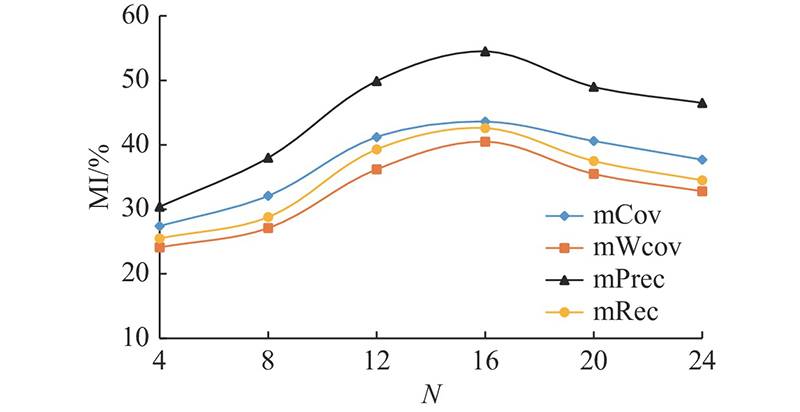
A point cloud instance segmentation model with a k-nearest neighbors (KNN) module featuring attention mechanism and an improved associatively segmenting instances and semantics (ASIS) module was proposed to address the problems of discrete segmentation and insufficient feature utilization in traditional 3D convolution-based algorithms. The model took voxels as input and extracted point features through sparse convolution of 3D submanifolds. The KNN algorithm with attention mechanism was used for reorganizing the features in the semantic and instance feature space to alleviate the problem caused by the quantization error of extracted features. The reorganized semantic and instance features were correlated through the improved ASIS module to enhance the discrimination between point features. For semantic features and instance embedding, the softmax module and the meanshift algorithm were applied to obtain semantic and instance segmentation results respectively. The public S3DIS dataset was employed to validate the proposed model. The experimental results showed that the instance segmentation results of the proposed model achieved 53.1%, 57.1%, 65.2% and 52.8% in terms of mean coverage (mCoV), mean weighted coverage (mWCov), mean precision (mPrec) and mean recall (mRec) for the instance segmentation. The semantic segmentation achieved 61.7% and 88.1% respectively in terms of mean intersection over union (mIoU) and Over-all accuracy (Oacc) for the semantic segmentation. The ablation experiment verified the effectiveness of the proposed modules.
XIANG Xue-yong, WANG Li, ZONG Wen-peng, LI Guang-yun. Point cloud instance segmentation based on attention mechanism KNN and ASIS module. Journal of Zhejiang University(Engineering Science)[J], 2023, 57(5): 875-882 doi:10.3785/j.issn.1008-973X.2023.05.003
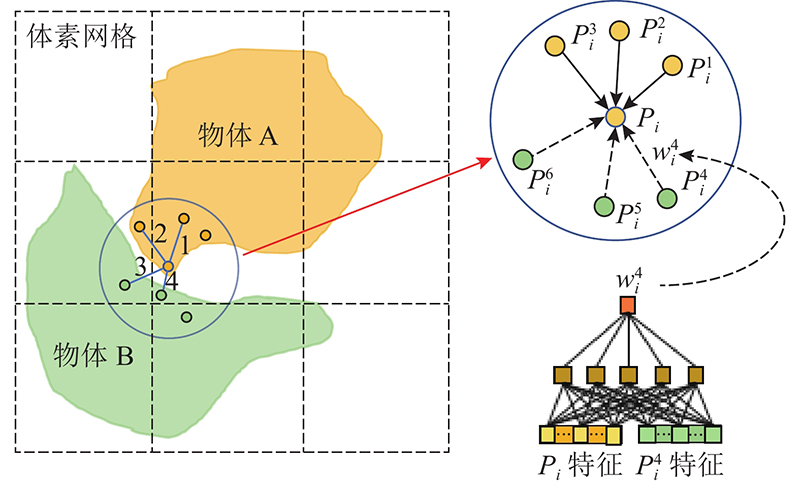
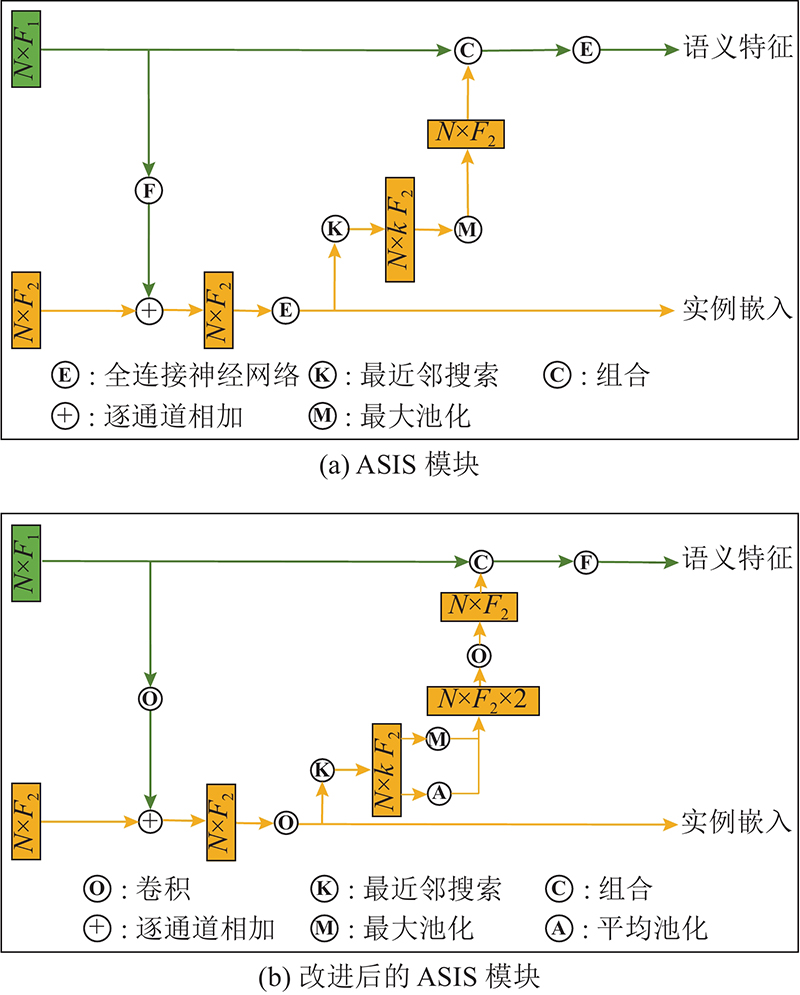
基于上述分析,本研究采用子流形稀疏卷积网络作为主干网络,在提取点特征的同时保留场景的全局信息,为了克服提取到的特征离散化问题,提出具有注意力机制的KNN(k-nearest neighbors)模块[17-18]. 对于Wang等[9]提出的ASIS(associatively segmenting instances and semantics)模块加以改进,实现语义与实例特征空间相互关联与优势互补,以增强点之间的区分度,进一步改善模型分割结果.
1. 研究方法
1.1. 模型架构
提出的ASIS模块支持下融合注意力机制的点云实例分割模型由图1所示. 可以看出,网络整体结构由1个主干网络和2个分支网络构成. 将维度为 $ N \times 6 $点云输入至主干网络, $ N $为点个数. 主干网络用于提取逐点特征,输出的点特征维度为F. 一个分支网络进行语义标签预测,另一个分支网络生成实例分割结果. 主干网络采用3D子流形稀疏卷积网络,该网络可在提取点云场景全局特征的前提下,有效克服传统3D卷积的高计算量问题,之后将提取到的逐点特征输入至语义分割与实例分割2个分支网络,并通过提出具有注意力机制的KNN模块对特征进行聚合操作,分别得到维度为 $ {F_1} $的语义特征和维度为 $ {F_2} $的实例特征. 并利用改进的ASIS模块做进一步的处理,最终语义分支网络输出 $ N \times C $的特征向量,其中 $ C $为点云语义类别数,实例分支网络输出 $ N \times E $的实例嵌入. 其中E为实例嵌入的维度.
ZHAO N, CHUA T S, LEE G H. Few-shot 3d point cloud semantic segmentation [C]// IEEE Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 8873-8882.
YAO Pei-jun, YIN Yan-yun, Facade measurement method based on three-dimensional laser scanner and total station technology [J]. Geotechnical Engineering Technique, 2022, 36(2): 156-159.
HOU J, DAI A, NIEßNER M. 3D-SIS: 3d semantic instance segmentation of RGB-d scans [C]// IEEE Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 4421-4430.
YI L, ZHAO W, WANG H, et al. GSPN: generative shape proposal network for 3d instance segmentation in point cloud [C]// IEEE Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 3947-3956.
WANG W Y, YU R, HUANG Q, et al. SGPN: similarity group proposal network for 3d point cloud instance segmentation [C]// IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 2569-2578.
WANG X L, LIU S, SHEN X Y, et al. Associatively segmenting instances and semantics in point clouds [C]// IEEE Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 4096-4105.
PHAM Q H, NGUYEN T, HUA B S, et al. Jsis3d: joint semantic-instance segmentation of 3d point clouds with multi-task pointwise networks and multi-value conditional random fields [C]// IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 8827-8836.
LAHOUD J, GHANEM B, POLLEFEYS M, et al. 3D instance segmentation via multi-task metric learning [C]// IEEE International Conference on Computer Vision Workshops. Seoul: IEEE, 2019: 9256-9266.
DU J, CAI G R, WANG Z Y, et al. Convertible sparse convolution for point cloud instace segmentation [C]// IEEE International Geoscience and Remote Sensing Symposium. Brussels: IEEE, 2021: 4111-4114.
PAN R Y, HUANG C M. Accuracy improvement of deep learning 3d point cloud instance segmentation [C]// IEEE International Conference on Consumer Electronics Taiwan. Taiwan: IEEE, 2021: 1-12.
QI R, SU H, MO K, et al. PointNet: deep learning on point sets for 3d classification and segmentation [C]// IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 652-660.
GRAHAM B, ENGELCKE M, VAN DER MAATEN L. 3D semantic segmentation with submanifold sparse convolutional networks [C]// IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 9224-9232.
CHOY C, GWAK J Y, SAVARESE S. 4D spatio-temporal convnets: minkowski convolutional neural networks [C]// IEEE Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 998-1008.
HE K M, ZHANG X, REN S Q, et al. Deep residual learning for image recognition [C]// IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778.
WEN Y D, ZHANG K P, LI Z F, et al. A discriminative feature learning approach for deep face recognition [C]// European Conference on Computer Vision. Amsterdam: Springer, 2016: 499-515.
DE BRABANDERE B, NEVEN D, VAN GOOL L. Semantic instance segmentation with a discriminative loss function [EB/OL]. [2017-08-08]. https://arxiv.org/abs/1708.02551.
LIU W Y, WEN Y, YU Z, et al. Large-margin softmax loss for convolutional neural networks [C]// International Conference on Machine Learning. New York City: IMLS, 2016: 7-18.
ARMENI I, SENER O, ZAMIR A, et al. 3D semantic parsing of large-scale indoor spaces [C]// IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 1534-1543.
MENGYE R, RICHARD Z. End-to-end instance segmentation with recurrent attention [C]// IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 6656-6664.
LIU S R, JIA J, FIDLER S, et al. SGN: sequential grouping networks for instance segmentation [C]// IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 6656-6664.
ZHUO W, SALZMANN M, HE X, et al. Indoor scene parsing with instance segmentation, semantic labeling and support relationship inference [C]// IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 6656-6664.
MO K, ZHU S, CHANG A X, et al. PartNet: a large-scale benchmark for fine-grained and hierarchical part-level 3d object understanding [C]// IEEE Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 998-1008.
YANG B, WANG J, CLARK R, ET AL. Learning object bounding boxes for 3d instance segmentation on point clouds [C]// Proceedings of the Advances in Neural Information Processing Systems. Vancouver: NIPS, 2019: 563-575.
QI C R, YI L, SU H, et al. PointNet++: deep hierarchical feature learning on point sets in a metric space [C]// Proceedings of the Advances in Neural Information Processing Systems. Long Beach: NIPS, 2017: 5099-5108.
CATHRIN E, FRANCIS E, THEODORA K, et al. 3D bird’s-eye-view instance segmentation [C]// German Conference on Pattern Recognition. Bonn: DAGM, 2019: 48-61.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}