|
|
|
| Assembly strategy for large-diameter peg-in-hole based on deep reinforcement learning |
Yu-feng JIANG( ),Dong-sheng CHEN*() ),Dong-sheng CHEN*() |
| Institute of Mechanical Manufacturing Technology, China Academy of Engineering and Physics, Mianyang 621900, China |
|
|
|
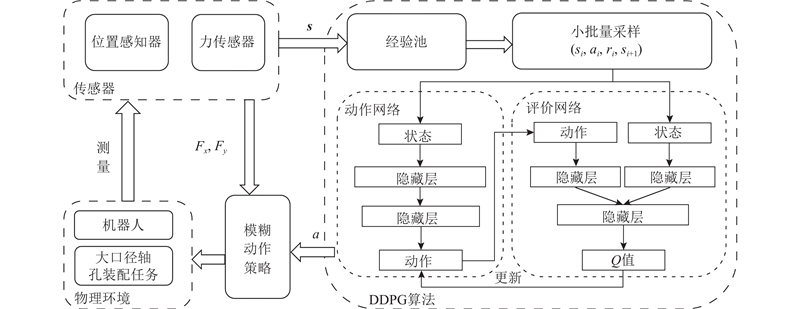
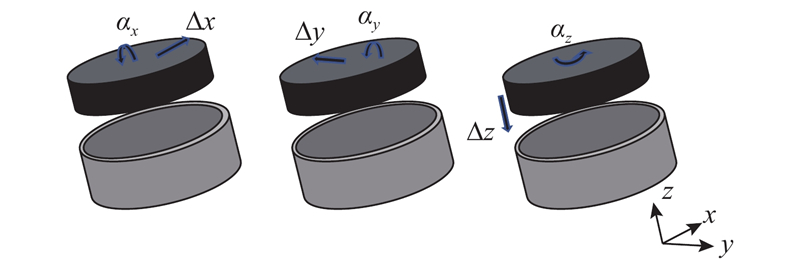
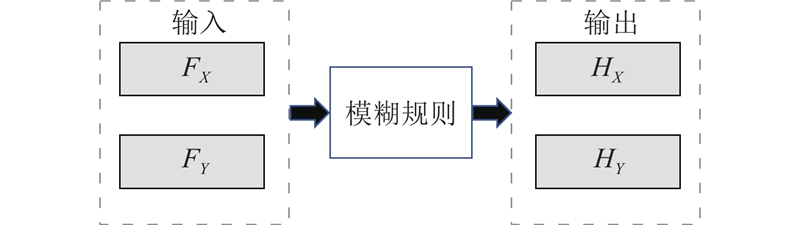
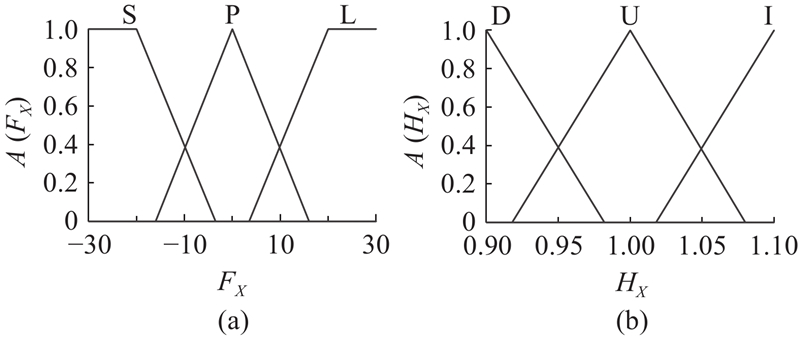
Abstract A large-diameter peg-in-hole assembly strategy based on deep reinforcement learning and fuzzy strategy was proposed, in order to address the problems of large inertial impact, unstable force control, and poor assembly accuracy in the large-diameter peg-in-hole assembly task. In this strategy, the assembly actions output from the reinforcement learning algorithm were compensated by a fuzzy action generator to achieve accurate state tracking. The deep deterministic policy gradient (DDPG) algorithm was used to acquire the environmental state data and calculate the output actions, by which the robot’s assembly state was changed. A fuzzy action generator was introduced to combine with DDPG algorithm to generate DDPGFA assembly strategy, and the fuzzy strategy was utilized to add action coefficients to improve the accuracy of assembly actions. Based on the rational formulation of reward function and fuzzy rules, the rapid convergence of the training process was realized. System stresses were secured during e-learning by setting safety thresholds. Simulation and experimental results of large-diameter peg-in-hole assembly showed that, the DDPGFA strategy can complete the assembly in a more stable number of steps, and the offline training speed was increased by about 15% and the assembly contact force was reduced by about 30% compared with the reinforcement learning assembly strategy without fuzzy actions.
|
|
Received: 17 January 2023
Published: 11 December 2023
|
|
|
|
Corresponding Authors:
Dong-sheng CHEN
E-mail: jiangyufeng1021@163.com;13518311304@163.com
|
基于深度强化学习的大口径轴孔装配策略
针对大口径轴孔装配任务中存在的惯性冲击大、力控不稳定、装配精度差等问题,提出基于深度强化学习与模糊策略的大口径轴孔装配策略. 该策略通过模糊动作生成器对强化学习算法输出的装配动作进行补偿,实现精确的状态跟踪. 通过深度确定性决策梯度(DDPG)算法采集环境状态数据并计算输出动作,引导机器人改变装配状态. 引入模糊动作生成器,与DDPG算法结合生成DDPGFA装配策略,利用模糊策略添加动作系数,提高装配动作准确性.在合理制定奖赏函数和模糊规则的基础上,实现训练过程的快速收敛.通过设定安全阈值保证在线学习过程中系统的受力安全.大口径轴孔装配仿真和实验结果表明,与未采用模糊动作的强化学习装配策略相比,DDPGFA策略能在更稳定的步数下完成装配,且离线训练速度提升约15%,装配接触力减小约30%.
关键词:
轴孔装配,
深度强化学习,
深度确定性决策梯度(DDPG),
模糊策略,
大口径部件
|
|
| [1] |
孟明辉, 周传德, 陈礼彬, 等 工业机器人的研发及应用综述[J]. 上海交通大学学报, 2016, 50 (Suppl.1): 98- 101
MENG Ming-hui, ZHOU Chuan-de, CHEN Li-bin, et al A review of the research and development of industrial robots[J]. Journal of Shanghai Jiao Tong University, 2016, 50 (Suppl.1): 98- 101
doi: 10.16183/j.cnki.jsjtu.2016.S.025
|
|
|
| [2] |
CHERNYAKHOVSKAYA L B, SIMAKOV D A Peg-on-hole: mathematical investigation of motion of a peg and of forces of its interaction with a vertically fixed hole during their alignment with a three-point contact[J]. The International Journal of Advanced Manufacturing Technology, 2020, 170: 689- 704
|
|
|
| [3] |
吴炳龙, 曲道奎, 徐方 基于力/位混合控制的工业机器人精密轴孔装配[J]. 浙江大学学报: 工学版, 2018, 52 (2): 379- 386
WU Bing-long, QU Dao-kui, XU Fang Industrial robot high precision peg-in-hole assembly based on hybrid force/position control[J]. Journal of Zhejiang University: Engineering Science, 2018, 52 (2): 379- 386
|
|
|
| [4] |
ZHANG K, SHI M, XU J, et al Force control for a rigid dual peg-in-hole assembly[J]. Assembly Automation, 2017, 37 (2): 200- 207
doi: 10.1108/AA-09-2016-120
|
|
|
| [5] |
PAN G, JIA Q, CHEN G, et al A control method of space manipulator for peg-in-hole assembly task considering equivalent stiffness optimization[J]. Aerospace, 2021, 8 (10): 310
doi: 10.3390/aerospace8100310
|
|
|
| [6] |
BELTRAN-HERNANDEZ C C, Petit D, RAMIREZ-ALPIZAR I G, et al Variable compliance control for robotic peg-in-hole assembly: a deep-reinforcement-learning approach[J]. Applied Sciences, 2020, 10 (19): 6923
doi: 10.3390/app10196923
|
|
|
| [7] |
YANG C, ZENG C, CONG Y, et al A learning framework of adaptive manipulative skills from human to robot[J]. IEEE Transactions on Industrial Informatics, 2018, 15 (2): 1153- 1161
|
|
|
| [8] |
POLYDORDS A S, NALPANTIDIS L Survey of model-based reinforcement learning: applications on robotics[J]. Journal of Intelligent and Robotic Systems, 2017, 86 (2): 153- 173
doi: 10.1007/s10846-017-0468-y
|
|
|
| [9] |
KOBER J, BAGNELL J A, PETERS J Reinforcement learning in robotics: a survey[J]. The International Journal of Robotics Research, 2013, 32 (11): 1238- 1274
doi: 10.1177/0278364913495721
|
|
|
| [10] |
KIM D, LEE J, CHUNG W Y, et al Artificial intelligence-based optimal grasping control[J]. Sensors, 2020, 20 (21): 6390
doi: 10.3390/s20216390
|
|
|
| [11] |
MA Y, ZHU W, BENTON M G, et al Continuous control of a polymerization system with deep reinforcement learning[J]. Journal of Process Control, 2019, 75: 40- 47
doi: 10.1016/j.jprocont.2018.11.004
|
|
|
| [12] |
ARULKUMARAN K, DEISENROTH M P, BRUNDAGE M, et al Deep reinforcement learning: a brief survey[J]. IEEE Signal Processing Magazine, 2017, 34 (6): 26- 38
doi: 10.1109/MSP.2017.2743240
|
|
|
| [13] |
GARCIA J, FERNANDEZ F A comprehensive survey on safe reinforcement learning[J]. Journal of Machine Learning Research, 2015, 16 (1): 1437- 1480
|
|
|
| [14] |
KUMAR A, SHARMA R Linguistic Lyapunov reinforcement learning control for robotic manipulators[J]. Neurocomputing, 2018, 272: 84- 95
doi: 10.1016/j.neucom.2017.06.064
|
|
|
| [15] |
ZARANDI M H F, MOOSAVI S V, ZARINBAL M A fuzzy reinforcement learning algorithm for inventory control in supply chains[J]. The International Journal of Advanced Manufacturing Technology, 2013, 65 (1): 557- 569
|
|
|
| [16] |
REN T, DONG Y, WU D, et al Learning-based variable compliance control for robotic assembly[J]. Journal of Mechanisms and Robotics, 2018, 10 (6): 061008
doi: 10.1115/1.4041331
|
|
|
| [17] |
XU J, HOU Z, WANG W, et al Feedback deep deterministic policy gradient with fuzzy reward for robotic multiple peg-in-hole assembly tasks[J]. IEEE Transactions on Industrial Informatics, 2018, 15 (3): 1658- 1667
|
|
|
| [18] |
ZHANG R, LV Q, LI J, et al A reinforcement learning method for human-robot collaboration in assembly tasks[J]. Robotics and Computer-Integrated Manufacturing, 2022, 73: 102227
doi: 10.1016/j.rcim.2021.102227
|
|
|
| [19] |
MA Y, XU D, QIN F Efficient insertion control for precision assembly based on demonstration learning and reinforcement learning[J]. IEEE Transactions on Industrial Informatics, 2021, 17 (7): 4492- 4502
doi: 10.1109/TII.2020.3020065
|
|
|
| [20] |
HOU Z, LI Z, HSU C, et al Fuzzy logic-driven variable time-scale prediction-based reinforcement learning for robotic multiple peg-in-hole assembly[J]. IEEE Transactions on Automation Science and Engineering, 2020, 19 (1): 218- 229
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|