| 计算机技术、控制工程、通信技术 |
|

|
|
|
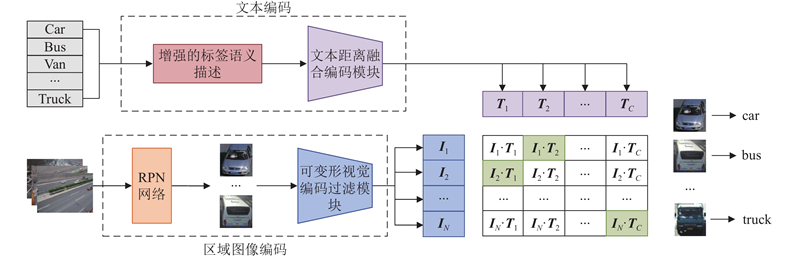
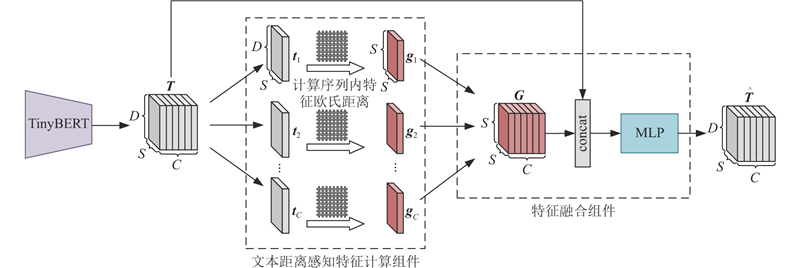
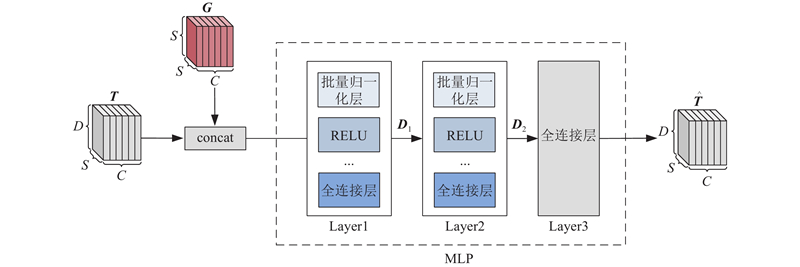
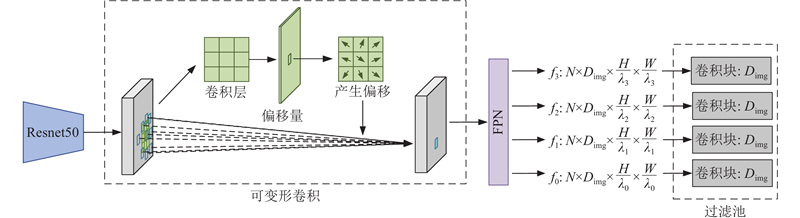
| 基于对比学习的可扩展交通图像自动标注方法 |
侯越( ),李前辉,袁鹏,张鑫,王甜甜,郝紫微 ),李前辉,袁鹏,张鑫,王甜甜,郝紫微 |
| 兰州交通大学 电子与信息工程学院,甘肃 兰州 730000 |
|
| Scalable traffic image auto-annotation method based on contrastive learning |
| Yue HOU(),Qianhui LI,Peng YUAN,Xin ZHANG,Tiantian WANG,Ziwei HAO |
| School of Electronics and Information Engineering, Lanzhou Jiaotong University, Lanzhou 730070, China |
引用本文:
侯越,李前辉,袁鹏,张鑫,王甜甜,郝紫微. 基于对比学习的可扩展交通图像自动标注方法[J]. 浙江大学学报(工学版), 2025, 59(8): 1634-1643.
Yue HOU,Qianhui LI,Peng YUAN,Xin ZHANG,Tiantian WANG,Ziwei HAO. Scalable traffic image auto-annotation method based on contrastive learning. Journal of ZheJiang University (Engineering Science), 2025, 59(8): 1634-1643.
链接本文:
https://www.zjujournals.com/eng/CN/10.3785/j.issn.1008-973X.2025.08.010
或
https://www.zjujournals.com/eng/CN/Y2025/V59/I8/1634
|
| 1 |
马艳春, 刘永坚, 解庆, 等 自动图像标注技术综述[J]. 计算机研究与发展, 2020, 57 (11): 2348- 2374
MA Yanchun, LIU Yongjian, XIE Qing, et al Review of automatic image annotation technology[J]. Journal of Computer Research and Development, 2020, 57 (11): 2348- 2374
|
| 2 |
史先进, 曹爽, 张重生, 等 基于锚点的字符级甲骨图像自动标注算法研究[J]. 电子学报, 2021, 49 (10): 2020- 2031
SHI Xianjin, CAO Shuang, ZHANG Chongsheng, et al Research on automatic annotation algorithm for character-level oracle-bone images based on anchor points[J]. Acta Electronica Sinica, 2021, 49 (10): 2020- 2031
|
| 3 |
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Columbus: IEEE, 2014: 580-587.
|
| 4 |
GIRSHICK R. Fast r-cnn [C]// Proceedings of the IEEE International Conference on Computer Vision. Santiago: IEEE, 2015: 1440-1448.
|
| 5 |
REN S, HE K, GIRSHICK R, et al Faster r-cnn: towards real-time object detection with region proposal networks[J]. Transactions on Pattern Analysis and Machine Intelligence, 2016, 39 (6): 1137- 1149
|
| 6 |
HE K, GKIOXARI G, DOLLÁR P, et al. Mask r-cnn [C]// Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 2961-2969.
|
| 7 |
CAI Z, VASCONCELOS N. Cascade r-cnn: delving into high quality object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 6154-6162.
|
| 8 |
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2016: 779-788.
|
| 9 |
REDMON J, FARHADI A. YOLO9000: better, faster, stronger [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 7263-7271.
|
| 10 |
REDMON J, FARHADI A. Yolov3: an incremental improvement [EB/OL]. (2018-04-08) [2024-08-15]. https://arxiv.org/abs/1804.02767.
|
| 11 |
WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 7464-7475.
|
| 12 |
LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C]// 14th European Conference on Computer Vision. Amsterdam: Springer, 2016: 21-37.
|
| 13 |
谢禹, 李玉俊, 董文生 基于SSD神经网络的图像自动标注及应用研究[J]. 信息技术与标准化, 2020, (4): 38- 42
XIE Yu, LI Yujun, DONG Wensheng Automatic image annotation and applied research based on SSD deep neural network[J]. Information Technology and Standardization, 2020, (4): 38- 42
|
| 14 |
乔人杰, 蔡成涛 对鱼眼图像的FastSAM多点标注算法[J]. 哈尔滨工程大学学报, 2024, 45 (8): 1427- 1433
QIAO Renjie, CAI Chengtao Research on FastSAM multi-point annotation algorithm for fisheye images[J]. Journal of Harbin Engineering University, 2024, 45 (8): 1427- 1433
|
| 15 |
RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]// International Conference on Machine Learning. Vienna: PMLR, 2021: 8748-8763.
|
| 16 |
ZHONG Y, YANG J, ZHANG P, et al. Regionclip: region-based language-image pretraining [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 16793-16803.
|
| 17 |
YANG J, LI C, ZHANG P, et al. Unified contrastive learning in image-text-label space [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 19163-19173.
|
| 18 |
JIAO X, YIN Y, SHANG L, et al. Tinybert: distilling bert for natural language understanding [EB/OL]. (2020-10-16) [2024-08-15]. https://arxiv.org/abs/1909.10351.
|
| 19 |
DONG Z, WU Y, PEI M, et al Vehicle type classification using a semisupervised convolutional neural network[J]. IEEE Transactions on Intelligent Transportation Systems, 2015, 16 (4): 2247- 2256
doi: 10.1109/TITS.2015.2402438
|
| 20 |
BOCHKOVSKIY A, WANG C Y, LIAO H Y M. Yolov4: optimal speed and accuracy of object detection [EB/OL]. (2020-04-23)[2024-08-15]. https://arxiv.org/abs/1909.10351.
|
| 21 |
CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers [C]//European Conference on Computer Vision. Cham: Springer, 2020: 213-229.
|
| 22 |
ULTRALYTICS. YOLOv5 [EB/OL]. (2021-04-15)[2024-08-15]. https://github.com/ultralytics/yolov5.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|