|
|
|
| Video snapshot compressive imaging reconstruction based on temporal super-resolution |
Zan CHEN( ),Ran LI,Yuanjing FENG,Yongqiang LI ),Ran LI,Yuanjing FENG,Yongqiang LI |
| College of Information Engineering, Zhejiang University of Technology, Hangzhou 310023, China |
|
|
|
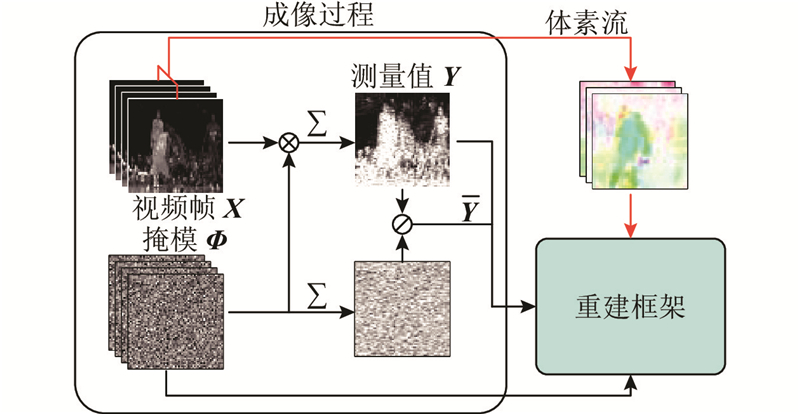
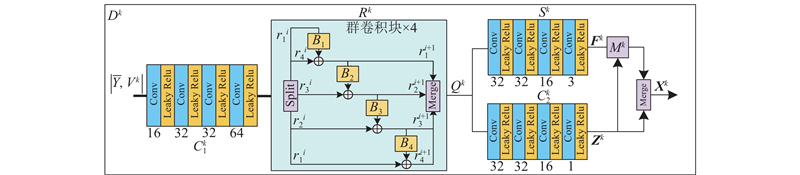
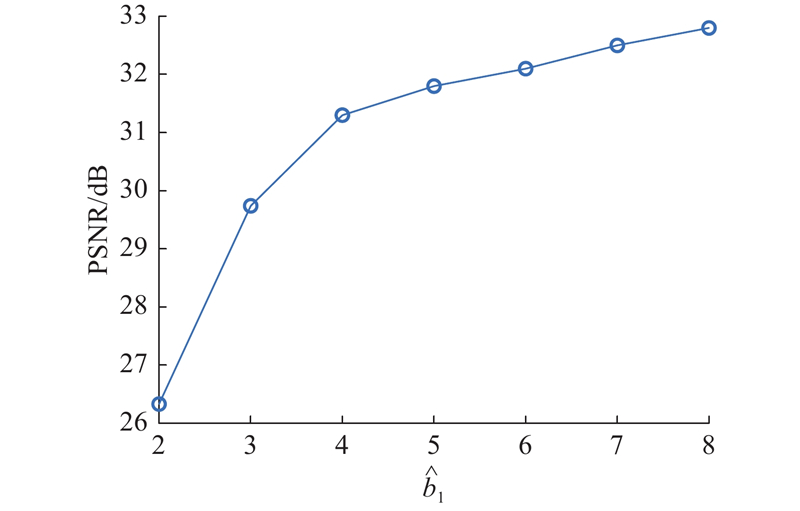
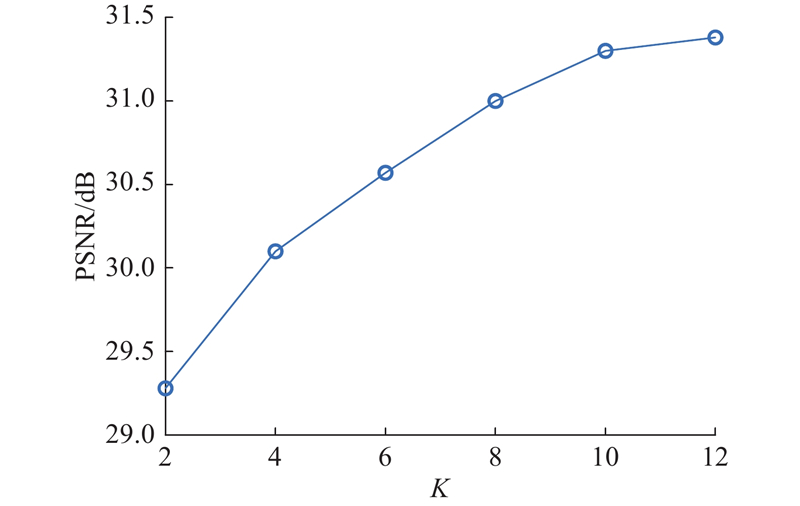
Abstract A voxel flow-based deep unfolding reconstruction framework was proposed to perform time-dimensional super-resolution on the reconstructed video frames aiming at the problems of high reconstruction hardware burden and poor reconstruction quality of video snapshot compressed imaging (SCI) due to small compressive sampling rate. A deep denoising network was proposed based on optimized iteration to iteratively reconstruct the initial frames. The video features of the denoising network were converted into voxel flow features in order to estimate the voxel information. A motion regularizer was constructed based on voxel streams in order to compute time-dimensional super-resolved frames by using voxels from the original frames. Group convolution was combined in the model to fuse the voxel stream information at different stages to reduce the loss of motion information. The experimental results showed that the average reconstructed peak signal-to-noise ratio on the benchmark dataset was improved by 0.23 dB compared to the comparison method, and the visual quality of reconstructed frames was higher. The compressive sampling rate of the video SCI system can be significantly reduced with the same frame rate of the reconstructed video by using the proposed method in order to maintain high quality reconstruction results.
|
|
Received: 09 April 2024
Published: 25 April 2025
|
|
|
| Fund: 国家自然科学基金资助项目(62002327);浙江省自然科学基金资助项目(LQ21F020017). |
基于时间维超分辨率的视频快照压缩成像重构
针对视频快照压缩成像(SCI)因压缩采样率较小所导致的重构硬件负担高、重构质量差的问题,提出基于体素流的深度展开式重构框架,对重构视频进行时间维度超分. 基于优化迭代提出深度去噪网络,对初始帧进行迭代重构. 将去噪网络的视频特征转换为体素流特征,以估计体素信息. 基于体素流构造运动正则化器,使用原始帧的体素计算时间维超分辨的帧. 在模型中结合群卷积,融合不同阶段的体素流信息,减少运动信息损失. 实验结果表明,在基准数据集上的平均重构峰值信噪比相较于对比方法提高了0.23 dB,重构帧视觉质量更高. 在重构视频帧率相同的情况下,利用提出的方法能够显著降低视频SCI系统的压缩采样率,保持高质量的重构结果.
关键词:
快照压缩成像,
压缩感知,
体素流,
深度学习,
超分辨率
|
|
| [1] |
CHEN Z, GUO W, FENG Y, et al Deep-learned regularization and proximal operator for image compressive sensing[J]. IEEE Transactions on Image Processing, 2021, 30: 7112- 7126
|
|
|
| [2] |
QIAO M, LIU X, YUAN X Snapshot spatial–temporal compressive imaging[J]. Optics Letters, 2020, 45 (7): 1659- 1662
doi: 10.1364/OL.386238
|
|
|
| [3] |
LU R, CHEN B, LIU G, et al Dual-view snapshot compressive imaging via optical flow aided recurrent neural network[J]. International Journal of Computer Vision, 2021, 129 (12): 3279- 3298
doi: 10.1007/s11263-021-01532-1
|
|
|
| [4] |
LLULL P, LIAO X, YUAN X, et al Coded aperture compressive temporal imaging[J]. Optics Express, 2013, 21 (9): 10526- 10545
doi: 10.1364/OE.21.010526
|
|
|
| [5] |
YUAN X, BRADY D, KATSAGGELOS A Snapshot compressive imaging: theory, algorithms, and applications[J]. IEEE Signal Processing Magazine, 2021, 38 (2): 65- 88
doi: 10.1109/MSP.2020.3023869
|
|
|
| [6] |
SUN Y, YUAN X, PANG S Compressive high-speed stereo imaging[J]. Optics Express, 2017, 25 (15): 18182- 18190
doi: 10.1364/OE.25.018182
|
|
|
| [7] |
ZHANG Z, DENG C, LIU Y, et al Ten-mega-pixel snapshot compressive imaging with a hybrid coded aperture[J]. Photonics Research, 2021, 9 (11): 2277- 2287
doi: 10.1364/PRJ.435256
|
|
|
| [8] |
ZHAN C, HU H, SUI X, et al Joint resource allocation and 3D aerial trajectory design for video streaming in UAV communication systems[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2020, 31 (8): 3227- 3241
|
|
|
| [9] |
LIN F, FU C, HE Y, et al Learning temporary block-based bidirectional incongruity-aware correlation filters for efficient UAV object tracking[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2020, 31 (6): 2160- 2174
|
|
|
| [10] |
LIU Y, YUAN X, SUO J, et al Rank minimization for snapshot compressive imaging[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 41 (12): 2990- 3006
|
|
|
| [11] |
YUAN X, LIU Y, SUO J, et al. Plug-and-play algorithms for large-scale snapshot compressive imaging [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 1447-1457.
|
|
|
| [12] |
YUAN X, LIU Y, SUO J, et al Plug-and-play algorithms for video snapshot compressive imaging[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 44 (10): 7093- 7111
|
|
|
| [13] |
YANG J, YUAN X, LIAO X, et al Video compressive sensing using Gaussian mixture models[J]. IEEE Transactions on Image Processing, 2014, 23 (11): 4863- 4878
doi: 10.1109/TIP.2014.2344294
|
|
|
| [14] |
SHI B, WANG Y, LI D Provable general bounded denoisers for snapshot compressive imaging with convergence guarantee[J]. IEEE Transactions on Computational Imaging, 2023, 9 (2): 55- 69
|
|
|
| [15] |
SHI B, LI D, WANG Y, et al Provable deep video denoiser using spatial–temporal information for video snapshot compressive imaging: algorithm and convergence analysis[J]. Signal Processing, 2024, 214 (1): 109236
|
|
|
| [16] |
SHI B, WANG Y, LIAN Q. A trainable bounded denoiser using double tight frame network for snapshot compressive imaging [C]// IEEE International Conference on Acoustics, Speech and Signal Processing . Singapore: IEEE, 2022: 1516-1520.
|
|
|
| [17] |
QIAO M, MENG Z, MA J, et al Deep learning for video compressive sensing[J]. Apl Photonics, 2020, 5 (3): 030801
doi: 10.1063/1.5140721
|
|
|
| [18] |
CHENG Z, CHEN B, LIU G, et al. Memory-efficient network for large-scale video compressive sensing [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 16246-16255.
|
|
|
| [19] |
HAN X, WU B, SHOU Z, et al. Tensor FISTA-Net for real-time snapshot compressive imaging [C]// Proceedings of the AAAI Conference on Artificial Intelligence . New York: AAAI, 2020, 34(7): 10933-10940.
|
|
|
| [20] |
MENG Z, YUAN X, JALALI S Deep unfolding for snapshot compressive imaging[J]. International Journal of Computer Vision, 2023, 131 (11): 2933- 2958
doi: 10.1007/s11263-023-01844-4
|
|
|
| [21] |
WANG Z, ZHANG H, CHENG Z, et al. Metasci: scalable and adaptive reconstruction for video compressive sensing [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 2083-2092.
|
|
|
| [22] |
NIKLAUS S, MAI L, LIU F. Video frame interpolation via adaptive convolution [C]// IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 670-679.
|
|
|
| [23] |
LIU Z, YEH R, TANG X, et al. Video frame synthesis using deep voxel flow [C]// IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 4463-4471.
|
|
|
| [24] |
ZHANG Y, LIU X, WU B, et al. Video synthesis via transform-based tensor neural network [C]// Proceedings of the 28th ACM International Conference on Multimedia . Melbourne: ACM, 2020: 2454-2462.
|
|
|
| [25] |
KRIZHEVSKY A, SUTSKEVER I, HINTON G ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60 (6): 84- 90
doi: 10.1145/3065386
|
|
|
| [26] |
XIE S, GIRSHICK R, DOLLÁR P, et al. Aggregated residual transformations for deep neural networks [C]// IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 1492-1500.
|
|
|
| [27] |
HUANG G, LIU S, MAATEN L, et al. Condensenet: an efficient DenseNet using learned group convolutions [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 2752-2761.
|
|
|
| [28] |
MIAO Y, ZHAO X, WANG J, et al Snapshot compressive imaging using domain-factorized deep video prior[J]. IEEE Transactions on Computational Imaging, 2024, 10 (1): 93- 102
|
|
|
| [29] |
LI S, ZHENG Z, DAI W, et al. REV-AE: a learned frame set for image reconstruction [C]// IEEE International Conference on Acoustics, Speech and Signal Processing. Barcelona: IEEE, 2020: 1823-1827.
|
|
|
| [30] |
WU Z, ZHANG J, MOU C. Dense deep unfolding network with 3D-CNN prior for snapshot compressive imaging [C]// IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 4872-4881.
|
|
|
| [31] |
LI S, DAI W, ZHENG Z, et al Reversible autoencoder: a CNN-based nonlinear lifting scheme for image reconstruction[J]. IEEE Transactions on Signal Processing, 2021, 69 (5): 3117- 3131
|
|
|
| [32] |
CHEN Z, LI R, LI Y, et al. Video snapshot compressive imaging via optical flow [C]// IEEE International Conference on Multimedia and Expo . Brisbane: IEEE, 2023: 2177-2182.
|
|
|
| [33] |
WANG L, CAO M, YUAN X. Efficientsci: densely connected network with space-time factorization for large-scale video snapshot compressive imaging [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 18477-18486.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|