

Forster等[10]设计实现了基于直接法的视觉里程计-半直接单目视觉里程计(semi-direct monocular visual odometry,SVO),标志着直接法在SLAM中的成功应用. 但直接法须满足灰度不变假设[12](brightness constancy assumption,BCA),即同一个空间点的像素灰度,在各个图像中保持不变. 在实际环境中,由于光照变化,BCA假设经常失效. 因此,改进的SLAM算法开始逐渐受到关注. Engel等[9]在LSD-SLAM的基础上设计实现了直接稀疏里程计(direct sparse odometry,DSO),该算法提出了更为细致的光度模型,能够让算法更加鲁棒,但是对相机要求更高,成本高昂. Park等[12]提出Census变换[13]可以用于实际的光照变化场景中,同时也指出Census变换不适合使用在基于图像梯度优化的直接法中. 在立体视觉领域,Census变换是对于光照变化有鲁棒性的局部二进制描述子. 但直接法中用于计算相机位姿的光度误差定义在欧氏空间中,将二进制的Census变换结果直接应用在直接法中会造成算法严重的计算误差.
为了改善直接法在光照变化场景下的鲁棒性同时降低硬件的成本,提出基于改进Census变换的单目视觉里程计,向量Census变换半直接单目视觉里程计(vector-Census semi-direct monocular visual odometry,VC-SVO). 首先改进Census变换的表达形式,使其应用在欧氏空间中. 之后,改进SVO算法并融合改进的Census变换,通过最小化对应地图点的Census变换误差计算相机的位姿. 最后,采用均匀-高斯混合分布的逆深度滤波器[14]对特征点进行深度估计,同时构建出稀疏的环境地图. 在EuRoC[15]、New Tsukuba Stereo[16]和TUM数据集上的实验表明,VC-SVO在光照变化场景下可以有效地估计出相机的位姿.
1. Census transform的改进
1.1. Census变换
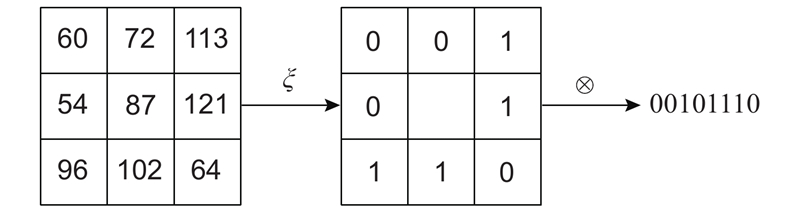
Census变换以某个像素点作为中心点选择3×3大小的矩形窗口,用中心像素n的灰度作为参考值,与除中心之外的每一个像素m的灰度进行比较,如果中心像素灰度大于等于该点的灰度,那么该点的Census变换值设为0,反之,设为1.
式中:I为像素灰度,ξ为Census变换值.
之后按顺序排列,得到最终的结果,变换后的结果为8位二进制码.
式中:
变换过程如图1所示,在
图 1
1.2. V-Census变换
为了保证Census变换的结果对光照变化有较好的鲁棒性,比较就要在二进制的形式下进行,一般采用汉明距离. 汉明距离是指2个二进制结果之间不同位数的个数.
直接法是在欧氏空间中进行推导和计算的. 对于参考图像上的像素点,假设其灰度为215,通过最开始的位姿估计得到在新的图像上的灰度为123,光度误差的计算采用欧氏距离,直接相减,得到误差结果92. 通过不断调整位姿,可以减少这个误差.
为了将Census变换与直接法相结合,改善直接法在光照变化场景下的定位失败问题,提出改进的Census变换:V-Census变换,变换形式如下:
存储Census变换的每一位,将其变换为八位向量进行存储,这样就避免了二进制结果. 由于改变了Census变换的结果形式,故采用SSD[19](sum of squared distance)方式进行差异计算.
式中:n1、n2为2个矩形方阵的中心,mi为除矩阵中心之外的元素.
使用SSD来衡量2个V-Census变换,在几何意义上与汉明距离一致. 由式(4)可知,V-Census变换之后的向量排列顺序对SSD的计算结果没有影响.
2. 算法流程
本研究算法流程参考SVO算法框架,如图2所示. 整体分为位姿估计与地图构建2个线程,以提高运行效率.
图 2
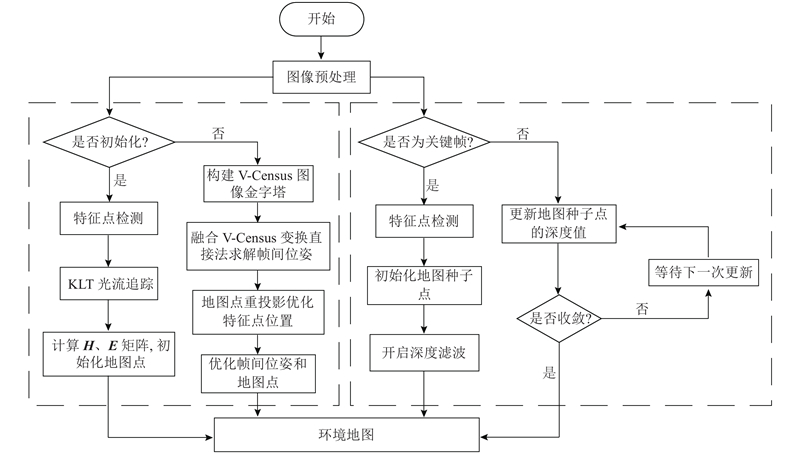
当发生跟踪丢失时,SVO的重定位策略是,只有当相机运动到跟丢的位置时,才能重定位回来. 因此,须改进SVO中的重定位策略,改进如下:1)跟丢之后,假设当前帧与最近的关键帧位姿一样,将地图点投影到当前帧上,不限制地图点的投影位置,允许地图点的集中,并进行位姿估计,若位姿估计成功,则重定位成功,将关键帧位姿设置为当前帧位姿. 若失败,就继续下一帧. 2)若持续多帧重定位失败,则说明相机运动距离较大,地图点投影失败,须重新进行初始化,并使用最近关键帧的位姿作为初始化位姿.
2.1. 特征均匀分布
对最开始的图像进行加速段测试特征点提取(features from accelerated segment test,FAST)[22],为之后的初始化做准备. 特征点的提取对于相机位姿的估计起着至关重要的作用,但传统的FAST特征点提取存在着特征点分布不均匀、特征点集中的现象,严重影响相机的位姿估计与初始化地图点的质量,因此本研究实现了一种特征点均匀化的处理算法.
构建输入图像的图像金字塔模型,对金字塔每一层图像进行四叉树网格划分,在网格内进行FAST特征点检测. 对于特征不明显的网格,进行降阈值检测. 对于网格内存在的多个特征点,采用非极大值抑制(non-maximum suppression,NMS)[23]的方法,使得每个网格内只存在一个最优特征点. 从而实现在整张图像上的特征点均匀提取.
图 3

图 4
2.2. 非平面场景假设模型
由于SVO的目标应用场景是无人机的俯视相机,认为所有的特征点都位于同一平面上,这就是平面假设模型. 对于相机俯视的情况,所有特征点位于同一平面是成立的,此时相邻图像上特征点的对极约束由单应矩阵H来描述. 但在实际应用中,更多的是相机前视的情况.
当相机前视时,场景的特征点不是在同一个平面上的,因此须补充非平面场景假设模型. 当SVO单目初始化时,根据KLT光流追踪的结果,统计每一个追踪到的特征点的视差,并计算所有特征点视差的标准差. 当视差的标准差大于一定阈值时,则认为特征点之间的深度差距过大,特征点应位于不同的平面上,此时特征点的对极约束由本质矩阵E来描述,使用随机采样性一致(random sample consensus, RANSAC)来求解相机位姿. 当标准差小于阈值时,则认为平面假设成立,由单应矩阵H求解相机位姿,初始化流程如图2所示.
2.3. 位姿估计
设空间中一点P的世界坐标P=(X, Y, Z),对应的相邻2帧图像的像素坐标为p1=(u1, v1)和p2=(u2, v2),fx、fy、cx、cy为相机的内参,相邻的2帧图像的位姿分别为Tc1w、Tc2w,2帧之间的位姿变换为Tc2c1. 通过优化2帧图像上对应特征点的V-Census误差来计算相机位姿:
式中:
式中:Vi1、Vi2为p1、p2处的V-Census变换,w表示从空间点到像素点的变换.
对变换后的非线性公式(式(6))在θ的附近进行一阶泰勒展开,由链式规则得到
为了求其近似解,对
用
式中:
式中:p1x、p1y为原始图像上p1点处
变换后的一阶导数保留了与直接法中的像素梯度同样的性质[24],因此能够把优化引导到正确的方向上.
计算如下:
式中:
在每次迭代求出
式中:
直到迭代终止,得到优化后的Tc2c1.
2.4. 关键帧选取
合适的关键帧不仅可以更好地估计相机的位姿,还可以加速建图线程中地图点的收敛速度.
SVO算法由于采用平面模型假设,在选择关键帧时,仅使用平移量作为新的关键帧选择策略. 由于补充了非平面模型假设,因此,设计新的关键帧选择策略:1)若当前帧上投影的地图点数量小于一定阈值,将当前帧设为关键帧. 2)若当前帧与相邻帧的平移量或旋转量大于一定阈值,将当前帧设为关键帧. 3)若当前帧上投影点位置与最近关键帧上的特征点位置的差值大于一定阈值,将当前帧设为关键帧.
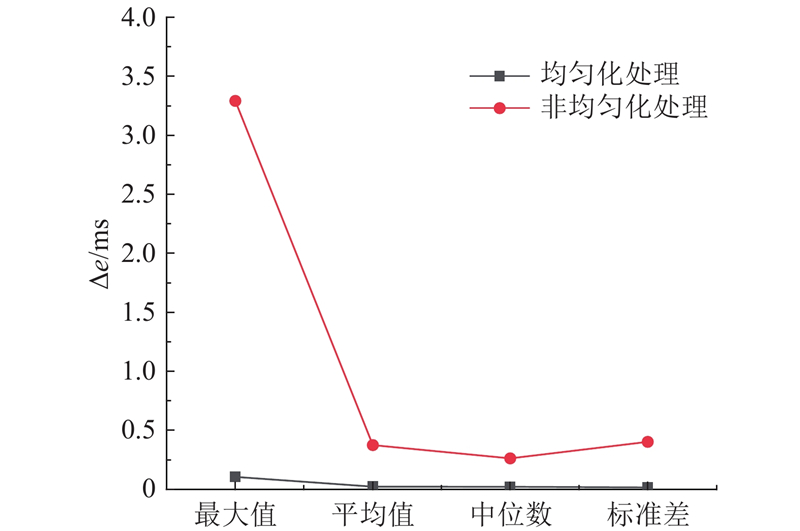
如表1所示为在EuRoC数据集中MH_01、MH_02与MH_03图像序列中关键帧数量的变化对比图. 可以看出,新的关键帧提取策略提高了关键帧选择的效率.
表 1 各序列关键帧数量对比
Tab.1
| 图像序列 | 改进前数量 | 改进后数量 |
| MH_01 | 84 | 329 |
| MH_02 | 77 | 301 |
| MH_03 | 65 | 296 |
3. 实验分析
本研究算法使用C++和OpenCV实现,图形界面使用Pangolin实现,系统配置为Linux16.04,CPU为Inteli5-8400,8 G内存. 使用MH_01图像序列进行算法耗时统计,结果如表2所示.可以看出,KLT光流追踪耗时最长,但是只在初始化过程中实现一次,因此在实际运行过程中,平均每帧图像耗时总长为24.66 ms,运行速度为41帧/s,基本满足实时性要求.
实验数据使用EuRoC数据集、New Tsukuba Stereo数据集与TUM数据集进行实际图像实验. 对实验的结果采用相对位姿误差(relative pose error,RPE)进行评估. 在与轨迹的真实值作对比时,使用EVO(evaluation of odometry and SLAM)工具进行数据对齐.
表 2 算法各步骤耗时
Tab.2
| 算法步骤 | 耗时/ms | 总时间/ms |
| 特征点提取 | 5.74 | 90.53 |
| KLT光流追踪 | 67.88 | |
| V-Census变换 | 6.87 | |
| 计算位姿 | 10.04 | |
| 优化像素位置 | 1.83 | 2.01 |
| 优化位姿 | 0.16 | |
| 优化地图点 | 0.02 |
3.1. EuRoC数据集
EuRoC数据集由苏黎世联邦工业大学ASL实验室使用微型飞行器采集得到,微型飞行器挂载双目全局VIO相机,记录了200 Hz的IMU数据以及20 Hz的双目相机图像. 此外,数据集还提供了毫米级的真实轨迹数据. 由于VC-SVO算法是单目视觉里程计,只使用EuRoC数据集中的单目图像数据.
图 5
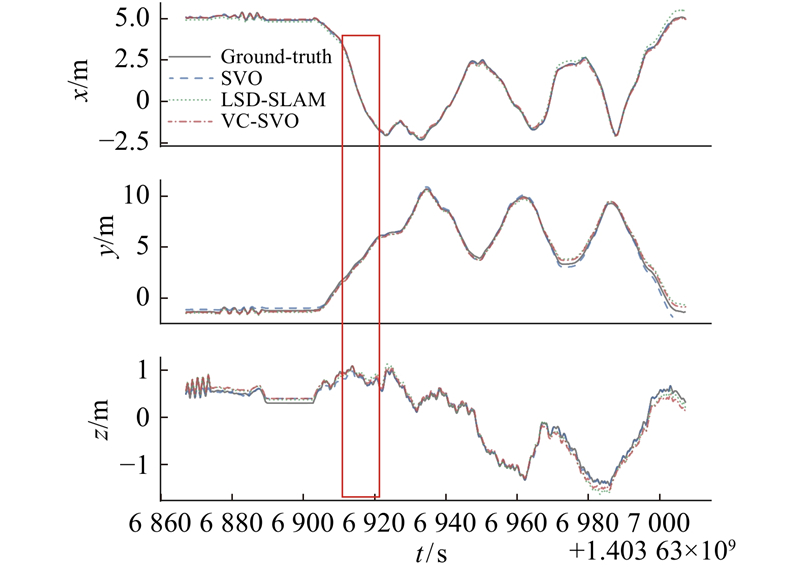
图 6
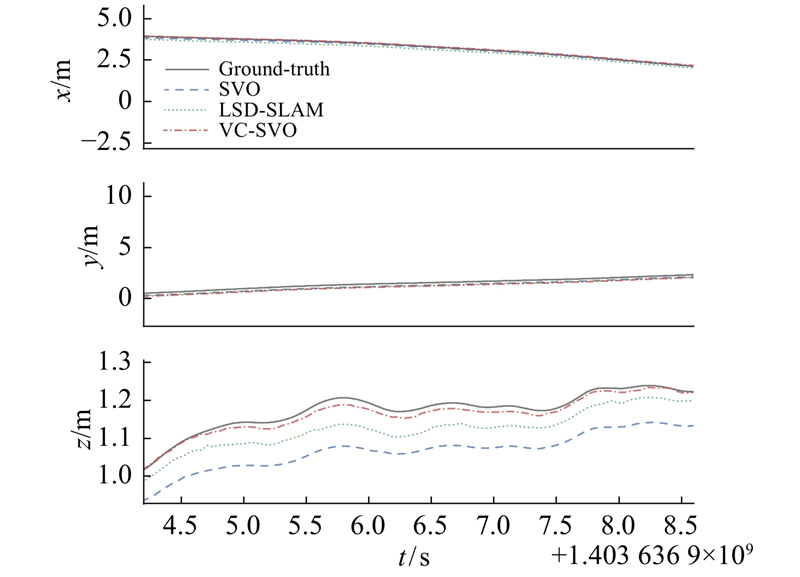
如表3所示为各算法的误差,其中,误差的衡量标准为均方根误差(root mean square error,RESM)和误差的中位数(median,M). 可以看出,在满足灰度不变假设的情况下,本研究的算法VC-SVO在定位准确度上要优于改进后的SVO和LSD-SLAM. 在MH_02图像序列上,VC-SVO与SVO算法相比,均方根误差减小了9.56%,误差中位数减小了3.65%;与LSD-SLAM算法相比,均方根误差减小了6.52%,误差中位数减小了1.36%.
表 3 MH_02序列下各算法误差
Tab.3
| 算法 | RMSE/ms−1 | M/ms−1 |
| SVO | 0.0285990 | 0.0238094 |
| LSD-SLAM | 0.0275552 | 0.0232427 |
| VC-SVO | 0.0258653 | 0.0229387 |
图 7
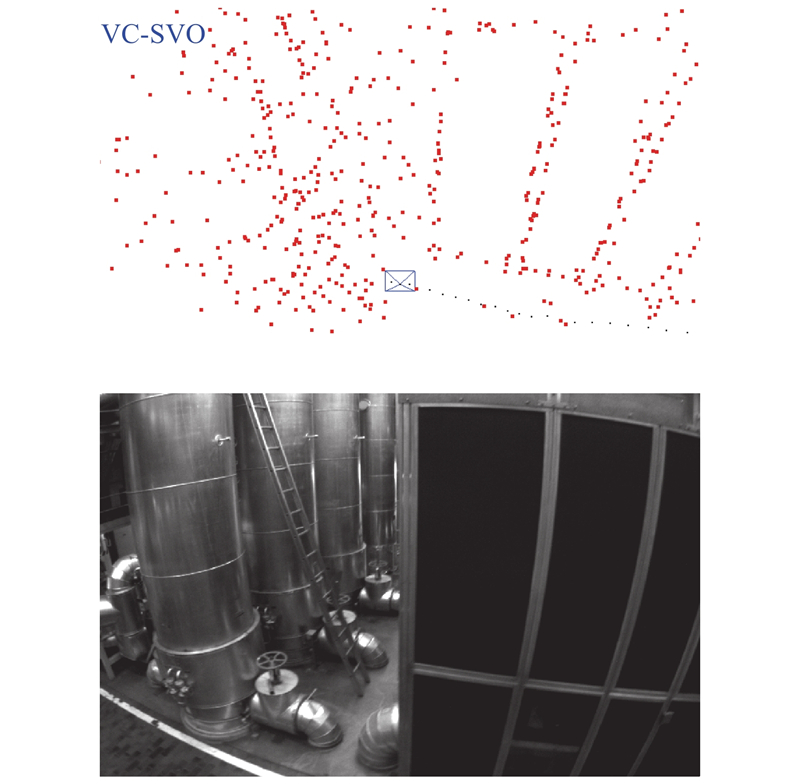
图 8

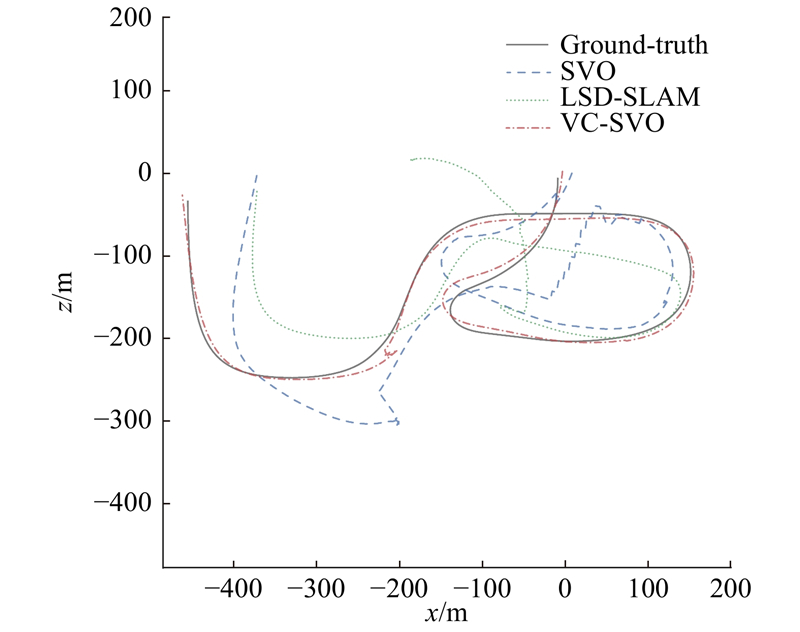
使用MH_03序列来验证算法在光照变化场景下的可行性与准确性. 如图9所示为在MH_03图像序列下的轨迹图,并与LSD-SLAM、SVO进行轨迹比较.可以看出,由于不满足BCA假设,SVO算法在刚开始就定位失败,x、y、z方向上的位姿没有任何变化. 如图10所示为MH_03序列局部放大图. 可以看出,LSD-SLAM算法在不满足灰度不变假设的情况下,只有最开始的位姿估计,之后算法停止,没有位姿输出,算法定位失败. 本研究所提出的算法VC-SVO在不满足灰度不变假设的情况下成功估计了相机的位姿,但在图9的第2个框中,VC-SVO算法发生了丢失现象. 丢失的原因是MH_03图像序列除了有场景的明暗变化,还存在完全的黑暗状况,如图11所示. 场景的完全黑暗导致算法出现跟踪丢失.但在离开黑暗环境后,改进后的重定位方法使得VC-SVO重定位成功,构建了具有全局一致性的稀疏环境地图.
图 9
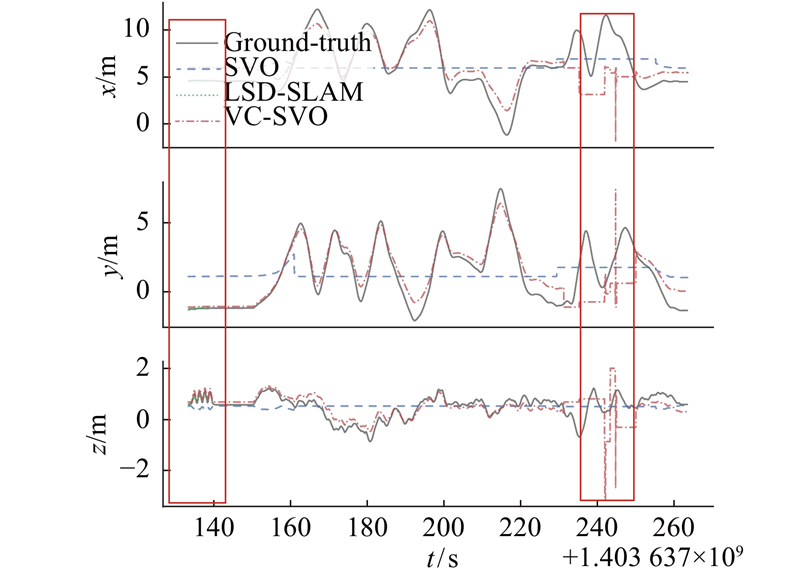
图 10
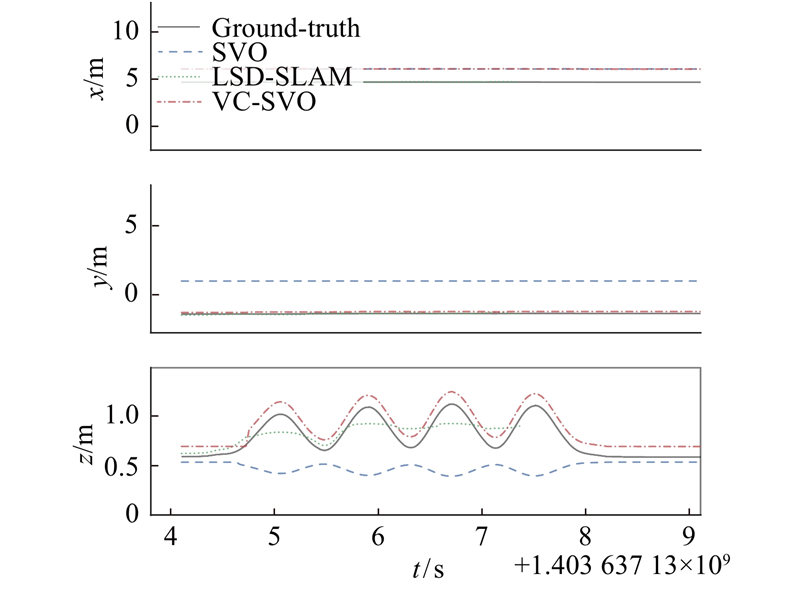
图 11

3.2. New Tsukuba Stereo数据集
New Tsukuba Stereo数据集是日本筑波大学使用计算机图形技术生成的模拟的室内场景数据集,同时也给出了摄像机在每帧上的三维位置和方向,可以对计算结果进行评估. New Tsukuba Stereo数据集提供了双目图像以及对应的视差图,本实验仅使用其中的单目数据.
图 12

图 12 daylight序列中的光照增强场景
Fig.12 Illumination enhancement scene in daylight sequence
图 13
如表4所示为各算法估计位姿与真实位姿之间欧氏距离的误差.可以看出,VC-SVO算法在不满足灰度不变假设的情况下依旧有效,并且VC-SVO的均方根误差比SVO和LSD-SLAM分别减少了56.76%和48.04%,误差中位数分别减小了46.65%与48.88%,VC-SVO的定位精度明显优于SVO与LSD-SLAM.
表 4 daylight序列下各算法误差
Tab.4
| 算法 | RMSE/ms−1 | M/ms−1 |
| SVO | 4.06884 | 2.21581 |
| LSD-SLAM | 3.38588 | 2.31256 |
| VC-SVO | 1.75917 | 1.18218 |
3.3. TUM数据集
TUM数据集是德国慕尼黑工业大学提供的公开数据集,包含多个室内与室外的场景,包括RGB-D数据集与单目数据集,每个数据集均提供了相机真实位姿,用于评估视觉里程计与视觉SLAM的精度.
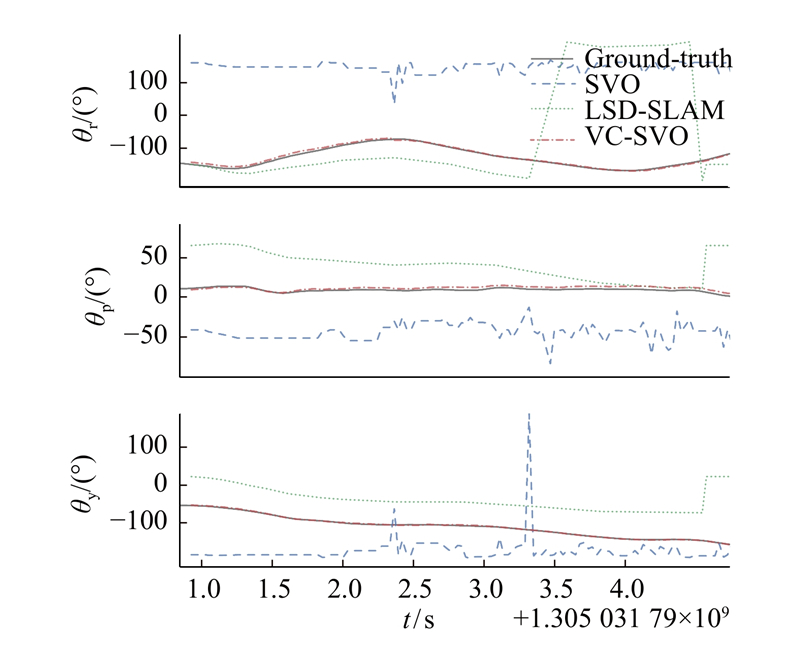
使用fr1/360图像序列进行对比实验,这是一个手持相机的图像序列,由于手持相机的缘故,图像较为模糊,此外也存在场景的亮暗变化,如图14所示.场景的光照条件变化导致图像产生整体明显的亮暗变化. 如图15、16所示为在fr1/360图像序列下的旋转轨迹对比图和局部放大图. 图中,θr、θp、θy分别为俯仰角、偏航角、翻滚角. 由图16可以看出,由于不满足BCA假设,SVO算法在刚开始就定位失败,θr、θp与θy的估计出现了严重的错误. LSD-SLAM算法在初始化之后就定位失败,之后算法停止,旋转角度没有任何变化. 而VC-SVO则较为准确地估计出相机位姿. 对比实验说明VC-SVO在满足灰度不变假设的情况下,定位精度高于SVO与LSD-SLAM算法,验证了算法的定位精度;在不满足灰度不变假设的情况下,VC-SVO仍能成功地估计相机的位姿,验证了本研究算法的有效性.
图 14

图 15
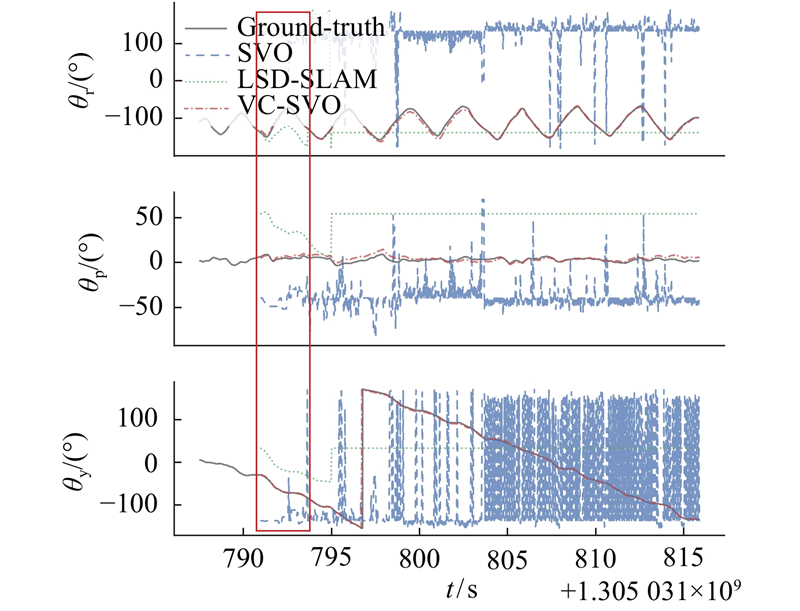
图 15 fr1/360序列旋转轨迹对比
Fig.15 Comparison of rotation trajectory of fr1/360 sequence
图 16
4. 结 语
针对直接法在光照变化情况下的算法失效问题,设计了融合改进Census变换的单目视觉里程计,向量Census变换单目里程计(VC-SVO). 使用可以减少光照变化影响的Census变换来代替图像原来的灰度,并对Census变换进行改进,使其成功地在非线性优化中使用. 同时推导了融合Census变换后的数据关联算法、状态更新模型,使用均匀-高斯混合分布的逆深度滤波器对地图点进行优化,完成了位姿估计与地图构建.
在公开数据集EuRoC、New Tsukuba Stereo以及TUM上的实验表明,融合Census变换的单目视觉里程计(VC-SVO)在满足灰度不变假设情况下,相对位姿误差的均方根比SVO算法和LSD-SLAM算法分别减少9.56%和6.52%;在有光照变化的情况下,相对位姿误差的均方根比SVO算法和LSD-SLAM算法分别减少56.76%和48.04%;在光照明显变化的场景下,VC-SVO成功估计了相机的位姿,而SVO与LSD-SLAM则发生了算法失败,证明了本研究算法的有效性与准确性.
尽管本研究算法在光照变化场景下有较好的表现,但仍然出现了在黑暗场景下失效的问题,可以在融合惯性测量单元等其他传感器信息和融合点特征、线特征与面特征,这两方面进行改进,以获得精度和鲁棒性更高的单目视觉里程计.
参考文献
On the representation and estimation of spatial uncertainty
[J].DOI:10.1177/027836498600500404 [本文引用: 1]
基于单目视觉的同时定位与地图构建算法综述
[J].
Overview of simultaneous localization and mapping algorithms based on monocular camera
[J].
3D mapping with an RGB-D camera
[J].
ORB-SLAM: a versatile and accurate monocular SLAM system
[J].DOI:10.1109/TRO.2015.2463671 [本文引用: 1]
Distinctive image features from scale-invariant keypoints
[J].DOI:10.1023/B:VISI.0000029664.99615.94 [本文引用: 1]
Direct sparse odometry
[J].DOI:10.1109/TPAMI.2017.2658577 [本文引用: 1]
ORB-SLAM2: an open-source SLAM system for monocular, stereo, and RGB-D cameras
[J].DOI:10.1109/TRO.2017.2705103 [本文引用: 1]
The EuRoC micro aerial vehicle datasets
[J].DOI:10.1177/0278364915620033 [本文引用: 1]
A comparative study of texture measures with classification based on featured distributions
[J].DOI:10.1016/0031-3203(95)00067-4 [本文引用: 1]
Lucas Kanade 20 years on: a unifying framework
[J].DOI:10.1023/B:VISI.0000011205.11775.fd [本文引用: 2]
Faster and better: a machine learning approach to corner detection
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}