

机器人抓取是机器人与环境交互的一种重要手段,实现准确、快速地抓取是机器人高质量、高效率地完成抓取任务的前提. 在结构化环境(structured environment)中,待抓取物体的种类通常是十分单一的,并且物体的形状和大小较为规则. 在这种受控环境中,机器人可以充分利用待抓取物体的先验知识,来完成特定的抓取任务. 例如,在工业环境下的工业机器人可以通过事先学习和识别待抓取物体的特征,针对特定的物体准备特定的抓取动作,从而有效地完成抓取任务. 然而,在非结构化环境中,待抓取物体的形状(2D或3D模型)、大小、种类、物理属性等先验知识往往不能预先获取[1-6],并且待抓取物体的位置和姿态会发生变化[1,4,6],实现机器人准确、快速地抓取是一项具有挑战性的任务[1,6-7].
近年来,基于深度学习的抓取方法凭借无需人工设计抓取特征[2-4,6]、特征提取能力强[1,6-7]、泛化性好[2,4,6-9]等优点在机器人抓取领域获得巨大成功. Jiang等[5]提出抓取矩形框,将机器人抓取问题转变为抓取位姿检测问题. Lenz等[6]首先将深度学习应用于抓取检测中,利用深度学习自动提取特征,从而无须耗时费力地人工设计抓取特征. Redmon等[10]直接对抓取框参数进行单阶段回归,有效减少了以往滑动窗口法[5]和两阶段候选[6]导致的检测耗时. Kumra等[11]使用深层网络ResNet50[12]提取抓取特征,该方法表明使用深层网络可提高抓取检测准确率. Guo等[13]将机器人抓取物体过程中的力矩数据作为机器人抓取结果的反馈,使得抓取检测网络可以学习到更丰富的抓取特征. Chu等[14]将非抓取类标签作为角度分类标签的竞争项,利用该方法可对多个物体同时生成抓取检测结果. Zhou等[15]提出旋转锚框机制,该方法改进Guo等[13]的定向锚框,增强了对抓取角度的约束. 夏晶等[8]提出Angle-Net对抓取角度进行精细估计,提高了抓取角度的检测精度. 喻群超等[9]提出3级级联的卷积神经网络来逐级评估抓取检测框,提高了抓取框的检测准确度. Morrison等[16]提出轻量化的GG-CNN,该方法对输入深度图像中每个像素点位置处的抓取参数进行预测,使得网络能够生成像素级的抓取检测结果. 张云洲等[7]将多层级特征应用于抓取检测,该方法对尺度变化的物体表现出较好的检测效果. Kumra等[17]将残差模块[12]引入到GG-CNN中,提高了网络对抓取特征的提取能力. Cheng等[18]使用高斯函数对角度分类标签进行平滑编码,缓解了one-hot编码角度方式存在的抓取角度分类损失的一致性问题. Wang等[19]在Morrison等[16]基础上使用transformer结构取代卷积神经网络作为特征提取主干网络,利用transformer的自注意力机制对输入图像中的全局抓取信息进行建模,实现了更好的抓取检测效果.
1. 问题描述
图 1
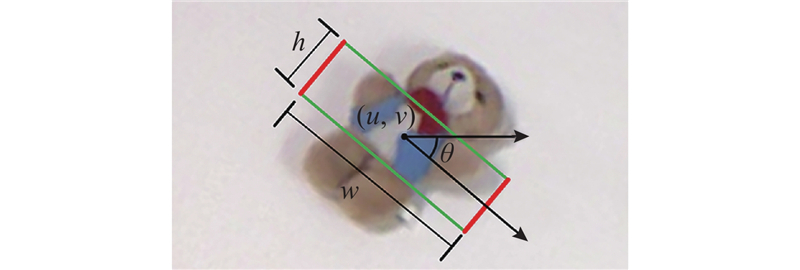
对于确定的末端夹持工具,五维抓取参数可简化为四维抓取参数
图 2
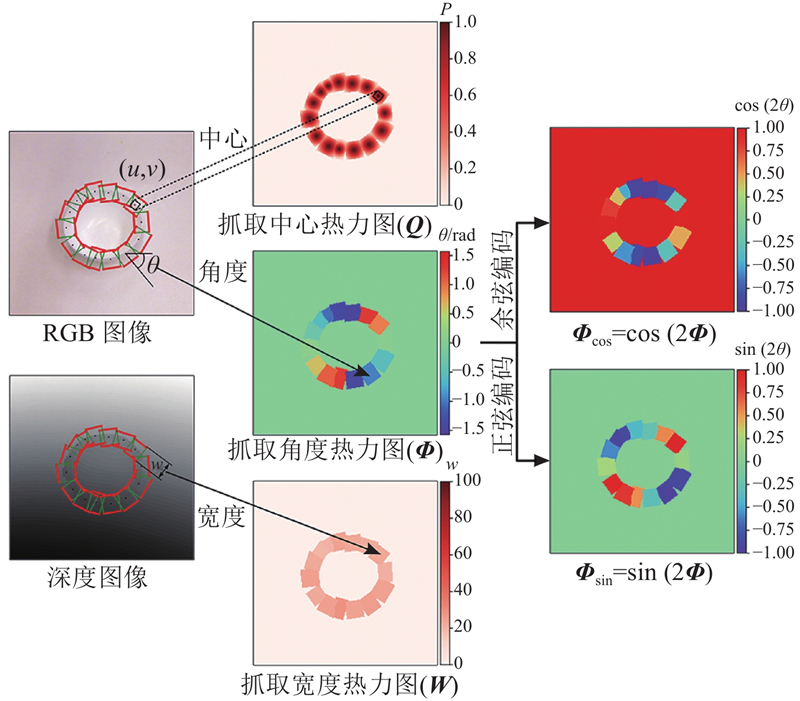
输入图像
式中:
通常,将抓取中心热力图
式中:
综上,机器人抓取检测问题变为如下函数
式中:
2. RTGN抓取检测算法
图 3
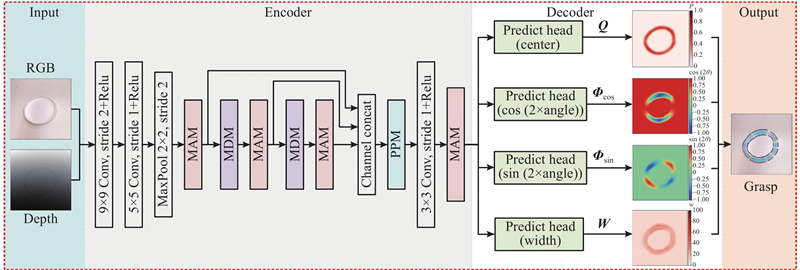
图 3 RTGN抓取检测算法整体结构
Fig.3 Overview architecture of RTGN grasp detection algorithm
如图3所示,RTGN可看作由编码器(encoder)和解码器(decoder)2部分组成. 编码器主要由多尺度空洞卷积模块MDM、混合注意力模块MAM及金字塔池化模块PPM组成,负责从输入的RGB-D图像中提取抓取特征;解码器由预测输出头构成,负责将编码器提取的抓取特征解码为热力图抓取表示. 接下来对各个模块作详细介绍.
2.1. 多尺度空洞卷积模块
图 4
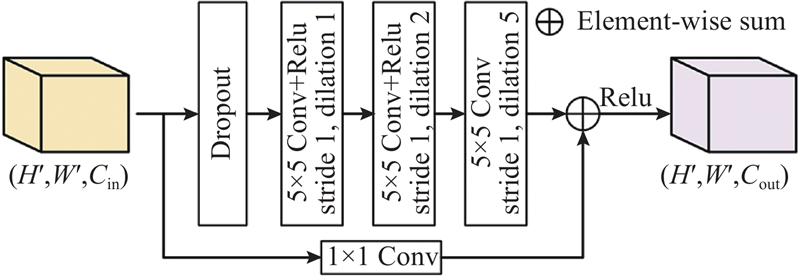
如图5所示,以3×3大小的卷积核为例,当空洞率为1时,空洞卷积核和普通卷积核并无区别,它们感受野大小相同;当空洞率大于1时,空洞卷积核的感受野比普通卷积核更大. 本研究通过将3个不同空洞率的空洞卷积进行串联,使得卷积核能够逐渐感知更大区域的输入特征信息,从而更好地捕捉全局抓取特征,实现高效的抓取特征提取.
图 5
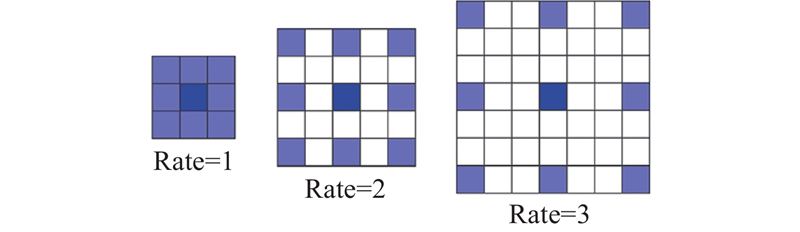
图 5 不同空洞率下3×3大小的空洞卷积核
Fig.5 3×3 dilated convolution kernels at different dilation rates
2.2. 混合注意力模块
在抓取检测任务中,网络提取到的抓取特征并非都对最终的检测结果起关键作用. 为了解决这个问题,将注意力机制引入检测算法中,使网络能够有选择性地关注重要的抓取特征并忽略其他无关的特征. 注意力机制是网络中额外的特殊结构,它通过对输入特征进行加权处理,从而实现对重要特征的关注.
将两者聚合后,混合注意力模块可使网络同时关注于不同通道和空间位置上的重要抓取特征,从而进一步增强网络对重要抓取特征的表达能力.
2.2.1. 通道注意力模块
图 6

2.2.2. 坐标注意力模块
图 7
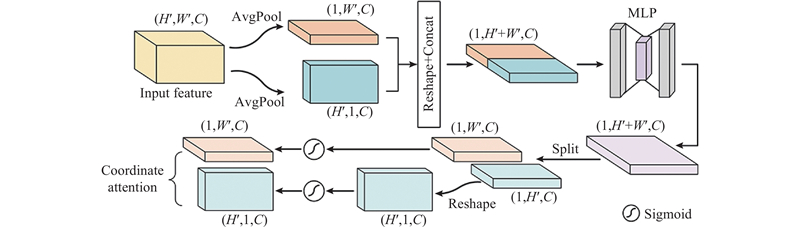
2.2.3. 特征聚合模块
图 8

式中:
2.3. 金字塔池化模块
金字塔池化模块结构如图9所示. 首先,将多层级特征作为模块的输入特征,经过全局自适应平均池化(global adaptive average pooling, GAP)操作,得到4个不同尺度大小的池化子区域特征. 然后,使用1×1卷积对这些池化子区域特征进行降维处理,再对降维后的特征进行上采样操作,使其尺寸与输入特征相同. 最后,将得到的池化子区域特征与输入特征在通道维度进行拼接,并再次使用1×1卷积对拼接特征进行降维,得到最终的融合特征. 多尺度池化子区域的尺寸分别为3×3、7×7、15×15、31×31,这些池化子区域特征聚合了输入特征中不同区域的局部特征. 通过融合这些多尺度池化子区域特征,可以将更广泛的上下文抓取特征用于抓取检测,从而尽可能避免抓取检测算法陷入到局部最优的检测结果.
图 9
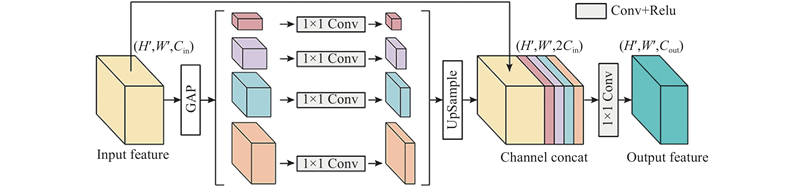
2.4. 预测输出头
预测输出头结构如图10所示. 预测输出头采用全卷积神经网络结构,通过卷积和上采样操作,将主干网络提取的抓取特征以单阶段回归的方式解码为与原始输入图像尺寸相同的抓取中心
图 10
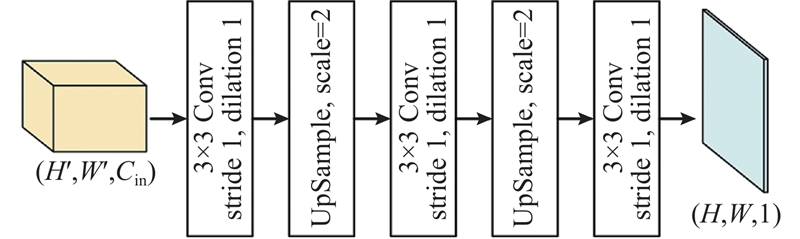
2.5. 损失函数
使用Huber loss函数
式中:
3. 实验结果与分析
3.1. 实验条件
RTGN的搭建和训练在Pytorch(1.13.0)深度学习框架下完成,编程语言为Python(3.9.15). 实验所用计算机操作系统为Ubuntu 20.04,GPU为NVIDIA GeForce RTX 2080,处理器为Intel© CoreTM i9-9900K CPU @ 3.60GHz×16,运行内存为48 GB. 训练时使用Adam参数优化算法,权值衰减(weight decay)为
3.2. 数据集
由于RGB图像和深度图像的像素值数值范围不一致,统一将其线性归一化到[0,1. 0],并以0填充深度图像中的缺省值. 同时,对训练集图像进行数据增强来避免网络在训练过程中出现过拟合. 首先,将图像按标注抓取框中心进行最大尺寸为360×360的随机裁剪;然后,将图像缩放到256×256,并按图像中心在0~360°随机旋转;最后,将旋转后的图像再次缩放到256×256,并在水平、垂直方向上进行随机镜像翻转. 测试集图像的增强在训练集图像增强方式的基础上将随机裁剪变为固定360×360裁剪,并将旋转角度间隔调整为90°,每张测试图像经过增强后得到8张不同的图像.
3.3. 评估指标
1)预测抓取框
2)预测抓取框
式中:
3.4. 实验结果
3.4.1. Cornell抓取数据集实验结果
表 1 Cornell抓取数据集上不同算法对比结果
Tab.1
| 方法 | A/% | v/ms | |
| Image-wise | Object-wise | ||
| Jiang 等[5] | 60. 50 | 58. 30 | 5000 |
| Lenz 等[6] | 73. 90 | 75. 60 | 1350 |
| Redmon 等[10] | 88. 00 | 87. 10 | 76 |
| Kumra 等[11] | 89. 21 | 88. 96 | 103 |
| Guo 等[13] | 93. 20 | 89. 10 | — |
| Chu 等[14] | 96. 00 | 96. 10 | 120 |
| Zhou 等[15] | 97. 74 | 96. 61 | 118 |
| 夏晶等[8] | 93. 80 | 91. 30 | 57 |
| 喻群超等[9] | 94. 10 | 93. 30 | — |
| 张云洲等[7] | 95. 71 | 94. 01 | 17 |
| Morrison 等[16] | 73. 00 | 69. 00 | 19 |
| Kumra 等[17] | 97. 70 | 96. 60 | 20 |
| Cheng 等[18] | 98. 00 | 97. 00 | 73 |
| Wang 等[19] | 97. 99 | 96. 70 | 41. 6 |
| RTGN | 98. 26 | 97. 65 | 7 |
图 11
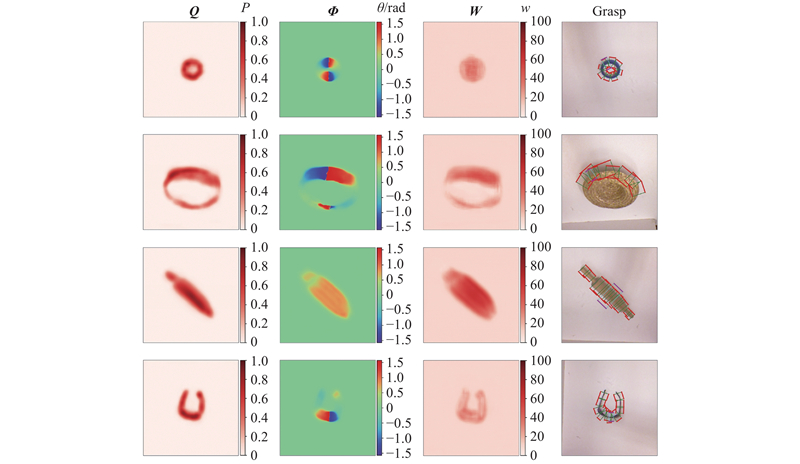
图 11 RTGN在Cornell数据集上的抓取检测可视化结果
Fig.11 Visualization results of grasping detection on Cornell grasping dataset predicted by RTGN
图 12

图 12 Cornell数据集的不完全标注
Fig.12 Incomplete labelled ground truth of Cornell grasping dataset
3.4.2. 消融实验
为了直观理解各模块对RTGN抓取检测性能的影响,对MAM模块和PPM模块进行消融实验. 同时,为了评估本研究设计的MAM模块对检测性能的影响,用已有的CBAM[23]模块对MAM模块进行替换,并进行检测性能对比. 实验环境和训练细节与上文一致,实验结果如表2所示. 其中基线算法(MDM-Backbone)为在RTGN(见图3)基础上去掉MAM模块,并以1×1卷积代替PPM模块,基线算法可用于评估本研究所设计的轻量化特征提取主干网络的检测性能. 实验结果表明,本研究所设计的轻量化特征提取主干网络在检测速度上优势明显(5.29 ms),并且MAM模块和PPM模块能够有效地进一步提升算法的抓取检测准确率. 其次,相比于CBAM[23]模块,无论是将MAM模块单独引入到网络中或是与PPM模块结合,都能够更有效地提升检测准确率. 将MAM模块和PPM模块结合后,算法在图像拆分和对象拆分上的检测准确率有明显提高,同时对算法的检测速度影响较小,从而使得算法的整体性能得到进一步提升.
表 2 Cornell数据集上模块消融实验对比结果
Tab.2
| 网络架构 | A/% | v/ms | |
| Image-wise | Object-wise | ||
| MDM-Backbone | 97. 73 | 96. 80 | 5. 29 |
| +CBAM | 97. 86(+0. 13) | 96. 90(+0. 10) | 6. 42 |
| +MAM | 97. 91(+0. 18) | 97. 00(+0. 20) | 6. 60 |
| +PPM | 97. 95(+0. 22) | 97. 03(+0. 23) | 5. 64 |
| +CBAM+PPM | 98. 08(+0. 35) | 97. 18(+0. 38) | 6. 74 |
| +MAM+PPM | 98. 26(+0. 53) | 97. 65(+0. 85) | 6. 96 |
3.4.3. 模型参数大小对比实验
表 3 不同方法的模型性能和参数大小对比结果
Tab.3
与使用知识蒸馏[25]来使模型轻量化的方法不同的是,RTGN的轻量化是通过设计更为简单、轻量的网络结构来实现的. 这使得RTGN不依赖于教师模型,从而可以避免额外的训练过程以及教师模型性能对学生模型性能的影响,使得RTGN能够独立地达到理想的性能.
3.4.4. 单个未知物体抓取检测实验
为了评估RTGN对真实环境下的未知物体的抓取检测泛化性,从日常生活中选取69个形状、大小、种类等变化不一的物体进行抓取检测实验,使用的相机为Intel RealSense L515 RGB-D相机. 须注意的是,所选取的物体都未参与到RTGN的训练过程,即实验中使用的物体对RTGN来说都是未知物体,这可以较好地评估RTGN的泛化能力. 并且,与RTGN训练时所用的Cornell抓取数据集的白色背景不同,实际抓取场景下的光影变化、背景变化干扰更加明显,这要求抓取检测算法具有较好的鲁棒性. 在实验时每个物体按照不同的位置和姿态进行摆放,然后由RTGN生成抓取检测结果 (
图 13

3.4.5. 多个未知物体抓取检测实验
在单个未知物体的抓取检测实验基础上,对多个未知物体进行抓取检测实验. 如图14所示为RTGN对多个未知物体的抓取检测的可视化结果. 图中,从上到下的每行图像分别为抓取中心
图 14

图 14 RTGN对多个未知物体的抓取检测可视化结果
Fig.14 Visualization results of grasping detection for multiple novel objects predicted by RTGN
如图14所示,尽管RTGN在训练时仅使用了单个物体,但在多个未知物体的抓取检测任务中,RTGN仍能生成准确的预测热力图,从而得出可靠的抓取检测结果. 该实验表明RTGN能够较好地适应多个未知物体的抓取检测.
3.5. 机器人抓取实验
为了进一步评估RTGN抓取真实环境中的未知物体的应用效果,搭建了如图15所示的机器人抓取平台. 所使用的机器人为大象6自由度机械臂Pro600,图中数字1~6代表其6个关节;相机为Intel RealSense L515 RGB-D相机,相机与机器人之间以eye-to-hand方式固定安装;末端夹持工具为平行二指电动夹爪.
图 15

机器人抓取实验所用物体为抓取检测实验中选取的20个代表物体,如图16所示. 这些物体的形状、大小、种类各不相同,并且都未参与到RTGN的训练过程,即抓取物体均为未知物体.
图 16

在机器人抓取实验中,采用顶抓策略控制机械臂执行抓取动作. 首先,初始化机械臂位姿以及夹爪张开宽度,并将RTGN在图像像素坐标系下的抓取检测结果转换到机器人基座坐标系,得到抓取点位置和抓取角度;然后,控制机械臂末端到达抓取点的正上方,并旋转末端执行器至对应的抓取角度;最后,控制机械臂末端竖直向下移动(夹爪抓取深度应尽可能大,以增大夹爪两指与物体的接触面积,避免物体滑动,同时也要考虑夹爪两指抓取区域环境深度分布情况和夹爪两指长度限制,以避免发生碰撞),并使夹爪闭合,完成对物体的抓取.
RTGN的抓取检测结果由图像像素坐标系下向机器人基底坐标系下的转换如下:
式中:
图 17

表 4 机器人抓取统计结果
Tab.4
| 物体 | As | 物体 | As | |
| 桔子 | 100% (20/20) | 糖果 | 100% (20/20) | |
| 饼干 | 100% (20/20) | 塑料盘 | 100% (20/20) | |
| 鼠标 | 85% (17/20) | 塑料碗 | 95% (19/20) | |
| 纸杯 | 90% (18/20) | 雨伞 | 80% (16/20) | |
| 酒精喷雾瓶 | 90% (18/20) | 胶布 | 100% (20/20) | |
| 五号电池 | 100% (20/20) | 圆柱积木 | 100% (20/20) | |
| 螺丝刀 | 100% (20/20) | 牛奶盒 | 95% (19/20) | |
| 牙膏盒 | 100% (20/20) | 牙膏 | 90% (18/20) | |
| 洗衣液瓶 | 100% (20/20) | 刷子 | 100% (20/20) | |
| 洗面奶 | 95% (19/20) | 化妆水瓶 | 100% (20/20) |
4. 结 语
为了进一步提升机器人对形状、大小、种类等变化不一的未知物体的抓取检测准确率及检测速度,本研究提出轻量化的抓取位姿实时检测算法. 算法以多尺度空洞卷积模块为基础来构建轻量化的特征提取主干网络,有效地提升了检测速度. 通过结合混合注意力模块和金字塔池化模块,增强了算法对重要抓取特征的表达能力以及对抓取物体的抓取感知能力,进一步提升了检测准确率. 实验结果表明,相比于现有算法,所提算法兼顾了检测准确率和检测速度2方面性能的进一步提升. 在真实抓取场景中,所提算法对形状、大小、种类等变化不一的未知物体表现出良好的抓取检测效果,对多个未知物体的抓取检测也有较好的适应性.
尽管本研究所提方法取得了较好的准确率与实时性,但仍然存在一些有待改进的地方. 由于所提算法在检测时无须考虑抓取物体的种类,这可能导致机器人对多个物体进行抓取时不能优先抓取指定类别的物体. 在未来的工作中可以将目标检测和语义分割方法进行结合,避免抓取过程的无序性.
参考文献
机器人抓取检测技术的研究现状
[J].
Recent researches on robot autonomous grasp technology
[J].
Data-driven grasp synthesis: a survey
[J].DOI:10.1109/TRO.2013.2289018 [本文引用: 2]
基于多模特征深度学习的机器人抓取判别方法
[J].
Multimodal features deep learning for robotic potential grasp recognition
[J].
一种基于深度学习的机械臂抓取方法
[J].
A robotic grasping method based on deep learning
[J].
Deep learning for detecting robotic grasps
[J].
基于多层级特征的机械臂单阶段抓取位姿检测
[J].
Single-stage grasp pose detection of manipulator based on multi-level features
[J].
基于级联卷积神经网络的机器人平面抓取位姿快速检测
[J].
Fast planar grasp pose detection for robot based on cascaded deep convolutional neural networks
[J].
基于三级卷积神经网络的物体抓取检测
[J].
Object grasp detecting based on three-level convolution neural network
[J].
Real-world multiobject, multigrasp detection
[J].DOI:10.1109/LRA.2018.2852777 [本文引用: 7]
When transformer meets robotic grasping: exploits context for efficient grasp detection
[J].DOI:10.1109/LRA.2022.3187261 [本文引用: 14]
Dropout: a simple way to prevent neural networks from overfitting
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}