| 计算机技术 |
|

|
|
|
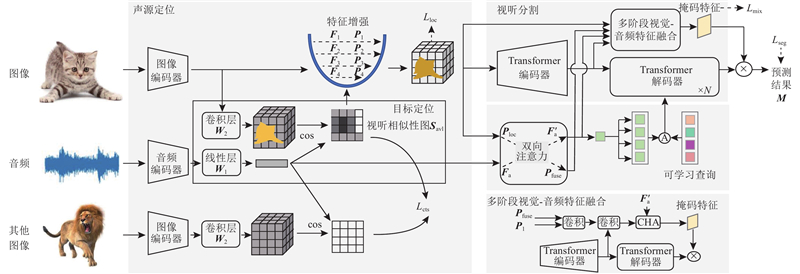
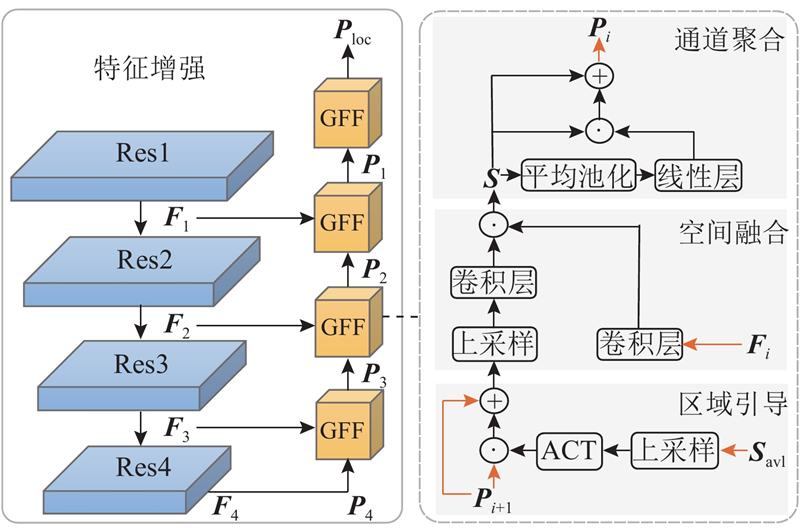
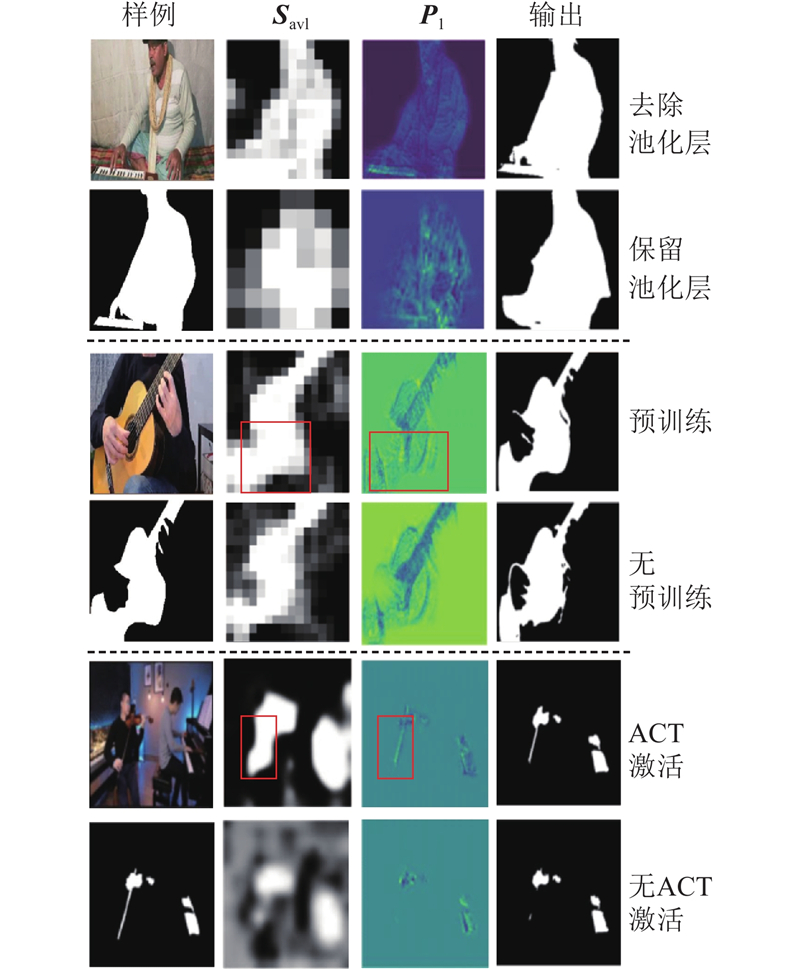
| 基于对比学习的声源定位引导视听分割模型 |
黄文湖( ),赵邢*(),谢亮,梁浩然,梁荣华 ),赵邢*(),谢亮,梁浩然,梁荣华 |
| 浙江工业大学 计算机科学与技术学院,浙江 杭州 310023 |
|
| Contrastive learning-based sound source localization-guided audio-visual segmentation model |
| Wenhu HUANG(),Xing ZHAO*(),Liang XIE,Haoran LIANG,Ronghua LIANG |
| College of Computer Science and Technology, Zhejiang University of Technology, Hangzhou 310023, China |
引用本文:
黄文湖,赵邢,谢亮,梁浩然,梁荣华. 基于对比学习的声源定位引导视听分割模型[J]. 浙江大学学报(工学版), 2025, 59(9): 1803-1813.
Wenhu HUANG,Xing ZHAO,Liang XIE,Haoran LIANG,Ronghua LIANG. Contrastive learning-based sound source localization-guided audio-visual segmentation model. Journal of ZheJiang University (Engineering Science), 2025, 59(9): 1803-1813.
链接本文:
https://www.zjujournals.com/eng/CN/10.3785/j.issn.1008-973X.2025.09.004
或
https://www.zjujournals.com/eng/CN/Y2025/V59/I9/1803
|
| 1 |
ARANDJELOVIĆ R, ZISSERMAN A. Look, listen and learn [C]// Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 609–617.
|
| 2 |
ARANDJELOVIĆ R, ZISSERMAN A. Objects that sound [C]// Proceedings of the European Conference on Computer Vision. Murich: ECVA, 2018: 451–466.
|
| 3 |
QIAN R, HU D, DINKEL H, et al. Multiple sound sources localization from coarse to fine [C]// Proceedings of the European Conference on Computer Vision. Glasgow: ECVA, 2020: 292–308.
|
| 4 |
MO S, MORGADO P. Localizing visual sounds the easy way [C]// Proceedings of the European Conference on Computer Vision. Tel Aviv: ECVA, 2022: 218–234.
|
| 5 |
HU X, CHEN Z, OWENS A. Mix and localize: localizing sound sources in mixtures [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 10473–10482.
|
| 6 |
HU D, WEI Y, QIAN R, et al Class-aware sounding objects localization via audiovisual correspondence[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44 (12): 9844- 9859
|
| 7 |
MO S, TIAN Y. Audio-visual grouping network for sound localization from mixtures [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 10565–10574.
|
| 8 |
MINAEE S, BOYKOV Y, PORIKLI F, et al Image segmentation using deep learning: a survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44 (7): 3523- 3542
|
| 9 |
ZHOU J, WANG J, ZHANG J, et al. Audio–visual segmentation [C]// Proceedings of the European Conference on Computer Vision. Tel Aviv: ECVA, 2022: 386–403.
|
| 10 |
YANG Q, NIE X, LI T, et al. Cooperation does matter: exploring multi-order bilateral relations for audio-visual segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 27124–27133.
|
| 11 |
LIU J, WANG Y, JU C, et al. Annotation-free audio-visual segmentation [C]// Proceedings of the IEEE Winter Conference on Applications of Computer Vision. Waikoloa: IEEE, 2024: 5592–5602.
|
| 12 |
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale [EB/OL]. (2020-10-22) [2025-01-10]. https://arxiv.org/abs/2010.11929.
|
| 13 |
WANG R, TANG D, DUAN N, et al. K-adapter: infusing knowledge into pre-trained models with adapters [EB/OL]. (2020-02-05) [2025-01-10]. https://arxiv.org/abs/2002.01808.
|
| 14 |
KIRILLOV A, MINTUN E, RAVI N, et al. Segment anything [C]// Proceedings of the IEEE International Conference on Computer Vision. Paris: IEEE, 2023: 3992–4003.
|
| 15 |
WANG Y, LIU W, LI G, et al. Prompting segmentation with sound is generalizable audio-visual source localizer [C]// Proceedings of the AAAI Conference on Artificial Intelligence. Vancouver: AAAI, 2024: 5669–5677.
|
| 16 |
MA J, SUN P, WANG Y, et al. Stepping stones: a progressive training strategy for audio-visual semantic segmentation [C]// Proceedings of the European Conference on Computer Vision. Milan: ECVA, 2024: 311–327.
|
| 17 |
CHENG B, MISRA I, SCHWING A G, et al. Masked-attention mask Transformer for universal image segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 1280–1289.
|
| 18 |
LIU J, JU C, MA C, et al. Audio-aware query-enhanced Transformer for audio-visual segmentation [EB/OL]. (2023-07-25) [2025-01-10]. https://arxiv.org/abs/2307.13236.
|
| 19 |
LI K, YANG Z, CHEN L, et al. CATR: combinatorial-dependence audio-queried Transformer for audio-visual video segmentation [C]// Proceedings of the 31st ACM International Conference on Multimedia. Ottawa: ACM, 2023: 1485–1494.
|
| 20 |
GAO S, CHEN Z, CHEN G, et al. AVSegFormer: audio-visual segmentation with Transformer [C]// Proceedings of the AAAI Conference on Artificial Intelligence. Vancouver: AAAI, 2024: 12155–12163.
|
| 21 |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st Annual Conference on Neural Information Processing Systems. Long Beach: NeurIPS Foundation, 2017: 6000–6010.
|
| 22 |
XU B, LIANG H, LIANG R, et al. Locate globally, segment locally: a progressive architecture with knowledge review network for salient object detection [C]// Proceedings of the AAAI Conference on Artificial Intelligence. [S.l.]: AAAI, 2021: 3004–3012.
|
| 23 |
MAO Y, ZHANG J, XIANG M, et al. Multimodal variational auto-encoder based audio-visual segmentation [C]// Proceedings of the IEEE International Conference on Computer Vision. Paris: IEEE, 2023: 954–965.
|
| 24 |
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770–778.
|
| 25 |
WANG W, XIE E, LI X, et al PVT v2: improved baselines with pyramid vision Transformer[J]. Computational Visual Media, 2022, 8 (3): 415- 424
doi: 10.1007/s41095-022-0274-8
|
| 26 |
HERSHEY S, CHAUDHURI S, ELLIS D P W, et al. CNN architectures for large-scale audio classification [C]// Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. New Orleans: IEEE, 2017: 131–135.
|
| 27 |
RONNEBERGER O, FISCHER P, BROX T. U-net: convolutional networks for biomedical image segmentation [C]// Proceedings of the Medical Image Computing and Computer-Assisted Intervention. Munich: Springer, 2015: 234–241.
|
| 28 |
WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// Proceedings of the European Conference on Computer Vision. Munich: ECVA, 2018: 3–19.
|
| 29 |
ZHAO X, LIANG H, LI P, et al Motion-aware memory network for fast video salient object detection[J]. IEEE Transactions on Image Processing, 2024, 33: 709- 721
|
| 30 |
WANG Q, WU B, ZHU P, et al. ECA-net: efficient channel attention for deep convolutional neural networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 11531–11539.
|
| 31 |
MILLETARI F, NAVAB N, AHMADI S A. V-net: fully convolutional neural networks for volumetric medical image segmentation [C]// Fourth International Conference on 3D Vision. Stanford: IEEE, 2016: 565–571.
|
| 32 |
LIU J, LIU Y, ZHANG F, et al. Audio-visual segmentation via unlabeled frame exploitation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 26318–26329.
|
| 33 |
LOSHCHILOV I, HUTTER F. Decoupled weight decay regularization [EB/OL]. (2017-11-14) [2025-01-10]. https://arxiv.org/abs/1711.05101.
|
| 34 |
DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Miami: IEEE, 2009: 248–255.
|
| 35 |
GEMMEKE J F, ELLIS D P W, FREEDMAN D, et al. Audio set: an ontology and human-labeled dataset for audio events [C]// Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. New Orleans: IEEE, 2017: 776–780.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|