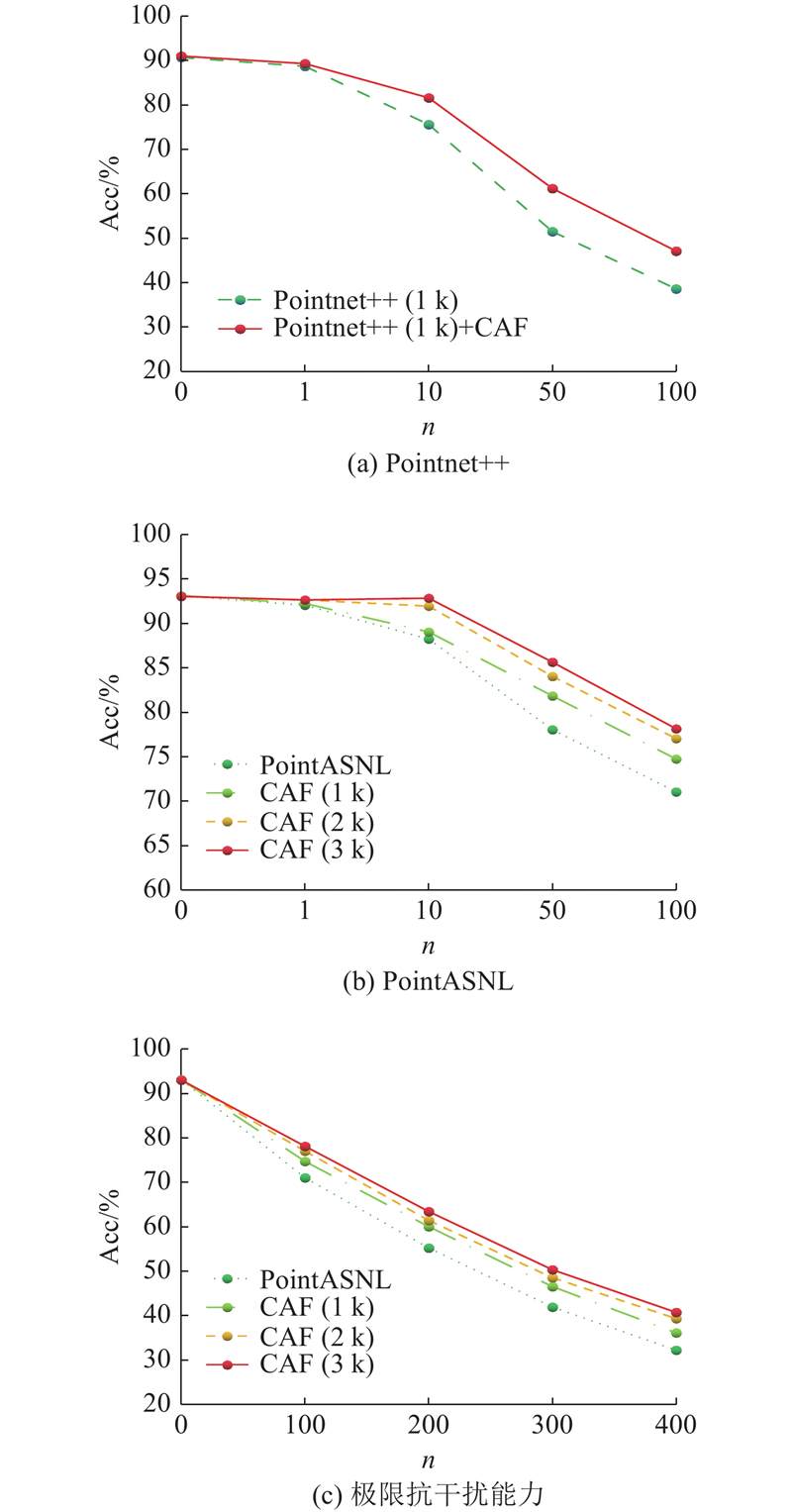
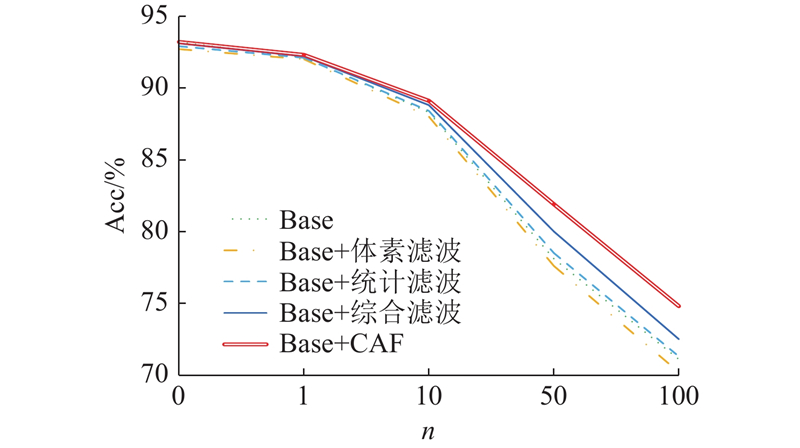
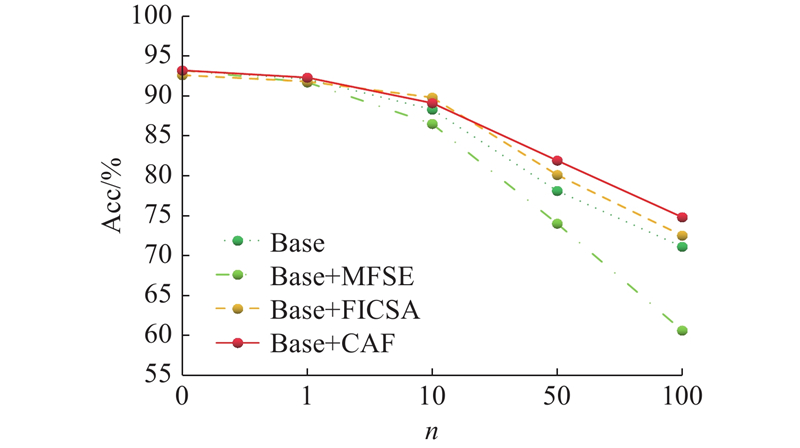
| 计算机技术 |
|


|
|
|
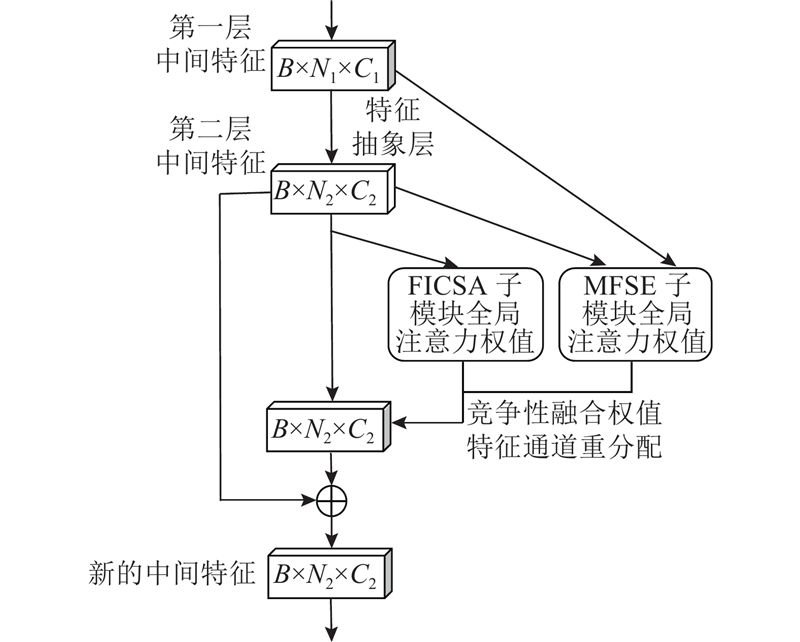
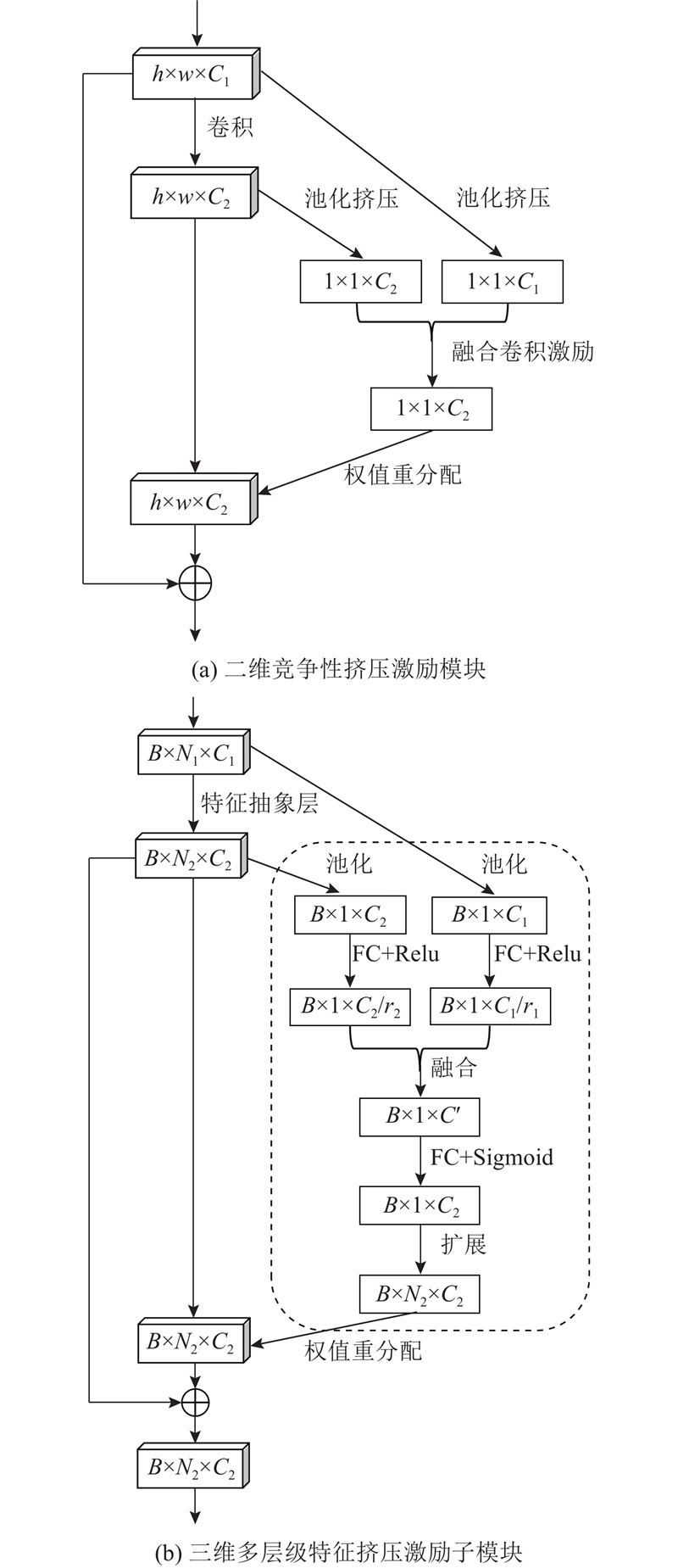
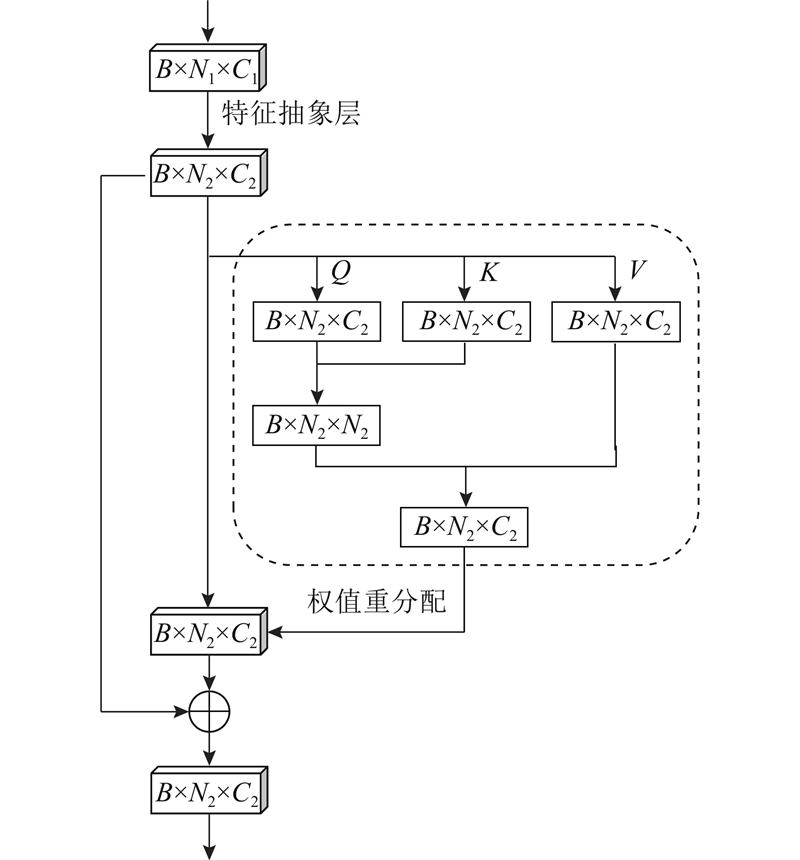
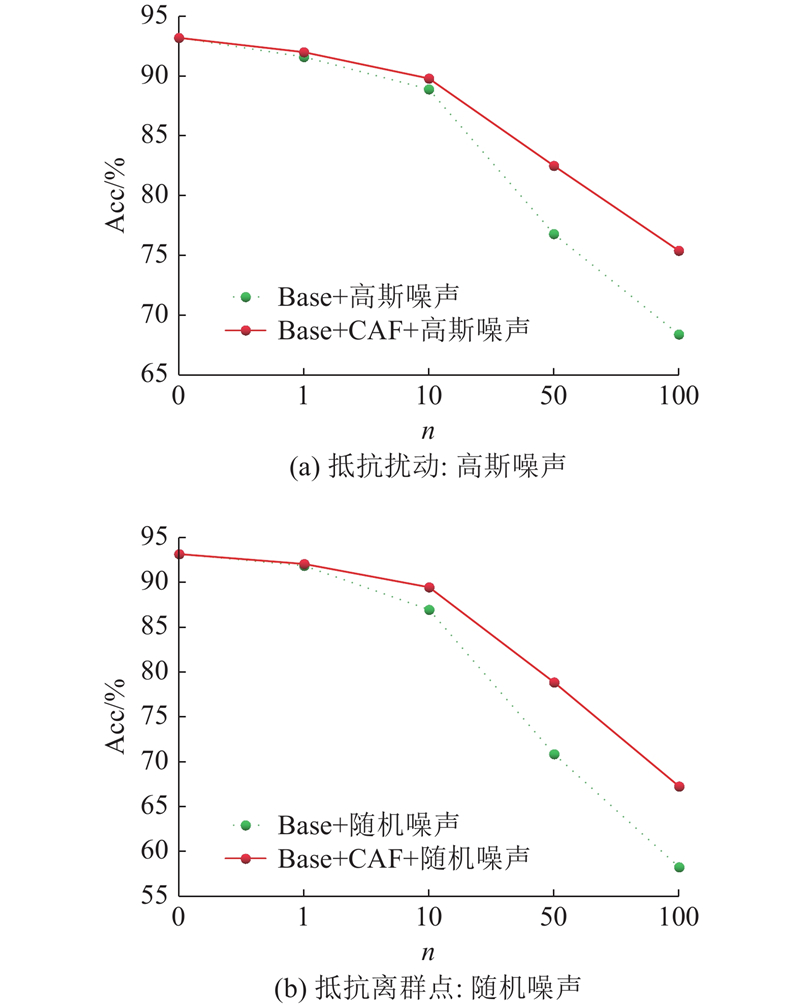
| 基于竞争注意力融合的深度三维点云分类网络 |
陈涵娟1,2( ),达飞鹏1,2,3,*(),盖绍彦1,2 ),达飞鹏1,2,3,*(),盖绍彦1,2 |
1. 东南大学 自动化学院,江苏 南京 210096
2. 东南大学 复杂工程系统测量与控制教育部重点实验室,江苏 南京 210096
3. 东南大学 深圳研究院,广东 深圳 518063 |
|
| Deep 3D point cloud classification network based on competitive attention fusion |
| Han-juan CHEN1,2(),Fei-peng DA1,2,3,*(),Shao-yan GAI1,2 |
1. School of Automation, Southeast University, Nanjing 210096, China
2. Key Laboratory of Measurement and Control of Complex Systems of Engineering, Ministry of Education, Southeast University, Nanjing 210096, China
3. Shenzhen Research Institute, Southeast University, Shenzhen 518063, China |
| 1 |
BU S, LIU Z, HAN J, et al Learning high-level feature by deep belief networks for 3-D model retrieval and recognition[J]. IEEE Transactions on Multimedia, 2014, 16 (8): 2154- 2167
doi: 10.1109/TMM.2014.2351788
|
| 2 |
SU H, MAJI S, KALOGERAKIS E, et al. Multi-view convolutional neural networks for 3D shape recognition [C]// 2015 IEEE International Conference on Computer Vision. Santiago: IEEE, 2015: 945-953.
|
| 3 |
WU Z, SONG S, KHOSLA A, et al. 3D shapeNets: a deep representation for volumetric shapes [C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 1912-1920.
|
| 4 |
QI C R, SU H, MO K, et al. PointNet: deep learning on point sets for 3D classification and segmentation [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 77-85.
|
| 5 |
QI C R, YI L, SU H, et al. PointNet++: deep hierarchical feature learning on point sets in a metric space [C]// Advances in Neural Information Processing Systems. Long Beach: MIT Press, 2017: 5099-5108.
|
| 6 |
GUERRERO P, KLEIMAN Y, OVSJANIKOV M, et al PCPNET learning local shape properties from raw point clouds[J]. Computer Graphics Forum, 2018, 37 (2): 75- 85
doi: 10.1111/cgf.13343
|
| 7 |
SHEN Y, FENG C, YANG Y, et al. Mining point cloud local structures by kernel correlation and graph pooling [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 4548-4557.
|
| 8 |
LI J, CHEN B M, LEE G H. SO-Net: self-organizing network for point cloud analysis [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 9397-9406.
|
| 9 |
QI C R, LIU W, WU C, et al. Frustum PointNets for 3D object detection from RGB-D data [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 918-927.
|
| 10 |
LI Y, BU R, SUN M, et al. PointCNN: convolution on Χ-transformed points [C]// Advances in Neural Information Processing Systems. Montreal: MIT Press, 2018: 828-838.
|
| 11 |
LIU Y, FAN B, MENG G, et al. DensePoint: learning densely contextual representation for efficient point cloud processing [C]// 2019 IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 5238-5247.
|
| 12 |
LIU X, HAN Z, LIU Y S, et al. Point2Sequence: learning the shape representation of 3D point clouds with an attention-based sequence to sequence network [C]// Proceedings of the AAAI conference on Artificial Intelligence. Honolulu: AAAI, 2019: 8778-8785.
|
| 13 |
KOMARICHEV A, ZHONG Z, HUA J. A-CNN: annularly convolutional neural networks on point clouds [C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 7413-7422.
|
| 14 |
ZHAO H, JIANG L, FU C W, et al. PointWeb: enhancing local neighborhood features for point cloud processing [C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 5560-5568.
|
| 15 |
WANG C, SAMARI B, SIDDIQI K. Local spectral graph convolution for point set feature learning [C]// 15th European Conference on Computer Vision. Munich: Springer, 2018: 56-71.
|
| 16 |
TE G, HU W, GUO Z, et al. RGCNN: regularized graph CNN for point cloud segmentation [C]// Proceedings of the 26th ACM international conference on Multimedia. Seoul: ACM, 2018: 746-754.
|
| 17 |
LANDRIEU L, SIMONOVSKY M. Large-scale point cloud semantic segmentation with superpoint graphs [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 4558-4567.
|
| 18 |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Advances in Neural Information Processing Systems. Long Beach: MIT Press, 2017: 5998-6008.
|
| 19 |
HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 7132-7141.
|
| 20 |
YOU H, FENG Y, JI R, et al. PVNet: a joint convolutional network of point cloud and multi-view for 3D shape recognition [C]// Proceedings of the 26th ACM international conference on Multimedia. Seoul: ACM, 2018: 1310-1318.
|
| 21 |
YAN X, ZHENG C, LI Z, et al. PointASNL: robust point clouds processing using nonlocal neural networks with adaptive sampling [C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 5588-5597.
|
| 22 |
HU Y, WEN G, LUO M, et al. Competitive inner-imaging squeeze and excitation for residual network [EB/OL]. (2018-12-23)[2020-12-29]. https://arxiv.org/abs/1807.08920.
|
| 23 |
YI L, KIM V G, CEYLAN D, et al A scalable active framework for region annotation in 3D shape collections[J]. ACM Transactions on Graphics, 2016, 35 (6): 210
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|