[1]
王志忠 铁路施工安全管理的桎梏及应对
[J]. 中国安全科学学报 , 2021 , 31 (Suppl.1 ): 56 - 61
[本文引用: 1]
WANG Zhizhong Shackles of railway construction safety management and their countermeasures
[J]. China Safety Science Journal , 2021 , 31 (Suppl.1 ): 56 - 61
[本文引用: 1]
[2]
YANG B, FANG L Automated extraction of 3-D railway tracks from mobile laser scanning point clouds
[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , 2014 , 7 (12 ): 4750 - 4761
DOI:10.1109/JSTARS.2014.2312378
[本文引用: 1]
[3]
ZHU L, HYYPPA J The use of airborne and mobile laser scanning for modeling railway environments in 3D
[J]. Remote Sensing , 2014 , 6 (4 ): 3075 - 3100
DOI:10.3390/rs6043075
[本文引用: 1]
[5]
王泉东, 杨岳, 罗意平, 等 铁路侵限异物检测方法综述
[J]. 铁道科学与工程学报 , 2019 , 16 (12 ): 3152 - 3159
[本文引用: 1]
WANG Quandong, YANG Yue, LUO Yiping, et al Review on railway intrusion detection methods
[J]. Journal of Railway Science and Engineering , 2019 , 16 (12 ): 3152 - 3159
[本文引用: 1]
[6]
RISTIĆ-DURRANT D, FRANKE M, MICHELS K A review of vision-based on-board obstacle detection and distance estimation in railways
[J]. Sensors , 2021 , 21 (10 ): 3452
DOI:10.3390/s21103452
[本文引用: 1]
[7]
LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation [C]// IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 3431–3440.
[本文引用: 1]
[8]
RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation [C]// Medical Image Computing and Computer-Assisted Intervention . Munich: Springer, 2015: 234–241.
[本文引用: 1]
[9]
CHEN L C, ZHU Y, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation [C]// European Conference on Computer Vision . Munich: Springer, 2018: 833–851.
[本文引用: 1]
[10]
YU C, GAO C, WANG J, et al BiSeNet V2: bilateral network with guided aggregation for real-time semantic segmentation
[J]. International Journal of Computer Vision , 2021 , 129 : 3051 - 3068
DOI:10.1007/s11263-021-01515-2
[本文引用: 1]
[11]
LIN T Y, GOYAL P, GIRSHICK R, et al. Focal Loss for dense object detection [C]// 2017 IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2999–3007.
[本文引用: 1]
[12]
BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: optimal speed and accuracy of object detection [EB/OL]. (2020–04–23)[2024−03−05]. https://arxiv.org/pdf/2004.10934.
[本文引用: 1]
[13]
LIU S, QI L, QIN H, et al. Path aggregation network for instance segmentation [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 8759–8768.
[本文引用: 1]
[14]
TAN M, PANG R, LE Q V. EfficientDet: scalable and efficient object detection [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 10781–10790.
[本文引用: 1]
[15]
LORE K G, AKINTAYO A, SARKAR S LLNet: a deep autoencoder approach to natural low-light image enhancement
[J]. Pattern Recognition , 2017 , 61 : 650 - 662
DOI:10.1016/j.patcog.2016.06.008
[本文引用: 1]
[16]
LV F, LU F, WU J, et al. MBLLEN: low-light image/video enhancement using CNNs [C]// British Machine Vision Conference . Newcastle: [s.n.], 2018: 1–13.
[本文引用: 1]
[17]
WEI C, WANG W, YANG W, et al. Deep Retinex decomposition for low-light enhancement [EB/OL]. (2018−08−14)[2024−03−05]. https://arxiv.org/pdf/1808.04560.
[本文引用: 1]
[18]
ZHANG Y, ZHANG J, GUO X. Kindling the darkness: a practical low-light image enhancer [C]// Proceedings of the 27th ACM International Conference on Multimedia . [S.l.]: ACM, 2019: 1632–1640.
[本文引用: 1]
[19]
JIANG Y, GONG X, LIU D, et al EnlightenGAN: deep light enhancement without paired supervision
[J]. IEEE Transactions on Image Processing , 2021 , 30 : 2340 - 2349
DOI:10.1109/TIP.2021.3051462
[本文引用: 1]
[20]
ZHANG L, ZHANG L, LIU X, et al. Zero-shot restoration of back-lit images using deep internal learning [C]// Proceedings of the 27th ACM International Conference on Multimedia . [S.l.]: ACM, 2019: 1623–1631.
[本文引用: 1]
[21]
ZHU A, ZHANG L, SHEN Y, et al. Zero-shot restoration of underexposed images via robust Retinex decomposition [C]// 2020 IEEE International Conference on Multimedia and Expo . London: IEEE, 2020: 1–6.
[本文引用: 1]
[22]
GUO C, LI C, GUO J, et al. Zero-reference deep curve estimation for low-light image enhancement [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 1780–1789.
[本文引用: 3]
[23]
QI C R, SU H, MO K, et al. PointNet: deep learning on point sets for 3D classification and segmentation [C]// IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 652–660.
[本文引用: 1]
[24]
WU B, WAN A, YUE X, et al. SqueezeSeg: convolutional neural nets with recurrent CRF for real-time road-object segmentation from 3D LiDAR point cloud [C]// IEEE International Conference on Robotics and Automation . Brisbane: IEEE, 2018: 1887–1893.
[本文引用: 1]
[25]
ZHANG Y, ZHOU Z, DAVID P, et al. PolarNet: an improved grid representation for online LiDAR point clouds semantic segmentation [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 9601–9610.
[本文引用: 1]
[26]
ZHOU Y, TUZEL O. VoxelNet: end-to-end learning for point cloud based 3D object detection [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 4490–4499.
[本文引用: 1]
[27]
YAN Y, MAO Y, LI B SECOND: sparsely embedded convolutional detection
[J]. Sensors , 2018 , 18 (10 ): 3337
DOI:10.3390/s18103337
[本文引用: 1]
[28]
LANG A H, VORA S, CAESAR H, et al. PointPillars: fast encoders for object detection from point clouds [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 12697–12705.
[本文引用: 1]
[29]
SHI S, WANG X, LI H. PointRCNN: 3D object proposal generation and detection from point cloud [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 770–779.
[本文引用: 1]
[30]
SHI S, WANG Z, WANG X, et al. Part-A 2 net: 3D part-aware and aggregation neural network for object detection from point cloud [EB/OL]. (2020−03−16)[2024−03−05]. https://arxiv.org/pdf/1907.03670v1.
[本文引用: 1]
[31]
ZHANG Y, ZHANG Q, ZHU Z, et al GLENet: boosting 3D object detectors with generative label uncertainty estimation
[J]. International Journal of Computer Vision , 2023 , 131 : 3332 - 3352
DOI:10.1007/s11263-023-01869-9
[本文引用: 1]
[32]
SHI S, GUO C, JIANG L, et al. PV-RCNN: point-voxel feature set abstraction for 3D object detection [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 10529–10538.
[本文引用: 1]
[33]
PAN X, XIA Z, SONG S, et al. 3D object detection with pointformer [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 7463–7472.
[本文引用: 1]
[34]
SHENG H, CAI S, LIU Y, et al. Improving 3D object detection with channel-wise Transformer [C]// IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 2743–2752.
[本文引用: 1]
[35]
NABATI R, QI H. CenterFusion: center-based radar and camera fusion for 3D object detection [C]// IEEE Winter Conference on Applications of Computer Vision . Waikoloa: IEEE, 2021: 1527–1536.
[本文引用: 2]
[36]
VORA S, LANG A H, HELOU B, et al. PointPainting: sequential fusion for 3D object detection [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 4604–4612.
[本文引用: 2]
[37]
LIU Z, TANG H, AMINI A, et al. BEVFusion: multi-task multi-sensor fusion with unified bird’s-eye view representation [C]// IEEE International Conference on Robotics and Automation . London: IEEE, 2023: 2774–2781.
[本文引用: 3]
[38]
CAESAR H, BANKITI V, LANG A H, et al. NuScenes: a multimodal dataset for autonomous driving [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 11621–11631.
[本文引用: 1]
[40]
何文玉, 杨杰, 张天露 基于深度学习的轨道异物入侵检测算法
[J]. 计算机工程与设计 , 2020 , 41 (12 ): 3376 - 3383
[本文引用: 1]
HE Wenyu, YANG Jie, ZHANG Tianlu Orbital foreign object intrusion detection algorithm based on deep learning
[J]. Computer Engineering and Design , 2020 , 41 (12 ): 3376 - 3383
[本文引用: 1]
[42]
BAI X, HU Z, ZHU X, et al. TransFusion: robust LiDAR-camera fusion for 3D object detection with transformers [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 1090–1099.
[本文引用: 1]
[43]
CHEN X, ZHANG T, WANG Y, et al. FUTR3D: a unified sensor fusion framework for 3D detection [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops . Vancouver: IEEE, 2023: 172–181.
[本文引用: 1]
[44]
TONG L, WANG Z, JIA L, et al Fully decoupled residual ConvNet for real-time railway scene parsing of UAV aerial images
[J]. IEEE Transactions on Intelligent Transportation Systems , 2022 , 23 (9 ): 14806 - 14819
DOI:10.1109/TITS.2021.3134318
[本文引用: 1]
[45]
KIM B, KIM I, KIM N, et al SeMA-UNet: a semi-supervised learning with multimodal approach of UNet for effective segmentation of key components in railway images
[J]. Journal of Electrical Engineering and Technology , 2024 , 19 : 3317 - 3330
DOI:10.1007/s42835-024-01867-y
[本文引用: 1]
[46]
WU Y, MENG F, QIN Y, et al UAV imagery based potential safety hazard evaluation for high-speed railroad using real-time instance segmentation
[J]. Advanced Engineering Informatics , 2023 , 55 : 101819
DOI:10.1016/j.aei.2022.101819
[本文引用: 1]
[47]
WU Y, CHEN P, QIN Y, et al Automatic railroad track components inspection using hybrid deep learning framework
[J]. IEEE Transactions on Instrumentation and Measurement , 2023 , 72 : 5011415
[本文引用: 1]
[48]
CHEN Z, YANG J, ZHOU F RailSegVITNet: a lightweight VIT-based real-time track surface segmentation network for improving railroad safety
[J]. Journal of King Saud University-Computer and Information Sciences , 2024 , 36 (1 ): 101929
DOI:10.1016/j.jksuci.2024.101929
[本文引用: 1]
[49]
CHEN Z, YANG J, CHEN L, et al Efficient railway track region segmentation algorithm based on lightweight neural network and cross-fusion decoder
[J]. Automation in Construction , 2023 , 155 : 105069
DOI:10.1016/j.autcon.2023.105069
[本文引用: 2]
[50]
BRUCKER M, CRAMARIUC A, VON EINEM C, et al. Local and global information in obstacle detection on railway tracks [C]// IEEE/RSJ International Conference on Intelligent Robots and Systems . Detroit: IEEE, 2023: 9049–9056.
[本文引用: 1]
[51]
FENG Z, YANG J, CHEN Z, et al LRseg: an efficient railway region extraction method based on lightweight encoder and self-correcting decoder
[J]. Expert Systems with Applications , 2024 , 238 : 122386
DOI:10.1016/j.eswa.2023.122386
[本文引用: 1]
[52]
于新善, 孟祥印, 金腾飞, 等 基于改进Canny算法的物体边缘检测算法
[J]. 激光与光电子学进展 , 2023 , 60 (22 ): 2212002
DOI:10.3788/LOP223400
[本文引用: 1]
YU Xinshan, MENG Xiangyin, JIN Tengfei, et al Object edge detection algorithm based on improved Canny algorithm
[J]. Laser and Optoelectronics Progress , 2023 , 60 (22 ): 2212002
DOI:10.3788/LOP223400
[本文引用: 1]
[53]
LIU W, WANG L Quantum image edge detection based on eight-direction Sobel operator for NEQR
[J]. Quantum Information Processing , 2022 , 21 : 190
DOI:10.1007/s11128-022-03527-4
[本文引用: 1]
[55]
王世勇, 乾国康, 李迪, 等 面向边缘特征的实时模板匹配方法
[J]. 华南理工大学学报: 自然科学版 , 2023 , 51 (9 ): 1 - 10
[本文引用: 1]
WANG Shiyong, QIAN Guokang, LI Di, et al Real-time template matching method for edge features
[J]. Journal of South China University of Technology: Natural Science Edition , 2023 , 51 (9 ): 1 - 10
[本文引用: 1]
[56]
CHEN C, YANG B, SONG S, et al Automatic clearance anomaly detection for transmission line corridors utilizing UAV-borne LiDAR data
[J]. Remote Sensing , 2018 , 10 (4 ): 613
DOI:10.3390/rs10040613
[本文引用: 1]
[57]
LI H, DONG Y, LIU Y, et al Design and implementation of UAVs for bird’s nest inspection on transmission lines based on deep learning
[J]. Drones , 2022 , 6 (9 ): 252
DOI:10.3390/drones6090252
[本文引用: 1]
[58]
TANG C, DONG H, HUANG Y, et al Foreign object detection for transmission lines based on Swin Transformer V2 and YOLOX
[J]. The Visual Computer , 2024 , 40 : 3003 - 3021
DOI:10.1007/s00371-023-03004-8
[本文引用: 2]
[59]
YU Y, QIU Z, LIAO H, et al A method based on multi-network feature fusion and random forest for foreign objects detection on transmission lines
[J]. Applied Sciences , 2022 , 12 (10 ): 4982
DOI:10.3390/app12104982
[本文引用: 2]
[60]
CHEN Z, YANG J, FENG Z, et al RailFOD23: a dataset for foreign object detection on railroad transmission lines
[J]. Scientific Data , 2024 , 11 : 72
DOI:10.1038/s41597-024-02918-9
[本文引用: 2]
[61]
QIU Z, ZHU X, LIAO C, et al A lightweight YOLOv4-EDAM model for accurate and real-time detection of foreign objects suspended on power lines
[J]. IEEE Transactions on Power Delivery , 2022 , 38 (2 ): 1329 - 1340
[本文引用: 1]
[62]
LI S, LIU Y, LI M, et al DF-YOLO: highly accurate transmission line foreign object detection algorithm
[J]. IEEE Access , 2023 , 11 : 108398 - 108406
DOI:10.1109/ACCESS.2023.3321385
[本文引用: 1]
[63]
ZHANG W, LIU X, YUAN J, et al RCNN-based foreign object detection for securing power transmission lines (RCNN4SPTL)
[J]. Procedia Computer Science , 2019 , 147 : 331 - 337
DOI:10.1016/j.procs.2019.01.232
[本文引用: 1]
[64]
LI G, YANG Y, QU X, et al A deep learning based image enhancement approach for autonomous driving at night
[J]. Knowledge-Based Systems , 2021 , 213 : 106617
DOI:10.1016/j.knosys.2020.106617
[本文引用: 1]
[65]
刘文强. 基于深度学习的接触网支持装置状态检测方法研究[D]. 成都: 西南交通大学, 2021.
[本文引用: 1]
LIU Wenqiang. Study on deep learning-based state detection method study for catenary support devices [D]. Chengdu: Southwest Jiaotong University, 2021.
[本文引用: 1]
[66]
CHEN Z, YANG J, YANG C BrightsightNet: a lightweight progressive low-light image enhancement network and its application in “Rainbow” maglev train
[J]. Journal of King Saud University-Computer and Information Sciences , 2023 , 35 (10 ): 101814
DOI:10.1016/j.jksuci.2023.101814
[本文引用: 1]
[67]
LIN S, XU C, CHEN L, et al LiDAR point cloud recognition of overhead catenary system with deep learning
[J]. Sensors , 2020 , 20 (8 ): 2212
DOI:10.3390/s20082212
[本文引用: 1]
[68]
YU X, HE W, QIAN X, et al Real-time rail recognition based on 3D point clouds
[J]. Measurement Science and Technology , 2022 , 33 (10 ): 105207
DOI:10.1088/1361-6501/ac750c
[本文引用: 1]
[69]
DIBARI P, NITTI M, MAGLIETTA R, et al. Semantic segmentation of multimodal point clouds from the railway context [C]// Multimodal Sensing and Artificial Intelligence: Technologies and Applications II . Washington: SPIE, 2021, 11785: 158–166.
[本文引用: 1]
[70]
GRANDIO J, RIVEIRO B, SOILÁN M, et al Point cloud semantic segmentation of complex railway environments using deep learning
[J]. Automation in Construction , 2022 , 141 : 104425
DOI:10.1016/j.autcon.2022.104425
[本文引用: 2]
[71]
SOILÁN M, NÓVOA A, SÁNCHEZ-RODRÍGUEZ A, et al Semantic segmentation of point clouds with PointNet and KPConv architectures applied to railway tunnels
[J]. ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences , 2020 , 2 : 281 - 288
[本文引用: 1]
[72]
WANG Z, YU G, CHEN P, et al FarNet: an attention-aggregation network for long-range rail track point cloud segmentation
[J]. IEEE Transactions on Intelligent Transportation Systems , 2022 , 23 (8 ): 13118 - 13126
DOI:10.1109/TITS.2021.3119900
[本文引用: 3]
[73]
LIU P, YU G, WANG Z, et al Uncertainty-aware point-cloud semantic segmentation for unstructured roads
[J]. IEEE Sensors Journal , 2023 , 23 (13 ): 15071 - 15080
DOI:10.1109/JSEN.2023.3266802
[本文引用: 1]
[74]
MAURI A, KHEMMAR R, DECOUX B, et al Real-time 3D multi-object detection and localization based on deep learning for road and railway smart mobility
[J]. Journal of Imaging , 2021 , 7 (8 ): 145
DOI:10.3390/jimaging7080145
[本文引用: 1]
[75]
MAURI A, KHEMMAR R, DECOUX B, et al Lightweight convolutional neural network for real-time 3D object detection in road and railway environments
[J]. Journal of Real-Time Image Processing , 2022 , 19 : 499 - 516
DOI:10.1007/s11554-022-01202-6
[本文引用: 1]
[76]
TAGIEW R, KLASEK P, TILLY R, et al. OSDaR23: open sensor data for rail 2023 [C]// International Conference on Robotics and Automation Engineering . Singapore: IEEE, 2023: 270–276.
[本文引用: 2]
[77]
KOPUZ E. Multi-modal 3D object detection in long range and low-resolution conditions of sensors [D]. Munich: Technical University of Munich, 2023.
[本文引用: 2]
[78]
WU Y, QIN Y, QIAN Y, et al Automatic detection of arbitrarily oriented fastener defect in high-speed railway
[J]. Automation in Construction , 2021 , 131 : 103913
DOI:10.1016/j.autcon.2021.103913
[本文引用: 1]
[79]
WU Y, QIN Y, QIAN Y, et al Hybrid deep learning architecture for rail surface segmentation and surface defect detection
[J]. Computer-Aided Civil and Infrastructure Engineering , 2022 , 37 (2 ): 227 - 244
DOI:10.1111/mice.12710
[本文引用: 1]
铁路施工安全管理的桎梏及应对
1
2021
... 火车、轮船和飞机等交通工具的发明与每次重大革新都会推动人类文明的快速发展,使世界格局发生巨大变化. 轨道交通是国之重器、国家名片,为提高运输能力、降低运输成本和缓解交通压力做出了巨大贡献. 轨道交通系统的运行速度不断提高,路网环境日益复杂,现行基于驾驶员肉眼瞭望的感知方法越来越难以适应安全、智能、绿色的发展要求. 2021年6月,兰新线K596次列车在曲线地段瞭望视线受阻,与跨线转移的维修人员相撞,造成9人当场死亡[1 ] . 其他列车与侵限车辆、动物或障碍物等发生碰撞的事故也是屡见不鲜,人员伤亡和经济损失触目惊心,基于新一代信息技术研究更加智能高效的线路环境感知方法迫在眉睫. ...
铁路施工安全管理的桎梏及应对
1
2021
... 火车、轮船和飞机等交通工具的发明与每次重大革新都会推动人类文明的快速发展,使世界格局发生巨大变化. 轨道交通是国之重器、国家名片,为提高运输能力、降低运输成本和缓解交通压力做出了巨大贡献. 轨道交通系统的运行速度不断提高,路网环境日益复杂,现行基于驾驶员肉眼瞭望的感知方法越来越难以适应安全、智能、绿色的发展要求. 2021年6月,兰新线K596次列车在曲线地段瞭望视线受阻,与跨线转移的维修人员相撞,造成9人当场死亡[1 ] . 其他列车与侵限车辆、动物或障碍物等发生碰撞的事故也是屡见不鲜,人员伤亡和经济损失触目惊心,基于新一代信息技术研究更加智能高效的线路环境感知方法迫在眉睫. ...
Automated extraction of 3-D railway tracks from mobile laser scanning point clouds
1
2014
... 随着传感器技术的不断升级和人工智能的迅猛发展,相机与激光雷达已成为环境感知领域中不可或缺的传感器. 相机作为被动型传感器,具有高分辨率的特点,能够捕捉列车周围丰富的视觉信息;激光雷达作为主动型传感器,通过主动发射激光束并测量反射时间获取场景的三维点云数据. 因此,以相机和激光雷达为核心的关键算法在理解真实场景、识别异常状态方面具有重要的研究价值. 传统的列车运行环境感知研究[2 -3 ] 主要采用手工特征提取方法,通过预先定义和选择特定视觉或激光雷达特征来识别和描述周围环境. 手工特征提取方法普遍依赖大量的专业知识和经验,存在设计难度大和泛化能力差的缺点. 深度学习[4 ] 的出现使感知系统得以自动提取数据内的关键抽象特征,智能化地解析来自相机与激光雷达的信息,为列车的环境感知问题提供了更为高效的解决方案. ...
The use of airborne and mobile laser scanning for modeling railway environments in 3D
1
2014
... 随着传感器技术的不断升级和人工智能的迅猛发展,相机与激光雷达已成为环境感知领域中不可或缺的传感器. 相机作为被动型传感器,具有高分辨率的特点,能够捕捉列车周围丰富的视觉信息;激光雷达作为主动型传感器,通过主动发射激光束并测量反射时间获取场景的三维点云数据. 因此,以相机和激光雷达为核心的关键算法在理解真实场景、识别异常状态方面具有重要的研究价值. 传统的列车运行环境感知研究[2 -3 ] 主要采用手工特征提取方法,通过预先定义和选择特定视觉或激光雷达特征来识别和描述周围环境. 手工特征提取方法普遍依赖大量的专业知识和经验,存在设计难度大和泛化能力差的缺点. 深度学习[4 ] 的出现使感知系统得以自动提取数据内的关键抽象特征,智能化地解析来自相机与激光雷达的信息,为列车的环境感知问题提供了更为高效的解决方案. ...
Deep learning
1
2015
... 随着传感器技术的不断升级和人工智能的迅猛发展,相机与激光雷达已成为环境感知领域中不可或缺的传感器. 相机作为被动型传感器,具有高分辨率的特点,能够捕捉列车周围丰富的视觉信息;激光雷达作为主动型传感器,通过主动发射激光束并测量反射时间获取场景的三维点云数据. 因此,以相机和激光雷达为核心的关键算法在理解真实场景、识别异常状态方面具有重要的研究价值. 传统的列车运行环境感知研究[2 -3 ] 主要采用手工特征提取方法,通过预先定义和选择特定视觉或激光雷达特征来识别和描述周围环境. 手工特征提取方法普遍依赖大量的专业知识和经验,存在设计难度大和泛化能力差的缺点. 深度学习[4 ] 的出现使感知系统得以自动提取数据内的关键抽象特征,智能化地解析来自相机与激光雷达的信息,为列车的环境感知问题提供了更为高效的解决方案. ...
铁路侵限异物检测方法综述
1
2019
... 针对列车运行环境感知的综述文献不少. 王泉东等[5 ] 从硬件防护方面论述异物检测的实现原理和相关研究,较少涉及算法研究. Ristić-Durrant等[6 ] 以基于手工视觉特征的方法为主,综述轨道交通障碍物感知方面的研究,较少介绍主流的基于深度学习的方法. 本文将深入分析和讨论深度学习技术在列车运行环境感知中的应用和进展,重点阐述以相机和激光雷达作为数据驱动源的关键感知算法的原理和实现方式,揭示列车运行环境感知技术面临的主要挑战,提出针对未来研究方向的建议. ...
铁路侵限异物检测方法综述
1
2019
... 针对列车运行环境感知的综述文献不少. 王泉东等[5 ] 从硬件防护方面论述异物检测的实现原理和相关研究,较少涉及算法研究. Ristić-Durrant等[6 ] 以基于手工视觉特征的方法为主,综述轨道交通障碍物感知方面的研究,较少介绍主流的基于深度学习的方法. 本文将深入分析和讨论深度学习技术在列车运行环境感知中的应用和进展,重点阐述以相机和激光雷达作为数据驱动源的关键感知算法的原理和实现方式,揭示列车运行环境感知技术面临的主要挑战,提出针对未来研究方向的建议. ...
A review of vision-based on-board obstacle detection and distance estimation in railways
1
2021
... 针对列车运行环境感知的综述文献不少. 王泉东等[5 ] 从硬件防护方面论述异物检测的实现原理和相关研究,较少涉及算法研究. Ristić-Durrant等[6 ] 以基于手工视觉特征的方法为主,综述轨道交通障碍物感知方面的研究,较少介绍主流的基于深度学习的方法. 本文将深入分析和讨论深度学习技术在列车运行环境感知中的应用和进展,重点阐述以相机和激光雷达作为数据驱动源的关键感知算法的原理和实现方式,揭示列车运行环境感知技术面临的主要挑战,提出针对未来研究方向的建议. ...
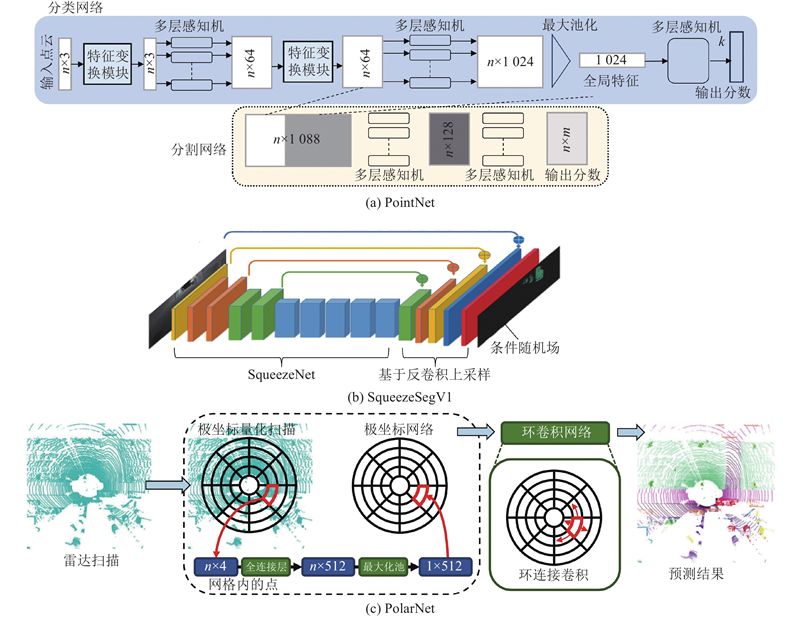
1
... 语义分割是计算机视觉领域中的重要任务,目的是将图像划分为具有语义信息的各个区域并为每个像素分配相应的语义标签. 深度学习已经成为语义分割的主流解决方案. Long等[7 ] 提出全卷积网络(fully convolutional networks, FCN)用于语义分割任务,FCN在VOC 2012数据集中使分割精度提高了约20%,推动了语义分割技术的发展. 如图2 所示为基于深度学习的语义分割主流架构,FCN的提出奠定了语义分割任务中编码器-解码器的架构基础. 在编码过程中,将传统分类网络的全连接层替换为卷积层,实现对深层语义信息的编码;在解码过程中,通过转置卷积进行上采样,逐步恢复图像的细节信息并扩大特征图的尺寸. Ronneberger等[8 ] 借鉴了FCN的设计思路,在编码器-解码器的基础上引入跨层拼接操作,提出U-Net模型对语义信息和空间信息进行均衡. Deeplab系列[9 ] 通过在深度卷积网络后嵌入空洞卷积来提升编码器的感受野. Yu等[10 ] 提出在语义分割任务中既需要足够大的感受野又需要充分的空间信息的观点,所设计的BiSeNet模型采用双边路径对语义信息和空间信息进行解耦,随后对双边路径产生的特征图进行融合,提升了分割精度. ...
1
... 语义分割是计算机视觉领域中的重要任务,目的是将图像划分为具有语义信息的各个区域并为每个像素分配相应的语义标签. 深度学习已经成为语义分割的主流解决方案. Long等[7 ] 提出全卷积网络(fully convolutional networks, FCN)用于语义分割任务,FCN在VOC 2012数据集中使分割精度提高了约20%,推动了语义分割技术的发展. 如图2 所示为基于深度学习的语义分割主流架构,FCN的提出奠定了语义分割任务中编码器-解码器的架构基础. 在编码过程中,将传统分类网络的全连接层替换为卷积层,实现对深层语义信息的编码;在解码过程中,通过转置卷积进行上采样,逐步恢复图像的细节信息并扩大特征图的尺寸. Ronneberger等[8 ] 借鉴了FCN的设计思路,在编码器-解码器的基础上引入跨层拼接操作,提出U-Net模型对语义信息和空间信息进行均衡. Deeplab系列[9 ] 通过在深度卷积网络后嵌入空洞卷积来提升编码器的感受野. Yu等[10 ] 提出在语义分割任务中既需要足够大的感受野又需要充分的空间信息的观点,所设计的BiSeNet模型采用双边路径对语义信息和空间信息进行解耦,随后对双边路径产生的特征图进行融合,提升了分割精度. ...
1
... 语义分割是计算机视觉领域中的重要任务,目的是将图像划分为具有语义信息的各个区域并为每个像素分配相应的语义标签. 深度学习已经成为语义分割的主流解决方案. Long等[7 ] 提出全卷积网络(fully convolutional networks, FCN)用于语义分割任务,FCN在VOC 2012数据集中使分割精度提高了约20%,推动了语义分割技术的发展. 如图2 所示为基于深度学习的语义分割主流架构,FCN的提出奠定了语义分割任务中编码器-解码器的架构基础. 在编码过程中,将传统分类网络的全连接层替换为卷积层,实现对深层语义信息的编码;在解码过程中,通过转置卷积进行上采样,逐步恢复图像的细节信息并扩大特征图的尺寸. Ronneberger等[8 ] 借鉴了FCN的设计思路,在编码器-解码器的基础上引入跨层拼接操作,提出U-Net模型对语义信息和空间信息进行均衡. Deeplab系列[9 ] 通过在深度卷积网络后嵌入空洞卷积来提升编码器的感受野. Yu等[10 ] 提出在语义分割任务中既需要足够大的感受野又需要充分的空间信息的观点,所设计的BiSeNet模型采用双边路径对语义信息和空间信息进行解耦,随后对双边路径产生的特征图进行融合,提升了分割精度. ...
BiSeNet V2: bilateral network with guided aggregation for real-time semantic segmentation
1
2021
... 语义分割是计算机视觉领域中的重要任务,目的是将图像划分为具有语义信息的各个区域并为每个像素分配相应的语义标签. 深度学习已经成为语义分割的主流解决方案. Long等[7 ] 提出全卷积网络(fully convolutional networks, FCN)用于语义分割任务,FCN在VOC 2012数据集中使分割精度提高了约20%,推动了语义分割技术的发展. 如图2 所示为基于深度学习的语义分割主流架构,FCN的提出奠定了语义分割任务中编码器-解码器的架构基础. 在编码过程中,将传统分类网络的全连接层替换为卷积层,实现对深层语义信息的编码;在解码过程中,通过转置卷积进行上采样,逐步恢复图像的细节信息并扩大特征图的尺寸. Ronneberger等[8 ] 借鉴了FCN的设计思路,在编码器-解码器的基础上引入跨层拼接操作,提出U-Net模型对语义信息和空间信息进行均衡. Deeplab系列[9 ] 通过在深度卷积网络后嵌入空洞卷积来提升编码器的感受野. Yu等[10 ] 提出在语义分割任务中既需要足够大的感受野又需要充分的空间信息的观点,所设计的BiSeNet模型采用双边路径对语义信息和空间信息进行解耦,随后对双边路径产生的特征图进行融合,提升了分割精度. ...
1
... 如图3 所示,主流的基于深度学习的目标检测算法可以分为两阶段和单阶段2种. 两阶段检测方法在输入数据经过主干网络后,须借助区域建议网络(region proposal network, RPN)生成建议区域,再对所生成的区域进行更精细的分类和定位. 单阶段算法没有建议区域的生成步骤,直接在主干网络产生的中间特征图上进行目标的分类与位置回归,在一次检测后即得到最终结果,处理速度显著提升. 得益于损失函数、数据增强和特征聚合等方面的优化,单阶段目标检测算法在检测精度方面逐渐超越两阶段检测器. 例如,Focal Loss[11 ] 能够有效缓解训练中的正负样本不平衡问题,广义交并比(generalized intersection over union, GIoU)和距离交并比 (distance intersection over union, DIoU)损失函数进一步提升了定位精度. 在数据增强方面,自YOLO v4[12 ] 起采用的Mosaic方法增加了训练数据的多样性和复杂性. 在特征聚合上,路径聚合网络[13 ] (path aggregation network, PAN)和双向特征金字塔网络[14 ] (bidirectional feature pyramid network, BIFPN)实现了多尺度信息的高效整合. ...
1
... 如图3 所示,主流的基于深度学习的目标检测算法可以分为两阶段和单阶段2种. 两阶段检测方法在输入数据经过主干网络后,须借助区域建议网络(region proposal network, RPN)生成建议区域,再对所生成的区域进行更精细的分类和定位. 单阶段算法没有建议区域的生成步骤,直接在主干网络产生的中间特征图上进行目标的分类与位置回归,在一次检测后即得到最终结果,处理速度显著提升. 得益于损失函数、数据增强和特征聚合等方面的优化,单阶段目标检测算法在检测精度方面逐渐超越两阶段检测器. 例如,Focal Loss[11 ] 能够有效缓解训练中的正负样本不平衡问题,广义交并比(generalized intersection over union, GIoU)和距离交并比 (distance intersection over union, DIoU)损失函数进一步提升了定位精度. 在数据增强方面,自YOLO v4[12 ] 起采用的Mosaic方法增加了训练数据的多样性和复杂性. 在特征聚合上,路径聚合网络[13 ] (path aggregation network, PAN)和双向特征金字塔网络[14 ] (bidirectional feature pyramid network, BIFPN)实现了多尺度信息的高效整合. ...
1
... 如图3 所示,主流的基于深度学习的目标检测算法可以分为两阶段和单阶段2种. 两阶段检测方法在输入数据经过主干网络后,须借助区域建议网络(region proposal network, RPN)生成建议区域,再对所生成的区域进行更精细的分类和定位. 单阶段算法没有建议区域的生成步骤,直接在主干网络产生的中间特征图上进行目标的分类与位置回归,在一次检测后即得到最终结果,处理速度显著提升. 得益于损失函数、数据增强和特征聚合等方面的优化,单阶段目标检测算法在检测精度方面逐渐超越两阶段检测器. 例如,Focal Loss[11 ] 能够有效缓解训练中的正负样本不平衡问题,广义交并比(generalized intersection over union, GIoU)和距离交并比 (distance intersection over union, DIoU)损失函数进一步提升了定位精度. 在数据增强方面,自YOLO v4[12 ] 起采用的Mosaic方法增加了训练数据的多样性和复杂性. 在特征聚合上,路径聚合网络[13 ] (path aggregation network, PAN)和双向特征金字塔网络[14 ] (bidirectional feature pyramid network, BIFPN)实现了多尺度信息的高效整合. ...
1
... 如图3 所示,主流的基于深度学习的目标检测算法可以分为两阶段和单阶段2种. 两阶段检测方法在输入数据经过主干网络后,须借助区域建议网络(region proposal network, RPN)生成建议区域,再对所生成的区域进行更精细的分类和定位. 单阶段算法没有建议区域的生成步骤,直接在主干网络产生的中间特征图上进行目标的分类与位置回归,在一次检测后即得到最终结果,处理速度显著提升. 得益于损失函数、数据增强和特征聚合等方面的优化,单阶段目标检测算法在检测精度方面逐渐超越两阶段检测器. 例如,Focal Loss[11 ] 能够有效缓解训练中的正负样本不平衡问题,广义交并比(generalized intersection over union, GIoU)和距离交并比 (distance intersection over union, DIoU)损失函数进一步提升了定位精度. 在数据增强方面,自YOLO v4[12 ] 起采用的Mosaic方法增加了训练数据的多样性和复杂性. 在特征聚合上,路径聚合网络[13 ] (path aggregation network, PAN)和双向特征金字塔网络[14 ] (bidirectional feature pyramid network, BIFPN)实现了多尺度信息的高效整合. ...
LLNet: a deep autoencoder approach to natural low-light image enhancement
1
2017
... 低照度图像增强的核心目标是恢复图像的亮度和对比度至理想水平,为其他视觉感知任务提供更为清晰的图像输入,有效促进图像分类、目标检测、语义分割等下游感知任务识别精度的提升. Lore等[15 ] 提出基于深度学习的弱光图像增强网络LLNet,该网络通过堆叠深度自编码器实现图像增强. Lv等[16 ] 采用多分支网络结构分别处理噪声、光照和对比度. Wei等[17 ] 基于视网膜理论提出Retinex-Net,将图像解构为物体固有颜色的反射分量与场景照明的光分量的乘积. Zhang等[18 ] 扩展了Retinex-Net模型,以更加复杂的网络架构进一步提升视觉质量. 虽然这些方法在提升低光图像质量方面取得了显著成效,但是监督学习的方法须获取与低光照图像配对的高质量标签图像,由此出现了一系列基于无监督学习的方案. EnlightenGAN[19 ] 利用生成对抗网络架构,在无监督的训练环境下,通过生成和对抗过程,实现了对图像亮度和对比度的自动调整. ExCNet[20 ] 是零样本自监督学习方法,通过估计图像内容的S形曲线来恢复亮度. RRDNet[21 ] 是为曝光不足图像恢复而设计的三分支CNN,通过使用专门的损失函数来训练网络. 尽管EnlightenGAN、ExCNet、RRDNet等方法在处理图像增强问题方面取得了显著进展,但在实时处理方面仍存在局限性. Guo等[22 ] 提出轻量级的零参考深度曲线估计算法(zero-reference deep curve estimation, ZeroDCE),算法的整体架构如图4 所示. ZeroDCE基于光曲线增强理论,通过构建编码器-解码器结构来预测光曲线的关键参数,并通过一系列自监督损失函数优化网络,显著提高了低光条件下图像质量. Zero-DCE的参数规模较小,与Retinex-Net、EnlightenGAN、RRDNet等模型相比,更适用于实时处理. ...
1
... 低照度图像增强的核心目标是恢复图像的亮度和对比度至理想水平,为其他视觉感知任务提供更为清晰的图像输入,有效促进图像分类、目标检测、语义分割等下游感知任务识别精度的提升. Lore等[15 ] 提出基于深度学习的弱光图像增强网络LLNet,该网络通过堆叠深度自编码器实现图像增强. Lv等[16 ] 采用多分支网络结构分别处理噪声、光照和对比度. Wei等[17 ] 基于视网膜理论提出Retinex-Net,将图像解构为物体固有颜色的反射分量与场景照明的光分量的乘积. Zhang等[18 ] 扩展了Retinex-Net模型,以更加复杂的网络架构进一步提升视觉质量. 虽然这些方法在提升低光图像质量方面取得了显著成效,但是监督学习的方法须获取与低光照图像配对的高质量标签图像,由此出现了一系列基于无监督学习的方案. EnlightenGAN[19 ] 利用生成对抗网络架构,在无监督的训练环境下,通过生成和对抗过程,实现了对图像亮度和对比度的自动调整. ExCNet[20 ] 是零样本自监督学习方法,通过估计图像内容的S形曲线来恢复亮度. RRDNet[21 ] 是为曝光不足图像恢复而设计的三分支CNN,通过使用专门的损失函数来训练网络. 尽管EnlightenGAN、ExCNet、RRDNet等方法在处理图像增强问题方面取得了显著进展,但在实时处理方面仍存在局限性. Guo等[22 ] 提出轻量级的零参考深度曲线估计算法(zero-reference deep curve estimation, ZeroDCE),算法的整体架构如图4 所示. ZeroDCE基于光曲线增强理论,通过构建编码器-解码器结构来预测光曲线的关键参数,并通过一系列自监督损失函数优化网络,显著提高了低光条件下图像质量. Zero-DCE的参数规模较小,与Retinex-Net、EnlightenGAN、RRDNet等模型相比,更适用于实时处理. ...
1
... 低照度图像增强的核心目标是恢复图像的亮度和对比度至理想水平,为其他视觉感知任务提供更为清晰的图像输入,有效促进图像分类、目标检测、语义分割等下游感知任务识别精度的提升. Lore等[15 ] 提出基于深度学习的弱光图像增强网络LLNet,该网络通过堆叠深度自编码器实现图像增强. Lv等[16 ] 采用多分支网络结构分别处理噪声、光照和对比度. Wei等[17 ] 基于视网膜理论提出Retinex-Net,将图像解构为物体固有颜色的反射分量与场景照明的光分量的乘积. Zhang等[18 ] 扩展了Retinex-Net模型,以更加复杂的网络架构进一步提升视觉质量. 虽然这些方法在提升低光图像质量方面取得了显著成效,但是监督学习的方法须获取与低光照图像配对的高质量标签图像,由此出现了一系列基于无监督学习的方案. EnlightenGAN[19 ] 利用生成对抗网络架构,在无监督的训练环境下,通过生成和对抗过程,实现了对图像亮度和对比度的自动调整. ExCNet[20 ] 是零样本自监督学习方法,通过估计图像内容的S形曲线来恢复亮度. RRDNet[21 ] 是为曝光不足图像恢复而设计的三分支CNN,通过使用专门的损失函数来训练网络. 尽管EnlightenGAN、ExCNet、RRDNet等方法在处理图像增强问题方面取得了显著进展,但在实时处理方面仍存在局限性. Guo等[22 ] 提出轻量级的零参考深度曲线估计算法(zero-reference deep curve estimation, ZeroDCE),算法的整体架构如图4 所示. ZeroDCE基于光曲线增强理论,通过构建编码器-解码器结构来预测光曲线的关键参数,并通过一系列自监督损失函数优化网络,显著提高了低光条件下图像质量. Zero-DCE的参数规模较小,与Retinex-Net、EnlightenGAN、RRDNet等模型相比,更适用于实时处理. ...
1
... 低照度图像增强的核心目标是恢复图像的亮度和对比度至理想水平,为其他视觉感知任务提供更为清晰的图像输入,有效促进图像分类、目标检测、语义分割等下游感知任务识别精度的提升. Lore等[15 ] 提出基于深度学习的弱光图像增强网络LLNet,该网络通过堆叠深度自编码器实现图像增强. Lv等[16 ] 采用多分支网络结构分别处理噪声、光照和对比度. Wei等[17 ] 基于视网膜理论提出Retinex-Net,将图像解构为物体固有颜色的反射分量与场景照明的光分量的乘积. Zhang等[18 ] 扩展了Retinex-Net模型,以更加复杂的网络架构进一步提升视觉质量. 虽然这些方法在提升低光图像质量方面取得了显著成效,但是监督学习的方法须获取与低光照图像配对的高质量标签图像,由此出现了一系列基于无监督学习的方案. EnlightenGAN[19 ] 利用生成对抗网络架构,在无监督的训练环境下,通过生成和对抗过程,实现了对图像亮度和对比度的自动调整. ExCNet[20 ] 是零样本自监督学习方法,通过估计图像内容的S形曲线来恢复亮度. RRDNet[21 ] 是为曝光不足图像恢复而设计的三分支CNN,通过使用专门的损失函数来训练网络. 尽管EnlightenGAN、ExCNet、RRDNet等方法在处理图像增强问题方面取得了显著进展,但在实时处理方面仍存在局限性. Guo等[22 ] 提出轻量级的零参考深度曲线估计算法(zero-reference deep curve estimation, ZeroDCE),算法的整体架构如图4 所示. ZeroDCE基于光曲线增强理论,通过构建编码器-解码器结构来预测光曲线的关键参数,并通过一系列自监督损失函数优化网络,显著提高了低光条件下图像质量. Zero-DCE的参数规模较小,与Retinex-Net、EnlightenGAN、RRDNet等模型相比,更适用于实时处理. ...
EnlightenGAN: deep light enhancement without paired supervision
1
2021
... 低照度图像增强的核心目标是恢复图像的亮度和对比度至理想水平,为其他视觉感知任务提供更为清晰的图像输入,有效促进图像分类、目标检测、语义分割等下游感知任务识别精度的提升. Lore等[15 ] 提出基于深度学习的弱光图像增强网络LLNet,该网络通过堆叠深度自编码器实现图像增强. Lv等[16 ] 采用多分支网络结构分别处理噪声、光照和对比度. Wei等[17 ] 基于视网膜理论提出Retinex-Net,将图像解构为物体固有颜色的反射分量与场景照明的光分量的乘积. Zhang等[18 ] 扩展了Retinex-Net模型,以更加复杂的网络架构进一步提升视觉质量. 虽然这些方法在提升低光图像质量方面取得了显著成效,但是监督学习的方法须获取与低光照图像配对的高质量标签图像,由此出现了一系列基于无监督学习的方案. EnlightenGAN[19 ] 利用生成对抗网络架构,在无监督的训练环境下,通过生成和对抗过程,实现了对图像亮度和对比度的自动调整. ExCNet[20 ] 是零样本自监督学习方法,通过估计图像内容的S形曲线来恢复亮度. RRDNet[21 ] 是为曝光不足图像恢复而设计的三分支CNN,通过使用专门的损失函数来训练网络. 尽管EnlightenGAN、ExCNet、RRDNet等方法在处理图像增强问题方面取得了显著进展,但在实时处理方面仍存在局限性. Guo等[22 ] 提出轻量级的零参考深度曲线估计算法(zero-reference deep curve estimation, ZeroDCE),算法的整体架构如图4 所示. ZeroDCE基于光曲线增强理论,通过构建编码器-解码器结构来预测光曲线的关键参数,并通过一系列自监督损失函数优化网络,显著提高了低光条件下图像质量. Zero-DCE的参数规模较小,与Retinex-Net、EnlightenGAN、RRDNet等模型相比,更适用于实时处理. ...
1
... 低照度图像增强的核心目标是恢复图像的亮度和对比度至理想水平,为其他视觉感知任务提供更为清晰的图像输入,有效促进图像分类、目标检测、语义分割等下游感知任务识别精度的提升. Lore等[15 ] 提出基于深度学习的弱光图像增强网络LLNet,该网络通过堆叠深度自编码器实现图像增强. Lv等[16 ] 采用多分支网络结构分别处理噪声、光照和对比度. Wei等[17 ] 基于视网膜理论提出Retinex-Net,将图像解构为物体固有颜色的反射分量与场景照明的光分量的乘积. Zhang等[18 ] 扩展了Retinex-Net模型,以更加复杂的网络架构进一步提升视觉质量. 虽然这些方法在提升低光图像质量方面取得了显著成效,但是监督学习的方法须获取与低光照图像配对的高质量标签图像,由此出现了一系列基于无监督学习的方案. EnlightenGAN[19 ] 利用生成对抗网络架构,在无监督的训练环境下,通过生成和对抗过程,实现了对图像亮度和对比度的自动调整. ExCNet[20 ] 是零样本自监督学习方法,通过估计图像内容的S形曲线来恢复亮度. RRDNet[21 ] 是为曝光不足图像恢复而设计的三分支CNN,通过使用专门的损失函数来训练网络. 尽管EnlightenGAN、ExCNet、RRDNet等方法在处理图像增强问题方面取得了显著进展,但在实时处理方面仍存在局限性. Guo等[22 ] 提出轻量级的零参考深度曲线估计算法(zero-reference deep curve estimation, ZeroDCE),算法的整体架构如图4 所示. ZeroDCE基于光曲线增强理论,通过构建编码器-解码器结构来预测光曲线的关键参数,并通过一系列自监督损失函数优化网络,显著提高了低光条件下图像质量. Zero-DCE的参数规模较小,与Retinex-Net、EnlightenGAN、RRDNet等模型相比,更适用于实时处理. ...
1
... 低照度图像增强的核心目标是恢复图像的亮度和对比度至理想水平,为其他视觉感知任务提供更为清晰的图像输入,有效促进图像分类、目标检测、语义分割等下游感知任务识别精度的提升. Lore等[15 ] 提出基于深度学习的弱光图像增强网络LLNet,该网络通过堆叠深度自编码器实现图像增强. Lv等[16 ] 采用多分支网络结构分别处理噪声、光照和对比度. Wei等[17 ] 基于视网膜理论提出Retinex-Net,将图像解构为物体固有颜色的反射分量与场景照明的光分量的乘积. Zhang等[18 ] 扩展了Retinex-Net模型,以更加复杂的网络架构进一步提升视觉质量. 虽然这些方法在提升低光图像质量方面取得了显著成效,但是监督学习的方法须获取与低光照图像配对的高质量标签图像,由此出现了一系列基于无监督学习的方案. EnlightenGAN[19 ] 利用生成对抗网络架构,在无监督的训练环境下,通过生成和对抗过程,实现了对图像亮度和对比度的自动调整. ExCNet[20 ] 是零样本自监督学习方法,通过估计图像内容的S形曲线来恢复亮度. RRDNet[21 ] 是为曝光不足图像恢复而设计的三分支CNN,通过使用专门的损失函数来训练网络. 尽管EnlightenGAN、ExCNet、RRDNet等方法在处理图像增强问题方面取得了显著进展,但在实时处理方面仍存在局限性. Guo等[22 ] 提出轻量级的零参考深度曲线估计算法(zero-reference deep curve estimation, ZeroDCE),算法的整体架构如图4 所示. ZeroDCE基于光曲线增强理论,通过构建编码器-解码器结构来预测光曲线的关键参数,并通过一系列自监督损失函数优化网络,显著提高了低光条件下图像质量. Zero-DCE的参数规模较小,与Retinex-Net、EnlightenGAN、RRDNet等模型相比,更适用于实时处理. ...
3
... 低照度图像增强的核心目标是恢复图像的亮度和对比度至理想水平,为其他视觉感知任务提供更为清晰的图像输入,有效促进图像分类、目标检测、语义分割等下游感知任务识别精度的提升. Lore等[15 ] 提出基于深度学习的弱光图像增强网络LLNet,该网络通过堆叠深度自编码器实现图像增强. Lv等[16 ] 采用多分支网络结构分别处理噪声、光照和对比度. Wei等[17 ] 基于视网膜理论提出Retinex-Net,将图像解构为物体固有颜色的反射分量与场景照明的光分量的乘积. Zhang等[18 ] 扩展了Retinex-Net模型,以更加复杂的网络架构进一步提升视觉质量. 虽然这些方法在提升低光图像质量方面取得了显著成效,但是监督学习的方法须获取与低光照图像配对的高质量标签图像,由此出现了一系列基于无监督学习的方案. EnlightenGAN[19 ] 利用生成对抗网络架构,在无监督的训练环境下,通过生成和对抗过程,实现了对图像亮度和对比度的自动调整. ExCNet[20 ] 是零样本自监督学习方法,通过估计图像内容的S形曲线来恢复亮度. RRDNet[21 ] 是为曝光不足图像恢复而设计的三分支CNN,通过使用专门的损失函数来训练网络. 尽管EnlightenGAN、ExCNet、RRDNet等方法在处理图像增强问题方面取得了显著进展,但在实时处理方面仍存在局限性. Guo等[22 ] 提出轻量级的零参考深度曲线估计算法(zero-reference deep curve estimation, ZeroDCE),算法的整体架构如图4 所示. ZeroDCE基于光曲线增强理论,通过构建编码器-解码器结构来预测光曲线的关键参数,并通过一系列自监督损失函数优化网络,显著提高了低光条件下图像质量. Zero-DCE的参数规模较小,与Retinex-Net、EnlightenGAN、RRDNet等模型相比,更适用于实时处理. ...
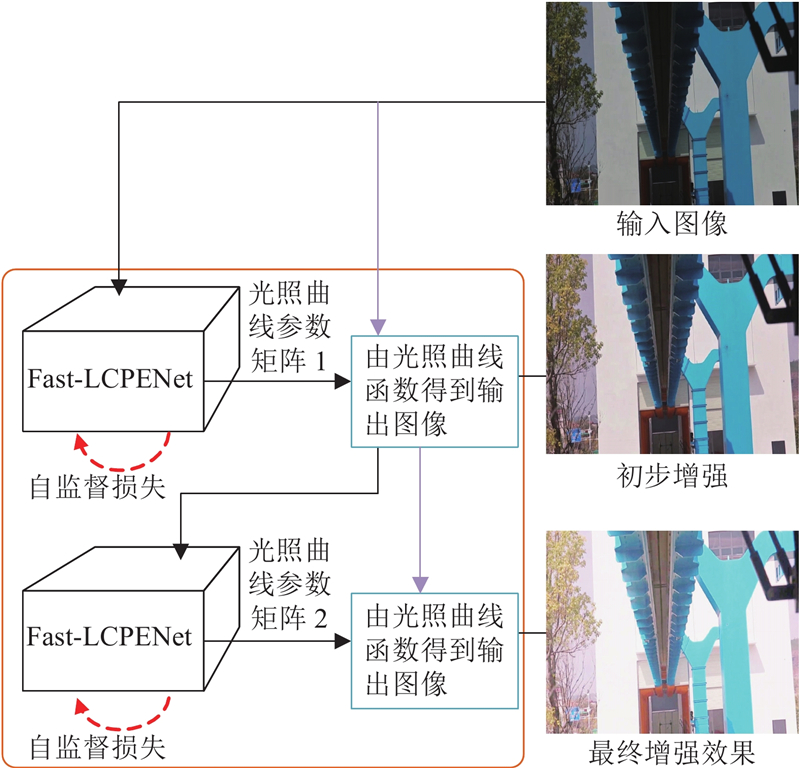
... 零参考深度曲线估计算法的整体架构[22 ] ...
... Overall architecture of zero-reference deep curve estimation[22 ] ...
1
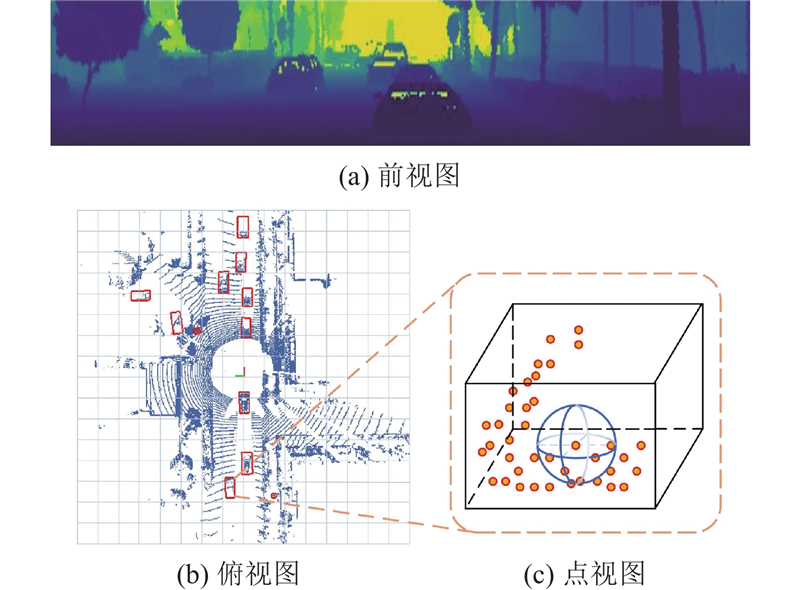
... 如图6 所示为3种典型视图的点云分割结构. PointNet[23 ] 是面向点集数据的深度学习网络,具备直接处理点云数据的能力,无需事先进行网格化或投影. 该网络对点云中的每个点进行特征提取,随后对整个点集执行池化操作,最终输出全局的点云特征. PointNet的显著特点是对输入点的置换不变性,即输入点的顺序变化不会影响网络的输出. SqueezeSeg[24 ] 采用球面投影将点云映射到平面,再借助紧凑型的轻量级二维CNN进行特征提取和分割. PolarNet[25 ] 通过把点云坐标系转换为极坐标系的方式将点云量化为网格. ...
1
... 如图6 所示为3种典型视图的点云分割结构. PointNet[23 ] 是面向点集数据的深度学习网络,具备直接处理点云数据的能力,无需事先进行网格化或投影. 该网络对点云中的每个点进行特征提取,随后对整个点集执行池化操作,最终输出全局的点云特征. PointNet的显著特点是对输入点的置换不变性,即输入点的顺序变化不会影响网络的输出. SqueezeSeg[24 ] 采用球面投影将点云映射到平面,再借助紧凑型的轻量级二维CNN进行特征提取和分割. PolarNet[25 ] 通过把点云坐标系转换为极坐标系的方式将点云量化为网格. ...
1
... 如图6 所示为3种典型视图的点云分割结构. PointNet[23 ] 是面向点集数据的深度学习网络,具备直接处理点云数据的能力,无需事先进行网格化或投影. 该网络对点云中的每个点进行特征提取,随后对整个点集执行池化操作,最终输出全局的点云特征. PointNet的显著特点是对输入点的置换不变性,即输入点的顺序变化不会影响网络的输出. SqueezeSeg[24 ] 采用球面投影将点云映射到平面,再借助紧凑型的轻量级二维CNN进行特征提取和分割. PolarNet[25 ] 通过把点云坐标系转换为极坐标系的方式将点云量化为网格. ...
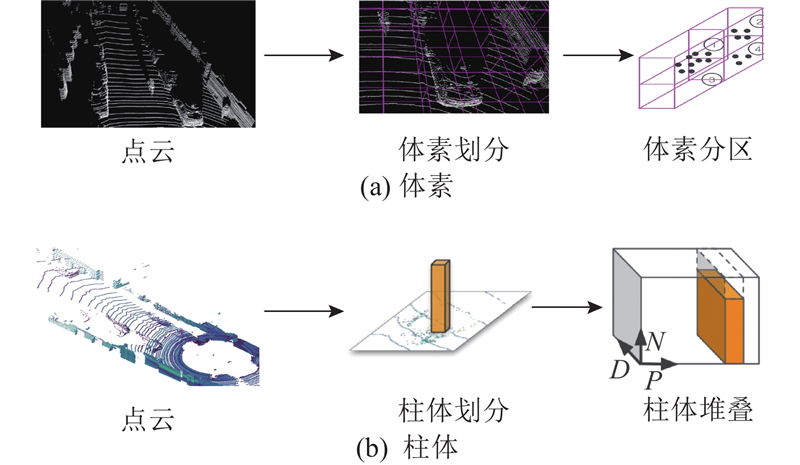
1
... 如图7 所示,处理点云数据的常见方法是将数据转换为体素或柱体格式. 例如,VoxelNet[26 ] 通过将点云划分为一系列体素,并将空间中的点映射到相应的体素中,再利用体素特征编码层来提取局部特征. SECOND[27 ] 通过引入稀疏卷积来替换VoxelNet中的3D卷积,使计算量有效降低,训练效率得到提升. PointPillars[28 ] 将点云按照柱状划分并转化为稀疏的伪图像,再使用2D网络进行特征学习,使得体素数量和昂贵的3D卷积操作显著减少,提高了检测速度. 转换为柱体或体素可能会损失点云数据的原始特性,因此有些研究直接从原始点云中提取空间几何特征. 例如,PointRCNN[29 ] 将点云分割为前景点和背景点,从前景点中生成少量的3D候选框,再结合分割结果对边界框进行修正. Part-A 2 net [30 ] 充分利用原始数据集中的标签内部信息,减少了PointRCNN中检测框的冗余. GLENet-VR[31 ] 采用基于条件变分自编码器的生成框架,以解决由遮挡、信号缺失或人工标注等引起的标签不确定性问题. PV-RCNN[32 ] 结合了原始点云和体素特征的特性,通过体素划分获取多尺度特征并生成高质量的3D候选框,同时利用原始点云可变的感受野来保留更精确的位置信息. 基于Transformer结构的方法也被应用于3D点云目标检测中,如PointFormer[33 ] 和CT3D[34 ] 有基于Transformer的骨干网络,用于提取点云特征,在解码模块中Transformer能够生成更有效的解码权重,高效地融合多级上下文信息. ...
SECOND: sparsely embedded convolutional detection
1
2018
... 如图7 所示,处理点云数据的常见方法是将数据转换为体素或柱体格式. 例如,VoxelNet[26 ] 通过将点云划分为一系列体素,并将空间中的点映射到相应的体素中,再利用体素特征编码层来提取局部特征. SECOND[27 ] 通过引入稀疏卷积来替换VoxelNet中的3D卷积,使计算量有效降低,训练效率得到提升. PointPillars[28 ] 将点云按照柱状划分并转化为稀疏的伪图像,再使用2D网络进行特征学习,使得体素数量和昂贵的3D卷积操作显著减少,提高了检测速度. 转换为柱体或体素可能会损失点云数据的原始特性,因此有些研究直接从原始点云中提取空间几何特征. 例如,PointRCNN[29 ] 将点云分割为前景点和背景点,从前景点中生成少量的3D候选框,再结合分割结果对边界框进行修正. Part-A 2 net [30 ] 充分利用原始数据集中的标签内部信息,减少了PointRCNN中检测框的冗余. GLENet-VR[31 ] 采用基于条件变分自编码器的生成框架,以解决由遮挡、信号缺失或人工标注等引起的标签不确定性问题. PV-RCNN[32 ] 结合了原始点云和体素特征的特性,通过体素划分获取多尺度特征并生成高质量的3D候选框,同时利用原始点云可变的感受野来保留更精确的位置信息. 基于Transformer结构的方法也被应用于3D点云目标检测中,如PointFormer[33 ] 和CT3D[34 ] 有基于Transformer的骨干网络,用于提取点云特征,在解码模块中Transformer能够生成更有效的解码权重,高效地融合多级上下文信息. ...
1
... 如图7 所示,处理点云数据的常见方法是将数据转换为体素或柱体格式. 例如,VoxelNet[26 ] 通过将点云划分为一系列体素,并将空间中的点映射到相应的体素中,再利用体素特征编码层来提取局部特征. SECOND[27 ] 通过引入稀疏卷积来替换VoxelNet中的3D卷积,使计算量有效降低,训练效率得到提升. PointPillars[28 ] 将点云按照柱状划分并转化为稀疏的伪图像,再使用2D网络进行特征学习,使得体素数量和昂贵的3D卷积操作显著减少,提高了检测速度. 转换为柱体或体素可能会损失点云数据的原始特性,因此有些研究直接从原始点云中提取空间几何特征. 例如,PointRCNN[29 ] 将点云分割为前景点和背景点,从前景点中生成少量的3D候选框,再结合分割结果对边界框进行修正. Part-A 2 net [30 ] 充分利用原始数据集中的标签内部信息,减少了PointRCNN中检测框的冗余. GLENet-VR[31 ] 采用基于条件变分自编码器的生成框架,以解决由遮挡、信号缺失或人工标注等引起的标签不确定性问题. PV-RCNN[32 ] 结合了原始点云和体素特征的特性,通过体素划分获取多尺度特征并生成高质量的3D候选框,同时利用原始点云可变的感受野来保留更精确的位置信息. 基于Transformer结构的方法也被应用于3D点云目标检测中,如PointFormer[33 ] 和CT3D[34 ] 有基于Transformer的骨干网络,用于提取点云特征,在解码模块中Transformer能够生成更有效的解码权重,高效地融合多级上下文信息. ...
1
... 如图7 所示,处理点云数据的常见方法是将数据转换为体素或柱体格式. 例如,VoxelNet[26 ] 通过将点云划分为一系列体素,并将空间中的点映射到相应的体素中,再利用体素特征编码层来提取局部特征. SECOND[27 ] 通过引入稀疏卷积来替换VoxelNet中的3D卷积,使计算量有效降低,训练效率得到提升. PointPillars[28 ] 将点云按照柱状划分并转化为稀疏的伪图像,再使用2D网络进行特征学习,使得体素数量和昂贵的3D卷积操作显著减少,提高了检测速度. 转换为柱体或体素可能会损失点云数据的原始特性,因此有些研究直接从原始点云中提取空间几何特征. 例如,PointRCNN[29 ] 将点云分割为前景点和背景点,从前景点中生成少量的3D候选框,再结合分割结果对边界框进行修正. Part-A 2 net [30 ] 充分利用原始数据集中的标签内部信息,减少了PointRCNN中检测框的冗余. GLENet-VR[31 ] 采用基于条件变分自编码器的生成框架,以解决由遮挡、信号缺失或人工标注等引起的标签不确定性问题. PV-RCNN[32 ] 结合了原始点云和体素特征的特性,通过体素划分获取多尺度特征并生成高质量的3D候选框,同时利用原始点云可变的感受野来保留更精确的位置信息. 基于Transformer结构的方法也被应用于3D点云目标检测中,如PointFormer[33 ] 和CT3D[34 ] 有基于Transformer的骨干网络,用于提取点云特征,在解码模块中Transformer能够生成更有效的解码权重,高效地融合多级上下文信息. ...
1
... 如图7 所示,处理点云数据的常见方法是将数据转换为体素或柱体格式. 例如,VoxelNet[26 ] 通过将点云划分为一系列体素,并将空间中的点映射到相应的体素中,再利用体素特征编码层来提取局部特征. SECOND[27 ] 通过引入稀疏卷积来替换VoxelNet中的3D卷积,使计算量有效降低,训练效率得到提升. PointPillars[28 ] 将点云按照柱状划分并转化为稀疏的伪图像,再使用2D网络进行特征学习,使得体素数量和昂贵的3D卷积操作显著减少,提高了检测速度. 转换为柱体或体素可能会损失点云数据的原始特性,因此有些研究直接从原始点云中提取空间几何特征. 例如,PointRCNN[29 ] 将点云分割为前景点和背景点,从前景点中生成少量的3D候选框,再结合分割结果对边界框进行修正. Part-A 2 net [30 ] 充分利用原始数据集中的标签内部信息,减少了PointRCNN中检测框的冗余. GLENet-VR[31 ] 采用基于条件变分自编码器的生成框架,以解决由遮挡、信号缺失或人工标注等引起的标签不确定性问题. PV-RCNN[32 ] 结合了原始点云和体素特征的特性,通过体素划分获取多尺度特征并生成高质量的3D候选框,同时利用原始点云可变的感受野来保留更精确的位置信息. 基于Transformer结构的方法也被应用于3D点云目标检测中,如PointFormer[33 ] 和CT3D[34 ] 有基于Transformer的骨干网络,用于提取点云特征,在解码模块中Transformer能够生成更有效的解码权重,高效地融合多级上下文信息. ...
GLENet: boosting 3D object detectors with generative label uncertainty estimation
1
2023
... 如图7 所示,处理点云数据的常见方法是将数据转换为体素或柱体格式. 例如,VoxelNet[26 ] 通过将点云划分为一系列体素,并将空间中的点映射到相应的体素中,再利用体素特征编码层来提取局部特征. SECOND[27 ] 通过引入稀疏卷积来替换VoxelNet中的3D卷积,使计算量有效降低,训练效率得到提升. PointPillars[28 ] 将点云按照柱状划分并转化为稀疏的伪图像,再使用2D网络进行特征学习,使得体素数量和昂贵的3D卷积操作显著减少,提高了检测速度. 转换为柱体或体素可能会损失点云数据的原始特性,因此有些研究直接从原始点云中提取空间几何特征. 例如,PointRCNN[29 ] 将点云分割为前景点和背景点,从前景点中生成少量的3D候选框,再结合分割结果对边界框进行修正. Part-A 2 net [30 ] 充分利用原始数据集中的标签内部信息,减少了PointRCNN中检测框的冗余. GLENet-VR[31 ] 采用基于条件变分自编码器的生成框架,以解决由遮挡、信号缺失或人工标注等引起的标签不确定性问题. PV-RCNN[32 ] 结合了原始点云和体素特征的特性,通过体素划分获取多尺度特征并生成高质量的3D候选框,同时利用原始点云可变的感受野来保留更精确的位置信息. 基于Transformer结构的方法也被应用于3D点云目标检测中,如PointFormer[33 ] 和CT3D[34 ] 有基于Transformer的骨干网络,用于提取点云特征,在解码模块中Transformer能够生成更有效的解码权重,高效地融合多级上下文信息. ...
1
... 如图7 所示,处理点云数据的常见方法是将数据转换为体素或柱体格式. 例如,VoxelNet[26 ] 通过将点云划分为一系列体素,并将空间中的点映射到相应的体素中,再利用体素特征编码层来提取局部特征. SECOND[27 ] 通过引入稀疏卷积来替换VoxelNet中的3D卷积,使计算量有效降低,训练效率得到提升. PointPillars[28 ] 将点云按照柱状划分并转化为稀疏的伪图像,再使用2D网络进行特征学习,使得体素数量和昂贵的3D卷积操作显著减少,提高了检测速度. 转换为柱体或体素可能会损失点云数据的原始特性,因此有些研究直接从原始点云中提取空间几何特征. 例如,PointRCNN[29 ] 将点云分割为前景点和背景点,从前景点中生成少量的3D候选框,再结合分割结果对边界框进行修正. Part-A 2 net [30 ] 充分利用原始数据集中的标签内部信息,减少了PointRCNN中检测框的冗余. GLENet-VR[31 ] 采用基于条件变分自编码器的生成框架,以解决由遮挡、信号缺失或人工标注等引起的标签不确定性问题. PV-RCNN[32 ] 结合了原始点云和体素特征的特性,通过体素划分获取多尺度特征并生成高质量的3D候选框,同时利用原始点云可变的感受野来保留更精确的位置信息. 基于Transformer结构的方法也被应用于3D点云目标检测中,如PointFormer[33 ] 和CT3D[34 ] 有基于Transformer的骨干网络,用于提取点云特征,在解码模块中Transformer能够生成更有效的解码权重,高效地融合多级上下文信息. ...
1
... 如图7 所示,处理点云数据的常见方法是将数据转换为体素或柱体格式. 例如,VoxelNet[26 ] 通过将点云划分为一系列体素,并将空间中的点映射到相应的体素中,再利用体素特征编码层来提取局部特征. SECOND[27 ] 通过引入稀疏卷积来替换VoxelNet中的3D卷积,使计算量有效降低,训练效率得到提升. PointPillars[28 ] 将点云按照柱状划分并转化为稀疏的伪图像,再使用2D网络进行特征学习,使得体素数量和昂贵的3D卷积操作显著减少,提高了检测速度. 转换为柱体或体素可能会损失点云数据的原始特性,因此有些研究直接从原始点云中提取空间几何特征. 例如,PointRCNN[29 ] 将点云分割为前景点和背景点,从前景点中生成少量的3D候选框,再结合分割结果对边界框进行修正. Part-A 2 net [30 ] 充分利用原始数据集中的标签内部信息,减少了PointRCNN中检测框的冗余. GLENet-VR[31 ] 采用基于条件变分自编码器的生成框架,以解决由遮挡、信号缺失或人工标注等引起的标签不确定性问题. PV-RCNN[32 ] 结合了原始点云和体素特征的特性,通过体素划分获取多尺度特征并生成高质量的3D候选框,同时利用原始点云可变的感受野来保留更精确的位置信息. 基于Transformer结构的方法也被应用于3D点云目标检测中,如PointFormer[33 ] 和CT3D[34 ] 有基于Transformer的骨干网络,用于提取点云特征,在解码模块中Transformer能够生成更有效的解码权重,高效地融合多级上下文信息. ...
1
... 如图7 所示,处理点云数据的常见方法是将数据转换为体素或柱体格式. 例如,VoxelNet[26 ] 通过将点云划分为一系列体素,并将空间中的点映射到相应的体素中,再利用体素特征编码层来提取局部特征. SECOND[27 ] 通过引入稀疏卷积来替换VoxelNet中的3D卷积,使计算量有效降低,训练效率得到提升. PointPillars[28 ] 将点云按照柱状划分并转化为稀疏的伪图像,再使用2D网络进行特征学习,使得体素数量和昂贵的3D卷积操作显著减少,提高了检测速度. 转换为柱体或体素可能会损失点云数据的原始特性,因此有些研究直接从原始点云中提取空间几何特征. 例如,PointRCNN[29 ] 将点云分割为前景点和背景点,从前景点中生成少量的3D候选框,再结合分割结果对边界框进行修正. Part-A 2 net [30 ] 充分利用原始数据集中的标签内部信息,减少了PointRCNN中检测框的冗余. GLENet-VR[31 ] 采用基于条件变分自编码器的生成框架,以解决由遮挡、信号缺失或人工标注等引起的标签不确定性问题. PV-RCNN[32 ] 结合了原始点云和体素特征的特性,通过体素划分获取多尺度特征并生成高质量的3D候选框,同时利用原始点云可变的感受野来保留更精确的位置信息. 基于Transformer结构的方法也被应用于3D点云目标检测中,如PointFormer[33 ] 和CT3D[34 ] 有基于Transformer的骨干网络,用于提取点云特征,在解码模块中Transformer能够生成更有效的解码权重,高效地融合多级上下文信息. ...
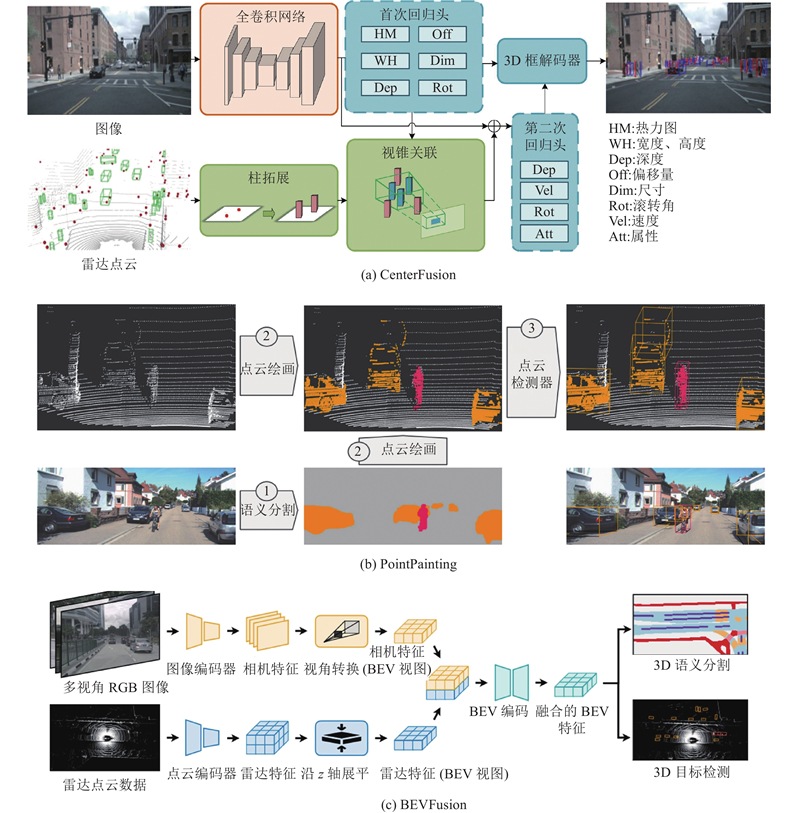
2
... 在自动驾驶和三维感知的领域中,相机和激光雷达被视为2种关键的感知传感器,分别从不同的视角捕捉数据:相机捕获前视图像,激光雷达获取空间数据. 最大化地发挥这2种传感器的优势需要高效的融合策略,以生成适用于多模态应用的统一表示. 融合方法主要有3种:提议级融合、点级融合和并行融合. 1)提议级融合方法致力于在空间中生成目标对象的候选区域,并将这些候选区域映射至图像空间中,实现相机与激光雷达数据的有效融合. 如图8 (a)所示,CenterFusion[35 ] 是典型的提议级融合模型. 全卷积网络作为主干,提取目标物体的中心点图像特征,通过初步的回归过程获得3D边界框;在空间内,依据视锥理论形成雷达点云的候选区域,并进一步提取候选区域特征;将图像与雷达特征进行拼接,通过第二次回归头修正检测结果. 2)点级融合方法注重将图像的语义特征映射到激光雷达点云上,以实现几何和语义信息的融合. 如图8 (b)所示,PointPainting[36 ] 通过在激光雷达点云上绘制来自图像的语义信息,实现了目标中心和几何中心的融合. PointPainting的关键步骤是有效地将图像信息投影到点云上,以增强点云的语义表示. 点级融合方法需要分阶段处理,难以进行端到端的训练. 3)并行融合方法同时将相机和激光雷达的信息输入网络,通过并行处理实现信息融合. BEVFusion[37 ] 被认为是领先的融合架构,其网络结构如图8 (c)所示. 相机图像基于2D主干网络和特征聚合块提取特征,再经过视角转换模块获得图像的BEV(bird’s eye view)特征,同时激光雷达点云基于PointNet++提取特征,将这些特征映射到BEV空间,得到激光雷达分支的BEV特征图;通过融合模块将相机BEV和激光雷达BEV特征进行融合,并将融合后的特征输入任务头,以执行不同的感知任务. ...
... Performance comparison of different fusion methods in NuScenes dataset
Tab.2 融合方法 模型 mAP/% t /ms提议级融合 CenterFusion[35 ] 32.6 — 提议级融合 TransFusion[42 ] 68.9 156.6 提议级融合 FUTR3D[43 ] 64.5 321.4 点级融合 FusionPainting[36 ] 68.1 185.8 并行融合 BEVFusion[37 ] 75.0 119.2
3. 基于图像识别的列车运行环境感知关键算法 关键算法的探讨将涉及轨道沿线环境状态感知、铁路接触网异物检测以及低照度场景图像增强等方面,这些关键算法与理论在提升列车安全性与降低运营风险上具有重要的工程应用价值. ...
2
... 在自动驾驶和三维感知的领域中,相机和激光雷达被视为2种关键的感知传感器,分别从不同的视角捕捉数据:相机捕获前视图像,激光雷达获取空间数据. 最大化地发挥这2种传感器的优势需要高效的融合策略,以生成适用于多模态应用的统一表示. 融合方法主要有3种:提议级融合、点级融合和并行融合. 1)提议级融合方法致力于在空间中生成目标对象的候选区域,并将这些候选区域映射至图像空间中,实现相机与激光雷达数据的有效融合. 如图8 (a)所示,CenterFusion[35 ] 是典型的提议级融合模型. 全卷积网络作为主干,提取目标物体的中心点图像特征,通过初步的回归过程获得3D边界框;在空间内,依据视锥理论形成雷达点云的候选区域,并进一步提取候选区域特征;将图像与雷达特征进行拼接,通过第二次回归头修正检测结果. 2)点级融合方法注重将图像的语义特征映射到激光雷达点云上,以实现几何和语义信息的融合. 如图8 (b)所示,PointPainting[36 ] 通过在激光雷达点云上绘制来自图像的语义信息,实现了目标中心和几何中心的融合. PointPainting的关键步骤是有效地将图像信息投影到点云上,以增强点云的语义表示. 点级融合方法需要分阶段处理,难以进行端到端的训练. 3)并行融合方法同时将相机和激光雷达的信息输入网络,通过并行处理实现信息融合. BEVFusion[37 ] 被认为是领先的融合架构,其网络结构如图8 (c)所示. 相机图像基于2D主干网络和特征聚合块提取特征,再经过视角转换模块获得图像的BEV(bird’s eye view)特征,同时激光雷达点云基于PointNet++提取特征,将这些特征映射到BEV空间,得到激光雷达分支的BEV特征图;通过融合模块将相机BEV和激光雷达BEV特征进行融合,并将融合后的特征输入任务头,以执行不同的感知任务. ...
... Performance comparison of different fusion methods in NuScenes dataset
Tab.2 融合方法 模型 mAP/% t /ms提议级融合 CenterFusion[35 ] 32.6 — 提议级融合 TransFusion[42 ] 68.9 156.6 提议级融合 FUTR3D[43 ] 64.5 321.4 点级融合 FusionPainting[36 ] 68.1 185.8 并行融合 BEVFusion[37 ] 75.0 119.2
3. 基于图像识别的列车运行环境感知关键算法 关键算法的探讨将涉及轨道沿线环境状态感知、铁路接触网异物检测以及低照度场景图像增强等方面,这些关键算法与理论在提升列车安全性与降低运营风险上具有重要的工程应用价值. ...
3
... 在自动驾驶和三维感知的领域中,相机和激光雷达被视为2种关键的感知传感器,分别从不同的视角捕捉数据:相机捕获前视图像,激光雷达获取空间数据. 最大化地发挥这2种传感器的优势需要高效的融合策略,以生成适用于多模态应用的统一表示. 融合方法主要有3种:提议级融合、点级融合和并行融合. 1)提议级融合方法致力于在空间中生成目标对象的候选区域,并将这些候选区域映射至图像空间中,实现相机与激光雷达数据的有效融合. 如图8 (a)所示,CenterFusion[35 ] 是典型的提议级融合模型. 全卷积网络作为主干,提取目标物体的中心点图像特征,通过初步的回归过程获得3D边界框;在空间内,依据视锥理论形成雷达点云的候选区域,并进一步提取候选区域特征;将图像与雷达特征进行拼接,通过第二次回归头修正检测结果. 2)点级融合方法注重将图像的语义特征映射到激光雷达点云上,以实现几何和语义信息的融合. 如图8 (b)所示,PointPainting[36 ] 通过在激光雷达点云上绘制来自图像的语义信息,实现了目标中心和几何中心的融合. PointPainting的关键步骤是有效地将图像信息投影到点云上,以增强点云的语义表示. 点级融合方法需要分阶段处理,难以进行端到端的训练. 3)并行融合方法同时将相机和激光雷达的信息输入网络,通过并行处理实现信息融合. BEVFusion[37 ] 被认为是领先的融合架构,其网络结构如图8 (c)所示. 相机图像基于2D主干网络和特征聚合块提取特征,再经过视角转换模块获得图像的BEV(bird’s eye view)特征,同时激光雷达点云基于PointNet++提取特征,将这些特征映射到BEV空间,得到激光雷达分支的BEV特征图;通过融合模块将相机BEV和激光雷达BEV特征进行融合,并将融合后的特征输入任务头,以执行不同的感知任务. ...
... 如表2 所示为不同融合方法在NuScenes[38 ] 数据集上的性能对比. 表中,平均精确度均值mAP用于衡量检测精度,t 为单次推理耗时. 可以看出,在参与对比的几种模型中,采用并行融合的BEVFusion在平均检测精度和推理耗时方面都有较好表现. Liu等[37 ] 指出,提议级融合方法将点云投影到前视图时可能导致几何失真,从而影响模型的精度. 点级融合尝试将相机的语义信息投影到3D点云,但信息损失问题很严重,只有约5%的数据能够成功匹配. 相比之下,并行融合方法通过端到端训练和综合利用多模态信息,显著提高了自动驾驶感知的准确性和鲁棒性,成为优选方案. ...
... Performance comparison of different fusion methods in NuScenes dataset
Tab.2 融合方法 模型 mAP/% t /ms提议级融合 CenterFusion[35 ] 32.6 — 提议级融合 TransFusion[42 ] 68.9 156.6 提议级融合 FUTR3D[43 ] 64.5 321.4 点级融合 FusionPainting[36 ] 68.1 185.8 并行融合 BEVFusion[37 ] 75.0 119.2
3. 基于图像识别的列车运行环境感知关键算法 关键算法的探讨将涉及轨道沿线环境状态感知、铁路接触网异物检测以及低照度场景图像增强等方面,这些关键算法与理论在提升列车安全性与降低运营风险上具有重要的工程应用价值. ...
1
... 如表2 所示为不同融合方法在NuScenes[38 ] 数据集上的性能对比. 表中,平均精确度均值mAP用于衡量检测精度,t 为单次推理耗时. 可以看出,在参与对比的几种模型中,采用并行融合的BEVFusion在平均检测精度和推理耗时方面都有较好表现. Liu等[37 ] 指出,提议级融合方法将点云投影到前视图时可能导致几何失真,从而影响模型的精度. 点级融合尝试将相机的语义信息投影到3D点云,但信息损失问题很严重,只有约5%的数据能够成功匹配. 相比之下,并行融合方法通过端到端训练和综合利用多模态信息,显著提高了自动驾驶感知的准确性和鲁棒性,成为优选方案. ...
基于深度学习的轨道表面异物识别方法
2
2023
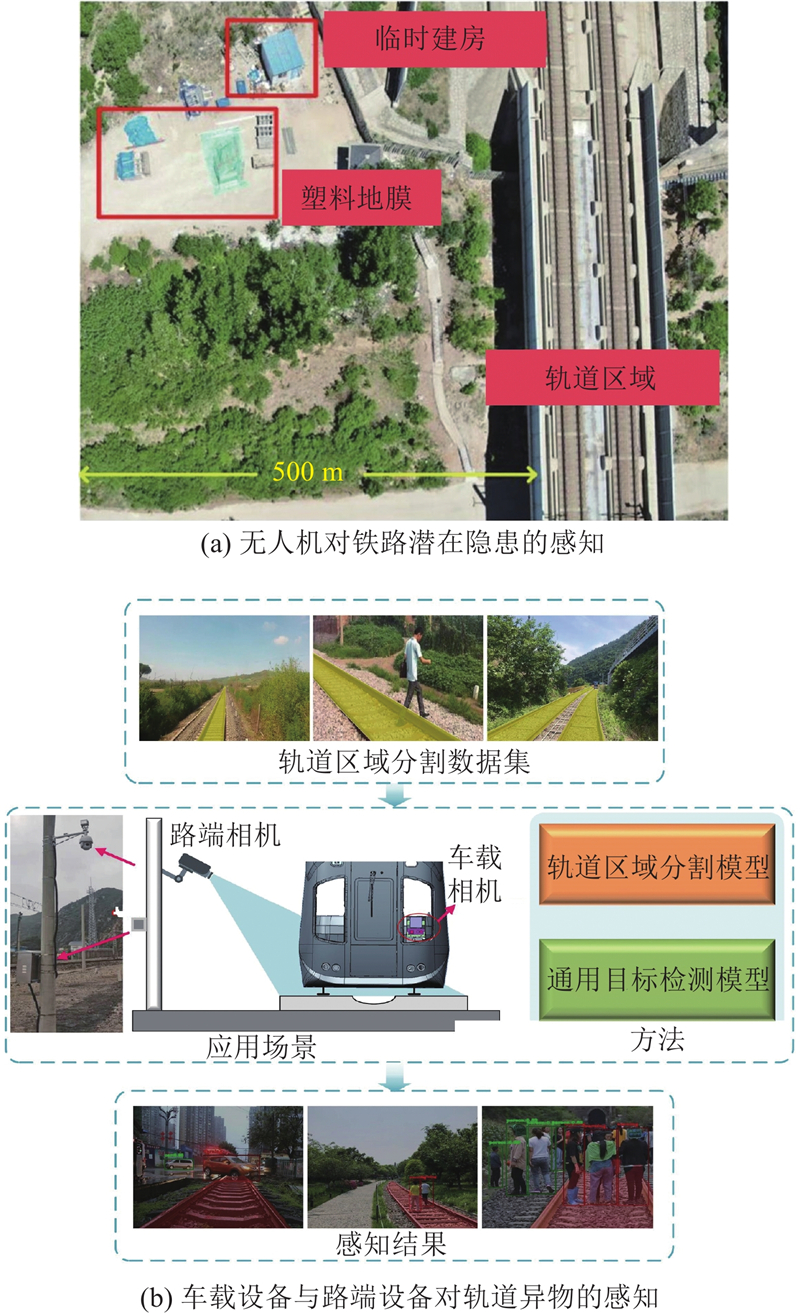
... 轨道区域被界定为车辆在轨道表面的垂直投影所覆盖的区域[39 ] . 在铁路沿线状态感知方面,现有研究采用综合的监测方案,包括无人机、车载设备和路端设备的协同应用. 如图9 (a)所示,无人机具有对广阔区域的探测能力和远距离监控的优势,其高清相机实时采集轨道和周边环境的图像数据,利用算法对上述图像数据进行处理与分析,能够及时发现入侵轨道的隐患物体. 如图9 (b)所示,车载设备应用于列车的行驶过程中,其长短焦相机进行一定距离的监测,实现对行人、车辆、动物的检测. 路端设备部署于关键位置(如道岔、信号灯处),实现长期监控. 上述应用的核心在于准确提取轨道区域的信息. 在现有研究中,语义分割技术能够实现对图像的像素级分类,众多研究者倾向于利用该技术来提取轨道的前景信息并开展对轨道环境状态的感知研究. ...
... 在车载设备对沿线异物的感知研究方面,Chen等[48 -49 ] 利用Transformer实现对轨道区域的分割,结合额外检测模型实现异物检测,并在此基础上提出轨道区域与异物目标框重合度的评估方法. 另有方案在获取到轨道区域的基础上,进一步利用分割模型提取异常像素[50 ] . 由于列车运行中需要执行大规模、连续且实时的感知任务,研究通常集中于模型轻量化以提升效率. 深度可分离卷积是网络轻量化中常用的高效特征提取算子,通过深度卷积处理特征深度,逐点卷积处理通道空间信息,计算量和参数量显著降低. 在网络架构设计方面,通过跨阶段部分连接(cross stage partial, CSP)结构在通道维度上对输入特征进行拆分和跨层重新组合,有助于降低卷积层的输入维度和提升梯度传播效率. 此外,在诸如MobileNet v3的网络设计中[39 ] ,反向残差连接的方式实现了较小通道数的输入,显著降低了网络整体的计算复杂度. 知识蒸馏通过从大型模型中提取知识来训练小型模型,可作为小模型精度提升的有效策略. Feng等[51 ] 基于大型模型Deeplab v3+进行知识蒸馏,显著提升了小型模型在轨道分割任务上的精度. ...
基于深度学习的轨道表面异物识别方法
2
2023
... 轨道区域被界定为车辆在轨道表面的垂直投影所覆盖的区域[39 ] . 在铁路沿线状态感知方面,现有研究采用综合的监测方案,包括无人机、车载设备和路端设备的协同应用. 如图9 (a)所示,无人机具有对广阔区域的探测能力和远距离监控的优势,其高清相机实时采集轨道和周边环境的图像数据,利用算法对上述图像数据进行处理与分析,能够及时发现入侵轨道的隐患物体. 如图9 (b)所示,车载设备应用于列车的行驶过程中,其长短焦相机进行一定距离的监测,实现对行人、车辆、动物的检测. 路端设备部署于关键位置(如道岔、信号灯处),实现长期监控. 上述应用的核心在于准确提取轨道区域的信息. 在现有研究中,语义分割技术能够实现对图像的像素级分类,众多研究者倾向于利用该技术来提取轨道的前景信息并开展对轨道环境状态的感知研究. ...
... 在车载设备对沿线异物的感知研究方面,Chen等[48 -49 ] 利用Transformer实现对轨道区域的分割,结合额外检测模型实现异物检测,并在此基础上提出轨道区域与异物目标框重合度的评估方法. 另有方案在获取到轨道区域的基础上,进一步利用分割模型提取异常像素[50 ] . 由于列车运行中需要执行大规模、连续且实时的感知任务,研究通常集中于模型轻量化以提升效率. 深度可分离卷积是网络轻量化中常用的高效特征提取算子,通过深度卷积处理特征深度,逐点卷积处理通道空间信息,计算量和参数量显著降低. 在网络架构设计方面,通过跨阶段部分连接(cross stage partial, CSP)结构在通道维度上对输入特征进行拆分和跨层重新组合,有助于降低卷积层的输入维度和提升梯度传播效率. 此外,在诸如MobileNet v3的网络设计中[39 ] ,反向残差连接的方式实现了较小通道数的输入,显著降低了网络整体的计算复杂度. 知识蒸馏通过从大型模型中提取知识来训练小型模型,可作为小模型精度提升的有效策略. Feng等[51 ] 基于大型模型Deeplab v3+进行知识蒸馏,显著提升了小型模型在轨道分割任务上的精度. ...
基于深度学习的轨道异物入侵检测算法
1
2020
... 传统的分割方法主要依赖边缘检测、形态学操作和阈值分割等手工特征提取算法来识别轨道特征. 有研究者尝试基于轨道的几何特性建模,如何文玉等[40 ] 通过霍夫变换提取钢轨边缘的直线信息,该方法在处理曲线轨道和复杂轨道场景时显得不够灵活. He等[41 ] 提出根据列车前方视角和位置确定轨道区域的方法,该方法虽然能够大致确定位置,但在处理长距离轨道时难以精确拟合. 在简单且特定的场景下,传统方法能够有效识别轨道特征,例如通过将视觉传感器部署于沿线路端来监测特定区域. 当利用无人机和车载设备对轨道沿线环境进行感知时,传统方法已无法满足现场实际应用的严格要求. 在处理错综复杂的背景和不断变化的光照条件问题上,深度学习技术展现出巨大潜力,它通过算法对多源数据进行分析,能够有效提升铁路沿线状态的感知精度. ...
基于深度学习的轨道异物入侵检测算法
1
2020
... 传统的分割方法主要依赖边缘检测、形态学操作和阈值分割等手工特征提取算法来识别轨道特征. 有研究者尝试基于轨道的几何特性建模,如何文玉等[40 ] 通过霍夫变换提取钢轨边缘的直线信息,该方法在处理曲线轨道和复杂轨道场景时显得不够灵活. He等[41 ] 提出根据列车前方视角和位置确定轨道区域的方法,该方法虽然能够大致确定位置,但在处理长距离轨道时难以精确拟合. 在简单且特定的场景下,传统方法能够有效识别轨道特征,例如通过将视觉传感器部署于沿线路端来监测特定区域. 当利用无人机和车载设备对轨道沿线环境进行感知时,传统方法已无法满足现场实际应用的严格要求. 在处理错综复杂的背景和不断变化的光照条件问题上,深度学习技术展现出巨大潜力,它通过算法对多源数据进行分析,能够有效提升铁路沿线状态的感知精度. ...
Obstacle detection of rail transit based on deep learning
1
2021
... 传统的分割方法主要依赖边缘检测、形态学操作和阈值分割等手工特征提取算法来识别轨道特征. 有研究者尝试基于轨道的几何特性建模,如何文玉等[40 ] 通过霍夫变换提取钢轨边缘的直线信息,该方法在处理曲线轨道和复杂轨道场景时显得不够灵活. He等[41 ] 提出根据列车前方视角和位置确定轨道区域的方法,该方法虽然能够大致确定位置,但在处理长距离轨道时难以精确拟合. 在简单且特定的场景下,传统方法能够有效识别轨道特征,例如通过将视觉传感器部署于沿线路端来监测特定区域. 当利用无人机和车载设备对轨道沿线环境进行感知时,传统方法已无法满足现场实际应用的严格要求. 在处理错综复杂的背景和不断变化的光照条件问题上,深度学习技术展现出巨大潜力,它通过算法对多源数据进行分析,能够有效提升铁路沿线状态的感知精度. ...
1
... Performance comparison of different fusion methods in NuScenes dataset
Tab.2 融合方法 模型 mAP/% t /ms提议级融合 CenterFusion[35 ] 32.6 — 提议级融合 TransFusion[42 ] 68.9 156.6 提议级融合 FUTR3D[43 ] 64.5 321.4 点级融合 FusionPainting[36 ] 68.1 185.8 并行融合 BEVFusion[37 ] 75.0 119.2
3. 基于图像识别的列车运行环境感知关键算法 关键算法的探讨将涉及轨道沿线环境状态感知、铁路接触网异物检测以及低照度场景图像增强等方面,这些关键算法与理论在提升列车安全性与降低运营风险上具有重要的工程应用价值. ...
1
... Performance comparison of different fusion methods in NuScenes dataset
Tab.2 融合方法 模型 mAP/% t /ms提议级融合 CenterFusion[35 ] 32.6 — 提议级融合 TransFusion[42 ] 68.9 156.6 提议级融合 FUTR3D[43 ] 64.5 321.4 点级融合 FusionPainting[36 ] 68.1 185.8 并行融合 BEVFusion[37 ] 75.0 119.2
3. 基于图像识别的列车运行环境感知关键算法 关键算法的探讨将涉及轨道沿线环境状态感知、铁路接触网异物检测以及低照度场景图像增强等方面,这些关键算法与理论在提升列车安全性与降低运营风险上具有重要的工程应用价值. ...
Fully decoupled residual ConvNet for real-time railway scene parsing of UAV aerial images
1
2022
... 在无人机巡检领域,针对图像中语义信息缺乏和轨道特征难以准确提取的问题,研究者开发出多种改进的全卷积语义分割模型并应用在实际工程项目中. Tong等[44 ] 为了抑制结果中的异常值,根据轨道的几何特性设计新型损失函数,提升了分割精度. Kim等[45 ] 利用U-Net结构实现语义信息与空间信息的均衡,再构造混合注意力机制捕获特征图中的重要信息,实现对轨道中重要部件的分割. 一些研究者利用单阶段网络在速度上的优势,对单阶段网络进行任务分支重构. Wu等[46 ] 结合多感受野的主干网络、多尺度金字塔和残差结构设计了兼有检测和分割功能的感知模型,并在此基础上提出结合感知结果的异物与轨道之间的距离评估策略. Wu等[47 ] 提出的AYOLO模型集成了检测和分割分支,能够提高轨道表面缺陷的检测精度. ...
SeMA-UNet: a semi-supervised learning with multimodal approach of UNet for effective segmentation of key components in railway images
1
2024
... 在无人机巡检领域,针对图像中语义信息缺乏和轨道特征难以准确提取的问题,研究者开发出多种改进的全卷积语义分割模型并应用在实际工程项目中. Tong等[44 ] 为了抑制结果中的异常值,根据轨道的几何特性设计新型损失函数,提升了分割精度. Kim等[45 ] 利用U-Net结构实现语义信息与空间信息的均衡,再构造混合注意力机制捕获特征图中的重要信息,实现对轨道中重要部件的分割. 一些研究者利用单阶段网络在速度上的优势,对单阶段网络进行任务分支重构. Wu等[46 ] 结合多感受野的主干网络、多尺度金字塔和残差结构设计了兼有检测和分割功能的感知模型,并在此基础上提出结合感知结果的异物与轨道之间的距离评估策略. Wu等[47 ] 提出的AYOLO模型集成了检测和分割分支,能够提高轨道表面缺陷的检测精度. ...
UAV imagery based potential safety hazard evaluation for high-speed railroad using real-time instance segmentation
1
2023
... 在无人机巡检领域,针对图像中语义信息缺乏和轨道特征难以准确提取的问题,研究者开发出多种改进的全卷积语义分割模型并应用在实际工程项目中. Tong等[44 ] 为了抑制结果中的异常值,根据轨道的几何特性设计新型损失函数,提升了分割精度. Kim等[45 ] 利用U-Net结构实现语义信息与空间信息的均衡,再构造混合注意力机制捕获特征图中的重要信息,实现对轨道中重要部件的分割. 一些研究者利用单阶段网络在速度上的优势,对单阶段网络进行任务分支重构. Wu等[46 ] 结合多感受野的主干网络、多尺度金字塔和残差结构设计了兼有检测和分割功能的感知模型,并在此基础上提出结合感知结果的异物与轨道之间的距离评估策略. Wu等[47 ] 提出的AYOLO模型集成了检测和分割分支,能够提高轨道表面缺陷的检测精度. ...
Automatic railroad track components inspection using hybrid deep learning framework
1
2023
... 在无人机巡检领域,针对图像中语义信息缺乏和轨道特征难以准确提取的问题,研究者开发出多种改进的全卷积语义分割模型并应用在实际工程项目中. Tong等[44 ] 为了抑制结果中的异常值,根据轨道的几何特性设计新型损失函数,提升了分割精度. Kim等[45 ] 利用U-Net结构实现语义信息与空间信息的均衡,再构造混合注意力机制捕获特征图中的重要信息,实现对轨道中重要部件的分割. 一些研究者利用单阶段网络在速度上的优势,对单阶段网络进行任务分支重构. Wu等[46 ] 结合多感受野的主干网络、多尺度金字塔和残差结构设计了兼有检测和分割功能的感知模型,并在此基础上提出结合感知结果的异物与轨道之间的距离评估策略. Wu等[47 ] 提出的AYOLO模型集成了检测和分割分支,能够提高轨道表面缺陷的检测精度. ...
RailSegVITNet: a lightweight VIT-based real-time track surface segmentation network for improving railroad safety
1
2024
... 在车载设备对沿线异物的感知研究方面,Chen等[48 -49 ] 利用Transformer实现对轨道区域的分割,结合额外检测模型实现异物检测,并在此基础上提出轨道区域与异物目标框重合度的评估方法. 另有方案在获取到轨道区域的基础上,进一步利用分割模型提取异常像素[50 ] . 由于列车运行中需要执行大规模、连续且实时的感知任务,研究通常集中于模型轻量化以提升效率. 深度可分离卷积是网络轻量化中常用的高效特征提取算子,通过深度卷积处理特征深度,逐点卷积处理通道空间信息,计算量和参数量显著降低. 在网络架构设计方面,通过跨阶段部分连接(cross stage partial, CSP)结构在通道维度上对输入特征进行拆分和跨层重新组合,有助于降低卷积层的输入维度和提升梯度传播效率. 此外,在诸如MobileNet v3的网络设计中[39 ] ,反向残差连接的方式实现了较小通道数的输入,显著降低了网络整体的计算复杂度. 知识蒸馏通过从大型模型中提取知识来训练小型模型,可作为小模型精度提升的有效策略. Feng等[51 ] 基于大型模型Deeplab v3+进行知识蒸馏,显著提升了小型模型在轨道分割任务上的精度. ...
Efficient railway track region segmentation algorithm based on lightweight neural network and cross-fusion decoder
2
2023
... 在车载设备对沿线异物的感知研究方面,Chen等[48 -49 ] 利用Transformer实现对轨道区域的分割,结合额外检测模型实现异物检测,并在此基础上提出轨道区域与异物目标框重合度的评估方法. 另有方案在获取到轨道区域的基础上,进一步利用分割模型提取异常像素[50 ] . 由于列车运行中需要执行大规模、连续且实时的感知任务,研究通常集中于模型轻量化以提升效率. 深度可分离卷积是网络轻量化中常用的高效特征提取算子,通过深度卷积处理特征深度,逐点卷积处理通道空间信息,计算量和参数量显著降低. 在网络架构设计方面,通过跨阶段部分连接(cross stage partial, CSP)结构在通道维度上对输入特征进行拆分和跨层重新组合,有助于降低卷积层的输入维度和提升梯度传播效率. 此外,在诸如MobileNet v3的网络设计中[39 ] ,反向残差连接的方式实现了较小通道数的输入,显著降低了网络整体的计算复杂度. 知识蒸馏通过从大型模型中提取知识来训练小型模型,可作为小模型精度提升的有效策略. Feng等[51 ] 基于大型模型Deeplab v3+进行知识蒸馏,显著提升了小型模型在轨道分割任务上的精度. ...
... 列车运行环境感知技术在实际工业应用中仍面临诸多挑战,限制了其推广和应用. 1)在铁路场景的图像分析中,小尺寸目标和模糊外观对检测精度有负面影响. 特别是无人机执行高空拍摄任务的情况[78 -79 ] ,小尺寸目标再加上雾天气象条件的影响,加大了目标特征提取的难度. 2)现代列车普遍装配前向摄像头[49 ] ,产生的海量数据对改善模型的精度至关重要,但是手工标注海量数据耗时且成本高昂,严重制约数据的有效闭环利用. 3)铁路沿线如鸟巢、气球、塑料膜等的异常图像数据稀缺[60 ] ,导致高质量的大规模异物数据集难以构建,模型精度评估变得困难. 4)无监督学习能够降低标记数据依赖性,具有增强低照度图像性能,但是缺少精准的标签信息导致生成图像容易包含噪声,干扰后续的处理任务. 5)点云处理算法的研究集中在对单帧点云数据的分析上,忽略了单帧点云数据在空间中通常呈现的显著稀疏性影响了3D视觉任务的精度. 6)大规模的高质量铁路场景3D数据集缺乏,深度学习方法对标注数据的依赖性强,创建用于多模态3D检测的数据集极其昂贵且耗时. 7)在深度学习模型的改进过程中,多数方法在追求精度提升的同时增加了计算负担,使模型难以满足列车对环境进行大规模、实时性、持续性感知的需求. ...
1
... 在车载设备对沿线异物的感知研究方面,Chen等[48 -49 ] 利用Transformer实现对轨道区域的分割,结合额外检测模型实现异物检测,并在此基础上提出轨道区域与异物目标框重合度的评估方法. 另有方案在获取到轨道区域的基础上,进一步利用分割模型提取异常像素[50 ] . 由于列车运行中需要执行大规模、连续且实时的感知任务,研究通常集中于模型轻量化以提升效率. 深度可分离卷积是网络轻量化中常用的高效特征提取算子,通过深度卷积处理特征深度,逐点卷积处理通道空间信息,计算量和参数量显著降低. 在网络架构设计方面,通过跨阶段部分连接(cross stage partial, CSP)结构在通道维度上对输入特征进行拆分和跨层重新组合,有助于降低卷积层的输入维度和提升梯度传播效率. 此外,在诸如MobileNet v3的网络设计中[39 ] ,反向残差连接的方式实现了较小通道数的输入,显著降低了网络整体的计算复杂度. 知识蒸馏通过从大型模型中提取知识来训练小型模型,可作为小模型精度提升的有效策略. Feng等[51 ] 基于大型模型Deeplab v3+进行知识蒸馏,显著提升了小型模型在轨道分割任务上的精度. ...
LRseg: an efficient railway region extraction method based on lightweight encoder and self-correcting decoder
1
2024
... 在车载设备对沿线异物的感知研究方面,Chen等[48 -49 ] 利用Transformer实现对轨道区域的分割,结合额外检测模型实现异物检测,并在此基础上提出轨道区域与异物目标框重合度的评估方法. 另有方案在获取到轨道区域的基础上,进一步利用分割模型提取异常像素[50 ] . 由于列车运行中需要执行大规模、连续且实时的感知任务,研究通常集中于模型轻量化以提升效率. 深度可分离卷积是网络轻量化中常用的高效特征提取算子,通过深度卷积处理特征深度,逐点卷积处理通道空间信息,计算量和参数量显著降低. 在网络架构设计方面,通过跨阶段部分连接(cross stage partial, CSP)结构在通道维度上对输入特征进行拆分和跨层重新组合,有助于降低卷积层的输入维度和提升梯度传播效率. 此外,在诸如MobileNet v3的网络设计中[39 ] ,反向残差连接的方式实现了较小通道数的输入,显著降低了网络整体的计算复杂度. 知识蒸馏通过从大型模型中提取知识来训练小型模型,可作为小模型精度提升的有效策略. Feng等[51 ] 基于大型模型Deeplab v3+进行知识蒸馏,显著提升了小型模型在轨道分割任务上的精度. ...
基于改进Canny算法的物体边缘检测算法
1
2023
... 在早期异物检测技术研究中,研究人员主要依靠手工特征提取算法. 霍夫变换广泛用于识别图像中的线性结构,尤其是在检测长条形异物方面表现良好. Canny边缘检测算法[52 ] 能够捕捉异物的轮廓信息, Sobel算子[53 ] 利用基于梯度的方法来增强线性异物的特征. 背景差分法[54 ] 通过比较图像的当前帧与背景帧的差异,提取可能存在异物的区域. 模板匹配技术[55 ] 通过比较图像中的区域与预先定义的模板来查找与模板相似的区域,从而识别出潜在的异物形状. 有研究者或采用基于颜色和纹理特征的识别方法,或利用欧几里得距离计算的聚类算法[56 ] 来区分异物与背景,这些方法往往需要严格的参数设定和环境假设,缺少对自然环境变化的灵活适应性. ...
基于改进Canny算法的物体边缘检测算法
1
2023
... 在早期异物检测技术研究中,研究人员主要依靠手工特征提取算法. 霍夫变换广泛用于识别图像中的线性结构,尤其是在检测长条形异物方面表现良好. Canny边缘检测算法[52 ] 能够捕捉异物的轮廓信息, Sobel算子[53 ] 利用基于梯度的方法来增强线性异物的特征. 背景差分法[54 ] 通过比较图像的当前帧与背景帧的差异,提取可能存在异物的区域. 模板匹配技术[55 ] 通过比较图像中的区域与预先定义的模板来查找与模板相似的区域,从而识别出潜在的异物形状. 有研究者或采用基于颜色和纹理特征的识别方法,或利用欧几里得距离计算的聚类算法[56 ] 来区分异物与背景,这些方法往往需要严格的参数设定和环境假设,缺少对自然环境变化的灵活适应性. ...
Quantum image edge detection based on eight-direction Sobel operator for NEQR
1
2022
... 在早期异物检测技术研究中,研究人员主要依靠手工特征提取算法. 霍夫变换广泛用于识别图像中的线性结构,尤其是在检测长条形异物方面表现良好. Canny边缘检测算法[52 ] 能够捕捉异物的轮廓信息, Sobel算子[53 ] 利用基于梯度的方法来增强线性异物的特征. 背景差分法[54 ] 通过比较图像的当前帧与背景帧的差异,提取可能存在异物的区域. 模板匹配技术[55 ] 通过比较图像中的区域与预先定义的模板来查找与模板相似的区域,从而识别出潜在的异物形状. 有研究者或采用基于颜色和纹理特征的识别方法,或利用欧几里得距离计算的聚类算法[56 ] 来区分异物与背景,这些方法往往需要严格的参数设定和环境假设,缺少对自然环境变化的灵活适应性. ...
基于空间尺度标准化的动车组底部异常检测
1
2022
... 在早期异物检测技术研究中,研究人员主要依靠手工特征提取算法. 霍夫变换广泛用于识别图像中的线性结构,尤其是在检测长条形异物方面表现良好. Canny边缘检测算法[52 ] 能够捕捉异物的轮廓信息, Sobel算子[53 ] 利用基于梯度的方法来增强线性异物的特征. 背景差分法[54 ] 通过比较图像的当前帧与背景帧的差异,提取可能存在异物的区域. 模板匹配技术[55 ] 通过比较图像中的区域与预先定义的模板来查找与模板相似的区域,从而识别出潜在的异物形状. 有研究者或采用基于颜色和纹理特征的识别方法,或利用欧几里得距离计算的聚类算法[56 ] 来区分异物与背景,这些方法往往需要严格的参数设定和环境假设,缺少对自然环境变化的灵活适应性. ...
基于空间尺度标准化的动车组底部异常检测
1
2022
... 在早期异物检测技术研究中,研究人员主要依靠手工特征提取算法. 霍夫变换广泛用于识别图像中的线性结构,尤其是在检测长条形异物方面表现良好. Canny边缘检测算法[52 ] 能够捕捉异物的轮廓信息, Sobel算子[53 ] 利用基于梯度的方法来增强线性异物的特征. 背景差分法[54 ] 通过比较图像的当前帧与背景帧的差异,提取可能存在异物的区域. 模板匹配技术[55 ] 通过比较图像中的区域与预先定义的模板来查找与模板相似的区域,从而识别出潜在的异物形状. 有研究者或采用基于颜色和纹理特征的识别方法,或利用欧几里得距离计算的聚类算法[56 ] 来区分异物与背景,这些方法往往需要严格的参数设定和环境假设,缺少对自然环境变化的灵活适应性. ...
面向边缘特征的实时模板匹配方法
1
2023
... 在早期异物检测技术研究中,研究人员主要依靠手工特征提取算法. 霍夫变换广泛用于识别图像中的线性结构,尤其是在检测长条形异物方面表现良好. Canny边缘检测算法[52 ] 能够捕捉异物的轮廓信息, Sobel算子[53 ] 利用基于梯度的方法来增强线性异物的特征. 背景差分法[54 ] 通过比较图像的当前帧与背景帧的差异,提取可能存在异物的区域. 模板匹配技术[55 ] 通过比较图像中的区域与预先定义的模板来查找与模板相似的区域,从而识别出潜在的异物形状. 有研究者或采用基于颜色和纹理特征的识别方法,或利用欧几里得距离计算的聚类算法[56 ] 来区分异物与背景,这些方法往往需要严格的参数设定和环境假设,缺少对自然环境变化的灵活适应性. ...
面向边缘特征的实时模板匹配方法
1
2023
... 在早期异物检测技术研究中,研究人员主要依靠手工特征提取算法. 霍夫变换广泛用于识别图像中的线性结构,尤其是在检测长条形异物方面表现良好. Canny边缘检测算法[52 ] 能够捕捉异物的轮廓信息, Sobel算子[53 ] 利用基于梯度的方法来增强线性异物的特征. 背景差分法[54 ] 通过比较图像的当前帧与背景帧的差异,提取可能存在异物的区域. 模板匹配技术[55 ] 通过比较图像中的区域与预先定义的模板来查找与模板相似的区域,从而识别出潜在的异物形状. 有研究者或采用基于颜色和纹理特征的识别方法,或利用欧几里得距离计算的聚类算法[56 ] 来区分异物与背景,这些方法往往需要严格的参数设定和环境假设,缺少对自然环境变化的灵活适应性. ...
Automatic clearance anomaly detection for transmission line corridors utilizing UAV-borne LiDAR data
1
2018
... 在早期异物检测技术研究中,研究人员主要依靠手工特征提取算法. 霍夫变换广泛用于识别图像中的线性结构,尤其是在检测长条形异物方面表现良好. Canny边缘检测算法[52 ] 能够捕捉异物的轮廓信息, Sobel算子[53 ] 利用基于梯度的方法来增强线性异物的特征. 背景差分法[54 ] 通过比较图像的当前帧与背景帧的差异,提取可能存在异物的区域. 模板匹配技术[55 ] 通过比较图像中的区域与预先定义的模板来查找与模板相似的区域,从而识别出潜在的异物形状. 有研究者或采用基于颜色和纹理特征的识别方法,或利用欧几里得距离计算的聚类算法[56 ] 来区分异物与背景,这些方法往往需要严格的参数设定和环境假设,缺少对自然环境变化的灵活适应性. ...
Design and implementation of UAVs for bird’s nest inspection on transmission lines based on deep learning
1
2022
... 在铁路接触网检测领域主要面临的挑战包括模型推理的耗时问题、异物特征难提取的问题和数据量有限的问题,为此研究者对基于深度学习的目标检测方法进行了优化,优化思路如表3 所示. 1)在耗时问题方面,YOLO系列算法因具有精度和速度的平衡性而受到研究者的关注. Li等[57 ] 构建包含2 000张鸟巢图片的数据集,通过训练YOLOv5模型,使平均精度均值达到92.1%. 2)在特征提取方面,结合Transformer和YOLO可以有效提升特征的表达能力. Tang等[58 ] 提出融合Swin Transformer与YOLOX的检测技术,并创建含有鸟巢、风筝、气球等1 790张图片的数据集,使平均精度均值达到96.7%. 传统特征与深度学习的结合方法也被应用于此领域. Yu等[59 ] 利用传统方法提取可能存在的异物区域,并结合基于深度学习的分类模型进行分类,分类准确率达到95.88%. 3)由于实验数据有限,图像的数量往往是几百至几千张,使模型过拟合的风险增加. 考虑到深度学习由数据驱动,确保数据的充足和有效性是实现模型鲁棒性训练的关键. 针对数据稀缺的问题,生成式人工智能是值得探索的解决方案. 常见的数据生成方法是基于生成对抗网络(generative adversarial networks, GAN),通过在现有数据上训练生成器和判别器,生成与原始图像分布相似的新图像. 这种方法依赖已有的图像数据,且生成的图像相似度较高,难以完全拟合真实场景. Chen等[60 ] 提出RailFOD23数据集,通过深入融合ChatGPT的文本生成能力与Stable Diffusion的文本生成图片的性能,合成了大量的异常数据,采用基于光照平滑的合成方法将异物目标与现有铁路场景图像进行合成. RailFOD23数据集包括14 615张图像和40 541个标注对象,涵盖铁路输电线路上的4种常见异物. ...
Foreign object detection for transmission lines based on Swin Transformer V2 and YOLOX
2
2024
... 在铁路接触网检测领域主要面临的挑战包括模型推理的耗时问题、异物特征难提取的问题和数据量有限的问题,为此研究者对基于深度学习的目标检测方法进行了优化,优化思路如表3 所示. 1)在耗时问题方面,YOLO系列算法因具有精度和速度的平衡性而受到研究者的关注. Li等[57 ] 构建包含2 000张鸟巢图片的数据集,通过训练YOLOv5模型,使平均精度均值达到92.1%. 2)在特征提取方面,结合Transformer和YOLO可以有效提升特征的表达能力. Tang等[58 ] 提出融合Swin Transformer与YOLOX的检测技术,并创建含有鸟巢、风筝、气球等1 790张图片的数据集,使平均精度均值达到96.7%. 传统特征与深度学习的结合方法也被应用于此领域. Yu等[59 ] 利用传统方法提取可能存在的异物区域,并结合基于深度学习的分类模型进行分类,分类准确率达到95.88%. 3)由于实验数据有限,图像的数量往往是几百至几千张,使模型过拟合的风险增加. 考虑到深度学习由数据驱动,确保数据的充足和有效性是实现模型鲁棒性训练的关键. 针对数据稀缺的问题,生成式人工智能是值得探索的解决方案. 常见的数据生成方法是基于生成对抗网络(generative adversarial networks, GAN),通过在现有数据上训练生成器和判别器,生成与原始图像分布相似的新图像. 这种方法依赖已有的图像数据,且生成的图像相似度较高,难以完全拟合真实场景. Chen等[60 ] 提出RailFOD23数据集,通过深入融合ChatGPT的文本生成能力与Stable Diffusion的文本生成图片的性能,合成了大量的异常数据,采用基于光照平滑的合成方法将异物目标与现有铁路场景图像进行合成. RailFOD23数据集包括14 615张图像和40 541个标注对象,涵盖铁路输电线路上的4种常见异物. ...
... Main concepts of foreign object detection algorithms
Tab.3 算法类别 算法 主要思路 图片数量 异物类别 YOLO系列 YOLOv4-EDAM[61 ] 基于轻量级网络改进YOLOv4的主干网络,嵌入注意力机制 1 232 鸟巢、风筝、气球、垃圾 YOLO系列 ST2Rep–YOLOX[58 ] 基于Swin Transformer改进YOLOX主干,引入高效算子 1 560 鸟巢、风筝、气球 YOLO系列 DF-YOLO[62 ] 基准模型为YOLOv7-tiny,引入可形变卷积,焦点损失 1 942 鸟巢、风筝、气球、垃圾 RCNN系列 RCNN4SPTL[63 ] 在FasterRCNN的基础上,利用小卷积核优化网络 5 000 漂浮物、气球、风筝 传统方法结合分类模型 Yu等[59 ] 通过二值化和形态学处理提取异物区域,基于CNN分类 861 鸟巢、气球、风筝、塑料
综合上述分析与讨论,传统的检测方法在场景适应性、参数设定方面存在困难,基于深度学习的检测方法在检测架构上已较为完善. 在实际应用中,基于深度学习的异物检测方法仍面临数据稀缺性的挑战,获得更多的可用异常数据仍然是异物检测中的难点. ...
A method based on multi-network feature fusion and random forest for foreign objects detection on transmission lines
2
2022
... 在铁路接触网检测领域主要面临的挑战包括模型推理的耗时问题、异物特征难提取的问题和数据量有限的问题,为此研究者对基于深度学习的目标检测方法进行了优化,优化思路如表3 所示. 1)在耗时问题方面,YOLO系列算法因具有精度和速度的平衡性而受到研究者的关注. Li等[57 ] 构建包含2 000张鸟巢图片的数据集,通过训练YOLOv5模型,使平均精度均值达到92.1%. 2)在特征提取方面,结合Transformer和YOLO可以有效提升特征的表达能力. Tang等[58 ] 提出融合Swin Transformer与YOLOX的检测技术,并创建含有鸟巢、风筝、气球等1 790张图片的数据集,使平均精度均值达到96.7%. 传统特征与深度学习的结合方法也被应用于此领域. Yu等[59 ] 利用传统方法提取可能存在的异物区域,并结合基于深度学习的分类模型进行分类,分类准确率达到95.88%. 3)由于实验数据有限,图像的数量往往是几百至几千张,使模型过拟合的风险增加. 考虑到深度学习由数据驱动,确保数据的充足和有效性是实现模型鲁棒性训练的关键. 针对数据稀缺的问题,生成式人工智能是值得探索的解决方案. 常见的数据生成方法是基于生成对抗网络(generative adversarial networks, GAN),通过在现有数据上训练生成器和判别器,生成与原始图像分布相似的新图像. 这种方法依赖已有的图像数据,且生成的图像相似度较高,难以完全拟合真实场景. Chen等[60 ] 提出RailFOD23数据集,通过深入融合ChatGPT的文本生成能力与Stable Diffusion的文本生成图片的性能,合成了大量的异常数据,采用基于光照平滑的合成方法将异物目标与现有铁路场景图像进行合成. RailFOD23数据集包括14 615张图像和40 541个标注对象,涵盖铁路输电线路上的4种常见异物. ...
... Main concepts of foreign object detection algorithms
Tab.3 算法类别 算法 主要思路 图片数量 异物类别 YOLO系列 YOLOv4-EDAM[61 ] 基于轻量级网络改进YOLOv4的主干网络,嵌入注意力机制 1 232 鸟巢、风筝、气球、垃圾 YOLO系列 ST2Rep–YOLOX[58 ] 基于Swin Transformer改进YOLOX主干,引入高效算子 1 560 鸟巢、风筝、气球 YOLO系列 DF-YOLO[62 ] 基准模型为YOLOv7-tiny,引入可形变卷积,焦点损失 1 942 鸟巢、风筝、气球、垃圾 RCNN系列 RCNN4SPTL[63 ] 在FasterRCNN的基础上,利用小卷积核优化网络 5 000 漂浮物、气球、风筝 传统方法结合分类模型 Yu等[59 ] 通过二值化和形态学处理提取异物区域,基于CNN分类 861 鸟巢、气球、风筝、塑料
综合上述分析与讨论,传统的检测方法在场景适应性、参数设定方面存在困难,基于深度学习的检测方法在检测架构上已较为完善. 在实际应用中,基于深度学习的异物检测方法仍面临数据稀缺性的挑战,获得更多的可用异常数据仍然是异物检测中的难点. ...
RailFOD23: a dataset for foreign object detection on railroad transmission lines
2
2024
... 在铁路接触网检测领域主要面临的挑战包括模型推理的耗时问题、异物特征难提取的问题和数据量有限的问题,为此研究者对基于深度学习的目标检测方法进行了优化,优化思路如表3 所示. 1)在耗时问题方面,YOLO系列算法因具有精度和速度的平衡性而受到研究者的关注. Li等[57 ] 构建包含2 000张鸟巢图片的数据集,通过训练YOLOv5模型,使平均精度均值达到92.1%. 2)在特征提取方面,结合Transformer和YOLO可以有效提升特征的表达能力. Tang等[58 ] 提出融合Swin Transformer与YOLOX的检测技术,并创建含有鸟巢、风筝、气球等1 790张图片的数据集,使平均精度均值达到96.7%. 传统特征与深度学习的结合方法也被应用于此领域. Yu等[59 ] 利用传统方法提取可能存在的异物区域,并结合基于深度学习的分类模型进行分类,分类准确率达到95.88%. 3)由于实验数据有限,图像的数量往往是几百至几千张,使模型过拟合的风险增加. 考虑到深度学习由数据驱动,确保数据的充足和有效性是实现模型鲁棒性训练的关键. 针对数据稀缺的问题,生成式人工智能是值得探索的解决方案. 常见的数据生成方法是基于生成对抗网络(generative adversarial networks, GAN),通过在现有数据上训练生成器和判别器,生成与原始图像分布相似的新图像. 这种方法依赖已有的图像数据,且生成的图像相似度较高,难以完全拟合真实场景. Chen等[60 ] 提出RailFOD23数据集,通过深入融合ChatGPT的文本生成能力与Stable Diffusion的文本生成图片的性能,合成了大量的异常数据,采用基于光照平滑的合成方法将异物目标与现有铁路场景图像进行合成. RailFOD23数据集包括14 615张图像和40 541个标注对象,涵盖铁路输电线路上的4种常见异物. ...
... 列车运行环境感知技术在实际工业应用中仍面临诸多挑战,限制了其推广和应用. 1)在铁路场景的图像分析中,小尺寸目标和模糊外观对检测精度有负面影响. 特别是无人机执行高空拍摄任务的情况[78 -79 ] ,小尺寸目标再加上雾天气象条件的影响,加大了目标特征提取的难度. 2)现代列车普遍装配前向摄像头[49 ] ,产生的海量数据对改善模型的精度至关重要,但是手工标注海量数据耗时且成本高昂,严重制约数据的有效闭环利用. 3)铁路沿线如鸟巢、气球、塑料膜等的异常图像数据稀缺[60 ] ,导致高质量的大规模异物数据集难以构建,模型精度评估变得困难. 4)无监督学习能够降低标记数据依赖性,具有增强低照度图像性能,但是缺少精准的标签信息导致生成图像容易包含噪声,干扰后续的处理任务. 5)点云处理算法的研究集中在对单帧点云数据的分析上,忽略了单帧点云数据在空间中通常呈现的显著稀疏性影响了3D视觉任务的精度. 6)大规模的高质量铁路场景3D数据集缺乏,深度学习方法对标注数据的依赖性强,创建用于多模态3D检测的数据集极其昂贵且耗时. 7)在深度学习模型的改进过程中,多数方法在追求精度提升的同时增加了计算负担,使模型难以满足列车对环境进行大规模、实时性、持续性感知的需求. ...
A lightweight YOLOv4-EDAM model for accurate and real-time detection of foreign objects suspended on power lines
1
2022
... Main concepts of foreign object detection algorithms
Tab.3 算法类别 算法 主要思路 图片数量 异物类别 YOLO系列 YOLOv4-EDAM[61 ] 基于轻量级网络改进YOLOv4的主干网络,嵌入注意力机制 1 232 鸟巢、风筝、气球、垃圾 YOLO系列 ST2Rep–YOLOX[58 ] 基于Swin Transformer改进YOLOX主干,引入高效算子 1 560 鸟巢、风筝、气球 YOLO系列 DF-YOLO[62 ] 基准模型为YOLOv7-tiny,引入可形变卷积,焦点损失 1 942 鸟巢、风筝、气球、垃圾 RCNN系列 RCNN4SPTL[63 ] 在FasterRCNN的基础上,利用小卷积核优化网络 5 000 漂浮物、气球、风筝 传统方法结合分类模型 Yu等[59 ] 通过二值化和形态学处理提取异物区域,基于CNN分类 861 鸟巢、气球、风筝、塑料
综合上述分析与讨论,传统的检测方法在场景适应性、参数设定方面存在困难,基于深度学习的检测方法在检测架构上已较为完善. 在实际应用中,基于深度学习的异物检测方法仍面临数据稀缺性的挑战,获得更多的可用异常数据仍然是异物检测中的难点. ...
DF-YOLO: highly accurate transmission line foreign object detection algorithm
1
2023
... Main concepts of foreign object detection algorithms
Tab.3 算法类别 算法 主要思路 图片数量 异物类别 YOLO系列 YOLOv4-EDAM[61 ] 基于轻量级网络改进YOLOv4的主干网络,嵌入注意力机制 1 232 鸟巢、风筝、气球、垃圾 YOLO系列 ST2Rep–YOLOX[58 ] 基于Swin Transformer改进YOLOX主干,引入高效算子 1 560 鸟巢、风筝、气球 YOLO系列 DF-YOLO[62 ] 基准模型为YOLOv7-tiny,引入可形变卷积,焦点损失 1 942 鸟巢、风筝、气球、垃圾 RCNN系列 RCNN4SPTL[63 ] 在FasterRCNN的基础上,利用小卷积核优化网络 5 000 漂浮物、气球、风筝 传统方法结合分类模型 Yu等[59 ] 通过二值化和形态学处理提取异物区域,基于CNN分类 861 鸟巢、气球、风筝、塑料
综合上述分析与讨论,传统的检测方法在场景适应性、参数设定方面存在困难,基于深度学习的检测方法在检测架构上已较为完善. 在实际应用中,基于深度学习的异物检测方法仍面临数据稀缺性的挑战,获得更多的可用异常数据仍然是异物检测中的难点. ...
RCNN-based foreign object detection for securing power transmission lines (RCNN4SPTL)
1
2019
... Main concepts of foreign object detection algorithms
Tab.3 算法类别 算法 主要思路 图片数量 异物类别 YOLO系列 YOLOv4-EDAM[61 ] 基于轻量级网络改进YOLOv4的主干网络,嵌入注意力机制 1 232 鸟巢、风筝、气球、垃圾 YOLO系列 ST2Rep–YOLOX[58 ] 基于Swin Transformer改进YOLOX主干,引入高效算子 1 560 鸟巢、风筝、气球 YOLO系列 DF-YOLO[62 ] 基准模型为YOLOv7-tiny,引入可形变卷积,焦点损失 1 942 鸟巢、风筝、气球、垃圾 RCNN系列 RCNN4SPTL[63 ] 在FasterRCNN的基础上,利用小卷积核优化网络 5 000 漂浮物、气球、风筝 传统方法结合分类模型 Yu等[59 ] 通过二值化和形态学处理提取异物区域,基于CNN分类 861 鸟巢、气球、风筝、塑料
综合上述分析与讨论,传统的检测方法在场景适应性、参数设定方面存在困难,基于深度学习的检测方法在检测架构上已较为完善. 在实际应用中,基于深度学习的异物检测方法仍面临数据稀缺性的挑战,获得更多的可用异常数据仍然是异物检测中的难点. ...
A deep learning based image enhancement approach for autonomous driving at night
1
2021
... 在复杂的列车环境和多变的光照条件中,获取用于训练的配对数据极为困难,限制了监督学习方法的应用. 为了克服监督模式下训练数据的配对问题,Li等[64 ] 提出数据合成方法,通过伽马变换和对比度调整将日间照片转换为低光照图像,以供监督学习训练使用. 该方法虽然在一定程度上缓解了配对数据需求问题,但参数的敏感度高,且存在与真实世界的光照变化不匹配的情况. 相对于传统的监督学习方法,无监督学习提供了不依赖于配对标签的训练方式,直接使用未标记的数据进行学习. 刘文强[65 ] 采用Retinex理论和生成对抗网络,提出用于增强接触网图像的方法. 该方法通过分离图像的反射和照明成分来改善亮度和对比度,利用对抗性训练生成逼真的图像样本,但是GAN模型的高计算量给后续的识别任务带来了挑战. Chen等[66 ] 提出基于光照曲线参数估计的轻量级渐进式低照度图像增强网络. 如图11 所示,该网络通过2个串联的子网络(Fast-LCPENet)逐步预测并应用光照曲线参数实现对图像光照的逐步恢复. 该方法被用于如图12 所示的低照度城轨列车场景下恢复图像的亮度,提升了目标检测的精度,但方法的无监督损失函数有待改进,以减少生成图像中的噪声. ...
1
... 在复杂的列车环境和多变的光照条件中,获取用于训练的配对数据极为困难,限制了监督学习方法的应用. 为了克服监督模式下训练数据的配对问题,Li等[64 ] 提出数据合成方法,通过伽马变换和对比度调整将日间照片转换为低光照图像,以供监督学习训练使用. 该方法虽然在一定程度上缓解了配对数据需求问题,但参数的敏感度高,且存在与真实世界的光照变化不匹配的情况. 相对于传统的监督学习方法,无监督学习提供了不依赖于配对标签的训练方式,直接使用未标记的数据进行学习. 刘文强[65 ] 采用Retinex理论和生成对抗网络,提出用于增强接触网图像的方法. 该方法通过分离图像的反射和照明成分来改善亮度和对比度,利用对抗性训练生成逼真的图像样本,但是GAN模型的高计算量给后续的识别任务带来了挑战. Chen等[66 ] 提出基于光照曲线参数估计的轻量级渐进式低照度图像增强网络. 如图11 所示,该网络通过2个串联的子网络(Fast-LCPENet)逐步预测并应用光照曲线参数实现对图像光照的逐步恢复. 该方法被用于如图12 所示的低照度城轨列车场景下恢复图像的亮度,提升了目标检测的精度,但方法的无监督损失函数有待改进,以减少生成图像中的噪声. ...
1
... 在复杂的列车环境和多变的光照条件中,获取用于训练的配对数据极为困难,限制了监督学习方法的应用. 为了克服监督模式下训练数据的配对问题,Li等[64 ] 提出数据合成方法,通过伽马变换和对比度调整将日间照片转换为低光照图像,以供监督学习训练使用. 该方法虽然在一定程度上缓解了配对数据需求问题,但参数的敏感度高,且存在与真实世界的光照变化不匹配的情况. 相对于传统的监督学习方法,无监督学习提供了不依赖于配对标签的训练方式,直接使用未标记的数据进行学习. 刘文强[65 ] 采用Retinex理论和生成对抗网络,提出用于增强接触网图像的方法. 该方法通过分离图像的反射和照明成分来改善亮度和对比度,利用对抗性训练生成逼真的图像样本,但是GAN模型的高计算量给后续的识别任务带来了挑战. Chen等[66 ] 提出基于光照曲线参数估计的轻量级渐进式低照度图像增强网络. 如图11 所示,该网络通过2个串联的子网络(Fast-LCPENet)逐步预测并应用光照曲线参数实现对图像光照的逐步恢复. 该方法被用于如图12 所示的低照度城轨列车场景下恢复图像的亮度,提升了目标检测的精度,但方法的无监督损失函数有待改进,以减少生成图像中的噪声. ...
BrightsightNet: a lightweight progressive low-light image enhancement network and its application in “Rainbow” maglev train
1
2023
... 在复杂的列车环境和多变的光照条件中,获取用于训练的配对数据极为困难,限制了监督学习方法的应用. 为了克服监督模式下训练数据的配对问题,Li等[64 ] 提出数据合成方法,通过伽马变换和对比度调整将日间照片转换为低光照图像,以供监督学习训练使用. 该方法虽然在一定程度上缓解了配对数据需求问题,但参数的敏感度高,且存在与真实世界的光照变化不匹配的情况. 相对于传统的监督学习方法,无监督学习提供了不依赖于配对标签的训练方式,直接使用未标记的数据进行学习. 刘文强[65 ] 采用Retinex理论和生成对抗网络,提出用于增强接触网图像的方法. 该方法通过分离图像的反射和照明成分来改善亮度和对比度,利用对抗性训练生成逼真的图像样本,但是GAN模型的高计算量给后续的识别任务带来了挑战. Chen等[66 ] 提出基于光照曲线参数估计的轻量级渐进式低照度图像增强网络. 如图11 所示,该网络通过2个串联的子网络(Fast-LCPENet)逐步预测并应用光照曲线参数实现对图像光照的逐步恢复. 该方法被用于如图12 所示的低照度城轨列车场景下恢复图像的亮度,提升了目标检测的精度,但方法的无监督损失函数有待改进,以减少生成图像中的噪声. ...
LiDAR point cloud recognition of overhead catenary system with deep learning
1
2020
... 点云数据通常由成千上万个不规则分布的点组成,每个点都带有空间坐标信息,有时还包括颜色、强度或其他特征. 由于CNN通常需要规则的网格数据输入,数据的不规则性和稀疏性使得直接应用标准的CNN变得困难. 体素法转换点云数据为体素表示,运用3D卷积学习全局上下文信息. Lin等[67 -68 ] 展示了利用3D CNN来分析点云上下文的可能性以及将体素化数据作为深度学习模型输入的策略,这些模型结合了共享的多层感知机和最大池化层. 尽管基于体素的方法在一定程度上提高了对整体结构的理解,却引入了过大的额外计算开销. 体素的大小选择是性能的关键因素,不适当的体素大小会导致重要细节信息丢失. 由于3D CNN计算开销的问题,体素化方法在铁路领域的应用受到限制. ...
Real-time rail recognition based on 3D point clouds
1
2022
... 点云数据通常由成千上万个不规则分布的点组成,每个点都带有空间坐标信息,有时还包括颜色、强度或其他特征. 由于CNN通常需要规则的网格数据输入,数据的不规则性和稀疏性使得直接应用标准的CNN变得困难. 体素法转换点云数据为体素表示,运用3D卷积学习全局上下文信息. Lin等[67 -68 ] 展示了利用3D CNN来分析点云上下文的可能性以及将体素化数据作为深度学习模型输入的策略,这些模型结合了共享的多层感知机和最大池化层. 尽管基于体素的方法在一定程度上提高了对整体结构的理解,却引入了过大的额外计算开销. 体素的大小选择是性能的关键因素,不适当的体素大小会导致重要细节信息丢失. 由于3D CNN计算开销的问题,体素化方法在铁路领域的应用受到限制. ...
1
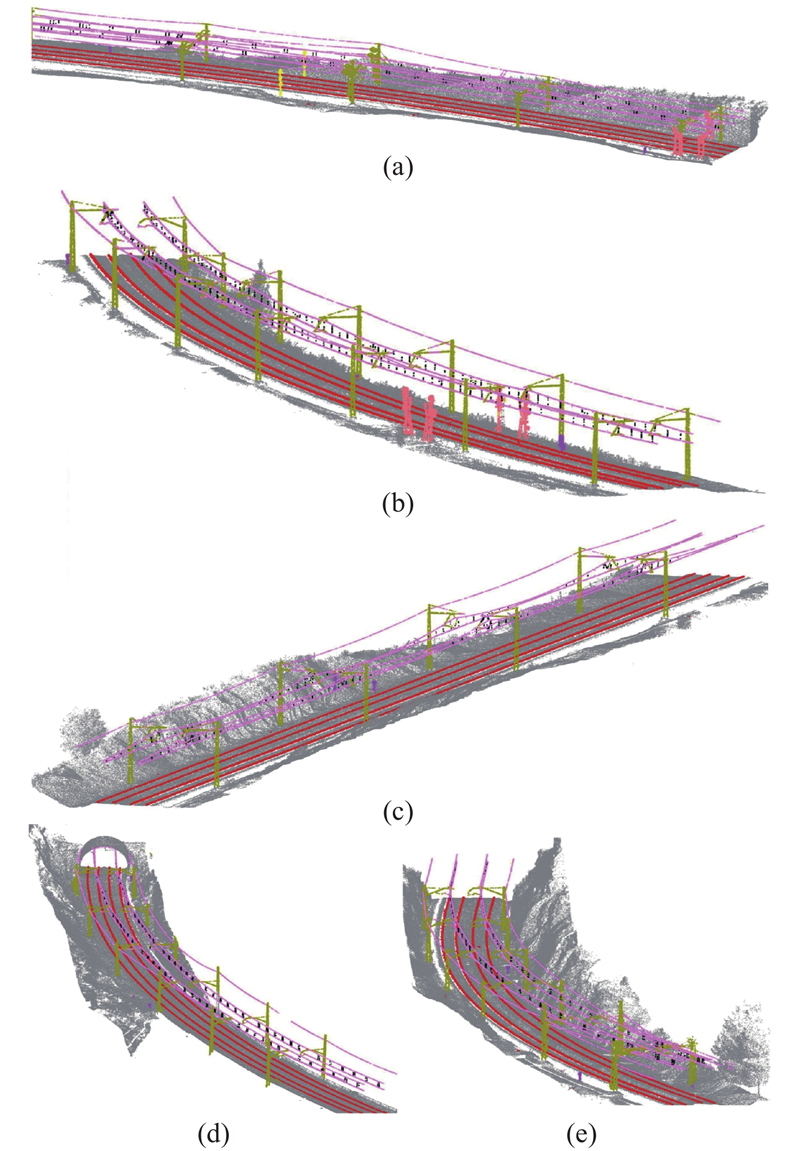
... 由于3D CNN的极大计算消耗,研究者开始探索直接处理原始点云数据的方法. 基于原始点云的方法在处理非均匀密度和复杂空间分布方面展现出其优势,能够精确捕捉点级别的细粒度信息. 作为点云数据处理领域的开创性技术,PointNet能够直接处理原始点云. 在此基础上,PointNet++引入了局部邻域概念能够捕捉局部和全局特征,在铁路场景的点云分割应用中已被广泛采用. Dibari等[69 ] 的比较分析显示,在铁路场景分割中,PointNet++优势大,迁移学习能够显著提高3D分割的精度. Grandio等[70 ] 将点云数据采样至32 768个点,使用PointNet++进行大规模铁路场景的点云分割;如图13 所示为该研究在5种不同场景下的分割效果,证明PointNet++在多种环境下均有良好的分割效果. 在铁路点云数据分割任务中,核点卷积(kernel point convolution, KPConv)是PointNet及PointNet++的重要扩展和改进. 引入灵活的核点卷积机制,不仅提升了复杂空间结构的识别能力,还增强了模型在处理不规则点云数据时的准确性和效率. Grandio等[70 -71 ] 分别通过KPConv对PointNet和PointNet++进行优化,提升了复杂场景下的分割精度,但伴随而来的是显著增加的计算量. 尽管基于原始点云的方法在铁路场景分割精度上取得了显著成就,但研究者对这些算法的计算效率分析相对有限. 点云数据的规模庞大,特别是在处理大规模点云数据时,提升计算效率和采样时间成为研究者亟待解决的问题. ...
Point cloud semantic segmentation of complex railway environments using deep learning
2
2022
... 由于3D CNN的极大计算消耗,研究者开始探索直接处理原始点云数据的方法. 基于原始点云的方法在处理非均匀密度和复杂空间分布方面展现出其优势,能够精确捕捉点级别的细粒度信息. 作为点云数据处理领域的开创性技术,PointNet能够直接处理原始点云. 在此基础上,PointNet++引入了局部邻域概念能够捕捉局部和全局特征,在铁路场景的点云分割应用中已被广泛采用. Dibari等[69 ] 的比较分析显示,在铁路场景分割中,PointNet++优势大,迁移学习能够显著提高3D分割的精度. Grandio等[70 ] 将点云数据采样至32 768个点,使用PointNet++进行大规模铁路场景的点云分割;如图13 所示为该研究在5种不同场景下的分割效果,证明PointNet++在多种环境下均有良好的分割效果. 在铁路点云数据分割任务中,核点卷积(kernel point convolution, KPConv)是PointNet及PointNet++的重要扩展和改进. 引入灵活的核点卷积机制,不仅提升了复杂空间结构的识别能力,还增强了模型在处理不规则点云数据时的准确性和效率. Grandio等[70 -71 ] 分别通过KPConv对PointNet和PointNet++进行优化,提升了复杂场景下的分割精度,但伴随而来的是显著增加的计算量. 尽管基于原始点云的方法在铁路场景分割精度上取得了显著成就,但研究者对这些算法的计算效率分析相对有限. 点云数据的规模庞大,特别是在处理大规模点云数据时,提升计算效率和采样时间成为研究者亟待解决的问题. ...
... [70 -71 ]分别通过KPConv对PointNet和PointNet++进行优化,提升了复杂场景下的分割精度,但伴随而来的是显著增加的计算量. 尽管基于原始点云的方法在铁路场景分割精度上取得了显著成就,但研究者对这些算法的计算效率分析相对有限. 点云数据的规模庞大,特别是在处理大规模点云数据时,提升计算效率和采样时间成为研究者亟待解决的问题. ...
Semantic segmentation of point clouds with PointNet and KPConv architectures applied to railway tunnels
1
2020
... 由于3D CNN的极大计算消耗,研究者开始探索直接处理原始点云数据的方法. 基于原始点云的方法在处理非均匀密度和复杂空间分布方面展现出其优势,能够精确捕捉点级别的细粒度信息. 作为点云数据处理领域的开创性技术,PointNet能够直接处理原始点云. 在此基础上,PointNet++引入了局部邻域概念能够捕捉局部和全局特征,在铁路场景的点云分割应用中已被广泛采用. Dibari等[69 ] 的比较分析显示,在铁路场景分割中,PointNet++优势大,迁移学习能够显著提高3D分割的精度. Grandio等[70 ] 将点云数据采样至32 768个点,使用PointNet++进行大规模铁路场景的点云分割;如图13 所示为该研究在5种不同场景下的分割效果,证明PointNet++在多种环境下均有良好的分割效果. 在铁路点云数据分割任务中,核点卷积(kernel point convolution, KPConv)是PointNet及PointNet++的重要扩展和改进. 引入灵活的核点卷积机制,不仅提升了复杂空间结构的识别能力,还增强了模型在处理不规则点云数据时的准确性和效率. Grandio等[70 -71 ] 分别通过KPConv对PointNet和PointNet++进行优化,提升了复杂场景下的分割精度,但伴随而来的是显著增加的计算量. 尽管基于原始点云的方法在铁路场景分割精度上取得了显著成就,但研究者对这些算法的计算效率分析相对有限. 点云数据的规模庞大,特别是在处理大规模点云数据时,提升计算效率和采样时间成为研究者亟待解决的问题. ...
FarNet: an attention-aggregation network for long-range rail track point cloud segmentation
3
2022
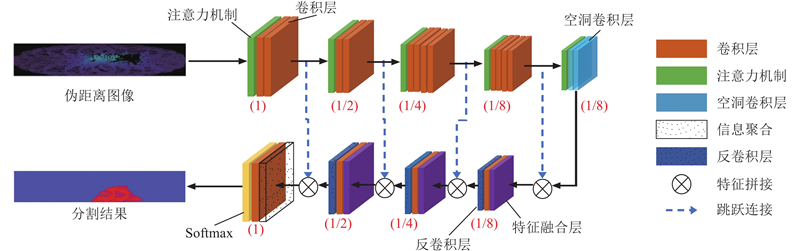
... 在铁路场景分割的研究领域中,基于投影的技术,特别是前视图投影方法已成为主流研究方向. 前视图投影的核心思想:将激光雷达捕获的点云数据通过球面坐标系的转换映射到平面上. 通过前视图转换处理后的网格化数据有5个通道,分别代表点云的空间位置(x , y , z )、距离和反射强度信息. 前视图的表示形式与图像标准格式保持一致,使得基于编解码机制的2D语义分割技术能够高效地应用于前视图. 如图14 所示,FarNet[72 ] 包含球面投影、注意力聚集网络和结果细化3个核心部分. FarNet充分利用2D语义分割技术的优势,通过引入注意力机制来捕捉空间上的相关性. Liu等[73 ] 基于前视图转换的方法对输入点云进行投影变换,利用UNet来处理铁路场景中的非结构化道路,在后处理阶段采用混合高斯分类器进行优化,实现了分割精度的提升. ...
... FarNet的网络结构[72 ] ...
... Network structure of FarNet[72 ] ...
Uncertainty-aware point-cloud semantic segmentation for unstructured roads
1
2023
... 在铁路场景分割的研究领域中,基于投影的技术,特别是前视图投影方法已成为主流研究方向. 前视图投影的核心思想:将激光雷达捕获的点云数据通过球面坐标系的转换映射到平面上. 通过前视图转换处理后的网格化数据有5个通道,分别代表点云的空间位置(x , y , z )、距离和反射强度信息. 前视图的表示形式与图像标准格式保持一致,使得基于编解码机制的2D语义分割技术能够高效地应用于前视图. 如图14 所示,FarNet[72 ] 包含球面投影、注意力聚集网络和结果细化3个核心部分. FarNet充分利用2D语义分割技术的优势,通过引入注意力机制来捕捉空间上的相关性. Liu等[73 ] 基于前视图转换的方法对输入点云进行投影变换,利用UNet来处理铁路场景中的非结构化道路,在后处理阶段采用混合高斯分类器进行优化,实现了分割精度的提升. ...
Real-time 3D multi-object detection and localization based on deep learning for road and railway smart mobility
1
2021
... 传统的2D目标检测方法虽然可以检测出目标在图像中的像素位置,但是无法获取目标的深度信息,极大地限制了它在列车自动驾驶领域的应用. 单目3D目标检测采用基于单一摄像头视觉的解决策略,顺应了2D目标检测方法的逻辑. 该技术通过卷积神经网络直接从图像中回归出3D边界框的参数,实现了端到端的训练过程. 在铁路场景应用中,Mauri等[74 -75 ] 在YOLO检测框架的基础上进行创新,通过引入混合锚框技术实现了3D参数的回归;为了评估模型在铁路环境下的性能,采用《侠盗猎车手V》游戏中的场景模拟铁路和道路环境,结合KITTI数据集进行了模型训练;实验结果显示,当在KITTI的中等难度测试集上以0.5的交并比阈值为标准进行评估时,模型的mAP = 48.45%. 虽然依赖大量数据的训练可以在一定程度上提升识别精度,但是定位精度的提高仍面临挑战,特别是当交并比阈值提高至0.75时,mAP降至18.46%. 单目3D目标检测利用单一摄像头完成目标检测,在降低传感器成本方面具有不可忽视的优势,但其空间位置的检测精度与基于激光雷达的点云检测方法的差异显著. 因此,单目3D检测技术仍处于发展瓶颈阶段. ...
Lightweight convolutional neural network for real-time 3D object detection in road and railway environments
1
2022
... 传统的2D目标检测方法虽然可以检测出目标在图像中的像素位置,但是无法获取目标的深度信息,极大地限制了它在列车自动驾驶领域的应用. 单目3D目标检测采用基于单一摄像头视觉的解决策略,顺应了2D目标检测方法的逻辑. 该技术通过卷积神经网络直接从图像中回归出3D边界框的参数,实现了端到端的训练过程. 在铁路场景应用中,Mauri等[74 -75 ] 在YOLO检测框架的基础上进行创新,通过引入混合锚框技术实现了3D参数的回归;为了评估模型在铁路环境下的性能,采用《侠盗猎车手V》游戏中的场景模拟铁路和道路环境,结合KITTI数据集进行了模型训练;实验结果显示,当在KITTI的中等难度测试集上以0.5的交并比阈值为标准进行评估时,模型的mAP = 48.45%. 虽然依赖大量数据的训练可以在一定程度上提升识别精度,但是定位精度的提高仍面临挑战,特别是当交并比阈值提高至0.75时,mAP降至18.46%. 单目3D目标检测利用单一摄像头完成目标检测,在降低传感器成本方面具有不可忽视的优势,但其空间位置的检测精度与基于激光雷达的点云检测方法的差异显著. 因此,单目3D检测技术仍处于发展瓶颈阶段. ...
2
... 点云3D检测方法在汽车自动驾驶领域备受关注,已有诸多公开数据集可供使用. 梳理铁路行业内3D检测文献,发现具备激光雷达、相机和毫米波雷达的多元传感数据的公开数据集稀缺,仅有OSDaR23[76 ] . 该数据集由DB Netz AG公司和德国铁路运输研究中心发布. 如图15 所示,数据集的采集设备包括多个校准和同步的红外相机、可见光相机、激光雷达以及安装在铁路车辆前部的毫米波雷达传感器. Kopuz[77 ] 以OSDaR23数据集作为研究对象,探讨了使用激光雷达和图像这2种不同模态进行3D目标检测的效果. OSDaR23涵盖45个序列,总计1 534帧图像,标注对象为204 091个. 该数据集存在明显的长尾分布问题,即部分类别的样本数量极为有限. 鉴于此,Kopuz[77 ] 的研究主要集中在相对常见的类别:行人、接触网杆、信号杆、道路车辆和止冲挡,使用BEVFusion在OSDaR23上进行多模态检测的实验结果如表4 所示. 表中,C表示使用相机模态输入;L表示使用激光雷达模态输入;+TF表示模型采用考虑连续帧之间的关联和动态变化,以此来增强数据;+TA-GTP表示在训练数据中加入具有不同时间戳的目标,以此来增强数据集. 由表可知,当仅使用相机作为传感器时,BEVFusion模型在多个目标类别上的mAP相对较低,特别是行人类别,mAP = 28.76%,接触网杆和信号杆的检测精度无法满足要求. 当仅使用激光雷达作为传感器时,BEVFusion模型在所有目标类别上的mAP显著提升,尤其是行人类别,mAP = 79.99%,接触网杆和信号杆的检测精度得到明显改善. 在结合相机和激光雷达作为传感器后,BEVFusion模型的整体检测精度进一步增强. 此外,2种考虑时间维度的数据增强技术对模型性能的提升也起了积极作用. 如表5 所示为不同目标距离情况下BEVFusion的平均精度均值. 可以看出,不同模态之间的信息显著影响检测精度. 相机适用于近距离的细节感知,激光雷达适用于远距离的深度感知,通过合理地选择和融合不同模态的数据,可以提高列车在不同距离范围内的感知能力,从而提高驾驶安全性和效率. ...
... OSDaR23数据集的数据采集设备[76 ] ...
2
... 点云3D检测方法在汽车自动驾驶领域备受关注,已有诸多公开数据集可供使用. 梳理铁路行业内3D检测文献,发现具备激光雷达、相机和毫米波雷达的多元传感数据的公开数据集稀缺,仅有OSDaR23[76 ] . 该数据集由DB Netz AG公司和德国铁路运输研究中心发布. 如图15 所示,数据集的采集设备包括多个校准和同步的红外相机、可见光相机、激光雷达以及安装在铁路车辆前部的毫米波雷达传感器. Kopuz[77 ] 以OSDaR23数据集作为研究对象,探讨了使用激光雷达和图像这2种不同模态进行3D目标检测的效果. OSDaR23涵盖45个序列,总计1 534帧图像,标注对象为204 091个. 该数据集存在明显的长尾分布问题,即部分类别的样本数量极为有限. 鉴于此,Kopuz[77 ] 的研究主要集中在相对常见的类别:行人、接触网杆、信号杆、道路车辆和止冲挡,使用BEVFusion在OSDaR23上进行多模态检测的实验结果如表4 所示. 表中,C表示使用相机模态输入;L表示使用激光雷达模态输入;+TF表示模型采用考虑连续帧之间的关联和动态变化,以此来增强数据;+TA-GTP表示在训练数据中加入具有不同时间戳的目标,以此来增强数据集. 由表可知,当仅使用相机作为传感器时,BEVFusion模型在多个目标类别上的mAP相对较低,特别是行人类别,mAP = 28.76%,接触网杆和信号杆的检测精度无法满足要求. 当仅使用激光雷达作为传感器时,BEVFusion模型在所有目标类别上的mAP显著提升,尤其是行人类别,mAP = 79.99%,接触网杆和信号杆的检测精度得到明显改善. 在结合相机和激光雷达作为传感器后,BEVFusion模型的整体检测精度进一步增强. 此外,2种考虑时间维度的数据增强技术对模型性能的提升也起了积极作用. 如表5 所示为不同目标距离情况下BEVFusion的平均精度均值. 可以看出,不同模态之间的信息显著影响检测精度. 相机适用于近距离的细节感知,激光雷达适用于远距离的深度感知,通过合理地选择和融合不同模态的数据,可以提高列车在不同距离范围内的感知能力,从而提高驾驶安全性和效率. ...
... [77 ]的研究主要集中在相对常见的类别:行人、接触网杆、信号杆、道路车辆和止冲挡,使用BEVFusion在OSDaR23上进行多模态检测的实验结果如表4 所示. 表中,C表示使用相机模态输入;L表示使用激光雷达模态输入;+TF表示模型采用考虑连续帧之间的关联和动态变化,以此来增强数据;+TA-GTP表示在训练数据中加入具有不同时间戳的目标,以此来增强数据集. 由表可知,当仅使用相机作为传感器时,BEVFusion模型在多个目标类别上的mAP相对较低,特别是行人类别,mAP = 28.76%,接触网杆和信号杆的检测精度无法满足要求. 当仅使用激光雷达作为传感器时,BEVFusion模型在所有目标类别上的mAP显著提升,尤其是行人类别,mAP = 79.99%,接触网杆和信号杆的检测精度得到明显改善. 在结合相机和激光雷达作为传感器后,BEVFusion模型的整体检测精度进一步增强. 此外,2种考虑时间维度的数据增强技术对模型性能的提升也起了积极作用. 如表5 所示为不同目标距离情况下BEVFusion的平均精度均值. 可以看出,不同模态之间的信息显著影响检测精度. 相机适用于近距离的细节感知,激光雷达适用于远距离的深度感知,通过合理地选择和融合不同模态的数据,可以提高列车在不同距离范围内的感知能力,从而提高驾驶安全性和效率. ...
Automatic detection of arbitrarily oriented fastener defect in high-speed railway
1
2021
... 列车运行环境感知技术在实际工业应用中仍面临诸多挑战,限制了其推广和应用. 1)在铁路场景的图像分析中,小尺寸目标和模糊外观对检测精度有负面影响. 特别是无人机执行高空拍摄任务的情况[78 -79 ] ,小尺寸目标再加上雾天气象条件的影响,加大了目标特征提取的难度. 2)现代列车普遍装配前向摄像头[49 ] ,产生的海量数据对改善模型的精度至关重要,但是手工标注海量数据耗时且成本高昂,严重制约数据的有效闭环利用. 3)铁路沿线如鸟巢、气球、塑料膜等的异常图像数据稀缺[60 ] ,导致高质量的大规模异物数据集难以构建,模型精度评估变得困难. 4)无监督学习能够降低标记数据依赖性,具有增强低照度图像性能,但是缺少精准的标签信息导致生成图像容易包含噪声,干扰后续的处理任务. 5)点云处理算法的研究集中在对单帧点云数据的分析上,忽略了单帧点云数据在空间中通常呈现的显著稀疏性影响了3D视觉任务的精度. 6)大规模的高质量铁路场景3D数据集缺乏,深度学习方法对标注数据的依赖性强,创建用于多模态3D检测的数据集极其昂贵且耗时. 7)在深度学习模型的改进过程中,多数方法在追求精度提升的同时增加了计算负担,使模型难以满足列车对环境进行大规模、实时性、持续性感知的需求. ...
Hybrid deep learning architecture for rail surface segmentation and surface defect detection
1
2022
... 列车运行环境感知技术在实际工业应用中仍面临诸多挑战,限制了其推广和应用. 1)在铁路场景的图像分析中,小尺寸目标和模糊外观对检测精度有负面影响. 特别是无人机执行高空拍摄任务的情况[78 -79 ] ,小尺寸目标再加上雾天气象条件的影响,加大了目标特征提取的难度. 2)现代列车普遍装配前向摄像头[49 ] ,产生的海量数据对改善模型的精度至关重要,但是手工标注海量数据耗时且成本高昂,严重制约数据的有效闭环利用. 3)铁路沿线如鸟巢、气球、塑料膜等的异常图像数据稀缺[60 ] ,导致高质量的大规模异物数据集难以构建,模型精度评估变得困难. 4)无监督学习能够降低标记数据依赖性,具有增强低照度图像性能,但是缺少精准的标签信息导致生成图像容易包含噪声,干扰后续的处理任务. 5)点云处理算法的研究集中在对单帧点云数据的分析上,忽略了单帧点云数据在空间中通常呈现的显著稀疏性影响了3D视觉任务的精度. 6)大规模的高质量铁路场景3D数据集缺乏,深度学习方法对标注数据的依赖性强,创建用于多模态3D检测的数据集极其昂贵且耗时. 7)在深度学习模型的改进过程中,多数方法在追求精度提升的同时增加了计算负担,使模型难以满足列车对环境进行大规模、实时性、持续性感知的需求. ...










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}