|
|
|
| Heterogeneous cloud-end medical dialogue federation based on bi-directional bootstrapping distillation |
Yupeng LIU( ),Minghao LIN,Jiang ZHANG,Dengju YAO ),Minghao LIN,Jiang ZHANG,Dengju YAO |
| School of Computer Science and Technology, Harbin University of Science and Technology, Harbin 150080, China |
|
|
|
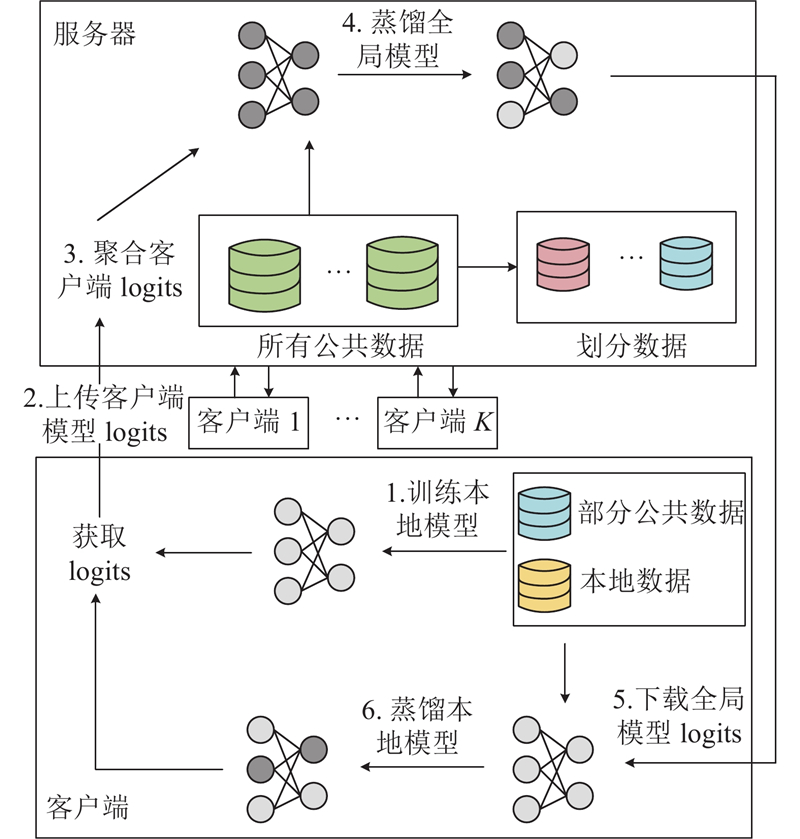
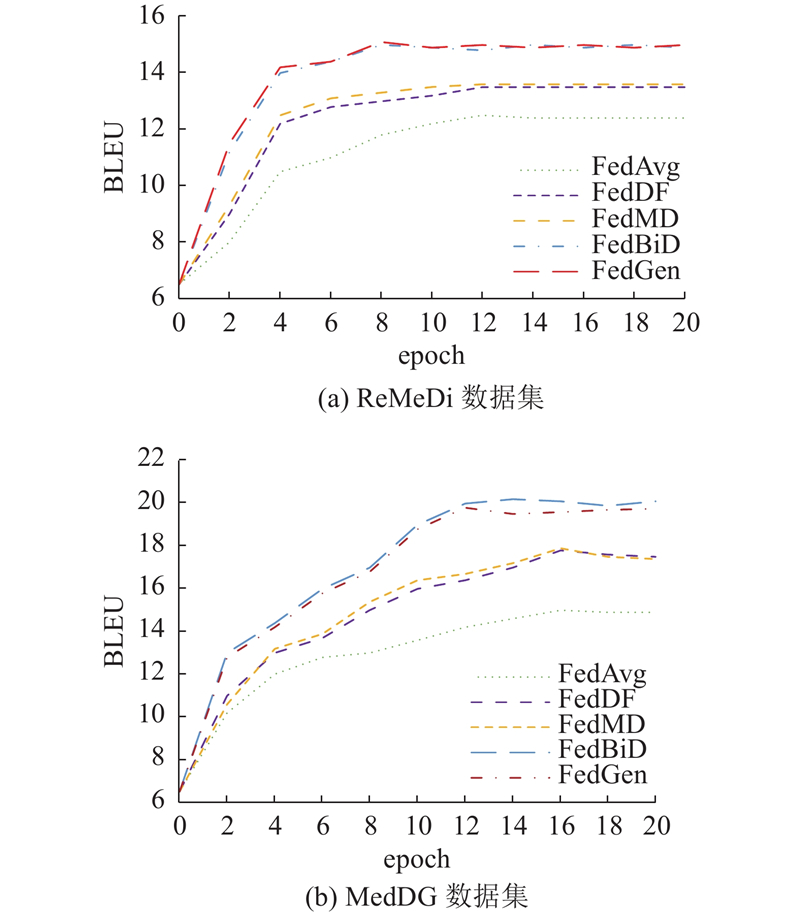
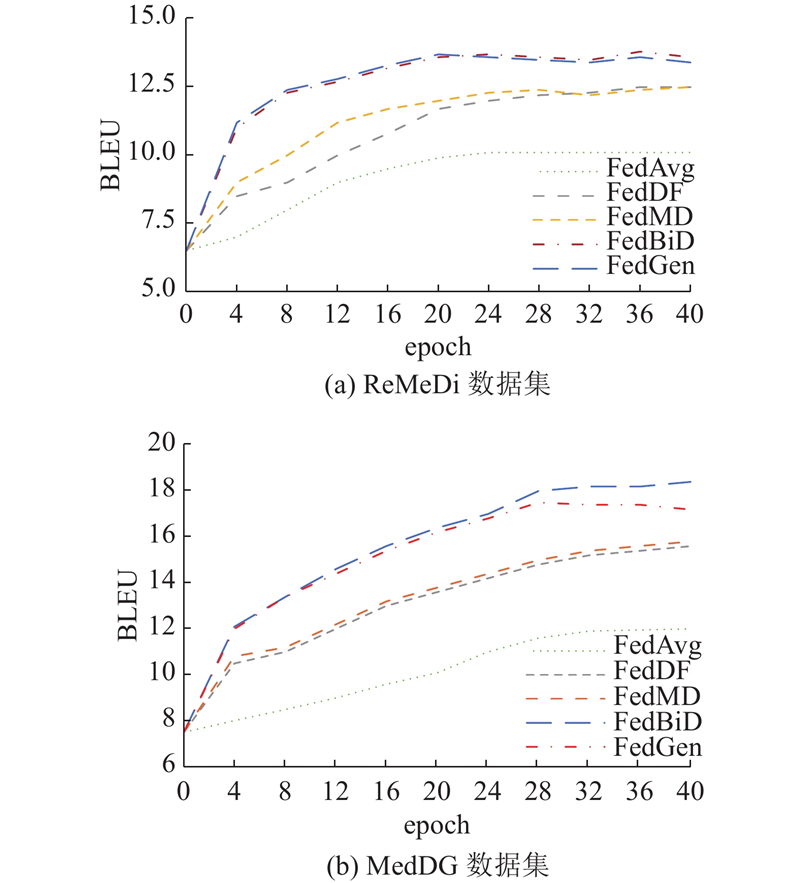
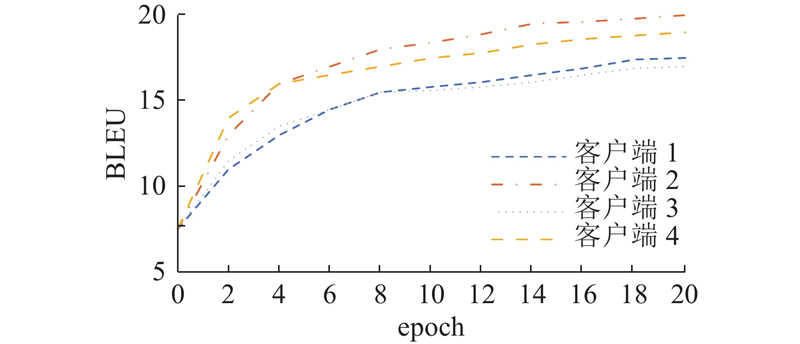
Abstract A new federated learning method was proposed in the medical dialogue scene for the heterogeneous data/models and different types of data. The cloud model and the end model transferred knowledge by mutual bootstrapping distillation. The end-to-cloud bootstrapping distillation process was a multi-teacher-single-student model, and knowledge was distilled from multiple local models to a global model. The cloud-to-end bootstrapping distillation process was a single-teacher-multi-student model, and knowledge was distilled from the global model back to multiple local models. On the medical dialogue ReMeDi and MedDG data sets, the proposed method is significantly improved compared with the classical baseline by the text generation evaluation criterion, and the training speed has also been improved.
|
|
Received: 29 July 2023
Published: 27 September 2024
|
|
|
| Fund: 国家自然科学基金资助项目(61300115, 62172128). |
基于双向自举蒸馏的异质云-端医疗对话联邦
医疗对话场景下的数据/模型异质、数据类型不同,为此提出新的联邦学习方法. 云模型和端模型以相互自举蒸馏的方式进行知识递进传递. 端到云的自举蒸馏过程为多教师-单学生模式,知识被从多个局部模型蒸馏统一到全局模型;云到端的自举蒸馏过程为单教师-多学生模式,知识被从全局模型蒸馏回多个局部模型. 在医疗对话ReMeDi和MedDG数据集上,所提方法与经典基线相比通过文本生成指标评价获得了显著提高,训练速度有所提升.
关键词:
自举蒸馏,
异质数据,
异质模型,
结构正则,
医疗对话
|
|
| [1] |
YAO A C. Protocols for secure computations [C]// Proceedings of 23rd Annual Symposium on Foundations of Computer Science . Chicago: IEEE, 1982: 160–164.
|
|
|
| [2] |
GOLDREICH O, MICALI S, WIGDERSON A. How to play any mental game [C]// Proceedings of the Nineteenth Annual ACM Symposium on Theory of Computing . New York: [s.n.], 1987: 218–229.
|
|
|
| [3] |
SHAMIR A How to share a secret[J]. Communications of the ACM, 1979, 22 (11): 612- 613
doi: 10.1145/359168.359176
|
|
|
| [4] |
KONEČNÝ J, MCMAHAN H B, RAMAGE D, et al. Federated optimization: distributed machine learning for on-device intelligence [EB/OL]. (2016−10−08) [2022−12−01]. https://arxiv.org/pdf/1610.02527.
|
|
|
| [5] |
TAN Y, LONG G, LIU L, et al. FedProto: federated prototype learning across heterogeneous clients [C]// Proceedings of the AAAI Conference on Artificial Intelligence . [S.l.]: AAAI Press, 2022: 8432−8440.
|
|
|
| [6] |
LI D, WANG J. FedMD: heterogenous federated learning via model distillation [EB/OL]. (2019−10−08)[2022−12−01]. https://arxiv.org/pdf/1910.03581.
|
|
|
| [7] |
MCMAHAN H B, MOORE E, RAMAGE D, et al. Communication-efficient learning of deep networks from decentralized data [EB/OL]. (2023−01−26) [2023−12−01]. https://arxiv.org/pdf/1602.05629.
|
|
|
| [8] |
HANZELY F, RICHTÁRIK P. Federated learning of a mixture of global and local models [EB/OL]. (2021−02−12)[2022−12−01]. https://arxiv.org/pdf/2002.05516.
|
|
|
| [9] |
HUANG L, YIN Y, FU Z, et al. LoAdaBoost: loss-based AdaBoost federated machine learning with reduced computational complexity on IID and non-IID intensive care data [J]. PLoS ONE , 2020, 15(4): e0230706.
|
|
|
| [10] |
HINTON G, VINYALS O, DEAN J. Distilling the knowledge in a neural network [EB/OL]. (2015−03−09)[2022−12−01]. https://arxiv.org/pdf/1503.02531.
|
|
|
| [11] |
FURLANELLO T, LIPTON Z C, TSCHANNEN M, et al. Born-again neural networks [EB/OL]. (2018−06−29)[2022−12−01]. https://arxiv.org/pdf/1805.04770.
|
|
|
| [12] |
KIMURA A, GHAHRAMANI Z, TAKEUCHI K, et al. Few-shot learning of neural networks from scratch by pseudo example optimization [EB/OL]. (2018−07−05)[2022−12−01]. https://arxiv.org/pdf/1802.03039.
|
|
|
| [13] |
LOPES R G, FENU S, STARNER T. Data-free knowledge distillation for deep neural networks [EB/OL]. (2017−11−23)[2022−12−01]. https://arxiv.org/pdf/1710.07535.
|
|
|
| [14] |
NAYAK G K, MOPURI K R, SHAJ V, et al. Zero-shot knowledge distillation in deep networks [EB/OL]. (2019−05−20) [2022−12−01]. https://arxiv.org/pdf/1905.08114.
|
|
|
| [15] |
CHEN H, WANG Y, XU C, et al. Data-free learning of student networks [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 3514–3522.
|
|
|
| [16] |
FANG G, SONG J, SHEN C, et al. Data-free adversarial distillation [EB/OL]. (2020−03−02) [2022−12−01]. https://arxiv.org/pdf/1912.11006.
|
|
|
| [17] |
JEONG E, OH S, KIM H, et al. Communication-efficient on-device machine learning: federated distillation and augmentation under non-IID private data [EB/OL]. (2023−10−19)[2023−12−01]. https://arxiv.org/pdf/1811.11479.
|
|
|
| [18] |
ITAHARA S, NISHIO T, KODA Y, et al Distillation-based semi-supervised federated learning for communication-efficient collaborative training with non-IID private data[J]. IEEE Transactions on Mobile Computing, 2021, 22 (1): 191- 205
|
|
|
| [19] |
LIN T, KONG L, STICH S U, et al. Ensemble distillation for robust model fusion in federated learning [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems . [S.l.]: CAI, 2020: 2351−2363.
|
|
|
| [20] |
CHANDRAKALA S, JAYALAKSHMI S L Generative model driven representation learning in a hybrid framework for environmental audio scene and sound event recognition[J]. IEEE Transactions on Multimedia, 2019, 22 (1): 3- 14
|
|
|
| [21] |
ARIVAZHAGAN M G, AGGARWAL V, SINGH A K, et al. Federated learning with personalization layers [EB/OL]. (2019−12−02) [2022−12−01]. https://arxiv.org/pdf/1912.00818.
|
|
|
| [22] |
ZHU Z, HONG J, ZHOU J. Data-free knowledge distillation for heterogeneous federated learning [EB/OL]. (2021−06−09) [2022−12−01]. https://arxiv.org/pdf/2105.10056.
|
|
|
| [23] |
RADFORD A, WU J, CHILD R, et al. Language models are unsupervised multitask learners [EB/OL]. [2022−12−01]. https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf.
|
|
|
| [24] |
YAN G, PEI J, REN P, et al. ReMeDi: resources for multi-domain, multi-service, medical dialogues [EB/OL]. (2022−03−01) [2022−12−01]. https://arxiv.org/pdf/2109.00430.
|
|
|
| [25] |
LIU W, TANG J, CHENG Y, et al. MedDG: an entity-centric medical consultation dataset for entity-aware medical dialogue generation [C]// Natural Language Processing and Chinese Computing . [S.l.]: Springer, 2022: 447−459.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|