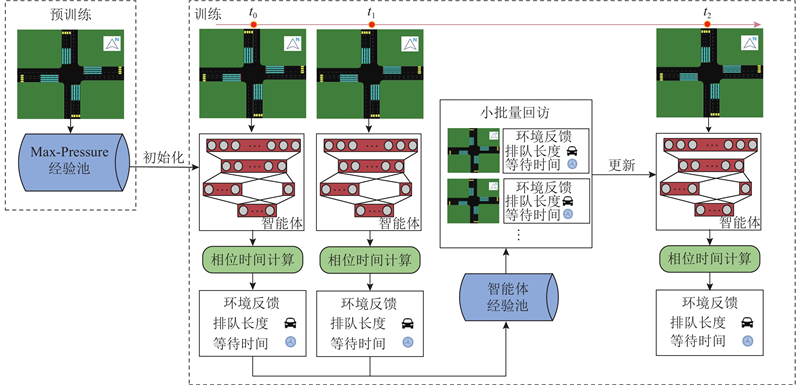
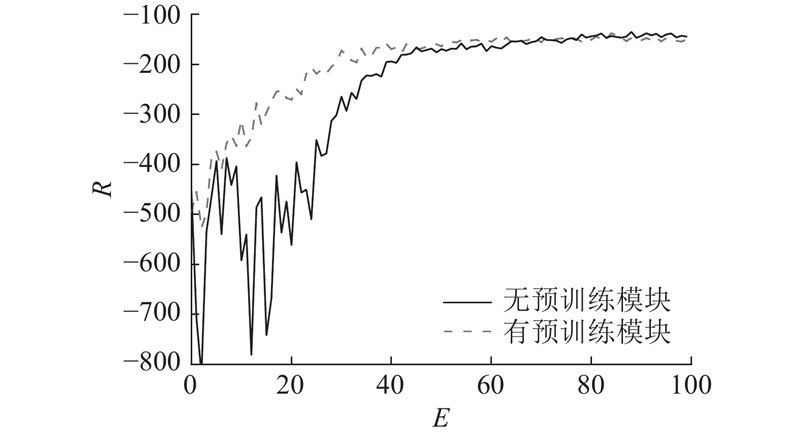
... 通过专家数据对模型进行初始化训练以获得性能较好的策略是解决深度强化学习方法学习速度慢的方法之一. Hester等[19 ] 将人类玩游戏的经验数据与深度强化学习进行融合,提出学习演示的深度 Q 学习(deep Q-learning from demonstrations, DQFD)方法. DQFD通过离线的方式利用人类的经验数据对DQN算法中的神经网络进行初始化,缓解了深度强化学习模型初始化不稳定的状况,在一定程度上加快了网络的学习. 与DQFD解决的问题不同,在交通信号控制领域中不存在专家轨迹样本. 本研究须解决2个问题:1)采用何种交通控制方法作为模仿的专家方法,2)如何利用该交通控制方法产生的数据对深度强化学习智能体进行预训练. ...
1
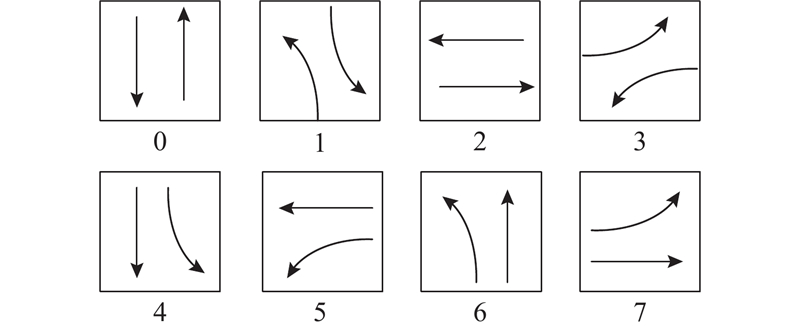
... Max-Pressure方法[20 ] 旨在通过最小化交叉口的压力来平衡相邻交叉口之间的排队长度,从而降低过度饱和的风险. 在Max-Pressure方法中,信号灯每间隔固定的时间切换相位,其中相位根据各个相位的压力差从给定的相位方案中选取,相位方案如图3 所示. 压力差定义为相位控制的进口车道排队车辆数与相应出口车道排队车辆数的差值. Max-Pressure方法与本研究设计的智能体动作空间一致,且该方法作为对比方法在以往的强化学习信号控制研究中均表现出较好的控制效果,因此Max-Pressure方法相比于其他方法更加适合作为本研究中智能体模仿的专家方法. ...
1
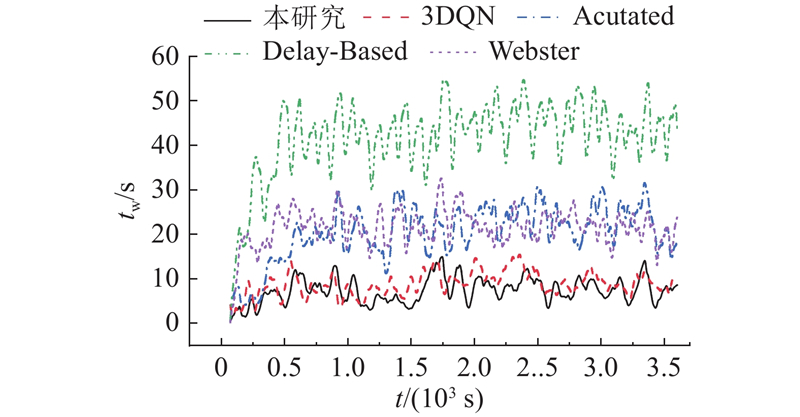
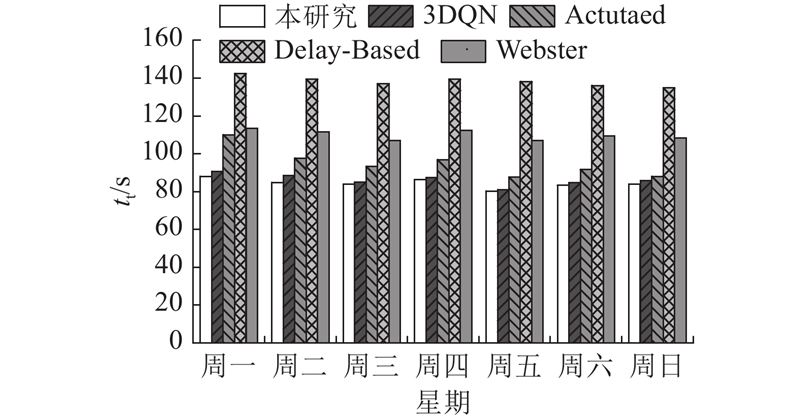
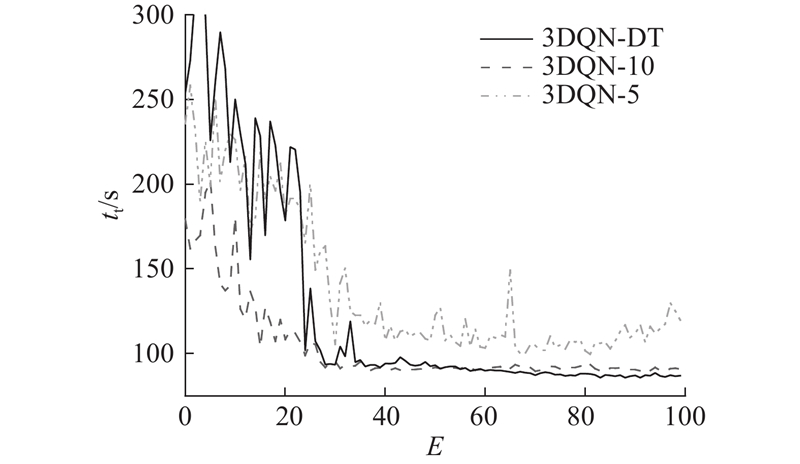
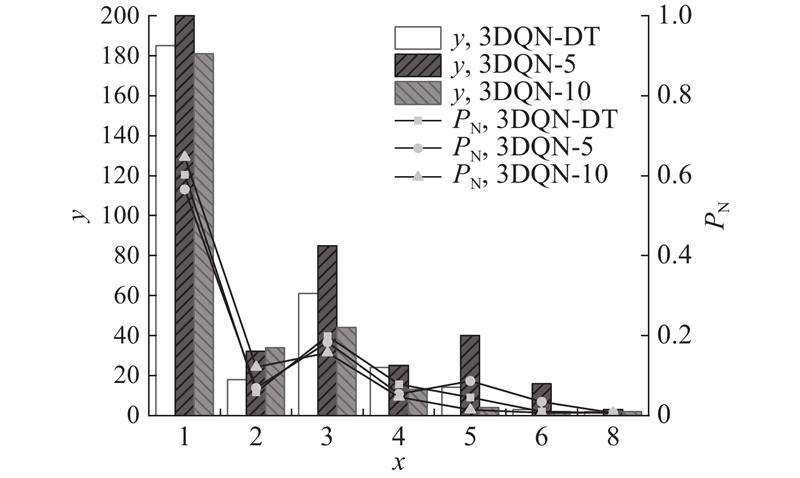
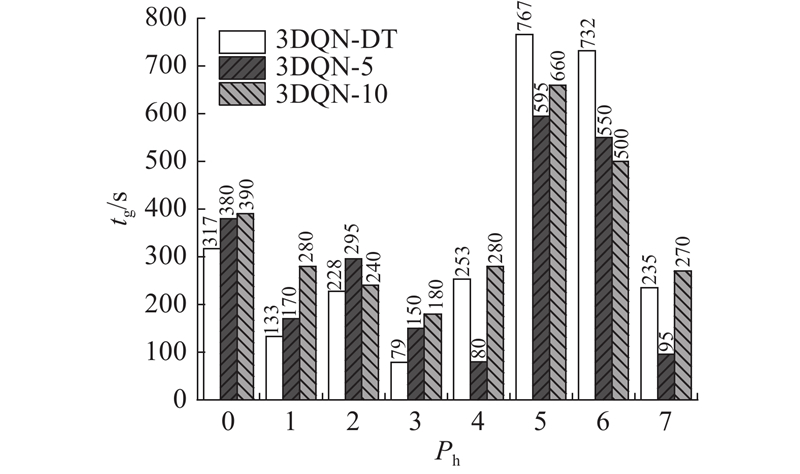
... 利用2021年10月18日的早高峰数据进行仿真训练,与传统的基于3DQN算法、感应式信号控制方法Actuated和Delay-Based[21 ] 以及定时信号控制方法Webster的控制效果进行对比. 不同方法在车辆平均等待时间 ${t_{\rm{w}}}$ ${t_{\rm{t}}}$ $v$ 表3 所示. 本研究算法在各项指标上均表现出最好的控制效果. 相比于定时信号控制,本研究算法在平均旅行时间上减少了22.97%. 如表4 所示为采用不同方法控制信号灯时各进口道的平均排队长度,其中 ${L_{\text{n}}}$ ${L_{\text{s}}}$ ${L_{\text{e}}}$ ${L_{\text{w}}}$ 图6 所示为采用不同方法控制信号灯时路网内车辆平均等待时间的变化情况,其中 $t$


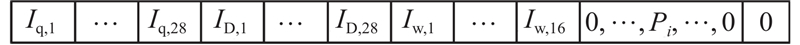

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}