[1]
ARANDJELOVIĆ R, ZISSERMAN A. Look, listen and learn [C]// Proceedings of the IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 609–617.
[本文引用: 1]
[2]
ARANDJELOVIĆ R, ZISSERMAN A. Objects that sound [C]// Proceedings of the European Conference on Computer Vision . Murich: ECVA, 2018: 451–466.
[本文引用: 1]
[3]
QIAN R, HU D, DINKEL H, et al. Multiple sound sources localization from coarse to fine [C]// Proceedings of the European Conference on Computer Vision . Glasgow: ECVA, 2020: 292–308.
[本文引用: 4]
[4]
MO S, MORGADO P. Localizing visual sounds the easy way [C]// Proceedings of the European Conference on Computer Vision . Tel Aviv: ECVA, 2022: 218–234.
[5]
HU X, CHEN Z, OWENS A. Mix and localize: localizing sound sources in mixtures [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 10473–10482.
[本文引用: 3]
[6]
HU D, WEI Y, QIAN R, et al Class-aware sounding objects localization via audiovisual correspondence
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2022 , 44 (12 ): 9844 - 9859
[本文引用: 1]
[7]
MO S, TIAN Y. Audio-visual grouping network for sound localization from mixtures [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 10565–10574.
[本文引用: 1]
[8]
MINAEE S, BOYKOV Y, PORIKLI F, et al Image segmentation using deep learning: a survey
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2022 , 44 (7 ): 3523 - 3542
[本文引用: 1]
[9]
ZHOU J, WANG J, ZHANG J, et al. Audio–visual segmentation [C]// Proceedings of the European Conference on Computer Vision . Tel Aviv: ECVA, 2022: 386–403.
[本文引用: 5]
[10]
YANG Q, NIE X, LI T, et al. Cooperation does matter: exploring multi-order bilateral relations for audio-visual segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2024: 27124–27133.
[本文引用: 4]
[11]
LIU J, WANG Y, JU C, et al. Annotation-free audio-visual segmentation [C]// Proceedings of the IEEE Winter Conference on Applications of Computer Vision . Waikoloa: IEEE, 2024: 5592–5602.
[本文引用: 1]
[12]
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale [EB/OL]. (2020-10-22) [2025-01-10]. https://arxiv.org/abs/2010.11929.
[本文引用: 1]
[13]
WANG R, TANG D, DUAN N, et al. K-adapter: infusing knowledge into pre-trained models with adapters [EB/OL]. (2020-02-05) [2025-01-10]. https://arxiv.org/abs/2002.01808.
[本文引用: 1]
[14]
KIRILLOV A, MINTUN E, RAVI N, et al. Segment anything [C]// Proceedings of the IEEE International Conference on Computer Vision . Paris: IEEE, 2023: 3992–4003.
[本文引用: 2]
[15]
WANG Y, LIU W, LI G, et al. Prompting segmentation with sound is generalizable audio-visual source localizer [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Vancouver: AAAI, 2024: 5669–5677.
[本文引用: 2]
[16]
MA J, SUN P, WANG Y, et al. Stepping stones: a progressive training strategy for audio-visual semantic segmentation [C]// Proceedings of the European Conference on Computer Vision . Milan: ECVA, 2024: 311–327.
[本文引用: 1]
[17]
CHENG B, MISRA I, SCHWING A G, et al. Masked-attention mask Transformer for universal image segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 1280–1289.
[本文引用: 1]
[18]
LIU J, JU C, MA C, et al. Audio-aware query-enhanced Transformer for audio-visual segmentation [EB/OL]. (2023-07-25) [2025-01-10]. https://arxiv.org/abs/2307.13236.
[本文引用: 1]
[19]
LI K, YANG Z, CHEN L, et al. CATR: combinatorial-dependence audio-queried Transformer for audio-visual video segmentation [C]// Proceedings of the 31st ACM International Conference on Multimedia . Ottawa: ACM, 2023: 1485–1494.
[本文引用: 2]
[20]
GAO S, CHEN Z, CHEN G, et al. AVSegFormer: audio-visual segmentation with Transformer [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Vancouver: AAAI, 2024: 12155–12163.
[本文引用: 6]
[21]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st Annual Conference on Neural Information Processing Systems. Long Beach: NeurIPS Foundation, 2017: 6000–6010.
[本文引用: 1]
[22]
XU B, LIANG H, LIANG R, et al. Locate globally, segment locally: a progressive architecture with knowledge review network for salient object detection [C]// Proceedings of the AAAI Conference on Artificial Intelligence . [S.l.]: AAAI, 2021: 3004–3012.
[本文引用: 1]
[23]
MAO Y, ZHANG J, XIANG M, et al. Multimodal variational auto-encoder based audio-visual segmentation [C]// Proceedings of the IEEE International Conference on Computer Vision . Paris: IEEE, 2023: 954–965.
[本文引用: 2]
[24]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770–778.
[本文引用: 1]
[25]
WANG W, XIE E, LI X, et al PVT v2: improved baselines with pyramid vision Transformer
[J]. Computational Visual Media , 2022 , 8 (3 ): 415 - 424
DOI:10.1007/s41095-022-0274-8
[本文引用: 1]
[26]
HERSHEY S, CHAUDHURI S, ELLIS D P W, et al. CNN architectures for large-scale audio classification [C]// Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing . New Orleans: IEEE, 2017: 131–135.
[本文引用: 2]
[27]
RONNEBERGER O, FISCHER P, BROX T. U-net: convolutional networks for biomedical image segmentation [C]// Proceedings of the Medical Image Computing and Computer-Assisted Intervention . Munich: Springer, 2015: 234–241.
[本文引用: 1]
[28]
WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// Proceedings of the European Conference on Computer Vision . Munich: ECVA, 2018: 3–19.
[本文引用: 1]
[29]
ZHAO X, LIANG H, LI P, et al Motion-aware memory network for fast video salient object detection
[J]. IEEE Transactions on Image Processing , 2024 , 33 : 709 - 721
[本文引用: 1]
[30]
WANG Q, WU B, ZHU P, et al. ECA-net: efficient channel attention for deep convolutional neural networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 11531–11539.
[本文引用: 1]
[31]
MILLETARI F, NAVAB N, AHMADI S A. V-net: fully convolutional neural networks for volumetric medical image segmentation [C]// Fourth International Conference on 3D Vision . Stanford: IEEE, 2016: 565–571.
[本文引用: 1]
[32]
LIU J, LIU Y, ZHANG F, et al. Audio-visual segmentation via unlabeled frame exploitation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2024: 26318–26329.
[本文引用: 2]
[33]
LOSHCHILOV I, HUTTER F. Decoupled weight decay regularization [EB/OL]. (2017-11-14) [2025-01-10]. https://arxiv.org/abs/1711.05101.
[本文引用: 1]
[34]
DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Miami: IEEE, 2009: 248–255.
[本文引用: 1]
[35]
GEMMEKE J F, ELLIS D P W, FREEDMAN D, et al. Audio set: an ontology and human-labeled dataset for audio events [C]// Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing . New Orleans: IEEE, 2017: 776–780.
[本文引用: 1]
[36]
LIU C, LI P P, QI X, et al. Audio-visual segmentation by exploring cross-modal mutual semantics [C]// Proceedings of the 31st ACM International Conference on Multimedia . Ottawa: ACM, 2023: 7590–7598.
[本文引用: 1]
1
... 人类能够根据声音识别物体,表明声音信号与视觉物体之间存在强对应关系. 这种关联性为多种视听任务奠定了基础,例如视听对应[1 -2 ] ,旨在判断视觉图像与音频信号是否匹配;还有声源定位[3 -5 ] ,其任务是寻找声源物体的位置. 鉴于声音信号与视觉物体之间的强关联性,视听任务在多个领域展现出广泛的应用前景. 例如,在医疗领域中,视听技术可以协助医护人员监测患者的健康状况;在视频监控系统中,音频信号可以协助系统定位可疑声源;在自动驾驶领域,通过识别紧急车辆的警报声,车辆可以更好地理解周围环境以做出避让选择. ...
1
... 人类能够根据声音识别物体,表明声音信号与视觉物体之间存在强对应关系. 这种关联性为多种视听任务奠定了基础,例如视听对应[1 -2 ] ,旨在判断视觉图像与音频信号是否匹配;还有声源定位[3 -5 ] ,其任务是寻找声源物体的位置. 鉴于声音信号与视觉物体之间的强关联性,视听任务在多个领域展现出广泛的应用前景. 例如,在医疗领域中,视听技术可以协助医护人员监测患者的健康状况;在视频监控系统中,音频信号可以协助系统定位可疑声源;在自动驾驶领域,通过识别紧急车辆的警报声,车辆可以更好地理解周围环境以做出避让选择. ...
4
... 人类能够根据声音识别物体,表明声音信号与视觉物体之间存在强对应关系. 这种关联性为多种视听任务奠定了基础,例如视听对应[1 -2 ] ,旨在判断视觉图像与音频信号是否匹配;还有声源定位[3 -5 ] ,其任务是寻找声源物体的位置. 鉴于声音信号与视觉物体之间的强关联性,视听任务在多个领域展现出广泛的应用前景. 例如,在医疗领域中,视听技术可以协助医护人员监测患者的健康状况;在视频监控系统中,音频信号可以协助系统定位可疑声源;在自动驾驶领域,通过识别紧急车辆的警报声,车辆可以更好地理解周围环境以做出避让选择. ...
... 在SSL领域,关于视听模态对齐的研究大多采用多实例对比学习方法[3 -5 ] ,通过匹配音频与图像区域实现特征对齐. 在类别感知方面,一些研究采用两阶段策略[3 ,6 ] ,将在简单场景中学到的物体类别知识应用于复杂场景中的物体识别. Mo等[7 ] 提出视听分组网络(audio-visual grouping network, AVGN),利用可学习的视听类别令牌来聚合类感知的声源特征,并将聚合的语义特征用于指导相应视觉区域的定位,使AVGN能够灵活定位多个声源. 这些视听模态对齐和对象类别表示学习方法极大地启发了AVS研究. ...
... [3 ,6 ],将在简单场景中学到的物体类别知识应用于复杂场景中的物体识别. Mo等[7 ] 提出视听分组网络(audio-visual grouping network, AVGN),利用可学习的视听类别令牌来聚合类感知的声源特征,并将聚合的语义特征用于指导相应视觉区域的定位,使AVGN能够灵活定位多个声源. 这些视听模态对齐和对象类别表示学习方法极大地启发了AVS研究. ...
... 对比学习在声源定位领域中已展现出显著成效[3 -5 ] ,其核心思想是通过最小化跨模态对比学习损失,使音频表示与视觉表示在至少1个空间位置上对齐,而这个位置对应于目标物体所在区域. SSL2AVS将对比学习引入视听分割任务中,来获取反映物体视觉特征激活情况的视听相似性图$ {{\boldsymbol{S}}_{{\text{avl}}}} $ . 将$ {{\boldsymbol{S}}_{{\text{avl}}}} $
3
... 人类能够根据声音识别物体,表明声音信号与视觉物体之间存在强对应关系. 这种关联性为多种视听任务奠定了基础,例如视听对应[1 -2 ] ,旨在判断视觉图像与音频信号是否匹配;还有声源定位[3 -5 ] ,其任务是寻找声源物体的位置. 鉴于声音信号与视觉物体之间的强关联性,视听任务在多个领域展现出广泛的应用前景. 例如,在医疗领域中,视听技术可以协助医护人员监测患者的健康状况;在视频监控系统中,音频信号可以协助系统定位可疑声源;在自动驾驶领域,通过识别紧急车辆的警报声,车辆可以更好地理解周围环境以做出避让选择. ...
... 在SSL领域,关于视听模态对齐的研究大多采用多实例对比学习方法[3 -5 ] ,通过匹配音频与图像区域实现特征对齐. 在类别感知方面,一些研究采用两阶段策略[3 ,6 ] ,将在简单场景中学到的物体类别知识应用于复杂场景中的物体识别. Mo等[7 ] 提出视听分组网络(audio-visual grouping network, AVGN),利用可学习的视听类别令牌来聚合类感知的声源特征,并将聚合的语义特征用于指导相应视觉区域的定位,使AVGN能够灵活定位多个声源. 这些视听模态对齐和对象类别表示学习方法极大地启发了AVS研究. ...
... 对比学习在声源定位领域中已展现出显著成效[3 -5 ] ,其核心思想是通过最小化跨模态对比学习损失,使音频表示与视觉表示在至少1个空间位置上对齐,而这个位置对应于目标物体所在区域. SSL2AVS将对比学习引入视听分割任务中,来获取反映物体视觉特征激活情况的视听相似性图$ {{\boldsymbol{S}}_{{\text{avl}}}} $ . 将$ {{\boldsymbol{S}}_{{\text{avl}}}} $
Class-aware sounding objects localization via audiovisual correspondence
1
2022
... 在SSL领域,关于视听模态对齐的研究大多采用多实例对比学习方法[3 -5 ] ,通过匹配音频与图像区域实现特征对齐. 在类别感知方面,一些研究采用两阶段策略[3 ,6 ] ,将在简单场景中学到的物体类别知识应用于复杂场景中的物体识别. Mo等[7 ] 提出视听分组网络(audio-visual grouping network, AVGN),利用可学习的视听类别令牌来聚合类感知的声源特征,并将聚合的语义特征用于指导相应视觉区域的定位,使AVGN能够灵活定位多个声源. 这些视听模态对齐和对象类别表示学习方法极大地启发了AVS研究. ...
1
... 在SSL领域,关于视听模态对齐的研究大多采用多实例对比学习方法[3 -5 ] ,通过匹配音频与图像区域实现特征对齐. 在类别感知方面,一些研究采用两阶段策略[3 ,6 ] ,将在简单场景中学到的物体类别知识应用于复杂场景中的物体识别. Mo等[7 ] 提出视听分组网络(audio-visual grouping network, AVGN),利用可学习的视听类别令牌来聚合类感知的声源特征,并将聚合的语义特征用于指导相应视觉区域的定位,使AVGN能够灵活定位多个声源. 这些视听模态对齐和对象类别表示学习方法极大地启发了AVS研究. ...
Image segmentation using deep learning: a survey
1
2022
... 相较于SSL的区域级定位,AVS通常需要实现像素级定位,要求模型能够精确分割出发声物体的轮廓,因此在自动驾驶碰撞预警、视频内容理解等场景中展现出更直接的应用价值. 这种高精度要求使AVS面临比SSL更复杂的挑战. 1)AVS涉及图像分割[8 ] . 与一维音频信号相比,二维图像信号包含更多复杂信息,容易受到背景噪声的干扰,因此需要精确提取出物体特征. 2)AVS涉及音频和视觉模态. 和仅寻找声源位置的SSL任务不同,AVS需要将音频特征与更加精细的像素级特征进行对齐和融合. 3)音频信号是信息密集的,通常同时包含多个来源的声音,例如音乐会中的乐器声和人声常常交织在一起. 这要求将每个时间点的音频信号解耦为多种潜在成分,以便有效捕捉每个声源的独特声音特征. ...
5
... 为了解决上述问题,Zhou等[9 ] 提出时间像素级视听交互模块,注入音频语义来指导视觉分割过程. 一些方法基于基础模型实现视听分割. 例如,Yang等[10 ] 利用基础模型生成语义掩码,将其融入视觉特征中. Liu等[11 ] 使用冻结的ViT-H模型[12 ] 提取图像特征,并通过Adapter策略[13 ] 将音频信息注入到预训练的SAM模型[14 ] 中,以实现视听融合. Wang等[15 ] 基于SAM模型,通过构建音频提示,并且调优参与跨模态注意力模块的上下文来构建视听相关性;Ma等[16 ] 基于Mask2Former架构[17 ] ,将视听分割结果用于辅助语义分割中的物体定位. 另外,许多方法[18 -20 ] 基于Transformer架构[21 ] ,通过将音频解耦为音频查询来实现实例级感知和识别. 例如,在AVSegFormer模型[20 ] 中,编码器负责挖掘对象的语义信息,查询生成器利用音频特征生成音频查询,解码器通过交叉注意力机制,利用音频查询来分离潜在对象. ...
... 遵循文献方法[9 ,10 ,19 ,20 ,23 ] 的特征提取方式,图像编码器采用基于卷积的ResNet-50模型[24 ] 和基于视觉Transformer的PVT v2模型[25 ] ,音频编码器采用VGGish模型[26 ] . 不同的是,为了使用对比学习方法,需要重新组织输入,让不同视频的帧之间构成对比项. 给定一批包含B 个视频、每个视频有T 帧的视觉信息,该信息可以表示为$ {\boldsymbol{V}} \in {{\bf{R}}^{B \times T \times 3 \times H \times W}} $ H 和W 表示帧的大小;重新组织视觉信息为$ {\boldsymbol{V}} \in {{\bf{R}}^{T \times B \times 3 \times H \times W}} $ . 将每批数据分T 次输入到模型中,每次的输入为$ {{{\boldsymbol{V}}}_{{\text{input}}}} \in {{\bf{R}}^{B \times {\text{3}} \times H \times W}} $ B 个视频的帧之间构成对比项. 音频信息的组织方式同理. ...
... AVSBench-Object[9 ] 是专门为视听分割任务设计的视听数据集,包含像素级注释. 根据场景中声源物体的数量,将数据集划分为2个子集:用于单个声源分割的单声源子集(S4)和用于多个声源分割的多声源子集(MS3). S4子集包含4 932个视频,其中3 452个视频用于训练,740个用于验证,740个用于测试. 其目标对象涵盖23个类别,包括人、动物、车辆和乐器. MS3子集有424个视频,包括296个训练视频、64个验证视频和 64个测试视频,涵盖类别与S4子集相同. ...
... 和文献[9 ]、[20 ]、[32 ]一样,本研究使用均交并比(mean Intersection-over-Union, mIoU)和F1分数(F-score)作为评价指标,分别用$ {M_{\text{J}}} $ $ {M_{\mathrm{F}}} $
... Performance comparison of SSL2AVS and existing AVS methods
Tab.2 方法 图像编码器 S4 MS3 $ {M_{\text{F}}} $ $ {M_{\text{J}}} $ $ {M_{\text{F}}} $ $ {M_{\text{J}}} $ AVSBench[9 ] ResNet-50 84.8 72.80 57.8 47.90 PVT v2 87.9 78.70 64.5 54.00 ECMVAE[23 ] ResNet-50 86.5 76.33 60.7 48.69 PVT v2 90.1 81.74 70.8 57.84 CATR[19 ] ResNet-50 86.6 74.80 65.3 52.80 PVT v2 89.6 81.40 70.0 59.00 AVSC[36 ] ResNet-50 85.2 77.02 61.5 49.58 PVT v2 88.2 80.57 65.1 58.22 AVS-UFE[32 ] ResNet-50 87.5 78.96 64.5 55.88 PVT v2 90.4 83.15 70.9 61.95 COMBO[10 ] ResNet-50 90.1 81.70 66.6 54.50 PVT v2 91.9 84.70 71.2 59.20 AVSegFormer[20 ] ResNet-50 85.9 76.45 62.8 49.53 PVT v2 89.9 82.06 69.3 58.36 SSL2AVS ResNet-50 86.8 77.16 66.9 56.18 PVT v2 90.3 82.42 72.3 62.15
由表1 可知,当以512×512的图像作为输入时,与AVSegFormer模型相比,SSL2AVS-R50*和SSL2AVS-PVTv2*的$ {M_{\text{J}}} $ $ {M_{\text{J}}} $ $ {M_{\text{J}}} $
4
... 为了解决上述问题,Zhou等[9 ] 提出时间像素级视听交互模块,注入音频语义来指导视觉分割过程. 一些方法基于基础模型实现视听分割. 例如,Yang等[10 ] 利用基础模型生成语义掩码,将其融入视觉特征中. Liu等[11 ] 使用冻结的ViT-H模型[12 ] 提取图像特征,并通过Adapter策略[13 ] 将音频信息注入到预训练的SAM模型[14 ] 中,以实现视听融合. Wang等[15 ] 基于SAM模型,通过构建音频提示,并且调优参与跨模态注意力模块的上下文来构建视听相关性;Ma等[16 ] 基于Mask2Former架构[17 ] ,将视听分割结果用于辅助语义分割中的物体定位. 另外,许多方法[18 -20 ] 基于Transformer架构[21 ] ,通过将音频解耦为音频查询来实现实例级感知和识别. 例如,在AVSegFormer模型[20 ] 中,编码器负责挖掘对象的语义信息,查询生成器利用音频特征生成音频查询,解码器通过交叉注意力机制,利用音频查询来分离潜在对象. ...
... 遵循文献方法[9 ,10 ,19 ,20 ,23 ] 的特征提取方式,图像编码器采用基于卷积的ResNet-50模型[24 ] 和基于视觉Transformer的PVT v2模型[25 ] ,音频编码器采用VGGish模型[26 ] . 不同的是,为了使用对比学习方法,需要重新组织输入,让不同视频的帧之间构成对比项. 给定一批包含B 个视频、每个视频有T 帧的视觉信息,该信息可以表示为$ {\boldsymbol{V}} \in {{\bf{R}}^{B \times T \times 3 \times H \times W}} $ H 和W 表示帧的大小;重新组织视觉信息为$ {\boldsymbol{V}} \in {{\bf{R}}^{T \times B \times 3 \times H \times W}} $ . 将每批数据分T 次输入到模型中,每次的输入为$ {{{\boldsymbol{V}}}_{{\text{input}}}} \in {{\bf{R}}^{B \times {\text{3}} \times H \times W}} $ B 个视频的帧之间构成对比项. 音频信息的组织方式同理. ...
... 在以往的研究中,音频查询通常由音频特征独立获得,但这忽略了视觉信息对音频特征的重要作用[14 -15 ] . 特别是当场景中存在外形与声源物体相似的干扰物体时,仅依靠原始音频特征,模型难以准确建立查询与物体视觉特征之间的对应关系. 为了应对这一问题,采用COMBO框架[10 ] 中的双向注意力融合模块(bilateral-fusion module, BFM). 通过4个线性层将$ {{{\boldsymbol{P}}}_{{\text{loc}}}} $ $ {{\boldsymbol{F}}_{{\text{a}}}} $ $ {{\boldsymbol{Q}}} = {{{\boldsymbol{P}}}_{{\text{loc}}}}{{\boldsymbol{W}}_{\boldsymbol{Q}}} $ $ {{\boldsymbol{K}}} = {{\boldsymbol{F}}_{{\text{a}}}}{{\boldsymbol{W}}_K} $ $ {{{\boldsymbol{V}}}_{\text{v}}} = {{{\boldsymbol{P}}}_{{\text{loc}}}}{\boldsymbol{W}}_{\boldsymbol{V}}^{\text{v}} $ ${{{\boldsymbol{V}}}_{\text{a}}}{\text{ = }} $ $ {{\boldsymbol{F}}_{{\text{a}}}}{\boldsymbol{W}}_{\boldsymbol{V}}^{\text{a}} $ . 双向注意力的操作为 ...
... Performance comparison of SSL2AVS and existing AVS methods
Tab.2 方法 图像编码器 S4 MS3 $ {M_{\text{F}}} $ $ {M_{\text{J}}} $ $ {M_{\text{F}}} $ $ {M_{\text{J}}} $ AVSBench[9 ] ResNet-50 84.8 72.80 57.8 47.90 PVT v2 87.9 78.70 64.5 54.00 ECMVAE[23 ] ResNet-50 86.5 76.33 60.7 48.69 PVT v2 90.1 81.74 70.8 57.84 CATR[19 ] ResNet-50 86.6 74.80 65.3 52.80 PVT v2 89.6 81.40 70.0 59.00 AVSC[36 ] ResNet-50 85.2 77.02 61.5 49.58 PVT v2 88.2 80.57 65.1 58.22 AVS-UFE[32 ] ResNet-50 87.5 78.96 64.5 55.88 PVT v2 90.4 83.15 70.9 61.95 COMBO[10 ] ResNet-50 90.1 81.70 66.6 54.50 PVT v2 91.9 84.70 71.2 59.20 AVSegFormer[20 ] ResNet-50 85.9 76.45 62.8 49.53 PVT v2 89.9 82.06 69.3 58.36 SSL2AVS ResNet-50 86.8 77.16 66.9 56.18 PVT v2 90.3 82.42 72.3 62.15
由表1 可知,当以512×512的图像作为输入时,与AVSegFormer模型相比,SSL2AVS-R50*和SSL2AVS-PVTv2*的$ {M_{\text{J}}} $ $ {M_{\text{J}}} $ $ {M_{\text{J}}} $
1
... 为了解决上述问题,Zhou等[9 ] 提出时间像素级视听交互模块,注入音频语义来指导视觉分割过程. 一些方法基于基础模型实现视听分割. 例如,Yang等[10 ] 利用基础模型生成语义掩码,将其融入视觉特征中. Liu等[11 ] 使用冻结的ViT-H模型[12 ] 提取图像特征,并通过Adapter策略[13 ] 将音频信息注入到预训练的SAM模型[14 ] 中,以实现视听融合. Wang等[15 ] 基于SAM模型,通过构建音频提示,并且调优参与跨模态注意力模块的上下文来构建视听相关性;Ma等[16 ] 基于Mask2Former架构[17 ] ,将视听分割结果用于辅助语义分割中的物体定位. 另外,许多方法[18 -20 ] 基于Transformer架构[21 ] ,通过将音频解耦为音频查询来实现实例级感知和识别. 例如,在AVSegFormer模型[20 ] 中,编码器负责挖掘对象的语义信息,查询生成器利用音频特征生成音频查询,解码器通过交叉注意力机制,利用音频查询来分离潜在对象. ...
1
... 为了解决上述问题,Zhou等[9 ] 提出时间像素级视听交互模块,注入音频语义来指导视觉分割过程. 一些方法基于基础模型实现视听分割. 例如,Yang等[10 ] 利用基础模型生成语义掩码,将其融入视觉特征中. Liu等[11 ] 使用冻结的ViT-H模型[12 ] 提取图像特征,并通过Adapter策略[13 ] 将音频信息注入到预训练的SAM模型[14 ] 中,以实现视听融合. Wang等[15 ] 基于SAM模型,通过构建音频提示,并且调优参与跨模态注意力模块的上下文来构建视听相关性;Ma等[16 ] 基于Mask2Former架构[17 ] ,将视听分割结果用于辅助语义分割中的物体定位. 另外,许多方法[18 -20 ] 基于Transformer架构[21 ] ,通过将音频解耦为音频查询来实现实例级感知和识别. 例如,在AVSegFormer模型[20 ] 中,编码器负责挖掘对象的语义信息,查询生成器利用音频特征生成音频查询,解码器通过交叉注意力机制,利用音频查询来分离潜在对象. ...
1
... 为了解决上述问题,Zhou等[9 ] 提出时间像素级视听交互模块,注入音频语义来指导视觉分割过程. 一些方法基于基础模型实现视听分割. 例如,Yang等[10 ] 利用基础模型生成语义掩码,将其融入视觉特征中. Liu等[11 ] 使用冻结的ViT-H模型[12 ] 提取图像特征,并通过Adapter策略[13 ] 将音频信息注入到预训练的SAM模型[14 ] 中,以实现视听融合. Wang等[15 ] 基于SAM模型,通过构建音频提示,并且调优参与跨模态注意力模块的上下文来构建视听相关性;Ma等[16 ] 基于Mask2Former架构[17 ] ,将视听分割结果用于辅助语义分割中的物体定位. 另外,许多方法[18 -20 ] 基于Transformer架构[21 ] ,通过将音频解耦为音频查询来实现实例级感知和识别. 例如,在AVSegFormer模型[20 ] 中,编码器负责挖掘对象的语义信息,查询生成器利用音频特征生成音频查询,解码器通过交叉注意力机制,利用音频查询来分离潜在对象. ...
2
... 为了解决上述问题,Zhou等[9 ] 提出时间像素级视听交互模块,注入音频语义来指导视觉分割过程. 一些方法基于基础模型实现视听分割. 例如,Yang等[10 ] 利用基础模型生成语义掩码,将其融入视觉特征中. Liu等[11 ] 使用冻结的ViT-H模型[12 ] 提取图像特征,并通过Adapter策略[13 ] 将音频信息注入到预训练的SAM模型[14 ] 中,以实现视听融合. Wang等[15 ] 基于SAM模型,通过构建音频提示,并且调优参与跨模态注意力模块的上下文来构建视听相关性;Ma等[16 ] 基于Mask2Former架构[17 ] ,将视听分割结果用于辅助语义分割中的物体定位. 另外,许多方法[18 -20 ] 基于Transformer架构[21 ] ,通过将音频解耦为音频查询来实现实例级感知和识别. 例如,在AVSegFormer模型[20 ] 中,编码器负责挖掘对象的语义信息,查询生成器利用音频特征生成音频查询,解码器通过交叉注意力机制,利用音频查询来分离潜在对象. ...
... 在以往的研究中,音频查询通常由音频特征独立获得,但这忽略了视觉信息对音频特征的重要作用[14 -15 ] . 特别是当场景中存在外形与声源物体相似的干扰物体时,仅依靠原始音频特征,模型难以准确建立查询与物体视觉特征之间的对应关系. 为了应对这一问题,采用COMBO框架[10 ] 中的双向注意力融合模块(bilateral-fusion module, BFM). 通过4个线性层将$ {{{\boldsymbol{P}}}_{{\text{loc}}}} $ $ {{\boldsymbol{F}}_{{\text{a}}}} $ $ {{\boldsymbol{Q}}} = {{{\boldsymbol{P}}}_{{\text{loc}}}}{{\boldsymbol{W}}_{\boldsymbol{Q}}} $ $ {{\boldsymbol{K}}} = {{\boldsymbol{F}}_{{\text{a}}}}{{\boldsymbol{W}}_K} $ $ {{{\boldsymbol{V}}}_{\text{v}}} = {{{\boldsymbol{P}}}_{{\text{loc}}}}{\boldsymbol{W}}_{\boldsymbol{V}}^{\text{v}} $ ${{{\boldsymbol{V}}}_{\text{a}}}{\text{ = }} $ $ {{\boldsymbol{F}}_{{\text{a}}}}{\boldsymbol{W}}_{\boldsymbol{V}}^{\text{a}} $ . 双向注意力的操作为 ...
2
... 为了解决上述问题,Zhou等[9 ] 提出时间像素级视听交互模块,注入音频语义来指导视觉分割过程. 一些方法基于基础模型实现视听分割. 例如,Yang等[10 ] 利用基础模型生成语义掩码,将其融入视觉特征中. Liu等[11 ] 使用冻结的ViT-H模型[12 ] 提取图像特征,并通过Adapter策略[13 ] 将音频信息注入到预训练的SAM模型[14 ] 中,以实现视听融合. Wang等[15 ] 基于SAM模型,通过构建音频提示,并且调优参与跨模态注意力模块的上下文来构建视听相关性;Ma等[16 ] 基于Mask2Former架构[17 ] ,将视听分割结果用于辅助语义分割中的物体定位. 另外,许多方法[18 -20 ] 基于Transformer架构[21 ] ,通过将音频解耦为音频查询来实现实例级感知和识别. 例如,在AVSegFormer模型[20 ] 中,编码器负责挖掘对象的语义信息,查询生成器利用音频特征生成音频查询,解码器通过交叉注意力机制,利用音频查询来分离潜在对象. ...
... 在以往的研究中,音频查询通常由音频特征独立获得,但这忽略了视觉信息对音频特征的重要作用[14 -15 ] . 特别是当场景中存在外形与声源物体相似的干扰物体时,仅依靠原始音频特征,模型难以准确建立查询与物体视觉特征之间的对应关系. 为了应对这一问题,采用COMBO框架[10 ] 中的双向注意力融合模块(bilateral-fusion module, BFM). 通过4个线性层将$ {{{\boldsymbol{P}}}_{{\text{loc}}}} $ $ {{\boldsymbol{F}}_{{\text{a}}}} $ $ {{\boldsymbol{Q}}} = {{{\boldsymbol{P}}}_{{\text{loc}}}}{{\boldsymbol{W}}_{\boldsymbol{Q}}} $ $ {{\boldsymbol{K}}} = {{\boldsymbol{F}}_{{\text{a}}}}{{\boldsymbol{W}}_K} $ $ {{{\boldsymbol{V}}}_{\text{v}}} = {{{\boldsymbol{P}}}_{{\text{loc}}}}{\boldsymbol{W}}_{\boldsymbol{V}}^{\text{v}} $ ${{{\boldsymbol{V}}}_{\text{a}}}{\text{ = }} $ $ {{\boldsymbol{F}}_{{\text{a}}}}{\boldsymbol{W}}_{\boldsymbol{V}}^{\text{a}} $ . 双向注意力的操作为 ...
1
... 为了解决上述问题,Zhou等[9 ] 提出时间像素级视听交互模块,注入音频语义来指导视觉分割过程. 一些方法基于基础模型实现视听分割. 例如,Yang等[10 ] 利用基础模型生成语义掩码,将其融入视觉特征中. Liu等[11 ] 使用冻结的ViT-H模型[12 ] 提取图像特征,并通过Adapter策略[13 ] 将音频信息注入到预训练的SAM模型[14 ] 中,以实现视听融合. Wang等[15 ] 基于SAM模型,通过构建音频提示,并且调优参与跨模态注意力模块的上下文来构建视听相关性;Ma等[16 ] 基于Mask2Former架构[17 ] ,将视听分割结果用于辅助语义分割中的物体定位. 另外,许多方法[18 -20 ] 基于Transformer架构[21 ] ,通过将音频解耦为音频查询来实现实例级感知和识别. 例如,在AVSegFormer模型[20 ] 中,编码器负责挖掘对象的语义信息,查询生成器利用音频特征生成音频查询,解码器通过交叉注意力机制,利用音频查询来分离潜在对象. ...
1
... 为了解决上述问题,Zhou等[9 ] 提出时间像素级视听交互模块,注入音频语义来指导视觉分割过程. 一些方法基于基础模型实现视听分割. 例如,Yang等[10 ] 利用基础模型生成语义掩码,将其融入视觉特征中. Liu等[11 ] 使用冻结的ViT-H模型[12 ] 提取图像特征,并通过Adapter策略[13 ] 将音频信息注入到预训练的SAM模型[14 ] 中,以实现视听融合. Wang等[15 ] 基于SAM模型,通过构建音频提示,并且调优参与跨模态注意力模块的上下文来构建视听相关性;Ma等[16 ] 基于Mask2Former架构[17 ] ,将视听分割结果用于辅助语义分割中的物体定位. 另外,许多方法[18 -20 ] 基于Transformer架构[21 ] ,通过将音频解耦为音频查询来实现实例级感知和识别. 例如,在AVSegFormer模型[20 ] 中,编码器负责挖掘对象的语义信息,查询生成器利用音频特征生成音频查询,解码器通过交叉注意力机制,利用音频查询来分离潜在对象. ...
1
... 为了解决上述问题,Zhou等[9 ] 提出时间像素级视听交互模块,注入音频语义来指导视觉分割过程. 一些方法基于基础模型实现视听分割. 例如,Yang等[10 ] 利用基础模型生成语义掩码,将其融入视觉特征中. Liu等[11 ] 使用冻结的ViT-H模型[12 ] 提取图像特征,并通过Adapter策略[13 ] 将音频信息注入到预训练的SAM模型[14 ] 中,以实现视听融合. Wang等[15 ] 基于SAM模型,通过构建音频提示,并且调优参与跨模态注意力模块的上下文来构建视听相关性;Ma等[16 ] 基于Mask2Former架构[17 ] ,将视听分割结果用于辅助语义分割中的物体定位. 另外,许多方法[18 -20 ] 基于Transformer架构[21 ] ,通过将音频解耦为音频查询来实现实例级感知和识别. 例如,在AVSegFormer模型[20 ] 中,编码器负责挖掘对象的语义信息,查询生成器利用音频特征生成音频查询,解码器通过交叉注意力机制,利用音频查询来分离潜在对象. ...
2
... 遵循文献方法[9 ,10 ,19 ,20 ,23 ] 的特征提取方式,图像编码器采用基于卷积的ResNet-50模型[24 ] 和基于视觉Transformer的PVT v2模型[25 ] ,音频编码器采用VGGish模型[26 ] . 不同的是,为了使用对比学习方法,需要重新组织输入,让不同视频的帧之间构成对比项. 给定一批包含B 个视频、每个视频有T 帧的视觉信息,该信息可以表示为$ {\boldsymbol{V}} \in {{\bf{R}}^{B \times T \times 3 \times H \times W}} $ H 和W 表示帧的大小;重新组织视觉信息为$ {\boldsymbol{V}} \in {{\bf{R}}^{T \times B \times 3 \times H \times W}} $ . 将每批数据分T 次输入到模型中,每次的输入为$ {{{\boldsymbol{V}}}_{{\text{input}}}} \in {{\bf{R}}^{B \times {\text{3}} \times H \times W}} $ B 个视频的帧之间构成对比项. 音频信息的组织方式同理. ...
... Performance comparison of SSL2AVS and existing AVS methods
Tab.2 方法 图像编码器 S4 MS3 $ {M_{\text{F}}} $ $ {M_{\text{J}}} $ $ {M_{\text{F}}} $ $ {M_{\text{J}}} $ AVSBench[9 ] ResNet-50 84.8 72.80 57.8 47.90 PVT v2 87.9 78.70 64.5 54.00 ECMVAE[23 ] ResNet-50 86.5 76.33 60.7 48.69 PVT v2 90.1 81.74 70.8 57.84 CATR[19 ] ResNet-50 86.6 74.80 65.3 52.80 PVT v2 89.6 81.40 70.0 59.00 AVSC[36 ] ResNet-50 85.2 77.02 61.5 49.58 PVT v2 88.2 80.57 65.1 58.22 AVS-UFE[32 ] ResNet-50 87.5 78.96 64.5 55.88 PVT v2 90.4 83.15 70.9 61.95 COMBO[10 ] ResNet-50 90.1 81.70 66.6 54.50 PVT v2 91.9 84.70 71.2 59.20 AVSegFormer[20 ] ResNet-50 85.9 76.45 62.8 49.53 PVT v2 89.9 82.06 69.3 58.36 SSL2AVS ResNet-50 86.8 77.16 66.9 56.18 PVT v2 90.3 82.42 72.3 62.15
由表1 可知,当以512×512的图像作为输入时,与AVSegFormer模型相比,SSL2AVS-R50*和SSL2AVS-PVTv2*的$ {M_{\text{J}}} $ $ {M_{\text{J}}} $ $ {M_{\text{J}}} $
6
... 为了解决上述问题,Zhou等[9 ] 提出时间像素级视听交互模块,注入音频语义来指导视觉分割过程. 一些方法基于基础模型实现视听分割. 例如,Yang等[10 ] 利用基础模型生成语义掩码,将其融入视觉特征中. Liu等[11 ] 使用冻结的ViT-H模型[12 ] 提取图像特征,并通过Adapter策略[13 ] 将音频信息注入到预训练的SAM模型[14 ] 中,以实现视听融合. Wang等[15 ] 基于SAM模型,通过构建音频提示,并且调优参与跨模态注意力模块的上下文来构建视听相关性;Ma等[16 ] 基于Mask2Former架构[17 ] ,将视听分割结果用于辅助语义分割中的物体定位. 另外,许多方法[18 -20 ] 基于Transformer架构[21 ] ,通过将音频解耦为音频查询来实现实例级感知和识别. 例如,在AVSegFormer模型[20 ] 中,编码器负责挖掘对象的语义信息,查询生成器利用音频特征生成音频查询,解码器通过交叉注意力机制,利用音频查询来分离潜在对象. ...
... [20 ]中,编码器负责挖掘对象的语义信息,查询生成器利用音频特征生成音频查询,解码器通过交叉注意力机制,利用音频查询来分离潜在对象. ...
... 遵循文献方法[9 ,10 ,19 ,20 ,23 ] 的特征提取方式,图像编码器采用基于卷积的ResNet-50模型[24 ] 和基于视觉Transformer的PVT v2模型[25 ] ,音频编码器采用VGGish模型[26 ] . 不同的是,为了使用对比学习方法,需要重新组织输入,让不同视频的帧之间构成对比项. 给定一批包含B 个视频、每个视频有T 帧的视觉信息,该信息可以表示为$ {\boldsymbol{V}} \in {{\bf{R}}^{B \times T \times 3 \times H \times W}} $ H 和W 表示帧的大小;重新组织视觉信息为$ {\boldsymbol{V}} \in {{\bf{R}}^{T \times B \times 3 \times H \times W}} $ . 将每批数据分T 次输入到模型中,每次的输入为$ {{{\boldsymbol{V}}}_{{\text{input}}}} \in {{\bf{R}}^{B \times {\text{3}} \times H \times W}} $ B 个视频的帧之间构成对比项. 音频信息的组织方式同理. ...
... 多阶段特征融合器融合多个来源的视觉特征,并利用注意力机制将融合后的视觉特征与$ {{\boldsymbol{F}}'_{{\text{a}}}} $ α 将$ {{{\boldsymbol{P}}}_{{\text{fuse}}}} $ $ {{{\boldsymbol{P}}}_1} $ $ {{{\boldsymbol{P}}}_1} $ $ {{\boldsymbol{P}}'_1} $ . 接着,将$ {{\boldsymbol{P}}'_1} $ $ {{\boldsymbol{P}}'_2} $ $ {{\boldsymbol{F}}_{{\text{mask}}}} $ . 最后,利用通道注意力(channel attention, CHA)[20 ] 选择性地缩放不同的视觉通道,提高模型捕捉复杂视听关系的能力,这是从通道角度对视觉特征的增强. 整个过程可以表示为 ...
... 和文献[9 ]、[20 ]、[32 ]一样,本研究使用均交并比(mean Intersection-over-Union, mIoU)和F1分数(F-score)作为评价指标,分别用$ {M_{\text{J}}} $ $ {M_{\mathrm{F}}} $
... Performance comparison of SSL2AVS and existing AVS methods
Tab.2 方法 图像编码器 S4 MS3 $ {M_{\text{F}}} $ $ {M_{\text{J}}} $ $ {M_{\text{F}}} $ $ {M_{\text{J}}} $ AVSBench[9 ] ResNet-50 84.8 72.80 57.8 47.90 PVT v2 87.9 78.70 64.5 54.00 ECMVAE[23 ] ResNet-50 86.5 76.33 60.7 48.69 PVT v2 90.1 81.74 70.8 57.84 CATR[19 ] ResNet-50 86.6 74.80 65.3 52.80 PVT v2 89.6 81.40 70.0 59.00 AVSC[36 ] ResNet-50 85.2 77.02 61.5 49.58 PVT v2 88.2 80.57 65.1 58.22 AVS-UFE[32 ] ResNet-50 87.5 78.96 64.5 55.88 PVT v2 90.4 83.15 70.9 61.95 COMBO[10 ] ResNet-50 90.1 81.70 66.6 54.50 PVT v2 91.9 84.70 71.2 59.20 AVSegFormer[20 ] ResNet-50 85.9 76.45 62.8 49.53 PVT v2 89.9 82.06 69.3 58.36 SSL2AVS ResNet-50 86.8 77.16 66.9 56.18 PVT v2 90.3 82.42 72.3 62.15
由表1 可知,当以512×512的图像作为输入时,与AVSegFormer模型相比,SSL2AVS-R50*和SSL2AVS-PVTv2*的$ {M_{\text{J}}} $ $ {M_{\text{J}}} $ $ {M_{\text{J}}} $
1
... 为了解决上述问题,Zhou等[9 ] 提出时间像素级视听交互模块,注入音频语义来指导视觉分割过程. 一些方法基于基础模型实现视听分割. 例如,Yang等[10 ] 利用基础模型生成语义掩码,将其融入视觉特征中. Liu等[11 ] 使用冻结的ViT-H模型[12 ] 提取图像特征,并通过Adapter策略[13 ] 将音频信息注入到预训练的SAM模型[14 ] 中,以实现视听融合. Wang等[15 ] 基于SAM模型,通过构建音频提示,并且调优参与跨模态注意力模块的上下文来构建视听相关性;Ma等[16 ] 基于Mask2Former架构[17 ] ,将视听分割结果用于辅助语义分割中的物体定位. 另外,许多方法[18 -20 ] 基于Transformer架构[21 ] ,通过将音频解耦为音频查询来实现实例级感知和识别. 例如,在AVSegFormer模型[20 ] 中,编码器负责挖掘对象的语义信息,查询生成器利用音频特征生成音频查询,解码器通过交叉注意力机制,利用音频查询来分离潜在对象. ...
1
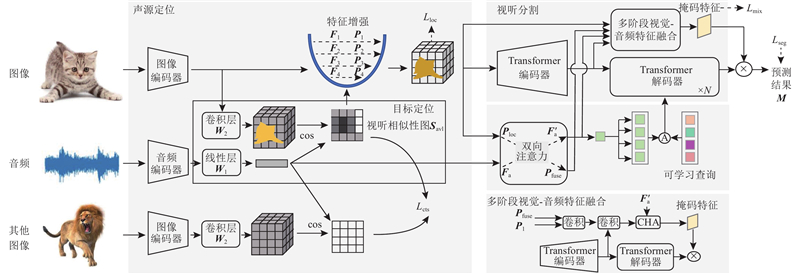
... 考虑到声源定位结果有助于聚焦潜在的声源物体,将声源定位结果用于引导视听分割,以解决AVS任务中由背景噪声干扰导致的分割不明确的问题. 提出的基于对比学习的声源定位引导视听分割(sound source localization-guided audio-visual segmentation, SSL2AVS)模型包含2个阶段[22 ] :先进行声源粗定位,优化视觉特征,再进行视听分割. 第1阶段包含目标定位和特征增强2个模块,其中目标定位模块生成定位结果,特征增强模块利用定位结果优化视觉特征;2个模块共同作用以减少背景噪声干扰. 提出辅助定位损失函数以监督第1阶段产生的视觉特征,鼓励模型关注与音频特征更相似的图像区域,从而优化粗定位结果. 在解码分割前,利用双向注意力模块实现进一步的跨模态交互,以提高音视觉信号之间的交互敏感性. 定位引导特征增强的策略仅引入少量参数,却显著提升了分割效果,有助于模型更好地拟合. ...
2
... 遵循文献方法[9 ,10 ,19 ,20 ,23 ] 的特征提取方式,图像编码器采用基于卷积的ResNet-50模型[24 ] 和基于视觉Transformer的PVT v2模型[25 ] ,音频编码器采用VGGish模型[26 ] . 不同的是,为了使用对比学习方法,需要重新组织输入,让不同视频的帧之间构成对比项. 给定一批包含B 个视频、每个视频有T 帧的视觉信息,该信息可以表示为$ {\boldsymbol{V}} \in {{\bf{R}}^{B \times T \times 3 \times H \times W}} $ H 和W 表示帧的大小;重新组织视觉信息为$ {\boldsymbol{V}} \in {{\bf{R}}^{T \times B \times 3 \times H \times W}} $ . 将每批数据分T 次输入到模型中,每次的输入为$ {{{\boldsymbol{V}}}_{{\text{input}}}} \in {{\bf{R}}^{B \times {\text{3}} \times H \times W}} $ B 个视频的帧之间构成对比项. 音频信息的组织方式同理. ...
... Performance comparison of SSL2AVS and existing AVS methods
Tab.2 方法 图像编码器 S4 MS3 $ {M_{\text{F}}} $ $ {M_{\text{J}}} $ $ {M_{\text{F}}} $ $ {M_{\text{J}}} $ AVSBench[9 ] ResNet-50 84.8 72.80 57.8 47.90 PVT v2 87.9 78.70 64.5 54.00 ECMVAE[23 ] ResNet-50 86.5 76.33 60.7 48.69 PVT v2 90.1 81.74 70.8 57.84 CATR[19 ] ResNet-50 86.6 74.80 65.3 52.80 PVT v2 89.6 81.40 70.0 59.00 AVSC[36 ] ResNet-50 85.2 77.02 61.5 49.58 PVT v2 88.2 80.57 65.1 58.22 AVS-UFE[32 ] ResNet-50 87.5 78.96 64.5 55.88 PVT v2 90.4 83.15 70.9 61.95 COMBO[10 ] ResNet-50 90.1 81.70 66.6 54.50 PVT v2 91.9 84.70 71.2 59.20 AVSegFormer[20 ] ResNet-50 85.9 76.45 62.8 49.53 PVT v2 89.9 82.06 69.3 58.36 SSL2AVS ResNet-50 86.8 77.16 66.9 56.18 PVT v2 90.3 82.42 72.3 62.15
由表1 可知,当以512×512的图像作为输入时,与AVSegFormer模型相比,SSL2AVS-R50*和SSL2AVS-PVTv2*的$ {M_{\text{J}}} $ $ {M_{\text{J}}} $ $ {M_{\text{J}}} $
1
... 遵循文献方法[9 ,10 ,19 ,20 ,23 ] 的特征提取方式,图像编码器采用基于卷积的ResNet-50模型[24 ] 和基于视觉Transformer的PVT v2模型[25 ] ,音频编码器采用VGGish模型[26 ] . 不同的是,为了使用对比学习方法,需要重新组织输入,让不同视频的帧之间构成对比项. 给定一批包含B 个视频、每个视频有T 帧的视觉信息,该信息可以表示为$ {\boldsymbol{V}} \in {{\bf{R}}^{B \times T \times 3 \times H \times W}} $ H 和W 表示帧的大小;重新组织视觉信息为$ {\boldsymbol{V}} \in {{\bf{R}}^{T \times B \times 3 \times H \times W}} $ . 将每批数据分T 次输入到模型中,每次的输入为$ {{{\boldsymbol{V}}}_{{\text{input}}}} \in {{\bf{R}}^{B \times {\text{3}} \times H \times W}} $ B 个视频的帧之间构成对比项. 音频信息的组织方式同理. ...
PVT v2: improved baselines with pyramid vision Transformer
1
2022
... 遵循文献方法[9 ,10 ,19 ,20 ,23 ] 的特征提取方式,图像编码器采用基于卷积的ResNet-50模型[24 ] 和基于视觉Transformer的PVT v2模型[25 ] ,音频编码器采用VGGish模型[26 ] . 不同的是,为了使用对比学习方法,需要重新组织输入,让不同视频的帧之间构成对比项. 给定一批包含B 个视频、每个视频有T 帧的视觉信息,该信息可以表示为$ {\boldsymbol{V}} \in {{\bf{R}}^{B \times T \times 3 \times H \times W}} $ H 和W 表示帧的大小;重新组织视觉信息为$ {\boldsymbol{V}} \in {{\bf{R}}^{T \times B \times 3 \times H \times W}} $ . 将每批数据分T 次输入到模型中,每次的输入为$ {{{\boldsymbol{V}}}_{{\text{input}}}} \in {{\bf{R}}^{B \times {\text{3}} \times H \times W}} $ B 个视频的帧之间构成对比项. 音频信息的组织方式同理. ...
2
... 遵循文献方法[9 ,10 ,19 ,20 ,23 ] 的特征提取方式,图像编码器采用基于卷积的ResNet-50模型[24 ] 和基于视觉Transformer的PVT v2模型[25 ] ,音频编码器采用VGGish模型[26 ] . 不同的是,为了使用对比学习方法,需要重新组织输入,让不同视频的帧之间构成对比项. 给定一批包含B 个视频、每个视频有T 帧的视觉信息,该信息可以表示为$ {\boldsymbol{V}} \in {{\bf{R}}^{B \times T \times 3 \times H \times W}} $ H 和W 表示帧的大小;重新组织视觉信息为$ {\boldsymbol{V}} \in {{\bf{R}}^{T \times B \times 3 \times H \times W}} $ . 将每批数据分T 次输入到模型中,每次的输入为$ {{{\boldsymbol{V}}}_{{\text{input}}}} \in {{\bf{R}}^{B \times {\text{3}} \times H \times W}} $ B 个视频的帧之间构成对比项. 音频信息的组织方式同理. ...
... 实验使用的GPU型号为NVIDIA 3090 ,深度学习框架为PyTorch 1.10.0版本,CUDA运行环境为11.1版. SSL2AVS模型在S4和MS3子集上训练时的迭代次数分别为30和60,批次大小为4,使用的优化器为AdamW[33 ] ,初始学习率为$ 2 \times {10^{ - 5}} $ [34 ] 上预训练的ResNet-50或PVT v2图像编码器提取视觉特征,使用在AudioSet[35 ] 上预训练的VGGish[26 ] 音频编码器提取音频特征. Transformer编码器和解码器的层数为6,嵌入维度为256. 损失系数$ {\lambda _1} $ $ {\lambda _2} $ $ {\lambda _3} $
1
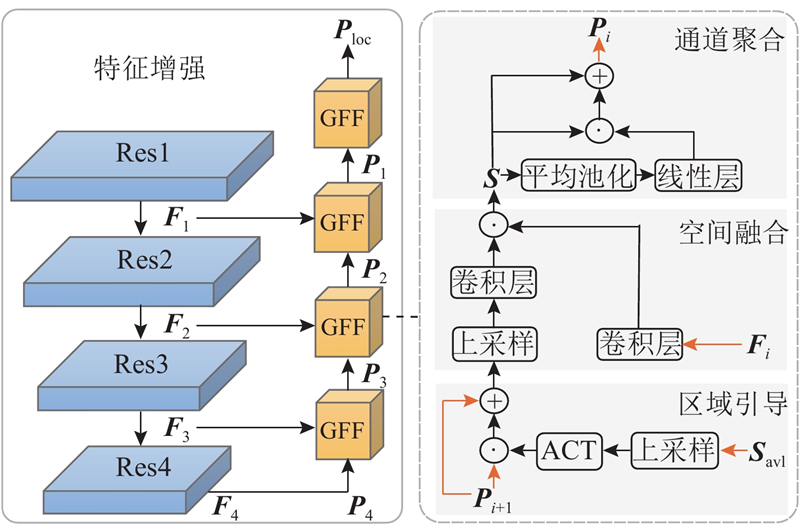
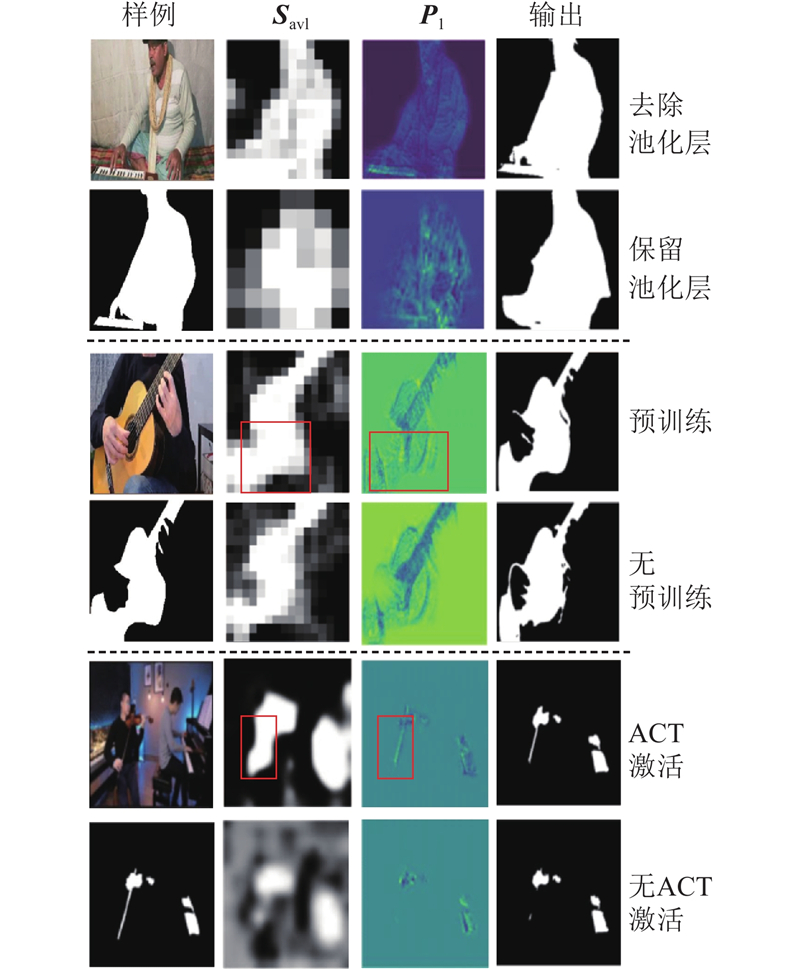
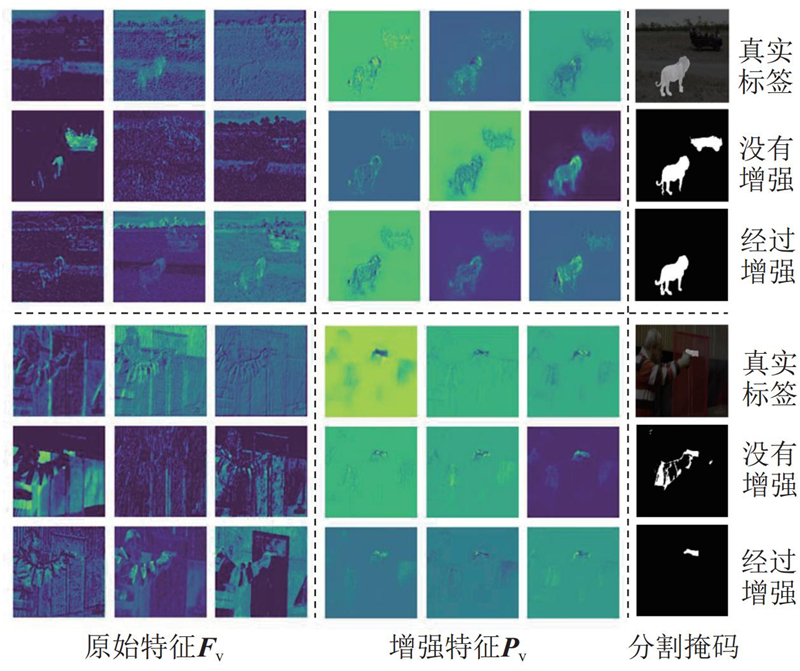
... 特征增强策略因其融合多尺度特征、利用上下文信息中丰富的区域或通道特征的能力被广泛应用于目标分割领域. 原始视觉特征$ {{\boldsymbol{F}}_{{\text{v}}}} = \left\{ {{{\boldsymbol{F}}_1},{{\boldsymbol{F}}_2},{{\boldsymbol{F}}_3},{{\boldsymbol{F}}_4}} \right\} $ 图2 所示,该模块包含一系列的上采样过程,生成优化后的视觉特征$ {\boldsymbol{P}}_{{\mathrm{v}}}=\{{\boldsymbol{P}}_{1},{\boldsymbol{P}}_{2},{\boldsymbol{P}}_{3},{\boldsymbol{P}}_{4}\} $ $ {{{\boldsymbol{P}}}_{{\text{loc}}}} $ $ {{{\boldsymbol{P}}}_i} \in {{\bf{R}}^{B \times {C_i} \times {H_i} \times {{\boldsymbol{W}}_i}}} $ $ {{{\boldsymbol{P}}}_4} = {{\boldsymbol{F}}_4} $ . 不同于U-Net模型[27 ] 直接使用跳跃连接进行融合,本研究开发引导式特征融合(guided feature fusion, GFF)方法. 该方法具体包含3个步骤:区域引导、空间融合[28 -29 ] 和通道聚合[30 ] . ...
1
... 特征增强策略因其融合多尺度特征、利用上下文信息中丰富的区域或通道特征的能力被广泛应用于目标分割领域. 原始视觉特征$ {{\boldsymbol{F}}_{{\text{v}}}} = \left\{ {{{\boldsymbol{F}}_1},{{\boldsymbol{F}}_2},{{\boldsymbol{F}}_3},{{\boldsymbol{F}}_4}} \right\} $ 图2 所示,该模块包含一系列的上采样过程,生成优化后的视觉特征$ {\boldsymbol{P}}_{{\mathrm{v}}}=\{{\boldsymbol{P}}_{1},{\boldsymbol{P}}_{2},{\boldsymbol{P}}_{3},{\boldsymbol{P}}_{4}\} $ $ {{{\boldsymbol{P}}}_{{\text{loc}}}} $ $ {{{\boldsymbol{P}}}_i} \in {{\bf{R}}^{B \times {C_i} \times {H_i} \times {{\boldsymbol{W}}_i}}} $ $ {{{\boldsymbol{P}}}_4} = {{\boldsymbol{F}}_4} $ . 不同于U-Net模型[27 ] 直接使用跳跃连接进行融合,本研究开发引导式特征融合(guided feature fusion, GFF)方法. 该方法具体包含3个步骤:区域引导、空间融合[28 -29 ] 和通道聚合[30 ] . ...
Motion-aware memory network for fast video salient object detection
1
2024
... 特征增强策略因其融合多尺度特征、利用上下文信息中丰富的区域或通道特征的能力被广泛应用于目标分割领域. 原始视觉特征$ {{\boldsymbol{F}}_{{\text{v}}}} = \left\{ {{{\boldsymbol{F}}_1},{{\boldsymbol{F}}_2},{{\boldsymbol{F}}_3},{{\boldsymbol{F}}_4}} \right\} $ 图2 所示,该模块包含一系列的上采样过程,生成优化后的视觉特征$ {\boldsymbol{P}}_{{\mathrm{v}}}=\{{\boldsymbol{P}}_{1},{\boldsymbol{P}}_{2},{\boldsymbol{P}}_{3},{\boldsymbol{P}}_{4}\} $ $ {{{\boldsymbol{P}}}_{{\text{loc}}}} $ $ {{{\boldsymbol{P}}}_i} \in {{\bf{R}}^{B \times {C_i} \times {H_i} \times {{\boldsymbol{W}}_i}}} $ $ {{{\boldsymbol{P}}}_4} = {{\boldsymbol{F}}_4} $ . 不同于U-Net模型[27 ] 直接使用跳跃连接进行融合,本研究开发引导式特征融合(guided feature fusion, GFF)方法. 该方法具体包含3个步骤:区域引导、空间融合[28 -29 ] 和通道聚合[30 ] . ...
1
... 特征增强策略因其融合多尺度特征、利用上下文信息中丰富的区域或通道特征的能力被广泛应用于目标分割领域. 原始视觉特征$ {{\boldsymbol{F}}_{{\text{v}}}} = \left\{ {{{\boldsymbol{F}}_1},{{\boldsymbol{F}}_2},{{\boldsymbol{F}}_3},{{\boldsymbol{F}}_4}} \right\} $ 图2 所示,该模块包含一系列的上采样过程,生成优化后的视觉特征$ {\boldsymbol{P}}_{{\mathrm{v}}}=\{{\boldsymbol{P}}_{1},{\boldsymbol{P}}_{2},{\boldsymbol{P}}_{3},{\boldsymbol{P}}_{4}\} $ $ {{{\boldsymbol{P}}}_{{\text{loc}}}} $ $ {{{\boldsymbol{P}}}_i} \in {{\bf{R}}^{B \times {C_i} \times {H_i} \times {{\boldsymbol{W}}_i}}} $ $ {{{\boldsymbol{P}}}_4} = {{\boldsymbol{F}}_4} $ . 不同于U-Net模型[27 ] 直接使用跳跃连接进行融合,本研究开发引导式特征融合(guided feature fusion, GFF)方法. 该方法具体包含3个步骤:区域引导、空间融合[28 -29 ] 和通道聚合[30 ] . ...
1
... 随着定位生成和特征增强过程的引入,模型在初步对齐音视频语义和定位声源物体方面取得了良好的效果,但是在面对复杂场景时,存在语义混淆问题,导致鲁棒性不足. 因此采用定位损失$ {L_{{\text{loc}}}} $ $ {{\boldsymbol{P}}_{{\text{loc}}}} $ . 将$ {{\boldsymbol{P}}_{{\text{loc}}}} $ $ {{\boldsymbol{T}}} $ [31 ] ,以确保声源物体所在区域拥有更高的响应值而背景区域有较低的响应值. 定位损失$ {L_{{\text{loc}}}} $
2
... 和文献[9 ]、[20 ]、[32 ]一样,本研究使用均交并比(mean Intersection-over-Union, mIoU)和F1分数(F-score)作为评价指标,分别用$ {M_{\text{J}}} $ $ {M_{\mathrm{F}}} $
... Performance comparison of SSL2AVS and existing AVS methods
Tab.2 方法 图像编码器 S4 MS3 $ {M_{\text{F}}} $ $ {M_{\text{J}}} $ $ {M_{\text{F}}} $ $ {M_{\text{J}}} $ AVSBench[9 ] ResNet-50 84.8 72.80 57.8 47.90 PVT v2 87.9 78.70 64.5 54.00 ECMVAE[23 ] ResNet-50 86.5 76.33 60.7 48.69 PVT v2 90.1 81.74 70.8 57.84 CATR[19 ] ResNet-50 86.6 74.80 65.3 52.80 PVT v2 89.6 81.40 70.0 59.00 AVSC[36 ] ResNet-50 85.2 77.02 61.5 49.58 PVT v2 88.2 80.57 65.1 58.22 AVS-UFE[32 ] ResNet-50 87.5 78.96 64.5 55.88 PVT v2 90.4 83.15 70.9 61.95 COMBO[10 ] ResNet-50 90.1 81.70 66.6 54.50 PVT v2 91.9 84.70 71.2 59.20 AVSegFormer[20 ] ResNet-50 85.9 76.45 62.8 49.53 PVT v2 89.9 82.06 69.3 58.36 SSL2AVS ResNet-50 86.8 77.16 66.9 56.18 PVT v2 90.3 82.42 72.3 62.15
由表1 可知,当以512×512的图像作为输入时,与AVSegFormer模型相比,SSL2AVS-R50*和SSL2AVS-PVTv2*的$ {M_{\text{J}}} $ $ {M_{\text{J}}} $ $ {M_{\text{J}}} $
1
... 实验使用的GPU型号为NVIDIA 3090 ,深度学习框架为PyTorch 1.10.0版本,CUDA运行环境为11.1版. SSL2AVS模型在S4和MS3子集上训练时的迭代次数分别为30和60,批次大小为4,使用的优化器为AdamW[33 ] ,初始学习率为$ 2 \times {10^{ - 5}} $ [34 ] 上预训练的ResNet-50或PVT v2图像编码器提取视觉特征,使用在AudioSet[35 ] 上预训练的VGGish[26 ] 音频编码器提取音频特征. Transformer编码器和解码器的层数为6,嵌入维度为256. 损失系数$ {\lambda _1} $ $ {\lambda _2} $ $ {\lambda _3} $
1
... 实验使用的GPU型号为NVIDIA 3090 ,深度学习框架为PyTorch 1.10.0版本,CUDA运行环境为11.1版. SSL2AVS模型在S4和MS3子集上训练时的迭代次数分别为30和60,批次大小为4,使用的优化器为AdamW[33 ] ,初始学习率为$ 2 \times {10^{ - 5}} $ [34 ] 上预训练的ResNet-50或PVT v2图像编码器提取视觉特征,使用在AudioSet[35 ] 上预训练的VGGish[26 ] 音频编码器提取音频特征. Transformer编码器和解码器的层数为6,嵌入维度为256. 损失系数$ {\lambda _1} $ $ {\lambda _2} $ $ {\lambda _3} $
1
... 实验使用的GPU型号为NVIDIA 3090 ,深度学习框架为PyTorch 1.10.0版本,CUDA运行环境为11.1版. SSL2AVS模型在S4和MS3子集上训练时的迭代次数分别为30和60,批次大小为4,使用的优化器为AdamW[33 ] ,初始学习率为$ 2 \times {10^{ - 5}} $ [34 ] 上预训练的ResNet-50或PVT v2图像编码器提取视觉特征,使用在AudioSet[35 ] 上预训练的VGGish[26 ] 音频编码器提取音频特征. Transformer编码器和解码器的层数为6,嵌入维度为256. 损失系数$ {\lambda _1} $ $ {\lambda _2} $ $ {\lambda _3} $
1
... Performance comparison of SSL2AVS and existing AVS methods
Tab.2 方法 图像编码器 S4 MS3 $ {M_{\text{F}}} $ $ {M_{\text{J}}} $ $ {M_{\text{F}}} $ $ {M_{\text{J}}} $ AVSBench[9 ] ResNet-50 84.8 72.80 57.8 47.90 PVT v2 87.9 78.70 64.5 54.00 ECMVAE[23 ] ResNet-50 86.5 76.33 60.7 48.69 PVT v2 90.1 81.74 70.8 57.84 CATR[19 ] ResNet-50 86.6 74.80 65.3 52.80 PVT v2 89.6 81.40 70.0 59.00 AVSC[36 ] ResNet-50 85.2 77.02 61.5 49.58 PVT v2 88.2 80.57 65.1 58.22 AVS-UFE[32 ] ResNet-50 87.5 78.96 64.5 55.88 PVT v2 90.4 83.15 70.9 61.95 COMBO[10 ] ResNet-50 90.1 81.70 66.6 54.50 PVT v2 91.9 84.70 71.2 59.20 AVSegFormer[20 ] ResNet-50 85.9 76.45 62.8 49.53 PVT v2 89.9 82.06 69.3 58.36 SSL2AVS ResNet-50 86.8 77.16 66.9 56.18 PVT v2 90.3 82.42 72.3 62.15
由表1 可知,当以512×512的图像作为输入时,与AVSegFormer模型相比,SSL2AVS-R50*和SSL2AVS-PVTv2*的$ {M_{\text{J}}} $ $ {M_{\text{J}}} $ $ {M_{\text{J}}} $




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}