|
|
|
| Image generation for power personnel behaviors based on diffusion model with multimodal prompts |
Zhihang ZHU1( ),Yunfeng YAN1,2,Donglian QI1,2,*() ),Yunfeng YAN1,2,Donglian QI1,2,*() |
1. College of Electrical Engineering, Zhejiang University, Hangzhou 310027, China
2. Hainan Institute of Zhejiang University, Sanya 572025, China |
|
|
|
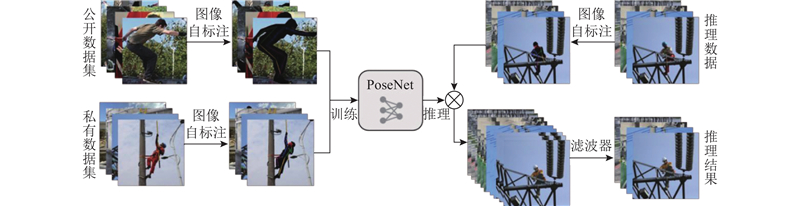
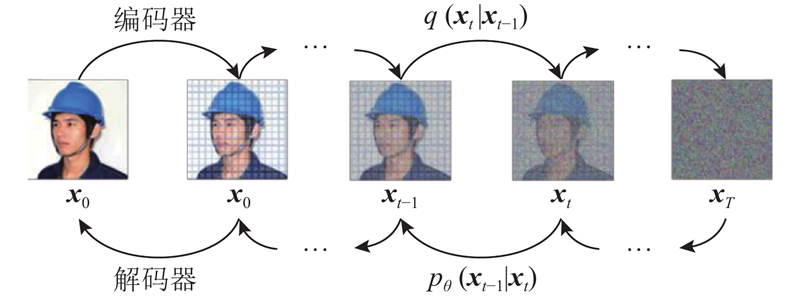
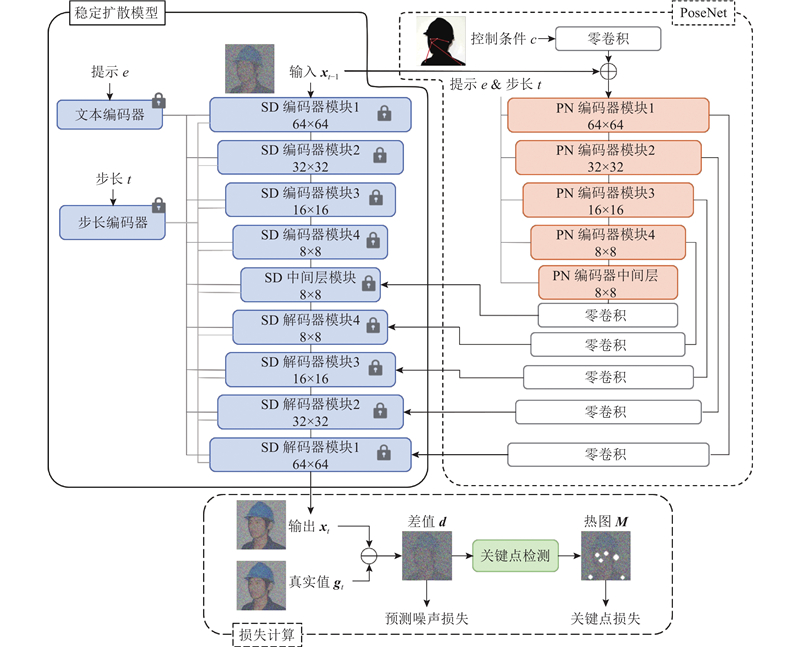
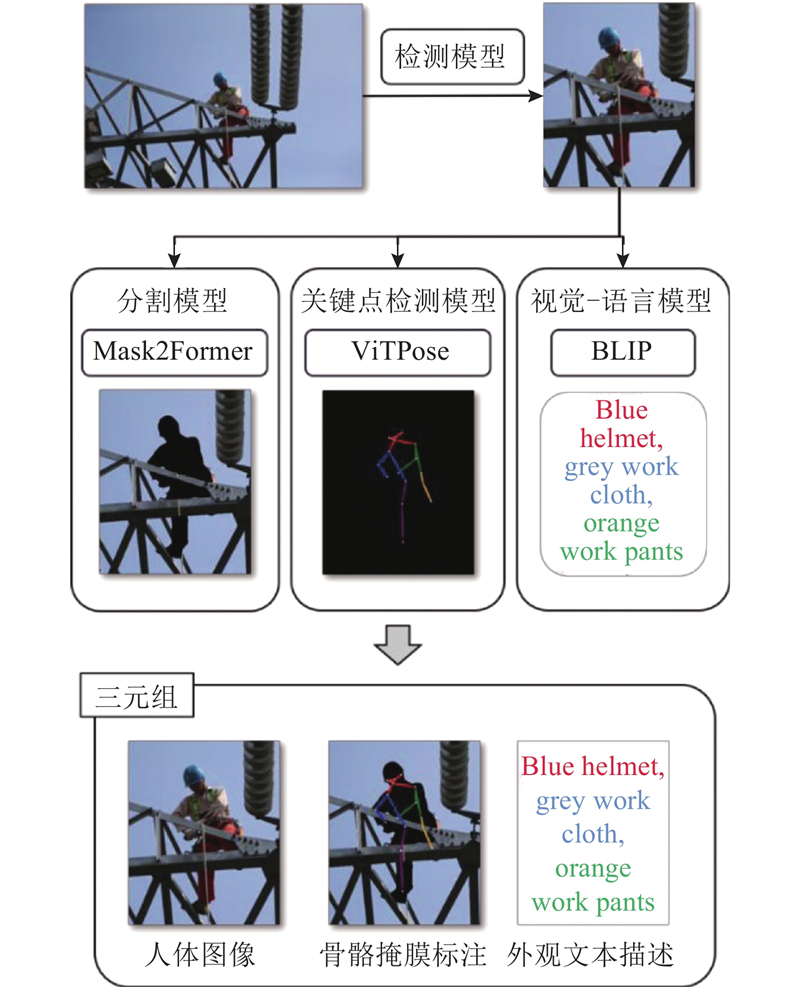
Abstract A multimodal conditional-control image generation model PoseNet for power personnel behaviors was established to address the challenges posed to data-driven behavior identification due to the scarcity of image data caused by the unique and complex nature of power personnel behaviors. On the basis of the stable diffusion model, the human skeleton, mask and text description information were fully integrated, and the key point loss function was added to the model, enabling the model to generate high-quality and controllable human body images. An image filter based on the similarity of the key points was designed to remove the erroneous and low-quality generated images, and the two-stage training strategy was used to pre-train the model on the generic data and fine-tune the model on the private data to improve the model performance. For the behavioral characteristics of the power personnel, a set of evaluation metrics for generating images integrating the generic and specialized evaluation metrics was designed, and the image generation performance under different evaluation metrics was analyzed. The experimental results showed that compared with the mainstream human generation models ControlNet and HumanSD, this model achieved more accurate, realistic and superior results.
|
|
Received: 17 December 2024
Published: 15 December 2025
|
|
|
|
Corresponding Authors:
Donglian QI
E-mail: 22210044@zju.edu.cn;qidl@zju.edu.cn
|
基于扩散模型多模态提示的电力人员行为图像生成
电力人员行为的特殊性与复杂性导致其图像数据稀缺,给数据驱动下的行为识别带来了挑战. 在稳定扩散模型的基础上,充分融合人体骨架、掩膜以及文本描述信息,加入关键点损失函数,建立多模态条件控制的电力人员行为图像生成模型PoseNet,该模型可以生成高质量的可控人体图像. 设计基于关键点相似度的图像滤波器,以去除错误、低质量的生成图像;采用双阶段训练策略,在通用数据上对模型进行预训练,并在私有数据上微调,提升模型性能;针对电力人员行为特点,设计集通用、专用评价指标于一体的生成图像评价指标集,分析不同评价指标下的图像生成效果. 实验结果表明,与主流人体生成模型ControlNet、HumanSD相比,该模型的生成结果更精准、真实、效果更优.
关键词:
条件图像生成模型,
数据扩充,
人体关键点,
图像分割,
扩散模型,
深度学习
|
|
| [1] |
王刘旺 机器视觉技术在电力安全监控中的应用综述[J]. 浙江电力, 2022, 41 (10): 16- 26
WANG Liuwang A review of the application of machine vision in power safety monitoring[J]. Zhejiang Electric Power, 2022, 41 (10): 16- 26
|
|
|
| [2] |
赵振兵, 张薇, 翟永杰, 等. 电力视觉技术的概念、研究现状与展望[J]. 电力科学与工程, 2020, 36(1): 1–8.
ZHAO Zhenbing, ZHANG Wei, ZHAI Yongjie, et al. Concept, research status and prospect of electric power vision technology [J]. Electric Power Science and Engineering, 2020, 36(1): 1–8.
|
|
|
| [3] |
齐冬莲, 韩译锋, 周自强, 等 基于视频图像的输变电设备外部缺陷检测技术及其应用现状[J]. 电子与信息学报, 2022, 44 (11): 3709- 3720
QI Donglian, HAN Yifeng, ZHOU Ziqiang, et al Review of defect detection technology of power equipment based on video images[J]. Journal of Electronics and Information Technology, 2022, 44 (11): 3709- 3720
doi: 10.11999/JEIT211588
|
|
|
| [4] |
闫云凤, 陈汐, 金浩远, 等 基于计算机视觉的电力作业人员行为分析研究现状与展望[J]. 高电压技术, 2024, 50 (5): 1842- 1854
YAN Yunfeng, CHEN Xi, JIN Haoyuan, et al Research status and development of computer-vision-based power workers’ behavior analysis[J]. High Voltage Engineering, 2024, 50 (5): 1842- 1854
|
|
|
| [5] |
陈佛计, 朱枫, 吴清潇, 等 生成对抗网络及其在图像生成中的应用研究综述[J]. 计算机学报, 2021, 44 (2): 347- 369
CHEN Foji, ZHU Feng, WU Qingxiao, et al A survey about image generation with generative adversarial nets[J]. Chinese Journal of Computers, 2021, 44 (2): 347- 369
doi: 10.11897/SP.J.1016.2021.00347
|
|
|
| [6] |
GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al Generative adversarial networks[J]. Communications of the ACM, 2020, 63 (11): 139- 144
doi: 10.1145/3422622
|
|
|
| [7] |
HO J, JAIN A, ABBEEL P. Denoising diffusion probabilistic models [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Vancouver: NeurIPS Foundation, 2020: 6840–6851.
|
|
|
| [8] |
NICHOL A, DHARIWAL P, RAMESH A, et al. GLIDE: towards photorealistic image generation and editing with text-guided diffusion models [EB/OL]. (2022−03−08) [2025−01−14]. https://arxiv.org/abs/2112.10741.
|
|
|
| [9] |
SAHARIA C, CHAN W, SAXENA S, et al. Photorealistic text-to-image diffusion models with deep language understanding [C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans: NeurIPS Foundation, 2022: 36479–36494.
|
|
|
| [10] |
张美锋, 谭翼坤, 陈世俊, 等 基于DAGAN的电气设备小样本红外图像生成技术与应用[J]. 电工技术, 2023, (6): 76- 79
ZHANG Meifeng, TAN Yikun, CHEN Shijun, et al Infrared image generation technology and application of small sample of electrical equipment based on DAGAN[J]. Electric Engineering, 2023, (6): 76- 79
|
|
|
| [11] |
何宇浩, 宋云海, 何森, 等 面向电力缺陷场景的小样本图像生成方法[J]. 浙江电力, 2024, 43 (1): 126- 132
HE Yuhao, SONG Yunhai, HE Sen, et al A few-shot image generation method for power defect scenarios[J]. Zhejiang Electric Power, 2024, 43 (1): 126- 132
|
|
|
| [12] |
杨剑锋, 秦钟, 庞小龙, 等 基于深度学习网络的输电线路异物入侵监测和识别方法[J]. 电力系统保护与控制, 2021, 49 (4): 37- 44
YANG Jianfeng, QIN Zhong, PANG Xiaolong, et al Foreign body intrusion monitoring and recognition method based on Dense-YOLOv3 deep learning network[J]. Power System Protection and Control, 2021, 49 (4): 37- 44
|
|
|
| [13] |
王德文, 李业东 基于WGAN图片去模糊的绝缘子目标检测[J]. 电力自动化设备, 2020, 40 (5): 188- 198
WANG Dewen, LI Yedong Insulator object detection based on image deblurring by WGAN[J]. Electric Power Automation Equipment, 2020, 40 (5): 188- 198
|
|
|
| [14] |
黄文琦, 许爱东, 明哲, 等 基于生成对抗网络的变电站工作人员行为预测的方法[J]. 南方电网技术, 2019, 13 (2): 45- 50
HUANG Wenqi, XU Aidong, MING Zhe, et al Prediction method for the behavior of substation staff based on generative adversarial network[J]. Southern Power System Technology, 2019, 13 (2): 45- 50
|
|
|
| [15] |
邵振国, 张承圣, 陈飞雄, 等 生成对抗网络及其在电力系统中的应用综述[J]. 中国电机工程学报, 2023, 43 (3): 987- 1004
SHAO Zhenguo, ZHANG Chengsheng, CHEN Feixiong, et al A review on generative adversarial networks for power system applications[J]. Proceedings of the CSEE, 2023, 43 (3): 987- 1004
|
|
|
| [16] |
ROMBACH R, BLATTMANN A, LORENZ D, et al. High-resolution image synthesis with latent diffusion models [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 10674–10685.
|
|
|
| [17] |
RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation [C]// Medical Image Computing and Computer-Assisted Intervention. Munich: Springer, 2015: 234–241.
|
|
|
| [18] |
ZHANG L, RAO A, AGRAWALA M. Adding conditional control to text-to-image diffusion models [C]// IEEE/CVF International Conference on Computer Vision. Paris: IEEE, 2023: 3813–3824.
|
|
|
| [19] |
MOU C, WANG X, XIE L, et al. T2I-adapter: learning adapters to dig out more controllable ability for text-to-image diffusion models [C]// AAAI Conference on Artificial Intelligence. Vancouver: AAAI, 2024: 4296–4304.
|
|
|
| [20] |
JU X, ZENG A, ZHAO C, et al. HumanSD: a native skeleton-guided diffusion model for human image generation [C]// IEEE/CVF International Conference on Computer Vision. Paris: IEEE, 2023: 15942–15952.
|
|
|
| [21] |
LIU X, REN J, SIAROHIN A, et al. HyperHuman: hyper-realistic human generation with latent structural diffusion [EB/OL]. (2024−03−15) [2025−01−14]. https://arxiv.org/abs/2310.08579.
|
|
|
| [22] |
闫政斌. 鲁棒性多姿态人体图像生成方法研究[D]. 天津: 天津工业大学, 2023.
YAN Zhengbin. Research on robust multi-pose human image generation method [D]. Tianjin: Tianjin University of Technology, 2023.
|
|
|
| [23] |
左然, 胡皓翔, 邓小明, 等 基于手绘草图的视觉内容生成深度学习方法综述[J]. 软件学报, 2024, 35 (7): 3497- 3530
ZUO Ran, HU Haoxiang, DENG Xiaoming, et al Survey on deep learning methods for freehand-sketch-based visual content generation[J]. Journal of Software, 2024, 35 (7): 3497- 3530
|
|
|
| [24] |
文渊博, 高涛, 安毅生, 等 基于视觉提示学习的天气退化图像恢复[J]. 计算机学报, 2024, 47 (10): 2401- 2416
WEN Yuanbo, GAO Tao, AN Yisheng, et al Weather-degraded image restoration based on visual prompt learning[J]. Chinese Journal of Computers, 2024, 47 (10): 2401- 2416
|
|
|
| [25] |
CORDTS M, OMRAN M, RAMOS S, et al. The cityscapes dataset for semantic urban scene understanding [C]// IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 3213–3223.
|
|
|
| [26] |
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 779–788.
|
|
|
| [27] |
CHENG B, MISRA I, SCHWING A G, et al. Masked-attention mask Transformer for universal image segmentation [C]// IEEE Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 1280–1289.
|
|
|
| [28] |
XU Y, ZHANG J, ZHANG Q, et al. Vitpose: simple vision Transformer baselines for human pose estimation [C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans: NeurIPS Foundation, 2022: 38571–38584.
|
|
|
| [29] |
LI J, LI D, XIONG C, et al. BLIP: bootstrapping language-image pre-training for unified vision-language understanding and generation [C]// International Conference on Machine Learning. Baltimore: PMLR, 2022: 12888–12900.
|
|
|
| [30] |
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [C]// European Conference on Computer Vision. Zurich: Springer, 2014: 740–755.
|
|
|
| [31] |
HEUSEL M, RAMSAUER H, UNTERTHINER T, et al. GANs trained by a two time-scale update rule converge to a local Nash equilibrium [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach: NeurIPS Foundation, 2017: 6629–6640.
|
|
|
| [32] |
BIŃKOWSKI M, SUTHERLAND D J, ARBEL M, et al. Demystifying MMD GANs [C]// International Conference on Learning Representations. Vancouver: ICLR, 2018: 1–36.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|