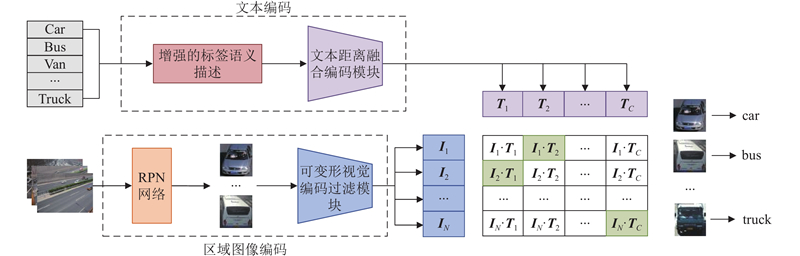
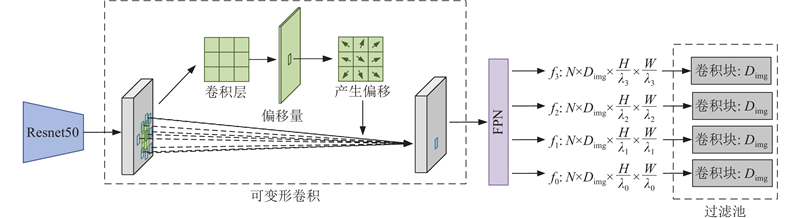
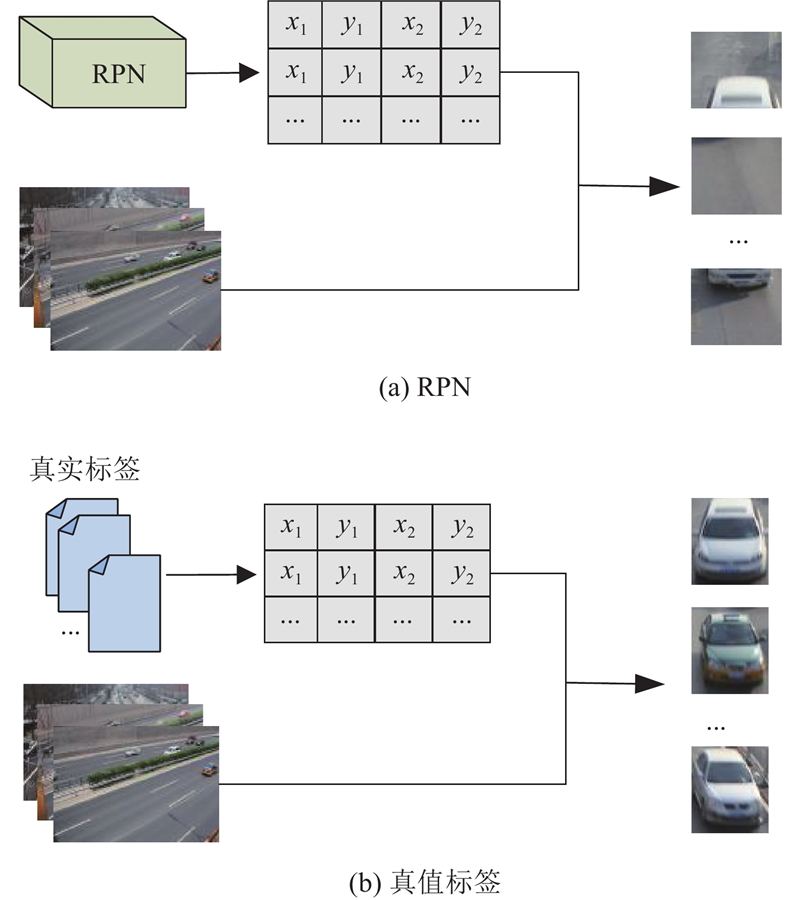
在双模态对比学习框架下,正负样本对的构建成为关键步骤. 在一个batch中,由文本距离融合编码模块提取的语义特征集合为${\{ {{\boldsymbol{l}}_m}\} _{m = 1,2,\cdots ,C}}$ ${\{ {{\boldsymbol{I}}_j}\} _{j = 1,2,\cdots ,N}}$ ${\{ {{\boldsymbol{r}}_i}\} _{i = 1,2,\cdots ,n}}$ . 由于单一图像可能包含多个目标区域,无法通过简单的顺序对应关系构建正样本对. 通过真值GT建立图像与类别语义的非顺序、多对一关系,形成图像-语义正样本对${\{ {{\boldsymbol{r}}_i},{{\boldsymbol{l}}_{m(i)}}\} _{i = 1,2,\cdots ,N}}$ ${\{ {{\boldsymbol{r}}_i},{{\boldsymbol{l}}_{m\left( i \right)}}\} _{i \ne j|i,j = 1,2,\cdots ,N}}$ .
[1]
马艳春, 刘永坚, 解庆, 等 自动图像标注技术综述
[J]. 计算机研究与发展 , 2020 , 57 (11 ): 2348 - 2374
[本文引用: 1]
MA Yanchun, LIU Yongjian, XIE Qing, et al Review of automatic image annotation technology
[J]. Journal of Computer Research and Development , 2020 , 57 (11 ): 2348 - 2374
[本文引用: 1]
[2]
史先进, 曹爽, 张重生, 等 基于锚点的字符级甲骨图像自动标注算法研究
[J]. 电子学报 , 2021 , 49 (10 ): 2020 - 2031
[本文引用: 1]
SHI Xianjin, CAO Shuang, ZHANG Chongsheng, et al Research on automatic annotation algorithm for character-level oracle-bone images based on anchor points
[J]. Acta Electronica Sinica , 2021 , 49 (10 ): 2020 - 2031
[本文引用: 1]
[3]
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Columbus: IEEE, 2014: 580-587.
[本文引用: 2]
[4]
GIRSHICK R. Fast r-cnn [C]// Proceedings of the IEEE International Conference on Computer Vision . Santiago: IEEE, 2015: 1440-1448.
[5]
REN S, HE K, GIRSHICK R, et al Faster r-cnn: towards real-time object detection with region proposal networks
[J]. Transactions on Pattern Analysis and Machine Intelligence , 2016 , 39 (6 ): 1137 - 1149
[本文引用: 1]
[6]
HE K, GKIOXARI G, DOLLÁR P, et al. Mask r-cnn [C]// Proceedings of the IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2961-2969.
[7]
CAI Z, VASCONCELOS N. Cascade r-cnn: delving into high quality object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 6154-6162.
[本文引用: 2]
[8]
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2016: 779-788.
[本文引用: 1]
[9]
REDMON J, FARHADI A. YOLO9000: better, faster, stronger [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 7263-7271.
[10]
REDMON J, FARHADI A. Yolov3: an incremental improvement [EB/OL]. (2018-04-08) [2024-08-15]. https://arxiv.org/abs/1804.02767.
[11]
WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 7464-7475.
[12]
LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C]// 14th European Conference on Computer Vision . Amsterdam: Springer, 2016: 21-37.
[本文引用: 2]
[13]
谢禹, 李玉俊, 董文生 基于SSD神经网络的图像自动标注及应用研究
[J]. 信息技术与标准化 , 2020 , (4 ): 38 - 42
[本文引用: 1]
XIE Yu, LI Yujun, DONG Wensheng Automatic image annotation and applied research based on SSD deep neural network
[J]. Information Technology and Standardization , 2020 , (4 ): 38 - 42
[本文引用: 1]
[14]
乔人杰, 蔡成涛 对鱼眼图像的FastSAM多点标注算法
[J]. 哈尔滨工程大学学报 , 2024 , 45 (8 ): 1427 - 1433
[本文引用: 1]
QIAO Renjie, CAI Chengtao Research on FastSAM multi-point annotation algorithm for fisheye images
[J]. Journal of Harbin Engineering University , 2024 , 45 (8 ): 1427 - 1433
[本文引用: 1]
[15]
RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]// International Conference on Machine Learning . Vienna: PMLR, 2021: 8748-8763.
[本文引用: 3]
[16]
ZHONG Y, YANG J, ZHANG P, et al. Regionclip: region-based language-image pretraining [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 16793-16803.
[本文引用: 1]
[17]
YANG J, LI C, ZHANG P, et al. Unified contrastive learning in image-text-label space [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 19163-19173.
[本文引用: 1]
[18]
JIAO X, YIN Y, SHANG L, et al. Tinybert: distilling bert for natural language understanding [EB/OL]. (2020-10-16) [2024-08-15]. https://arxiv.org/abs/1909.10351.
[本文引用: 1]
[19]
DONG Z, WU Y, PEI M, et al Vehicle type classification using a semisupervised convolutional neural network
[J]. IEEE Transactions on Intelligent Transportation Systems , 2015 , 16 (4 ): 2247 - 2256
DOI:10.1109/TITS.2015.2402438
[本文引用: 1]
[20]
BOCHKOVSKIY A, WANG C Y, LIAO H Y M. Yolov4: optimal speed and accuracy of object detection [EB/OL]. (2020-04-23)[2024-08-15]. https://arxiv.org/abs/1909.10351.
[本文引用: 1]
[21]
CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers [C]//European Conference on Computer Vision. Cham: Springer, 2020: 213-229.
[本文引用: 1]
[22]
ULTRALYTICS. YOLOv5 [EB/OL]. (2021-04-15)[2024-08-15]. https://github.com/ultralytics/yolov5.
[本文引用: 1]
[23]
JOCHER G, NISHIMURA K, MINEEVA T, et al. YOLOv8 [EB/OL]. (2023-01-13) [2024-08-15]. https://github.com/ultralytics/ultralytics/tags.
[本文引用: 1]
自动图像标注技术综述
1
2020
... 自动图像标注(automatic image annotation,AIA)技术是利用人工智能、模式识别或计算机视觉等方法对数字图像的视觉特征进行分析,从而为图像中的物体赋予特定语义标签的过程[1 ] . 交通图像自动标注作为智慧交通与自动驾驶目标识别的重要技术手段,通过自动标注交通场景中的目标物体,实现对车辆、行人及其他交通元素的快速识别分类. 这一过程是后续各类决策应用的基础,直接决定着各类应用场景下智能化决策模型分析结果的有效性,在智慧交通综合规划及自动化诱导方面具有非常重要的意义. ...
自动图像标注技术综述
1
2020
... 自动图像标注(automatic image annotation,AIA)技术是利用人工智能、模式识别或计算机视觉等方法对数字图像的视觉特征进行分析,从而为图像中的物体赋予特定语义标签的过程[1 ] . 交通图像自动标注作为智慧交通与自动驾驶目标识别的重要技术手段,通过自动标注交通场景中的目标物体,实现对车辆、行人及其他交通元素的快速识别分类. 这一过程是后续各类决策应用的基础,直接决定着各类应用场景下智能化决策模型分析结果的有效性,在智慧交通综合规划及自动化诱导方面具有非常重要的意义. ...
基于锚点的字符级甲骨图像自动标注算法研究
1
2021
... 现有的AIA工作主要依赖预训练的多标签目标检测模型实现[2 ] ,根据处理流程可以分为基于候选区域[3 -7 ] 和端到端[8 -12 ] 2类方法. 前者以RCNN[3 ] 为代表,使用区域建议网络(region proposal network,RPN)生成候选框,从而进行分类和边界回归. 在复杂背景或高噪声环境下,候选框的数量剧增,标注效率降低. 端到端方法因实时性和准确性高的特点,逐渐受到关注. 谢禹等[13 ] 采用SSD算法,结合半监督学习实现了AIA,但固定尺寸的候选框限制了交通场景中多目标标注的精度. 乔人杰等[14 ] 提出基于YOLOv8的多目标标注方案,提升了多目标分割精度,但因仅使用固定的全连接层进行分类,难以适应动态类别的变化,缺乏可扩展性. ...
基于锚点的字符级甲骨图像自动标注算法研究
1
2021
... 现有的AIA工作主要依赖预训练的多标签目标检测模型实现[2 ] ,根据处理流程可以分为基于候选区域[3 -7 ] 和端到端[8 -12 ] 2类方法. 前者以RCNN[3 ] 为代表,使用区域建议网络(region proposal network,RPN)生成候选框,从而进行分类和边界回归. 在复杂背景或高噪声环境下,候选框的数量剧增,标注效率降低. 端到端方法因实时性和准确性高的特点,逐渐受到关注. 谢禹等[13 ] 采用SSD算法,结合半监督学习实现了AIA,但固定尺寸的候选框限制了交通场景中多目标标注的精度. 乔人杰等[14 ] 提出基于YOLOv8的多目标标注方案,提升了多目标分割精度,但因仅使用固定的全连接层进行分类,难以适应动态类别的变化,缺乏可扩展性. ...
2
... 现有的AIA工作主要依赖预训练的多标签目标检测模型实现[2 ] ,根据处理流程可以分为基于候选区域[3 -7 ] 和端到端[8 -12 ] 2类方法. 前者以RCNN[3 ] 为代表,使用区域建议网络(region proposal network,RPN)生成候选框,从而进行分类和边界回归. 在复杂背景或高噪声环境下,候选框的数量剧增,标注效率降低. 端到端方法因实时性和准确性高的特点,逐渐受到关注. 谢禹等[13 ] 采用SSD算法,结合半监督学习实现了AIA,但固定尺寸的候选框限制了交通场景中多目标标注的精度. 乔人杰等[14 ] 提出基于YOLOv8的多目标标注方案,提升了多目标分割精度,但因仅使用固定的全连接层进行分类,难以适应动态类别的变化,缺乏可扩展性. ...
... [3 ]为代表,使用区域建议网络(region proposal network,RPN)生成候选框,从而进行分类和边界回归. 在复杂背景或高噪声环境下,候选框的数量剧增,标注效率降低. 端到端方法因实时性和准确性高的特点,逐渐受到关注. 谢禹等[13 ] 采用SSD算法,结合半监督学习实现了AIA,但固定尺寸的候选框限制了交通场景中多目标标注的精度. 乔人杰等[14 ] 提出基于YOLOv8的多目标标注方案,提升了多目标分割精度,但因仅使用固定的全连接层进行分类,难以适应动态类别的变化,缺乏可扩展性. ...
Faster r-cnn: towards real-time object detection with region proposal networks
1
2016
... Experimental result of different algorithms on BIT traffic dataset
Tab.1 模型 AP0.5 /% mAP0.5 /% mAP0.5:0.95 /% bus microbus minivan sedan suv truck Yolov4[20 ] 94.1 93.6 90.3 92.3 90.5 93.2 92.3 76.7 SSD[12 ] 95.3 94.7 91.6 93.2 92.1 96.1 93.8 77.1 DERT[21 ] 96.8 96.3 93.7 95.5 94.4 96.5 95.6 79.6 Faster RCNN[5 ] 97.0 96.5 94.2 95.8 94.1 96.5 95.7 79.9 Cascade RCNN[7 ] 97.8 97.2 94.3 96.7 94.9 98.1 96.5 80.4 Yolov5s[22 ] 96.3 95.7 92.8 94.6 93.9 96.7 95.0 78.5 Yolov8s[23 ] 98.3 97.8 95.1 97.5 95.7 98.2 97.1 81.2 SIAM-CML 99.1 98.7 94.8 98.9 95.2 98.9 97.6 81.5
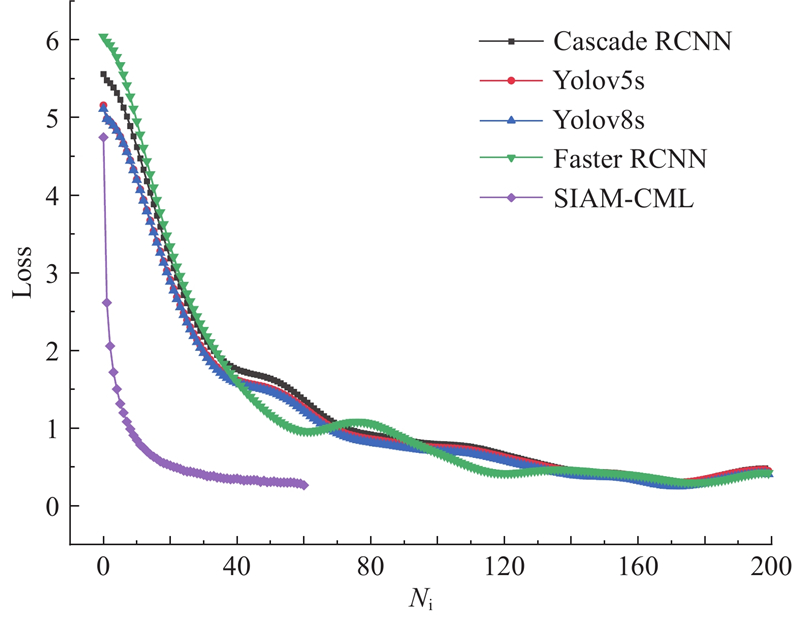
从表1 可知,SIAM-CML方法在BIT数集上的mAP0.5 及mAP0.5:0.95 分别为97.6%和81.5%,在bus、microbus、minivan、sedan、suv、truck类别上的检测精度分别为99.1%、98.7%、94.8%、98.9%、95.2%、98.9%. 相较于Yolov4模型、SSD模型、DERT模型、Faster RCNN模型、Cascade RCNN模型、Yolov5s模型与Yolov8s模型,mAP0.5 分别提高了5.3%、3.8%、2.0%、1.9%、1.1%、2.6%、0.5%,mAP0.5:0.95 分别提高了4.8%、4.4%、1.9%、1.6%、1.1%、3.0%、0.3%,实验结果最佳. 这表明SIAM-CML方法在提升文本局部信息感知能力的同时,可以有效过滤图像中的噪声信息,使得图像特征与文本语义保持较高的一致性. 此外,BIT数据集的图像分辨率高且包含的目标数量较少,这使得模型在标注和特征提取过程中能够更加准确地识别和定位目标,显著提升了边界框的精确性. ...
2
... 现有的AIA工作主要依赖预训练的多标签目标检测模型实现[2 ] ,根据处理流程可以分为基于候选区域[3 -7 ] 和端到端[8 -12 ] 2类方法. 前者以RCNN[3 ] 为代表,使用区域建议网络(region proposal network,RPN)生成候选框,从而进行分类和边界回归. 在复杂背景或高噪声环境下,候选框的数量剧增,标注效率降低. 端到端方法因实时性和准确性高的特点,逐渐受到关注. 谢禹等[13 ] 采用SSD算法,结合半监督学习实现了AIA,但固定尺寸的候选框限制了交通场景中多目标标注的精度. 乔人杰等[14 ] 提出基于YOLOv8的多目标标注方案,提升了多目标分割精度,但因仅使用固定的全连接层进行分类,难以适应动态类别的变化,缺乏可扩展性. ...
... Experimental result of different algorithms on BIT traffic dataset
Tab.1 模型 AP0.5 /% mAP0.5 /% mAP0.5:0.95 /% bus microbus minivan sedan suv truck Yolov4[20 ] 94.1 93.6 90.3 92.3 90.5 93.2 92.3 76.7 SSD[12 ] 95.3 94.7 91.6 93.2 92.1 96.1 93.8 77.1 DERT[21 ] 96.8 96.3 93.7 95.5 94.4 96.5 95.6 79.6 Faster RCNN[5 ] 97.0 96.5 94.2 95.8 94.1 96.5 95.7 79.9 Cascade RCNN[7 ] 97.8 97.2 94.3 96.7 94.9 98.1 96.5 80.4 Yolov5s[22 ] 96.3 95.7 92.8 94.6 93.9 96.7 95.0 78.5 Yolov8s[23 ] 98.3 97.8 95.1 97.5 95.7 98.2 97.1 81.2 SIAM-CML 99.1 98.7 94.8 98.9 95.2 98.9 97.6 81.5
从表1 可知,SIAM-CML方法在BIT数集上的mAP0.5 及mAP0.5:0.95 分别为97.6%和81.5%,在bus、microbus、minivan、sedan、suv、truck类别上的检测精度分别为99.1%、98.7%、94.8%、98.9%、95.2%、98.9%. 相较于Yolov4模型、SSD模型、DERT模型、Faster RCNN模型、Cascade RCNN模型、Yolov5s模型与Yolov8s模型,mAP0.5 分别提高了5.3%、3.8%、2.0%、1.9%、1.1%、2.6%、0.5%,mAP0.5:0.95 分别提高了4.8%、4.4%、1.9%、1.6%、1.1%、3.0%、0.3%,实验结果最佳. 这表明SIAM-CML方法在提升文本局部信息感知能力的同时,可以有效过滤图像中的噪声信息,使得图像特征与文本语义保持较高的一致性. 此外,BIT数据集的图像分辨率高且包含的目标数量较少,这使得模型在标注和特征提取过程中能够更加准确地识别和定位目标,显著提升了边界框的精确性. ...
1
... 现有的AIA工作主要依赖预训练的多标签目标检测模型实现[2 ] ,根据处理流程可以分为基于候选区域[3 -7 ] 和端到端[8 -12 ] 2类方法. 前者以RCNN[3 ] 为代表,使用区域建议网络(region proposal network,RPN)生成候选框,从而进行分类和边界回归. 在复杂背景或高噪声环境下,候选框的数量剧增,标注效率降低. 端到端方法因实时性和准确性高的特点,逐渐受到关注. 谢禹等[13 ] 采用SSD算法,结合半监督学习实现了AIA,但固定尺寸的候选框限制了交通场景中多目标标注的精度. 乔人杰等[14 ] 提出基于YOLOv8的多目标标注方案,提升了多目标分割精度,但因仅使用固定的全连接层进行分类,难以适应动态类别的变化,缺乏可扩展性. ...
2
... 现有的AIA工作主要依赖预训练的多标签目标检测模型实现[2 ] ,根据处理流程可以分为基于候选区域[3 -7 ] 和端到端[8 -12 ] 2类方法. 前者以RCNN[3 ] 为代表,使用区域建议网络(region proposal network,RPN)生成候选框,从而进行分类和边界回归. 在复杂背景或高噪声环境下,候选框的数量剧增,标注效率降低. 端到端方法因实时性和准确性高的特点,逐渐受到关注. 谢禹等[13 ] 采用SSD算法,结合半监督学习实现了AIA,但固定尺寸的候选框限制了交通场景中多目标标注的精度. 乔人杰等[14 ] 提出基于YOLOv8的多目标标注方案,提升了多目标分割精度,但因仅使用固定的全连接层进行分类,难以适应动态类别的变化,缺乏可扩展性. ...
... Experimental result of different algorithms on BIT traffic dataset
Tab.1 模型 AP0.5 /% mAP0.5 /% mAP0.5:0.95 /% bus microbus minivan sedan suv truck Yolov4[20 ] 94.1 93.6 90.3 92.3 90.5 93.2 92.3 76.7 SSD[12 ] 95.3 94.7 91.6 93.2 92.1 96.1 93.8 77.1 DERT[21 ] 96.8 96.3 93.7 95.5 94.4 96.5 95.6 79.6 Faster RCNN[5 ] 97.0 96.5 94.2 95.8 94.1 96.5 95.7 79.9 Cascade RCNN[7 ] 97.8 97.2 94.3 96.7 94.9 98.1 96.5 80.4 Yolov5s[22 ] 96.3 95.7 92.8 94.6 93.9 96.7 95.0 78.5 Yolov8s[23 ] 98.3 97.8 95.1 97.5 95.7 98.2 97.1 81.2 SIAM-CML 99.1 98.7 94.8 98.9 95.2 98.9 97.6 81.5
从表1 可知,SIAM-CML方法在BIT数集上的mAP0.5 及mAP0.5:0.95 分别为97.6%和81.5%,在bus、microbus、minivan、sedan、suv、truck类别上的检测精度分别为99.1%、98.7%、94.8%、98.9%、95.2%、98.9%. 相较于Yolov4模型、SSD模型、DERT模型、Faster RCNN模型、Cascade RCNN模型、Yolov5s模型与Yolov8s模型,mAP0.5 分别提高了5.3%、3.8%、2.0%、1.9%、1.1%、2.6%、0.5%,mAP0.5:0.95 分别提高了4.8%、4.4%、1.9%、1.6%、1.1%、3.0%、0.3%,实验结果最佳. 这表明SIAM-CML方法在提升文本局部信息感知能力的同时,可以有效过滤图像中的噪声信息,使得图像特征与文本语义保持较高的一致性. 此外,BIT数据集的图像分辨率高且包含的目标数量较少,这使得模型在标注和特征提取过程中能够更加准确地识别和定位目标,显著提升了边界框的精确性. ...
基于SSD神经网络的图像自动标注及应用研究
1
2020
... 现有的AIA工作主要依赖预训练的多标签目标检测模型实现[2 ] ,根据处理流程可以分为基于候选区域[3 -7 ] 和端到端[8 -12 ] 2类方法. 前者以RCNN[3 ] 为代表,使用区域建议网络(region proposal network,RPN)生成候选框,从而进行分类和边界回归. 在复杂背景或高噪声环境下,候选框的数量剧增,标注效率降低. 端到端方法因实时性和准确性高的特点,逐渐受到关注. 谢禹等[13 ] 采用SSD算法,结合半监督学习实现了AIA,但固定尺寸的候选框限制了交通场景中多目标标注的精度. 乔人杰等[14 ] 提出基于YOLOv8的多目标标注方案,提升了多目标分割精度,但因仅使用固定的全连接层进行分类,难以适应动态类别的变化,缺乏可扩展性. ...
基于SSD神经网络的图像自动标注及应用研究
1
2020
... 现有的AIA工作主要依赖预训练的多标签目标检测模型实现[2 ] ,根据处理流程可以分为基于候选区域[3 -7 ] 和端到端[8 -12 ] 2类方法. 前者以RCNN[3 ] 为代表,使用区域建议网络(region proposal network,RPN)生成候选框,从而进行分类和边界回归. 在复杂背景或高噪声环境下,候选框的数量剧增,标注效率降低. 端到端方法因实时性和准确性高的特点,逐渐受到关注. 谢禹等[13 ] 采用SSD算法,结合半监督学习实现了AIA,但固定尺寸的候选框限制了交通场景中多目标标注的精度. 乔人杰等[14 ] 提出基于YOLOv8的多目标标注方案,提升了多目标分割精度,但因仅使用固定的全连接层进行分类,难以适应动态类别的变化,缺乏可扩展性. ...
对鱼眼图像的FastSAM多点标注算法
1
2024
... 现有的AIA工作主要依赖预训练的多标签目标检测模型实现[2 ] ,根据处理流程可以分为基于候选区域[3 -7 ] 和端到端[8 -12 ] 2类方法. 前者以RCNN[3 ] 为代表,使用区域建议网络(region proposal network,RPN)生成候选框,从而进行分类和边界回归. 在复杂背景或高噪声环境下,候选框的数量剧增,标注效率降低. 端到端方法因实时性和准确性高的特点,逐渐受到关注. 谢禹等[13 ] 采用SSD算法,结合半监督学习实现了AIA,但固定尺寸的候选框限制了交通场景中多目标标注的精度. 乔人杰等[14 ] 提出基于YOLOv8的多目标标注方案,提升了多目标分割精度,但因仅使用固定的全连接层进行分类,难以适应动态类别的变化,缺乏可扩展性. ...
对鱼眼图像的FastSAM多点标注算法
1
2024
... 现有的AIA工作主要依赖预训练的多标签目标检测模型实现[2 ] ,根据处理流程可以分为基于候选区域[3 -7 ] 和端到端[8 -12 ] 2类方法. 前者以RCNN[3 ] 为代表,使用区域建议网络(region proposal network,RPN)生成候选框,从而进行分类和边界回归. 在复杂背景或高噪声环境下,候选框的数量剧增,标注效率降低. 端到端方法因实时性和准确性高的特点,逐渐受到关注. 谢禹等[13 ] 采用SSD算法,结合半监督学习实现了AIA,但固定尺寸的候选框限制了交通场景中多目标标注的精度. 乔人杰等[14 ] 提出基于YOLOv8的多目标标注方案,提升了多目标分割精度,但因仅使用固定的全连接层进行分类,难以适应动态类别的变化,缺乏可扩展性. ...
3
... 为了解决传统AIA方法标注类别不可扩展的问题,研究者们开始关注对比学习方法. Radford等[15 ] 提出对比语言-图像预训练模型(contrastive language image pre-training,CLIP). 该方法通过构建跨模态正负样本对,实现了图像级的可扩展标注,但未考虑区域级的细分类标注,且缺乏真值(ground truth,GT)对模型的直接引导,导致标注精度较低. Zhong等[16 ] 针对文献[15 ]未能实现区域级细分类标注的问题,利用RPN截取区域的图像特征,实现了区域级的语言-图像特征对齐. 该方法在训练过程中使用伪真值计算损失,影响特征匹配的准确性,导致标注精度不足. Yang等[17 ] 针对文献[15 ]标注精度低的问题,引入标签-文本-图像三元组关系,通过标签与文本间的隐式映射提升图像级分类精度,但未解决区域级多目标的细分标注问题. ...
... 针对文献[15 ]未能实现区域级细分类标注的问题,利用RPN截取区域的图像特征,实现了区域级的语言-图像特征对齐. 该方法在训练过程中使用伪真值计算损失,影响特征匹配的准确性,导致标注精度不足. Yang等[17 ] 针对文献[15 ]标注精度低的问题,引入标签-文本-图像三元组关系,通过标签与文本间的隐式映射提升图像级分类精度,但未解决区域级多目标的细分标注问题. ...
... 针对文献[15 ]标注精度低的问题,引入标签-文本-图像三元组关系,通过标签与文本间的隐式映射提升图像级分类精度,但未解决区域级多目标的细分标注问题. ...
1
... 为了解决传统AIA方法标注类别不可扩展的问题,研究者们开始关注对比学习方法. Radford等[15 ] 提出对比语言-图像预训练模型(contrastive language image pre-training,CLIP). 该方法通过构建跨模态正负样本对,实现了图像级的可扩展标注,但未考虑区域级的细分类标注,且缺乏真值(ground truth,GT)对模型的直接引导,导致标注精度较低. Zhong等[16 ] 针对文献[15 ]未能实现区域级细分类标注的问题,利用RPN截取区域的图像特征,实现了区域级的语言-图像特征对齐. 该方法在训练过程中使用伪真值计算损失,影响特征匹配的准确性,导致标注精度不足. Yang等[17 ] 针对文献[15 ]标注精度低的问题,引入标签-文本-图像三元组关系,通过标签与文本间的隐式映射提升图像级分类精度,但未解决区域级多目标的细分标注问题. ...
1
... 为了解决传统AIA方法标注类别不可扩展的问题,研究者们开始关注对比学习方法. Radford等[15 ] 提出对比语言-图像预训练模型(contrastive language image pre-training,CLIP). 该方法通过构建跨模态正负样本对,实现了图像级的可扩展标注,但未考虑区域级的细分类标注,且缺乏真值(ground truth,GT)对模型的直接引导,导致标注精度较低. Zhong等[16 ] 针对文献[15 ]未能实现区域级细分类标注的问题,利用RPN截取区域的图像特征,实现了区域级的语言-图像特征对齐. 该方法在训练过程中使用伪真值计算损失,影响特征匹配的准确性,导致标注精度不足. Yang等[17 ] 针对文献[15 ]标注精度低的问题,引入标签-文本-图像三元组关系,通过标签与文本间的隐式映射提升图像级分类精度,但未解决区域级多目标的细分标注问题. ...
1
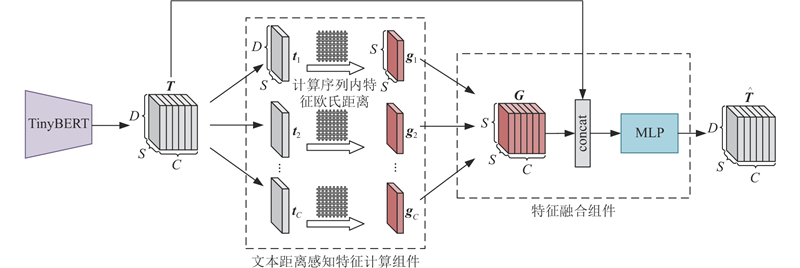
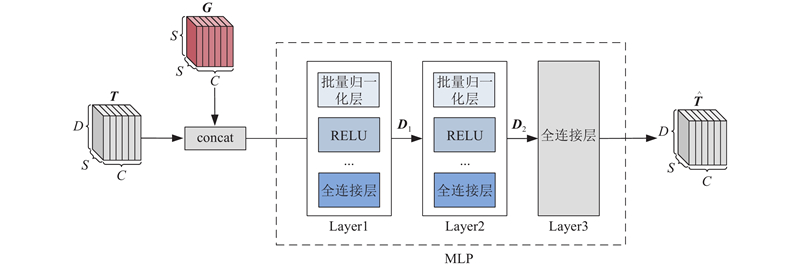
... 为了更准确、快速地将“增强的标签语义描述”转换为可有效表达所代表语义信息的文本特征,须进一步增强模型的特征提取和表示能力,降低模型复杂度,因此采用4layer-312dim的TinyBERT[18 ] 作为模型提取语义特征的基础主干网络${L_{{\mathrm{emb}}}}$ . 通过${L_{{\mathrm{emb}}}}$ ${\{ {L_m}\} _{m = 1,2,\cdots ,C}}$ C 为类别数量. ...
Vehicle type classification using a semisupervised convolutional neural network
1
2015
... 在BIT车辆和UA-DETRAC车辆检测数据集上验证模型的有效性. 其中,BIT车辆数据集[19 ] 由北京理工大学发布,包含2台相机在不同时间和地点拍摄的分辨率尺寸分别为1600 ×1200 和1920 ×1080 像素的9850 个车辆图像,以7∶1∶2的比例将其随机划分为训练集、验证集和测试集. 该数据集包括公共汽车、微型公共汽车、小型货车、轿车、suv和卡车6类. UA-DETRAC数据集包含使用佳能EOS-550D相机在中国北京和天津的24个不同地点拍摄的10 h视频,分辨率尺寸为960×540像素,包括超过14万帧的图像、121万已标注的对象边界框. 实验从UA-DETRAC数据集中随机选取10%,以7∶1∶2的比例随机划分为训练集、验证集和测试集. 该数据集包括汽车、公交车、面包车、其他交通工具4个类别. ...
1
... Experimental result of different algorithms on BIT traffic dataset
Tab.1 模型 AP0.5 /% mAP0.5 /% mAP0.5:0.95 /% bus microbus minivan sedan suv truck Yolov4[20 ] 94.1 93.6 90.3 92.3 90.5 93.2 92.3 76.7 SSD[12 ] 95.3 94.7 91.6 93.2 92.1 96.1 93.8 77.1 DERT[21 ] 96.8 96.3 93.7 95.5 94.4 96.5 95.6 79.6 Faster RCNN[5 ] 97.0 96.5 94.2 95.8 94.1 96.5 95.7 79.9 Cascade RCNN[7 ] 97.8 97.2 94.3 96.7 94.9 98.1 96.5 80.4 Yolov5s[22 ] 96.3 95.7 92.8 94.6 93.9 96.7 95.0 78.5 Yolov8s[23 ] 98.3 97.8 95.1 97.5 95.7 98.2 97.1 81.2 SIAM-CML 99.1 98.7 94.8 98.9 95.2 98.9 97.6 81.5
从表1 可知,SIAM-CML方法在BIT数集上的mAP0.5 及mAP0.5:0.95 分别为97.6%和81.5%,在bus、microbus、minivan、sedan、suv、truck类别上的检测精度分别为99.1%、98.7%、94.8%、98.9%、95.2%、98.9%. 相较于Yolov4模型、SSD模型、DERT模型、Faster RCNN模型、Cascade RCNN模型、Yolov5s模型与Yolov8s模型,mAP0.5 分别提高了5.3%、3.8%、2.0%、1.9%、1.1%、2.6%、0.5%,mAP0.5:0.95 分别提高了4.8%、4.4%、1.9%、1.6%、1.1%、3.0%、0.3%,实验结果最佳. 这表明SIAM-CML方法在提升文本局部信息感知能力的同时,可以有效过滤图像中的噪声信息,使得图像特征与文本语义保持较高的一致性. 此外,BIT数据集的图像分辨率高且包含的目标数量较少,这使得模型在标注和特征提取过程中能够更加准确地识别和定位目标,显著提升了边界框的精确性. ...
1
... Experimental result of different algorithms on BIT traffic dataset
Tab.1 模型 AP0.5 /% mAP0.5 /% mAP0.5:0.95 /% bus microbus minivan sedan suv truck Yolov4[20 ] 94.1 93.6 90.3 92.3 90.5 93.2 92.3 76.7 SSD[12 ] 95.3 94.7 91.6 93.2 92.1 96.1 93.8 77.1 DERT[21 ] 96.8 96.3 93.7 95.5 94.4 96.5 95.6 79.6 Faster RCNN[5 ] 97.0 96.5 94.2 95.8 94.1 96.5 95.7 79.9 Cascade RCNN[7 ] 97.8 97.2 94.3 96.7 94.9 98.1 96.5 80.4 Yolov5s[22 ] 96.3 95.7 92.8 94.6 93.9 96.7 95.0 78.5 Yolov8s[23 ] 98.3 97.8 95.1 97.5 95.7 98.2 97.1 81.2 SIAM-CML 99.1 98.7 94.8 98.9 95.2 98.9 97.6 81.5
从表1 可知,SIAM-CML方法在BIT数集上的mAP0.5 及mAP0.5:0.95 分别为97.6%和81.5%,在bus、microbus、minivan、sedan、suv、truck类别上的检测精度分别为99.1%、98.7%、94.8%、98.9%、95.2%、98.9%. 相较于Yolov4模型、SSD模型、DERT模型、Faster RCNN模型、Cascade RCNN模型、Yolov5s模型与Yolov8s模型,mAP0.5 分别提高了5.3%、3.8%、2.0%、1.9%、1.1%、2.6%、0.5%,mAP0.5:0.95 分别提高了4.8%、4.4%、1.9%、1.6%、1.1%、3.0%、0.3%,实验结果最佳. 这表明SIAM-CML方法在提升文本局部信息感知能力的同时,可以有效过滤图像中的噪声信息,使得图像特征与文本语义保持较高的一致性. 此外,BIT数据集的图像分辨率高且包含的目标数量较少,这使得模型在标注和特征提取过程中能够更加准确地识别和定位目标,显著提升了边界框的精确性. ...
1
... Experimental result of different algorithms on BIT traffic dataset
Tab.1 模型 AP0.5 /% mAP0.5 /% mAP0.5:0.95 /% bus microbus minivan sedan suv truck Yolov4[20 ] 94.1 93.6 90.3 92.3 90.5 93.2 92.3 76.7 SSD[12 ] 95.3 94.7 91.6 93.2 92.1 96.1 93.8 77.1 DERT[21 ] 96.8 96.3 93.7 95.5 94.4 96.5 95.6 79.6 Faster RCNN[5 ] 97.0 96.5 94.2 95.8 94.1 96.5 95.7 79.9 Cascade RCNN[7 ] 97.8 97.2 94.3 96.7 94.9 98.1 96.5 80.4 Yolov5s[22 ] 96.3 95.7 92.8 94.6 93.9 96.7 95.0 78.5 Yolov8s[23 ] 98.3 97.8 95.1 97.5 95.7 98.2 97.1 81.2 SIAM-CML 99.1 98.7 94.8 98.9 95.2 98.9 97.6 81.5
从表1 可知,SIAM-CML方法在BIT数集上的mAP0.5 及mAP0.5:0.95 分别为97.6%和81.5%,在bus、microbus、minivan、sedan、suv、truck类别上的检测精度分别为99.1%、98.7%、94.8%、98.9%、95.2%、98.9%. 相较于Yolov4模型、SSD模型、DERT模型、Faster RCNN模型、Cascade RCNN模型、Yolov5s模型与Yolov8s模型,mAP0.5 分别提高了5.3%、3.8%、2.0%、1.9%、1.1%、2.6%、0.5%,mAP0.5:0.95 分别提高了4.8%、4.4%、1.9%、1.6%、1.1%、3.0%、0.3%,实验结果最佳. 这表明SIAM-CML方法在提升文本局部信息感知能力的同时,可以有效过滤图像中的噪声信息,使得图像特征与文本语义保持较高的一致性. 此外,BIT数据集的图像分辨率高且包含的目标数量较少,这使得模型在标注和特征提取过程中能够更加准确地识别和定位目标,显著提升了边界框的精确性. ...
1
... Experimental result of different algorithms on BIT traffic dataset
Tab.1 模型 AP0.5 /% mAP0.5 /% mAP0.5:0.95 /% bus microbus minivan sedan suv truck Yolov4[20 ] 94.1 93.6 90.3 92.3 90.5 93.2 92.3 76.7 SSD[12 ] 95.3 94.7 91.6 93.2 92.1 96.1 93.8 77.1 DERT[21 ] 96.8 96.3 93.7 95.5 94.4 96.5 95.6 79.6 Faster RCNN[5 ] 97.0 96.5 94.2 95.8 94.1 96.5 95.7 79.9 Cascade RCNN[7 ] 97.8 97.2 94.3 96.7 94.9 98.1 96.5 80.4 Yolov5s[22 ] 96.3 95.7 92.8 94.6 93.9 96.7 95.0 78.5 Yolov8s[23 ] 98.3 97.8 95.1 97.5 95.7 98.2 97.1 81.2 SIAM-CML 99.1 98.7 94.8 98.9 95.2 98.9 97.6 81.5
从表1 可知,SIAM-CML方法在BIT数集上的mAP0.5 及mAP0.5:0.95 分别为97.6%和81.5%,在bus、microbus、minivan、sedan、suv、truck类别上的检测精度分别为99.1%、98.7%、94.8%、98.9%、95.2%、98.9%. 相较于Yolov4模型、SSD模型、DERT模型、Faster RCNN模型、Cascade RCNN模型、Yolov5s模型与Yolov8s模型,mAP0.5 分别提高了5.3%、3.8%、2.0%、1.9%、1.1%、2.6%、0.5%,mAP0.5:0.95 分别提高了4.8%、4.4%、1.9%、1.6%、1.1%、3.0%、0.3%,实验结果最佳. 这表明SIAM-CML方法在提升文本局部信息感知能力的同时,可以有效过滤图像中的噪声信息,使得图像特征与文本语义保持较高的一致性. 此外,BIT数据集的图像分辨率高且包含的目标数量较少,这使得模型在标注和特征提取过程中能够更加准确地识别和定位目标,显著提升了边界框的精确性. ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}