

准确且快速地识别障碍物是无人驾驶电机车安全运行的重要前提. 目前,常用的障碍物识别方法主要包括激光雷达、毫米波雷达及基于计算机视觉的目标检测技术等. 其中激光雷达与毫米波雷达分别通过激光和电磁波的反射来识别障碍物,然而煤矿巷道环境不同于地面环境,光线不足以及凹凸不平的巷道壁面容易使毫米波雷达和激光雷达产生噪声,导致障碍物检测不准确的问题. 激光雷达价格昂贵、使用寿命短,增加了生产成本[4]. 基于计算机视觉的深度学习目标检测模型具有部署简单、成本低廉、抗干扰能力强等优点,更适合作为煤矿无人驾驶轨道电机车的障碍物识别方法.
随着图像处理技术的发展,基于计算机视觉的目标检测技术在各个领域中得到了广泛使用,被越来越多地应用到矿山领域的检测场景中. 靳舒凯等[5]通过构建轻量级YOLOv4网络模型,提高了煤矿副井矿车装载物识别的速度. 卢万杰等[6]基于深度学习算法建立煤矿设备类型识别模型,实现了巡检机器人对煤矿设备的精确识别与分类. 李伟山等[7]提出改进Faster RCNN算法,提高了模型在环境恶劣的煤矿井下巷道中对行人的检测精度. Pan等[8]通过对tiny-YOLOv3进行改进,提出有效的煤和矸石快速识别模型,为煤矸分选技术提供理论依据. 张庆贺等[9]基于YOLOv5,结合数字图像相关技术(digital image correlation, DIC)构建的云图,提出智能识别复杂裂隙岩石破坏的方法,定量研究复杂裂隙岩石变形破坏的规律及裂隙扩展特征. 李飞等[10]提出改进型YOLOv4检测模型,实现对矿用带式输送机的纵向撕裂裂纹的精准识别检测. 可见,深度学习目标检测算法在煤矿领域中的应用能够提高安全生产水平,提高了生产效率和经济效益,对实现煤矿智能化具有重要意义.
利用基于计算机视觉的目标检测技术,能够保证物体边界的完整性,实现在不同的光照条件、角度和尺度等情况下准确地识别目标物体,然而复杂的煤矿井下巷道环境对模型的检测性能提出了较高的要求. 本研究基于YOLOv5,通过构建C3_P特征提取模块,增强模型的泛化能力和鲁棒性. 对模型的预测头进行解耦,提高模型的收敛速度和检测精度. 优化Mosaic数据增强方法,丰富训练样本特征. 提出用于无人驾驶电机车障碍物精准实时检测的PDM-YOLO模型,旨在为煤矿无人驾驶轨道电机车提供安全、可靠的障碍物检测方法.
1. PDM-YOLO模型
1.1. 构建C3_P特征提取模块
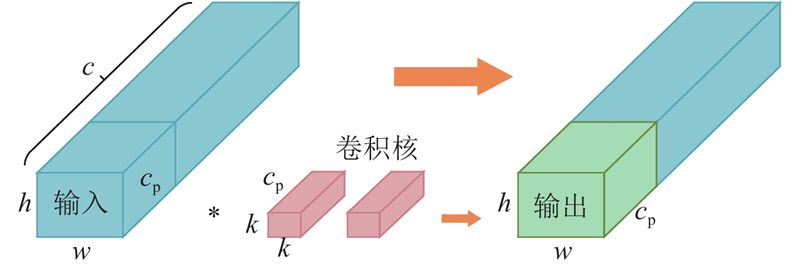
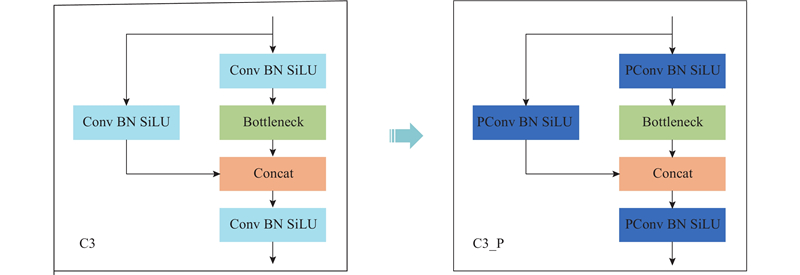
“更快更轻”的神经网络是计算机视觉领域的未来发展趋势,现有如MobileNet[11]、ShuffleNet[12]、GhostNet[13]等轻量化神经网络利用深度卷积(depthwise convolution)或组卷积(group convolution)提取特征,与传统神经网络相比,在计算量(浮点运算数量FLOPs)方面得到了一定程度的改进,降低了模型的复杂性. 这些网络由于频繁的内存访问及伴有较多的卷积、池化、级联等额外的数据操作,增加了运行时间和延迟时间,降低了模型的计算效率. 为了降低模型的计算量,提高模型的计算速度,采用部分卷积(partial convolution, PConv)[14]替换YOLOv5模型C3模块中的传统卷积(Conv),构建C3_P特征提取模块. 部分卷积过程如图1所示,仅对一部分输入通道cp应用传统卷积,并保持其余通道不变,通过减少冗余计算和内存访问,更加有效地提取空间特征.
图 1
部分卷积与传统卷积的FLOPs表达式如下所示:
部分卷积与传统卷积的内存访问量(memory access cost, MAC)的表达式如下所示:
通常部分卷积的通道数cp与输入通道数c的比值为1/4,则部分卷积的FLOPs仅为传统卷积的1/16,有效降低了模型的计算总量. 部分卷积的MAC为传统模型的1/4,有效减少了模型的延迟时间,提高了计算速度.
传统C3与C3_P特征提取模块的结构如图2所示,通过将卷积块(Conv BN SiLU)中的传统卷积Conv替换为部分卷积PConv,得到新的卷积块(PConv BN SiLU),其中BN为批标准化(batch normalization),SiLU为激活函数. 传统YOLOv5的每秒浮点运算次数(FLOPs)为15.9×109,检测速度为118.9 帧/s. 引入C3_P模块后模型的FLOPs为13.0×109,检测速度为135.1 帧/s. C3_P模块的引入使得模型的FLOPs减少了2.9×109,检测速度提高了16.2 帧/s.
图 2
1.2. 预测头解耦
YOLOv5的预测头负责从输入特征图中提取目标检测的结果,输出包含每个检测到的目标的类别标签(Cls)、边界框位置信息(Reg)及目标存在的置信度得分(Obj). 传统YOLOv5采用耦合的检测头输出预测结果,如图3(a)所示,通过1×1的卷积实现分类与回归任务,但这种耦合的预测头通常存在定位精度不准确的问题. 为了解决该问题,对预测头进行解耦,分别开展分类与回归任务. 在YOLO系列模型中,YOLOX[15]模型采用解耦预测头(decoupled head),如图3(b)所示,输入特征图经过1×1的卷积进行降维处理,经过分类、回归2个分支,每个分支上包括2个3×3的卷积,负责回归任务的分支划分为2个,分别用于确立边界框位置信息及置信度得分的分支. 解耦后的预测头提高了模型的收敛速度和检测精度,但会大幅增加模型的计算成本. 对YOLOX解耦头进行改进,如图3(c)所示,在分类和回归2个分支上分别减少3×3的卷积,以减小模型的参数量和推理时间. YOLOv5模型分别添加传统YOLOX解耦头及改进解耦头的计算量及检测速度v对比如表1所示,改进后解耦头的FLOPs较传统解耦头减少了19.8×109,检测速度提高了14.7 帧/s.
图 3
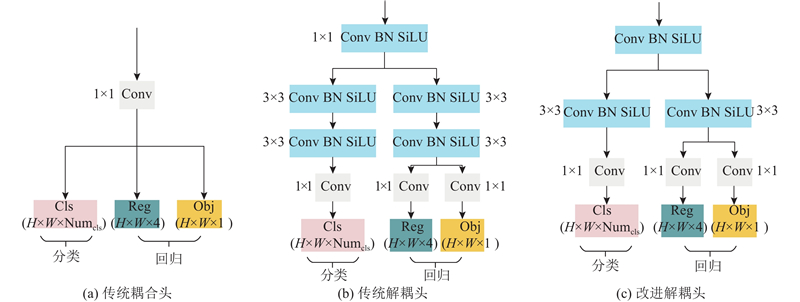
表 1 模型添加2种解耦头的浮点运算总量及检测速度的对比
Tab.1
| 模型 | FLOPs/109 | v/(帧·s−1) |
| YOLOv5-YOLOX解耦头 | 56.3 | 89.5 |
| YOLOv5-改进的解耦头 | 36.5 | 104.2 |
1.3. 优化Mosaic数据增强
当训练目标检测模型时,数据增强是常用的丰富数据集的技术. 数据增强通过对原始图像进行变换、扭曲、缩放等操作,增加了训练样本的多样性,使得模型能够更好地学习到不同场景下的目标特征,提高了模型的泛化能力和鲁棒性,在提升检测精度的同时不会增加计算成本,非常有益于目标检测任务. 常用的数据增强方法分为基于光学畸变和基于几何畸变两大类. 基于光学畸变的数据增强方法包括调整训练图像的亮度、对比度、饱和度和图像噪声等,几何畸变包括对训练图像进行随机缩放、剪裁、翻转、旋转等.
YOLOv5除了使用基本的光学畸变及几何畸变数据增强方法外,还采用 Mosaic 数据增强[16]. Mosaic数据增强的主要思想是在模型训练时随机挑选4张图像进行任意尺寸的裁剪、缩放,再随机排列拼接形成1张图像,有效地增加了训练样本的数量和图像的复杂度,提高了模型的鲁棒性及训练效率. 煤矿井下巷道环境恶劣,障碍物目标存在光照不足、遮挡及小目标特征不明显的问题. 为了进一步丰富障碍物目标特征,优化Mosaic数据增强方法,将一次随机处理4张图像改进为一次随机处理9张图像. 如图4(a)、(b)所示分别为改进前(Mosaic-4)与改进后(Mosaic-9)的Mosaic数据增强效果示意图. 可以看出,改进后的Mosaic-9数据增强处理后的图像包含更多的障碍物目标数量,有利于模型在训练过程中学习到更多的障碍物目标特征.
图 4
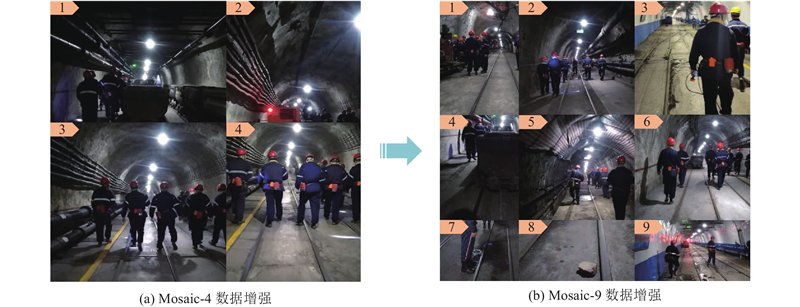
图 4 优化前、后的Mosaic数据增强效果对比
Fig.4 Comparison of Mosaic data enhancement effects before and after optimization
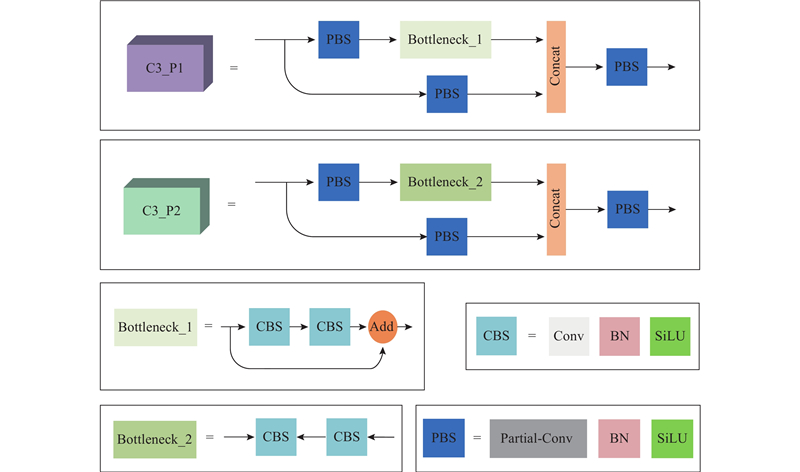
1.4. PDM-YOLO模型结构
PDM-YOLO网络结构如图5所示,模型由输入端(Input)、骨干(Backbone)、颈部(Neck)及预测头(Head)4部分组成. 根据Bottleneck结构的不同,设计C3_P1与C3_P2 2种特征提取模块,如图6所示,C3_P1与C3_P2分别应用在模型的骨干和颈部中. 模型骨干的末端采用金字塔池化模块(spatial pyramid pooling-fast, SPPF). SPPF采用3个相同大小的池化核,分别对输入特征图进行最大池化,得到统一大小的特征向量. 将这些特征向量按照一定的规则拼接在一起,形成固定大小的输出特征向量. 该输出特征向量包含了不同大小、比例和位置的目标的信息,可以用于后续的分类和回归任务,即SPPF能够在不同大小的感受野下提取特征并保持特征图的尺寸不变. 模型颈部采用特征金字塔(feature pyramid network, FPN)和路径聚合网络(path aggregation network, PANet)2个特征融合组件[17-18]. FPN是自上而下传递高层语义特征的金字塔结构,PANet是自下而上传递低层定位特征的金字塔结构. 模型颈部通过FPN结合PANet的结构,可以从不同尺度上对特征图进行聚合和加权,实现特征的有效融合. 模型预测头采用改进后的解耦头,从3种不同尺度输出预测结果.
图 5
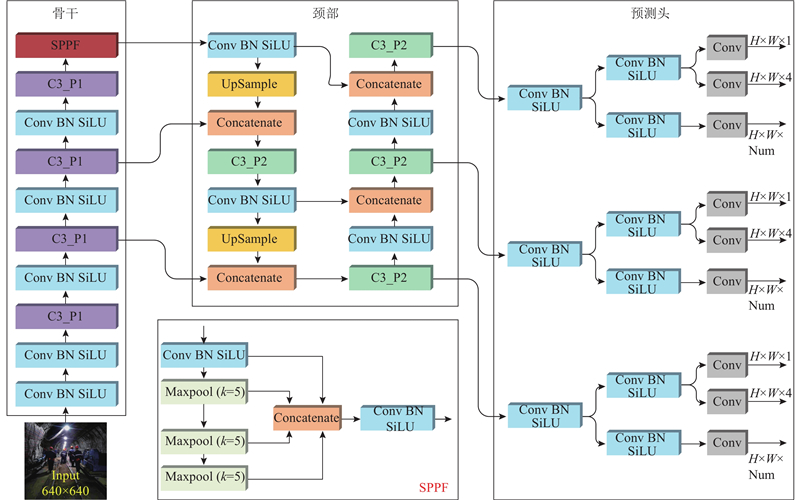
图 6
2. 实验分析
2.1. 模型训练
煤矿井下巷道不同于地面环境,传统的PASCAL VOC、COCO公共数据集难以准确体现出井下障碍物的特征,因此在安徽省淮南市顾桥煤矿及淮北市袁店一矿的井下巷道中沿着电机车的行驶路线采集图像,创建障碍物检测数据集.为了进一步丰富数据集,提高模型的鲁棒性,在拍摄时考虑不同的拍摄角度、障碍物所处的不同光照条件、位置以及障碍物部分遮挡情况等,获取的每张图像中包含多个数量或者不同种类的障碍物目标. 经过筛选得到训练集图像3 000张,建立测试集图像500张,用于验证模型的检测效果. 其中3 000张训练集图像中包含的障碍物目标总数量为16 195个,500张测试集图像包含的障碍物目标数量为2 857个.
影响井下无人驾驶轨道电机车安全运行的障碍物类别主要为行走的矿工、同轨道行驶的电机车、煤矿运输小车、载物平板车及洒落的矸石等. 将这5种典型的障碍物作为检测对象(与其他4类障碍物相比,矸石的体积更小且目标特征不明显, 因此将矸石作为小目标障碍物进行检测,本研究检测的矸石粒径大于100 mm),采用LabelImg标注工具对图像中的障碍物进行标注,分别以“Miner”、“Locomotive”、“Mine_car”、“Flat_car”、“Gangue”作为矿工、电机车、煤矿运输小车、载物平板车及矸石的训练标签. 部分训练数据集的图像如图7所示.
图 7

本研究的模型训练基于Ubuntu系统,计算机使用的CPU及GPU型号分别为AMD-5800X与GeForce-RTX-3060. 在训练模型前,调整训练超参数以获取最优模型,具体参数如表2所示.
表 2 模型训练超参数设定
Tab.2
| 超参数 | 参数值 |
| 输入图像尺寸(image size) | 640×640 |
| 学习率(learning rate) | 0.01 |
| 动量(momentum) | 0.937 |
| 权重衰减系数(weight decay) | 0.0005 |
| 色调(hue augmentation) | 0.015 |
| 饱和度(saturation augmentation) | 0.7 |
| 曝光度(value augmentation) | 0.4 |
| Mosaic | 1.0 |
| Mixup | 1.0 |
2.2. 模型评价指标
衡量目标检测算法的主要指标包括精确率P(precision)、召回率R(recall)、精度均值(average precision, AP)、平均精度均值(mean average precision, mAP)、FLOPs及检测速度等[19-20]. P称为查准率,是指模型预测的所有目标中正确预测所占的比例. R 称为查全率,是指在所有的真实目标中模型正确预测目标所占的比例. AP是以P 为纵坐标、R 为横坐标得到的曲线下方与坐标轴围成的封闭图形面积,指模型对某个同类目标的平均检测精度. mAP指模型对所有种类目标的平均检测精度. 其中AP0.5与mAP0.5分别表示交并比(intersection over union, IoU)阈值 > 0.5时的AP及mAP,mAP 0.5:0.95表示IoU阈值为0.5~0.95且步长为0.05时的平均mAP. 各指标的表达式如下所示:
式中:TP为正样本被正确检测的数量, FP为负样本被检测为正样本的数量,FN为正样本未被检测出的数量,Npred为预测出的所有检测框的数量,NGT为所有真实框(人工标注框ground truth)的数量.
2.3. 消融实验
通过消融实验,验证各个改进方案的有效性. 基于建立的障碍物检测数据集,分别测试不同改进方案下模型的检测性能,结果如表3所示. 模型仅使用构建的C3_P特征提取模块时,mAP为95.7%,FLOPs为13.0×109,与传统YOLOv5相比,单一使用C3_P的模型(YOLOv5-C3_P)使得mAP提高了2.6%,FLOPs降低了2.9×109. 当模型仅采用改进的解耦预测头(YOLOv5-Decoupled)时,mAP由原来的93.1%提高至96.1%, 但FLOPs增加了20.6×109. 模型使用优化后的Mosaic数据增强(YOLOv5-Mosaic9)未改变模型的计算总量,使得mAP提高了0.1%. 综合使用3种改进方法得到的PDM-YOLO模型,使得mAP由传统YOLOv5的93.1%提高至96.3%. 综上所述,3种改进方案均有利于提高模型的检测精度,使用改进的解耦预测头方案更加有效地提升了模型的检测精度.
表 3 消融对比分析
Tab.3
| 模型 | AP0.5/% | mAP0.5/% | FLOPs/109 | ||||
| Miner | Locomotive | Mine_car | Flat_car | Gangue | |||
| YOLOv5 | 93.1 | 97.8 | 92.3 | 85.3 | 97.2 | 93.1 | 15.9 |
| YOLOv5-C3_P | 96.9 | 97.5 | 94.5 | 97.6 | 92.3 | 95.7 | 13.0 |
| YOLOv5-Decoupled | 96.4 | 97.8 | 93.1 | 99.5 | 93.8 | 96.1 | 36.5 |
| YOLOv5-Mosaic9 | 96.3 | 98.5 | 95.2 | 78.3 | 97.6 | 93.2 | 15.9 |
| PDM-YOLO | 96.3 | 97.7 | 94.6 | 99.1 | 93.7 | 96.3 | 33.4 |
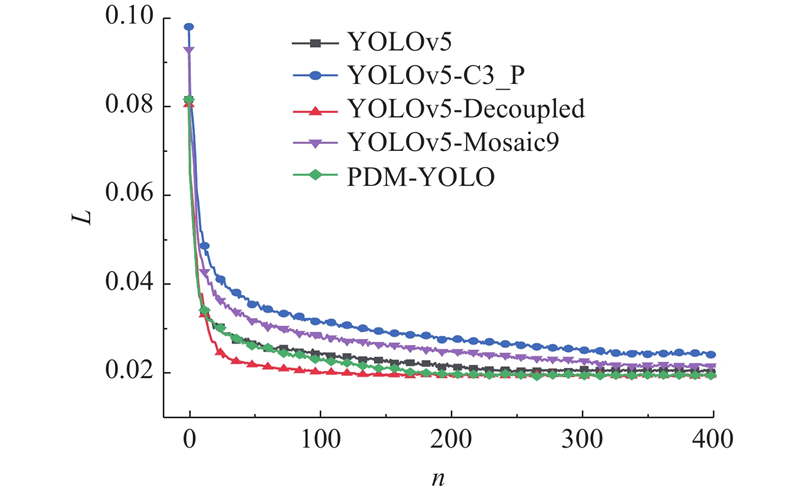
训练模型时,模型损失函数的数值随着迭代次数的增加而逐步减少,最终趋于稳定值而达到收敛状态. YOLOv5的损失函数由3部分组成,分别为定位损失函数、分类损失函数及置信度损失函数. 其中定位损失函数采用CIoU损失函数,分类损失函数及置信度损失函数采用二元交叉熵损失函数,模型的总损失值为3部分损失之和. 如图8所示为表4中各模型的训练总损失L对比. 图中,n为迭代次数. YOLOv5、YOLOv5-C3_P、YOLOv5-Decoupled、YOLOv5-Mosaic9、PDM-YOLO这5种模型的损失分别在迭代训练约240、320、100、350、180次后趋于稳定状态,YOLOv5-Decoupled模型的收敛速度更快,验证了解耦后的预测头提升了模型的收敛速度.
图 8
2.4. 不同模型检测的对比
目标检测模型主要分为以下2大类:一类是以RCNN系列[21-23]为代表的双阶段目标检测模型,首先生成候选框,再进行样本分类;另一类是以YOLO系列[24-26]为代表的单阶段目标检测模型,直接输出包含位置及分类信息. 双阶段目标检测模型的检测精度较高,但由于计算过程繁琐、推理时间长,检测速度通常仅为几帧每秒,无法在实时检测的场景中使用[27-28]. 基于建立的障碍物检测数据集,将PDM-YOLO模型与综合检测性能较优越的单阶段YOLO系列模型进行训练及测试,测试结果如表4所示. YOLOv3及YOLOv4模型的mAP分别达到93.2%和93.1%,但模型的FLOPs较大,分别为154.6×109和141.1×109. 2种模型的检测速度分别为27.0 和31.8 帧/s,与其他模型相比,检测速度较小,2种模型的内存大小分别为246.4和256.1 MB,其尺寸是PDM-YOLO的近10倍,不利于模型的部署. YOLOv3-Tiny以及YOLOv4-Tiny这2种轻量化模型的计算量少,检测速度快,模型内存小,但2种模型的mAP分别为88.9%和88.7%,对障碍物的检测精度较低. 与较高版本的YOLOv5、YOLOv6、YOLOv7及YOLOv8相比,4种模型的mAP及检测速度处于平均水平,但YOLOv6、YOLOv7及YOLOv8的计算量和内存大小均高于YOLOv5. 在YOLOv5模型的基础上提出PDM-YOLO模型,PDM-YOLO模型的mAP达到96.3%,检测速度达到109.2 帧/s,在计算量和内存大小方面均处于较低水平,PDM-YOLO模型的综合性能优于表4中的其他模型.
表 4 不同模型的对比分析
Tab.4
| 模型 | AP0.5/% | mAP0.5/% | FLOPs /109 | v/(帧·s−1) | 内存/MB | ||||
| Miner | Locomotive | Mine_car | Flat_car | Gangue | |||||
| YOLOv3 | 94.1 | 96.6 | 91.2 | 92.3 | 91.6 | 93.2 | 154.6 | 27.0 | 246.4 |
| YOLOv4 | 94.2 | 97.5 | 93.0 | 90.1 | 90.8 | 93.1 | 141.1 | 31.8 | 256.1 |
| YOLOv3-Tiny | 92.3 | 93.8 | 91.8 | 80.6 | 86.4 | 88.9 | 12.9 | 117.8 | 34.7 |
| YOLOv4-Tiny | 91.3 | 93.4 | 91.9 | 80.8 | 86.1 | 88.7 | 16.1 | 126.5 | 23.6 |
| YOLOv5 | 93.1 | 97.8 | 92.3 | 85.3 | 97.2 | 93.1 | 15.9 | 118.9 | 14.4 |
| YOLOv6 | 93.8 | 96.2 | 93.2 | 87.2 | 97.2 | 93.5 | 44.1 | 109.8 | 38.0 |
| YOLOv7 | 95.1 | 97.1 | 92.3 | 90.8 | 93.1 | 93.7 | 26.1 | 105.2 | 19.0 |
| YOLOv8 | 94.2 | 97.8 | 91.7 | 92.9 | 92.8 | 93.9 | 28.4 | 111.3 | 22.5 |
| PDM-YOLO | 96.3 | 97.7 | 94.6 | 99.1 | 93.7 | 96.3 | 33.4 | 109.2 | 26.6 |
2.5. 检测结果的对比
为了验证PDM-YOLO模型对障碍物的检测效果,在煤矿井下巷道的实际场景中对传统YOLOv5和PDM-YOLO进行对比检测,测试结果如图9所示. 图中,A1~A12为PDM-YOLO的检测结果,B1~B12为传统YOLOv5的检测结果. 2种模型的对比检测情况如表5所示. 表中,图A1~A3、B1~B3为障碍物部分遮挡的场景,图A4~A6、B4~B6为光照不足的场景,图A7~A9、B7~B9为小目标障碍物的场景,图A10~A12、B10~B12为远距离障碍物的场景. PDM-YOLO在不同场景下均能够准确识别出障碍物,未出现障碍物漏检的情况,而传统YOLOv5出现了较多的障碍物漏检问题,PDM-YOLO具有较高的鲁棒性和优良的检测性能.
图 9

图 9 PDM-YOLO与YOLOv5检测结果的对比
Fig.9 Comparison of PDM-YOLO and YOLOv5 detection results
表 5 PDM-YOLO与YOLOv5检测结果的对比分析
Tab.5
| 场景 | 图像编号 | PDM-YOLO检测结果 | YOLOv5检测结果 |
| 障碍物部分遮挡 | A1,B1 | 无漏检 | 漏检矿工 |
| A2,B2 | 无漏检 | 漏检矿工 | |
| A3,B3 | 无漏检 | 漏检矿工 | |
| 光照不足 | A4,B4 | 无漏检 | 漏检矿工 |
| A5,B5 | 无漏检 | 漏检矿工 | |
| A6,B6 | 无漏检 | 漏检矿工 | |
| 小目标障碍物 | A7,B7 | 无漏检 | 漏检矸石 |
| A8,B8 | 无漏检 | 漏检矸石 | |
| A9,B9 | 无漏检 | 漏检矸石 | |
| 远距离障碍物 | A10,B10 | 无漏检 | 漏检矿工 |
| A11,B11 | 无漏检 | 漏检矿工 | |
| A12,B12 | 无漏检 | 漏检矿工及煤矿运输小车 |
表 6 障碍物检测数量的对比
Tab.6
| 模型 | Nc | Nf | Nm | Nz |
| YOLOv3 | 2 618 | 48 | 191 | 2 857 |
| YOLOv4 | 2 656 | 42 | 159 | 2 857 |
| YOLOv3-Tiny | 2 515 | 59 | 283 | 2 857 |
| YOLOv4-Tiny | 2 554 | 51 | 252 | 2 857 |
| YOLOv5 | 2 675 | 31 | 151 | 2 857 |
| YOLOv6 | 2 652 | 47 | 158 | 2 857 |
| YOLOv7 | 2 686 | 36 | 135 | 2 857 |
| YOLOv8 | 2 692 | 42 | 123 | 2 857 |
| PDM-YOLO | 2 786 | 19 | 52 | 2 857 |
2.6. 公共数据集的检测精度对比
为了验证PDM-YOLO模型的检测精度, 基于2.1节的同一计算机配置及训练超参数,分别在PASCAL VOC 2007和PASCAL VOC 2012公共数据集上对比测试了PDM-YOLO、传统YOLOv5、YOLOv6、YOLOv7及YOLOv8模型. 对比结果如表7所示. PDM-YOLO模型在PASCAL VOC 2007公共数据集上的mAP0.5为70.9%,在PASCAL VOC 2012公共数据集上的mAP0.5为71.1%,均高于YOLOv5~YOLOv8模型组. PDM-YOLO模型在PASCAL VOC 2007公共数据集上的mAP0.5:0.95为49.0%,高于YOLOv5~YOLOv8模型组,在PASCAL VOC 2012公共数据集上的mAP0.5:0.95为49.6%,高于YOLOv5和YOLOv6模型,略低于YOLOv7和YOLOv8模型. 综合比较可知, PDM-YOLO模型在公共数据集上具有较高的检测精度.
表 7 不同模型在公共数据集上的检测精度比较
Tab.7
| 模型 | PASCAL VOC 2007 | PASCAL VOC 2012 | |||
| mAP0.5 /% | mAP0.5:0.95 /% | mAP0.5 /% | mAP0.5:0.95 /% | ||
| YOLOv5 | 68.7 | 48.8 | 70.6 | 48.4 | |
| YOLOv6 | 61.4 | 43.3 | 61.9 | 43.2 | |
| YOLOv7 | 67.6 | 47.8 | 69.9 | 49.8 | |
| YOLOv8 | 66.1 | 48.9 | 66.3 | 49.7 | |
| PDM-YOLO | 70.9 | 49.0 | 71.1 | 49.6 | |
3. 结 论
(1)针对现有煤矿井下无人驾驶轨道电机车因巷道环境恶劣导致障碍物识别精度低的问题,提出基于传统YOLOv5的PDM-YOLO检测模型. 实验结果表明,在自制障碍物检测数据集上,PDM-YOLO模型的mAP由原来的93.1%提高至96.3%,模型的检测速度达到109.2 帧/s,在PASCAL VOC 2007及PASCAL VOC 2012公共数据集上具有较高的检测精度. 与现有的YOLO系列模型相比,PDM-YOLO模型具有更好的综合检测性能,在地质复杂的煤矿巷道环境中能够准确地识别障碍物,模型具有较高的鲁棒性.
(2)通过在传统YOLOv5的C3模块中引入部分卷积,构建C3_P特征提取模块,使得模型的FLOPs减小了2.9×109,模型的mAP提高了2.6%,检测速度提高了16.2 帧/s.
(3)模型采用改进后的解耦头,与传统解耦头相比,FLOPs减少了19.8×109,检测精度由93.1%提高至96.1%. 采用解耦后的预测头,能够有效地提升模型的检测精度,加速模型的收敛.
(4)当采用优化后的Mosaic数据增强方法训练模型时,在没有增加额外计算成本的情况下,模型的mAP提高了0.1%. 优化后的Mosaic数据增强丰富了训练样本,有利于提高模型的识别精度.
本研究实现了无人驾驶电机车在复杂巷道环境下对障碍物的精准实时检测,为井下无人驾驶电机车的障碍物精准识别提供有效的方法. 由于井下巷道狭窄,摄像机获取的画面信息包含整个巷道断面,模型会识别出画面中包含的所有障碍物,造成电机车误将相邻轨道上运行的电机车以及轨道两侧处于安全区域内的工人视为危险障碍物,导致电机车错误预警而频繁启停的问题. 后期将深入研究如何建立有效的危险检测区域,避免识别处于安全行驶区域内的障碍物,对危险区域内识别出的障碍物进行距离估计,实现机车远距离鸣笛示警及近距离主动刹车的动作,进一步保障煤矿无人驾驶电机车的安全持续运营.
参考文献
煤矿智能化最新技术进展与问题探讨
[J].DOI:10.3969/j.issn.0253-2336.2022.1.mtkxjs202201001 [本文引用: 1]
New technological progress of coal mine intelligence and its problems
[J].DOI:10.3969/j.issn.0253-2336.2022.1.mtkxjs202201001 [本文引用: 1]
煤矿机器人技术新进展及新方向
[J].
New progress and direction of robot technology in coal mine
[J].
煤矿井下机车无人驾驶系统关键技术
[J].
Driverless technology of underground locomotive in coal mine
[J].
Real-time obstacle detection by stereo vision and ultrasonic data fusion
[J].DOI:10.1016/j.measurement.2022.110718 [本文引用: 1]
煤矿副井矿车装载物智能识别方法
[J].
Intelligent identification method for mine car load in coal mine auxiliary shaft
[J].
基于深度学习算法的矿用巡检机器人设备识别
[J].
Equipment recognition of mining patrol robot based on deep learning algorithm
[J].
改进的Faster RCNN煤矿井下行人检测算法
[J].
Improved faster RCNN approach for pedestrian detection in underground coal mine
[J].
Fast identification model for coal and gangue based on the improved tiny YOLO v3
[J].DOI:10.1007/s11554-022-01215-1 [本文引用: 1]
基于DIC和YOLO算法的复杂裂隙岩石破坏过程动态裂隙早期智能识别
[J].
Early and intelligent recognition of dynamic cracks during damage of complex fractured rock masses based on DIC and YOLO algorithms
[J].
基于混合域注意力 YOLOv4 的输送带纵向撕裂多维度检测
[J].
Multi-dimensional detection of longitudinal tearing of conveyor belt based on YOLOv4 of hybrid domain attention
[J].
基于改进YOLOv5的电子元件表面缺陷检测算法
[J].
Surface defect detection algorithm of electronic components based on improved YOLOv5
[J].
A feature fusion method to improve the driving obstacle detection under foggy weather
[J].DOI:10.1109/TTE.2021.3080690 [本文引用: 1]
Faster R-CNN: towards real-time object detection with region proposal networks
[J].DOI:10.1109/TPAMI.2016.2577031
基于改进YOLO及NMS的水果目标检测
[J].
Fruit target detection based on improved YOLO and NMS
[J].
Poly-YOLO: higher speed, more precise detection and instance segmentation for YOLOv3
[J].DOI:10.1007/s00521-021-05978-9 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}