[1]
程德强, 寇旗旗, 江鹤, 等 全矿井智能视频分析关键技术综述
[J]. 工矿自动化 , 2023 , 49 (11 ): 1 - 21
[本文引用: 1]
CHENG Deqiang, KOU Qiqi, JIANG He, et al Overview of key technologies for mine-wide intelligent video analysis
[J]. Journal of Mine Automation , 2023 , 49 (11 ): 1 - 21
[本文引用: 1]
[2]
程健, 李昊, 马昆, 等 矿井视觉计算体系架构与关键技术
[J]. 煤炭科学技术 , 2023 , 51 (9 ): 202 - 218
CHENG Jian, LI Hao, MA Kun, et al Architecture and key technologies of coalmine underground vision computing
[J]. Coal Science and Technology , 2023 , 51 (9 ): 202 - 218
[3]
巩师鑫, 赵国瑞, 王飞 机器视觉感知理论与技术在煤炭工业领域应用进展综述
[J]. 工矿自动化 , 2023 , 49 (5 ): 7 - 21
[本文引用: 1]
GONG Shixin, ZHAO Guorui, WANG Fei Review on the application of machine vision perception theory and technology in coal industry
[J]. Journal of Mine Automation , 2023 , 49 (5 ): 7 - 21
[本文引用: 1]
[4]
WANG Gongxian, ZHANG Libin, SUN Hui, et al Longitudinal tear detection of conveyor belt under uneven light based on Haar-AdaBoost and Cascade algorithm
[J]. Measurement , 2021 , 16 (8 ): 108341
[本文引用: 1]
[5]
李曼, 段雍, 曹现刚, 等 煤矸分选机器人图像识别方法和系统
[J]. 煤炭学报 , 2020 , 45 (10 ): 3636 - 3644
[本文引用: 1]
LI Man, DUAN Yong, CAO Xiangang, et al Image identification method and system for coal and gangue sorting robot
[J]. Journal of China Coal Society , 2020 , 45 (10 ): 3636 - 3644
[本文引用: 1]
[6]
王志勇, 李路, 王建, 等 基于HOG特征的InSAR矿区开采沉陷盆地检测方法
[J]. 中国矿业大学学报 , 2021 , 50 (2 ): 404 - 410
[本文引用: 1]
WANG Zhiyong, LI Lu, WANG Jian, et al A method of detecting the subsidence basin from InSAR interferogram in mining area based on HOG features
[J]. Journal of China University of Mining and Technology , 2021 , 50 (2 ): 404 - 410
[本文引用: 1]
[7]
WANG Yuanbin, WANG Yujing, DANG Langfei Video detection of foreign objects on the surface of belt conveyor underground coal mine based on improved SSD
[J]. Journal of Ambient Intelligence and Humanized Computing , 2023 , 14 (5 ): 5507 - 5516
DOI:10.1007/s12652-020-02495-w
[本文引用: 1]
[8]
邹盛, 周李兵, 季亮, 等 基于图像融合和改进CornerNet-Squeeze的煤矿井下行人检测方法
[J]. 工矿自动化 , 2023 , 49 (2 ): 77 - 84
[本文引用: 1]
ZOU Sheng, ZHOU Libing, JI Liang, et al A pedestrian target detection method for underground coal mine based on image fusion and improved CornerNet-Squeeze
[J]. Journal of Mine Automation , 2023 , 49 (2 ): 77 - 84
[本文引用: 1]
[9]
ZHENG J H, WANG D Y, GENG Z X Real-time detection of safety hazards in coal mines utilizing an enhanced YOLOv3 algorithm
[J]. Traitement du Signal , 2023 , 40 (4 ): 1565 - 1572
DOI:10.18280/ts.400424
[本文引用: 1]
[10]
郭永存, 杨豚, 王爽 基于改进YOLOv4–Tiny的矿井电机车多目标实时检测
[J]. 工程科学与技术 , 2023 , 55 (5 ): 232 - 241
[本文引用: 1]
GUO Yongcun, YANG Tun, WANG Shuang Multi-object real-time detection of mine electric locomotive based on improved YOLOv4-Tiny
[J]. Advanced Engineering Sciences , 2023 , 55 (5 ): 232 - 241
[本文引用: 1]
[11]
WANG X, WANG S, GUO Y C, et al Multi-scale coal and gangue detection in dense state based on improved Mask RCNN
[J]. Measurement , 2023 , 22 (1 ): 113467
[本文引用: 1]
[12]
杨洋 AI智能视频识别分析技术在智能化掘进的研究与应用
[J]. 工矿自动化 , 2023 , 49 (Suppl.1 ): 26 - 28
[本文引用: 1]
YANG Yang Research and application of AI intelligent video recognition analysis technology in intelligent excavation
[J]. Journal of Mine Automation , 2023 , 49 (Suppl.1 ): 26 - 28
[本文引用: 1]
[13]
杜雨馨, 张贺, 王树臣, 等 综掘系统视觉处理技术研究现状及发展趋势
[J]. 工矿自动化 , 2023 , 49 (11 ): 22 - 38
[本文引用: 1]
DU Yuxin, ZHANG He, WANG Shuchen, et al Research status and development trend of visual processing technology for fully mechanized excavation systems
[J]. Journal of Mine Automation , 2023 , 49 (11 ): 22 - 38
[本文引用: 1]
[14]
张农, 袁钰鑫, 韩昌良, 等 基于Mask R-CNN的煤矿巷道掘进迎头裂隙检测与定位算法
[J]. 采矿与安全工程学报 , 2023 , 40 (5 ): 925 - 932
[本文引用: 1]
ZHANG Nong, YUAN Yuxin, HAN Changliang, et al Research on crack detection and localization for advancing face in coal mine roadways based on Mask R-CNN
[J]. Journal of Mining and Safety Engineering , 2023 , 40 (5 ): 925 - 932
[本文引用: 1]
[15]
SUN S, MA H, WANG K, et al Research on the detection method of coal mine roadway bolt mesh based on improved YOLOv7
[J]. Electronics , 2023 , 12 (14 ): 3050
DOI:10.3390/electronics12143050
[本文引用: 1]
[16]
张夫净, 王宏伟, 王浩然, 等 煤矿巷道支护钢带锚孔智能识别与定位
[J]. 工矿自动化 , 2022 , 48 (10 ): 76 - 81
[本文引用: 1]
ZHANG Fujing, WANG Hongwei, WANG Haoran, et al Intelligent identification and positioning of steel belt anchor hole in coal mine roadway support
[J]. Journal of Mine Automation , 2022 , 48 (10 ): 76 - 81
[本文引用: 1]
[17]
ZHAO D Y, SU G Y, CHENG G, et al Research on real-time perception method of key targets in the comprehensive excavation working face of coal mine
[J]. Measurement Science and Technology , 2023 , 35 (1 ): 015410
[本文引用: 1]
[18]
WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 7464-7475.
[本文引用: 2]
[19]
KRIZHEVSKY A, SUTSKEVER I, HINTON G E ImageNet classification with deep convolutional neural networks
[J]. Communications of the ACM , 2017 , 60 (6 ): 84 - 90
DOI:10.1145/3065386
[本文引用: 1]
[20]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770-778.
[本文引用: 1]
[21]
HOWARD A G, ZHU M, CHEN B, et al. Mobilenets: efficient convolutional neural networks for mobile vision applications [EB/OL]. (2017-04-17)[2024-05-22]. https://doi.org/10.48550/arXiv.1704.04861.
[本文引用: 1]
[22]
ZHANG X, ZHOU X, LIN M, et al. Shufflenet: an extremely efficient convolutional neural network for mobile devices [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 6848-6856.
[本文引用: 1]
[23]
NASCIMENTO M G, FAWCETT R, PRISACARIU V A. DSConv: efficient convolution operator [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 5148-5157.
[本文引用: 1]
[24]
HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 7132-7141.
[本文引用: 1]
[25]
WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// Proceedings of the European Conference on Computer Vision . Munich: Springer, 2018: 3-19.
[本文引用: 1]
[26]
LIU Y, SHAO Z. Global attention mechanism: retain information to enhance channel-spatial interactions [EB/OL]. (2021-12-10)[2024-05-22]. https://doi.org/10.48550/arXiv.2112.05561.
[本文引用: 1]
[27]
PAN X, GE C, LU R, et al. On the integration of self-attention and convolution [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Louisiana: IEEE, 2022: 815-825.
[本文引用: 1]
[28]
YANG L X, ZHANG R Y, LI L D, et al. SimAM: a simple, parameter-free attention module for convolutional neural networks [C]// Proceedings of the 38th International Conference on Machine Learning . New York: PMLR, 2021: 11863-11874.
[本文引用: 1]
[29]
BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: Optimal speed and accuracy of object detection [EB/OL]. (2020-04-23)[2024-05-22]. https://doi.org/10.48550/arXiv.2004.10934.
[本文引用: 1]
[30]
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 779-788.
[本文引用: 1]
[31]
REDMON J, FARHADI A. YOLO9000: better, faster, stronger [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Hawaii State: IEEE, 2017: 7263-7271.
[32]
FARHADI A, RENMON J. YOLOv3: an incremental improvement [C]// Computer Vision and Pattern Recognition. Berlin: Springer, 2018: 1-6.
[本文引用: 1]
[33]
REN S, HE K, GIRSHICK R, et al Faster R-CNN: towards real-time object detection with region proposal networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 39 (6 ): 1137 - 1149
DOI:10.1109/TPAMI.2016.2577031
[本文引用: 1]
[34]
LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C]// Proceedings of the European Conference on Computer Vision . Amsterdam: Springer, 2016: 21-37.
[35]
CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers [C]// Proceedings of the European Conference on Computer Vision . Glasgow: Springer, 2020: 213-229.
[36]
ZHOU X, WANG D, KRAHENBUHL P. Objects as points [EB/OL]. (2019-04-25)[2024-05-22]. https://doi.org/10.48550/arXiv.1904.07850.
[37]
GE Z, LIU S, WANG F, et al. YOLOX: exceeding yolo series in 2021 [EB/OL]. (2021-08-06)[2024-05-22]. https://doi.org/10.48550/arXiv. 2107.08430.
[本文引用: 1]
全矿井智能视频分析关键技术综述
1
2023
... 随着煤矿智能化建设的不断推进,针对煤矿井下人员、装备与环境的视觉感知需求日益迫切. 在煤矿复杂环境中,通过构建特定作业场景下的机器视觉感知模型,利用图像处理、特征提取、特征融合等技术对作业场景进行描述和反馈,以实现对关键装备与作业人员的行为识别、安全监测、风险预警等,对建设煤矿全面感知、实时互联、自主决策的智能化体系具有重要意义[1 -3 ] . ...
全矿井智能视频分析关键技术综述
1
2023
... 随着煤矿智能化建设的不断推进,针对煤矿井下人员、装备与环境的视觉感知需求日益迫切. 在煤矿复杂环境中,通过构建特定作业场景下的机器视觉感知模型,利用图像处理、特征提取、特征融合等技术对作业场景进行描述和反馈,以实现对关键装备与作业人员的行为识别、安全监测、风险预警等,对建设煤矿全面感知、实时互联、自主决策的智能化体系具有重要意义[1 -3 ] . ...
机器视觉感知理论与技术在煤炭工业领域应用进展综述
1
2023
... 随着煤矿智能化建设的不断推进,针对煤矿井下人员、装备与环境的视觉感知需求日益迫切. 在煤矿复杂环境中,通过构建特定作业场景下的机器视觉感知模型,利用图像处理、特征提取、特征融合等技术对作业场景进行描述和反馈,以实现对关键装备与作业人员的行为识别、安全监测、风险预警等,对建设煤矿全面感知、实时互联、自主决策的智能化体系具有重要意义[1 -3 ] . ...
机器视觉感知理论与技术在煤炭工业领域应用进展综述
1
2023
... 随着煤矿智能化建设的不断推进,针对煤矿井下人员、装备与环境的视觉感知需求日益迫切. 在煤矿复杂环境中,通过构建特定作业场景下的机器视觉感知模型,利用图像处理、特征提取、特征融合等技术对作业场景进行描述和反馈,以实现对关键装备与作业人员的行为识别、安全监测、风险预警等,对建设煤矿全面感知、实时互联、自主决策的智能化体系具有重要意义[1 -3 ] . ...
Longitudinal tear detection of conveyor belt under uneven light based on Haar-AdaBoost and Cascade algorithm
1
2021
... 近年来,基于视觉信息的目标检测技术已广泛应用于采煤、掘进、巡检等煤矿场景. 传统的目标检测模型利用人工设计特征[4 ] 和机器学习分类器[5 ] ,实现对目标的识别与定位[6 ] ,但该检测模型在矿井实际应用中存在复杂度高、参数量大、鲁棒性差、检测效率低等问题. 相较于传统的目标检测模型,在对象级特征提取与描述中,基于深度学习的目标检测模型凭借自适应特征学习[7 ] 、多尺度信息整合[8 ] 、端对端的高效网络训练方法[9 ] 等优势,逐步成为研究热点. 郭永存等[10 ] 提出基于YOLOv4-tiny-4S的煤矿电机车多目标检测模型,提升了电机车对行人、信号灯与碎石的实时检测精度. Wang等[11 ] 针对煤与矸石粘连与半遮档导致的识别精度降低难题,提出基于Mask RCNN的煤矸图像实例分割网络. 上述算法在工况条件良好的作业场景中检测效果较好,但在煤矿综掘工作面中,受光照不均、高粉尘的恶劣环境因素干扰,视频图像采集终端易出现成像模糊、色彩辨识度低、对比度差等问题,导致目标检测模型的性能急剧下降. 为了提升目标检测模型对煤矿复杂环境下关键目标的识别与定位能力[12 -13 ] ,国内外学者将图像增强算法、注意力机制、特征金字塔结构等与深度学习算法相结合[14 -15 ] . 张夫净等[16 ] 结合超分辨率重构技术、坐标注意力机制与YOLOv5s算法,实现了不同光照条件下掘进巷道支护钢带的锚孔识别与定位. Zhao等[17 ] 针对煤矿恶劣环境中的关键目标感知难题,采用密集连接卷积网络、加权双向特征金字塔网络,对YOLOv5s算法进行优化,实现了煤矿恶劣环境中的多目标实时检测任务. ...
煤矸分选机器人图像识别方法和系统
1
2020
... 近年来,基于视觉信息的目标检测技术已广泛应用于采煤、掘进、巡检等煤矿场景. 传统的目标检测模型利用人工设计特征[4 ] 和机器学习分类器[5 ] ,实现对目标的识别与定位[6 ] ,但该检测模型在矿井实际应用中存在复杂度高、参数量大、鲁棒性差、检测效率低等问题. 相较于传统的目标检测模型,在对象级特征提取与描述中,基于深度学习的目标检测模型凭借自适应特征学习[7 ] 、多尺度信息整合[8 ] 、端对端的高效网络训练方法[9 ] 等优势,逐步成为研究热点. 郭永存等[10 ] 提出基于YOLOv4-tiny-4S的煤矿电机车多目标检测模型,提升了电机车对行人、信号灯与碎石的实时检测精度. Wang等[11 ] 针对煤与矸石粘连与半遮档导致的识别精度降低难题,提出基于Mask RCNN的煤矸图像实例分割网络. 上述算法在工况条件良好的作业场景中检测效果较好,但在煤矿综掘工作面中,受光照不均、高粉尘的恶劣环境因素干扰,视频图像采集终端易出现成像模糊、色彩辨识度低、对比度差等问题,导致目标检测模型的性能急剧下降. 为了提升目标检测模型对煤矿复杂环境下关键目标的识别与定位能力[12 -13 ] ,国内外学者将图像增强算法、注意力机制、特征金字塔结构等与深度学习算法相结合[14 -15 ] . 张夫净等[16 ] 结合超分辨率重构技术、坐标注意力机制与YOLOv5s算法,实现了不同光照条件下掘进巷道支护钢带的锚孔识别与定位. Zhao等[17 ] 针对煤矿恶劣环境中的关键目标感知难题,采用密集连接卷积网络、加权双向特征金字塔网络,对YOLOv5s算法进行优化,实现了煤矿恶劣环境中的多目标实时检测任务. ...
煤矸分选机器人图像识别方法和系统
1
2020
... 近年来,基于视觉信息的目标检测技术已广泛应用于采煤、掘进、巡检等煤矿场景. 传统的目标检测模型利用人工设计特征[4 ] 和机器学习分类器[5 ] ,实现对目标的识别与定位[6 ] ,但该检测模型在矿井实际应用中存在复杂度高、参数量大、鲁棒性差、检测效率低等问题. 相较于传统的目标检测模型,在对象级特征提取与描述中,基于深度学习的目标检测模型凭借自适应特征学习[7 ] 、多尺度信息整合[8 ] 、端对端的高效网络训练方法[9 ] 等优势,逐步成为研究热点. 郭永存等[10 ] 提出基于YOLOv4-tiny-4S的煤矿电机车多目标检测模型,提升了电机车对行人、信号灯与碎石的实时检测精度. Wang等[11 ] 针对煤与矸石粘连与半遮档导致的识别精度降低难题,提出基于Mask RCNN的煤矸图像实例分割网络. 上述算法在工况条件良好的作业场景中检测效果较好,但在煤矿综掘工作面中,受光照不均、高粉尘的恶劣环境因素干扰,视频图像采集终端易出现成像模糊、色彩辨识度低、对比度差等问题,导致目标检测模型的性能急剧下降. 为了提升目标检测模型对煤矿复杂环境下关键目标的识别与定位能力[12 -13 ] ,国内外学者将图像增强算法、注意力机制、特征金字塔结构等与深度学习算法相结合[14 -15 ] . 张夫净等[16 ] 结合超分辨率重构技术、坐标注意力机制与YOLOv5s算法,实现了不同光照条件下掘进巷道支护钢带的锚孔识别与定位. Zhao等[17 ] 针对煤矿恶劣环境中的关键目标感知难题,采用密集连接卷积网络、加权双向特征金字塔网络,对YOLOv5s算法进行优化,实现了煤矿恶劣环境中的多目标实时检测任务. ...
基于HOG特征的InSAR矿区开采沉陷盆地检测方法
1
2021
... 近年来,基于视觉信息的目标检测技术已广泛应用于采煤、掘进、巡检等煤矿场景. 传统的目标检测模型利用人工设计特征[4 ] 和机器学习分类器[5 ] ,实现对目标的识别与定位[6 ] ,但该检测模型在矿井实际应用中存在复杂度高、参数量大、鲁棒性差、检测效率低等问题. 相较于传统的目标检测模型,在对象级特征提取与描述中,基于深度学习的目标检测模型凭借自适应特征学习[7 ] 、多尺度信息整合[8 ] 、端对端的高效网络训练方法[9 ] 等优势,逐步成为研究热点. 郭永存等[10 ] 提出基于YOLOv4-tiny-4S的煤矿电机车多目标检测模型,提升了电机车对行人、信号灯与碎石的实时检测精度. Wang等[11 ] 针对煤与矸石粘连与半遮档导致的识别精度降低难题,提出基于Mask RCNN的煤矸图像实例分割网络. 上述算法在工况条件良好的作业场景中检测效果较好,但在煤矿综掘工作面中,受光照不均、高粉尘的恶劣环境因素干扰,视频图像采集终端易出现成像模糊、色彩辨识度低、对比度差等问题,导致目标检测模型的性能急剧下降. 为了提升目标检测模型对煤矿复杂环境下关键目标的识别与定位能力[12 -13 ] ,国内外学者将图像增强算法、注意力机制、特征金字塔结构等与深度学习算法相结合[14 -15 ] . 张夫净等[16 ] 结合超分辨率重构技术、坐标注意力机制与YOLOv5s算法,实现了不同光照条件下掘进巷道支护钢带的锚孔识别与定位. Zhao等[17 ] 针对煤矿恶劣环境中的关键目标感知难题,采用密集连接卷积网络、加权双向特征金字塔网络,对YOLOv5s算法进行优化,实现了煤矿恶劣环境中的多目标实时检测任务. ...
基于HOG特征的InSAR矿区开采沉陷盆地检测方法
1
2021
... 近年来,基于视觉信息的目标检测技术已广泛应用于采煤、掘进、巡检等煤矿场景. 传统的目标检测模型利用人工设计特征[4 ] 和机器学习分类器[5 ] ,实现对目标的识别与定位[6 ] ,但该检测模型在矿井实际应用中存在复杂度高、参数量大、鲁棒性差、检测效率低等问题. 相较于传统的目标检测模型,在对象级特征提取与描述中,基于深度学习的目标检测模型凭借自适应特征学习[7 ] 、多尺度信息整合[8 ] 、端对端的高效网络训练方法[9 ] 等优势,逐步成为研究热点. 郭永存等[10 ] 提出基于YOLOv4-tiny-4S的煤矿电机车多目标检测模型,提升了电机车对行人、信号灯与碎石的实时检测精度. Wang等[11 ] 针对煤与矸石粘连与半遮档导致的识别精度降低难题,提出基于Mask RCNN的煤矸图像实例分割网络. 上述算法在工况条件良好的作业场景中检测效果较好,但在煤矿综掘工作面中,受光照不均、高粉尘的恶劣环境因素干扰,视频图像采集终端易出现成像模糊、色彩辨识度低、对比度差等问题,导致目标检测模型的性能急剧下降. 为了提升目标检测模型对煤矿复杂环境下关键目标的识别与定位能力[12 -13 ] ,国内外学者将图像增强算法、注意力机制、特征金字塔结构等与深度学习算法相结合[14 -15 ] . 张夫净等[16 ] 结合超分辨率重构技术、坐标注意力机制与YOLOv5s算法,实现了不同光照条件下掘进巷道支护钢带的锚孔识别与定位. Zhao等[17 ] 针对煤矿恶劣环境中的关键目标感知难题,采用密集连接卷积网络、加权双向特征金字塔网络,对YOLOv5s算法进行优化,实现了煤矿恶劣环境中的多目标实时检测任务. ...
Video detection of foreign objects on the surface of belt conveyor underground coal mine based on improved SSD
1
2023
... 近年来,基于视觉信息的目标检测技术已广泛应用于采煤、掘进、巡检等煤矿场景. 传统的目标检测模型利用人工设计特征[4 ] 和机器学习分类器[5 ] ,实现对目标的识别与定位[6 ] ,但该检测模型在矿井实际应用中存在复杂度高、参数量大、鲁棒性差、检测效率低等问题. 相较于传统的目标检测模型,在对象级特征提取与描述中,基于深度学习的目标检测模型凭借自适应特征学习[7 ] 、多尺度信息整合[8 ] 、端对端的高效网络训练方法[9 ] 等优势,逐步成为研究热点. 郭永存等[10 ] 提出基于YOLOv4-tiny-4S的煤矿电机车多目标检测模型,提升了电机车对行人、信号灯与碎石的实时检测精度. Wang等[11 ] 针对煤与矸石粘连与半遮档导致的识别精度降低难题,提出基于Mask RCNN的煤矸图像实例分割网络. 上述算法在工况条件良好的作业场景中检测效果较好,但在煤矿综掘工作面中,受光照不均、高粉尘的恶劣环境因素干扰,视频图像采集终端易出现成像模糊、色彩辨识度低、对比度差等问题,导致目标检测模型的性能急剧下降. 为了提升目标检测模型对煤矿复杂环境下关键目标的识别与定位能力[12 -13 ] ,国内外学者将图像增强算法、注意力机制、特征金字塔结构等与深度学习算法相结合[14 -15 ] . 张夫净等[16 ] 结合超分辨率重构技术、坐标注意力机制与YOLOv5s算法,实现了不同光照条件下掘进巷道支护钢带的锚孔识别与定位. Zhao等[17 ] 针对煤矿恶劣环境中的关键目标感知难题,采用密集连接卷积网络、加权双向特征金字塔网络,对YOLOv5s算法进行优化,实现了煤矿恶劣环境中的多目标实时检测任务. ...
基于图像融合和改进CornerNet-Squeeze的煤矿井下行人检测方法
1
2023
... 近年来,基于视觉信息的目标检测技术已广泛应用于采煤、掘进、巡检等煤矿场景. 传统的目标检测模型利用人工设计特征[4 ] 和机器学习分类器[5 ] ,实现对目标的识别与定位[6 ] ,但该检测模型在矿井实际应用中存在复杂度高、参数量大、鲁棒性差、检测效率低等问题. 相较于传统的目标检测模型,在对象级特征提取与描述中,基于深度学习的目标检测模型凭借自适应特征学习[7 ] 、多尺度信息整合[8 ] 、端对端的高效网络训练方法[9 ] 等优势,逐步成为研究热点. 郭永存等[10 ] 提出基于YOLOv4-tiny-4S的煤矿电机车多目标检测模型,提升了电机车对行人、信号灯与碎石的实时检测精度. Wang等[11 ] 针对煤与矸石粘连与半遮档导致的识别精度降低难题,提出基于Mask RCNN的煤矸图像实例分割网络. 上述算法在工况条件良好的作业场景中检测效果较好,但在煤矿综掘工作面中,受光照不均、高粉尘的恶劣环境因素干扰,视频图像采集终端易出现成像模糊、色彩辨识度低、对比度差等问题,导致目标检测模型的性能急剧下降. 为了提升目标检测模型对煤矿复杂环境下关键目标的识别与定位能力[12 -13 ] ,国内外学者将图像增强算法、注意力机制、特征金字塔结构等与深度学习算法相结合[14 -15 ] . 张夫净等[16 ] 结合超分辨率重构技术、坐标注意力机制与YOLOv5s算法,实现了不同光照条件下掘进巷道支护钢带的锚孔识别与定位. Zhao等[17 ] 针对煤矿恶劣环境中的关键目标感知难题,采用密集连接卷积网络、加权双向特征金字塔网络,对YOLOv5s算法进行优化,实现了煤矿恶劣环境中的多目标实时检测任务. ...
基于图像融合和改进CornerNet-Squeeze的煤矿井下行人检测方法
1
2023
... 近年来,基于视觉信息的目标检测技术已广泛应用于采煤、掘进、巡检等煤矿场景. 传统的目标检测模型利用人工设计特征[4 ] 和机器学习分类器[5 ] ,实现对目标的识别与定位[6 ] ,但该检测模型在矿井实际应用中存在复杂度高、参数量大、鲁棒性差、检测效率低等问题. 相较于传统的目标检测模型,在对象级特征提取与描述中,基于深度学习的目标检测模型凭借自适应特征学习[7 ] 、多尺度信息整合[8 ] 、端对端的高效网络训练方法[9 ] 等优势,逐步成为研究热点. 郭永存等[10 ] 提出基于YOLOv4-tiny-4S的煤矿电机车多目标检测模型,提升了电机车对行人、信号灯与碎石的实时检测精度. Wang等[11 ] 针对煤与矸石粘连与半遮档导致的识别精度降低难题,提出基于Mask RCNN的煤矸图像实例分割网络. 上述算法在工况条件良好的作业场景中检测效果较好,但在煤矿综掘工作面中,受光照不均、高粉尘的恶劣环境因素干扰,视频图像采集终端易出现成像模糊、色彩辨识度低、对比度差等问题,导致目标检测模型的性能急剧下降. 为了提升目标检测模型对煤矿复杂环境下关键目标的识别与定位能力[12 -13 ] ,国内外学者将图像增强算法、注意力机制、特征金字塔结构等与深度学习算法相结合[14 -15 ] . 张夫净等[16 ] 结合超分辨率重构技术、坐标注意力机制与YOLOv5s算法,实现了不同光照条件下掘进巷道支护钢带的锚孔识别与定位. Zhao等[17 ] 针对煤矿恶劣环境中的关键目标感知难题,采用密集连接卷积网络、加权双向特征金字塔网络,对YOLOv5s算法进行优化,实现了煤矿恶劣环境中的多目标实时检测任务. ...
Real-time detection of safety hazards in coal mines utilizing an enhanced YOLOv3 algorithm
1
2023
... 近年来,基于视觉信息的目标检测技术已广泛应用于采煤、掘进、巡检等煤矿场景. 传统的目标检测模型利用人工设计特征[4 ] 和机器学习分类器[5 ] ,实现对目标的识别与定位[6 ] ,但该检测模型在矿井实际应用中存在复杂度高、参数量大、鲁棒性差、检测效率低等问题. 相较于传统的目标检测模型,在对象级特征提取与描述中,基于深度学习的目标检测模型凭借自适应特征学习[7 ] 、多尺度信息整合[8 ] 、端对端的高效网络训练方法[9 ] 等优势,逐步成为研究热点. 郭永存等[10 ] 提出基于YOLOv4-tiny-4S的煤矿电机车多目标检测模型,提升了电机车对行人、信号灯与碎石的实时检测精度. Wang等[11 ] 针对煤与矸石粘连与半遮档导致的识别精度降低难题,提出基于Mask RCNN的煤矸图像实例分割网络. 上述算法在工况条件良好的作业场景中检测效果较好,但在煤矿综掘工作面中,受光照不均、高粉尘的恶劣环境因素干扰,视频图像采集终端易出现成像模糊、色彩辨识度低、对比度差等问题,导致目标检测模型的性能急剧下降. 为了提升目标检测模型对煤矿复杂环境下关键目标的识别与定位能力[12 -13 ] ,国内外学者将图像增强算法、注意力机制、特征金字塔结构等与深度学习算法相结合[14 -15 ] . 张夫净等[16 ] 结合超分辨率重构技术、坐标注意力机制与YOLOv5s算法,实现了不同光照条件下掘进巷道支护钢带的锚孔识别与定位. Zhao等[17 ] 针对煤矿恶劣环境中的关键目标感知难题,采用密集连接卷积网络、加权双向特征金字塔网络,对YOLOv5s算法进行优化,实现了煤矿恶劣环境中的多目标实时检测任务. ...
基于改进YOLOv4–Tiny的矿井电机车多目标实时检测
1
2023
... 近年来,基于视觉信息的目标检测技术已广泛应用于采煤、掘进、巡检等煤矿场景. 传统的目标检测模型利用人工设计特征[4 ] 和机器学习分类器[5 ] ,实现对目标的识别与定位[6 ] ,但该检测模型在矿井实际应用中存在复杂度高、参数量大、鲁棒性差、检测效率低等问题. 相较于传统的目标检测模型,在对象级特征提取与描述中,基于深度学习的目标检测模型凭借自适应特征学习[7 ] 、多尺度信息整合[8 ] 、端对端的高效网络训练方法[9 ] 等优势,逐步成为研究热点. 郭永存等[10 ] 提出基于YOLOv4-tiny-4S的煤矿电机车多目标检测模型,提升了电机车对行人、信号灯与碎石的实时检测精度. Wang等[11 ] 针对煤与矸石粘连与半遮档导致的识别精度降低难题,提出基于Mask RCNN的煤矸图像实例分割网络. 上述算法在工况条件良好的作业场景中检测效果较好,但在煤矿综掘工作面中,受光照不均、高粉尘的恶劣环境因素干扰,视频图像采集终端易出现成像模糊、色彩辨识度低、对比度差等问题,导致目标检测模型的性能急剧下降. 为了提升目标检测模型对煤矿复杂环境下关键目标的识别与定位能力[12 -13 ] ,国内外学者将图像增强算法、注意力机制、特征金字塔结构等与深度学习算法相结合[14 -15 ] . 张夫净等[16 ] 结合超分辨率重构技术、坐标注意力机制与YOLOv5s算法,实现了不同光照条件下掘进巷道支护钢带的锚孔识别与定位. Zhao等[17 ] 针对煤矿恶劣环境中的关键目标感知难题,采用密集连接卷积网络、加权双向特征金字塔网络,对YOLOv5s算法进行优化,实现了煤矿恶劣环境中的多目标实时检测任务. ...
基于改进YOLOv4–Tiny的矿井电机车多目标实时检测
1
2023
... 近年来,基于视觉信息的目标检测技术已广泛应用于采煤、掘进、巡检等煤矿场景. 传统的目标检测模型利用人工设计特征[4 ] 和机器学习分类器[5 ] ,实现对目标的识别与定位[6 ] ,但该检测模型在矿井实际应用中存在复杂度高、参数量大、鲁棒性差、检测效率低等问题. 相较于传统的目标检测模型,在对象级特征提取与描述中,基于深度学习的目标检测模型凭借自适应特征学习[7 ] 、多尺度信息整合[8 ] 、端对端的高效网络训练方法[9 ] 等优势,逐步成为研究热点. 郭永存等[10 ] 提出基于YOLOv4-tiny-4S的煤矿电机车多目标检测模型,提升了电机车对行人、信号灯与碎石的实时检测精度. Wang等[11 ] 针对煤与矸石粘连与半遮档导致的识别精度降低难题,提出基于Mask RCNN的煤矸图像实例分割网络. 上述算法在工况条件良好的作业场景中检测效果较好,但在煤矿综掘工作面中,受光照不均、高粉尘的恶劣环境因素干扰,视频图像采集终端易出现成像模糊、色彩辨识度低、对比度差等问题,导致目标检测模型的性能急剧下降. 为了提升目标检测模型对煤矿复杂环境下关键目标的识别与定位能力[12 -13 ] ,国内外学者将图像增强算法、注意力机制、特征金字塔结构等与深度学习算法相结合[14 -15 ] . 张夫净等[16 ] 结合超分辨率重构技术、坐标注意力机制与YOLOv5s算法,实现了不同光照条件下掘进巷道支护钢带的锚孔识别与定位. Zhao等[17 ] 针对煤矿恶劣环境中的关键目标感知难题,采用密集连接卷积网络、加权双向特征金字塔网络,对YOLOv5s算法进行优化,实现了煤矿恶劣环境中的多目标实时检测任务. ...
Multi-scale coal and gangue detection in dense state based on improved Mask RCNN
1
2023
... 近年来,基于视觉信息的目标检测技术已广泛应用于采煤、掘进、巡检等煤矿场景. 传统的目标检测模型利用人工设计特征[4 ] 和机器学习分类器[5 ] ,实现对目标的识别与定位[6 ] ,但该检测模型在矿井实际应用中存在复杂度高、参数量大、鲁棒性差、检测效率低等问题. 相较于传统的目标检测模型,在对象级特征提取与描述中,基于深度学习的目标检测模型凭借自适应特征学习[7 ] 、多尺度信息整合[8 ] 、端对端的高效网络训练方法[9 ] 等优势,逐步成为研究热点. 郭永存等[10 ] 提出基于YOLOv4-tiny-4S的煤矿电机车多目标检测模型,提升了电机车对行人、信号灯与碎石的实时检测精度. Wang等[11 ] 针对煤与矸石粘连与半遮档导致的识别精度降低难题,提出基于Mask RCNN的煤矸图像实例分割网络. 上述算法在工况条件良好的作业场景中检测效果较好,但在煤矿综掘工作面中,受光照不均、高粉尘的恶劣环境因素干扰,视频图像采集终端易出现成像模糊、色彩辨识度低、对比度差等问题,导致目标检测模型的性能急剧下降. 为了提升目标检测模型对煤矿复杂环境下关键目标的识别与定位能力[12 -13 ] ,国内外学者将图像增强算法、注意力机制、特征金字塔结构等与深度学习算法相结合[14 -15 ] . 张夫净等[16 ] 结合超分辨率重构技术、坐标注意力机制与YOLOv5s算法,实现了不同光照条件下掘进巷道支护钢带的锚孔识别与定位. Zhao等[17 ] 针对煤矿恶劣环境中的关键目标感知难题,采用密集连接卷积网络、加权双向特征金字塔网络,对YOLOv5s算法进行优化,实现了煤矿恶劣环境中的多目标实时检测任务. ...
AI智能视频识别分析技术在智能化掘进的研究与应用
1
2023
... 近年来,基于视觉信息的目标检测技术已广泛应用于采煤、掘进、巡检等煤矿场景. 传统的目标检测模型利用人工设计特征[4 ] 和机器学习分类器[5 ] ,实现对目标的识别与定位[6 ] ,但该检测模型在矿井实际应用中存在复杂度高、参数量大、鲁棒性差、检测效率低等问题. 相较于传统的目标检测模型,在对象级特征提取与描述中,基于深度学习的目标检测模型凭借自适应特征学习[7 ] 、多尺度信息整合[8 ] 、端对端的高效网络训练方法[9 ] 等优势,逐步成为研究热点. 郭永存等[10 ] 提出基于YOLOv4-tiny-4S的煤矿电机车多目标检测模型,提升了电机车对行人、信号灯与碎石的实时检测精度. Wang等[11 ] 针对煤与矸石粘连与半遮档导致的识别精度降低难题,提出基于Mask RCNN的煤矸图像实例分割网络. 上述算法在工况条件良好的作业场景中检测效果较好,但在煤矿综掘工作面中,受光照不均、高粉尘的恶劣环境因素干扰,视频图像采集终端易出现成像模糊、色彩辨识度低、对比度差等问题,导致目标检测模型的性能急剧下降. 为了提升目标检测模型对煤矿复杂环境下关键目标的识别与定位能力[12 -13 ] ,国内外学者将图像增强算法、注意力机制、特征金字塔结构等与深度学习算法相结合[14 -15 ] . 张夫净等[16 ] 结合超分辨率重构技术、坐标注意力机制与YOLOv5s算法,实现了不同光照条件下掘进巷道支护钢带的锚孔识别与定位. Zhao等[17 ] 针对煤矿恶劣环境中的关键目标感知难题,采用密集连接卷积网络、加权双向特征金字塔网络,对YOLOv5s算法进行优化,实现了煤矿恶劣环境中的多目标实时检测任务. ...
AI智能视频识别分析技术在智能化掘进的研究与应用
1
2023
... 近年来,基于视觉信息的目标检测技术已广泛应用于采煤、掘进、巡检等煤矿场景. 传统的目标检测模型利用人工设计特征[4 ] 和机器学习分类器[5 ] ,实现对目标的识别与定位[6 ] ,但该检测模型在矿井实际应用中存在复杂度高、参数量大、鲁棒性差、检测效率低等问题. 相较于传统的目标检测模型,在对象级特征提取与描述中,基于深度学习的目标检测模型凭借自适应特征学习[7 ] 、多尺度信息整合[8 ] 、端对端的高效网络训练方法[9 ] 等优势,逐步成为研究热点. 郭永存等[10 ] 提出基于YOLOv4-tiny-4S的煤矿电机车多目标检测模型,提升了电机车对行人、信号灯与碎石的实时检测精度. Wang等[11 ] 针对煤与矸石粘连与半遮档导致的识别精度降低难题,提出基于Mask RCNN的煤矸图像实例分割网络. 上述算法在工况条件良好的作业场景中检测效果较好,但在煤矿综掘工作面中,受光照不均、高粉尘的恶劣环境因素干扰,视频图像采集终端易出现成像模糊、色彩辨识度低、对比度差等问题,导致目标检测模型的性能急剧下降. 为了提升目标检测模型对煤矿复杂环境下关键目标的识别与定位能力[12 -13 ] ,国内外学者将图像增强算法、注意力机制、特征金字塔结构等与深度学习算法相结合[14 -15 ] . 张夫净等[16 ] 结合超分辨率重构技术、坐标注意力机制与YOLOv5s算法,实现了不同光照条件下掘进巷道支护钢带的锚孔识别与定位. Zhao等[17 ] 针对煤矿恶劣环境中的关键目标感知难题,采用密集连接卷积网络、加权双向特征金字塔网络,对YOLOv5s算法进行优化,实现了煤矿恶劣环境中的多目标实时检测任务. ...
综掘系统视觉处理技术研究现状及发展趋势
1
2023
... 近年来,基于视觉信息的目标检测技术已广泛应用于采煤、掘进、巡检等煤矿场景. 传统的目标检测模型利用人工设计特征[4 ] 和机器学习分类器[5 ] ,实现对目标的识别与定位[6 ] ,但该检测模型在矿井实际应用中存在复杂度高、参数量大、鲁棒性差、检测效率低等问题. 相较于传统的目标检测模型,在对象级特征提取与描述中,基于深度学习的目标检测模型凭借自适应特征学习[7 ] 、多尺度信息整合[8 ] 、端对端的高效网络训练方法[9 ] 等优势,逐步成为研究热点. 郭永存等[10 ] 提出基于YOLOv4-tiny-4S的煤矿电机车多目标检测模型,提升了电机车对行人、信号灯与碎石的实时检测精度. Wang等[11 ] 针对煤与矸石粘连与半遮档导致的识别精度降低难题,提出基于Mask RCNN的煤矸图像实例分割网络. 上述算法在工况条件良好的作业场景中检测效果较好,但在煤矿综掘工作面中,受光照不均、高粉尘的恶劣环境因素干扰,视频图像采集终端易出现成像模糊、色彩辨识度低、对比度差等问题,导致目标检测模型的性能急剧下降. 为了提升目标检测模型对煤矿复杂环境下关键目标的识别与定位能力[12 -13 ] ,国内外学者将图像增强算法、注意力机制、特征金字塔结构等与深度学习算法相结合[14 -15 ] . 张夫净等[16 ] 结合超分辨率重构技术、坐标注意力机制与YOLOv5s算法,实现了不同光照条件下掘进巷道支护钢带的锚孔识别与定位. Zhao等[17 ] 针对煤矿恶劣环境中的关键目标感知难题,采用密集连接卷积网络、加权双向特征金字塔网络,对YOLOv5s算法进行优化,实现了煤矿恶劣环境中的多目标实时检测任务. ...
综掘系统视觉处理技术研究现状及发展趋势
1
2023
... 近年来,基于视觉信息的目标检测技术已广泛应用于采煤、掘进、巡检等煤矿场景. 传统的目标检测模型利用人工设计特征[4 ] 和机器学习分类器[5 ] ,实现对目标的识别与定位[6 ] ,但该检测模型在矿井实际应用中存在复杂度高、参数量大、鲁棒性差、检测效率低等问题. 相较于传统的目标检测模型,在对象级特征提取与描述中,基于深度学习的目标检测模型凭借自适应特征学习[7 ] 、多尺度信息整合[8 ] 、端对端的高效网络训练方法[9 ] 等优势,逐步成为研究热点. 郭永存等[10 ] 提出基于YOLOv4-tiny-4S的煤矿电机车多目标检测模型,提升了电机车对行人、信号灯与碎石的实时检测精度. Wang等[11 ] 针对煤与矸石粘连与半遮档导致的识别精度降低难题,提出基于Mask RCNN的煤矸图像实例分割网络. 上述算法在工况条件良好的作业场景中检测效果较好,但在煤矿综掘工作面中,受光照不均、高粉尘的恶劣环境因素干扰,视频图像采集终端易出现成像模糊、色彩辨识度低、对比度差等问题,导致目标检测模型的性能急剧下降. 为了提升目标检测模型对煤矿复杂环境下关键目标的识别与定位能力[12 -13 ] ,国内外学者将图像增强算法、注意力机制、特征金字塔结构等与深度学习算法相结合[14 -15 ] . 张夫净等[16 ] 结合超分辨率重构技术、坐标注意力机制与YOLOv5s算法,实现了不同光照条件下掘进巷道支护钢带的锚孔识别与定位. Zhao等[17 ] 针对煤矿恶劣环境中的关键目标感知难题,采用密集连接卷积网络、加权双向特征金字塔网络,对YOLOv5s算法进行优化,实现了煤矿恶劣环境中的多目标实时检测任务. ...
基于Mask R-CNN的煤矿巷道掘进迎头裂隙检测与定位算法
1
2023
... 近年来,基于视觉信息的目标检测技术已广泛应用于采煤、掘进、巡检等煤矿场景. 传统的目标检测模型利用人工设计特征[4 ] 和机器学习分类器[5 ] ,实现对目标的识别与定位[6 ] ,但该检测模型在矿井实际应用中存在复杂度高、参数量大、鲁棒性差、检测效率低等问题. 相较于传统的目标检测模型,在对象级特征提取与描述中,基于深度学习的目标检测模型凭借自适应特征学习[7 ] 、多尺度信息整合[8 ] 、端对端的高效网络训练方法[9 ] 等优势,逐步成为研究热点. 郭永存等[10 ] 提出基于YOLOv4-tiny-4S的煤矿电机车多目标检测模型,提升了电机车对行人、信号灯与碎石的实时检测精度. Wang等[11 ] 针对煤与矸石粘连与半遮档导致的识别精度降低难题,提出基于Mask RCNN的煤矸图像实例分割网络. 上述算法在工况条件良好的作业场景中检测效果较好,但在煤矿综掘工作面中,受光照不均、高粉尘的恶劣环境因素干扰,视频图像采集终端易出现成像模糊、色彩辨识度低、对比度差等问题,导致目标检测模型的性能急剧下降. 为了提升目标检测模型对煤矿复杂环境下关键目标的识别与定位能力[12 -13 ] ,国内外学者将图像增强算法、注意力机制、特征金字塔结构等与深度学习算法相结合[14 -15 ] . 张夫净等[16 ] 结合超分辨率重构技术、坐标注意力机制与YOLOv5s算法,实现了不同光照条件下掘进巷道支护钢带的锚孔识别与定位. Zhao等[17 ] 针对煤矿恶劣环境中的关键目标感知难题,采用密集连接卷积网络、加权双向特征金字塔网络,对YOLOv5s算法进行优化,实现了煤矿恶劣环境中的多目标实时检测任务. ...
基于Mask R-CNN的煤矿巷道掘进迎头裂隙检测与定位算法
1
2023
... 近年来,基于视觉信息的目标检测技术已广泛应用于采煤、掘进、巡检等煤矿场景. 传统的目标检测模型利用人工设计特征[4 ] 和机器学习分类器[5 ] ,实现对目标的识别与定位[6 ] ,但该检测模型在矿井实际应用中存在复杂度高、参数量大、鲁棒性差、检测效率低等问题. 相较于传统的目标检测模型,在对象级特征提取与描述中,基于深度学习的目标检测模型凭借自适应特征学习[7 ] 、多尺度信息整合[8 ] 、端对端的高效网络训练方法[9 ] 等优势,逐步成为研究热点. 郭永存等[10 ] 提出基于YOLOv4-tiny-4S的煤矿电机车多目标检测模型,提升了电机车对行人、信号灯与碎石的实时检测精度. Wang等[11 ] 针对煤与矸石粘连与半遮档导致的识别精度降低难题,提出基于Mask RCNN的煤矸图像实例分割网络. 上述算法在工况条件良好的作业场景中检测效果较好,但在煤矿综掘工作面中,受光照不均、高粉尘的恶劣环境因素干扰,视频图像采集终端易出现成像模糊、色彩辨识度低、对比度差等问题,导致目标检测模型的性能急剧下降. 为了提升目标检测模型对煤矿复杂环境下关键目标的识别与定位能力[12 -13 ] ,国内外学者将图像增强算法、注意力机制、特征金字塔结构等与深度学习算法相结合[14 -15 ] . 张夫净等[16 ] 结合超分辨率重构技术、坐标注意力机制与YOLOv5s算法,实现了不同光照条件下掘进巷道支护钢带的锚孔识别与定位. Zhao等[17 ] 针对煤矿恶劣环境中的关键目标感知难题,采用密集连接卷积网络、加权双向特征金字塔网络,对YOLOv5s算法进行优化,实现了煤矿恶劣环境中的多目标实时检测任务. ...
Research on the detection method of coal mine roadway bolt mesh based on improved YOLOv7
1
2023
... 近年来,基于视觉信息的目标检测技术已广泛应用于采煤、掘进、巡检等煤矿场景. 传统的目标检测模型利用人工设计特征[4 ] 和机器学习分类器[5 ] ,实现对目标的识别与定位[6 ] ,但该检测模型在矿井实际应用中存在复杂度高、参数量大、鲁棒性差、检测效率低等问题. 相较于传统的目标检测模型,在对象级特征提取与描述中,基于深度学习的目标检测模型凭借自适应特征学习[7 ] 、多尺度信息整合[8 ] 、端对端的高效网络训练方法[9 ] 等优势,逐步成为研究热点. 郭永存等[10 ] 提出基于YOLOv4-tiny-4S的煤矿电机车多目标检测模型,提升了电机车对行人、信号灯与碎石的实时检测精度. Wang等[11 ] 针对煤与矸石粘连与半遮档导致的识别精度降低难题,提出基于Mask RCNN的煤矸图像实例分割网络. 上述算法在工况条件良好的作业场景中检测效果较好,但在煤矿综掘工作面中,受光照不均、高粉尘的恶劣环境因素干扰,视频图像采集终端易出现成像模糊、色彩辨识度低、对比度差等问题,导致目标检测模型的性能急剧下降. 为了提升目标检测模型对煤矿复杂环境下关键目标的识别与定位能力[12 -13 ] ,国内外学者将图像增强算法、注意力机制、特征金字塔结构等与深度学习算法相结合[14 -15 ] . 张夫净等[16 ] 结合超分辨率重构技术、坐标注意力机制与YOLOv5s算法,实现了不同光照条件下掘进巷道支护钢带的锚孔识别与定位. Zhao等[17 ] 针对煤矿恶劣环境中的关键目标感知难题,采用密集连接卷积网络、加权双向特征金字塔网络,对YOLOv5s算法进行优化,实现了煤矿恶劣环境中的多目标实时检测任务. ...
煤矿巷道支护钢带锚孔智能识别与定位
1
2022
... 近年来,基于视觉信息的目标检测技术已广泛应用于采煤、掘进、巡检等煤矿场景. 传统的目标检测模型利用人工设计特征[4 ] 和机器学习分类器[5 ] ,实现对目标的识别与定位[6 ] ,但该检测模型在矿井实际应用中存在复杂度高、参数量大、鲁棒性差、检测效率低等问题. 相较于传统的目标检测模型,在对象级特征提取与描述中,基于深度学习的目标检测模型凭借自适应特征学习[7 ] 、多尺度信息整合[8 ] 、端对端的高效网络训练方法[9 ] 等优势,逐步成为研究热点. 郭永存等[10 ] 提出基于YOLOv4-tiny-4S的煤矿电机车多目标检测模型,提升了电机车对行人、信号灯与碎石的实时检测精度. Wang等[11 ] 针对煤与矸石粘连与半遮档导致的识别精度降低难题,提出基于Mask RCNN的煤矸图像实例分割网络. 上述算法在工况条件良好的作业场景中检测效果较好,但在煤矿综掘工作面中,受光照不均、高粉尘的恶劣环境因素干扰,视频图像采集终端易出现成像模糊、色彩辨识度低、对比度差等问题,导致目标检测模型的性能急剧下降. 为了提升目标检测模型对煤矿复杂环境下关键目标的识别与定位能力[12 -13 ] ,国内外学者将图像增强算法、注意力机制、特征金字塔结构等与深度学习算法相结合[14 -15 ] . 张夫净等[16 ] 结合超分辨率重构技术、坐标注意力机制与YOLOv5s算法,实现了不同光照条件下掘进巷道支护钢带的锚孔识别与定位. Zhao等[17 ] 针对煤矿恶劣环境中的关键目标感知难题,采用密集连接卷积网络、加权双向特征金字塔网络,对YOLOv5s算法进行优化,实现了煤矿恶劣环境中的多目标实时检测任务. ...
煤矿巷道支护钢带锚孔智能识别与定位
1
2022
... 近年来,基于视觉信息的目标检测技术已广泛应用于采煤、掘进、巡检等煤矿场景. 传统的目标检测模型利用人工设计特征[4 ] 和机器学习分类器[5 ] ,实现对目标的识别与定位[6 ] ,但该检测模型在矿井实际应用中存在复杂度高、参数量大、鲁棒性差、检测效率低等问题. 相较于传统的目标检测模型,在对象级特征提取与描述中,基于深度学习的目标检测模型凭借自适应特征学习[7 ] 、多尺度信息整合[8 ] 、端对端的高效网络训练方法[9 ] 等优势,逐步成为研究热点. 郭永存等[10 ] 提出基于YOLOv4-tiny-4S的煤矿电机车多目标检测模型,提升了电机车对行人、信号灯与碎石的实时检测精度. Wang等[11 ] 针对煤与矸石粘连与半遮档导致的识别精度降低难题,提出基于Mask RCNN的煤矸图像实例分割网络. 上述算法在工况条件良好的作业场景中检测效果较好,但在煤矿综掘工作面中,受光照不均、高粉尘的恶劣环境因素干扰,视频图像采集终端易出现成像模糊、色彩辨识度低、对比度差等问题,导致目标检测模型的性能急剧下降. 为了提升目标检测模型对煤矿复杂环境下关键目标的识别与定位能力[12 -13 ] ,国内外学者将图像增强算法、注意力机制、特征金字塔结构等与深度学习算法相结合[14 -15 ] . 张夫净等[16 ] 结合超分辨率重构技术、坐标注意力机制与YOLOv5s算法,实现了不同光照条件下掘进巷道支护钢带的锚孔识别与定位. Zhao等[17 ] 针对煤矿恶劣环境中的关键目标感知难题,采用密集连接卷积网络、加权双向特征金字塔网络,对YOLOv5s算法进行优化,实现了煤矿恶劣环境中的多目标实时检测任务. ...
Research on real-time perception method of key targets in the comprehensive excavation working face of coal mine
1
2023
... 近年来,基于视觉信息的目标检测技术已广泛应用于采煤、掘进、巡检等煤矿场景. 传统的目标检测模型利用人工设计特征[4 ] 和机器学习分类器[5 ] ,实现对目标的识别与定位[6 ] ,但该检测模型在矿井实际应用中存在复杂度高、参数量大、鲁棒性差、检测效率低等问题. 相较于传统的目标检测模型,在对象级特征提取与描述中,基于深度学习的目标检测模型凭借自适应特征学习[7 ] 、多尺度信息整合[8 ] 、端对端的高效网络训练方法[9 ] 等优势,逐步成为研究热点. 郭永存等[10 ] 提出基于YOLOv4-tiny-4S的煤矿电机车多目标检测模型,提升了电机车对行人、信号灯与碎石的实时检测精度. Wang等[11 ] 针对煤与矸石粘连与半遮档导致的识别精度降低难题,提出基于Mask RCNN的煤矸图像实例分割网络. 上述算法在工况条件良好的作业场景中检测效果较好,但在煤矿综掘工作面中,受光照不均、高粉尘的恶劣环境因素干扰,视频图像采集终端易出现成像模糊、色彩辨识度低、对比度差等问题,导致目标检测模型的性能急剧下降. 为了提升目标检测模型对煤矿复杂环境下关键目标的识别与定位能力[12 -13 ] ,国内外学者将图像增强算法、注意力机制、特征金字塔结构等与深度学习算法相结合[14 -15 ] . 张夫净等[16 ] 结合超分辨率重构技术、坐标注意力机制与YOLOv5s算法,实现了不同光照条件下掘进巷道支护钢带的锚孔识别与定位. Zhao等[17 ] 针对煤矿恶劣环境中的关键目标感知难题,采用密集连接卷积网络、加权双向特征金字塔网络,对YOLOv5s算法进行优化,实现了煤矿恶劣环境中的多目标实时检测任务. ...
2
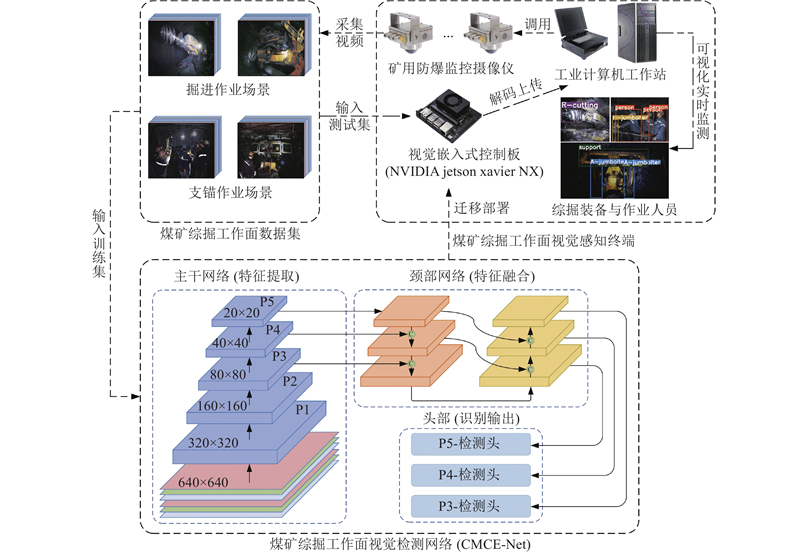
... 针对煤矿综掘工作面恶劣环境干扰因素所导致的目标复杂特征提取困难、目标特征感知区域模糊以及目标分类与定位精度降低的问题,分别采用融合分布移位卷积DSConv的ELAN-DS特征提取模块、SimAM注意力模块与解耦检测头对YOLOv7-tiny算法[18 ] 进行优化. 提出煤矿综掘工作面视觉检测网络(CMCE-Net),以提升煤矿复杂作业场景下系统对关键装备与作业人员的检测性能. CMCE-Net的整体结构如图2 所示. ...
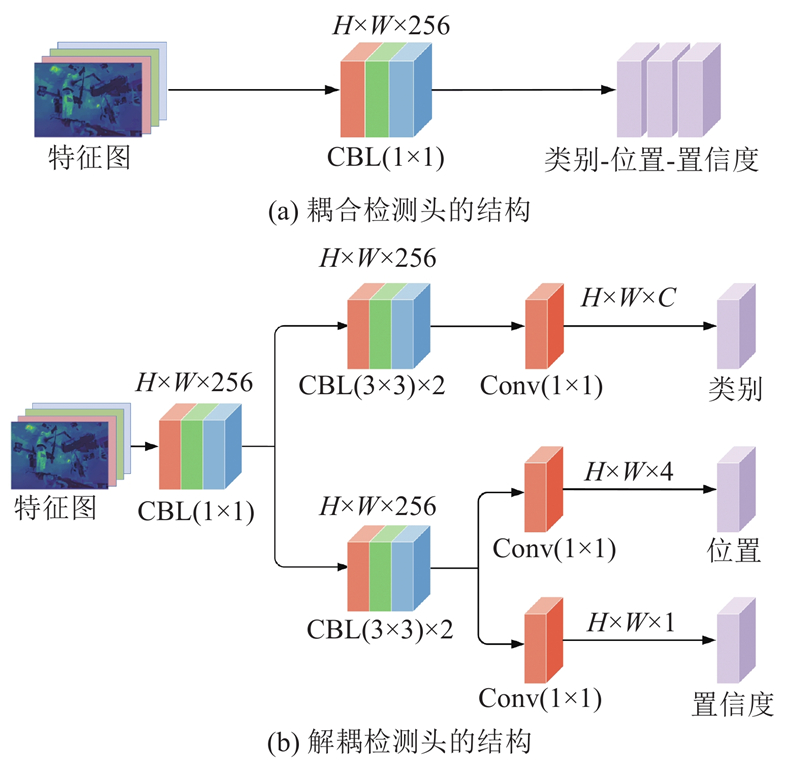
... 如图5 (a)所示,在YOLO系列检测算法[18 ,29 -32 ] 中,普遍采用耦合检测头提取检测结果,输出待检测目标的类别标签、位置信息与置信度. 在耦合检测头中,分类任务与回归任务共享同一组特征权重参数,但两项任务本身对特征图的关注区域存在明显差异. 当将二者进行耦合计算时,易引起特征需求冲突与误差信息交叉干扰的问题,加之煤矿综掘工作面粉尘浓度高、人机多目标混杂、目标间遮挡等因素的干扰,极大加剧了网络对关键装备与作业人员的分类与定位精度损失. 在煤矿综掘工作面视觉检测网络(CMCE-Net)的检测头部,引入解耦检测头以实现对不同层级特征图的并行处理,避免耦合检测头所造成的性能损失. 如图5 (b)所示,解耦检测头利用1个1×1的CBL模块将多种维度的输入特征图统一映射为H ×W ×256的固定维度,再分别利用2条独立分支中的2组3×3的CBL模块同步执行分类与回归操作,通过3个1×1的Conv模块独立输出目标的类别标签、位置信息与置信度. ...
ImageNet classification with deep convolutional neural networks
1
2017
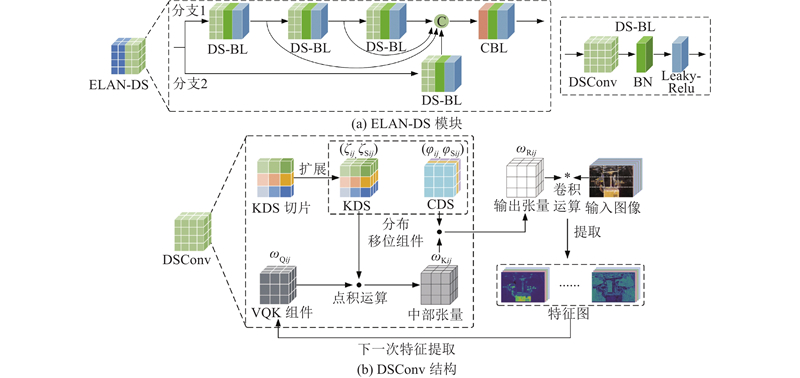
... 随着以AlexNet[19 ] 、ResNet[20 ] 为代表的大型卷积神经网络的应用,计算机视觉中的高精度检测与深层特征提取技术取得了突破,但标准卷积层的过度堆叠给大型网络带来了高额的计算成本,大幅降低了运算速度与存储效率. 为了使网络“更小更快”,相关研究学者通过优化标准卷积块的结构并引入轻量化算子,构建“即插即用”的新型卷积模块,如MobileNet[21 ] 中的深度可分离卷积、ShuffleNet[22 ] 中的信道混洗与分组卷积. 上述轻量化卷积块在信息处理时会损失部分原始的特征信息,导致特征提取不充分. 此外,由于煤矿综掘工作面掘进与支锚作业过程中存在高粉尘、光照不均的恶劣环境因素干扰,导致装备与作业人员的特征对比度降低且复杂性提高,使得YOLOv7-tiny算法原有的ELAN模块仅凭借固定卷积核与单一线性的特征学习方式,难以在煤矿复杂背景中提取目标的有效特征信息. 为了在减少运算量的同时提升特征提取能力,将DSConv[23 ] 模块与ELAN模块相结合,重新构建ELAN-DS特征提取模块,凭借DSConv的可变量化核(variable quantized kernel, VQK)与分布移位组件,提升检测网络对复杂特征的提取与学习能力. ELAN-DS模块与DSConv的整体结构如图3 所示. ...
1
... 随着以AlexNet[19 ] 、ResNet[20 ] 为代表的大型卷积神经网络的应用,计算机视觉中的高精度检测与深层特征提取技术取得了突破,但标准卷积层的过度堆叠给大型网络带来了高额的计算成本,大幅降低了运算速度与存储效率. 为了使网络“更小更快”,相关研究学者通过优化标准卷积块的结构并引入轻量化算子,构建“即插即用”的新型卷积模块,如MobileNet[21 ] 中的深度可分离卷积、ShuffleNet[22 ] 中的信道混洗与分组卷积. 上述轻量化卷积块在信息处理时会损失部分原始的特征信息,导致特征提取不充分. 此外,由于煤矿综掘工作面掘进与支锚作业过程中存在高粉尘、光照不均的恶劣环境因素干扰,导致装备与作业人员的特征对比度降低且复杂性提高,使得YOLOv7-tiny算法原有的ELAN模块仅凭借固定卷积核与单一线性的特征学习方式,难以在煤矿复杂背景中提取目标的有效特征信息. 为了在减少运算量的同时提升特征提取能力,将DSConv[23 ] 模块与ELAN模块相结合,重新构建ELAN-DS特征提取模块,凭借DSConv的可变量化核(variable quantized kernel, VQK)与分布移位组件,提升检测网络对复杂特征的提取与学习能力. ELAN-DS模块与DSConv的整体结构如图3 所示. ...
1
... 随着以AlexNet[19 ] 、ResNet[20 ] 为代表的大型卷积神经网络的应用,计算机视觉中的高精度检测与深层特征提取技术取得了突破,但标准卷积层的过度堆叠给大型网络带来了高额的计算成本,大幅降低了运算速度与存储效率. 为了使网络“更小更快”,相关研究学者通过优化标准卷积块的结构并引入轻量化算子,构建“即插即用”的新型卷积模块,如MobileNet[21 ] 中的深度可分离卷积、ShuffleNet[22 ] 中的信道混洗与分组卷积. 上述轻量化卷积块在信息处理时会损失部分原始的特征信息,导致特征提取不充分. 此外,由于煤矿综掘工作面掘进与支锚作业过程中存在高粉尘、光照不均的恶劣环境因素干扰,导致装备与作业人员的特征对比度降低且复杂性提高,使得YOLOv7-tiny算法原有的ELAN模块仅凭借固定卷积核与单一线性的特征学习方式,难以在煤矿复杂背景中提取目标的有效特征信息. 为了在减少运算量的同时提升特征提取能力,将DSConv[23 ] 模块与ELAN模块相结合,重新构建ELAN-DS特征提取模块,凭借DSConv的可变量化核(variable quantized kernel, VQK)与分布移位组件,提升检测网络对复杂特征的提取与学习能力. ELAN-DS模块与DSConv的整体结构如图3 所示. ...
1
... 随着以AlexNet[19 ] 、ResNet[20 ] 为代表的大型卷积神经网络的应用,计算机视觉中的高精度检测与深层特征提取技术取得了突破,但标准卷积层的过度堆叠给大型网络带来了高额的计算成本,大幅降低了运算速度与存储效率. 为了使网络“更小更快”,相关研究学者通过优化标准卷积块的结构并引入轻量化算子,构建“即插即用”的新型卷积模块,如MobileNet[21 ] 中的深度可分离卷积、ShuffleNet[22 ] 中的信道混洗与分组卷积. 上述轻量化卷积块在信息处理时会损失部分原始的特征信息,导致特征提取不充分. 此外,由于煤矿综掘工作面掘进与支锚作业过程中存在高粉尘、光照不均的恶劣环境因素干扰,导致装备与作业人员的特征对比度降低且复杂性提高,使得YOLOv7-tiny算法原有的ELAN模块仅凭借固定卷积核与单一线性的特征学习方式,难以在煤矿复杂背景中提取目标的有效特征信息. 为了在减少运算量的同时提升特征提取能力,将DSConv[23 ] 模块与ELAN模块相结合,重新构建ELAN-DS特征提取模块,凭借DSConv的可变量化核(variable quantized kernel, VQK)与分布移位组件,提升检测网络对复杂特征的提取与学习能力. ELAN-DS模块与DSConv的整体结构如图3 所示. ...
1
... 随着以AlexNet[19 ] 、ResNet[20 ] 为代表的大型卷积神经网络的应用,计算机视觉中的高精度检测与深层特征提取技术取得了突破,但标准卷积层的过度堆叠给大型网络带来了高额的计算成本,大幅降低了运算速度与存储效率. 为了使网络“更小更快”,相关研究学者通过优化标准卷积块的结构并引入轻量化算子,构建“即插即用”的新型卷积模块,如MobileNet[21 ] 中的深度可分离卷积、ShuffleNet[22 ] 中的信道混洗与分组卷积. 上述轻量化卷积块在信息处理时会损失部分原始的特征信息,导致特征提取不充分. 此外,由于煤矿综掘工作面掘进与支锚作业过程中存在高粉尘、光照不均的恶劣环境因素干扰,导致装备与作业人员的特征对比度降低且复杂性提高,使得YOLOv7-tiny算法原有的ELAN模块仅凭借固定卷积核与单一线性的特征学习方式,难以在煤矿复杂背景中提取目标的有效特征信息. 为了在减少运算量的同时提升特征提取能力,将DSConv[23 ] 模块与ELAN模块相结合,重新构建ELAN-DS特征提取模块,凭借DSConv的可变量化核(variable quantized kernel, VQK)与分布移位组件,提升检测网络对复杂特征的提取与学习能力. ELAN-DS模块与DSConv的整体结构如图3 所示. ...
1
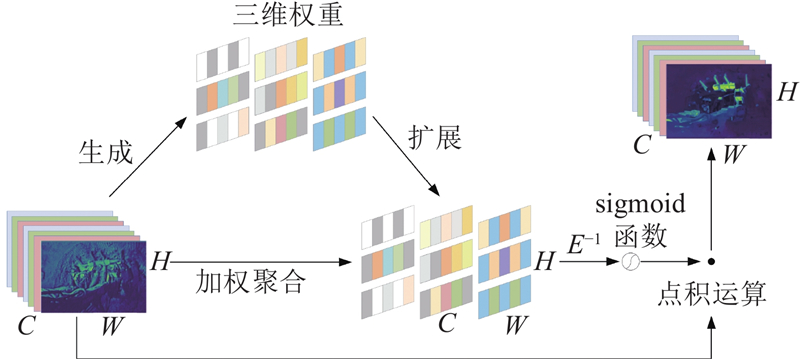
... 在深度学习算法中,注意力机制可以促进检测网络捕获与任务相关的特征信息,抑制无关背景因素的干扰. 挤压激励(squeeze and excitation network, SE)模块[24 ] 、CBAM[25 ] 注意力机制通常只能沿着空间或通道维度来细化特征,限制了对于注意力权重学习的灵活性,而全局注意力机制(global attention mechanism, GAM)[26 ] 、ACmix模块[27 ] 虽然对特征的捕获能力强,但结构复杂且参数量大. 区别于上述注意力机制模块,SimAM注意力模块[28 ] 在保持轻量级属性的同时,可以通过生成全三维权重来加强网络的全局信息感知能力. 本文在视觉检测网络的颈部集成了3组SimAM注意力模块,在不额外增加参数的情况下,引导视觉检测网络将目标感知区域聚焦于关键装备与作业人员,进一步降低煤矿综掘工作面的复杂背景干扰. SimAM注意力模块的结构如图4 所示. 图中,H 、W 、C 分别为输入特征图的高、宽与通道数. ...
1
... 在深度学习算法中,注意力机制可以促进检测网络捕获与任务相关的特征信息,抑制无关背景因素的干扰. 挤压激励(squeeze and excitation network, SE)模块[24 ] 、CBAM[25 ] 注意力机制通常只能沿着空间或通道维度来细化特征,限制了对于注意力权重学习的灵活性,而全局注意力机制(global attention mechanism, GAM)[26 ] 、ACmix模块[27 ] 虽然对特征的捕获能力强,但结构复杂且参数量大. 区别于上述注意力机制模块,SimAM注意力模块[28 ] 在保持轻量级属性的同时,可以通过生成全三维权重来加强网络的全局信息感知能力. 本文在视觉检测网络的颈部集成了3组SimAM注意力模块,在不额外增加参数的情况下,引导视觉检测网络将目标感知区域聚焦于关键装备与作业人员,进一步降低煤矿综掘工作面的复杂背景干扰. SimAM注意力模块的结构如图4 所示. 图中,H 、W 、C 分别为输入特征图的高、宽与通道数. ...
1
... 在深度学习算法中,注意力机制可以促进检测网络捕获与任务相关的特征信息,抑制无关背景因素的干扰. 挤压激励(squeeze and excitation network, SE)模块[24 ] 、CBAM[25 ] 注意力机制通常只能沿着空间或通道维度来细化特征,限制了对于注意力权重学习的灵活性,而全局注意力机制(global attention mechanism, GAM)[26 ] 、ACmix模块[27 ] 虽然对特征的捕获能力强,但结构复杂且参数量大. 区别于上述注意力机制模块,SimAM注意力模块[28 ] 在保持轻量级属性的同时,可以通过生成全三维权重来加强网络的全局信息感知能力. 本文在视觉检测网络的颈部集成了3组SimAM注意力模块,在不额外增加参数的情况下,引导视觉检测网络将目标感知区域聚焦于关键装备与作业人员,进一步降低煤矿综掘工作面的复杂背景干扰. SimAM注意力模块的结构如图4 所示. 图中,H 、W 、C 分别为输入特征图的高、宽与通道数. ...
1
... 在深度学习算法中,注意力机制可以促进检测网络捕获与任务相关的特征信息,抑制无关背景因素的干扰. 挤压激励(squeeze and excitation network, SE)模块[24 ] 、CBAM[25 ] 注意力机制通常只能沿着空间或通道维度来细化特征,限制了对于注意力权重学习的灵活性,而全局注意力机制(global attention mechanism, GAM)[26 ] 、ACmix模块[27 ] 虽然对特征的捕获能力强,但结构复杂且参数量大. 区别于上述注意力机制模块,SimAM注意力模块[28 ] 在保持轻量级属性的同时,可以通过生成全三维权重来加强网络的全局信息感知能力. 本文在视觉检测网络的颈部集成了3组SimAM注意力模块,在不额外增加参数的情况下,引导视觉检测网络将目标感知区域聚焦于关键装备与作业人员,进一步降低煤矿综掘工作面的复杂背景干扰. SimAM注意力模块的结构如图4 所示. 图中,H 、W 、C 分别为输入特征图的高、宽与通道数. ...
1
... 在深度学习算法中,注意力机制可以促进检测网络捕获与任务相关的特征信息,抑制无关背景因素的干扰. 挤压激励(squeeze and excitation network, SE)模块[24 ] 、CBAM[25 ] 注意力机制通常只能沿着空间或通道维度来细化特征,限制了对于注意力权重学习的灵活性,而全局注意力机制(global attention mechanism, GAM)[26 ] 、ACmix模块[27 ] 虽然对特征的捕获能力强,但结构复杂且参数量大. 区别于上述注意力机制模块,SimAM注意力模块[28 ] 在保持轻量级属性的同时,可以通过生成全三维权重来加强网络的全局信息感知能力. 本文在视觉检测网络的颈部集成了3组SimAM注意力模块,在不额外增加参数的情况下,引导视觉检测网络将目标感知区域聚焦于关键装备与作业人员,进一步降低煤矿综掘工作面的复杂背景干扰. SimAM注意力模块的结构如图4 所示. 图中,H 、W 、C 分别为输入特征图的高、宽与通道数. ...
1
... 如图5 (a)所示,在YOLO系列检测算法[18 ,29 -32 ] 中,普遍采用耦合检测头提取检测结果,输出待检测目标的类别标签、位置信息与置信度. 在耦合检测头中,分类任务与回归任务共享同一组特征权重参数,但两项任务本身对特征图的关注区域存在明显差异. 当将二者进行耦合计算时,易引起特征需求冲突与误差信息交叉干扰的问题,加之煤矿综掘工作面粉尘浓度高、人机多目标混杂、目标间遮挡等因素的干扰,极大加剧了网络对关键装备与作业人员的分类与定位精度损失. 在煤矿综掘工作面视觉检测网络(CMCE-Net)的检测头部,引入解耦检测头以实现对不同层级特征图的并行处理,避免耦合检测头所造成的性能损失. 如图5 (b)所示,解耦检测头利用1个1×1的CBL模块将多种维度的输入特征图统一映射为H ×W ×256的固定维度,再分别利用2条独立分支中的2组3×3的CBL模块同步执行分类与回归操作,通过3个1×1的Conv模块独立输出目标的类别标签、位置信息与置信度. ...
1
... 在目标检测领域,通常采用平均检测精度均值mAP(mean average precision)、平均检测精度AP(average precision)、检测准确率P (precision)、检测召回率R (recall)、内存、参数量、每秒浮点运算次数FLOPs(floating point operations per second)与帧率作为实验评价指标[30 ] ,mAP0.5 、mAP0.75 、mAP0.5∶0.95 分别为交并比阈值为0.5、0.75、0.5~0.95时的平均精度,综合评价模型的检测性能. 相关评价指标的计算如下所示: ...
1
... 如图5 (a)所示,在YOLO系列检测算法[18 ,29 -32 ] 中,普遍采用耦合检测头提取检测结果,输出待检测目标的类别标签、位置信息与置信度. 在耦合检测头中,分类任务与回归任务共享同一组特征权重参数,但两项任务本身对特征图的关注区域存在明显差异. 当将二者进行耦合计算时,易引起特征需求冲突与误差信息交叉干扰的问题,加之煤矿综掘工作面粉尘浓度高、人机多目标混杂、目标间遮挡等因素的干扰,极大加剧了网络对关键装备与作业人员的分类与定位精度损失. 在煤矿综掘工作面视觉检测网络(CMCE-Net)的检测头部,引入解耦检测头以实现对不同层级特征图的并行处理,避免耦合检测头所造成的性能损失. 如图5 (b)所示,解耦检测头利用1个1×1的CBL模块将多种维度的输入特征图统一映射为H ×W ×256的固定维度,再分别利用2条独立分支中的2组3×3的CBL模块同步执行分类与回归操作,通过3个1×1的Conv模块独立输出目标的类别标签、位置信息与置信度. ...
Faster R-CNN: towards real-time object detection with region proposal networks
1
2017
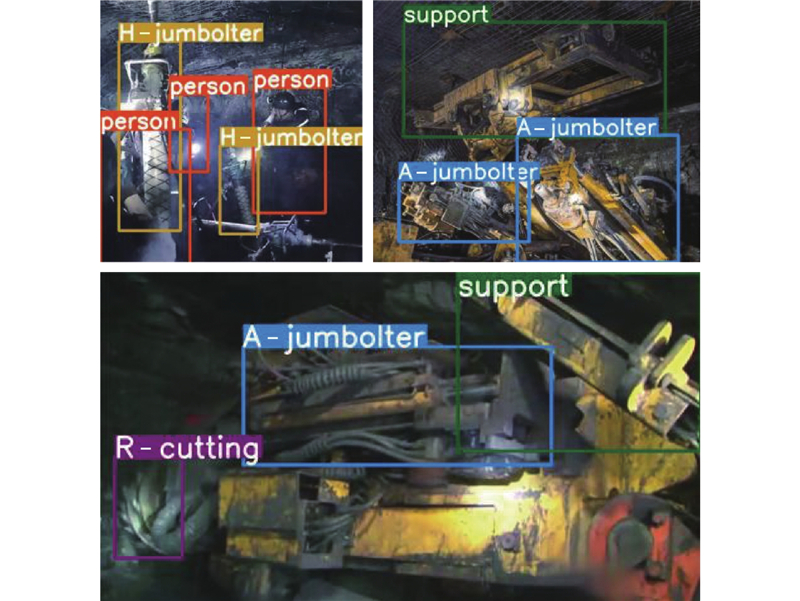
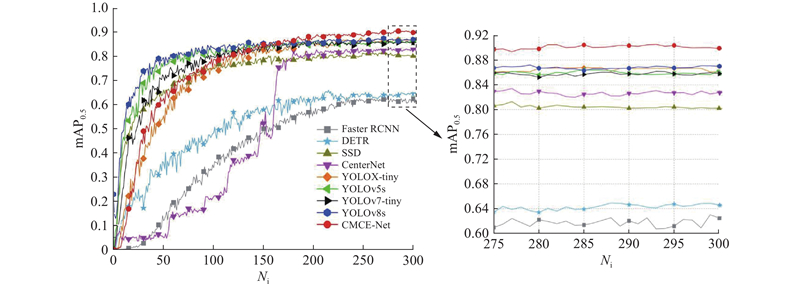
... 为了进一步探究CMCE-Net检测性能的优越性与可靠性,选取Faster RCNN~CenterNet[33 -37 ] 4种经典检测算法,YOLOX-tiny~YOLOv8s 4种YOLO系列检测算法,并与CMCE-Net算法在煤矿综掘工作面数据集、公共数据集上进行对比实验,实验结果如图12 、表2 、表3 所示. 表中,T1表示person,T2表示R-cutting,T3表示A-jumbolter,T4表示H-jumbolter,T5表示support,N p 为参数量. ...
1
... 为了进一步探究CMCE-Net检测性能的优越性与可靠性,选取Faster RCNN~CenterNet[33 -37 ] 4种经典检测算法,YOLOX-tiny~YOLOv8s 4种YOLO系列检测算法,并与CMCE-Net算法在煤矿综掘工作面数据集、公共数据集上进行对比实验,实验结果如图12 、表2 、表3 所示. 表中,T1表示person,T2表示R-cutting,T3表示A-jumbolter,T4表示H-jumbolter,T5表示support,N p 为参数量. ...









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}