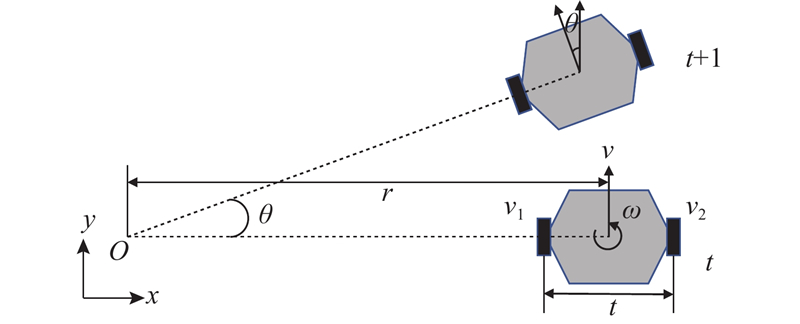
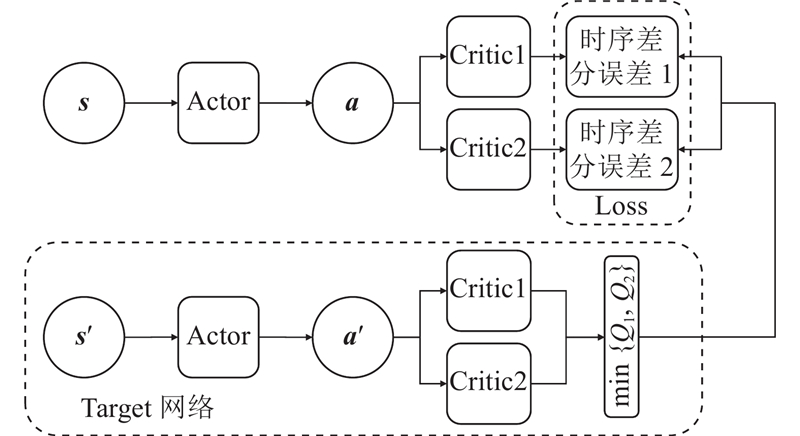
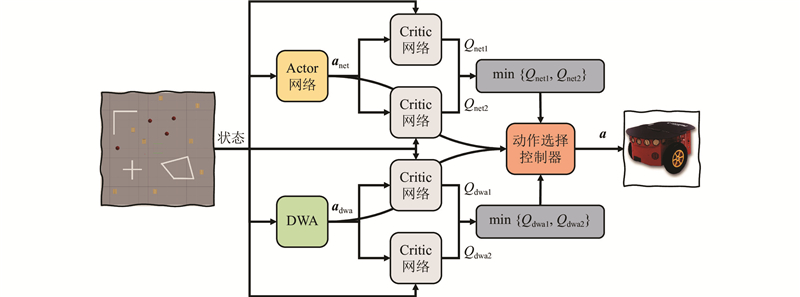
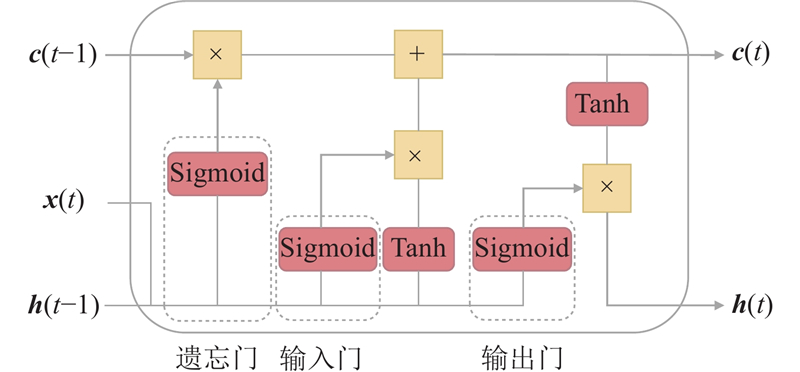
|
|
|
| TD3 mapless navigation algorithm guided by dynamic window approach |
Jiale LIU1( ),Yali XUE1,*(),Shan CUI2,Jun HONG2 ),Yali XUE1,*(),Shan CUI2,Jun HONG2 |
1. College of Automation Engineering, Nanjing University of Aeronautics and Astronautics, Nanjing 211106, China
2. Shanghai Electro-Mechanical Engineering Institute, Shanghai 201109, China |
|
|
|
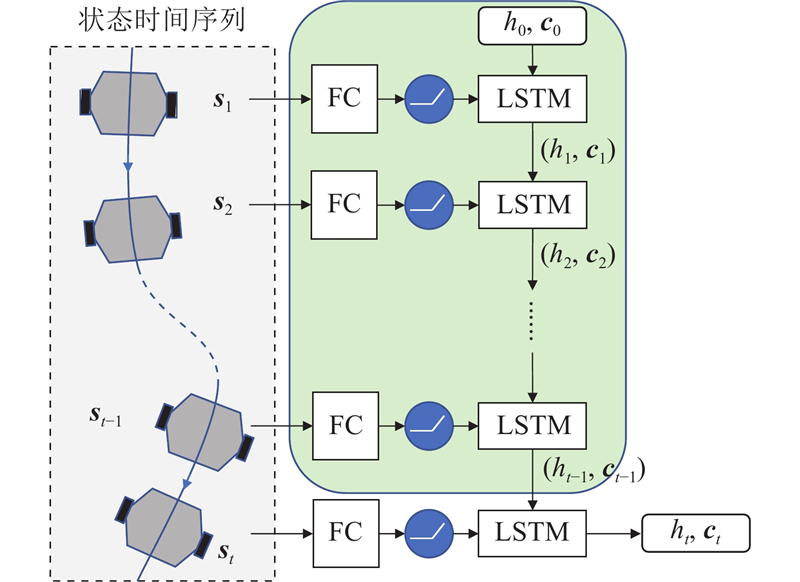
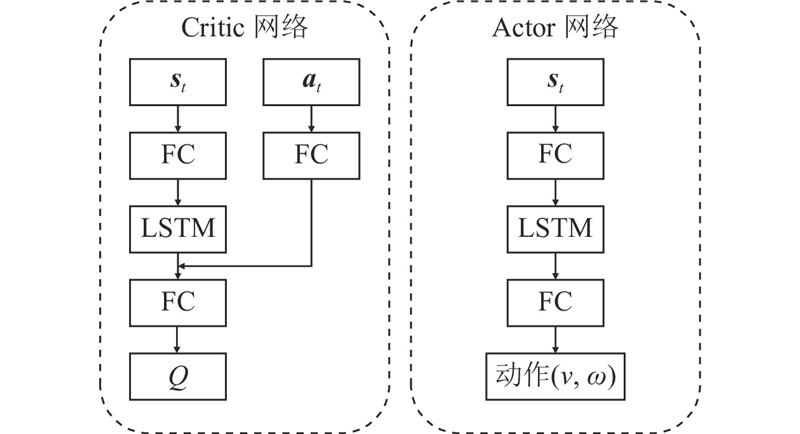
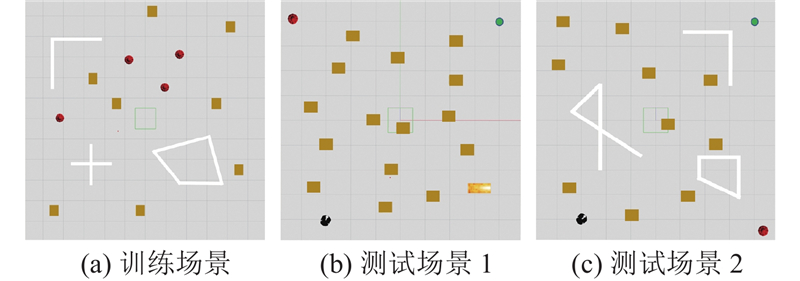
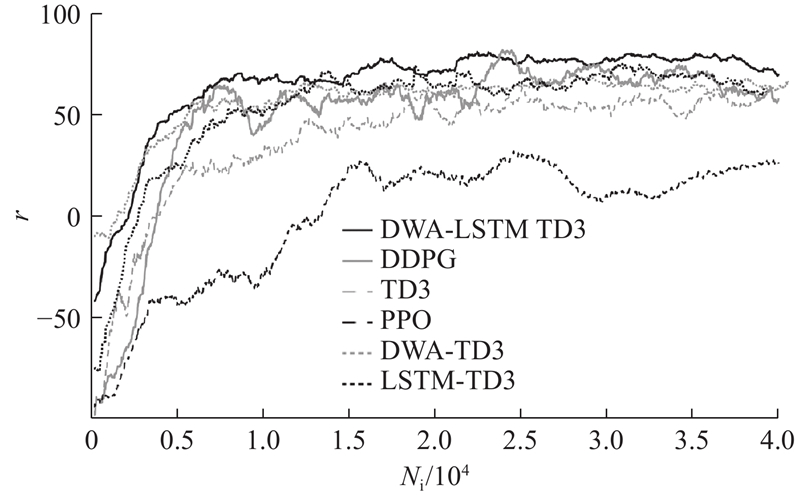
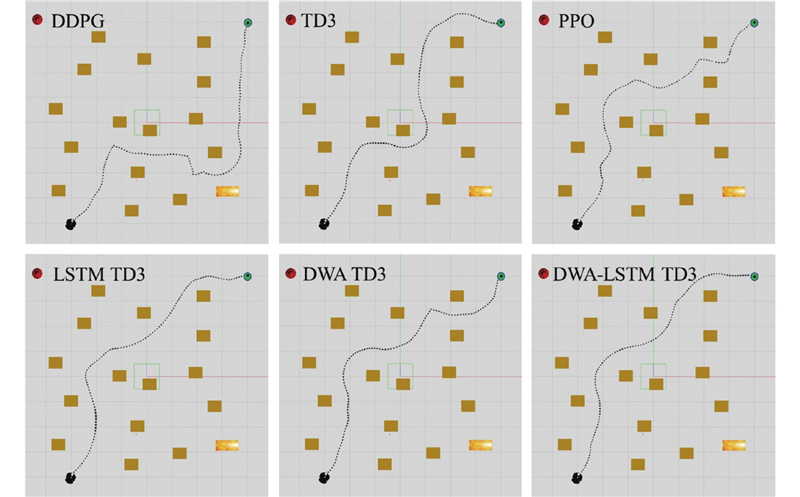
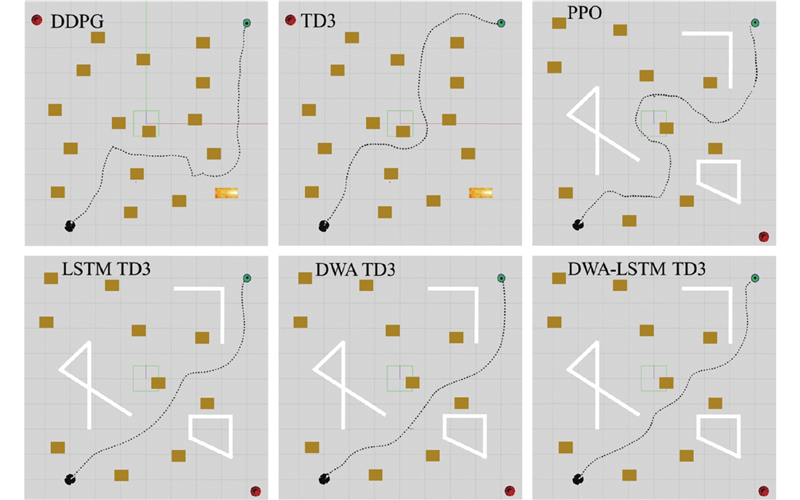
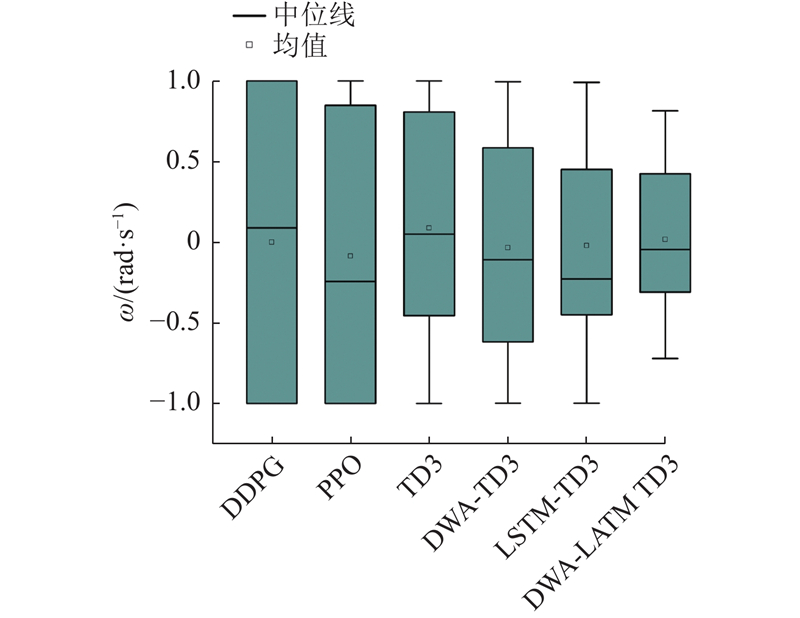
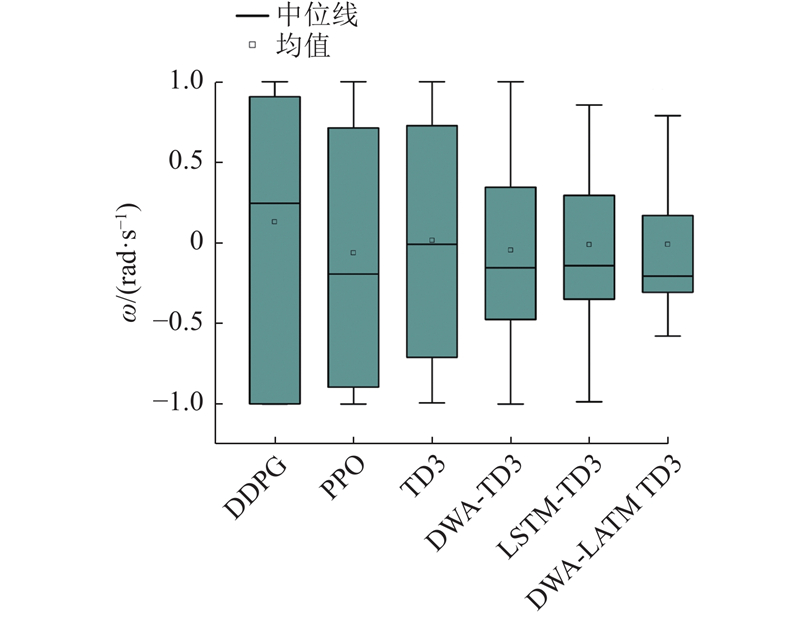
Abstract The DWA-LSTM TD3 algorithm was proposed in order to address the challenges of high data demand in deep reinforcement learning (DRL) and insufficient utilization of continuous navigation information. Robot motion was controlled based on the relative position of the target point, the robot’s own velocity, and current LiDAR data, without relying on any prior map. The dynamic window approach (DWA) was employed to guide the twin delayed deep deterministic policy gradient (TD3) algorithm during training, thereby enhancing the quality of collected training data. A long short-term memory (LSTM) neural network was integrated into the policy network in order to improve the agent’s ability to process continuous navigation information. A simulation environment was constructed for training and evaluation, and comparative experiments were conducted with other methods. The experimental results show that the DWA-LSTM TD3 algorithm achieves higher cumulative rewards and improves the success rate of navigation tasks under the same number of training steps. The fluctuation range of navigation orientation angles was reduced, smoother trajectories were produced, and the safety performance of robot motion was enhanced. The algorithm can be used to efficiently accomplish across various scenarios. The algorithm has strong generalization ability.
|
|
Received: 24 May 2024
Published: 28 July 2025
|
|
|
| Fund: 国家自然科学基金资助项目(62073164);上海市航天科技创新基金资助项目(SAST2022-013). |
|
Corresponding Authors:
Yali XUE
E-mail: liujiale@nuaa.edu.cn;xueyali@nuaa.edu.cn
|
动态窗口法引导的TD3无地图导航算法
针对深度强化学习(DRL)算法训练数据需求量大、连续导航信息利用不充分的问题,提出DWA-LSTM TD3算法. 该算法根据目标点相对位置、机器人自身速度和当前激光雷达数据控制机器人运动,过程无需先验地图. 在训练过程中,利用动态窗口法(DWA)引导双延迟确定策略梯度(TD3),提高训练数据的质量. 在策略网络中引入长短期记忆神经网络(LSTM),提升智能体对连续导航信息的处理能力. 搭建仿真环境训练测试,与其他方法进行对比. 实验结果表明,DWA-LSTM TD3在相同的训练步数下能够获得更高的奖励值,提高了导航任务的成功率;导航姿态角的波动范围变化更小,轨迹更平滑,改善机器人的运动安全性能. 利用该算法,能够在不同场景下高效完成导航任务. 该算法具有很强的泛化能力.
关键词:
无地图导航,
动态窗口法,
深度强化学习,
双延迟确定策略梯度算法,
长短期记忆
|
|
| [1] |
ZHANG H, LIN W, CHEN A Path planning for the mobile robot: a review[J]. Symmetry, 2018, 10 (10): 450
doi: 10.3390/sym10100450
|
|
|
| [2] |
SINGH R, REN J, LIN X A Review of deep reinforcement learning algorithms for mobile robot path planning[J]. Vehicles, 2023, 5 (4): 1423- 1451
doi: 10.3390/vehicles5040078
|
|
|
| [3] |
ZHU K, ZHANG T Deep reinforcement learning based mobile robot navigation: a review[J]. Tsinghua Science and Technology, 2021, 26 (5): 674- 691
doi: 10.26599/TST.2021.9010012
|
|
|
| [4] |
刘宇庭, 郭世杰, 唐术锋, 等 改进A*与ROA-DWA融合的机器人路径规划[J]. 浙江大学学报: 工学版, 2024, 58 (2): 360- 369
LIU Yuting, GUO Shijie, TANG Shufeng, et al Improved A* and ROA-DWA fusion for robot path planning[J]. Journal of Zhejiang University: Engineering Science, 2024, 58 (2): 360- 369
|
|
|
| [5] |
YAN K, MA B Mapless navigation based on 2D LIDAR in complex unknown environments[J]. Sensors, 2020, 20 (20): 5802
doi: 10.3390/s20205802
|
|
|
| [6] |
ALI M, LIU L. GP-Frontier for local mapless navigation [C]//IEEE International Conference on Robotics and Automation. London: IEEE, 2023: 10047-10053.
|
|
|
| [7] |
康振兴 基于路径规划和深度强化学习的机器人避障导航研究[J]. 计算机应用与软件, 2024, 41 (1): 297- 303
KANG Zhenxing Research on robot obstacle avoidance navigation based on path planning and deep reinforcement learning[J]. Computer Applications and Software, 2024, 41 (1): 297- 303
doi: 10.3969/j.issn.1000-386x.2024.01.043
|
|
|
| [8] |
朱威, 洪力栋, 施海东, 等. 结合优势结构和最小目标Q值的深度强化学习导航算法[J/OL]. 控制理论与应用, 2024, 41(4): 716-728 [2024-05-10]. http://kns.cnki.net/kcms/detail/44.1240.TP.20230223.1323.020.html.
ZHU Wei, HONG Lidong, SHI Haidong, et al. Deep reinforcement learning navigation algorithm combining advantage structure and minimum target Q value [J/OL]. Control Theory and Applications, 2024, 41(4): 716-728 [2024-05-10]. http://kns.cnki.net/kcms/detail/44.1240.TP.20230223.1323.020.html.
|
|
|
| [9] |
李昭莹, 欧一鸣, 石若凌 基于深度Q网络的改进RRT路径规划算法[J]. 空天防御, 2021, 4 (3): 17- 23
LI Zhaoying, OU Yiming, SHI Ruoling Improved RRT path planning algorithm based on deep Q-network[J]. Air and Space Defense, 2021, 4 (3): 17- 23
doi: 10.3969/j.issn.2096-4641.2021.03.003
|
|
|
| [10] |
WANG C, WANG J, SHEN Y, et al Autonomous navigation of UAVs in large-scale complex environments: a deep reinforcement learning approach[J]. IEEE Transactions on Vehicular Technology, 2019, 68 (3): 2124- 2136
doi: 10.1109/TVT.2018.2890773
|
|
|
| [11] |
CIMURS R, SUH I H, LEE J H Goal-driven autonomous exploration through deep reinforcement learning[J]. IEEE Robotics and Automation Letters, 2021, 7 (2): 730- 737
|
|
|
| [12] |
KONG F, WANG Q, GAO S, et al B-APFDQN: a UAV path planning algorithm based on deep Q-network and artificial potential field[J]. IEEE Access, 2023, 11: 44051- 44064
doi: 10.1109/ACCESS.2023.3273164
|
|
|
| [13] |
李永迪, 李彩虹, 张耀玉, 等 基于APF-LSTM-DDPG算法的移动机器人局部路径规划[J]. 山东理工大学学报: 自然科学版, 2024, 38 (1): 33- 41
LI Yongdi, LI Caihong, ZHANG Yaoyu, et al Local path planning for mobile robots based on APF-LSTM-DDPG algorithm[J]. Journal of Shandong University of Technology: Natural Science Edition, 2024, 38 (1): 33- 41
|
|
|
| [14] |
张凤, 顾琦然, 袁帅 好奇心蒸馏双Q网络移动机器人路径规划方法[J]. 计算机工程与应用, 2023, 59 (19): 316- 322
ZHANG Feng, GU Qiran, YUAN Shuai Path planning method for mobile robots using curiosity distilled double Q-network[J]. Computer Engineering and Applications, 2023, 59 (19): 316- 322
doi: 10.3778/j.issn.1002-8331.2208-0422
|
|
|
| [15] |
ZHANG Q, ZHANG L, MA Q, et al. The LSTM-PER-TD3 algorithm for deep reinforcement learning in continuous control tasks [C]//China Automation Congress. Chongqing: IEEE, 2023: 671-676.
|
|
|
| [16] |
TAN Y, LIN Y, LIU T, et al. PL-TD3: a dynamic path planning algorithm of mobile robot [C]//IEEE International Conference on Systems, Man, and Cybernetics. Prague: IEEE, 2022: 3040-3045.
|
|
|
| [17] |
HUANG B, XIE J, YAN J Inspection robot navigation based on improved TD3 algorithm[J]. Sensors, 2024, 24 (8): 2525
doi: 10.3390/s24082525
|
|
|
| [18] |
XIE L, WANG S, ROSA S, et al. Learning with training wheels: speeding up training with a simple controller for deep reinforcement learning [C]//IEEE International Conference on Robotics and Automation. Brisbane: IEEE, 2018: 6276-6283.
|
|
|
| [19] |
YU W, PENG J, QIU Q, et al. PathRL: an end-to-end path generation method for collision avoidance via deep reinforcement learning [C]// IEEE International Conference on Robotics and Automation. Yokohama: IEEE, 2024: 9278-9284.
|
|
|
| [20] |
户高铭, 蔡克卫, 王芳, 等 基于深度强化学习的无地图移动机器人导航[J]. 控制与决策, 2024, 39 (3): 985- 993
HU Gaoming, CAI Kewei, WANG Fang, et al Mapless navigation for mobile robots based on deep reinforcement learning[J]. Control and Decision, 2024, 39 (3): 985- 993
|
|
|
| [21] |
金毅康. 移动机器人多机探索与路径规划算法研究[D]. 西安: 西安电子科技大学, 2020.
JIN Yikang. Research on multi-robot exploration and path planning algorithms for mobile robots [D]. Xi’an: Xidian University, 2020.
|
|
|
| [22] |
罗洁, 王中训, 潘康路, 等 基于改进人工势场法的无人车路径规划算法[J]. 电子设计工程, 2022, 30 (17): 90- 94
LUO Jie, WANG Zhongxun, PAN Kanglu, et al Path planning algorithm for unmanned vehicles based on improved artificial potential field method[J]. Electronic Design Engineering, 2022, 30 (17): 90- 94
|
|
|
| [23] |
DOBREVSKI M, SKOČAJ D. Adaptive dynamic window approach for local navigation [C]//IEEE/RSJ International Conference on Intelligent Robots and Systems. Las Vegas: IEEE, 2020: 6930-6936.
|
|
|
| [24] |
DOBREVSKI M, SKOČAJ D. Dynamic adaptive dynamic window approach [J]. IEEE Transactions on Robotics, 2024, 40: 3068-3081.
|
|
|
| [25] |
ZHANG S, LI Y, DONG Q Autonomous navigation of UAV in multi-obstacle environments based on a deep reinforcement learning approach[J]. Applied Soft Computing, 2022, 115
|
|
|
| [26] |
张仪, 冯伟, 王卫军, 等 融合LSTM和PPO算法的移动机器人视觉导航[J]. 电子测量与仪器学报, 2022, 36 (8): 132- 140
ZHANG Yi, FENG Wei, WANG Weijun, et al Vision-based navigation of mobile robots integrating LSTM and PPO algorithms[J]. Journal of Electronic Measurement and Instrumentation, 2022, 36 (8): 132- 140
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|