|
|
|
| Image super-resolution reconstruction method driven by two-dimensional cross-fusion |
Xiaofen JIA1,2( ),Zixiang WANG3,Baiting ZHAO3,Zhenhuan LIANG2,Rui HU2 ),Zixiang WANG3,Baiting ZHAO3,Zhenhuan LIANG2,Rui HU2 |
1. State Key Laboratory of Digital Intelligent Technology for Unmanned Coal Mining, Anhui University of Science and Technology, Huainan 232001, China
2. Institute of Artificial Intelligence, Anhui University of Science and Technology, Huainan 232001, China
3. Institute of Electrical and Information Engineering, Anhui University of Science and Technology, Huainan 232001, China |
|
|
|
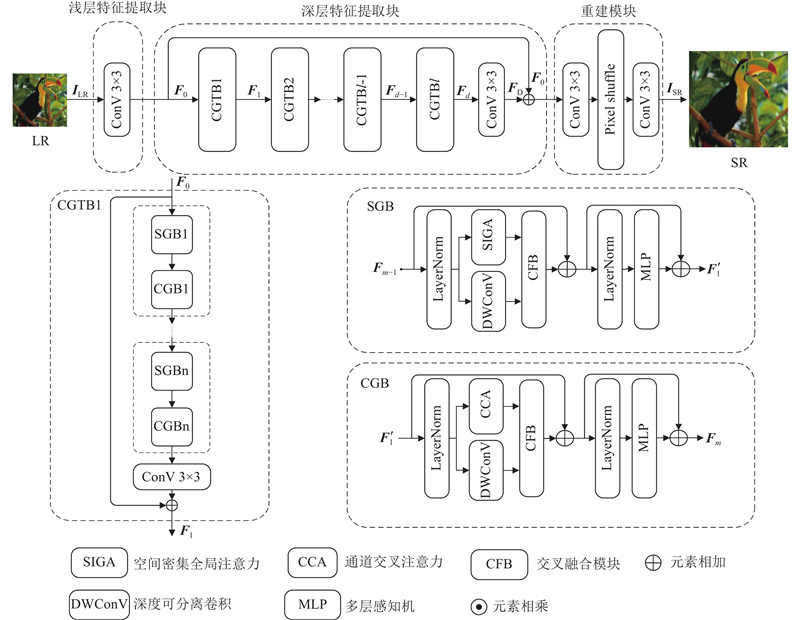
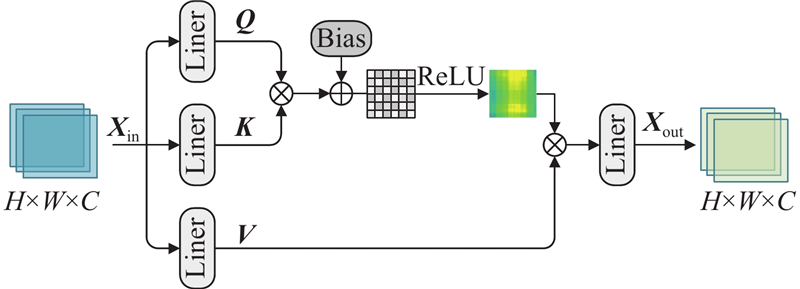
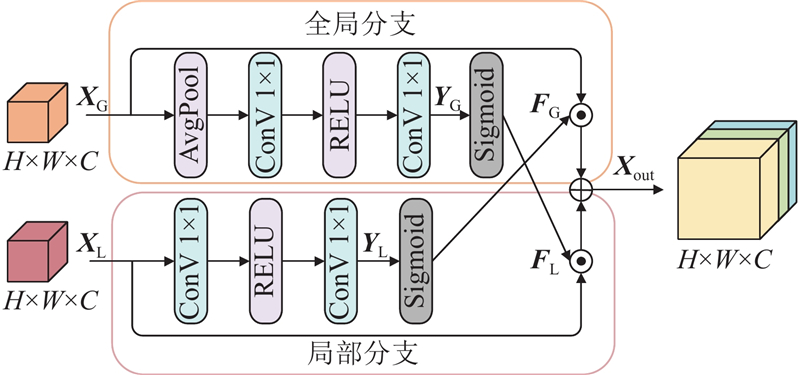
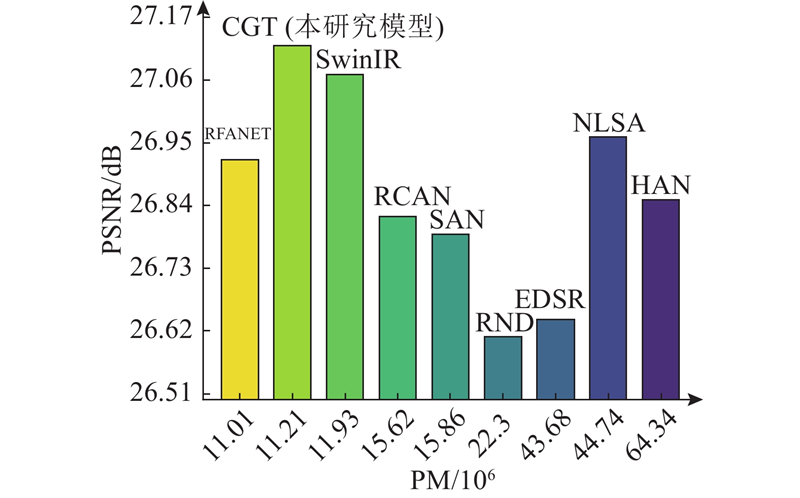
Abstract The existing image super-resolution models do not extract the underlying features in the deep semantic information of the image sufficiently, leading to the loss of details of the reconstructed image. Thus, an image super-resolution model driven by the cross-fusion of two dimensions of space and channel was proposed. The model used Transformer’s attention mechanism to build spatial intensive global attention (SIGA) in the spatial dimension to capture the location relationship of deep spatial regions. Channel cross attention (CCA) was built in the channel dimension to capture the feature dependence between channels. SIGA and CCA were respectively connected in parallel with deep separable convolutions to enhance the model’s ability to extract low-level features from high-level semantic information. Meanwhile, a cross fusion block (CFB) was developed by using a spatial compression strategy to ensure the efficient fusion of fine-grained features between the attention modules and deep separable convolutions. The cascaded two-dimensional cross-fusion modules facilitate the comprehensive intersection and aggregation of deep semantic information, thus realizing the restoration of delicate structures in the image. The experimental results showed that the proposed model achieved a PSNR improvement of 0.52 dB and 0.81 dB respectively compared with the latest method BiGLFE, in Urban100 and Manga109 with a scale factor of 4.
|
|
Received: 03 December 2024
Published: 25 November 2025
|
|
|
| Fund: 国家自然科学基金资助项目(52174141);安徽省自然科学基金资助项目(2108085ME158);合肥综合性国家科学中心大健康研究院职业医学与健康联合研究中心科研资助项目(OMH-2023-10);安徽理工大学引进人才科研启动基金(2022yjrc44). |
双维度交叉融合驱动的图像超分辨率重建方法
针对现有图像超分辨率模型对图像深层语义信息中的底层特征提取不充分,导致重建图像细节丢失的问题,提出从空间、通道双维度交叉融合驱动的图像超分辨率模型. 该模型利用Transformer的注意力机制,在空间维度搭建空间密集全局注意力(SIGA),捕捉深层空间区域位置关系;在通道维度搭建通道交叉注意力(CCA),捕获通道间的特征依赖性. SIGA与CCA分别并联深度可分离卷积,增强模型高层语义信息中底层特征的提取能力,并使用空间压缩策略开发交叉融合模块(CFB),保证注意力模块与卷积之间的细粒特征高效融合. 级联双维度融合模块,助力深层语义信息全面交汇与聚合,实现恢复图像中的细腻结构. 实验表明,在比例因子为4的Urban100和Manga109中,相较于最新方法BiGLFE,该模型在PSNR上分别提高了0.52、0.81 dB.
关键词:
图像超分,
Transformer,
CNN,
融合,
空间注意力,
通道注意力
|
|
| [1] |
DENG C, LUO X, WANG W Multiple frame splicing and degradation learning for hyperspectral imagery super-resolution[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2022, 15: 8389- 8401
doi: 10.1109/JSTARS.2022.3207777
|
|
|
| [2] |
MA J, LIU S, CHENG S, et al STSRNet: self-texture transfer super-resolution and refocusing network[J]. IEEE Transactions on Medical Imaging, 2022, 41 (2): 383- 393
doi: 10.1109/TMI.2021.3112923
|
|
|
| [3] |
ZHAO Z, ZHANG Y, LI C, et al Thermal UAV image super-resolution guided by multiple visible cues[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 5000314
|
|
|
| [4] |
DONG C, LOY C C, HE K, et al Image super-resolution using deep convolutional networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38 (2): 295- 307
doi: 10.1109/TPAMI.2015.2439281
|
|
|
| [5] |
KIM J, LEE J K, LEE K M. Accurate image super-resolution using very deep convolutional networks [C]// IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 1646–1654.
|
|
|
| [6] |
ZHANG Y, TIAN Y, KONG Y, et al. Residual dense network for image super-resolution [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 2472–2481.
|
|
|
| [7] |
HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 7132–7141.
|
|
|
| [8] |
LIM B, SON S, KIM H, et al. Enhanced deep residual networks for single image super-resolution [C]// IEEE Conference on Computer Vision and Pattern Recognition Workshops. Honolulu: IEEE, 2017: 1132–1140.
|
|
|
| [9] |
VASWANI A, SHAZEER N M, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. California: Curran Associates Inc., 2017: 6000–6010.
|
|
|
| [10] |
LIANG J, CAO J, SUN G, et al. SwinIR: image restoration using swin transformer [C]// IEEE/CVF International Conference on Computer Vision Workshops. Montreal: IEEE, 2021: 1833–1844.
|
|
|
| [11] |
CHU X, TIAN Z, WANG Y, et al. Twins: revisiting the design of spatial attention in vision transformers [J]. Advances in Neural Information Processing Systems. 2021, 34: 9355–9366.
|
|
|
| [12] |
YANG R, MA H, WU J, et al. ScalableViT: rethinking the context-oriented generalization of vision transformer [C]// Proceedings of Computer Vision – ECCV 2022. Cham: Springer, 2022: 480–496.
|
|
|
| [13] |
CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers [C]// Proceedings of Computer Vision – ECCV 2020. Cham: Springer, 2020: 213–229.
|
|
|
| [14] |
BEAL J, KIM E, TZENG E, et al. Toward Transformer-Based Object Detection [EB/OL]. (2020−12−17) [2025−09−15]. https://doi.org/10.48550/arXiv.2012.09958.
|
|
|
| [15] |
PENG Z, HUANG W, GU S, et al. Conformer: local features coupling global representations for visual recognition [C]// 2021 IEEE/CVF International Conference on Computer Vision (ICCV). Montreal: IEEE, 2021: 357−366.
|
|
|
| [16] |
WANG H, CHEN X, NI B, et al. Omni aggregation networks for lightweight image super-resolution [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 22378–22387.
|
|
|
| [17] |
HUI Z, GAO X, YANG Y, et al. Lightweight image super-resolution with information multi-distillation network [C]// 27th ACM International Conference on Multimedia. [S.l.]: ACM, 2019: 2024−2032.
|
|
|
| [18] |
JI J, ZHONG B, WU Q, et al A channel-wise multi-scale network for single image super-resolution[J]. IEEE Signal Processing Letters, 2024, 31: 805- 809
doi: 10.1109/LSP.2024.3372781
|
|
|
| [19] |
WANG X, JI H, SHI C, et al. Heterogeneous Graph Attention Network [C]// The World Wide Web Conference. San Francisco: [s.n.], 2019: 2022–2032.
|
|
|
| [20] |
LI X, DONG J, TANG J, et al. DLGSANet: lightweight dynamic local and global self-attention network for image super-resolution [C]// IEEE/CVF International Conference on Computer Vision. Paris: IEEE, 2023: 12746–12755.
|
|
|
| [21] |
LIN H, CHENG X, WU X, et al. CAT: cross attention in vision transformer [C]// IEEE International Conference on Multimedia and Expo. Taipei: IEEE, 2022: 1–6.
|
|
|
| [22] |
CHEN Z, ZHANG Y, GU J, et al. Recursive Generalization Transformer for Image Super-Resolution [EB/OL]. (2023−03−11) [2025−09−15]. https://doi.org/10.48550/arXiv.2303.06373.
|
|
|
| [23] |
KINGMA D, BA J. Adam: a method for stochastic optimization [EB/OL]. (2014−12−14) [2025−09−15]. https://doi.org/10.48550/arXiv.1412.6980.
|
|
|
| [24] |
AGUSTSSON E, TIMOFTE R. NTIRE 2017 challenge on single image super-resolution: dataset and study [C]// IEEE Conference on Computer Vision and Pattern Recognition Workshops. Honolulu: IEEE, 2017: 1122–1131.
|
|
|
| [25] |
BEVILACQUA M, ROUMY A, GUILLEMOT C, et al. Low-complexity single-image super-resolution based on nonnegative neighbor embedding [C]// Proceedings of British Machine Vision Conference. Surrey: British Machine Vision Association, 2012.
|
|
|
| [26] |
ZEYDE R, ELAD M, PROTTER M. On single image scale-up using sparse-representations [C]// Proceedings of International Conference on Curves and Surfaces. Avignon: Springer, 2010: 711–730.
|
|
|
| [27] |
MARTIN D, FOWLKES C, TAL D, et al. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics [C]// 8th IEEE International Conference on Computer Vision. Vancouver: IEEE, 2001: 416–423.
|
|
|
| [28] |
HUANG J B, SINGH A, AHUJA N. Single image super-resolution from transformed self-exemplars [C]// IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 5197–5206.
|
|
|
| [29] |
MATSUI Y, ITO K, ARAMAKI Y, et al Sketch-based manga retrieval using manga109 dataset[J]. Multimedia Tools and Applications, 2017, 76 (20): 21811- 21838
doi: 10.1007/s11042-016-4020-z
|
|
|
| [30] |
WANG Z, BOVIK A C, SHEIKH H R, et al Image quality assessment: from error visibility to structural similarity[J]. IEEE Transactions on Image Processing, 2004, 13 (4): 600- 612
doi: 10.1109/TIP.2003.819861
|
|
|
| [31] |
ZHANG Y, TIAN Y, KONG Y, et al. Residual dense network for image super-resolution [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 2472–2481.
|
|
|
| [32] |
LYN J, YAN S. Non-local Second-order attention network for single image super resolution [C]// Proceedings of International Cross-Domain Conference for Machine Learning and Knowledge Extraction. Dublin: Springer, 2020: 267–279.
|
|
|
| [33] |
LIU J, ZHANG W, TANG Y, et al. Residual feature aggregation network for image super-resolution [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 2356–2365.
|
|
|
| [34] |
MEI Y, FAN Y, ZHOU Y. Image super-resolution with non-local sparse attention [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 3516–3525.
|
|
|
| [35] |
ZHENG L, ZHU J, SHI J, et al Efficient mixed transformer for single image super-resolution[J]. Engineering Applications of Artificial Intelligence, 2024, 133: 108035
doi: 10.1016/j.engappai.2024.108035
|
|
|
| [36] |
HWANG K, YOON G, SONG J, et al Fusing bi-directional global–local features for single image super-resolution[J]. Engineering Applications of Artificial Intelligence, 2024, 127: 107336
doi: 10.1016/j.engappai.2023.107336
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|