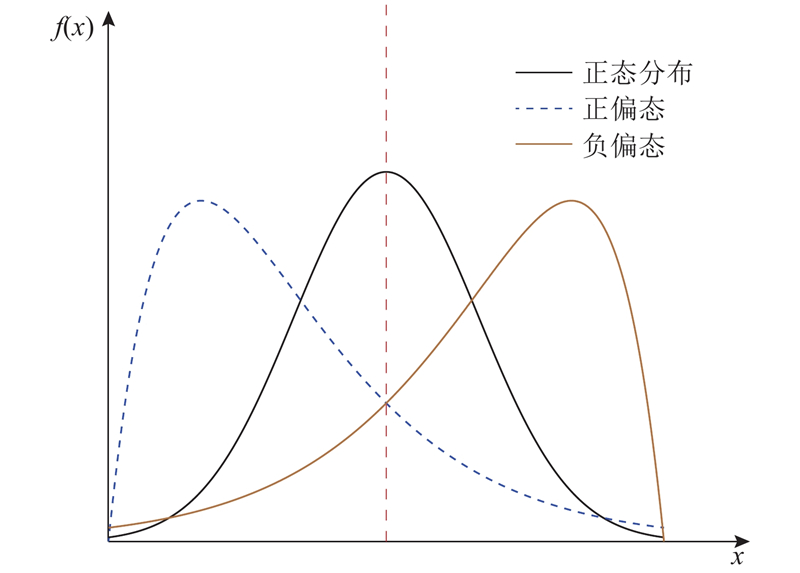
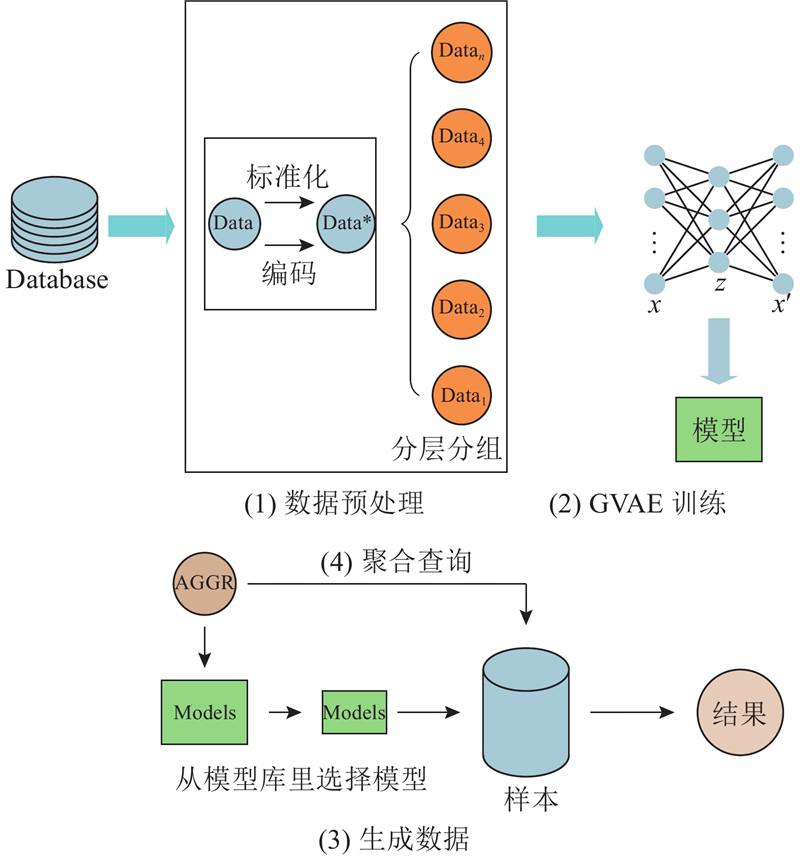
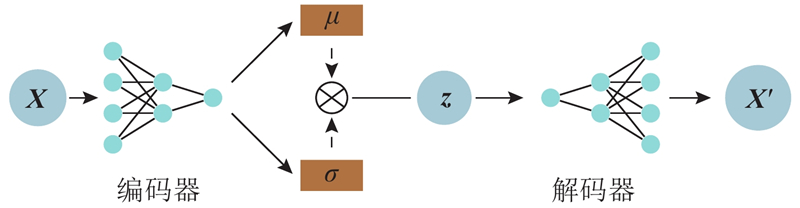
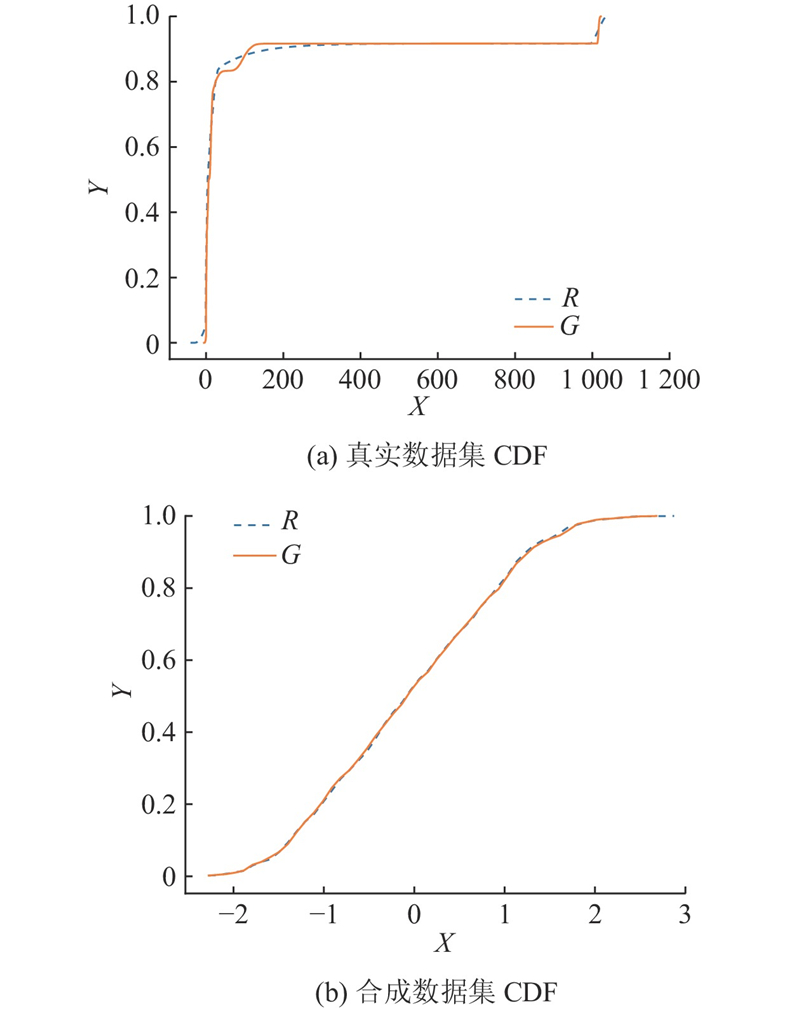
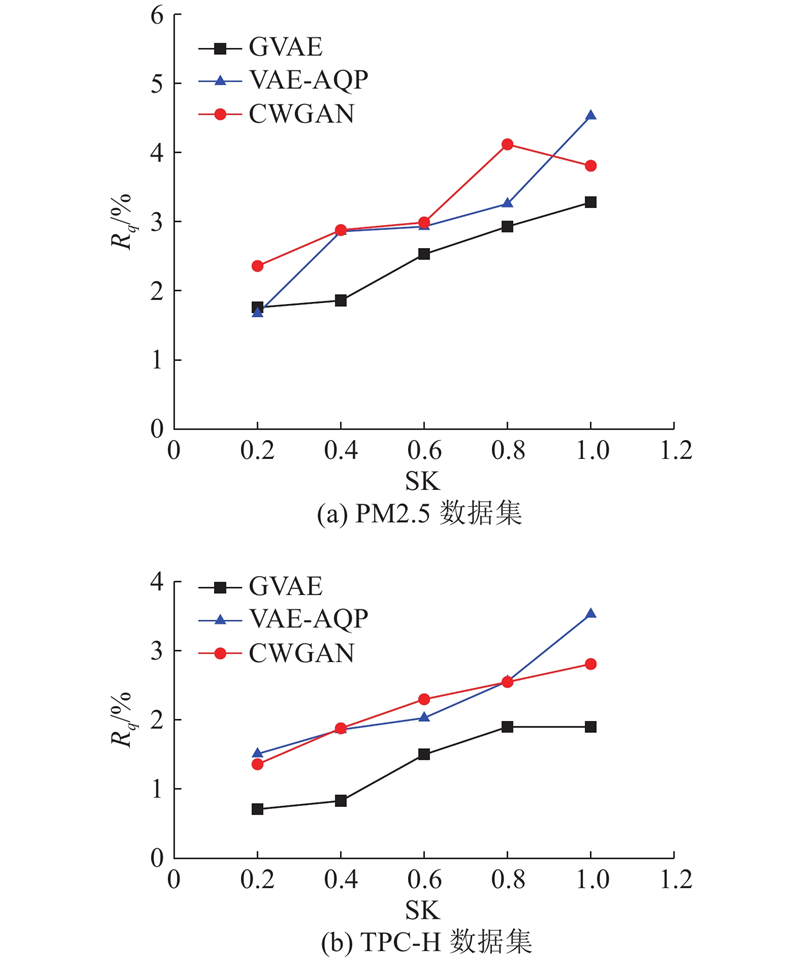
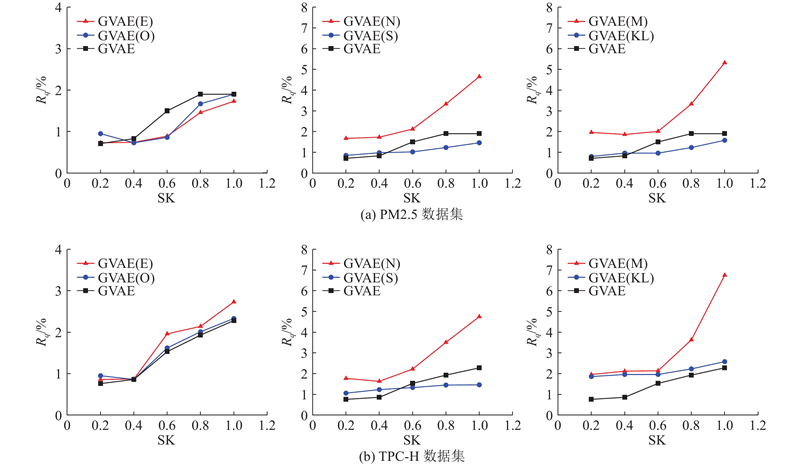
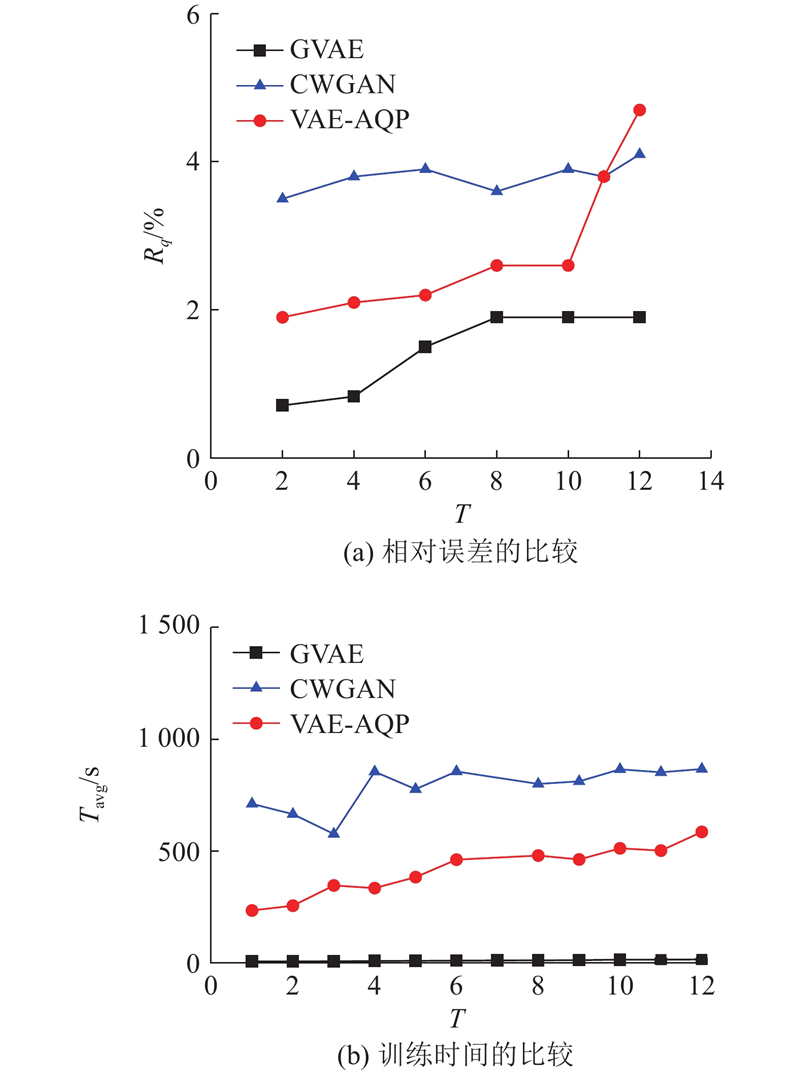
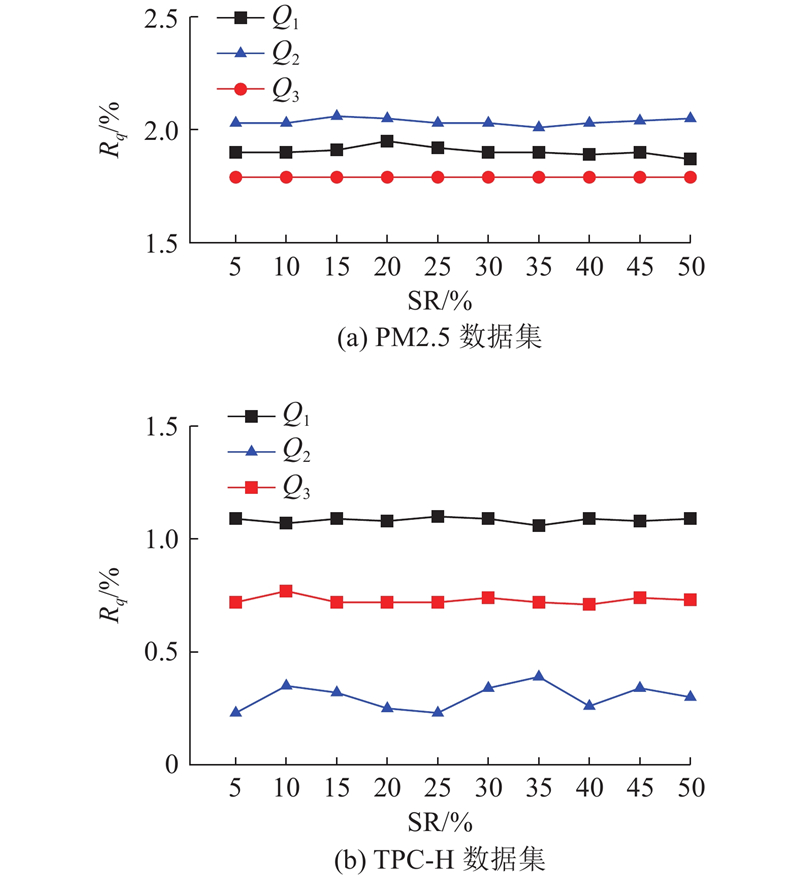
| 计算机技术、通信技术 |
|

|
|
|
| 基于变分自编码器的近似聚合查询优化方法 |
黄龙森1,2( ),房俊1,2,*(),周云亮1,2,郭志城1,2 ),房俊1,2,*(),周云亮1,2,郭志城1,2 |
1. 北方工业大学 信息学院,北京 100144
2. 北方工业大学 大规模流数据集成与分析技术北京市重点实验室,北京 100144 |
|
| Optimization method of approximate aggregate query based on variational auto-encoder |
| Longsen HUANG1,2(),Jun FANG1,2,*(),Yunliang ZHOU1,2,Zhicheng GUO1,2 |
1. College of Information, North China University of Technology, Beijing 100144, China
2. Beijing Key Laboratory on Integration and Analysis of Large-scale Stream Data, North China University of Technology, Beijing 100144, China |
引用本文:
黄龙森,房俊,周云亮,郭志城. 基于变分自编码器的近似聚合查询优化方法[J]. 浙江大学学报(工学版), 2024, 58(5): 931-940.
Longsen HUANG,Jun FANG,Yunliang ZHOU,Zhicheng GUO. Optimization method of approximate aggregate query based on variational auto-encoder. Journal of ZheJiang University (Engineering Science), 2024, 58(5): 931-940.
链接本文:
https://www.zjujournals.com/eng/CN/10.3785/j.issn.1008-973X.2024.05.006
或
https://www.zjujournals.com/eng/CN/Y2024/V58/I5/931
|
| 1 |
CHAUDURI S, DING B, KANDULA S. Approximate query processing: no silver bullet [C]// Proceedings of the 2017 ACM International Conference on Management of Data . New York: ACM, 2017: 511-519.
|
| 2 |
ZHANG Meifan, WANG Hongzhi LAQP: learning-based approximate query processing[J]. Information Sciences, 2021, 546: 1113- 1134
doi: 10.1016/j.ins.2020.09.070
|
| 3 |
LI Kaiyu, LI Guoliang. Approximate query processing: what is new and where to go? a survey on approximate query processing [J]. Data Science and Engineering , 2018: 379-397.
|
| 4 |
SANCA V, AILAMAKI A. Sampling-based AQP in modern analytical engines [C]// Proceedings of the 18th International Workshop on Data Management on New Hardware . New York: ACM, 2022: 1-8.
|
| 5 |
MA Qingzhi, TRIANTAFILLOU P. Dbest: revisiting approximate query processing engines with machine learning models [C]// Proceedings of the 2019 International Conference on Management of Data . New York: ACM, 2019: 1553-1570.
|
| 6 |
MA Qingzhi, SHANGHOOSHABAD A M, ALMASI M, et al. Learned approximate query processing: make it light, accurate and fast [C]// Conference on Innovative Data Systems. New York: ACM, 2021.
|
| 7 |
HILPRECHT B, SCHMIDT A, KULESSA M, et al DeepDB: learn from data, not from queries![J]. Proceedings of the VLDB Endowment, 2020, 13 (7): 992- 1005
doi: 10.14778/3384345.3384349
|
| 8 |
LEE T, PARK C S, NAM K, et al. Query transformation for approximate query processing using synthetic data from deep generative models [C]// IEEE International Conference on Consumer Electronics-Asia . Yeosu: IEEE, 2022: 1-4.
|
| 9 |
SHEORAN N, MITRA S, PORWAL V, et al. Conditional generative model based predicate-aware query approximation [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Palo Alto: AAAI, 2022, 36(8): 8259-8266.
|
| 10 |
OLKEN F, ROTEM D. Simple random sampling from relational databases [C]// Proceedings of the 12th International Conference on Very Large Data Bases . San Francisco: Morgan Kaufmann Publishers Inc, 1986: 160-169.
|
| 11 |
PENG Jinglin, ZHANG Dongxiang, WANG Jiannan, et al. Aqp++ connecting approximate query processing with aggregate precomputation for interactive analytics [C]// Proceedings of the 2018 International Conference on Management of Data . New York: ACM, 2018: 1477-1492.
|
| 12 |
HASAN S, THIRUMURUGANATHAN S, AUGUSTINE J, et al. Deep learning models for selectivity estimation of multi-attribute queries [C]// Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data . New York: ACM, 2020: 1035-1050.
|
| 13 |
LI Feifei, WU Bin, YI Ke, et al. Wander join: online aggregation via random walks [C]// Proceedings of the 2016 International Conference on Management of Data . New York: ACM, 2016: 615-629.
|
| 14 |
CHAUDHURI S, DAYAL U Data warehousing and OLAP for decision support[J]. ACM Sigmod Record, 1997, 26 (2): 507- 508
doi: 10.1145/253262.253373
|
| 15 |
AGARWAL S, MOZAFARI B, PANDA A, et al. BlinkDB: queries with bounded errors and bounded response times on very large data [C]// Proceedings of the 8th ACM European conference on computer systems . New York: ACM, 2013: 29-42.
|
| 16 |
CORMODE G, GAROFALAKIS M, HAAS P J, et al Synopses for massive data: samples, histograms, wavelets, sketches[J]. Foundations and Trends in Databases, 2011, 4 (1-3): 1- 294
doi: 10.1561/1900000004
|
| 17 |
LI Kaiyu, ZHANG Yong, LI Guoliang, et al. Bounded approximate query processing [J]. IEEE Transactions on Knowledge and Data Engineering , 2019, 31(12): 2262-2276.
|
| 18 |
LEE T, NAM K, PARK C S, et al. Exploiting machine learning models for approximate query processing [C]// IEEE International Conference on Big Data . Osaka: IEEE, 2022: 6752-6754.
|
| 19 |
KINGMA D P, WELLING M. Auto-encoding variational Bayes [EB/OL]. (2013-12-20). https://doi.org/10.48550/arXiv.1312.6114.
|
| 20 |
GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets [EB/OL].[2023-10-14]. https://arxiv.org/abs/1406.2661.
|
| 21 |
THIRUMURUGANATHAN S, HASAN S, KOUDAS N, et al. Approximate query processing for data exploration using deep generative models [C]// IEEE 36th International Conference on Data Engineering . Los Alamitos: IEEE, 2020: 1309-1320.
|
| 22 |
ZHANG Meifang, WANG Hongzhi. Approximate query processing for group-by queries based on conditional generative models [EB/OL]. (2021-01-08). https://doi.org/10.48550/arXiv.2101.02914.
|
| 23 |
SEGLEN P O The skewness of science[J]. Journal of the American Society for Information Science, 1992, 43 (9): 628- 638
doi: 10.1002/(SICI)1097-4571(199210)43:9<628::AID-ASI5>3.0.CO;2-0
|
| 24 |
TSOUMAKAS G, KATAKIS I Multi-label classification: an overview[J]. International Journal of Data Warehousing and Mining, 2007, 3 (3): 1- 13
doi: 10.4018/jdwm.2007070101
|
| 25 |
FU Hao, LI Chunyuan, LIU Xiaodong, et al. Cyclical annealing schedule: a simple approach to mitigating KL vanishing [C]// Proceedings of NAACL-HLT . Stroudsburg: ACL, 2019: 240-250.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|