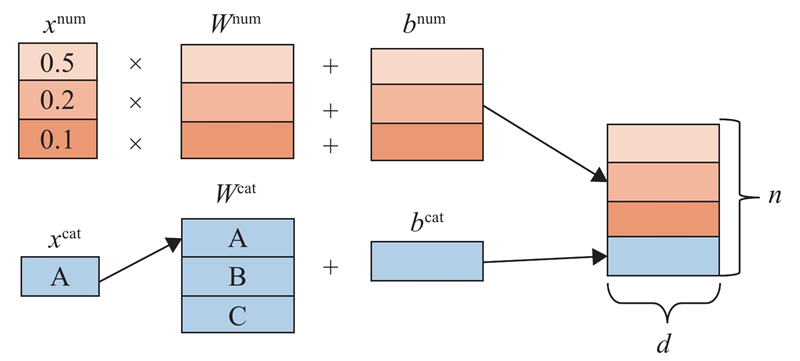
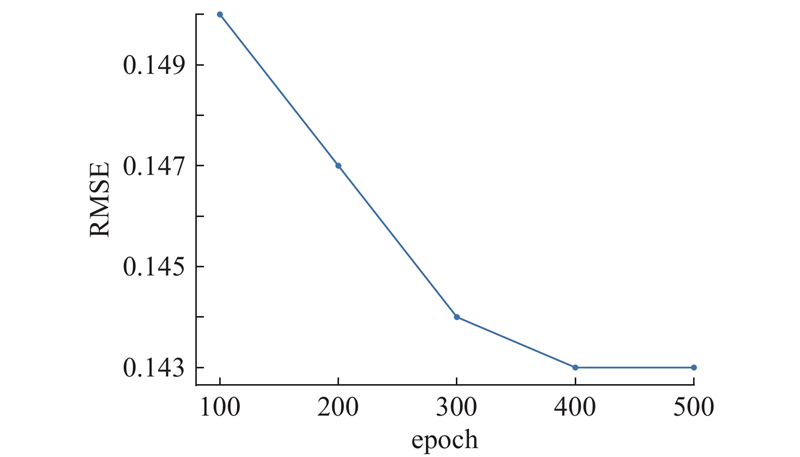
|
|
|
| Missing value imputation algorithm based on accelerated diffusion model |
Shengju WANG( ),Zan ZHANG*() ),Zan ZHANG*() |
| School of Electronics and Control Engineering, Chang’an University, Xi’an 710064, China |
|
|
|
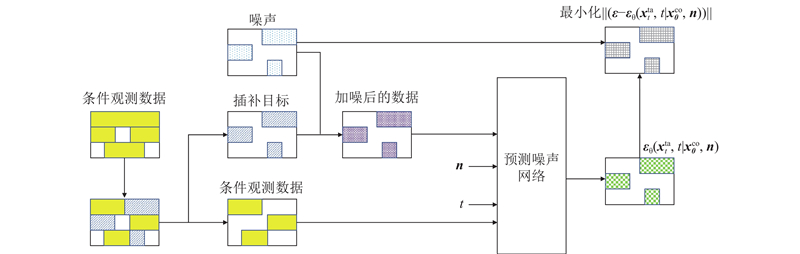
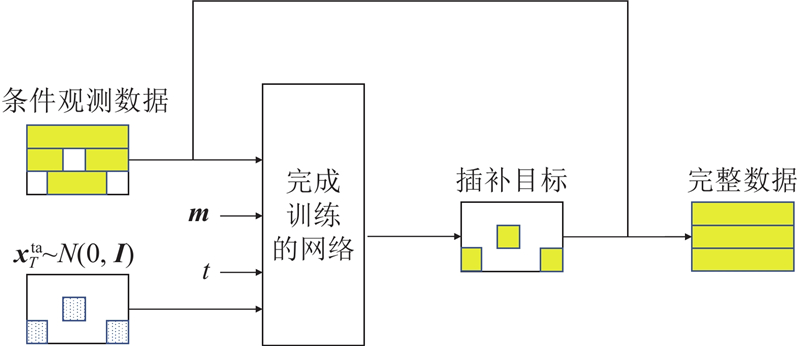
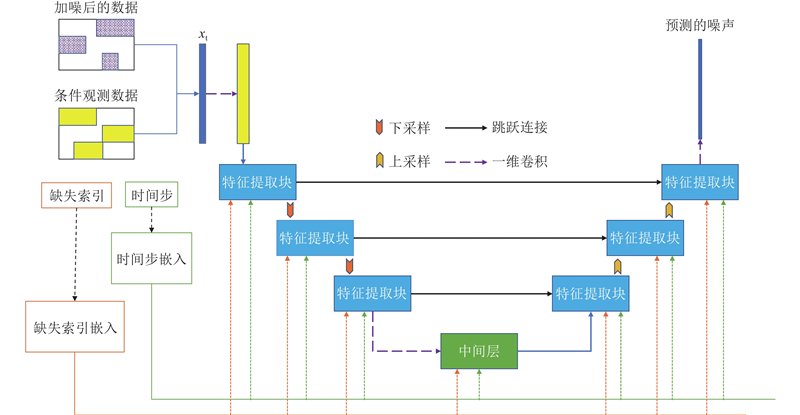
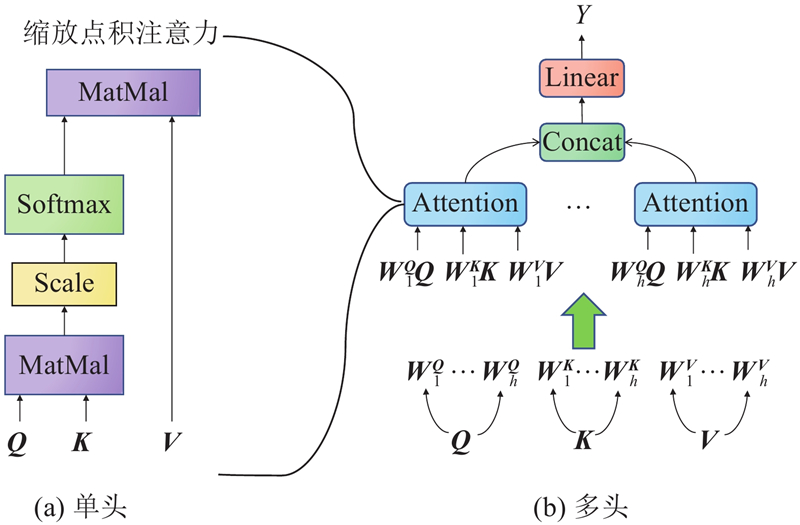
Abstract To address the adverse effects of missing data in tabular data on subsequent tasks, a method for imputation using diffusion models was proposed. An accelerated diffusion model-based imputation method (PNDM_Tab) was designed aiming at the problem that the original diffusion models being time-consuming during the generation process. The forward process of the diffusion model was realized through Gaussian noise addition, and the pseudo-numerical methods derived from diffusion models were employed to achieve acceleration of the reverse process. Using a network structure combining U-Net with attention mechanisms, significant features were extracted efficiently from the data to predict noise accurately. To provide supervised targets during the training phase, random masking of the training data generated new missing data. Comparative experiments were conducted in nine datasets, and the results showed that PNDM_Tab achieved the lowest root mean square error in six datasets compared to other imputation methods. Experimental results demonstrate that, compared to the original diffusion models, the use of pseudo-numerical methods in the reverse process can reduce the number of sampling steps while maintaining equivalent generative performance.
|
|
Received: 04 June 2024
Published: 25 July 2025
|
|
|
|
Corresponding Authors:
Zan ZHANG
E-mail: wangshengju@chd.edu.cn;z.zhang@chd.edu.cn
|
基于加速扩散模型的缺失值插补算法
为了解决表格数据中数据缺失对后续任务产生的不利影响,提出使用扩散模型进行缺失值插补的方法. 针对原始扩散模型在生成过程中耗时过长的问题,设计基于加速扩散模型的数据插补方法(PNDM_Tab). 扩散模型的前向过程通过高斯加噪方法实现,采用基于扩散模型的伪数值方法进行反向过程加速. 使用U-Net与注意力机制相结合的网络结构从数据中高效提取显著特征,实现噪声的准确预测. 为了使模型在训练阶段有监督目标,使用随机掩码处理训练数据以生成新的缺失数据. 在9个数据集中的插补方法对比实验结果表明:相较其他插补方法,PNDM_Tab在6个数据集中的均方根误差最低. 实验结果证明,相较于原始的扩散模型,反向过程使用扩散模型的伪数值方法能够在减少采样步数的同时保持生成性能不变.
关键词:
表格数据,
扩散模型,
数据插补,
注意力机制,
深度学习
|
|
| [1] |
VAN BUUREN S. Flexible imputation of missing data [M]. [S. l. ]: CRC Press, 2018.
|
|
|
| [2] |
STEKHOVEN D J, BÜHLMANN P MissForest: non-parametric missing value imputation for mixed-type data[J]. Bioinformatics, 2012, 28 (1): 112- 118
doi: 10.1093/bioinformatics/btr597
|
|
|
| [3] |
RESCHE-RIGON M, WHITE I R Multiple imputation by chained equations for systematically and sporadically missing multilevel data[J]. Statistical Methods in Medical Research, 2018, 27 (6): 1634- 1649
doi: 10.1177/0962280216666564
|
|
|
| [4] |
MAZUMDER R, HASTIE T, TIBSHIRANI R Spectral regularization algorithms for learning large incomplete matrices[J]. Journal of Machine Learning Research, 2010, 11: 2287- 2322
|
|
|
| [5] |
YOON J, JORDON J, SCHAAR M. GAIN: missing data imputation using generative adversarial nets [C]// Proceedings of the 35th International Conference on Machine Learning. Stockholm: ACM, 2018: 5689–5698.
|
|
|
| [6] |
MATTEI P A, FRELLSEN J. MIWAE: deep generative modelling and imputation of incomplete data sets [C]// Proceedings of the 36th International Conference on Machine Learning. Long Beach: ACM, 2019: 4413–4423.
|
|
|
| [7] |
ZHENG S, CHAROENPHAKDEE N. Diffusion models for missing value imputation in tabular data [EB/OL]. (2023–03–11)[2023–07–12]. https://arxiv.org/pdf/2210.17128.
|
|
|
| [8] |
LIU L, REN Y, LIN Z, et al. Pseudo numerical methods for diffusion models on manifolds [EB/OL]. (2022–10–31)[2023–08–19]. https://arxiv.org/pdf/2202.09778.
|
|
|
| [9] |
MCKNIGHT P E, MCKNIGHT K M, SIDANI S, et al. Missing data: a gentle introduction [M]. [S. l. ]: Guilford Press, 2007.
|
|
|
| [10] |
MALARVIZHI R, THANAMANI A S K-nearest neighbor in missing data imputation[J]. International Journal of Engineering Research and Development, 2012, 5 (1): 5- 7
|
|
|
| [11] |
庞新生 缺失数据插补处理方法的比较研究[J]. 统计与决策, 2012, 28 (24): 18- 22
PANG Xinsheng A comparative study on missing data interpolation methods[J]. Statistics and Decision, 2012, 28 (24): 18- 22
|
|
|
| [12] |
HO J, JAIN A, ABBEEL P. Denoising diffusion probabilistic models [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. [S. l. ]: Curran Associates Inc. , 2020: 6840–6851.
|
|
|
| [13] |
SONG J M, MENG C L, ERMON S. Denoising diffusion implicit models [EB/OL]. (2022–10–05)[2023–08–23]. https://arxiv.org/pdf/2010.02502.
|
|
|
| [14] |
SONG Y, SOHL-DICKSTEIN J, KINGMA D P, et al. Score-based generative modeling through stochastic differential equations [EB/OL]. (2021–02–10)[2023–08–25]. https://arxiv.org/pdf/2011.13456.
|
|
|
| [15] |
MAOUTSA D, REICH S, OPPER M Interacting particle solutions of Fokker–Planck equations through gradient–log–density estimation[J]. Entropy, 2020, 22 (8): 802
doi: 10.3390/e22080802
|
|
|
| [16] |
SALIMANS T, HO J. Progressive distillation for fast sampling of diffusion models [EB/OL]. (2022–06–07)[2024–01–23]. https://arxiv.org/pdf/2202.00512.
|
|
|
| [17] |
TASHIRO Y, SONG J, SONG Y, et al. CSDI: conditional score-based diffusion models for probabilistic time series imputation [C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. [S.l.]: Curran Associates Inc. , 2021: 24804–24816.
|
|
|
| [18] |
NICHOL A. Q, DHARIWAL P. Improved denoising diffusion probabilistic models [C]// Proceedings of the 38th International Conference on Machine Learning. Vienna: ACM, 2021: 8162–8171.
|
|
|
| [19] |
RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation [C]// Medical Image Computing and Computer-Assisted Intervention. [S. l. ]: Springer, 2015: 234–241.
|
|
|
| [20] |
DHARIWAL P, NICHOL A. Diffusion models beat gans on image synthesis [C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. [S. l.]: Curran Associates Inc. , 2021: 8780–8794.
|
|
|
| [21] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31th International Conference on Neural Information Processing Systems. [S. l.]: Curran Associates Inc. , 2017: 6000–6010.
|
|
|
| [22] |
GARCÍA-LAENCINA P J, SANCHO-GÓMEZ J L, FIGUEIRAS-VIDAL A R Pattern classification with missing data: a review[J]. Neural Computing and Applications, 2010, 19 (2): 263- 282
doi: 10.1007/s00521-009-0295-6
|
|
|
| [23] |
GORISHNIY Y, RUBACHEV I, KHRULKOV V, et al. Revisiting deep learning models for tabular data [C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. [S. l. ]: Curran Associates Inc., 2021: 18932–18943.
|
|
|
| [24] |
JARRETT D, CEBERE B C, LIU T, et al. Hyperimpute: Generalized iterative imputation with automatic model selection [C]// Proceedings of the 39th International Conference on Machine Learning. Baltimore: ACM, 2022: 9916–9937.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|