[1]
ZHENG T, FANG H, ZHANG Y, et al. RESA: recurrent feature-shift aggregator for lane detection [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Palo Alto: AAAI Press, 2021: 3547−3554.
[本文引用: 2]
[2]
QIN Z, WANG H, LI X. Ultra fast structure-aware deep lane detection [C]// Computer Vision–ECCV 2020: 16th European Conference . Glasgow: Springer, 2020: 276−291.
[本文引用: 4]
[3]
HONDA H, UCHIDA Y. CLRerNet: improving confidence of lane detection with LaneIoU [C]// Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision . Waikoloa: IEEE, 2024: 1165–1174.
[本文引用: 1]
[4]
HAN J, DENG X, CAI X, Laneformer: object-aware row-column transformers for lane detection [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Palo Alto: AAAI Press, 2022: 799−807.
[本文引用: 1]
[5]
LEE D H, LIU J L End-to-end deep learning of lane detection and path prediction for real-time autonomous driving
[J]. Signal, Image and Video Processing , 2023 , 17 (1 ): 199 - 205
DOI:10.1007/s11760-022-02222-2
[本文引用: 1]
[6]
PAN H, CHANG X, SUN W Multitask knowledge distillation guides end-to-end lane detection
[J]. IEEE Transactions on Industrial Informatics , 2023 , 19 (9 ): 9703 - 9712
DOI:10.1109/TII.2023.3233975
[本文引用: 1]
[7]
ZHENG T, HUANG Y, LIU Y, et al. CLRNet: cross layer refinement network for lane detection [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 888–897.
[本文引用: 7]
[8]
PAN X, SHI J, LUO P, et al. Spatial as deep: Spatial cnn for traffic scene understanding [C]// Proceedings of the AAAI Conference on Artificial Intelligence . New Orleans: AAAI Press, 2018: 589−592.
[本文引用: 5]
[9]
LEE M, LEE J, LEE D, et al. Robust lane detection via expanded self attention [C]// Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision . Waikoloa: IEEE, 2022: 1949–1958.
[本文引用: 1]
[10]
XU H, WANG S, CAI X, et al. CurveLane-NAS: unifying lane-sensitive architecture search and adaptive point blending [C]// Computer Vision–ECCV 2020: 16th European Conference . Glasgow: Springer, 2020: 689−704.
[本文引用: 1]
[11]
TABELINI L, BERRIEL R, PAIXAO T M, et al. PolyLaneNet: lane estimation via deep polynomial regression [C]// Proceedings of the 25th International Conference on Pattern Recognition . Milan: IEEE, 2021: 6150–6156.
[本文引用: 1]
[12]
LIU R, YUAN Z, LIU T, et al. End-to-end lane shape prediction with transformers [C]// Proceedings of the IEEE Winter Conference on Applications of Computer Vision . Waikoloa: IEEE, 2021: 3694–3702.
[本文引用: 1]
[13]
LIU L, CHEN X, ZHU S, et al. CondLaneNet: a top-to-down lane detection framework based on conditional convolution [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 3753–3762.
[本文引用: 2]
[14]
LI X, LI J, HU X, et al Line-CNN: end-to-end traffic line detection with line proposal unit
[J]. IEEE Transactions on Intelligent Transportation Systems , 2020 , 21 (1 ): 248 - 258
DOI:10.1109/TITS.2019.2890870
[本文引用: 2]
[15]
TABELINI L, BERRIEL R, PAIXAO T M, et al. Keep your eyes on the lane: real-time attention-guided lane detection [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 294–302.
[本文引用: 3]
[16]
WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// Proceedings of the European Conference on Computer Vision . Munich: Springer, 2018: 3-19.
[本文引用: 1]
[17]
LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 936–944.
[本文引用: 1]
[18]
LIU S, QI L, QIN H, et al. Path aggregation network for instance segmentation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 8759–8768.
[本文引用: 1]
[19]
LIM B, SON S, KIM H, et al. Enhanced deep residual networks for single image super-resolution [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops . Honolulu: IEEE, 2017: 1132–1140.
[本文引用: 1]
[20]
WANG X, GIRSHICK R, GUPTA A, et al. Non-local neural networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 7794–7803.
[本文引用: 1]
2
... 近年来,车道线检测的研究主要集中在深度学习领域,其中基于分割的方法[1 ] 涉及像素级别的预测,导致在实时应用中的计算成本较高;基于锚点的方法[2 -4 ] 对于复杂结构的车道不够灵活;基于参数预测的方法[5 -6 ] 推理速度快,但仍难以达到更高的性能. ...
... 基于分割的车道线检测通常将车道和背景预先定义为不同的类别,然后逐像素地预测特征图. 生成分割图后,需要一个后处理步骤将其解码为一组车道. 由于忽略了全局上下文信息和逐像素预测策略的复杂性,早期基于分割的方法在准确率和速度方面都表现不佳. 为了利用全局信息,Pan等[8 ] 设计特殊的卷积结构SCNN,使得消息能够跨行和列传递. 虽然该结构能够更好地捕获车道线的强空间关系、更有效地利用视觉信息,但该方法非常耗时(每秒处理7.5帧图片). 最近,Zheng等[1 ] 提出通过对切片的特征映射进行横向和纵向的聚合,从而提升SCNN的速度. 但是,基于分割的方法在速度和准确率上仍然不如其他方法. ...
4
... 近年来,车道线检测的研究主要集中在深度学习领域,其中基于分割的方法[1 ] 涉及像素级别的预测,导致在实时应用中的计算成本较高;基于锚点的方法[2 -4 ] 对于复杂结构的车道不够灵活;基于参数预测的方法[5 -6 ] 推理速度快,但仍难以达到更高的性能. ...
... 基于行锚的方法通过搜索预定义行锚上最可能包含车道线的单元格,来构建车道线. Qin等[2 ] 提出UFLD模型,以低延迟来换取性能,利用预设的车道锚框信息和全局图像特征进行行搜索,提升了检测效率和实时性. 虽然简单快速,但在复杂的驾驶场景下,其对车道线的检测能力一般. Liu等[13 ] 引入基于条件卷积和基于行锚的公式化的条件车道检测策略. 该类方法首先要定位车道线的起始点,然而,在一些复杂场景中,起始点难以识别,这导致性能相对较差. ...
... CGANet’s experimental results on CULane dataset
Tab.2 方法 基线网络 F1/% mF1/% F1/% N cross FPS/帧 Flops/109 Normal Crowd Dazzle Shadow No line Arrow Curve Ningt SCNN[8 ] VGG16 71.60 38.34 90.60 69.70 58.50 66.90 43.40 84.10 64.40 66.10 1990 7.5 328.4 UFLD[2 ] ResNet18 68.40 38.94 85.90 63.60 57.00 69.60 40.60 79.40 65.20 66.70 2037 282.0 8.4 ResNet34 72.30 38.96 87.70 66.00 58.40 68.80 40.20 81.00 57.90 62.10 1473 170.0 16.9 LaneATT[15 ] ResNet18 74.50 47.35 90.71 69.71 61.82 64.03 47.13 86.82 64.75 66.58 1020 153.0 9.3 ResNet34 74.00 47.57 91.14 72.03 62.47 74.15 47.39 87.38 64.75 68.72 1330 130.0 18.0 ResNet122 74.40 48.48 90.74 69.74 65.47 72.31 48.46 85.29 68.72 68.81 1264 21.0 70.5 CondLaneNet[14 ] ResNet18 75.13 48.84 91.87 74.87 66.72 76.01 50.39 88.37 72.40 71.23 1364 175.0 10.2 ResNet34 76.68 49.11 92.38 74.14 67.17 75.93 49.85 88.89 72.88 71.92 1387 128.0 19.6 ResNet101 77.02 50.83 92.47 74.14 66.93 76.91 52.13 89.16 72.21 72.80 1201 49.0 44.8 CLRerNet[3 ] ResNet18 76.12 52.11 92.60 75.92 70.23 77.33 52.34 88.57 72.68 73.25 1458 119.0 13.2 ResNet34 77.27 52.45 92.53 75.96 70.45 78.92 52.98 89.23 72.81 73.56 1334 104.0 24.5 ResNet101 78.80 52.68 92.80 76.12 69.84 78.95 53.65 89.69 73.45 73.37 1289 50.0 41.2 CLRNet[7 ] ResNet18 78.14 51.92 92.69 75.06 69.70 75.39 51.96 89.25 68.09 73.22 1520 119.0 12.9 ResNet34 78.74 51.14 92.49 75.33 70.57 75.92 52.01 89.59 72.77 73.02 1448 103.0 22.6 ResNet101 79.48 51.55 92.85 75.78 68.49 78.33 52.50 88.79 72.57 73.51 1456 46.0 40.5 CGANet ResNet18 79.58 52.62 92.89 76.03 69.53 76.60 49.73 88.57 72.37 73.13 1321 120.0 13.7 ResNet34 79.73 52.31 92.87 75.86 70.57 76.88 50.03 89.79 73.23 73.74 1216 112.0 30.6 ResNet101 80.13 52.88 92.54 76.78 68.49 79.51 50.58 87.62 73.68 73.36 1262 57.0 42.7
图 5 CULane数据集9种场景检测效果图 ...
... CGANet’s experimental results on TuSimple dataset
Tab.3 方法 基线网络 F1/% Acc/% P FP /%P FN /%SCNN[8 ] VGG16 94.97 93.12 7.17 2.20 UFLD[2 ] ResNet18 85.87 93.82 20.05 8.92 ResNet34 86.02 92.86 19.91 8.75 LaneATT[15 ] ResNet18 95.71 92.10 4.56 8.01 ResNet34 95.77 92.63 4.53 7.92 ResNet122 95.59 92.57 6.64 7.17 CondLaneNet[13 ] ResNet18 96.01 93.48 3.18 7.28 ResNet34 95.98 93.37 3.20 8.80 ResNet101 96.24 94.54 3.01 8.82 CLRNet[7 ] ResNet18 95.04 93.97 3.09 7.02 ResNet34 94.73 93.11 2.87 7.92 ResNet101 97.27 96.33 1.86 3.63 CGANet ResNet18 96.73 95.24 1.84 4.80 ResNet34 96.02 93.78 1.97 6.14 ResNet101 97.45 96.67 2.76 2.31
CGANet在Tusimple数据集上的车道线检测效果如图6 所示,考虑到TuSimple数据集包含了较为简单的驾驶场景、较优的外部环境条件以及清晰可辨的车道线,因此展示的检测效果表现良好,证明在条件较为理想的情况下,本节介绍的车道线检测方法能够可靠地执行其功能. ...
1
... CGANet’s experimental results on CULane dataset
Tab.2 方法 基线网络 F1/% mF1/% F1/% N cross FPS/帧 Flops/109 Normal Crowd Dazzle Shadow No line Arrow Curve Ningt SCNN[8 ] VGG16 71.60 38.34 90.60 69.70 58.50 66.90 43.40 84.10 64.40 66.10 1990 7.5 328.4 UFLD[2 ] ResNet18 68.40 38.94 85.90 63.60 57.00 69.60 40.60 79.40 65.20 66.70 2037 282.0 8.4 ResNet34 72.30 38.96 87.70 66.00 58.40 68.80 40.20 81.00 57.90 62.10 1473 170.0 16.9 LaneATT[15 ] ResNet18 74.50 47.35 90.71 69.71 61.82 64.03 47.13 86.82 64.75 66.58 1020 153.0 9.3 ResNet34 74.00 47.57 91.14 72.03 62.47 74.15 47.39 87.38 64.75 68.72 1330 130.0 18.0 ResNet122 74.40 48.48 90.74 69.74 65.47 72.31 48.46 85.29 68.72 68.81 1264 21.0 70.5 CondLaneNet[14 ] ResNet18 75.13 48.84 91.87 74.87 66.72 76.01 50.39 88.37 72.40 71.23 1364 175.0 10.2 ResNet34 76.68 49.11 92.38 74.14 67.17 75.93 49.85 88.89 72.88 71.92 1387 128.0 19.6 ResNet101 77.02 50.83 92.47 74.14 66.93 76.91 52.13 89.16 72.21 72.80 1201 49.0 44.8 CLRerNet[3 ] ResNet18 76.12 52.11 92.60 75.92 70.23 77.33 52.34 88.57 72.68 73.25 1458 119.0 13.2 ResNet34 77.27 52.45 92.53 75.96 70.45 78.92 52.98 89.23 72.81 73.56 1334 104.0 24.5 ResNet101 78.80 52.68 92.80 76.12 69.84 78.95 53.65 89.69 73.45 73.37 1289 50.0 41.2 CLRNet[7 ] ResNet18 78.14 51.92 92.69 75.06 69.70 75.39 51.96 89.25 68.09 73.22 1520 119.0 12.9 ResNet34 78.74 51.14 92.49 75.33 70.57 75.92 52.01 89.59 72.77 73.02 1448 103.0 22.6 ResNet101 79.48 51.55 92.85 75.78 68.49 78.33 52.50 88.79 72.57 73.51 1456 46.0 40.5 CGANet ResNet18 79.58 52.62 92.89 76.03 69.53 76.60 49.73 88.57 72.37 73.13 1321 120.0 13.7 ResNet34 79.73 52.31 92.87 75.86 70.57 76.88 50.03 89.79 73.23 73.74 1216 112.0 30.6 ResNet101 80.13 52.88 92.54 76.78 68.49 79.51 50.58 87.62 73.68 73.36 1262 57.0 42.7
图 5 CULane数据集9种场景检测效果图 ...
1
... 近年来,车道线检测的研究主要集中在深度学习领域,其中基于分割的方法[1 ] 涉及像素级别的预测,导致在实时应用中的计算成本较高;基于锚点的方法[2 -4 ] 对于复杂结构的车道不够灵活;基于参数预测的方法[5 -6 ] 推理速度快,但仍难以达到更高的性能. ...
End-to-end deep learning of lane detection and path prediction for real-time autonomous driving
1
2023
... 近年来,车道线检测的研究主要集中在深度学习领域,其中基于分割的方法[1 ] 涉及像素级别的预测,导致在实时应用中的计算成本较高;基于锚点的方法[2 -4 ] 对于复杂结构的车道不够灵活;基于参数预测的方法[5 -6 ] 推理速度快,但仍难以达到更高的性能. ...
Multitask knowledge distillation guides end-to-end lane detection
1
2023
... 近年来,车道线检测的研究主要集中在深度学习领域,其中基于分割的方法[1 ] 涉及像素级别的预测,导致在实时应用中的计算成本较高;基于锚点的方法[2 -4 ] 对于复杂结构的车道不够灵活;基于参数预测的方法[5 -6 ] 推理速度快,但仍难以达到更高的性能. ...
7
... 相比传统方法,深度学习在车道线检测任务中表现出更好的性能. 因此,本研究从基于锚点的方法中选择CLRNet[7 ] 作为基线,通过加入改进的注意力机制提升模型性能. 改进后的网络命名为:基于内容引导注意力的车道线检测网络(content-guided attention-based lane detection network,CGANet). 在CULane[8 ] 、Tusimple[9 ] 和CurveLanes[10 ] 3个数据集上验证了方法的有效性. 本研究主要创新点如下. ...
... 基于线锚的方法采用预定义的线锚作为引导,通过回归相对坐标来定位车道. Li等[14 ] 首次在车道线检测中使用线锚. Tabelini等[15 ] 考虑全局信息的重要性,提出新的基于锚的注意力机制. Zheng等[7 ] 提出结合预定义线锚,综合利用全局特征和结合局部特征提升了检测性能. 该类方法是目前车道线检测任务中最有效的方法,因此,本研究基于此类方法展开研究. ...
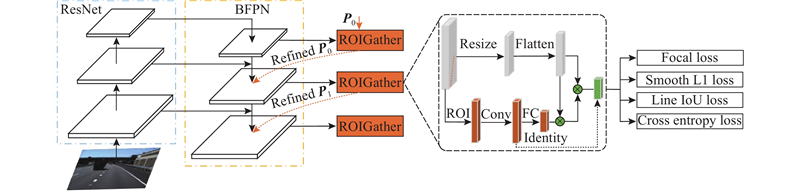
... 针对一些极端的情况,例如,不存在车道线存在的视觉证据,为了确定当前像素是否属于车道,必须要查看附近的特征,也就是上下文特征. 为此,采用ROIGather[7 ] 模块来进一步地学习车道线的特征,实现分类和回归任务. ...
... F1越接近于1.0代表模型的性能越好. 另外,本研究还采用了一个新的评价指标mF1进行评估[7 ] . ...
... CGANet’s experimental results on CULane dataset
Tab.2 方法 基线网络 F1/% mF1/% F1/% N cross FPS/帧 Flops/109 Normal Crowd Dazzle Shadow No line Arrow Curve Ningt SCNN[8 ] VGG16 71.60 38.34 90.60 69.70 58.50 66.90 43.40 84.10 64.40 66.10 1990 7.5 328.4 UFLD[2 ] ResNet18 68.40 38.94 85.90 63.60 57.00 69.60 40.60 79.40 65.20 66.70 2037 282.0 8.4 ResNet34 72.30 38.96 87.70 66.00 58.40 68.80 40.20 81.00 57.90 62.10 1473 170.0 16.9 LaneATT[15 ] ResNet18 74.50 47.35 90.71 69.71 61.82 64.03 47.13 86.82 64.75 66.58 1020 153.0 9.3 ResNet34 74.00 47.57 91.14 72.03 62.47 74.15 47.39 87.38 64.75 68.72 1330 130.0 18.0 ResNet122 74.40 48.48 90.74 69.74 65.47 72.31 48.46 85.29 68.72 68.81 1264 21.0 70.5 CondLaneNet[14 ] ResNet18 75.13 48.84 91.87 74.87 66.72 76.01 50.39 88.37 72.40 71.23 1364 175.0 10.2 ResNet34 76.68 49.11 92.38 74.14 67.17 75.93 49.85 88.89 72.88 71.92 1387 128.0 19.6 ResNet101 77.02 50.83 92.47 74.14 66.93 76.91 52.13 89.16 72.21 72.80 1201 49.0 44.8 CLRerNet[3 ] ResNet18 76.12 52.11 92.60 75.92 70.23 77.33 52.34 88.57 72.68 73.25 1458 119.0 13.2 ResNet34 77.27 52.45 92.53 75.96 70.45 78.92 52.98 89.23 72.81 73.56 1334 104.0 24.5 ResNet101 78.80 52.68 92.80 76.12 69.84 78.95 53.65 89.69 73.45 73.37 1289 50.0 41.2 CLRNet[7 ] ResNet18 78.14 51.92 92.69 75.06 69.70 75.39 51.96 89.25 68.09 73.22 1520 119.0 12.9 ResNet34 78.74 51.14 92.49 75.33 70.57 75.92 52.01 89.59 72.77 73.02 1448 103.0 22.6 ResNet101 79.48 51.55 92.85 75.78 68.49 78.33 52.50 88.79 72.57 73.51 1456 46.0 40.5 CGANet ResNet18 79.58 52.62 92.89 76.03 69.53 76.60 49.73 88.57 72.37 73.13 1321 120.0 13.7 ResNet34 79.73 52.31 92.87 75.86 70.57 76.88 50.03 89.79 73.23 73.74 1216 112.0 30.6 ResNet101 80.13 52.88 92.54 76.78 68.49 79.51 50.58 87.62 73.68 73.36 1262 57.0 42.7
图 5 CULane数据集9种场景检测效果图 ...
... CGANet’s experimental results on TuSimple dataset
Tab.3 方法 基线网络 F1/% Acc/% P FP /%P FN /%SCNN[8 ] VGG16 94.97 93.12 7.17 2.20 UFLD[2 ] ResNet18 85.87 93.82 20.05 8.92 ResNet34 86.02 92.86 19.91 8.75 LaneATT[15 ] ResNet18 95.71 92.10 4.56 8.01 ResNet34 95.77 92.63 4.53 7.92 ResNet122 95.59 92.57 6.64 7.17 CondLaneNet[13 ] ResNet18 96.01 93.48 3.18 7.28 ResNet34 95.98 93.37 3.20 8.80 ResNet101 96.24 94.54 3.01 8.82 CLRNet[7 ] ResNet18 95.04 93.97 3.09 7.02 ResNet34 94.73 93.11 2.87 7.92 ResNet101 97.27 96.33 1.86 3.63 CGANet ResNet18 96.73 95.24 1.84 4.80 ResNet34 96.02 93.78 1.97 6.14 ResNet101 97.45 96.67 2.76 2.31
CGANet在Tusimple数据集上的车道线检测效果如图6 所示,考虑到TuSimple数据集包含了较为简单的驾驶场景、较优的外部环境条件以及清晰可辨的车道线,因此展示的检测效果表现良好,证明在条件较为理想的情况下,本节介绍的车道线检测方法能够可靠地执行其功能. ...
... CGANet’s experimental results on CurveLanes dataset
Tab.4 方法 基线网络 F1/% P /%R /%FLOPs/109 CLRNet[7 ] ResNet18 85.09 87.75 82.58 10.3 ResNet34 85.92 88.29 83.68 19.7 ResNet101 86.10 88.98 83.41 44.9 CGANet ResNet18 85.98 91.05 81.12 18.4 ResNet34 86.18 91.62 81.57 20.1 ResNet101 86.39 91.52 81.61 44.8
CGANet在CurveLanes数据集上的车道线检测效果如图7 所示. 可以看出,在复杂的数据集上也能够正确检测出车道线位置,进一步证明所提方法的有效性,说明该算法具备较强的车道线检测能力. ...
5
... 相比传统方法,深度学习在车道线检测任务中表现出更好的性能. 因此,本研究从基于锚点的方法中选择CLRNet[7 ] 作为基线,通过加入改进的注意力机制提升模型性能. 改进后的网络命名为:基于内容引导注意力的车道线检测网络(content-guided attention-based lane detection network,CGANet). 在CULane[8 ] 、Tusimple[9 ] 和CurveLanes[10 ] 3个数据集上验证了方法的有效性. 本研究主要创新点如下. ...
... 基于分割的车道线检测通常将车道和背景预先定义为不同的类别,然后逐像素地预测特征图. 生成分割图后,需要一个后处理步骤将其解码为一组车道. 由于忽略了全局上下文信息和逐像素预测策略的复杂性,早期基于分割的方法在准确率和速度方面都表现不佳. 为了利用全局信息,Pan等[8 ] 设计特殊的卷积结构SCNN,使得消息能够跨行和列传递. 虽然该结构能够更好地捕获车道线的强空间关系、更有效地利用视觉信息,但该方法非常耗时(每秒处理7.5帧图片). 最近,Zheng等[1 ] 提出通过对切片的特征映射进行横向和纵向的聚合,从而提升SCNN的速度. 但是,基于分割的方法在速度和准确率上仍然不如其他方法. ...
... 对于CULane数据集,采用SCNN[8 ] 的评估指标,该指标利用F1作为度量. 首先将车道线看作宽度为30像素的线,计算真实车道线和预测车道线之间的交并比(intersection over union,IoU),然后根据预设的阈值,将检测结果划分为真阳性($ {\text{TP}} $ $ {\text{FP}} $ $ {\text{FN}} $ $ {\text{TP}} $ . 精度P 、召回率R 、F1值F1的定义分别如下: ...
... CGANet’s experimental results on CULane dataset
Tab.2 方法 基线网络 F1/% mF1/% F1/% N cross FPS/帧 Flops/109 Normal Crowd Dazzle Shadow No line Arrow Curve Ningt SCNN[8 ] VGG16 71.60 38.34 90.60 69.70 58.50 66.90 43.40 84.10 64.40 66.10 1990 7.5 328.4 UFLD[2 ] ResNet18 68.40 38.94 85.90 63.60 57.00 69.60 40.60 79.40 65.20 66.70 2037 282.0 8.4 ResNet34 72.30 38.96 87.70 66.00 58.40 68.80 40.20 81.00 57.90 62.10 1473 170.0 16.9 LaneATT[15 ] ResNet18 74.50 47.35 90.71 69.71 61.82 64.03 47.13 86.82 64.75 66.58 1020 153.0 9.3 ResNet34 74.00 47.57 91.14 72.03 62.47 74.15 47.39 87.38 64.75 68.72 1330 130.0 18.0 ResNet122 74.40 48.48 90.74 69.74 65.47 72.31 48.46 85.29 68.72 68.81 1264 21.0 70.5 CondLaneNet[14 ] ResNet18 75.13 48.84 91.87 74.87 66.72 76.01 50.39 88.37 72.40 71.23 1364 175.0 10.2 ResNet34 76.68 49.11 92.38 74.14 67.17 75.93 49.85 88.89 72.88 71.92 1387 128.0 19.6 ResNet101 77.02 50.83 92.47 74.14 66.93 76.91 52.13 89.16 72.21 72.80 1201 49.0 44.8 CLRerNet[3 ] ResNet18 76.12 52.11 92.60 75.92 70.23 77.33 52.34 88.57 72.68 73.25 1458 119.0 13.2 ResNet34 77.27 52.45 92.53 75.96 70.45 78.92 52.98 89.23 72.81 73.56 1334 104.0 24.5 ResNet101 78.80 52.68 92.80 76.12 69.84 78.95 53.65 89.69 73.45 73.37 1289 50.0 41.2 CLRNet[7 ] ResNet18 78.14 51.92 92.69 75.06 69.70 75.39 51.96 89.25 68.09 73.22 1520 119.0 12.9 ResNet34 78.74 51.14 92.49 75.33 70.57 75.92 52.01 89.59 72.77 73.02 1448 103.0 22.6 ResNet101 79.48 51.55 92.85 75.78 68.49 78.33 52.50 88.79 72.57 73.51 1456 46.0 40.5 CGANet ResNet18 79.58 52.62 92.89 76.03 69.53 76.60 49.73 88.57 72.37 73.13 1321 120.0 13.7 ResNet34 79.73 52.31 92.87 75.86 70.57 76.88 50.03 89.79 73.23 73.74 1216 112.0 30.6 ResNet101 80.13 52.88 92.54 76.78 68.49 79.51 50.58 87.62 73.68 73.36 1262 57.0 42.7
图 5 CULane数据集9种场景检测效果图 ...
... CGANet’s experimental results on TuSimple dataset
Tab.3 方法 基线网络 F1/% Acc/% P FP /%P FN /%SCNN[8 ] VGG16 94.97 93.12 7.17 2.20 UFLD[2 ] ResNet18 85.87 93.82 20.05 8.92 ResNet34 86.02 92.86 19.91 8.75 LaneATT[15 ] ResNet18 95.71 92.10 4.56 8.01 ResNet34 95.77 92.63 4.53 7.92 ResNet122 95.59 92.57 6.64 7.17 CondLaneNet[13 ] ResNet18 96.01 93.48 3.18 7.28 ResNet34 95.98 93.37 3.20 8.80 ResNet101 96.24 94.54 3.01 8.82 CLRNet[7 ] ResNet18 95.04 93.97 3.09 7.02 ResNet34 94.73 93.11 2.87 7.92 ResNet101 97.27 96.33 1.86 3.63 CGANet ResNet18 96.73 95.24 1.84 4.80 ResNet34 96.02 93.78 1.97 6.14 ResNet101 97.45 96.67 2.76 2.31
CGANet在Tusimple数据集上的车道线检测效果如图6 所示,考虑到TuSimple数据集包含了较为简单的驾驶场景、较优的外部环境条件以及清晰可辨的车道线,因此展示的检测效果表现良好,证明在条件较为理想的情况下,本节介绍的车道线检测方法能够可靠地执行其功能. ...
1
... 相比传统方法,深度学习在车道线检测任务中表现出更好的性能. 因此,本研究从基于锚点的方法中选择CLRNet[7 ] 作为基线,通过加入改进的注意力机制提升模型性能. 改进后的网络命名为:基于内容引导注意力的车道线检测网络(content-guided attention-based lane detection network,CGANet). 在CULane[8 ] 、Tusimple[9 ] 和CurveLanes[10 ] 3个数据集上验证了方法的有效性. 本研究主要创新点如下. ...
1
... 相比传统方法,深度学习在车道线检测任务中表现出更好的性能. 因此,本研究从基于锚点的方法中选择CLRNet[7 ] 作为基线,通过加入改进的注意力机制提升模型性能. 改进后的网络命名为:基于内容引导注意力的车道线检测网络(content-guided attention-based lane detection network,CGANet). 在CULane[8 ] 、Tusimple[9 ] 和CurveLanes[10 ] 3个数据集上验证了方法的有效性. 本研究主要创新点如下. ...
1
... 基于参数的方法直接输出由曲线方程表示的参数线,可以实现完整的端到端检测. Tabelini等[11 ] 提出PolyLaneNet模型,一个基于深度多项式回归的高效率模型,无需任何后处理方法来拟合车道线. 然而,它缺乏对全局上下文信息的学习,导致其在复杂数据集中的准确性较差. Liu等[12 ] 等引入Transformer架构在车道线检测任务中以获得全局特征. 虽然基于参数的方法有较高的推理速度,但在精度方面难以超过其他方法. ...
1
... 基于参数的方法直接输出由曲线方程表示的参数线,可以实现完整的端到端检测. Tabelini等[11 ] 提出PolyLaneNet模型,一个基于深度多项式回归的高效率模型,无需任何后处理方法来拟合车道线. 然而,它缺乏对全局上下文信息的学习,导致其在复杂数据集中的准确性较差. Liu等[12 ] 等引入Transformer架构在车道线检测任务中以获得全局特征. 虽然基于参数的方法有较高的推理速度,但在精度方面难以超过其他方法. ...
2
... 基于行锚的方法通过搜索预定义行锚上最可能包含车道线的单元格,来构建车道线. Qin等[2 ] 提出UFLD模型,以低延迟来换取性能,利用预设的车道锚框信息和全局图像特征进行行搜索,提升了检测效率和实时性. 虽然简单快速,但在复杂的驾驶场景下,其对车道线的检测能力一般. Liu等[13 ] 引入基于条件卷积和基于行锚的公式化的条件车道检测策略. 该类方法首先要定位车道线的起始点,然而,在一些复杂场景中,起始点难以识别,这导致性能相对较差. ...
... CGANet’s experimental results on TuSimple dataset
Tab.3 方法 基线网络 F1/% Acc/% P FP /%P FN /%SCNN[8 ] VGG16 94.97 93.12 7.17 2.20 UFLD[2 ] ResNet18 85.87 93.82 20.05 8.92 ResNet34 86.02 92.86 19.91 8.75 LaneATT[15 ] ResNet18 95.71 92.10 4.56 8.01 ResNet34 95.77 92.63 4.53 7.92 ResNet122 95.59 92.57 6.64 7.17 CondLaneNet[13 ] ResNet18 96.01 93.48 3.18 7.28 ResNet34 95.98 93.37 3.20 8.80 ResNet101 96.24 94.54 3.01 8.82 CLRNet[7 ] ResNet18 95.04 93.97 3.09 7.02 ResNet34 94.73 93.11 2.87 7.92 ResNet101 97.27 96.33 1.86 3.63 CGANet ResNet18 96.73 95.24 1.84 4.80 ResNet34 96.02 93.78 1.97 6.14 ResNet101 97.45 96.67 2.76 2.31
CGANet在Tusimple数据集上的车道线检测效果如图6 所示,考虑到TuSimple数据集包含了较为简单的驾驶场景、较优的外部环境条件以及清晰可辨的车道线,因此展示的检测效果表现良好,证明在条件较为理想的情况下,本节介绍的车道线检测方法能够可靠地执行其功能. ...
Line-CNN: end-to-end traffic line detection with line proposal unit
2
2020
... 基于线锚的方法采用预定义的线锚作为引导,通过回归相对坐标来定位车道. Li等[14 ] 首次在车道线检测中使用线锚. Tabelini等[15 ] 考虑全局信息的重要性,提出新的基于锚的注意力机制. Zheng等[7 ] 提出结合预定义线锚,综合利用全局特征和结合局部特征提升了检测性能. 该类方法是目前车道线检测任务中最有效的方法,因此,本研究基于此类方法展开研究. ...
... CGANet’s experimental results on CULane dataset
Tab.2 方法 基线网络 F1/% mF1/% F1/% N cross FPS/帧 Flops/109 Normal Crowd Dazzle Shadow No line Arrow Curve Ningt SCNN[8 ] VGG16 71.60 38.34 90.60 69.70 58.50 66.90 43.40 84.10 64.40 66.10 1990 7.5 328.4 UFLD[2 ] ResNet18 68.40 38.94 85.90 63.60 57.00 69.60 40.60 79.40 65.20 66.70 2037 282.0 8.4 ResNet34 72.30 38.96 87.70 66.00 58.40 68.80 40.20 81.00 57.90 62.10 1473 170.0 16.9 LaneATT[15 ] ResNet18 74.50 47.35 90.71 69.71 61.82 64.03 47.13 86.82 64.75 66.58 1020 153.0 9.3 ResNet34 74.00 47.57 91.14 72.03 62.47 74.15 47.39 87.38 64.75 68.72 1330 130.0 18.0 ResNet122 74.40 48.48 90.74 69.74 65.47 72.31 48.46 85.29 68.72 68.81 1264 21.0 70.5 CondLaneNet[14 ] ResNet18 75.13 48.84 91.87 74.87 66.72 76.01 50.39 88.37 72.40 71.23 1364 175.0 10.2 ResNet34 76.68 49.11 92.38 74.14 67.17 75.93 49.85 88.89 72.88 71.92 1387 128.0 19.6 ResNet101 77.02 50.83 92.47 74.14 66.93 76.91 52.13 89.16 72.21 72.80 1201 49.0 44.8 CLRerNet[3 ] ResNet18 76.12 52.11 92.60 75.92 70.23 77.33 52.34 88.57 72.68 73.25 1458 119.0 13.2 ResNet34 77.27 52.45 92.53 75.96 70.45 78.92 52.98 89.23 72.81 73.56 1334 104.0 24.5 ResNet101 78.80 52.68 92.80 76.12 69.84 78.95 53.65 89.69 73.45 73.37 1289 50.0 41.2 CLRNet[7 ] ResNet18 78.14 51.92 92.69 75.06 69.70 75.39 51.96 89.25 68.09 73.22 1520 119.0 12.9 ResNet34 78.74 51.14 92.49 75.33 70.57 75.92 52.01 89.59 72.77 73.02 1448 103.0 22.6 ResNet101 79.48 51.55 92.85 75.78 68.49 78.33 52.50 88.79 72.57 73.51 1456 46.0 40.5 CGANet ResNet18 79.58 52.62 92.89 76.03 69.53 76.60 49.73 88.57 72.37 73.13 1321 120.0 13.7 ResNet34 79.73 52.31 92.87 75.86 70.57 76.88 50.03 89.79 73.23 73.74 1216 112.0 30.6 ResNet101 80.13 52.88 92.54 76.78 68.49 79.51 50.58 87.62 73.68 73.36 1262 57.0 42.7
图 5 CULane数据集9种场景检测效果图 ...
3
... 基于线锚的方法采用预定义的线锚作为引导,通过回归相对坐标来定位车道. Li等[14 ] 首次在车道线检测中使用线锚. Tabelini等[15 ] 考虑全局信息的重要性,提出新的基于锚的注意力机制. Zheng等[7 ] 提出结合预定义线锚,综合利用全局特征和结合局部特征提升了检测性能. 该类方法是目前车道线检测任务中最有效的方法,因此,本研究基于此类方法展开研究. ...
... CGANet’s experimental results on CULane dataset
Tab.2 方法 基线网络 F1/% mF1/% F1/% N cross FPS/帧 Flops/109 Normal Crowd Dazzle Shadow No line Arrow Curve Ningt SCNN[8 ] VGG16 71.60 38.34 90.60 69.70 58.50 66.90 43.40 84.10 64.40 66.10 1990 7.5 328.4 UFLD[2 ] ResNet18 68.40 38.94 85.90 63.60 57.00 69.60 40.60 79.40 65.20 66.70 2037 282.0 8.4 ResNet34 72.30 38.96 87.70 66.00 58.40 68.80 40.20 81.00 57.90 62.10 1473 170.0 16.9 LaneATT[15 ] ResNet18 74.50 47.35 90.71 69.71 61.82 64.03 47.13 86.82 64.75 66.58 1020 153.0 9.3 ResNet34 74.00 47.57 91.14 72.03 62.47 74.15 47.39 87.38 64.75 68.72 1330 130.0 18.0 ResNet122 74.40 48.48 90.74 69.74 65.47 72.31 48.46 85.29 68.72 68.81 1264 21.0 70.5 CondLaneNet[14 ] ResNet18 75.13 48.84 91.87 74.87 66.72 76.01 50.39 88.37 72.40 71.23 1364 175.0 10.2 ResNet34 76.68 49.11 92.38 74.14 67.17 75.93 49.85 88.89 72.88 71.92 1387 128.0 19.6 ResNet101 77.02 50.83 92.47 74.14 66.93 76.91 52.13 89.16 72.21 72.80 1201 49.0 44.8 CLRerNet[3 ] ResNet18 76.12 52.11 92.60 75.92 70.23 77.33 52.34 88.57 72.68 73.25 1458 119.0 13.2 ResNet34 77.27 52.45 92.53 75.96 70.45 78.92 52.98 89.23 72.81 73.56 1334 104.0 24.5 ResNet101 78.80 52.68 92.80 76.12 69.84 78.95 53.65 89.69 73.45 73.37 1289 50.0 41.2 CLRNet[7 ] ResNet18 78.14 51.92 92.69 75.06 69.70 75.39 51.96 89.25 68.09 73.22 1520 119.0 12.9 ResNet34 78.74 51.14 92.49 75.33 70.57 75.92 52.01 89.59 72.77 73.02 1448 103.0 22.6 ResNet101 79.48 51.55 92.85 75.78 68.49 78.33 52.50 88.79 72.57 73.51 1456 46.0 40.5 CGANet ResNet18 79.58 52.62 92.89 76.03 69.53 76.60 49.73 88.57 72.37 73.13 1321 120.0 13.7 ResNet34 79.73 52.31 92.87 75.86 70.57 76.88 50.03 89.79 73.23 73.74 1216 112.0 30.6 ResNet101 80.13 52.88 92.54 76.78 68.49 79.51 50.58 87.62 73.68 73.36 1262 57.0 42.7
图 5 CULane数据集9种场景检测效果图 ...
... CGANet’s experimental results on TuSimple dataset
Tab.3 方法 基线网络 F1/% Acc/% P FP /%P FN /%SCNN[8 ] VGG16 94.97 93.12 7.17 2.20 UFLD[2 ] ResNet18 85.87 93.82 20.05 8.92 ResNet34 86.02 92.86 19.91 8.75 LaneATT[15 ] ResNet18 95.71 92.10 4.56 8.01 ResNet34 95.77 92.63 4.53 7.92 ResNet122 95.59 92.57 6.64 7.17 CondLaneNet[13 ] ResNet18 96.01 93.48 3.18 7.28 ResNet34 95.98 93.37 3.20 8.80 ResNet101 96.24 94.54 3.01 8.82 CLRNet[7 ] ResNet18 95.04 93.97 3.09 7.02 ResNet34 94.73 93.11 2.87 7.92 ResNet101 97.27 96.33 1.86 3.63 CGANet ResNet18 96.73 95.24 1.84 4.80 ResNet34 96.02 93.78 1.97 6.14 ResNet101 97.45 96.67 2.76 2.31
CGANet在Tusimple数据集上的车道线检测效果如图6 所示,考虑到TuSimple数据集包含了较为简单的驾驶场景、较优的外部环境条件以及清晰可辨的车道线,因此展示的检测效果表现良好,证明在条件较为理想的情况下,本节介绍的车道线检测方法能够可靠地执行其功能. ...
1
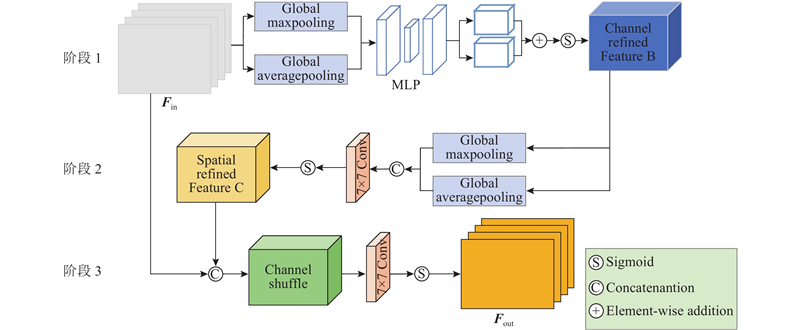
... CBAM[16 ] 由一个通道注意力和一个空间注意力组成,它们被依次放置以计算通道和空间维度上的注意力权重. 通道注意力计算逐通道向量,同时使用平均池化和最大池化操作,生成通道注意力映射,即$ {{F}}_{{\text{CRM}}} ( \cdot )\in {{\bf{R}}^{C \times 1 \times 1}} $ F C ),极大地提高了网络的表示能力;空间注意力沿着通道轴应用平均池化和最大池化操作,应用卷积层来生成空间注意力映射,即$ {{F}}_{{\text{SRM}}} ( \cdot )\in {{\bf{R}}^{1 \times H \times W}} $ F S ). CBAM不平等地对待不同的通道和像素,将其应用于车道线检测任务中,可提高检测性能. ...
1
... 车道线检测的难点之一是如何有效地表示和处理多尺度特征. 最近基于深度学习的车道线检测模型已经使用了特征金字塔网络(feature pyramid network,FPN)[17 ] 作为颈部模块,在低分辨率金字塔特征图中检测大对象,并且在高分辨率金字塔特征图中检测小对象. 高层神经元强烈响应整个对象,而其他神经元更有可能被局部纹理和模式激活的观点,表明增加自上而下的路径以传播高级语义特征的必要性. 然而,传统的自上而下的FPN受到单向信息流的限制. 为了有效解决这个问题,Liu等[18 ] 提出路径聚合网络(path aggregation network,PANet). PANet在FPN的基础上添加了一个额外的自底向上路径聚合网络. 受到以上多尺度特征网络的启发,进而开展进一步的研究. ...
1
... 车道线检测的难点之一是如何有效地表示和处理多尺度特征. 最近基于深度学习的车道线检测模型已经使用了特征金字塔网络(feature pyramid network,FPN)[17 ] 作为颈部模块,在低分辨率金字塔特征图中检测大对象,并且在高分辨率金字塔特征图中检测小对象. 高层神经元强烈响应整个对象,而其他神经元更有可能被局部纹理和模式激活的观点,表明增加自上而下的路径以传播高级语义特征的必要性. 然而,传统的自上而下的FPN受到单向信息流的限制. 为了有效解决这个问题,Liu等[18 ] 提出路径聚合网络(path aggregation network,PANet). PANet在FPN的基础上添加了一个额外的自底向上路径聚合网络. 受到以上多尺度特征网络的启发,进而开展进一步的研究. ...
1
... 首先,预定义的车道线分配给每个特征图之后,先使用ROIAlign[19 ] 获得每条预定义车道线的ROI特征($ {{\boldsymbol{X}}_{\rm{P}}} \in {{\bf{R}}^{C \times {N_{\rm{P}}}}} $ $ 9 \times 9 $ $ {{\boldsymbol{X}}_{\rm{P}}} \in {{\bf{R}}^{C \times 1}} $ $ {{\boldsymbol{X}}_{\rm{f}}} \in {{\bf{R}}^{C \times H \times W}} $ $ {{\boldsymbol{X}}_{\rm{f}}} \in {{\bf{R}}^{C \times HW}} $ X P )和全局特征图(X f )之间的注意力矩阵[20 ] : ...
1
... 首先,预定义的车道线分配给每个特征图之后,先使用ROIAlign[19 ] 获得每条预定义车道线的ROI特征($ {{\boldsymbol{X}}_{\rm{P}}} \in {{\bf{R}}^{C \times {N_{\rm{P}}}}} $ $ 9 \times 9 $ $ {{\boldsymbol{X}}_{\rm{P}}} \in {{\bf{R}}^{C \times 1}} $ $ {{\boldsymbol{X}}_{\rm{f}}} \in {{\bf{R}}^{C \times H \times W}} $ $ {{\boldsymbol{X}}_{\rm{f}}} \in {{\bf{R}}^{C \times HW}} $ X P )和全局特征图(X f )之间的注意力矩阵[20 ] : ...









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}