[1]
HU Y, TANG Y, HUANG H, et al. A graph isomorphism network with weighted multiple aggregators for speech emotion recognition [C]// Interspeech 2022. Incheon: ISCA, 2022: 4705−4709.
[本文引用: 1]
[2]
孙颖, 胡艳香, 张雪英, 等 面向情感语音识别的情感维度PAD预测
[J]. 浙江大学学报: 工学版 , 2019 , 53 (10 ): 2041 - 2048
[本文引用: 1]
SUN Ying, HU Yanxiang, ZHANG Xueying, et al Prediction of emotional dimensions PAD for emotional speech recognition
[J]. Journal of Zhejiang University: Engineering Science , 2019 , 53 (10 ): 2041 - 2048
[本文引用: 1]
[4]
PENTARI A, KAFENTZIS G, TSIKNAKIS M Speech emotion recognition via graph-based representations
[J]. Scientific Reports , 2024 , 14 : 4484
DOI:10.1038/s41598-024-52989-2
[本文引用: 5]
[5]
ABDELHAMID A A, EL-KENAWY E M, ALOTAIBI B, et al Robust speech emotion recognition using CNN+LSTM based on stochastic fractal search optimization algorithm
[J]. IEEE Access , 2022 , 10 : 49265 - 49284
DOI:10.1109/ACCESS.2022.3172954
[本文引用: 1]
[6]
ZHU Z, DAI W, HU Y, et al Speech emotion recognition model based on Bi-GRU and focal loss
[J]. Pattern Recognition Letters , 2020 , 140 : 358 - 365
DOI:10.1016/j.patrec.2020.11.009
[本文引用: 1]
[7]
LI M, YANG B, LEVY J, et al. Contrastive unsupervised learning for speech emotion recognition [C]// 2021 IEEE International Conference on Acoustics, Speech and Signal Processing . Toronto: IEEE, 2021: 6329−6333.
[本文引用: 4]
[8]
GERCZUK M, AMIRIPARIAN S, OTTL S, et al EmoNet: a transfer learning framework for multi-corpus speech emotion recognition
[J]. IEEE Transactions on Affective Computing , 2023 , 14 (2 ): 1472 - 1487
DOI:10.1109/TAFFC.2021.3135152
[本文引用: 2]
[9]
XU X, DENG J, COUTINHO E, et al Connecting subspace learning and extreme learning machine in speech emotion recognition
[J]. IEEE Transactions on Multimedia , 2019 , 21 (3 ): 795 - 808
DOI:10.1109/TMM.2018.2865834
[本文引用: 2]
[10]
PENTARI A, KAFENTZIS G, TSIKNAKIS M. Investigating graph-based features for speech emotion recognition [C]// IEEE-EMBS International Conference on Biomedical and Health Informatics . Ioannina: IEEE, 2022: 1–5.
[本文引用: 1]
[11]
MELO D F P, FADIGAS I S, PEREIRA H B B Graph-based feature extraction: a new proposal to study the classification of music signals outside the time-frequency domain
[J]. PLoS One , 2020 , 15 (11 ): e0240915
DOI:10.1371/journal.pone.0240915
[12]
SHIRIAN A, GUHA T. Compact graph architecture for speech emotion recognition [C]// 2021 IEEE International Conference on Acoustics, Speech and Signal Processing . Toronto: IEEE, 2021: 6284–6288.
[本文引用: 3]
[13]
KIM J, KIM J. Representation learning with graph neural networks for speech emotion recognition [EB/OL]. (2022–01–26) [2025–06–10]. https://arxiv.org/abs/2208.09830.
[本文引用: 3]
[14]
GHAYEKHLOO M, NICKABADI A Supervised contrastive learning for graph representation enhancement
[J]. Neurocomputing , 2024 , 588 : 127710
DOI:10.1016/j.neucom.2024.127710
[15]
YOU Y N, CHEN T L, SUI Y D, et al. Graph contrastive learning with augmentations [C]// 34th International Conference on Neural Information Processing Systems . Vancouver: NeurIPS, 2020: 5812−5823.
[本文引用: 3]
[16]
SHIRIAN A, SOMANDEPALLI K, GUHA T Self-supervised graphs for audio representation learning with limited labeled data
[J]. IEEE Journal of Selected Topics in Signal Processing , 2022 , 16 (6 ): 1391 - 1401
DOI:10.1109/JSTSP.2022.3190083
[本文引用: 1]
[17]
ESKIMEZ S E, DUAN Z, HEINZELMAN W. Unsupervised learning approach to feature analysis for automatic speech emotion recognition [C]// IEEE International Conference on Acoustics, Speech and Signal Processing. Calgary: IEEE, 2018: 5099–5103.
[本文引用: 1]
[18]
KANG H, XU Y, JIN G, et al FCAN: speech emotion recognition network based on focused contrastive learning
[J]. Biomedical Signal Processing and Control , 2024 , 96 : 106545
DOI:10.1016/j.bspc.2024.106545
[本文引用: 1]
[19]
SONG X, HUANG L, XUE H, et al. Supervised prototypical contrastive learning for emotion recognition in conversation [C]// Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing . Abu Dhabi, Stroudsburg: ACL, 2022: 5197−5206.
[本文引用: 1]
[20]
LI Y, WANG Y, YANG X, et al Speech emotion recognition based on Graph-LSTM neural network
[J]. EURASIP Journal on Audio, Speech, and Music Processing , 2023 , (1 ): 40
DOI:10.1186/s13636-023-00303-9
[本文引用: 2]
[21]
XU Y, WANG J, GUANG M, et al Graph contrastive learning with Min-max mutual information
[J]. Information Sciences , 2024 , 665 : 120378
DOI:10.1016/j.ins.2024.120378
[本文引用: 2]
[22]
WONG E, RICE L, KOLTER J. Fast is better than free: revisiting adversarial training [C]// 8th International Conference on Learning Representations . [S. l. ]: ICLR, 2020.
[本文引用: 1]
[23]
XU K, HU W H, LESKOVEC J, et al. How powerful are graph neural networks? [C]// 7th International Conference on Learning Representations . New Orleans: ICLR, 2019.
[本文引用: 1]
[24]
KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks [C]// 5th International Conference on Learning Representation . Toulon: ICLR, 2017.
[本文引用: 1]
[25]
BUSSO C, BULUT M, LEE C C, et al IEMOCAP: interactive emotional dyadic motion capture database
[J]. Language Resources and Evaluation , 2008 , 42 (4 ): 335 - 359
DOI:10.1007/s10579-008-9076-6
[本文引用: 1]
[26]
BURKHARDT F, PAESCHKE A, ROLFES M, et al. A database of German emotional speech [C]// Interspeech 2005 . Lisbon: ISCA, 2005: 1517−1520.
[本文引用: 1]
[27]
SCHULLER B, STEIDL S, BATLINER A, et al. The INTERSPEECH 2010 paralinguistic challenge [C]// Interspeech 2010 . Chiba: ISCA, 2010: 2794−2797.
[本文引用: 1]
[28]
PANDEY S K, SHEKHAWAT H S, PRASANNA S R M Attention gated tensor neural network architectures for speech emotion recognition
[J]. Biomedical Signal Processing and Control , 2022 , 71 : 103173
DOI:10.1016/j.bspc.2021.103173
[本文引用: 1]
[29]
LIU J, WANG H. Graph isomorphism network for speech emotion recognition [C]// Interspeech 2021 . Brno: ISCA, 2021: 3405−3409.
[本文引用: 1]
[30]
ULGEN I R, DU Z, BUSSO C, et al. Revealing emotional clusters in speaker embeddings: a contrastive learning strategy for speech emotion recognition [C]// 2024 IEEE International Conference on Acoustics, Speech and Signal Processing . Seoul: IEEE, 2024: 12081–12085.
[本文引用: 1]
[31]
GUO L, DING S, WANG L, et al DSTCNet: deep spectro-temporal-channel attention network for speech emotion recognition
[J]. IEEE Transactions on Neural Networks and Learning Systems , 2025 , 36 (1 ): 188 - 197
DOI:10.1109/TNNLS.2023.3304516
[本文引用: 3]
[32]
GUO L, LI J, DING S, et al APIN: amplitude- and phase-aware interaction network for speech emotion recognition
[J]. Speech Communication , 2025 , 169 : 103201
DOI:10.1016/j.specom.2025.103201
[本文引用: 2]
[33]
CHEN Z, LI J, LIU H, et al Learning multi-scale features for speech emotion recognition with connection attention mechanism
[J]. Expert Systems with Applications , 2023 , 214 : 118943
DOI:10.1016/j.eswa.2022.118943
[本文引用: 1]
[34]
GONG Z, SHI P, DONBEKCI K, et al. Learning more with less: self-supervised approaches for low-resource speech emotion recognition [EB/OL]. (2025−06−01) [2025−06−10]. https://arxiv. org/abs/2506.02059.
[本文引用: 1]
1
... 语音情感识别(speech emotion recognition,SER)是信号处理领域和情感计算领域的一个重要研究方向,旨在通过分析语音信号的特征和内容来识别说话者的情感状态[1 -2 ] ,被应用在医疗、人机交互、智能客服等许多领域[3 ] . 然而,由于语音的差异性和情感的复杂性,语音情感识别依然是具有挑战的[4 ] . ...
面向情感语音识别的情感维度PAD预测
1
2019
... 语音情感识别(speech emotion recognition,SER)是信号处理领域和情感计算领域的一个重要研究方向,旨在通过分析语音信号的特征和内容来识别说话者的情感状态[1 -2 ] ,被应用在医疗、人机交互、智能客服等许多领域[3 ] . 然而,由于语音的差异性和情感的复杂性,语音情感识别依然是具有挑战的[4 ] . ...
面向情感语音识别的情感维度PAD预测
1
2019
... 语音情感识别(speech emotion recognition,SER)是信号处理领域和情感计算领域的一个重要研究方向,旨在通过分析语音信号的特征和内容来识别说话者的情感状态[1 -2 ] ,被应用在医疗、人机交互、智能客服等许多领域[3 ] . 然而,由于语音的差异性和情感的复杂性,语音情感识别依然是具有挑战的[4 ] . ...
自监督对比学习的CNN-GRU语音情感识别算法
1
2024
... 语音情感识别(speech emotion recognition,SER)是信号处理领域和情感计算领域的一个重要研究方向,旨在通过分析语音信号的特征和内容来识别说话者的情感状态[1 -2 ] ,被应用在医疗、人机交互、智能客服等许多领域[3 ] . 然而,由于语音的差异性和情感的复杂性,语音情感识别依然是具有挑战的[4 ] . ...
自监督对比学习的CNN-GRU语音情感识别算法
1
2024
... 语音情感识别(speech emotion recognition,SER)是信号处理领域和情感计算领域的一个重要研究方向,旨在通过分析语音信号的特征和内容来识别说话者的情感状态[1 -2 ] ,被应用在医疗、人机交互、智能客服等许多领域[3 ] . 然而,由于语音的差异性和情感的复杂性,语音情感识别依然是具有挑战的[4 ] . ...
Speech emotion recognition via graph-based representations
5
2024
... 语音情感识别(speech emotion recognition,SER)是信号处理领域和情感计算领域的一个重要研究方向,旨在通过分析语音信号的特征和内容来识别说话者的情感状态[1 -2 ] ,被应用在医疗、人机交互、智能客服等许多领域[3 ] . 然而,由于语音的差异性和情感的复杂性,语音情感识别依然是具有挑战的[4 ] . ...
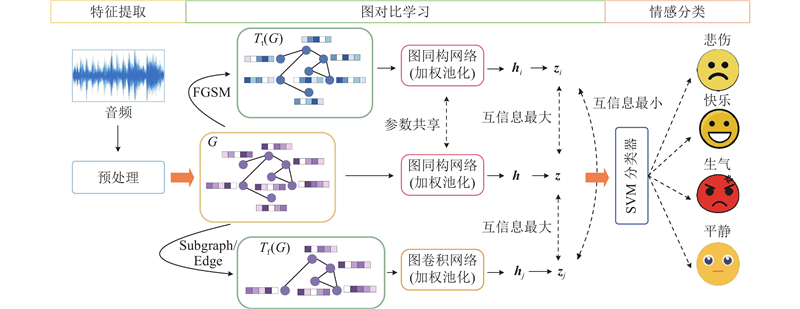
... 目前,深度学习已经被应用到语音情感识别领域. 常见的模型有卷积神经网络(convolutional neural networks,CNN)、长短期记忆网络(long short-term memory,LSTM)和门控循环单元(gate recurrent unit,GRU)等. Abdelhamid等[5 ] 将CNN和LSTM组合并基于随机分形搜索优化算法进行语音情感识别. Zhu等[6 ] 在卷积循环网络的基础上,使用双向GRU增强对短时长语音样本的处理能力,并引入聚焦损失函数处理样本不平衡问题. 不过存在以下两方面的问题. 1)它们往往需要大量的密集型有标签数据来训练模型[7 ] ,而大多数语音情感识别数据集存在稀疏性的问题[8 ] . 2)由于计算的限制,处理语音数据产生的高维特征空间是困难的[4 ,9 ] . 针对问题1,无监督学习使用无标签数据进行训练,可以有效避免语音情感识别中数据集稀疏性的问题[7 -8 ] . 针对问题2,图信号处理理论中的图表示是紧凑高效的,它能够有效捕捉语音信号帧之间的时序依赖和结构关系,将高维特征映射为低维表示[10 -12 ] . 图对比学习作为一种图表示学习方法,通过构建对比任务,可以从语音数据产生的高维特征空间中学习并优化整个图的低维嵌入表示[9 ,13 -15 ] . ...
... 图论被认为是信号处理的强大工具[4 ] . 近年来,已有研究尝试将语音帧之间的关系建模为图结构,利用图神经网络提取上下文特征,用于语音情感识别任务. 例如,Shirian等[12 ] 将语音信号建模为循环图或线图,并在此基础上构建了GCN架构. Li等[20 ] 通过特征相似性构建语音图,采用GCN和LSTM进行语音情感识别. Pentari等[4 ] 提出利用图论方法提取语音情感识别的特征集,并通过随机森林分类器进行情感分类. ...
... [4 ]提出利用图论方法提取语音情感识别的特征集,并通过随机森林分类器进行情感分类. ...
... Comparison with other speech emotion recognition models in EMO-DB dataset
Tab.3 模型 年份 UA/% WA/% AMSNet[33 ] 2023 88.56 88.34 SER-Graph[4 ] 2024 77.80 — DSTCNet-BLSTM[31 ] 2025 84.72 85.98 DSTCNet[31 ] 2025 86.55 88.79 APIN[32 ] 2025 86.00 87.85 CL[34 ] 2025 89.60 — SERUGCL 2025 91.04 90.29
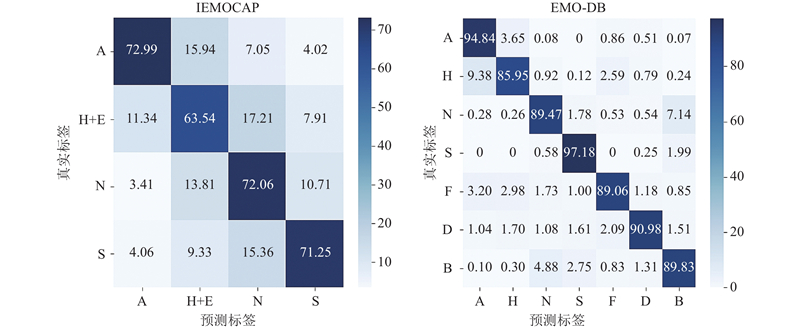
SERUGCL模型在IEMOCAP和EMO-DB数据集上的情感分类混淆矩阵如图5 所示,横轴表示模型的预测标签,纵轴表示真实标签. 在IEMOCAP数据集上,模型在识别愤怒、中性和悲伤情绪时表现良好,准确率较高,说明模型对这些情绪具有较强的区分能力. 对于快乐和兴奋情绪,准确率相对较低,且与愤怒和中性情绪存在混淆,表明这些情绪在语音特征上具有一定的相似性. 在EMO-DB数据集上,模型表现更加优异,识别准确率更高. 模型在识别愤怒、悲伤和厌恶情绪时性能最为突出. 但高兴易被误判成愤怒,无聊和中性情绪存在一定混淆,说明模型对边界不明显的情绪区别能力较弱. 总体而言,模型在大多数情绪上表现较稳定,但在部分情绪边界模糊的情况下仍有提升空间. ...
Robust speech emotion recognition using CNN+LSTM based on stochastic fractal search optimization algorithm
1
2022
... 目前,深度学习已经被应用到语音情感识别领域. 常见的模型有卷积神经网络(convolutional neural networks,CNN)、长短期记忆网络(long short-term memory,LSTM)和门控循环单元(gate recurrent unit,GRU)等. Abdelhamid等[5 ] 将CNN和LSTM组合并基于随机分形搜索优化算法进行语音情感识别. Zhu等[6 ] 在卷积循环网络的基础上,使用双向GRU增强对短时长语音样本的处理能力,并引入聚焦损失函数处理样本不平衡问题. 不过存在以下两方面的问题. 1)它们往往需要大量的密集型有标签数据来训练模型[7 ] ,而大多数语音情感识别数据集存在稀疏性的问题[8 ] . 2)由于计算的限制,处理语音数据产生的高维特征空间是困难的[4 ,9 ] . 针对问题1,无监督学习使用无标签数据进行训练,可以有效避免语音情感识别中数据集稀疏性的问题[7 -8 ] . 针对问题2,图信号处理理论中的图表示是紧凑高效的,它能够有效捕捉语音信号帧之间的时序依赖和结构关系,将高维特征映射为低维表示[10 -12 ] . 图对比学习作为一种图表示学习方法,通过构建对比任务,可以从语音数据产生的高维特征空间中学习并优化整个图的低维嵌入表示[9 ,13 -15 ] . ...
Speech emotion recognition model based on Bi-GRU and focal loss
1
2020
... 目前,深度学习已经被应用到语音情感识别领域. 常见的模型有卷积神经网络(convolutional neural networks,CNN)、长短期记忆网络(long short-term memory,LSTM)和门控循环单元(gate recurrent unit,GRU)等. Abdelhamid等[5 ] 将CNN和LSTM组合并基于随机分形搜索优化算法进行语音情感识别. Zhu等[6 ] 在卷积循环网络的基础上,使用双向GRU增强对短时长语音样本的处理能力,并引入聚焦损失函数处理样本不平衡问题. 不过存在以下两方面的问题. 1)它们往往需要大量的密集型有标签数据来训练模型[7 ] ,而大多数语音情感识别数据集存在稀疏性的问题[8 ] . 2)由于计算的限制,处理语音数据产生的高维特征空间是困难的[4 ,9 ] . 针对问题1,无监督学习使用无标签数据进行训练,可以有效避免语音情感识别中数据集稀疏性的问题[7 -8 ] . 针对问题2,图信号处理理论中的图表示是紧凑高效的,它能够有效捕捉语音信号帧之间的时序依赖和结构关系,将高维特征映射为低维表示[10 -12 ] . 图对比学习作为一种图表示学习方法,通过构建对比任务,可以从语音数据产生的高维特征空间中学习并优化整个图的低维嵌入表示[9 ,13 -15 ] . ...
4
... 目前,深度学习已经被应用到语音情感识别领域. 常见的模型有卷积神经网络(convolutional neural networks,CNN)、长短期记忆网络(long short-term memory,LSTM)和门控循环单元(gate recurrent unit,GRU)等. Abdelhamid等[5 ] 将CNN和LSTM组合并基于随机分形搜索优化算法进行语音情感识别. Zhu等[6 ] 在卷积循环网络的基础上,使用双向GRU增强对短时长语音样本的处理能力,并引入聚焦损失函数处理样本不平衡问题. 不过存在以下两方面的问题. 1)它们往往需要大量的密集型有标签数据来训练模型[7 ] ,而大多数语音情感识别数据集存在稀疏性的问题[8 ] . 2)由于计算的限制,处理语音数据产生的高维特征空间是困难的[4 ,9 ] . 针对问题1,无监督学习使用无标签数据进行训练,可以有效避免语音情感识别中数据集稀疏性的问题[7 -8 ] . 针对问题2,图信号处理理论中的图表示是紧凑高效的,它能够有效捕捉语音信号帧之间的时序依赖和结构关系,将高维特征映射为低维表示[10 -12 ] . 图对比学习作为一种图表示学习方法,通过构建对比任务,可以从语音数据产生的高维特征空间中学习并优化整个图的低维嵌入表示[9 ,13 -15 ] . ...
... [7 -8 ]. 针对问题2,图信号处理理论中的图表示是紧凑高效的,它能够有效捕捉语音信号帧之间的时序依赖和结构关系,将高维特征映射为低维表示[10 -12 ] . 图对比学习作为一种图表示学习方法,通过构建对比任务,可以从语音数据产生的高维特征空间中学习并优化整个图的低维嵌入表示[9 ,13 -15 ] . ...
... 近年来,无监督学习被应用到语音情感识别中,主要是为了克服对大量标注数据的依赖[7 ,16 ] . 无监督学习旨在从未标记的数据中自动挖掘潜在结构和分布规律,无需外部标签信息即可提取判别性表示. 典型的无监督方法包括聚类方法、自编码器、对比预测编码等. Eskimez等[17 ] 提出使用变分自编码器的无监督特征学习方法. Li等[7 ] 采用对比预测编码方法对未标记语音数据进行无监督学习,来获得对语音情感识别有用的特征表示. ...
... [7 ]采用对比预测编码方法对未标记语音数据进行无监督学习,来获得对语音情感识别有用的特征表示. ...
EmoNet: a transfer learning framework for multi-corpus speech emotion recognition
2
2023
... 目前,深度学习已经被应用到语音情感识别领域. 常见的模型有卷积神经网络(convolutional neural networks,CNN)、长短期记忆网络(long short-term memory,LSTM)和门控循环单元(gate recurrent unit,GRU)等. Abdelhamid等[5 ] 将CNN和LSTM组合并基于随机分形搜索优化算法进行语音情感识别. Zhu等[6 ] 在卷积循环网络的基础上,使用双向GRU增强对短时长语音样本的处理能力,并引入聚焦损失函数处理样本不平衡问题. 不过存在以下两方面的问题. 1)它们往往需要大量的密集型有标签数据来训练模型[7 ] ,而大多数语音情感识别数据集存在稀疏性的问题[8 ] . 2)由于计算的限制,处理语音数据产生的高维特征空间是困难的[4 ,9 ] . 针对问题1,无监督学习使用无标签数据进行训练,可以有效避免语音情感识别中数据集稀疏性的问题[7 -8 ] . 针对问题2,图信号处理理论中的图表示是紧凑高效的,它能够有效捕捉语音信号帧之间的时序依赖和结构关系,将高维特征映射为低维表示[10 -12 ] . 图对比学习作为一种图表示学习方法,通过构建对比任务,可以从语音数据产生的高维特征空间中学习并优化整个图的低维嵌入表示[9 ,13 -15 ] . ...
... -8 ]. 针对问题2,图信号处理理论中的图表示是紧凑高效的,它能够有效捕捉语音信号帧之间的时序依赖和结构关系,将高维特征映射为低维表示[10 -12 ] . 图对比学习作为一种图表示学习方法,通过构建对比任务,可以从语音数据产生的高维特征空间中学习并优化整个图的低维嵌入表示[9 ,13 -15 ] . ...
Connecting subspace learning and extreme learning machine in speech emotion recognition
2
2019
... 目前,深度学习已经被应用到语音情感识别领域. 常见的模型有卷积神经网络(convolutional neural networks,CNN)、长短期记忆网络(long short-term memory,LSTM)和门控循环单元(gate recurrent unit,GRU)等. Abdelhamid等[5 ] 将CNN和LSTM组合并基于随机分形搜索优化算法进行语音情感识别. Zhu等[6 ] 在卷积循环网络的基础上,使用双向GRU增强对短时长语音样本的处理能力,并引入聚焦损失函数处理样本不平衡问题. 不过存在以下两方面的问题. 1)它们往往需要大量的密集型有标签数据来训练模型[7 ] ,而大多数语音情感识别数据集存在稀疏性的问题[8 ] . 2)由于计算的限制,处理语音数据产生的高维特征空间是困难的[4 ,9 ] . 针对问题1,无监督学习使用无标签数据进行训练,可以有效避免语音情感识别中数据集稀疏性的问题[7 -8 ] . 针对问题2,图信号处理理论中的图表示是紧凑高效的,它能够有效捕捉语音信号帧之间的时序依赖和结构关系,将高维特征映射为低维表示[10 -12 ] . 图对比学习作为一种图表示学习方法,通过构建对比任务,可以从语音数据产生的高维特征空间中学习并优化整个图的低维嵌入表示[9 ,13 -15 ] . ...
... [9 ,13 -15 ]. ...
1
... 目前,深度学习已经被应用到语音情感识别领域. 常见的模型有卷积神经网络(convolutional neural networks,CNN)、长短期记忆网络(long short-term memory,LSTM)和门控循环单元(gate recurrent unit,GRU)等. Abdelhamid等[5 ] 将CNN和LSTM组合并基于随机分形搜索优化算法进行语音情感识别. Zhu等[6 ] 在卷积循环网络的基础上,使用双向GRU增强对短时长语音样本的处理能力,并引入聚焦损失函数处理样本不平衡问题. 不过存在以下两方面的问题. 1)它们往往需要大量的密集型有标签数据来训练模型[7 ] ,而大多数语音情感识别数据集存在稀疏性的问题[8 ] . 2)由于计算的限制,处理语音数据产生的高维特征空间是困难的[4 ,9 ] . 针对问题1,无监督学习使用无标签数据进行训练,可以有效避免语音情感识别中数据集稀疏性的问题[7 -8 ] . 针对问题2,图信号处理理论中的图表示是紧凑高效的,它能够有效捕捉语音信号帧之间的时序依赖和结构关系,将高维特征映射为低维表示[10 -12 ] . 图对比学习作为一种图表示学习方法,通过构建对比任务,可以从语音数据产生的高维特征空间中学习并优化整个图的低维嵌入表示[9 ,13 -15 ] . ...
Graph-based feature extraction: a new proposal to study the classification of music signals outside the time-frequency domain
0
2020
3
... 目前,深度学习已经被应用到语音情感识别领域. 常见的模型有卷积神经网络(convolutional neural networks,CNN)、长短期记忆网络(long short-term memory,LSTM)和门控循环单元(gate recurrent unit,GRU)等. Abdelhamid等[5 ] 将CNN和LSTM组合并基于随机分形搜索优化算法进行语音情感识别. Zhu等[6 ] 在卷积循环网络的基础上,使用双向GRU增强对短时长语音样本的处理能力,并引入聚焦损失函数处理样本不平衡问题. 不过存在以下两方面的问题. 1)它们往往需要大量的密集型有标签数据来训练模型[7 ] ,而大多数语音情感识别数据集存在稀疏性的问题[8 ] . 2)由于计算的限制,处理语音数据产生的高维特征空间是困难的[4 ,9 ] . 针对问题1,无监督学习使用无标签数据进行训练,可以有效避免语音情感识别中数据集稀疏性的问题[7 -8 ] . 针对问题2,图信号处理理论中的图表示是紧凑高效的,它能够有效捕捉语音信号帧之间的时序依赖和结构关系,将高维特征映射为低维表示[10 -12 ] . 图对比学习作为一种图表示学习方法,通过构建对比任务,可以从语音数据产生的高维特征空间中学习并优化整个图的低维嵌入表示[9 ,13 -15 ] . ...
... 图论被认为是信号处理的强大工具[4 ] . 近年来,已有研究尝试将语音帧之间的关系建模为图结构,利用图神经网络提取上下文特征,用于语音情感识别任务. 例如,Shirian等[12 ] 将语音信号建模为循环图或线图,并在此基础上构建了GCN架构. Li等[20 ] 通过特征相似性构建语音图,采用GCN和LSTM进行语音情感识别. Pentari等[4 ] 提出利用图论方法提取语音情感识别的特征集,并通过随机森林分类器进行情感分类. ...
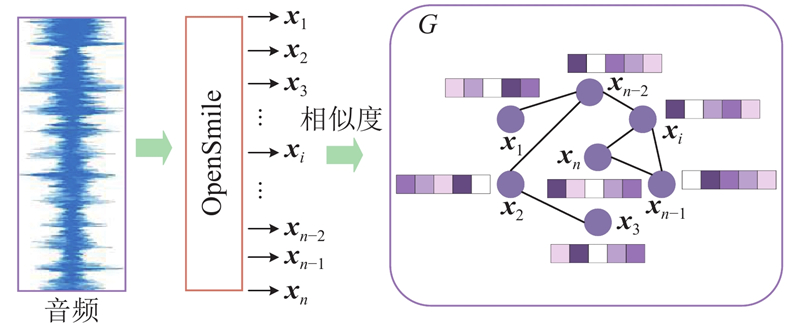
... 本研究采用基于帧的图构建方法[12 -13 ] ,其中每个语音帧形成图中的一个节点,帧级声学特征作为节点特征向量. 采用余弦相似度来衡量语音帧的特征相似性,将语音转换为图数据,具体过程如图2 所示. 这种图构建方式可以捕获长期依赖性并防止来自不相关邻居的扰动. ...
3
... 目前,深度学习已经被应用到语音情感识别领域. 常见的模型有卷积神经网络(convolutional neural networks,CNN)、长短期记忆网络(long short-term memory,LSTM)和门控循环单元(gate recurrent unit,GRU)等. Abdelhamid等[5 ] 将CNN和LSTM组合并基于随机分形搜索优化算法进行语音情感识别. Zhu等[6 ] 在卷积循环网络的基础上,使用双向GRU增强对短时长语音样本的处理能力,并引入聚焦损失函数处理样本不平衡问题. 不过存在以下两方面的问题. 1)它们往往需要大量的密集型有标签数据来训练模型[7 ] ,而大多数语音情感识别数据集存在稀疏性的问题[8 ] . 2)由于计算的限制,处理语音数据产生的高维特征空间是困难的[4 ,9 ] . 针对问题1,无监督学习使用无标签数据进行训练,可以有效避免语音情感识别中数据集稀疏性的问题[7 -8 ] . 针对问题2,图信号处理理论中的图表示是紧凑高效的,它能够有效捕捉语音信号帧之间的时序依赖和结构关系,将高维特征映射为低维表示[10 -12 ] . 图对比学习作为一种图表示学习方法,通过构建对比任务,可以从语音数据产生的高维特征空间中学习并优化整个图的低维嵌入表示[9 ,13 -15 ] . ...
... 本研究采用基于帧的图构建方法[12 -13 ] ,其中每个语音帧形成图中的一个节点,帧级声学特征作为节点特征向量. 采用余弦相似度来衡量语音帧的特征相似性,将语音转换为图数据,具体过程如图2 所示. 这种图构建方式可以捕获长期依赖性并防止来自不相关邻居的扰动. ...
... Comparison with other speech emotion recognition models in IEMOCAP dataset
Tab.2 模型 年份 UA/% WA/% GA-GRU[28 ] 2020 63.80 62.27 LSTM-GIN[29 ] 2021 65.53 64.65 CoGCN[13 ] 2022 63.67 62.64 GLNN[20 ] 2023 68.65 68.11 MTL[30 ] 2024 69.16 — DSTCNet[31 ] 2025 61.78 61.80 APIN[32 ] 2025 60.35 60.80 SERUGCL 2025 69.96 70.24
表 3 在EMO-DB数据集上与其他语音情感识别模型的比较 ...
Supervised contrastive learning for graph representation enhancement
0
2024
3
... 目前,深度学习已经被应用到语音情感识别领域. 常见的模型有卷积神经网络(convolutional neural networks,CNN)、长短期记忆网络(long short-term memory,LSTM)和门控循环单元(gate recurrent unit,GRU)等. Abdelhamid等[5 ] 将CNN和LSTM组合并基于随机分形搜索优化算法进行语音情感识别. Zhu等[6 ] 在卷积循环网络的基础上,使用双向GRU增强对短时长语音样本的处理能力,并引入聚焦损失函数处理样本不平衡问题. 不过存在以下两方面的问题. 1)它们往往需要大量的密集型有标签数据来训练模型[7 ] ,而大多数语音情感识别数据集存在稀疏性的问题[8 ] . 2)由于计算的限制,处理语音数据产生的高维特征空间是困难的[4 ,9 ] . 针对问题1,无监督学习使用无标签数据进行训练,可以有效避免语音情感识别中数据集稀疏性的问题[7 -8 ] . 针对问题2,图信号处理理论中的图表示是紧凑高效的,它能够有效捕捉语音信号帧之间的时序依赖和结构关系,将高维特征映射为低维表示[10 -12 ] . 图对比学习作为一种图表示学习方法,通过构建对比任务,可以从语音数据产生的高维特征空间中学习并优化整个图的低维嵌入表示[9 ,13 -15 ] . ...
... 图对比学习是将对比学习方法和图论相结合,在无需标签的情况下对图进行高质量的表示学习,常应用于节点分类、链接预测和图分类[15 ,21 ] . 基于此,本研究提出基于无监督图对比学习的语音情感识别框架,将语音数据建模为图,不仅能够有效捕捉语音帧之间的长期依赖关系,还能采用对比学习将高维特征映射为更具有表达性的低维嵌入表示,缓解高维特征直接建模带来的计算压力. 该方法不依赖标注数据,全部采用无标签的数据进行训练. ...
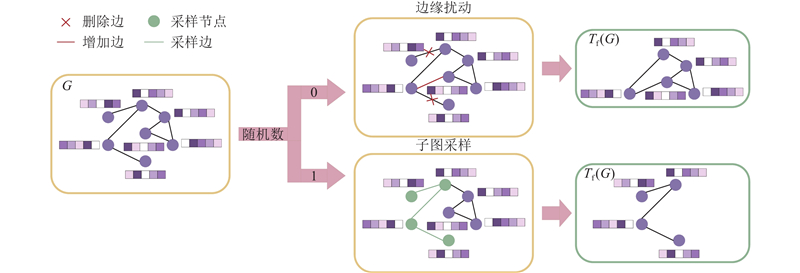
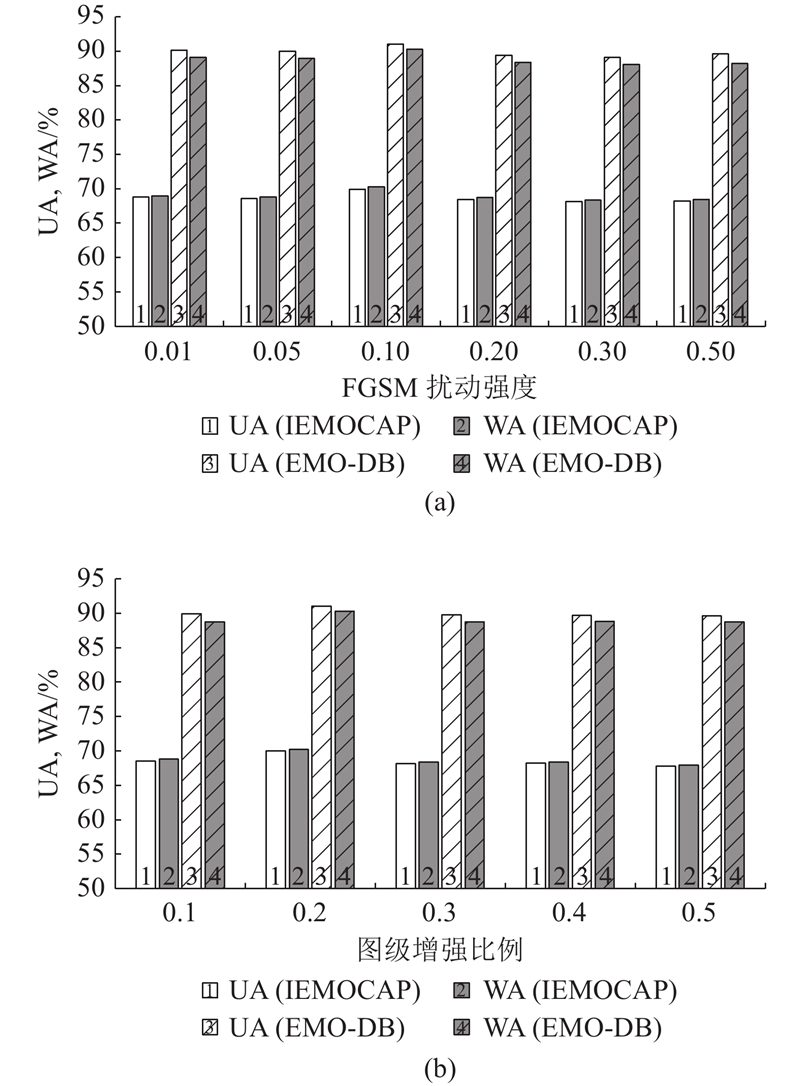
... 由于之前的研究已经证明组合不同的增强方式能更有效地提升模型性能[15 ] . 因此,图级增强选择子图采样-边缘扰动组合的方式来改变图$ G $ $ {T}_{{\mathrm{f}}}(G) $ . 具体过程如图3 所示. 对图$ G $ $ G $ $ G $
Self-supervised graphs for audio representation learning with limited labeled data
1
2022
... 近年来,无监督学习被应用到语音情感识别中,主要是为了克服对大量标注数据的依赖[7 ,16 ] . 无监督学习旨在从未标记的数据中自动挖掘潜在结构和分布规律,无需外部标签信息即可提取判别性表示. 典型的无监督方法包括聚类方法、自编码器、对比预测编码等. Eskimez等[17 ] 提出使用变分自编码器的无监督特征学习方法. Li等[7 ] 采用对比预测编码方法对未标记语音数据进行无监督学习,来获得对语音情感识别有用的特征表示. ...
1
... 近年来,无监督学习被应用到语音情感识别中,主要是为了克服对大量标注数据的依赖[7 ,16 ] . 无监督学习旨在从未标记的数据中自动挖掘潜在结构和分布规律,无需外部标签信息即可提取判别性表示. 典型的无监督方法包括聚类方法、自编码器、对比预测编码等. Eskimez等[17 ] 提出使用变分自编码器的无监督特征学习方法. Li等[7 ] 采用对比预测编码方法对未标记语音数据进行无监督学习,来获得对语音情感识别有用的特征表示. ...
FCAN: speech emotion recognition network based on focused contrastive learning
1
2024
... 对比学习作为一种无监督表示学习方法,其核心思想是最大化正样本之间的一致性并最小化负样本之间的相似性,已广泛应用于图像识别、语音建模、推荐系统等任务中. Kang等[18 ] 提出基于聚焦对比学习的语音情感识别网络,该网络包括双向GRU、注意力机制和加权损失函数. Song等[19 ] 通过对比学习解决情感识别中的不平衡分类问题. ...
1
... 对比学习作为一种无监督表示学习方法,其核心思想是最大化正样本之间的一致性并最小化负样本之间的相似性,已广泛应用于图像识别、语音建模、推荐系统等任务中. Kang等[18 ] 提出基于聚焦对比学习的语音情感识别网络,该网络包括双向GRU、注意力机制和加权损失函数. Song等[19 ] 通过对比学习解决情感识别中的不平衡分类问题. ...
Speech emotion recognition based on Graph-LSTM neural network
2
2023
... 图论被认为是信号处理的强大工具[4 ] . 近年来,已有研究尝试将语音帧之间的关系建模为图结构,利用图神经网络提取上下文特征,用于语音情感识别任务. 例如,Shirian等[12 ] 将语音信号建模为循环图或线图,并在此基础上构建了GCN架构. Li等[20 ] 通过特征相似性构建语音图,采用GCN和LSTM进行语音情感识别. Pentari等[4 ] 提出利用图论方法提取语音情感识别的特征集,并通过随机森林分类器进行情感分类. ...
... Comparison with other speech emotion recognition models in IEMOCAP dataset
Tab.2 模型 年份 UA/% WA/% GA-GRU[28 ] 2020 63.80 62.27 LSTM-GIN[29 ] 2021 65.53 64.65 CoGCN[13 ] 2022 63.67 62.64 GLNN[20 ] 2023 68.65 68.11 MTL[30 ] 2024 69.16 — DSTCNet[31 ] 2025 61.78 61.80 APIN[32 ] 2025 60.35 60.80 SERUGCL 2025 69.96 70.24
表 3 在EMO-DB数据集上与其他语音情感识别模型的比较 ...
Graph contrastive learning with Min-max mutual information
2
2024
... 图对比学习是将对比学习方法和图论相结合,在无需标签的情况下对图进行高质量的表示学习,常应用于节点分类、链接预测和图分类[15 ,21 ] . 基于此,本研究提出基于无监督图对比学习的语音情感识别框架,将语音数据建模为图,不仅能够有效捕捉语音帧之间的长期依赖关系,还能采用对比学习将高维特征映射为更具有表达性的低维嵌入表示,缓解高维特征直接建模带来的计算压力. 该方法不依赖标注数据,全部采用无标签的数据进行训练. ...
... 图数据增强是通过扰动图中的属性或拓扑信息来生成增强视图[21 ] ,本研究专注于节点级增强和图级增强. 已有研究证明FGSM具有高效、简单的优点,适合用于快速对抗训练[22 ] . 相较于随机噪声扰动,FGSM直接基于损失梯度生成针对性扰动,能够更有效地暴露模型对于关键特征维度的敏感性,从而引导编码器学习更具判别力和鲁棒性的全局图嵌入. 因此,在本研究中,节点级增强是采用FGSM对图$ G $ $ {T}_{{\mathrm{t}}}(G) $ . 节点级扰动大小设置为0.1,算法流程如下. ...
1
... 图数据增强是通过扰动图中的属性或拓扑信息来生成增强视图[21 ] ,本研究专注于节点级增强和图级增强. 已有研究证明FGSM具有高效、简单的优点,适合用于快速对抗训练[22 ] . 相较于随机噪声扰动,FGSM直接基于损失梯度生成针对性扰动,能够更有效地暴露模型对于关键特征维度的敏感性,从而引导编码器学习更具判别力和鲁棒性的全局图嵌入. 因此,在本研究中,节点级增强是采用FGSM对图$ G $ $ {T}_{{\mathrm{t}}}(G) $ . 节点级扰动大小设置为0.1,算法流程如下. ...
1
... 根据不同视图的特性选择最佳的编码器,可以避免模型对单一结构或特征依赖过重的问题. 对于原始视图$ G $ $ {T}_{{{{\mathrm{t}}}}}(G) $ $ {f}_{1}(\cdot ) $ [23 ] ,表达式如下: ...
1
... 对于增强视图$ {T}_{{\mathrm{f}}}(G) $ $ {f}_{2}(\cdot ) $ [24 ] . 表达式如下: ...
IEMOCAP: interactive emotional dyadic motion capture database
1
2008
... 使用IEMOCAP[25 ] 情感语音数据集和EMO-DB[26 ] 数据集来评估模型的有效性. IEMOCAP:包含12 h的视听数据,本研究中的情感识别任务仅使用语音数据. 为了和之前的研究保持一致,选择了4种情绪数据:中性、快乐(包含兴奋)、悲伤和愤怒,共5531 个语音样本. EMO-DB: 由10名专业演员录制的德语数据集,共包含535个语音样本. 数据集包含7种情绪:愤怒、无聊、厌恶、焦虑、快乐、悲伤和中性. ...
1
... 使用IEMOCAP[25 ] 情感语音数据集和EMO-DB[26 ] 数据集来评估模型的有效性. IEMOCAP:包含12 h的视听数据,本研究中的情感识别任务仅使用语音数据. 为了和之前的研究保持一致,选择了4种情绪数据:中性、快乐(包含兴奋)、悲伤和愤怒,共5531 个语音样本. EMO-DB: 由10名专业演员录制的德语数据集,共包含535个语音样本. 数据集包含7种情绪:愤怒、无聊、厌恶、焦虑、快乐、悲伤和中性. ...
1
... 使用openSMILE工具包从INTERSPEECH 2010副语言挑战[27 ] 中提取一组低级描述符(low-level descriptors,LLD). 特征集包括PCM响度、F0包络、LSP频率、梅尔频率倒谱系数、抖动等. 对于每个样本,研究使用长度为25 ms、步长为10 ms的滑动窗口来提取LLD. 并且,IEMOCAP数据集额外添加自发性的二进制特征. 因此每个语音样本会产生120个节点的图,IEMOCAP数据集的每个节点会产生78维特征向量,EMO-DB数据集的每个节点会产生76维特征向量. ...
Attention gated tensor neural network architectures for speech emotion recognition
1
2022
... Comparison with other speech emotion recognition models in IEMOCAP dataset
Tab.2 模型 年份 UA/% WA/% GA-GRU[28 ] 2020 63.80 62.27 LSTM-GIN[29 ] 2021 65.53 64.65 CoGCN[13 ] 2022 63.67 62.64 GLNN[20 ] 2023 68.65 68.11 MTL[30 ] 2024 69.16 — DSTCNet[31 ] 2025 61.78 61.80 APIN[32 ] 2025 60.35 60.80 SERUGCL 2025 69.96 70.24
表 3 在EMO-DB数据集上与其他语音情感识别模型的比较 ...
1
... Comparison with other speech emotion recognition models in IEMOCAP dataset
Tab.2 模型 年份 UA/% WA/% GA-GRU[28 ] 2020 63.80 62.27 LSTM-GIN[29 ] 2021 65.53 64.65 CoGCN[13 ] 2022 63.67 62.64 GLNN[20 ] 2023 68.65 68.11 MTL[30 ] 2024 69.16 — DSTCNet[31 ] 2025 61.78 61.80 APIN[32 ] 2025 60.35 60.80 SERUGCL 2025 69.96 70.24
表 3 在EMO-DB数据集上与其他语音情感识别模型的比较 ...
1
... Comparison with other speech emotion recognition models in IEMOCAP dataset
Tab.2 模型 年份 UA/% WA/% GA-GRU[28 ] 2020 63.80 62.27 LSTM-GIN[29 ] 2021 65.53 64.65 CoGCN[13 ] 2022 63.67 62.64 GLNN[20 ] 2023 68.65 68.11 MTL[30 ] 2024 69.16 — DSTCNet[31 ] 2025 61.78 61.80 APIN[32 ] 2025 60.35 60.80 SERUGCL 2025 69.96 70.24
表 3 在EMO-DB数据集上与其他语音情感识别模型的比较 ...
DSTCNet: deep spectro-temporal-channel attention network for speech emotion recognition
3
2025
... Comparison with other speech emotion recognition models in IEMOCAP dataset
Tab.2 模型 年份 UA/% WA/% GA-GRU[28 ] 2020 63.80 62.27 LSTM-GIN[29 ] 2021 65.53 64.65 CoGCN[13 ] 2022 63.67 62.64 GLNN[20 ] 2023 68.65 68.11 MTL[30 ] 2024 69.16 — DSTCNet[31 ] 2025 61.78 61.80 APIN[32 ] 2025 60.35 60.80 SERUGCL 2025 69.96 70.24
表 3 在EMO-DB数据集上与其他语音情感识别模型的比较 ...
... Comparison with other speech emotion recognition models in EMO-DB dataset
Tab.3 模型 年份 UA/% WA/% AMSNet[33 ] 2023 88.56 88.34 SER-Graph[4 ] 2024 77.80 — DSTCNet-BLSTM[31 ] 2025 84.72 85.98 DSTCNet[31 ] 2025 86.55 88.79 APIN[32 ] 2025 86.00 87.85 CL[34 ] 2025 89.60 — SERUGCL 2025 91.04 90.29
SERUGCL模型在IEMOCAP和EMO-DB数据集上的情感分类混淆矩阵如图5 所示,横轴表示模型的预测标签,纵轴表示真实标签. 在IEMOCAP数据集上,模型在识别愤怒、中性和悲伤情绪时表现良好,准确率较高,说明模型对这些情绪具有较强的区分能力. 对于快乐和兴奋情绪,准确率相对较低,且与愤怒和中性情绪存在混淆,表明这些情绪在语音特征上具有一定的相似性. 在EMO-DB数据集上,模型表现更加优异,识别准确率更高. 模型在识别愤怒、悲伤和厌恶情绪时性能最为突出. 但高兴易被误判成愤怒,无聊和中性情绪存在一定混淆,说明模型对边界不明显的情绪区别能力较弱. 总体而言,模型在大多数情绪上表现较稳定,但在部分情绪边界模糊的情况下仍有提升空间. ...
... [
31 ]
2025 86.55 88.79 APIN[32 ] 2025 86.00 87.85 CL[34 ] 2025 89.60 — SERUGCL 2025 91.04 90.29 SERUGCL模型在IEMOCAP和EMO-DB数据集上的情感分类混淆矩阵如图5 所示,横轴表示模型的预测标签,纵轴表示真实标签. 在IEMOCAP数据集上,模型在识别愤怒、中性和悲伤情绪时表现良好,准确率较高,说明模型对这些情绪具有较强的区分能力. 对于快乐和兴奋情绪,准确率相对较低,且与愤怒和中性情绪存在混淆,表明这些情绪在语音特征上具有一定的相似性. 在EMO-DB数据集上,模型表现更加优异,识别准确率更高. 模型在识别愤怒、悲伤和厌恶情绪时性能最为突出. 但高兴易被误判成愤怒,无聊和中性情绪存在一定混淆,说明模型对边界不明显的情绪区别能力较弱. 总体而言,模型在大多数情绪上表现较稳定,但在部分情绪边界模糊的情况下仍有提升空间. ...
APIN: amplitude- and phase-aware interaction network for speech emotion recognition
2
2025
... Comparison with other speech emotion recognition models in IEMOCAP dataset
Tab.2 模型 年份 UA/% WA/% GA-GRU[28 ] 2020 63.80 62.27 LSTM-GIN[29 ] 2021 65.53 64.65 CoGCN[13 ] 2022 63.67 62.64 GLNN[20 ] 2023 68.65 68.11 MTL[30 ] 2024 69.16 — DSTCNet[31 ] 2025 61.78 61.80 APIN[32 ] 2025 60.35 60.80 SERUGCL 2025 69.96 70.24
表 3 在EMO-DB数据集上与其他语音情感识别模型的比较 ...
... Comparison with other speech emotion recognition models in EMO-DB dataset
Tab.3 模型 年份 UA/% WA/% AMSNet[33 ] 2023 88.56 88.34 SER-Graph[4 ] 2024 77.80 — DSTCNet-BLSTM[31 ] 2025 84.72 85.98 DSTCNet[31 ] 2025 86.55 88.79 APIN[32 ] 2025 86.00 87.85 CL[34 ] 2025 89.60 — SERUGCL 2025 91.04 90.29
SERUGCL模型在IEMOCAP和EMO-DB数据集上的情感分类混淆矩阵如图5 所示,横轴表示模型的预测标签,纵轴表示真实标签. 在IEMOCAP数据集上,模型在识别愤怒、中性和悲伤情绪时表现良好,准确率较高,说明模型对这些情绪具有较强的区分能力. 对于快乐和兴奋情绪,准确率相对较低,且与愤怒和中性情绪存在混淆,表明这些情绪在语音特征上具有一定的相似性. 在EMO-DB数据集上,模型表现更加优异,识别准确率更高. 模型在识别愤怒、悲伤和厌恶情绪时性能最为突出. 但高兴易被误判成愤怒,无聊和中性情绪存在一定混淆,说明模型对边界不明显的情绪区别能力较弱. 总体而言,模型在大多数情绪上表现较稳定,但在部分情绪边界模糊的情况下仍有提升空间. ...
Learning multi-scale features for speech emotion recognition with connection attention mechanism
1
2023
... Comparison with other speech emotion recognition models in EMO-DB dataset
Tab.3 模型 年份 UA/% WA/% AMSNet[33 ] 2023 88.56 88.34 SER-Graph[4 ] 2024 77.80 — DSTCNet-BLSTM[31 ] 2025 84.72 85.98 DSTCNet[31 ] 2025 86.55 88.79 APIN[32 ] 2025 86.00 87.85 CL[34 ] 2025 89.60 — SERUGCL 2025 91.04 90.29
SERUGCL模型在IEMOCAP和EMO-DB数据集上的情感分类混淆矩阵如图5 所示,横轴表示模型的预测标签,纵轴表示真实标签. 在IEMOCAP数据集上,模型在识别愤怒、中性和悲伤情绪时表现良好,准确率较高,说明模型对这些情绪具有较强的区分能力. 对于快乐和兴奋情绪,准确率相对较低,且与愤怒和中性情绪存在混淆,表明这些情绪在语音特征上具有一定的相似性. 在EMO-DB数据集上,模型表现更加优异,识别准确率更高. 模型在识别愤怒、悲伤和厌恶情绪时性能最为突出. 但高兴易被误判成愤怒,无聊和中性情绪存在一定混淆,说明模型对边界不明显的情绪区别能力较弱. 总体而言,模型在大多数情绪上表现较稳定,但在部分情绪边界模糊的情况下仍有提升空间. ...
1
... Comparison with other speech emotion recognition models in EMO-DB dataset
Tab.3 模型 年份 UA/% WA/% AMSNet[33 ] 2023 88.56 88.34 SER-Graph[4 ] 2024 77.80 — DSTCNet-BLSTM[31 ] 2025 84.72 85.98 DSTCNet[31 ] 2025 86.55 88.79 APIN[32 ] 2025 86.00 87.85 CL[34 ] 2025 89.60 — SERUGCL 2025 91.04 90.29
SERUGCL模型在IEMOCAP和EMO-DB数据集上的情感分类混淆矩阵如图5 所示,横轴表示模型的预测标签,纵轴表示真实标签. 在IEMOCAP数据集上,模型在识别愤怒、中性和悲伤情绪时表现良好,准确率较高,说明模型对这些情绪具有较强的区分能力. 对于快乐和兴奋情绪,准确率相对较低,且与愤怒和中性情绪存在混淆,表明这些情绪在语音特征上具有一定的相似性. 在EMO-DB数据集上,模型表现更加优异,识别准确率更高. 模型在识别愤怒、悲伤和厌恶情绪时性能最为突出. 但高兴易被误判成愤怒,无聊和中性情绪存在一定混淆,说明模型对边界不明显的情绪区别能力较弱. 总体而言,模型在大多数情绪上表现较稳定,但在部分情绪边界模糊的情况下仍有提升空间. ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}