[1]
BU S, LIU Z, HAN J, et al Learning high-level feature by deep belief networks for 3-D model retrieval and recognition
[J]. IEEE Transactions on Multimedia , 2014 , 16 (8 ): 2154 - 2167
DOI:10.1109/TMM.2014.2351788
[本文引用: 1]
[2]
SU H, MAJI S, KALOGERAKIS E, et al. Multi-view convolutional neural networks for 3D shape recognition [C]// 2015 IEEE International Conference on Computer Vision . Santiago: IEEE, 2015: 945-953.
[本文引用: 1]
[3]
WU Z, SONG S, KHOSLA A, et al. 3D shapeNets: a deep representation for volumetric shapes [C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 1912-1920.
[本文引用: 2]
[4]
QI C R, SU H, MO K, et al. PointNet: deep learning on point sets for 3D classification and segmentation [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 77-85.
[本文引用: 5]
[5]
QI C R, YI L, SU H, et al. PointNet++: deep hierarchical feature learning on point sets in a metric space [C]// Advances in Neural Information Processing Systems . Long Beach: MIT Press, 2017: 5099-5108.
[本文引用: 6]
[6]
GUERRERO P, KLEIMAN Y, OVSJANIKOV M, et al PCPNET learning local shape properties from raw point clouds
[J]. Computer Graphics Forum , 2018 , 37 (2 ): 75 - 85
DOI:10.1111/cgf.13343
[本文引用: 1]
[7]
SHEN Y, FENG C, YANG Y, et al. Mining point cloud local structures by kernel correlation and graph pooling [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 4548-4557.
[本文引用: 2]
[8]
LI J, CHEN B M, LEE G H. SO-Net: self-organizing network for point cloud analysis [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 9397-9406.
[本文引用: 3]
[9]
QI C R, LIU W, WU C, et al. Frustum PointNets for 3D object detection from RGB-D data [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 918-927.
[本文引用: 1]
[10]
LI Y, BU R, SUN M, et al. PointCNN: convolution on Χ-transformed points [C]// Advances in Neural Information Processing Systems . Montreal: MIT Press, 2018: 828-838.
[本文引用: 3]
[11]
LIU Y, FAN B, MENG G, et al. DensePoint: learning densely contextual representation for efficient point cloud processing [C]// 2019 IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 5238-5247.
[本文引用: 1]
[12]
LIU X, HAN Z, LIU Y S, et al. Point2Sequence: learning the shape representation of 3D point clouds with an attention-based sequence to sequence network [C]// Proceedings of the AAAI conference on Artificial Intelligence . Honolulu: AAAI, 2019: 8778-8785.
[本文引用: 3]
[13]
KOMARICHEV A, ZHONG Z, HUA J. A-CNN: annularly convolutional neural networks on point clouds [C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 7413-7422.
[本文引用: 3]
[14]
ZHAO H, JIANG L, FU C W, et al. PointWeb: enhancing local neighborhood features for point cloud processing [C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 5560-5568.
[本文引用: 2]
[15]
WANG C, SAMARI B, SIDDIQI K. Local spectral graph convolution for point set feature learning [C]// 15th European Conference on Computer Vision . Munich: Springer, 2018: 56-71.
[本文引用: 1]
[16]
TE G, HU W, GUO Z, et al. RGCNN: regularized graph CNN for point cloud segmentation [C]// Proceedings of the 26th ACM international conference on Multimedia . Seoul: ACM, 2018: 746-754.
[本文引用: 1]
[17]
LANDRIEU L, SIMONOVSKY M. Large-scale point cloud semantic segmentation with superpoint graphs [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 4558-4567.
[本文引用: 1]
[18]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Advances in Neural Information Processing Systems . Long Beach: MIT Press, 2017: 5998-6008.
[本文引用: 1]
[19]
HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 7132-7141.
[本文引用: 2]
[20]
YOU H, FENG Y, JI R, et al. PVNet: a joint convolutional network of point cloud and multi-view for 3D shape recognition [C]// Proceedings of the 26th ACM international conference on Multimedia . Seoul: ACM, 2018: 1310-1318.
[本文引用: 1]
[21]
YAN X, ZHENG C, LI Z, et al. PointASNL: robust point clouds processing using nonlocal neural networks with adaptive sampling [C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 5588-5597.
[本文引用: 8]
[22]
HU Y, WEN G, LUO M, et al. Competitive inner-imaging squeeze and excitation for residual network [EB/OL]. (2018-12-23)[2020-12-29]. https://arxiv.org/abs/1807.08920.
[本文引用: 1]
[23]
YI L, KIM V G, CEYLAN D, et al A scalable active framework for region annotation in 3D shape collections
[J]. ACM Transactions on Graphics , 2016 , 35 (6 ): 210
URL
[本文引用: 1]
[24]
ARMENI I, SENER O, ZAMIR A R, et al. 3D semantic parsing of large-scale indoor spaces [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 1534-1543.
[本文引用: 1]
Learning high-level feature by deep belief networks for 3-D model retrieval and recognition
1
2014
... 在计算机视觉应用中,三维点云数据极大程度上弥补了二维图像对空间结构信息的缺失. 许多研究者采用的基于深度神经网络的学习方法,依据不同的三维数据表达方式可以分为基于手工特征预处理[1 ] 、多视图[2 ] 、体素[3 ] 和原始点云数据[4 -5 ] 的方法. ...
1
... 在计算机视觉应用中,三维点云数据极大程度上弥补了二维图像对空间结构信息的缺失. 许多研究者采用的基于深度神经网络的学习方法,依据不同的三维数据表达方式可以分为基于手工特征预处理[1 ] 、多视图[2 ] 、体素[3 ] 和原始点云数据[4 -5 ] 的方法. ...
2
... 在计算机视觉应用中,三维点云数据极大程度上弥补了二维图像对空间结构信息的缺失. 许多研究者采用的基于深度神经网络的学习方法,依据不同的三维数据表达方式可以分为基于手工特征预处理[1 ] 、多视图[2 ] 、体素[3 ] 和原始点云数据[4 -5 ] 的方法. ...
... 在三维点云数据集ModelNet40[3 ] 上进行分类实验、鲁棒性分析与对比,其中包括9 843个训练样本和2 468个测试样本,所有样本共分为40个类别. 此外,实验分析子模块的必要性,并进行语义分割实验. 所有实验都以Tensorflow为平台,应用1个GTX 2080Ti GPU. ...
5
... 在计算机视觉应用中,三维点云数据极大程度上弥补了二维图像对空间结构信息的缺失. 许多研究者采用的基于深度神经网络的学习方法,依据不同的三维数据表达方式可以分为基于手工特征预处理[1 ] 、多视图[2 ] 、体素[3 ] 和原始点云数据[4 -5 ] 的方法. ...
... 原始三维数据能展现物体的立体表征,将三维点云作为输入避免了在卷积网络中输入多视图、体素这类规则化数据造成不必要的体积划分和对点云数据不变性的影响. 受采集设备及坐标系影响,三维点云数据的排列顺序差别很大. 针对无序点云数据的分类和分割问题,Qi等[4 ] 提出PointNet网络,直接处理稀疏的非结构化点云. Qi等[5 ] 以PointNet为基础,对点云下采样和分组,提出PointNet++. PCPNet[6 ] 是基于PointNet体系的一种新颖的多尺度变体,采用基于补丁的学习方法. Shen等[7 ] 更有效地利用局部结构改进PointNet,在最近邻图上进行递归特征聚合获得局部高维特征. SO-Net[8 ] 通过自组织映射(self-organizing map,SOM)算法获得关键特征点,通过PointNet模块获取包含空间信息的模型描述子. Qi等[9 ] 利用二维目标检测算法将三维模型检测范围缩小到视锥中,用PointNet获得高维特征. Li等[10 ] 提出PointCNN,引入 X-Conv 转换方式实现无序点云的潜在规则化. DensePoint[11 ] 通过泛化卷积算子将规则网格CNN扩展到不规则点配置. Point2Sequence[12 ] 使用注意力机制聚合不同局部区域的信息. A-CNN[13 ] 根据特征与局部中心点的不同距离信息,通过环形卷积分别编码. PointWeb[14 ] 关联局部区域中的每组点对得到更有表达力的局部特征. 其他一些工作介绍了用图卷积网络学习局部图[15 -16 ] 或几何元素[17 ] ,提取点云局部特征. 注意力机制[18 ] 计算特征之间的相关程度. 二维图像处理常用的注意力机制有SE模块[19 ] . 三维点云网络中,PVNet[20 ] 嵌入注意力融合模块将中间特征与全局特征融合. PointASNL[21 ] 使用通用自注意力机制在自适应采样模块中进行组内特征更新. 在对深度三维点云分类网络的研究中,优化特征提取能力和提高对点云扰动、离群值、随机噪声等干扰因素的抵抗能力是研究热点,对三维点云分类任务及其应用具有十分重要的影响. ...
... Average classification accuracy on ModelNet40 dataset
Tab.1 方法 输入 N in /103 Acc/% PointNet[4 ] Pnt 1 89.2 SO-Net[8 ] Pnt,Noml 2 90.9 PointNet++[5 ] Pnt,Noml 5 91.9 PointCNN[10] Pnt 1 92.2 Point2Sequence[12 ] Pnt 1 92.6 A-CNN[13 ] Pnt,Noml 1 92.6 PointASNL[21 ] Pnt 1 92.9(92.85) PointASNL[21 ] Pnt,Noml 1 93.2(93.15) 本研究 Pnt 1 92.9(92.88) 本研究 Pnt,Noml 1 93.2(93.19)
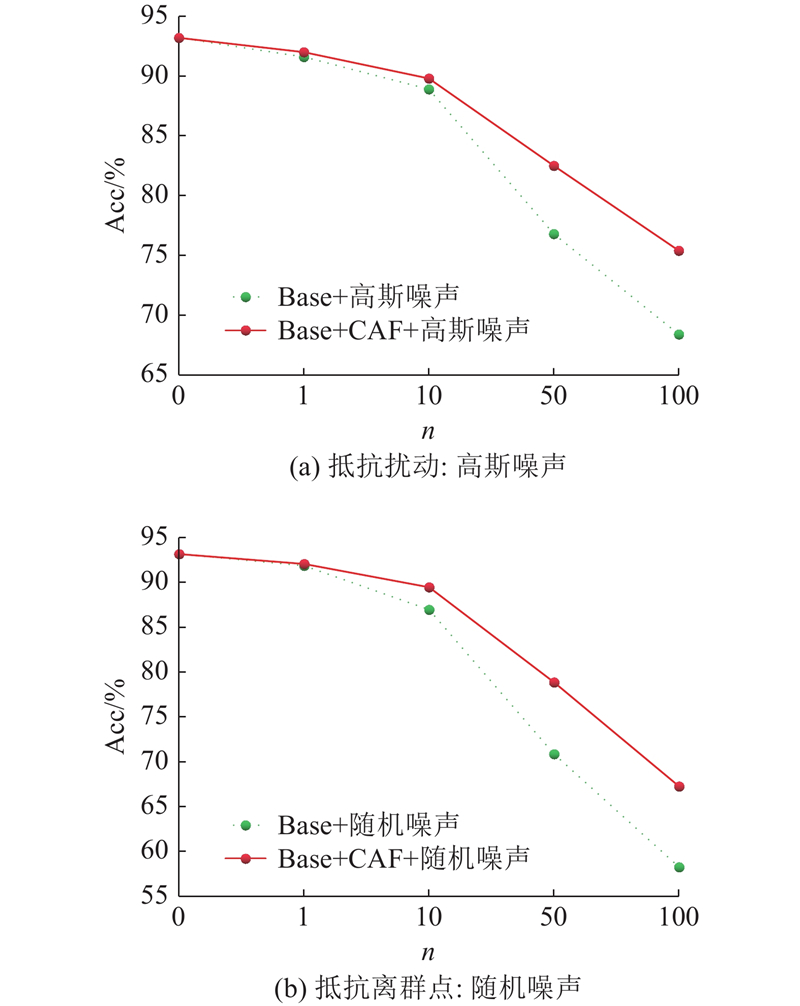
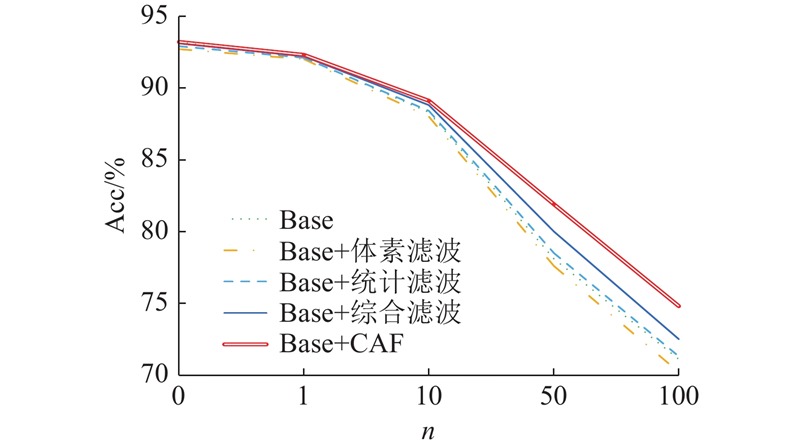
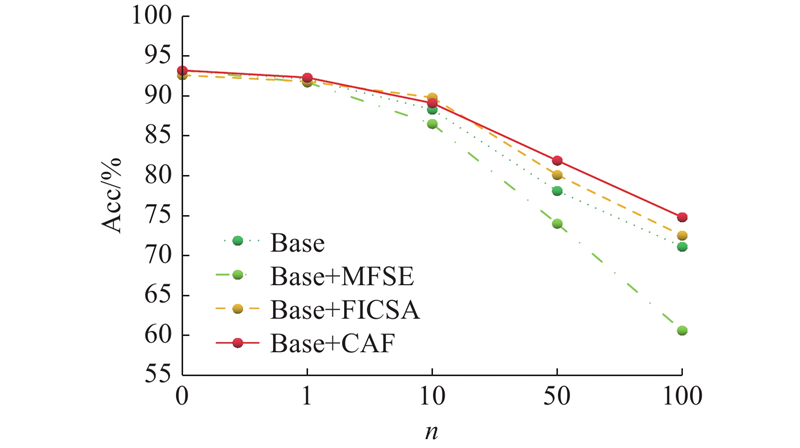
3.2. 鲁棒性分析 CAF模块对分类网络最大的贡献在于提高模型对噪声干扰的抵抗力,增强模型的鲁棒性.许多分类模型仅考虑完整点云数据集上的性能,未考虑实际情况中极大可能存在随机背景噪声和扰动,因此一些具有优秀分类性能的模型并不一定具备较强的抗干扰能力. ...
... Part segmentation performance on ShapeNetPart dataset
% Tab.3 方法 mIoU IoU areo bag cap car chair ear phone guitar knife lamp laptop motor mug pistol rocket skate board table PointNet[4 ] 83.7 83.4 78.7 82.5 74.9 89.6 73.0 91.5 85.9 80.8 95.3 65.2 93.0 81.2 57.9 72.8 80.6 SO-Net[8 ] 84.9 82.8 77.8 88.0 77.3 90.6 73.5 90.7 83.9 82.8 94.8 69.1 94.2 80.9 53.1 72.9 83.0 PointNet++[5 ] 85.1 82.4 79.0 87.7 77.3 90.8 71.8 91.0 85.9 83.7 95.3 71.6 94.1 81.3 58.7 76.4 82.6 P2Sequence[12 ] 85.2 82.6 81.8 87.5 77.3 90.8 77.1 91.1 86.9 83.9 95.7 70.8 94.6 79.3 58.1 75.2 82.8 PointCNN[10 ] 86.1 84.1 86.5 86.0 80.8 90.6 79.7 92.3 88.4 85.3 96.1 77.2 95.2 84.2 64.2 80.0 83.0 PointASNL[21 ] 86.1 84.1 84.7 87.9 79.7 92.2 73.7 91.0 87.2 84.2 95.8 74.4 95.2 81.0 63.0 76.3 83.2 本研究 85.9 84.2 83.2 87.4 79.2 91.9 74.3 91.5 86.4 84.3 95.7 73.7 95.4 82.6 62.4 75.0 82.7
在室内场景数据集S3DIS[24 ] 上进行语义场景分割,包括从3个建筑的6个区域中获得的271个房间,每个点都有一个语义标签将其划分为13类物体之一. 实验在6个区域上采用6折交叉验证比较平均交并比,实验结果如表4 所示. 结果显示本实验场景分割性能略低于基准模型,部分类别的交并比优于基准模型(beam、table、bookcase),其中OA为总体分类精度,mAcc为平均分类精度. ...
... Semantic segmentation performance on S3DIS dataset with 6-fold cross validation
% Tab.4 方法 OA mAcc mIoU IoU ceiling floor wall beam column window door table chair sofa bookcase board clutter PointNet[4 ] 78.5 66.2 47.6 88.0 88.7 69.3 42.4 23.1 47.5 51.6 42.0 54.1 38.2 9.6 29.4 35.2 A-CNN[13 ] 87.3 − 62.9 92.4 96.4 79.2 59.5 34.2 56.3 65.0 66.5 78.0 28.5 56.9 48.0 56.8 PointCNN[10 ] 88.1 75.6 65.4 94.8 97.3 75.8 63.3 51.7 58.4 57.2 71.6 69.1 39.1 61.2 52.2 58.6 PointWeb[14 ] 87.3 76.2 66.7 93.5 94.2 80.8 52.4 41.3 64.9 68.1 71.4 67.1 50.3 62.7 62.2 58.5 PointASNL[21 ] 88.8 79.0 68.7 95.3 97.9 81.9 47.0 48.0 67.3 70.5 71.3 77.8 50.7 60.4 63.0 62.8 本研究 88.2 78.7 68.3 95.1 97.3 81.2 47.4 45.8 67.0 69.1 72.1 77.5 50.6 60.8 62.4 61.6
将CAF模型用于中间特征通道权值重分配时,在语义分割任务中的表现不及分类任务.语义分割任务更艰巨,数据集更复杂,针对语义分割的研究也是三维点云深度网络的重要研究方向,如何应用CAF模型提高语义分割性能有待进一步研究. ...
6
... 在计算机视觉应用中,三维点云数据极大程度上弥补了二维图像对空间结构信息的缺失. 许多研究者采用的基于深度神经网络的学习方法,依据不同的三维数据表达方式可以分为基于手工特征预处理[1 ] 、多视图[2 ] 、体素[3 ] 和原始点云数据[4 -5 ] 的方法. ...
... 原始三维数据能展现物体的立体表征,将三维点云作为输入避免了在卷积网络中输入多视图、体素这类规则化数据造成不必要的体积划分和对点云数据不变性的影响. 受采集设备及坐标系影响,三维点云数据的排列顺序差别很大. 针对无序点云数据的分类和分割问题,Qi等[4 ] 提出PointNet网络,直接处理稀疏的非结构化点云. Qi等[5 ] 以PointNet为基础,对点云下采样和分组,提出PointNet++. PCPNet[6 ] 是基于PointNet体系的一种新颖的多尺度变体,采用基于补丁的学习方法. Shen等[7 ] 更有效地利用局部结构改进PointNet,在最近邻图上进行递归特征聚合获得局部高维特征. SO-Net[8 ] 通过自组织映射(self-organizing map,SOM)算法获得关键特征点,通过PointNet模块获取包含空间信息的模型描述子. Qi等[9 ] 利用二维目标检测算法将三维模型检测范围缩小到视锥中,用PointNet获得高维特征. Li等[10 ] 提出PointCNN,引入 X-Conv 转换方式实现无序点云的潜在规则化. DensePoint[11 ] 通过泛化卷积算子将规则网格CNN扩展到不规则点配置. Point2Sequence[12 ] 使用注意力机制聚合不同局部区域的信息. A-CNN[13 ] 根据特征与局部中心点的不同距离信息,通过环形卷积分别编码. PointWeb[14 ] 关联局部区域中的每组点对得到更有表达力的局部特征. 其他一些工作介绍了用图卷积网络学习局部图[15 -16 ] 或几何元素[17 ] ,提取点云局部特征. 注意力机制[18 ] 计算特征之间的相关程度. 二维图像处理常用的注意力机制有SE模块[19 ] . 三维点云网络中,PVNet[20 ] 嵌入注意力融合模块将中间特征与全局特征融合. PointASNL[21 ] 使用通用自注意力机制在自适应采样模块中进行组内特征更新. 在对深度三维点云分类网络的研究中,优化特征提取能力和提高对点云扰动、离群值、随机噪声等干扰因素的抵抗能力是研究热点,对三维点云分类任务及其应用具有十分重要的影响. ...
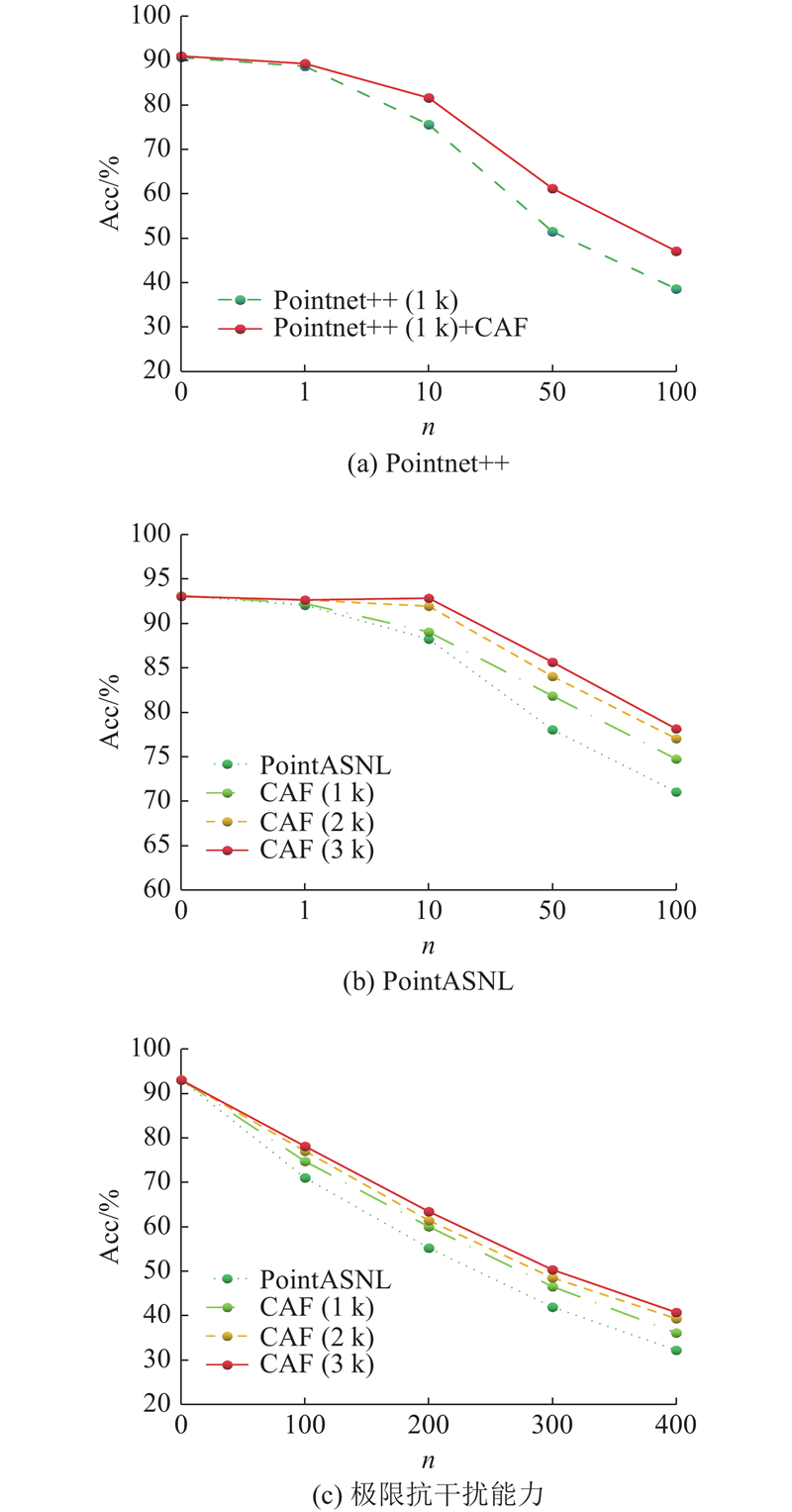
... 在Pointnet++中加入CAF模块,训练和测试中均加入法线向量,测试时随机旋转点云以模拟真实场景. 由于文献[5 ]中没有提供最优训练模型(输入点数为5 000,最优精度为91. 9%)详细的训练参数,本研究复现文献[5 ]的最优分类精度为90. 7%,加入CAF模块后平均分类精度为91. 0%,分类精度的提高证明了CAF模块的有效性和可行性. ...
... ]中没有提供最优训练模型(输入点数为5 000,最优精度为91. 9%)详细的训练参数,本研究复现文献[5 ]的最优分类精度为90. 7%,加入CAF模块后平均分类精度为91. 0%,分类精度的提高证明了CAF模块的有效性和可行性. ...
... Average classification accuracy on ModelNet40 dataset
Tab.1 方法 输入 N in /103 Acc/% PointNet[4 ] Pnt 1 89.2 SO-Net[8 ] Pnt,Noml 2 90.9 PointNet++[5 ] Pnt,Noml 5 91.9 PointCNN[10] Pnt 1 92.2 Point2Sequence[12 ] Pnt 1 92.6 A-CNN[13 ] Pnt,Noml 1 92.6 PointASNL[21 ] Pnt 1 92.9(92.85) PointASNL[21 ] Pnt,Noml 1 93.2(93.15) 本研究 Pnt 1 92.9(92.88) 本研究 Pnt,Noml 1 93.2(93.19)
3.2. 鲁棒性分析 CAF模块对分类网络最大的贡献在于提高模型对噪声干扰的抵抗力,增强模型的鲁棒性.许多分类模型仅考虑完整点云数据集上的性能,未考虑实际情况中极大可能存在随机背景噪声和扰动,因此一些具有优秀分类性能的模型并不一定具备较强的抗干扰能力. ...
... Part segmentation performance on ShapeNetPart dataset
% Tab.3 方法 mIoU IoU areo bag cap car chair ear phone guitar knife lamp laptop motor mug pistol rocket skate board table PointNet[4 ] 83.7 83.4 78.7 82.5 74.9 89.6 73.0 91.5 85.9 80.8 95.3 65.2 93.0 81.2 57.9 72.8 80.6 SO-Net[8 ] 84.9 82.8 77.8 88.0 77.3 90.6 73.5 90.7 83.9 82.8 94.8 69.1 94.2 80.9 53.1 72.9 83.0 PointNet++[5 ] 85.1 82.4 79.0 87.7 77.3 90.8 71.8 91.0 85.9 83.7 95.3 71.6 94.1 81.3 58.7 76.4 82.6 P2Sequence[12 ] 85.2 82.6 81.8 87.5 77.3 90.8 77.1 91.1 86.9 83.9 95.7 70.8 94.6 79.3 58.1 75.2 82.8 PointCNN[10 ] 86.1 84.1 86.5 86.0 80.8 90.6 79.7 92.3 88.4 85.3 96.1 77.2 95.2 84.2 64.2 80.0 83.0 PointASNL[21 ] 86.1 84.1 84.7 87.9 79.7 92.2 73.7 91.0 87.2 84.2 95.8 74.4 95.2 81.0 63.0 76.3 83.2 本研究 85.9 84.2 83.2 87.4 79.2 91.9 74.3 91.5 86.4 84.3 95.7 73.7 95.4 82.6 62.4 75.0 82.7
在室内场景数据集S3DIS[24 ] 上进行语义场景分割,包括从3个建筑的6个区域中获得的271个房间,每个点都有一个语义标签将其划分为13类物体之一. 实验在6个区域上采用6折交叉验证比较平均交并比,实验结果如表4 所示. 结果显示本实验场景分割性能略低于基准模型,部分类别的交并比优于基准模型(beam、table、bookcase),其中OA为总体分类精度,mAcc为平均分类精度. ...
PCPNET learning local shape properties from raw point clouds
1
2018
... 原始三维数据能展现物体的立体表征,将三维点云作为输入避免了在卷积网络中输入多视图、体素这类规则化数据造成不必要的体积划分和对点云数据不变性的影响. 受采集设备及坐标系影响,三维点云数据的排列顺序差别很大. 针对无序点云数据的分类和分割问题,Qi等[4 ] 提出PointNet网络,直接处理稀疏的非结构化点云. Qi等[5 ] 以PointNet为基础,对点云下采样和分组,提出PointNet++. PCPNet[6 ] 是基于PointNet体系的一种新颖的多尺度变体,采用基于补丁的学习方法. Shen等[7 ] 更有效地利用局部结构改进PointNet,在最近邻图上进行递归特征聚合获得局部高维特征. SO-Net[8 ] 通过自组织映射(self-organizing map,SOM)算法获得关键特征点,通过PointNet模块获取包含空间信息的模型描述子. Qi等[9 ] 利用二维目标检测算法将三维模型检测范围缩小到视锥中,用PointNet获得高维特征. Li等[10 ] 提出PointCNN,引入 X-Conv 转换方式实现无序点云的潜在规则化. DensePoint[11 ] 通过泛化卷积算子将规则网格CNN扩展到不规则点配置. Point2Sequence[12 ] 使用注意力机制聚合不同局部区域的信息. A-CNN[13 ] 根据特征与局部中心点的不同距离信息,通过环形卷积分别编码. PointWeb[14 ] 关联局部区域中的每组点对得到更有表达力的局部特征. 其他一些工作介绍了用图卷积网络学习局部图[15 -16 ] 或几何元素[17 ] ,提取点云局部特征. 注意力机制[18 ] 计算特征之间的相关程度. 二维图像处理常用的注意力机制有SE模块[19 ] . 三维点云网络中,PVNet[20 ] 嵌入注意力融合模块将中间特征与全局特征融合. PointASNL[21 ] 使用通用自注意力机制在自适应采样模块中进行组内特征更新. 在对深度三维点云分类网络的研究中,优化特征提取能力和提高对点云扰动、离群值、随机噪声等干扰因素的抵抗能力是研究热点,对三维点云分类任务及其应用具有十分重要的影响. ...
2
... 原始三维数据能展现物体的立体表征,将三维点云作为输入避免了在卷积网络中输入多视图、体素这类规则化数据造成不必要的体积划分和对点云数据不变性的影响. 受采集设备及坐标系影响,三维点云数据的排列顺序差别很大. 针对无序点云数据的分类和分割问题,Qi等[4 ] 提出PointNet网络,直接处理稀疏的非结构化点云. Qi等[5 ] 以PointNet为基础,对点云下采样和分组,提出PointNet++. PCPNet[6 ] 是基于PointNet体系的一种新颖的多尺度变体,采用基于补丁的学习方法. Shen等[7 ] 更有效地利用局部结构改进PointNet,在最近邻图上进行递归特征聚合获得局部高维特征. SO-Net[8 ] 通过自组织映射(self-organizing map,SOM)算法获得关键特征点,通过PointNet模块获取包含空间信息的模型描述子. Qi等[9 ] 利用二维目标检测算法将三维模型检测范围缩小到视锥中,用PointNet获得高维特征. Li等[10 ] 提出PointCNN,引入 X-Conv 转换方式实现无序点云的潜在规则化. DensePoint[11 ] 通过泛化卷积算子将规则网格CNN扩展到不规则点配置. Point2Sequence[12 ] 使用注意力机制聚合不同局部区域的信息. A-CNN[13 ] 根据特征与局部中心点的不同距离信息,通过环形卷积分别编码. PointWeb[14 ] 关联局部区域中的每组点对得到更有表达力的局部特征. 其他一些工作介绍了用图卷积网络学习局部图[15 -16 ] 或几何元素[17 ] ,提取点云局部特征. 注意力机制[18 ] 计算特征之间的相关程度. 二维图像处理常用的注意力机制有SE模块[19 ] . 三维点云网络中,PVNet[20 ] 嵌入注意力融合模块将中间特征与全局特征融合. PointASNL[21 ] 使用通用自注意力机制在自适应采样模块中进行组内特征更新. 在对深度三维点云分类网络的研究中,优化特征提取能力和提高对点云扰动、离群值、随机噪声等干扰因素的抵抗能力是研究热点,对三维点云分类任务及其应用具有十分重要的影响. ...
... 为了进一步实验CAF模块对模型鲁棒性的影响,参照PointASNL[21 ] 和KCNet[7 ] 中测试模型鲁棒性的方法,将一定数量的原始点集替换为 ${x、y、z \in}{[-1.0,1.0]} $ n 分别为0、1、10、50、100. ...
3
... 原始三维数据能展现物体的立体表征,将三维点云作为输入避免了在卷积网络中输入多视图、体素这类规则化数据造成不必要的体积划分和对点云数据不变性的影响. 受采集设备及坐标系影响,三维点云数据的排列顺序差别很大. 针对无序点云数据的分类和分割问题,Qi等[4 ] 提出PointNet网络,直接处理稀疏的非结构化点云. Qi等[5 ] 以PointNet为基础,对点云下采样和分组,提出PointNet++. PCPNet[6 ] 是基于PointNet体系的一种新颖的多尺度变体,采用基于补丁的学习方法. Shen等[7 ] 更有效地利用局部结构改进PointNet,在最近邻图上进行递归特征聚合获得局部高维特征. SO-Net[8 ] 通过自组织映射(self-organizing map,SOM)算法获得关键特征点,通过PointNet模块获取包含空间信息的模型描述子. Qi等[9 ] 利用二维目标检测算法将三维模型检测范围缩小到视锥中,用PointNet获得高维特征. Li等[10 ] 提出PointCNN,引入 X-Conv 转换方式实现无序点云的潜在规则化. DensePoint[11 ] 通过泛化卷积算子将规则网格CNN扩展到不规则点配置. Point2Sequence[12 ] 使用注意力机制聚合不同局部区域的信息. A-CNN[13 ] 根据特征与局部中心点的不同距离信息,通过环形卷积分别编码. PointWeb[14 ] 关联局部区域中的每组点对得到更有表达力的局部特征. 其他一些工作介绍了用图卷积网络学习局部图[15 -16 ] 或几何元素[17 ] ,提取点云局部特征. 注意力机制[18 ] 计算特征之间的相关程度. 二维图像处理常用的注意力机制有SE模块[19 ] . 三维点云网络中,PVNet[20 ] 嵌入注意力融合模块将中间特征与全局特征融合. PointASNL[21 ] 使用通用自注意力机制在自适应采样模块中进行组内特征更新. 在对深度三维点云分类网络的研究中,优化特征提取能力和提高对点云扰动、离群值、随机噪声等干扰因素的抵抗能力是研究热点,对三维点云分类任务及其应用具有十分重要的影响. ...
... Average classification accuracy on ModelNet40 dataset
Tab.1 方法 输入 N in /103 Acc/% PointNet[4 ] Pnt 1 89.2 SO-Net[8 ] Pnt,Noml 2 90.9 PointNet++[5 ] Pnt,Noml 5 91.9 PointCNN[10] Pnt 1 92.2 Point2Sequence[12 ] Pnt 1 92.6 A-CNN[13 ] Pnt,Noml 1 92.6 PointASNL[21 ] Pnt 1 92.9(92.85) PointASNL[21 ] Pnt,Noml 1 93.2(93.15) 本研究 Pnt 1 92.9(92.88) 本研究 Pnt,Noml 1 93.2(93.19)
3.2. 鲁棒性分析 CAF模块对分类网络最大的贡献在于提高模型对噪声干扰的抵抗力,增强模型的鲁棒性.许多分类模型仅考虑完整点云数据集上的性能,未考虑实际情况中极大可能存在随机背景噪声和扰动,因此一些具有优秀分类性能的模型并不一定具备较强的抗干扰能力. ...
... Part segmentation performance on ShapeNetPart dataset
% Tab.3 方法 mIoU IoU areo bag cap car chair ear phone guitar knife lamp laptop motor mug pistol rocket skate board table PointNet[4 ] 83.7 83.4 78.7 82.5 74.9 89.6 73.0 91.5 85.9 80.8 95.3 65.2 93.0 81.2 57.9 72.8 80.6 SO-Net[8 ] 84.9 82.8 77.8 88.0 77.3 90.6 73.5 90.7 83.9 82.8 94.8 69.1 94.2 80.9 53.1 72.9 83.0 PointNet++[5 ] 85.1 82.4 79.0 87.7 77.3 90.8 71.8 91.0 85.9 83.7 95.3 71.6 94.1 81.3 58.7 76.4 82.6 P2Sequence[12 ] 85.2 82.6 81.8 87.5 77.3 90.8 77.1 91.1 86.9 83.9 95.7 70.8 94.6 79.3 58.1 75.2 82.8 PointCNN[10 ] 86.1 84.1 86.5 86.0 80.8 90.6 79.7 92.3 88.4 85.3 96.1 77.2 95.2 84.2 64.2 80.0 83.0 PointASNL[21 ] 86.1 84.1 84.7 87.9 79.7 92.2 73.7 91.0 87.2 84.2 95.8 74.4 95.2 81.0 63.0 76.3 83.2 本研究 85.9 84.2 83.2 87.4 79.2 91.9 74.3 91.5 86.4 84.3 95.7 73.7 95.4 82.6 62.4 75.0 82.7
在室内场景数据集S3DIS[24 ] 上进行语义场景分割,包括从3个建筑的6个区域中获得的271个房间,每个点都有一个语义标签将其划分为13类物体之一. 实验在6个区域上采用6折交叉验证比较平均交并比,实验结果如表4 所示. 结果显示本实验场景分割性能略低于基准模型,部分类别的交并比优于基准模型(beam、table、bookcase),其中OA为总体分类精度,mAcc为平均分类精度. ...
1
... 原始三维数据能展现物体的立体表征,将三维点云作为输入避免了在卷积网络中输入多视图、体素这类规则化数据造成不必要的体积划分和对点云数据不变性的影响. 受采集设备及坐标系影响,三维点云数据的排列顺序差别很大. 针对无序点云数据的分类和分割问题,Qi等[4 ] 提出PointNet网络,直接处理稀疏的非结构化点云. Qi等[5 ] 以PointNet为基础,对点云下采样和分组,提出PointNet++. PCPNet[6 ] 是基于PointNet体系的一种新颖的多尺度变体,采用基于补丁的学习方法. Shen等[7 ] 更有效地利用局部结构改进PointNet,在最近邻图上进行递归特征聚合获得局部高维特征. SO-Net[8 ] 通过自组织映射(self-organizing map,SOM)算法获得关键特征点,通过PointNet模块获取包含空间信息的模型描述子. Qi等[9 ] 利用二维目标检测算法将三维模型检测范围缩小到视锥中,用PointNet获得高维特征. Li等[10 ] 提出PointCNN,引入 X-Conv 转换方式实现无序点云的潜在规则化. DensePoint[11 ] 通过泛化卷积算子将规则网格CNN扩展到不规则点配置. Point2Sequence[12 ] 使用注意力机制聚合不同局部区域的信息. A-CNN[13 ] 根据特征与局部中心点的不同距离信息,通过环形卷积分别编码. PointWeb[14 ] 关联局部区域中的每组点对得到更有表达力的局部特征. 其他一些工作介绍了用图卷积网络学习局部图[15 -16 ] 或几何元素[17 ] ,提取点云局部特征. 注意力机制[18 ] 计算特征之间的相关程度. 二维图像处理常用的注意力机制有SE模块[19 ] . 三维点云网络中,PVNet[20 ] 嵌入注意力融合模块将中间特征与全局特征融合. PointASNL[21 ] 使用通用自注意力机制在自适应采样模块中进行组内特征更新. 在对深度三维点云分类网络的研究中,优化特征提取能力和提高对点云扰动、离群值、随机噪声等干扰因素的抵抗能力是研究热点,对三维点云分类任务及其应用具有十分重要的影响. ...
3
... 原始三维数据能展现物体的立体表征,将三维点云作为输入避免了在卷积网络中输入多视图、体素这类规则化数据造成不必要的体积划分和对点云数据不变性的影响. 受采集设备及坐标系影响,三维点云数据的排列顺序差别很大. 针对无序点云数据的分类和分割问题,Qi等[4 ] 提出PointNet网络,直接处理稀疏的非结构化点云. Qi等[5 ] 以PointNet为基础,对点云下采样和分组,提出PointNet++. PCPNet[6 ] 是基于PointNet体系的一种新颖的多尺度变体,采用基于补丁的学习方法. Shen等[7 ] 更有效地利用局部结构改进PointNet,在最近邻图上进行递归特征聚合获得局部高维特征. SO-Net[8 ] 通过自组织映射(self-organizing map,SOM)算法获得关键特征点,通过PointNet模块获取包含空间信息的模型描述子. Qi等[9 ] 利用二维目标检测算法将三维模型检测范围缩小到视锥中,用PointNet获得高维特征. Li等[10 ] 提出PointCNN,引入 X-Conv 转换方式实现无序点云的潜在规则化. DensePoint[11 ] 通过泛化卷积算子将规则网格CNN扩展到不规则点配置. Point2Sequence[12 ] 使用注意力机制聚合不同局部区域的信息. A-CNN[13 ] 根据特征与局部中心点的不同距离信息,通过环形卷积分别编码. PointWeb[14 ] 关联局部区域中的每组点对得到更有表达力的局部特征. 其他一些工作介绍了用图卷积网络学习局部图[15 -16 ] 或几何元素[17 ] ,提取点云局部特征. 注意力机制[18 ] 计算特征之间的相关程度. 二维图像处理常用的注意力机制有SE模块[19 ] . 三维点云网络中,PVNet[20 ] 嵌入注意力融合模块将中间特征与全局特征融合. PointASNL[21 ] 使用通用自注意力机制在自适应采样模块中进行组内特征更新. 在对深度三维点云分类网络的研究中,优化特征提取能力和提高对点云扰动、离群值、随机噪声等干扰因素的抵抗能力是研究热点,对三维点云分类任务及其应用具有十分重要的影响. ...
... Part segmentation performance on ShapeNetPart dataset
% Tab.3 方法 mIoU IoU areo bag cap car chair ear phone guitar knife lamp laptop motor mug pistol rocket skate board table PointNet[4 ] 83.7 83.4 78.7 82.5 74.9 89.6 73.0 91.5 85.9 80.8 95.3 65.2 93.0 81.2 57.9 72.8 80.6 SO-Net[8 ] 84.9 82.8 77.8 88.0 77.3 90.6 73.5 90.7 83.9 82.8 94.8 69.1 94.2 80.9 53.1 72.9 83.0 PointNet++[5 ] 85.1 82.4 79.0 87.7 77.3 90.8 71.8 91.0 85.9 83.7 95.3 71.6 94.1 81.3 58.7 76.4 82.6 P2Sequence[12 ] 85.2 82.6 81.8 87.5 77.3 90.8 77.1 91.1 86.9 83.9 95.7 70.8 94.6 79.3 58.1 75.2 82.8 PointCNN[10 ] 86.1 84.1 86.5 86.0 80.8 90.6 79.7 92.3 88.4 85.3 96.1 77.2 95.2 84.2 64.2 80.0 83.0 PointASNL[21 ] 86.1 84.1 84.7 87.9 79.7 92.2 73.7 91.0 87.2 84.2 95.8 74.4 95.2 81.0 63.0 76.3 83.2 本研究 85.9 84.2 83.2 87.4 79.2 91.9 74.3 91.5 86.4 84.3 95.7 73.7 95.4 82.6 62.4 75.0 82.7
在室内场景数据集S3DIS[24 ] 上进行语义场景分割,包括从3个建筑的6个区域中获得的271个房间,每个点都有一个语义标签将其划分为13类物体之一. 实验在6个区域上采用6折交叉验证比较平均交并比,实验结果如表4 所示. 结果显示本实验场景分割性能略低于基准模型,部分类别的交并比优于基准模型(beam、table、bookcase),其中OA为总体分类精度,mAcc为平均分类精度. ...
... Semantic segmentation performance on S3DIS dataset with 6-fold cross validation
% Tab.4 方法 OA mAcc mIoU IoU ceiling floor wall beam column window door table chair sofa bookcase board clutter PointNet[4 ] 78.5 66.2 47.6 88.0 88.7 69.3 42.4 23.1 47.5 51.6 42.0 54.1 38.2 9.6 29.4 35.2 A-CNN[13 ] 87.3 − 62.9 92.4 96.4 79.2 59.5 34.2 56.3 65.0 66.5 78.0 28.5 56.9 48.0 56.8 PointCNN[10 ] 88.1 75.6 65.4 94.8 97.3 75.8 63.3 51.7 58.4 57.2 71.6 69.1 39.1 61.2 52.2 58.6 PointWeb[14 ] 87.3 76.2 66.7 93.5 94.2 80.8 52.4 41.3 64.9 68.1 71.4 67.1 50.3 62.7 62.2 58.5 PointASNL[21 ] 88.8 79.0 68.7 95.3 97.9 81.9 47.0 48.0 67.3 70.5 71.3 77.8 50.7 60.4 63.0 62.8 本研究 88.2 78.7 68.3 95.1 97.3 81.2 47.4 45.8 67.0 69.1 72.1 77.5 50.6 60.8 62.4 61.6
将CAF模型用于中间特征通道权值重分配时,在语义分割任务中的表现不及分类任务.语义分割任务更艰巨,数据集更复杂,针对语义分割的研究也是三维点云深度网络的重要研究方向,如何应用CAF模型提高语义分割性能有待进一步研究. ...
1
... 原始三维数据能展现物体的立体表征,将三维点云作为输入避免了在卷积网络中输入多视图、体素这类规则化数据造成不必要的体积划分和对点云数据不变性的影响. 受采集设备及坐标系影响,三维点云数据的排列顺序差别很大. 针对无序点云数据的分类和分割问题,Qi等[4 ] 提出PointNet网络,直接处理稀疏的非结构化点云. Qi等[5 ] 以PointNet为基础,对点云下采样和分组,提出PointNet++. PCPNet[6 ] 是基于PointNet体系的一种新颖的多尺度变体,采用基于补丁的学习方法. Shen等[7 ] 更有效地利用局部结构改进PointNet,在最近邻图上进行递归特征聚合获得局部高维特征. SO-Net[8 ] 通过自组织映射(self-organizing map,SOM)算法获得关键特征点,通过PointNet模块获取包含空间信息的模型描述子. Qi等[9 ] 利用二维目标检测算法将三维模型检测范围缩小到视锥中,用PointNet获得高维特征. Li等[10 ] 提出PointCNN,引入 X-Conv 转换方式实现无序点云的潜在规则化. DensePoint[11 ] 通过泛化卷积算子将规则网格CNN扩展到不规则点配置. Point2Sequence[12 ] 使用注意力机制聚合不同局部区域的信息. A-CNN[13 ] 根据特征与局部中心点的不同距离信息,通过环形卷积分别编码. PointWeb[14 ] 关联局部区域中的每组点对得到更有表达力的局部特征. 其他一些工作介绍了用图卷积网络学习局部图[15 -16 ] 或几何元素[17 ] ,提取点云局部特征. 注意力机制[18 ] 计算特征之间的相关程度. 二维图像处理常用的注意力机制有SE模块[19 ] . 三维点云网络中,PVNet[20 ] 嵌入注意力融合模块将中间特征与全局特征融合. PointASNL[21 ] 使用通用自注意力机制在自适应采样模块中进行组内特征更新. 在对深度三维点云分类网络的研究中,优化特征提取能力和提高对点云扰动、离群值、随机噪声等干扰因素的抵抗能力是研究热点,对三维点云分类任务及其应用具有十分重要的影响. ...
3
... 原始三维数据能展现物体的立体表征,将三维点云作为输入避免了在卷积网络中输入多视图、体素这类规则化数据造成不必要的体积划分和对点云数据不变性的影响. 受采集设备及坐标系影响,三维点云数据的排列顺序差别很大. 针对无序点云数据的分类和分割问题,Qi等[4 ] 提出PointNet网络,直接处理稀疏的非结构化点云. Qi等[5 ] 以PointNet为基础,对点云下采样和分组,提出PointNet++. PCPNet[6 ] 是基于PointNet体系的一种新颖的多尺度变体,采用基于补丁的学习方法. Shen等[7 ] 更有效地利用局部结构改进PointNet,在最近邻图上进行递归特征聚合获得局部高维特征. SO-Net[8 ] 通过自组织映射(self-organizing map,SOM)算法获得关键特征点,通过PointNet模块获取包含空间信息的模型描述子. Qi等[9 ] 利用二维目标检测算法将三维模型检测范围缩小到视锥中,用PointNet获得高维特征. Li等[10 ] 提出PointCNN,引入 X-Conv 转换方式实现无序点云的潜在规则化. DensePoint[11 ] 通过泛化卷积算子将规则网格CNN扩展到不规则点配置. Point2Sequence[12 ] 使用注意力机制聚合不同局部区域的信息. A-CNN[13 ] 根据特征与局部中心点的不同距离信息,通过环形卷积分别编码. PointWeb[14 ] 关联局部区域中的每组点对得到更有表达力的局部特征. 其他一些工作介绍了用图卷积网络学习局部图[15 -16 ] 或几何元素[17 ] ,提取点云局部特征. 注意力机制[18 ] 计算特征之间的相关程度. 二维图像处理常用的注意力机制有SE模块[19 ] . 三维点云网络中,PVNet[20 ] 嵌入注意力融合模块将中间特征与全局特征融合. PointASNL[21 ] 使用通用自注意力机制在自适应采样模块中进行组内特征更新. 在对深度三维点云分类网络的研究中,优化特征提取能力和提高对点云扰动、离群值、随机噪声等干扰因素的抵抗能力是研究热点,对三维点云分类任务及其应用具有十分重要的影响. ...
... Average classification accuracy on ModelNet40 dataset
Tab.1 方法 输入 N in /103 Acc/% PointNet[4 ] Pnt 1 89.2 SO-Net[8 ] Pnt,Noml 2 90.9 PointNet++[5 ] Pnt,Noml 5 91.9 PointCNN[10] Pnt 1 92.2 Point2Sequence[12 ] Pnt 1 92.6 A-CNN[13 ] Pnt,Noml 1 92.6 PointASNL[21 ] Pnt 1 92.9(92.85) PointASNL[21 ] Pnt,Noml 1 93.2(93.15) 本研究 Pnt 1 92.9(92.88) 本研究 Pnt,Noml 1 93.2(93.19)
3.2. 鲁棒性分析 CAF模块对分类网络最大的贡献在于提高模型对噪声干扰的抵抗力,增强模型的鲁棒性.许多分类模型仅考虑完整点云数据集上的性能,未考虑实际情况中极大可能存在随机背景噪声和扰动,因此一些具有优秀分类性能的模型并不一定具备较强的抗干扰能力. ...
... Part segmentation performance on ShapeNetPart dataset
% Tab.3 方法 mIoU IoU areo bag cap car chair ear phone guitar knife lamp laptop motor mug pistol rocket skate board table PointNet[4 ] 83.7 83.4 78.7 82.5 74.9 89.6 73.0 91.5 85.9 80.8 95.3 65.2 93.0 81.2 57.9 72.8 80.6 SO-Net[8 ] 84.9 82.8 77.8 88.0 77.3 90.6 73.5 90.7 83.9 82.8 94.8 69.1 94.2 80.9 53.1 72.9 83.0 PointNet++[5 ] 85.1 82.4 79.0 87.7 77.3 90.8 71.8 91.0 85.9 83.7 95.3 71.6 94.1 81.3 58.7 76.4 82.6 P2Sequence[12 ] 85.2 82.6 81.8 87.5 77.3 90.8 77.1 91.1 86.9 83.9 95.7 70.8 94.6 79.3 58.1 75.2 82.8 PointCNN[10 ] 86.1 84.1 86.5 86.0 80.8 90.6 79.7 92.3 88.4 85.3 96.1 77.2 95.2 84.2 64.2 80.0 83.0 PointASNL[21 ] 86.1 84.1 84.7 87.9 79.7 92.2 73.7 91.0 87.2 84.2 95.8 74.4 95.2 81.0 63.0 76.3 83.2 本研究 85.9 84.2 83.2 87.4 79.2 91.9 74.3 91.5 86.4 84.3 95.7 73.7 95.4 82.6 62.4 75.0 82.7
在室内场景数据集S3DIS[24 ] 上进行语义场景分割,包括从3个建筑的6个区域中获得的271个房间,每个点都有一个语义标签将其划分为13类物体之一. 实验在6个区域上采用6折交叉验证比较平均交并比,实验结果如表4 所示. 结果显示本实验场景分割性能略低于基准模型,部分类别的交并比优于基准模型(beam、table、bookcase),其中OA为总体分类精度,mAcc为平均分类精度. ...
3
... 原始三维数据能展现物体的立体表征,将三维点云作为输入避免了在卷积网络中输入多视图、体素这类规则化数据造成不必要的体积划分和对点云数据不变性的影响. 受采集设备及坐标系影响,三维点云数据的排列顺序差别很大. 针对无序点云数据的分类和分割问题,Qi等[4 ] 提出PointNet网络,直接处理稀疏的非结构化点云. Qi等[5 ] 以PointNet为基础,对点云下采样和分组,提出PointNet++. PCPNet[6 ] 是基于PointNet体系的一种新颖的多尺度变体,采用基于补丁的学习方法. Shen等[7 ] 更有效地利用局部结构改进PointNet,在最近邻图上进行递归特征聚合获得局部高维特征. SO-Net[8 ] 通过自组织映射(self-organizing map,SOM)算法获得关键特征点,通过PointNet模块获取包含空间信息的模型描述子. Qi等[9 ] 利用二维目标检测算法将三维模型检测范围缩小到视锥中,用PointNet获得高维特征. Li等[10 ] 提出PointCNN,引入 X-Conv 转换方式实现无序点云的潜在规则化. DensePoint[11 ] 通过泛化卷积算子将规则网格CNN扩展到不规则点配置. Point2Sequence[12 ] 使用注意力机制聚合不同局部区域的信息. A-CNN[13 ] 根据特征与局部中心点的不同距离信息,通过环形卷积分别编码. PointWeb[14 ] 关联局部区域中的每组点对得到更有表达力的局部特征. 其他一些工作介绍了用图卷积网络学习局部图[15 -16 ] 或几何元素[17 ] ,提取点云局部特征. 注意力机制[18 ] 计算特征之间的相关程度. 二维图像处理常用的注意力机制有SE模块[19 ] . 三维点云网络中,PVNet[20 ] 嵌入注意力融合模块将中间特征与全局特征融合. PointASNL[21 ] 使用通用自注意力机制在自适应采样模块中进行组内特征更新. 在对深度三维点云分类网络的研究中,优化特征提取能力和提高对点云扰动、离群值、随机噪声等干扰因素的抵抗能力是研究热点,对三维点云分类任务及其应用具有十分重要的影响. ...
... Average classification accuracy on ModelNet40 dataset
Tab.1 方法 输入 N in /103 Acc/% PointNet[4 ] Pnt 1 89.2 SO-Net[8 ] Pnt,Noml 2 90.9 PointNet++[5 ] Pnt,Noml 5 91.9 PointCNN[10] Pnt 1 92.2 Point2Sequence[12 ] Pnt 1 92.6 A-CNN[13 ] Pnt,Noml 1 92.6 PointASNL[21 ] Pnt 1 92.9(92.85) PointASNL[21 ] Pnt,Noml 1 93.2(93.15) 本研究 Pnt 1 92.9(92.88) 本研究 Pnt,Noml 1 93.2(93.19)
3.2. 鲁棒性分析 CAF模块对分类网络最大的贡献在于提高模型对噪声干扰的抵抗力,增强模型的鲁棒性.许多分类模型仅考虑完整点云数据集上的性能,未考虑实际情况中极大可能存在随机背景噪声和扰动,因此一些具有优秀分类性能的模型并不一定具备较强的抗干扰能力. ...
... Semantic segmentation performance on S3DIS dataset with 6-fold cross validation
% Tab.4 方法 OA mAcc mIoU IoU ceiling floor wall beam column window door table chair sofa bookcase board clutter PointNet[4 ] 78.5 66.2 47.6 88.0 88.7 69.3 42.4 23.1 47.5 51.6 42.0 54.1 38.2 9.6 29.4 35.2 A-CNN[13 ] 87.3 − 62.9 92.4 96.4 79.2 59.5 34.2 56.3 65.0 66.5 78.0 28.5 56.9 48.0 56.8 PointCNN[10 ] 88.1 75.6 65.4 94.8 97.3 75.8 63.3 51.7 58.4 57.2 71.6 69.1 39.1 61.2 52.2 58.6 PointWeb[14 ] 87.3 76.2 66.7 93.5 94.2 80.8 52.4 41.3 64.9 68.1 71.4 67.1 50.3 62.7 62.2 58.5 PointASNL[21 ] 88.8 79.0 68.7 95.3 97.9 81.9 47.0 48.0 67.3 70.5 71.3 77.8 50.7 60.4 63.0 62.8 本研究 88.2 78.7 68.3 95.1 97.3 81.2 47.4 45.8 67.0 69.1 72.1 77.5 50.6 60.8 62.4 61.6
将CAF模型用于中间特征通道权值重分配时,在语义分割任务中的表现不及分类任务.语义分割任务更艰巨,数据集更复杂,针对语义分割的研究也是三维点云深度网络的重要研究方向,如何应用CAF模型提高语义分割性能有待进一步研究. ...
2
... 原始三维数据能展现物体的立体表征,将三维点云作为输入避免了在卷积网络中输入多视图、体素这类规则化数据造成不必要的体积划分和对点云数据不变性的影响. 受采集设备及坐标系影响,三维点云数据的排列顺序差别很大. 针对无序点云数据的分类和分割问题,Qi等[4 ] 提出PointNet网络,直接处理稀疏的非结构化点云. Qi等[5 ] 以PointNet为基础,对点云下采样和分组,提出PointNet++. PCPNet[6 ] 是基于PointNet体系的一种新颖的多尺度变体,采用基于补丁的学习方法. Shen等[7 ] 更有效地利用局部结构改进PointNet,在最近邻图上进行递归特征聚合获得局部高维特征. SO-Net[8 ] 通过自组织映射(self-organizing map,SOM)算法获得关键特征点,通过PointNet模块获取包含空间信息的模型描述子. Qi等[9 ] 利用二维目标检测算法将三维模型检测范围缩小到视锥中,用PointNet获得高维特征. Li等[10 ] 提出PointCNN,引入 X-Conv 转换方式实现无序点云的潜在规则化. DensePoint[11 ] 通过泛化卷积算子将规则网格CNN扩展到不规则点配置. Point2Sequence[12 ] 使用注意力机制聚合不同局部区域的信息. A-CNN[13 ] 根据特征与局部中心点的不同距离信息,通过环形卷积分别编码. PointWeb[14 ] 关联局部区域中的每组点对得到更有表达力的局部特征. 其他一些工作介绍了用图卷积网络学习局部图[15 -16 ] 或几何元素[17 ] ,提取点云局部特征. 注意力机制[18 ] 计算特征之间的相关程度. 二维图像处理常用的注意力机制有SE模块[19 ] . 三维点云网络中,PVNet[20 ] 嵌入注意力融合模块将中间特征与全局特征融合. PointASNL[21 ] 使用通用自注意力机制在自适应采样模块中进行组内特征更新. 在对深度三维点云分类网络的研究中,优化特征提取能力和提高对点云扰动、离群值、随机噪声等干扰因素的抵抗能力是研究热点,对三维点云分类任务及其应用具有十分重要的影响. ...
... Semantic segmentation performance on S3DIS dataset with 6-fold cross validation
% Tab.4 方法 OA mAcc mIoU IoU ceiling floor wall beam column window door table chair sofa bookcase board clutter PointNet[4 ] 78.5 66.2 47.6 88.0 88.7 69.3 42.4 23.1 47.5 51.6 42.0 54.1 38.2 9.6 29.4 35.2 A-CNN[13 ] 87.3 − 62.9 92.4 96.4 79.2 59.5 34.2 56.3 65.0 66.5 78.0 28.5 56.9 48.0 56.8 PointCNN[10 ] 88.1 75.6 65.4 94.8 97.3 75.8 63.3 51.7 58.4 57.2 71.6 69.1 39.1 61.2 52.2 58.6 PointWeb[14 ] 87.3 76.2 66.7 93.5 94.2 80.8 52.4 41.3 64.9 68.1 71.4 67.1 50.3 62.7 62.2 58.5 PointASNL[21 ] 88.8 79.0 68.7 95.3 97.9 81.9 47.0 48.0 67.3 70.5 71.3 77.8 50.7 60.4 63.0 62.8 本研究 88.2 78.7 68.3 95.1 97.3 81.2 47.4 45.8 67.0 69.1 72.1 77.5 50.6 60.8 62.4 61.6
将CAF模型用于中间特征通道权值重分配时,在语义分割任务中的表现不及分类任务.语义分割任务更艰巨,数据集更复杂,针对语义分割的研究也是三维点云深度网络的重要研究方向,如何应用CAF模型提高语义分割性能有待进一步研究. ...
1
... 原始三维数据能展现物体的立体表征,将三维点云作为输入避免了在卷积网络中输入多视图、体素这类规则化数据造成不必要的体积划分和对点云数据不变性的影响. 受采集设备及坐标系影响,三维点云数据的排列顺序差别很大. 针对无序点云数据的分类和分割问题,Qi等[4 ] 提出PointNet网络,直接处理稀疏的非结构化点云. Qi等[5 ] 以PointNet为基础,对点云下采样和分组,提出PointNet++. PCPNet[6 ] 是基于PointNet体系的一种新颖的多尺度变体,采用基于补丁的学习方法. Shen等[7 ] 更有效地利用局部结构改进PointNet,在最近邻图上进行递归特征聚合获得局部高维特征. SO-Net[8 ] 通过自组织映射(self-organizing map,SOM)算法获得关键特征点,通过PointNet模块获取包含空间信息的模型描述子. Qi等[9 ] 利用二维目标检测算法将三维模型检测范围缩小到视锥中,用PointNet获得高维特征. Li等[10 ] 提出PointCNN,引入 X-Conv 转换方式实现无序点云的潜在规则化. DensePoint[11 ] 通过泛化卷积算子将规则网格CNN扩展到不规则点配置. Point2Sequence[12 ] 使用注意力机制聚合不同局部区域的信息. A-CNN[13 ] 根据特征与局部中心点的不同距离信息,通过环形卷积分别编码. PointWeb[14 ] 关联局部区域中的每组点对得到更有表达力的局部特征. 其他一些工作介绍了用图卷积网络学习局部图[15 -16 ] 或几何元素[17 ] ,提取点云局部特征. 注意力机制[18 ] 计算特征之间的相关程度. 二维图像处理常用的注意力机制有SE模块[19 ] . 三维点云网络中,PVNet[20 ] 嵌入注意力融合模块将中间特征与全局特征融合. PointASNL[21 ] 使用通用自注意力机制在自适应采样模块中进行组内特征更新. 在对深度三维点云分类网络的研究中,优化特征提取能力和提高对点云扰动、离群值、随机噪声等干扰因素的抵抗能力是研究热点,对三维点云分类任务及其应用具有十分重要的影响. ...
1
... 原始三维数据能展现物体的立体表征,将三维点云作为输入避免了在卷积网络中输入多视图、体素这类规则化数据造成不必要的体积划分和对点云数据不变性的影响. 受采集设备及坐标系影响,三维点云数据的排列顺序差别很大. 针对无序点云数据的分类和分割问题,Qi等[4 ] 提出PointNet网络,直接处理稀疏的非结构化点云. Qi等[5 ] 以PointNet为基础,对点云下采样和分组,提出PointNet++. PCPNet[6 ] 是基于PointNet体系的一种新颖的多尺度变体,采用基于补丁的学习方法. Shen等[7 ] 更有效地利用局部结构改进PointNet,在最近邻图上进行递归特征聚合获得局部高维特征. SO-Net[8 ] 通过自组织映射(self-organizing map,SOM)算法获得关键特征点,通过PointNet模块获取包含空间信息的模型描述子. Qi等[9 ] 利用二维目标检测算法将三维模型检测范围缩小到视锥中,用PointNet获得高维特征. Li等[10 ] 提出PointCNN,引入 X-Conv 转换方式实现无序点云的潜在规则化. DensePoint[11 ] 通过泛化卷积算子将规则网格CNN扩展到不规则点配置. Point2Sequence[12 ] 使用注意力机制聚合不同局部区域的信息. A-CNN[13 ] 根据特征与局部中心点的不同距离信息,通过环形卷积分别编码. PointWeb[14 ] 关联局部区域中的每组点对得到更有表达力的局部特征. 其他一些工作介绍了用图卷积网络学习局部图[15 -16 ] 或几何元素[17 ] ,提取点云局部特征. 注意力机制[18 ] 计算特征之间的相关程度. 二维图像处理常用的注意力机制有SE模块[19 ] . 三维点云网络中,PVNet[20 ] 嵌入注意力融合模块将中间特征与全局特征融合. PointASNL[21 ] 使用通用自注意力机制在自适应采样模块中进行组内特征更新. 在对深度三维点云分类网络的研究中,优化特征提取能力和提高对点云扰动、离群值、随机噪声等干扰因素的抵抗能力是研究热点,对三维点云分类任务及其应用具有十分重要的影响. ...
1
... 原始三维数据能展现物体的立体表征,将三维点云作为输入避免了在卷积网络中输入多视图、体素这类规则化数据造成不必要的体积划分和对点云数据不变性的影响. 受采集设备及坐标系影响,三维点云数据的排列顺序差别很大. 针对无序点云数据的分类和分割问题,Qi等[4 ] 提出PointNet网络,直接处理稀疏的非结构化点云. Qi等[5 ] 以PointNet为基础,对点云下采样和分组,提出PointNet++. PCPNet[6 ] 是基于PointNet体系的一种新颖的多尺度变体,采用基于补丁的学习方法. Shen等[7 ] 更有效地利用局部结构改进PointNet,在最近邻图上进行递归特征聚合获得局部高维特征. SO-Net[8 ] 通过自组织映射(self-organizing map,SOM)算法获得关键特征点,通过PointNet模块获取包含空间信息的模型描述子. Qi等[9 ] 利用二维目标检测算法将三维模型检测范围缩小到视锥中,用PointNet获得高维特征. Li等[10 ] 提出PointCNN,引入 X-Conv 转换方式实现无序点云的潜在规则化. DensePoint[11 ] 通过泛化卷积算子将规则网格CNN扩展到不规则点配置. Point2Sequence[12 ] 使用注意力机制聚合不同局部区域的信息. A-CNN[13 ] 根据特征与局部中心点的不同距离信息,通过环形卷积分别编码. PointWeb[14 ] 关联局部区域中的每组点对得到更有表达力的局部特征. 其他一些工作介绍了用图卷积网络学习局部图[15 -16 ] 或几何元素[17 ] ,提取点云局部特征. 注意力机制[18 ] 计算特征之间的相关程度. 二维图像处理常用的注意力机制有SE模块[19 ] . 三维点云网络中,PVNet[20 ] 嵌入注意力融合模块将中间特征与全局特征融合. PointASNL[21 ] 使用通用自注意力机制在自适应采样模块中进行组内特征更新. 在对深度三维点云分类网络的研究中,优化特征提取能力和提高对点云扰动、离群值、随机噪声等干扰因素的抵抗能力是研究热点,对三维点云分类任务及其应用具有十分重要的影响. ...
1
... 原始三维数据能展现物体的立体表征,将三维点云作为输入避免了在卷积网络中输入多视图、体素这类规则化数据造成不必要的体积划分和对点云数据不变性的影响. 受采集设备及坐标系影响,三维点云数据的排列顺序差别很大. 针对无序点云数据的分类和分割问题,Qi等[4 ] 提出PointNet网络,直接处理稀疏的非结构化点云. Qi等[5 ] 以PointNet为基础,对点云下采样和分组,提出PointNet++. PCPNet[6 ] 是基于PointNet体系的一种新颖的多尺度变体,采用基于补丁的学习方法. Shen等[7 ] 更有效地利用局部结构改进PointNet,在最近邻图上进行递归特征聚合获得局部高维特征. SO-Net[8 ] 通过自组织映射(self-organizing map,SOM)算法获得关键特征点,通过PointNet模块获取包含空间信息的模型描述子. Qi等[9 ] 利用二维目标检测算法将三维模型检测范围缩小到视锥中,用PointNet获得高维特征. Li等[10 ] 提出PointCNN,引入 X-Conv 转换方式实现无序点云的潜在规则化. DensePoint[11 ] 通过泛化卷积算子将规则网格CNN扩展到不规则点配置. Point2Sequence[12 ] 使用注意力机制聚合不同局部区域的信息. A-CNN[13 ] 根据特征与局部中心点的不同距离信息,通过环形卷积分别编码. PointWeb[14 ] 关联局部区域中的每组点对得到更有表达力的局部特征. 其他一些工作介绍了用图卷积网络学习局部图[15 -16 ] 或几何元素[17 ] ,提取点云局部特征. 注意力机制[18 ] 计算特征之间的相关程度. 二维图像处理常用的注意力机制有SE模块[19 ] . 三维点云网络中,PVNet[20 ] 嵌入注意力融合模块将中间特征与全局特征融合. PointASNL[21 ] 使用通用自注意力机制在自适应采样模块中进行组内特征更新. 在对深度三维点云分类网络的研究中,优化特征提取能力和提高对点云扰动、离群值、随机噪声等干扰因素的抵抗能力是研究热点,对三维点云分类任务及其应用具有十分重要的影响. ...
2
... 原始三维数据能展现物体的立体表征,将三维点云作为输入避免了在卷积网络中输入多视图、体素这类规则化数据造成不必要的体积划分和对点云数据不变性的影响. 受采集设备及坐标系影响,三维点云数据的排列顺序差别很大. 针对无序点云数据的分类和分割问题,Qi等[4 ] 提出PointNet网络,直接处理稀疏的非结构化点云. Qi等[5 ] 以PointNet为基础,对点云下采样和分组,提出PointNet++. PCPNet[6 ] 是基于PointNet体系的一种新颖的多尺度变体,采用基于补丁的学习方法. Shen等[7 ] 更有效地利用局部结构改进PointNet,在最近邻图上进行递归特征聚合获得局部高维特征. SO-Net[8 ] 通过自组织映射(self-organizing map,SOM)算法获得关键特征点,通过PointNet模块获取包含空间信息的模型描述子. Qi等[9 ] 利用二维目标检测算法将三维模型检测范围缩小到视锥中,用PointNet获得高维特征. Li等[10 ] 提出PointCNN,引入 X-Conv 转换方式实现无序点云的潜在规则化. DensePoint[11 ] 通过泛化卷积算子将规则网格CNN扩展到不规则点配置. Point2Sequence[12 ] 使用注意力机制聚合不同局部区域的信息. A-CNN[13 ] 根据特征与局部中心点的不同距离信息,通过环形卷积分别编码. PointWeb[14 ] 关联局部区域中的每组点对得到更有表达力的局部特征. 其他一些工作介绍了用图卷积网络学习局部图[15 -16 ] 或几何元素[17 ] ,提取点云局部特征. 注意力机制[18 ] 计算特征之间的相关程度. 二维图像处理常用的注意力机制有SE模块[19 ] . 三维点云网络中,PVNet[20 ] 嵌入注意力融合模块将中间特征与全局特征融合. PointASNL[21 ] 使用通用自注意力机制在自适应采样模块中进行组内特征更新. 在对深度三维点云分类网络的研究中,优化特征提取能力和提高对点云扰动、离群值、随机噪声等干扰因素的抵抗能力是研究热点,对三维点云分类任务及其应用具有十分重要的影响. ...
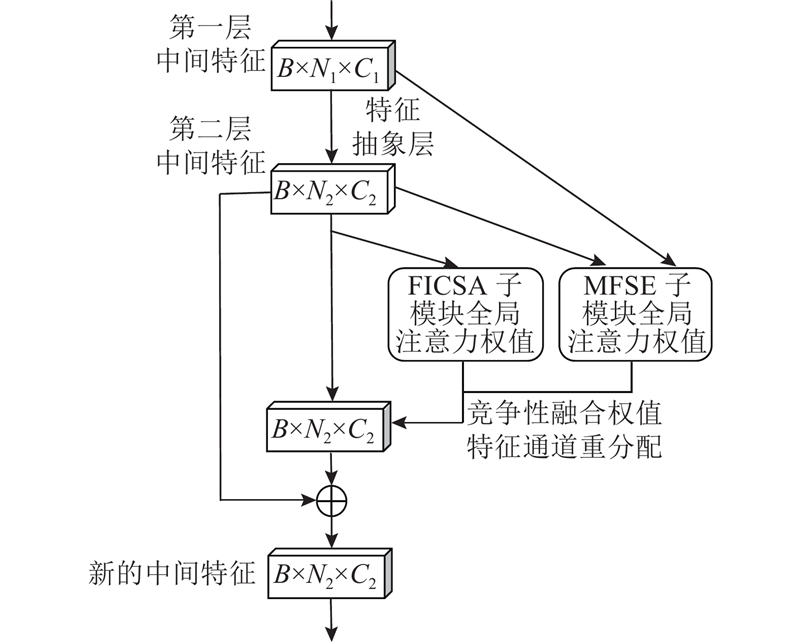
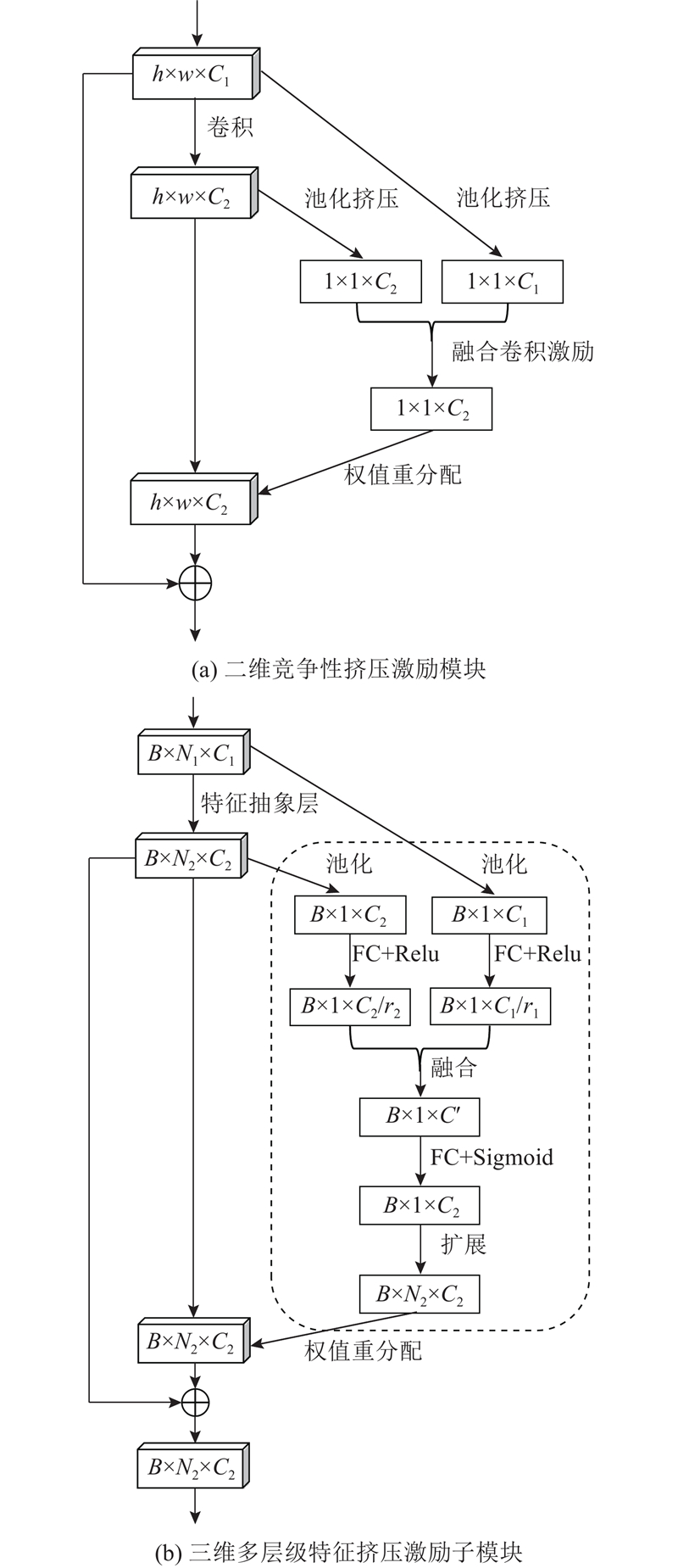
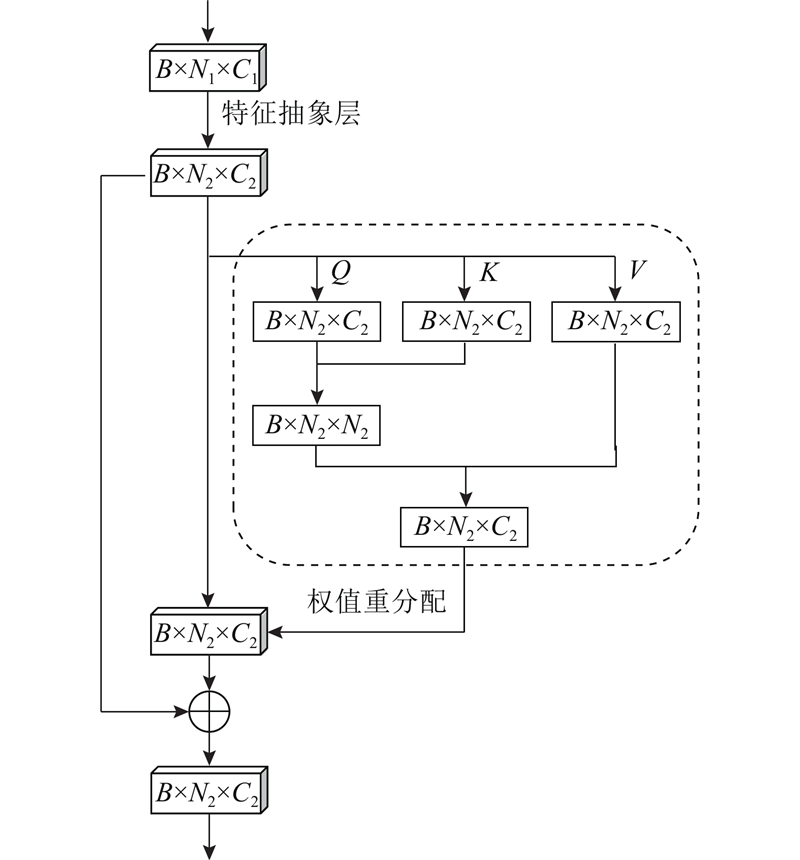
... 在二维图像分类任务中,挤压激励网络 (squeeze-excitation net,SE-Net)[19 ] 表现卓越,二维注意力机制SE模块基于通道之间的关联自适应地调整通道特征,将SE模块作为独立结构加入多种二维分类网络中能提高网络分类精度.竞争性挤压激励模块 (competitive squeeze-excitation, CMPE-SE)[22 ] 为了实现更好的映射结构,在SE模块基础上通过合并残差映射和恒等映射的竞争关系,实现二维图像内部特征的重成像,根据具体任务要求,可并列合并或是卷积合并中间融合特征通道,如图2 (a)所示. 图中,h 、w 、 ${C_i}$
1
... 原始三维数据能展现物体的立体表征,将三维点云作为输入避免了在卷积网络中输入多视图、体素这类规则化数据造成不必要的体积划分和对点云数据不变性的影响. 受采集设备及坐标系影响,三维点云数据的排列顺序差别很大. 针对无序点云数据的分类和分割问题,Qi等[4 ] 提出PointNet网络,直接处理稀疏的非结构化点云. Qi等[5 ] 以PointNet为基础,对点云下采样和分组,提出PointNet++. PCPNet[6 ] 是基于PointNet体系的一种新颖的多尺度变体,采用基于补丁的学习方法. Shen等[7 ] 更有效地利用局部结构改进PointNet,在最近邻图上进行递归特征聚合获得局部高维特征. SO-Net[8 ] 通过自组织映射(self-organizing map,SOM)算法获得关键特征点,通过PointNet模块获取包含空间信息的模型描述子. Qi等[9 ] 利用二维目标检测算法将三维模型检测范围缩小到视锥中,用PointNet获得高维特征. Li等[10 ] 提出PointCNN,引入 X-Conv 转换方式实现无序点云的潜在规则化. DensePoint[11 ] 通过泛化卷积算子将规则网格CNN扩展到不规则点配置. Point2Sequence[12 ] 使用注意力机制聚合不同局部区域的信息. A-CNN[13 ] 根据特征与局部中心点的不同距离信息,通过环形卷积分别编码. PointWeb[14 ] 关联局部区域中的每组点对得到更有表达力的局部特征. 其他一些工作介绍了用图卷积网络学习局部图[15 -16 ] 或几何元素[17 ] ,提取点云局部特征. 注意力机制[18 ] 计算特征之间的相关程度. 二维图像处理常用的注意力机制有SE模块[19 ] . 三维点云网络中,PVNet[20 ] 嵌入注意力融合模块将中间特征与全局特征融合. PointASNL[21 ] 使用通用自注意力机制在自适应采样模块中进行组内特征更新. 在对深度三维点云分类网络的研究中,优化特征提取能力和提高对点云扰动、离群值、随机噪声等干扰因素的抵抗能力是研究热点,对三维点云分类任务及其应用具有十分重要的影响. ...
8
... 原始三维数据能展现物体的立体表征,将三维点云作为输入避免了在卷积网络中输入多视图、体素这类规则化数据造成不必要的体积划分和对点云数据不变性的影响. 受采集设备及坐标系影响,三维点云数据的排列顺序差别很大. 针对无序点云数据的分类和分割问题,Qi等[4 ] 提出PointNet网络,直接处理稀疏的非结构化点云. Qi等[5 ] 以PointNet为基础,对点云下采样和分组,提出PointNet++. PCPNet[6 ] 是基于PointNet体系的一种新颖的多尺度变体,采用基于补丁的学习方法. Shen等[7 ] 更有效地利用局部结构改进PointNet,在最近邻图上进行递归特征聚合获得局部高维特征. SO-Net[8 ] 通过自组织映射(self-organizing map,SOM)算法获得关键特征点,通过PointNet模块获取包含空间信息的模型描述子. Qi等[9 ] 利用二维目标检测算法将三维模型检测范围缩小到视锥中,用PointNet获得高维特征. Li等[10 ] 提出PointCNN,引入 X-Conv 转换方式实现无序点云的潜在规则化. DensePoint[11 ] 通过泛化卷积算子将规则网格CNN扩展到不规则点配置. Point2Sequence[12 ] 使用注意力机制聚合不同局部区域的信息. A-CNN[13 ] 根据特征与局部中心点的不同距离信息,通过环形卷积分别编码. PointWeb[14 ] 关联局部区域中的每组点对得到更有表达力的局部特征. 其他一些工作介绍了用图卷积网络学习局部图[15 -16 ] 或几何元素[17 ] ,提取点云局部特征. 注意力机制[18 ] 计算特征之间的相关程度. 二维图像处理常用的注意力机制有SE模块[19 ] . 三维点云网络中,PVNet[20 ] 嵌入注意力融合模块将中间特征与全局特征融合. PointASNL[21 ] 使用通用自注意力机制在自适应采样模块中进行组内特征更新. 在对深度三维点云分类网络的研究中,优化特征提取能力和提高对点云扰动、离群值、随机噪声等干扰因素的抵抗能力是研究热点,对三维点云分类任务及其应用具有十分重要的影响. ...
... 在PointASNL中加入CAF模块,只输入坐标点时,分类精度为92.9%(92.88%),不低于文献[21 ]中的92.9%(实际测试最优分类精度为92.85%);训练和测试中加入法线向量时,分类精度为93.2%(93.19%),不低于文献[21 ]中的93.2%(实际测试最优分类精度为93.15%),如表1 所示.表中,N in 为输入点数,Acc为分类精度,Pnt为输入三维点云坐标数据,Noml为输入三维点云法线向量. 实验结果证明CAF模块具有独立性和可迁移性,并对保持分类精度有一定帮助. ...
... ]中的92.9%(实际测试最优分类精度为92.85%);训练和测试中加入法线向量时,分类精度为93.2%(93.19%),不低于文献[21 ]中的93.2%(实际测试最优分类精度为93.15%),如表1 所示.表中,N in 为输入点数,Acc为分类精度,Pnt为输入三维点云坐标数据,Noml为输入三维点云法线向量. 实验结果证明CAF模块具有独立性和可迁移性,并对保持分类精度有一定帮助. ...
... Average classification accuracy on ModelNet40 dataset
Tab.1 方法 输入 N in /103 Acc/% PointNet[4 ] Pnt 1 89.2 SO-Net[8 ] Pnt,Noml 2 90.9 PointNet++[5 ] Pnt,Noml 5 91.9 PointCNN[10] Pnt 1 92.2 Point2Sequence[12 ] Pnt 1 92.6 A-CNN[13 ] Pnt,Noml 1 92.6 PointASNL[21 ] Pnt 1 92.9(92.85) PointASNL[21 ] Pnt,Noml 1 93.2(93.15) 本研究 Pnt 1 92.9(92.88) 本研究 Pnt,Noml 1 93.2(93.19)
3.2. 鲁棒性分析 CAF模块对分类网络最大的贡献在于提高模型对噪声干扰的抵抗力,增强模型的鲁棒性.许多分类模型仅考虑完整点云数据集上的性能,未考虑实际情况中极大可能存在随机背景噪声和扰动,因此一些具有优秀分类性能的模型并不一定具备较强的抗干扰能力. ...
... [
21 ]
Pnt,Noml 1 93.2(93.15) 本研究 Pnt 1 92.9(92.88) 本研究 Pnt,Noml 1 93.2(93.19) 3.2. 鲁棒性分析 CAF模块对分类网络最大的贡献在于提高模型对噪声干扰的抵抗力,增强模型的鲁棒性.许多分类模型仅考虑完整点云数据集上的性能,未考虑实际情况中极大可能存在随机背景噪声和扰动,因此一些具有优秀分类性能的模型并不一定具备较强的抗干扰能力. ...
... 为了进一步实验CAF模块对模型鲁棒性的影响,参照PointASNL[21 ] 和KCNet[7 ] 中测试模型鲁棒性的方法,将一定数量的原始点集替换为 ${x、y、z \in}{[-1.0,1.0]} $ n 分别为0、1、10、50、100. ...
... Part segmentation performance on ShapeNetPart dataset
% Tab.3 方法 mIoU IoU areo bag cap car chair ear phone guitar knife lamp laptop motor mug pistol rocket skate board table PointNet[4 ] 83.7 83.4 78.7 82.5 74.9 89.6 73.0 91.5 85.9 80.8 95.3 65.2 93.0 81.2 57.9 72.8 80.6 SO-Net[8 ] 84.9 82.8 77.8 88.0 77.3 90.6 73.5 90.7 83.9 82.8 94.8 69.1 94.2 80.9 53.1 72.9 83.0 PointNet++[5 ] 85.1 82.4 79.0 87.7 77.3 90.8 71.8 91.0 85.9 83.7 95.3 71.6 94.1 81.3 58.7 76.4 82.6 P2Sequence[12 ] 85.2 82.6 81.8 87.5 77.3 90.8 77.1 91.1 86.9 83.9 95.7 70.8 94.6 79.3 58.1 75.2 82.8 PointCNN[10 ] 86.1 84.1 86.5 86.0 80.8 90.6 79.7 92.3 88.4 85.3 96.1 77.2 95.2 84.2 64.2 80.0 83.0 PointASNL[21 ] 86.1 84.1 84.7 87.9 79.7 92.2 73.7 91.0 87.2 84.2 95.8 74.4 95.2 81.0 63.0 76.3 83.2 本研究 85.9 84.2 83.2 87.4 79.2 91.9 74.3 91.5 86.4 84.3 95.7 73.7 95.4 82.6 62.4 75.0 82.7
在室内场景数据集S3DIS[24 ] 上进行语义场景分割,包括从3个建筑的6个区域中获得的271个房间,每个点都有一个语义标签将其划分为13类物体之一. 实验在6个区域上采用6折交叉验证比较平均交并比,实验结果如表4 所示. 结果显示本实验场景分割性能略低于基准模型,部分类别的交并比优于基准模型(beam、table、bookcase),其中OA为总体分类精度,mAcc为平均分类精度. ...
... Semantic segmentation performance on S3DIS dataset with 6-fold cross validation
% Tab.4 方法 OA mAcc mIoU IoU ceiling floor wall beam column window door table chair sofa bookcase board clutter PointNet[4 ] 78.5 66.2 47.6 88.0 88.7 69.3 42.4 23.1 47.5 51.6 42.0 54.1 38.2 9.6 29.4 35.2 A-CNN[13 ] 87.3 − 62.9 92.4 96.4 79.2 59.5 34.2 56.3 65.0 66.5 78.0 28.5 56.9 48.0 56.8 PointCNN[10 ] 88.1 75.6 65.4 94.8 97.3 75.8 63.3 51.7 58.4 57.2 71.6 69.1 39.1 61.2 52.2 58.6 PointWeb[14 ] 87.3 76.2 66.7 93.5 94.2 80.8 52.4 41.3 64.9 68.1 71.4 67.1 50.3 62.7 62.2 58.5 PointASNL[21 ] 88.8 79.0 68.7 95.3 97.9 81.9 47.0 48.0 67.3 70.5 71.3 77.8 50.7 60.4 63.0 62.8 本研究 88.2 78.7 68.3 95.1 97.3 81.2 47.4 45.8 67.0 69.1 72.1 77.5 50.6 60.8 62.4 61.6
将CAF模型用于中间特征通道权值重分配时,在语义分割任务中的表现不及分类任务.语义分割任务更艰巨,数据集更复杂,针对语义分割的研究也是三维点云深度网络的重要研究方向,如何应用CAF模型提高语义分割性能有待进一步研究. ...
1
... 在二维图像分类任务中,挤压激励网络 (squeeze-excitation net,SE-Net)[19 ] 表现卓越,二维注意力机制SE模块基于通道之间的关联自适应地调整通道特征,将SE模块作为独立结构加入多种二维分类网络中能提高网络分类精度.竞争性挤压激励模块 (competitive squeeze-excitation, CMPE-SE)[22 ] 为了实现更好的映射结构,在SE模块基础上通过合并残差映射和恒等映射的竞争关系,实现二维图像内部特征的重成像,根据具体任务要求,可并列合并或是卷积合并中间融合特征通道,如图2 (a)所示. 图中,h 、w 、 ${C_i}$
A scalable active framework for region annotation in 3D shape collections
1
2016
... 在数据集ShapeNet Part[23 ] 上进行语义零件分割,包括16个类别,50个零件,共计16 881个样本. 随机采样2 048个点作为输入,批处理大小为16,实验结果如表3 所示. 结果显示本实验平均交并比mIoU接近基准网络水平,在部分类别上的分割性能(交并比IoU)优于基准模型(areo、earphone、guitar、lamp、mug、pistol). ...
1
... 在室内场景数据集S3DIS[24 ] 上进行语义场景分割,包括从3个建筑的6个区域中获得的271个房间,每个点都有一个语义标签将其划分为13类物体之一. 实验在6个区域上采用6折交叉验证比较平均交并比,实验结果如表4 所示. 结果显示本实验场景分割性能略低于基准模型,部分类别的交并比优于基准模型(beam、table、bookcase),其中OA为总体分类精度,mAcc为平均分类精度. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}