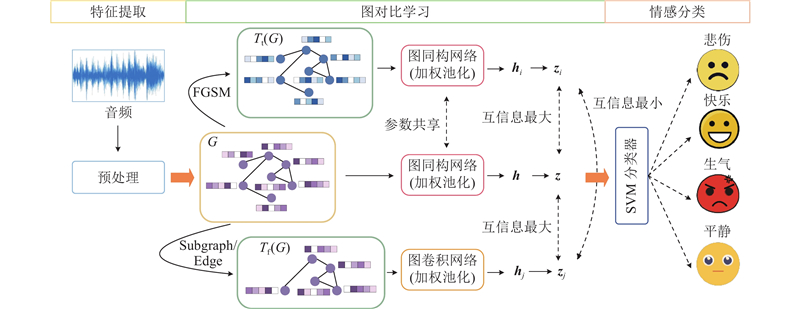
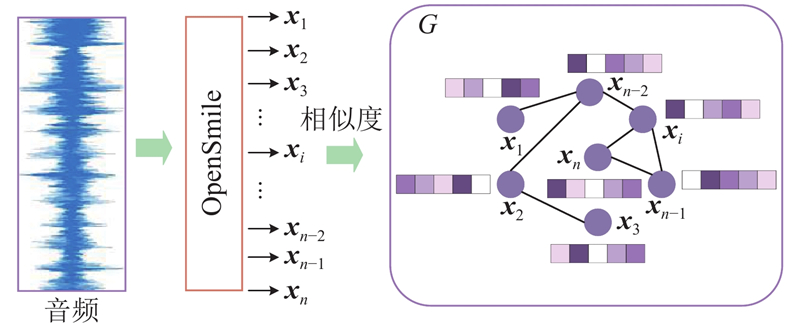
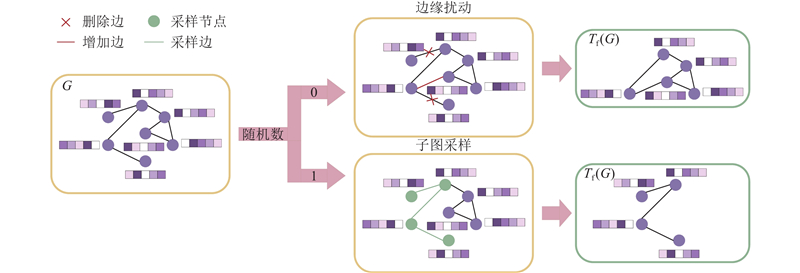
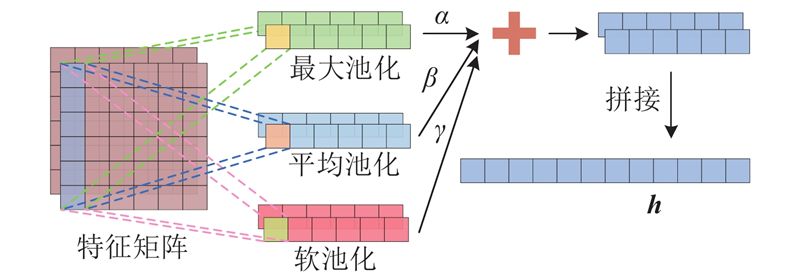
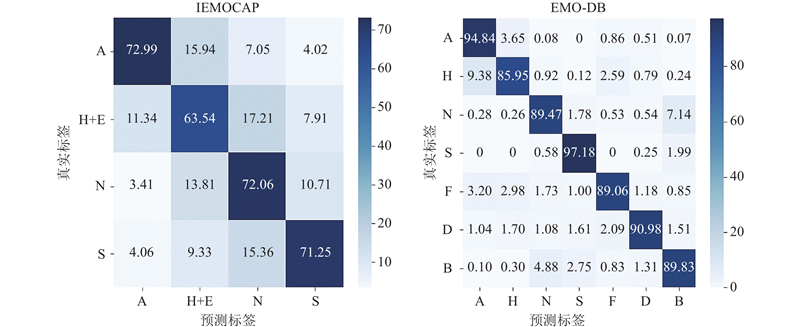
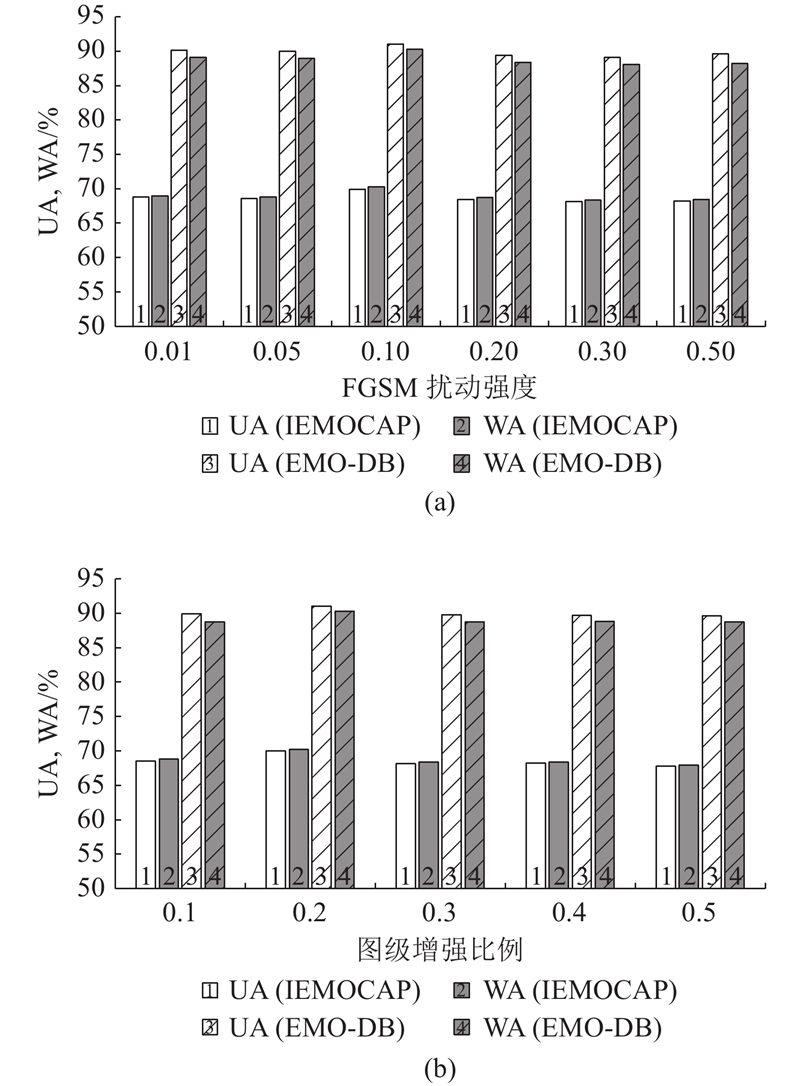
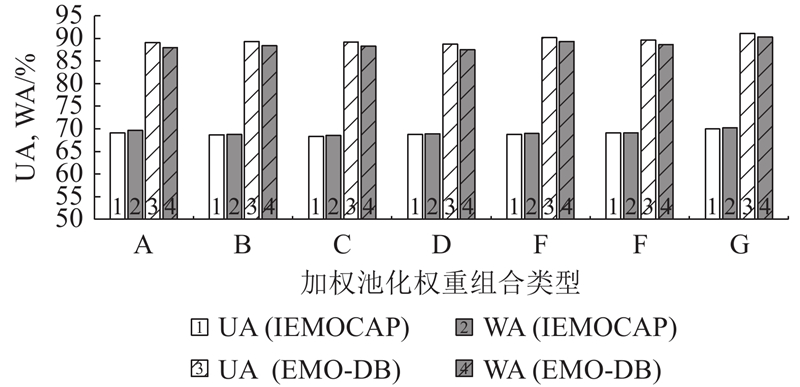
| 计算机技术 |
|

|
|
|
| 基于无监督图对比学习的语音情感识别 |
张雪梅( ),孙颖*(),张雪英 ),孙颖*(),张雪英 |
| 太原理工大学 电子信息工程学院,山西 太原 030024 |
|
| Speech emotion recognition with unsupervised graph contrastive learning |
| Xuemei ZHANG(),Ying SUN*(),Xueying ZHANG |
| College of Electronic Information Engineering, Taiyuan University of Technology, Taiyuan 030024, China |
| 1 |
HU Y, TANG Y, HUANG H, et al. A graph isomorphism network with weighted multiple aggregators for speech emotion recognition [C]// Interspeech 2022. Incheon: ISCA, 2022: 4705−4709.
|
| 2 |
孙颖, 胡艳香, 张雪英, 等 面向情感语音识别的情感维度PAD预测[J]. 浙江大学学报: 工学版, 2019, 53 (10): 2041- 2048
SUN Ying, HU Yanxiang, ZHANG Xueying, et al Prediction of emotional dimensions PAD for emotional speech recognition[J]. Journal of Zhejiang University: Engineering Science, 2019, 53 (10): 2041- 2048
|
| 3 |
孙志, 王冠 自监督对比学习的CNN-GRU语音情感识别算法[J]. 西安电子科技大学学报, 2024, 51 (6): 182- 193
SUN Zhi, WANG Guan CNN-GRU speech emotion recognition algorithm for self-supervised comparative learning[J]. Journal of Xidian University, 2024, 51 (6): 182- 193
doi: 10.19665/j.issn1001-2400.20241109
|
| 4 |
PENTARI A, KAFENTZIS G, TSIKNAKIS M Speech emotion recognition via graph-based representations[J]. Scientific Reports, 2024, 14: 4484
doi: 10.1038/s41598-024-52989-2
|
| 5 |
ABDELHAMID A A, EL-KENAWY E M, ALOTAIBI B, et al Robust speech emotion recognition using CNN+LSTM based on stochastic fractal search optimization algorithm[J]. IEEE Access, 2022, 10: 49265- 49284
doi: 10.1109/ACCESS.2022.3172954
|
| 6 |
ZHU Z, DAI W, HU Y, et al Speech emotion recognition model based on Bi-GRU and focal loss[J]. Pattern Recognition Letters, 2020, 140: 358- 365
doi: 10.1016/j.patrec.2020.11.009
|
| 7 |
LI M, YANG B, LEVY J, et al. Contrastive unsupervised learning for speech emotion recognition [C]// 2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Toronto: IEEE, 2021: 6329−6333.
|
| 8 |
GERCZUK M, AMIRIPARIAN S, OTTL S, et al EmoNet: a transfer learning framework for multi-corpus speech emotion recognition[J]. IEEE Transactions on Affective Computing, 2023, 14 (2): 1472- 1487
doi: 10.1109/TAFFC.2021.3135152
|
| 9 |
XU X, DENG J, COUTINHO E, et al Connecting subspace learning and extreme learning machine in speech emotion recognition[J]. IEEE Transactions on Multimedia, 2019, 21 (3): 795- 808
doi: 10.1109/TMM.2018.2865834
|
| 10 |
PENTARI A, KAFENTZIS G, TSIKNAKIS M. Investigating graph-based features for speech emotion recognition [C]// IEEE-EMBS International Conference on Biomedical and Health Informatics. Ioannina: IEEE, 2022: 1–5.
|
| 11 |
MELO D F P, FADIGAS I S, PEREIRA H B B Graph-based feature extraction: a new proposal to study the classification of music signals outside the time-frequency domain[J]. PLoS One, 2020, 15 (11): e0240915
doi: 10.1371/journal.pone.0240915
|
| 12 |
SHIRIAN A, GUHA T. Compact graph architecture for speech emotion recognition [C]// 2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Toronto: IEEE, 2021: 6284–6288.
|
| 13 |
KIM J, KIM J. Representation learning with graph neural networks for speech emotion recognition [EB/OL]. (2022–01–26) [2025–06–10]. https://arxiv.org/abs/2208.09830.
|
| 14 |
GHAYEKHLOO M, NICKABADI A Supervised contrastive learning for graph representation enhancement[J]. Neurocomputing, 2024, 588: 127710
doi: 10.1016/j.neucom.2024.127710
|
| 15 |
YOU Y N, CHEN T L, SUI Y D, et al. Graph contrastive learning with augmentations [C]// 34th International Conference on Neural Information Processing Systems. Vancouver: NeurIPS, 2020: 5812−5823.
|
| 16 |
SHIRIAN A, SOMANDEPALLI K, GUHA T Self-supervised graphs for audio representation learning with limited labeled data[J]. IEEE Journal of Selected Topics in Signal Processing, 2022, 16 (6): 1391- 1401
doi: 10.1109/JSTSP.2022.3190083
|
| 17 |
ESKIMEZ S E, DUAN Z, HEINZELMAN W. Unsupervised learning approach to feature analysis for automatic speech emotion recognition [C]// IEEE International Conference on Acoustics, Speech and Signal Processing. Calgary: IEEE, 2018: 5099–5103.
|
| 18 |
KANG H, XU Y, JIN G, et al FCAN: speech emotion recognition network based on focused contrastive learning[J]. Biomedical Signal Processing and Control, 2024, 96: 106545
doi: 10.1016/j.bspc.2024.106545
|
| 19 |
SONG X, HUANG L, XUE H, et al. Supervised prototypical contrastive learning for emotion recognition in conversation [C]// Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Abu Dhabi, Stroudsburg: ACL, 2022: 5197−5206.
|
| 20 |
LI Y, WANG Y, YANG X, et al Speech emotion recognition based on Graph-LSTM neural network[J]. EURASIP Journal on Audio, Speech, and Music Processing, 2023, (1): 40
doi: 10.1186/s13636-023-00303-9
|
| 21 |
XU Y, WANG J, GUANG M, et al Graph contrastive learning with Min-max mutual information[J]. Information Sciences, 2024, 665: 120378
doi: 10.1016/j.ins.2024.120378
|
| 22 |
WONG E, RICE L, KOLTER J. Fast is better than free: revisiting adversarial training [C]// 8th International Conference on Learning Representations. [S. l. ]: ICLR, 2020.
|
| 23 |
XU K, HU W H, LESKOVEC J, et al. How powerful are graph neural networks? [C]// 7th International Conference on Learning Representations. New Orleans: ICLR, 2019.
|
| 24 |
KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks [C]// 5th International Conference on Learning Representation. Toulon: ICLR, 2017.
|
| 25 |
BUSSO C, BULUT M, LEE C C, et al IEMOCAP: interactive emotional dyadic motion capture database[J]. Language Resources and Evaluation, 2008, 42 (4): 335- 359
doi: 10.1007/s10579-008-9076-6
|
| 26 |
BURKHARDT F, PAESCHKE A, ROLFES M, et al. A database of German emotional speech [C]// Interspeech 2005. Lisbon: ISCA, 2005: 1517−1520.
|
| 27 |
SCHULLER B, STEIDL S, BATLINER A, et al. The INTERSPEECH 2010 paralinguistic challenge [C]// Interspeech 2010. Chiba: ISCA, 2010: 2794−2797.
|
| 28 |
PANDEY S K, SHEKHAWAT H S, PRASANNA S R M Attention gated tensor neural network architectures for speech emotion recognition[J]. Biomedical Signal Processing and Control, 2022, 71: 103173
doi: 10.1016/j.bspc.2021.103173
|
| 29 |
LIU J, WANG H. Graph isomorphism network for speech emotion recognition [C]// Interspeech 2021. Brno: ISCA, 2021: 3405−3409.
|
| 30 |
ULGEN I R, DU Z, BUSSO C, et al. Revealing emotional clusters in speaker embeddings: a contrastive learning strategy for speech emotion recognition [C]// 2024 IEEE International Conference on Acoustics, Speech and Signal Processing. Seoul: IEEE, 2024: 12081–12085.
|
| 31 |
GUO L, DING S, WANG L, et al DSTCNet: deep spectro-temporal-channel attention network for speech emotion recognition[J]. IEEE Transactions on Neural Networks and Learning Systems, 2025, 36 (1): 188- 197
doi: 10.1109/TNNLS.2023.3304516
|
| 32 |
GUO L, LI J, DING S, et al APIN: amplitude- and phase-aware interaction network for speech emotion recognition[J]. Speech Communication, 2025, 169: 103201
doi: 10.1016/j.specom.2025.103201
|
| 33 |
CHEN Z, LI J, LIU H, et al Learning multi-scale features for speech emotion recognition with connection attention mechanism[J]. Expert Systems with Applications, 2023, 214: 118943
doi: 10.1016/j.eswa.2022.118943
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|