|
|
|
| Image captioning based on cross-modal cascaded diffusion model |
Qiaohong CHEN( ),Menghao GUO,Xian FANG*(),Qi SUN ),Menghao GUO,Xian FANG*(),Qi SUN |
| School of Computer Science and Technology, Zhejiang Sci-Tech University, Hangzhou 310018, China |
|
|
|
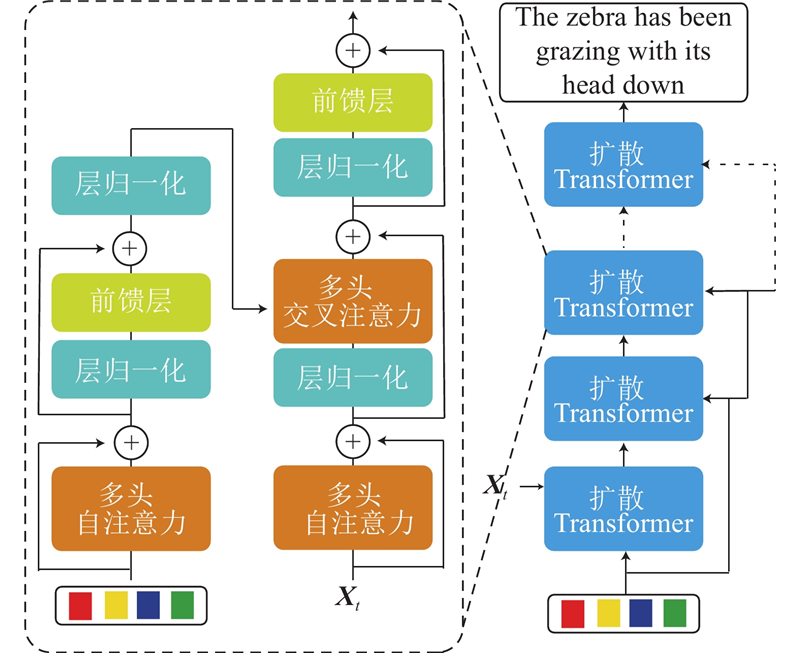
Abstract Current text diffusion model methods are ineffective in controlling the diffusion process based on semantic conditions, and the convergence of the diffusion model training process is challenging. A non-autoregressive image captioning method was proposed based on a cross-modal cascaded diffusion model. A cross-modal semantic alignment module was introduced to align the semantic relationships between visual and text modalities, with the aligned semantic feature vectors serving as the semantic condition for the subsequent diffusion model. By designing a cascaded diffusion model, rich semantic information was gradually introduced to ensure that the generated image description closely aligns with the overall context. A noise schedule was enhanced during the text diffusion process to increase the model’s sensitivity to text information, and the model was fully trained to enhance the overall performance of the model. Experimental results show that the proposed method generates more accurate and rich text descriptions than traditional image captioning methods. The proposed method significantly outperforms other non-autoregressive text generation methods in various evaluation metrics, which showcases the effectiveness and potential of using diffusion models in the task of image captioning.
|
|
Received: 18 January 2024
Published: 25 April 2025
|
|
|
| Fund: 浙江省自然科学基金资助项目(LQ23F020021). |
|
Corresponding Authors:
Xian FANG
E-mail: chen_lisa@zstu.edu.cn;xianfang@zstu.edu.cn
|
基于跨模态级联扩散模型的图像描述方法
现有文本扩散模型方法无法有效根据语义条件控制扩散过程,扩散模型训练过程的收敛较为困难,为此提出基于跨模态级联扩散模型的非自回归图像描述方法. 引入跨模态语义对齐模块用于对齐视觉模态和文本模态之间的语义关系,将对齐后的语义特征向量作为后续扩散模型的语义条件. 通过设计级联式的扩散模型逐步引入丰富的语义信息,确保生成的图像描述贴近整体语境. 增强文本扩散过程中的噪声计划以提升模型对文本信息的敏感性,充分训练模型以增强模型的整体性能. 实验结果表明,所提方法能够生成比传统图像描述生成方法更准确和丰富的文本描述. 所提方法在各项评价指标上均明显优于其他非自回归文本生成方法,展现了在图像描述任务中使用扩散模型的有效性和潜力.
关键词:
深度学习,
图像描述,
扩散模型,
多模态编码器,
级联结构
|
|
| [1] |
VINYALS O, TOSHEV A, BENGIO S, et al. Show and tell: a neural image caption generator [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 3156–3164.
|
|
|
| [2] |
XU K, BA J, KIROS R, et al. Show, attend and tell: neural image caption generation with visual attention [C]// Proceedings of the 32nd International Conference on Machine Learning . Lille: [s. n.], 2015: 2048–2057.
|
|
|
| [3] |
陈巧红, 裴皓磊, 孙麒 基于视觉关系推理与上下文门控机制的图像描述[J]. 浙江大学学报: 工学版, 2022, 56 (3): 542- 549
CHEN Qiaohong, PEI Haolei, SUN Qi Image caption based on relational reasoning and context gate mechanism[J]. Journal of Zhejiang University: Engineering Science, 2022, 56 (3): 542- 549
|
|
|
| [4] |
王鑫, 宋永红, 张元林 基于显著性特征提取的图像描述算法[J]. 自动化学报, 2022, 48 (3): 735- 746
WANG Xin, SONG Yonghong, ZHANG Yuanlin Salient feature extraction mechanism for image captioning[J]. Acta Automatica Sinica, 2022, 48 (3): 735- 746
|
|
|
| [5] |
卓亚琦, 魏家辉, 李志欣 基于双注意模型的图像描述生成方法研究[J]. 电子学报, 2022, 50 (5): 1123- 1130
ZHUO Yaqi, WEI Jiahui, LI Zhixin Research on image captioning based on double attention model[J]. Acta Electronica Sinica, 2022, 50 (5): 1123- 1130
doi: 10.12263/DZXB.20210696
|
|
|
| [6] |
SUTSKEVER I, VINYALS O, LE Q V. Sequence to sequence learning with neural networks [C]// Proceedings of the 28th International Conference on Neural Information Processing Systems . Montreal: ACM, 2014: 3104–3112.
|
|
|
| [7] |
MAO J, XU W, YANG Y, et al. Explain images with multimodal recurrent neural networks [EB/OL]. (2014–10–04)[ 2023–10–20]. https://arxiv.org/pdf/1410.1090.
|
|
|
| [8] |
ANDERSON P, HE X, BUEHLER C, et al. Bottom-up and top-down attention for image captioning and visual question answering [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 6077–6086.
|
|
|
| [9] |
刘茂福, 施琦, 聂礼强 基于视觉关联与上下文双注意力的图像描述生成方法[J]. 软件学报, 2022, 33 (9): 3210- 3222
LIU Maofu, SHI Qi, NIE Liqiang Image captioning based on visual relevance and context dual attention[J]. Journal of Software, 2022, 33 (9): 3210- 3222
|
|
|
| [10] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems . [S. l.]: Curran Associates Inc. , 2017: 6000–6010.
|
|
|
| [11] |
DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [EB/OL]. (2019–05–24)[2023–10–20]. https://arxiv.org/pdf/1810.04805.
|
|
|
| [12] |
HUANG L, WANG W, CHEN J, et al. Attention on attention for image captioning [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 4634–4643.
|
|
|
| [13] |
PAN Y, YAO T, LI Y, et al. X-linear attention networks for image captioning [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 10971–10980.
|
|
|
| [14] |
CORNIA M, STEFANINI M, BARALDI L, et al. Meshed-memory transformer for image captioning [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 10578–10587.
|
|
|
| [15] |
WANG Y, XU J, SUN Y End-to-end transformer based model for image captioning[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2022, 36 (3): 2585- 2594
doi: 10.1609/aaai.v36i3.20160
|
|
|
| [16] |
GAO J, MENG X, WANG S, et al. Masked non-autoregressive image captioning [EB/OL]. (2019–06–03) [2023–10–20]. https://arxiv.org/pdf/1906.00717.
|
|
|
| [17] |
GUO L, LIU J, ZHU X, et al. Non-autoregressive image captioning with counterfactuals-critical multi-agent learning [C]// Proceedings of the 29th International Joint Conference on Artificial Intelligence . Yokohama: ACM, 2021: 767–773.
|
|
|
| [18] |
HO J, JAIN A, ABBEEL P. Denoising diffusion probabilistic models [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems . Vancouver: ACM, 2020: 6840–6851.
|
|
|
| [19] |
SONG J, MENG C, ERMON S. Denoising diffusion implicit models [C]// International Conference on Learning Representations . [S.l.]: ICLR, 2020: 1–20.
|
|
|
| [20] |
ZHOU Y, ZHANG Y, HU Z, et al. Semi-autoregressive transformer for image captioning [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops . Montreal: IEEE, 2021: 3139–3143.
|
|
|
| [21] |
CHEN T, ZHANG R, HINTON G. Analog bits: generating discrete data using diffusion models with self-conditioning [C]// International Conference on Learning Representations . [S.l.]: ICLR, 2023: 1–23.
|
|
|
| [22] |
HE Y, CAI Z, GAN X, et al. DiffCap: exploring continuous diffusion on image captioning [EB/OL]. (2023–05–20) [2023–10–20]. https://arxiv.org/pdf/2305.12144.
|
|
|
| [23] |
HO J, SAHARIA C, CHAN W, et al Cascaded diffusion models for high fidelity image generation[J]. Journal of Machine Learning Research, 2022, 23 (1): 2249- 2281
|
|
|
| [24] |
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [C]// Computer Vision – ECCV 2014 . [S.l.]: Springer, 2014: 740–755.
|
|
|
| [25] |
PLUMMER B A, WANG L, CERVANTES C M, et al. Flickr30k entities: collecting region-to-phrase correspondences for richer image-to-sentence models [C]// Proceedings of the IEEE International Conference on Computer Vision . Santiago: IEEE, 2015: 2641–2649.
|
|
|
| [26] |
KARPATHY A, LI F F. Deep visual-semantic alignments for generating image descriptions [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 3128–3137.
|
|
|
| [27] |
PAPINENI K, ROUKOS S, WARD T, et al. BLEU: a method for automatic evaluation of machine translation [C]// Proceedings of the 40th Annual Meeting on Association for Computational Linguistics . Philadelphia: ACL, 2002: 311–318.
|
|
|
| [28] |
DENKOWSKI M, LAVIE A. Meteor 1.3: automatic metric for reliable optimization and evaluation of machine translation systems [C]// Proceedings of the Sixth Workshop on Statistical Machine Translation . Edinburgh: ACL, 2011: 85–91.
|
|
|
| [29] |
LIN CY. ROUGE: a package for automatic evaluation of summaries [C]// Text Summarization Branches Out . Barcelona: ACL, 2004: 74–81.
|
|
|
| [30] |
VEDANTAM R, ZITNICK C L, PARIKH D. CIDEr: consensus-based image description evaluation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 4566–4575.
|
|
|
| [31] |
LI J, LI D, XIONG C, et al. BLIP: bootstrapping language-image pre-training for unified vision-language understanding and generation [C]// Proceedings of the International Conference on Machine Learning . [S. l.]: PMLR, 2022: 12888–12900.
|
|
|
| [32] |
RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]// Proceedings of the International Conference on Machine Learning . [S. l.]: PMLR, 2021: 8748–8763.
|
|
|
| [33] |
KINGMA D P, BA J. ADAM: a method for stochastic optimization [EB/OL]. (2017–03–30)[2023–10–20]. https://arxiv.org/pdf/1412.6980.
|
|
|
| [34] |
LU J, YANG J, BATRA D, et al. Neural baby talk [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 7219–7228.
|
|
|
| [35] |
RENNIE S J, MARCHERET E, MROUEH Y, et al. Self-critical sequence training for image captioning [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 1179–1195.
|
|
|
| [36] |
JIANG W, MA L, JIANG Y G, et al. Recurrent fusion network for image captioning [C]// Computer Vision – ECCV 2018 . [S.l.]: Springer, 2018: 510–526.
|
|
|
| [37] |
YAO T, PAN Y, LI Y, et al. Exploring visual relationship for image captioning [C]// Computer Vision – ECCV 2018 . [S.l.]: Springer, 2018: 711–727.
|
|
|
| [38] |
HERDADE S, KAPPELER A, BOAKYE K, et al. Image captioning: transforming objects into words [EB/OL]. (2020–01–11)[2023–10–20]. https://arxiv.org/pdf/1906.05963.
|
|
|
| [39] |
ZHANG X, SUN X, LUO Y, et al. RSTNet: captioning with adaptive attention on visual and non-visual words [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 15465–15474.
|
|
|
| [40] |
WANG N, XIE J, WU J, et al Controllable image captioning via prompting[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2023, 37 (2): 2617- 2625
doi: 10.1609/aaai.v37i2.25360
|
|
|
| [41] |
YU H, LIU Y, QI B, et al. End-to-end non-autoregressive image captioning [C]// Proceedings of the ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing . Rhodes Island: IEEE, 2023: 1–5.
|
|
|
| [42] |
LU J, XIONG C, PARIKH D, et al. Knowing when to look: adaptive attention via a visual sentinel for image captioning [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 375–383.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|