|
|
|
| Semantic segmentation method on nighttime road scene based on Trans-nightSeg |
Canlin LI1( ),Wenjiao ZHANG1,Zhiwen SHAO2,3,Lizhuang MA3,Xinyue WANG1 ),Wenjiao ZHANG1,Zhiwen SHAO2,3,Lizhuang MA3,Xinyue WANG1 |
1. School of Computer and Communication Engineering, Zhengzhou University of Light Industry, Zhengzhou 450000, China
2. School of Computer Science and Technology, China University of Mining and Technology, Xuzhou 221116, China
3. Department of Computer Science and Engineering, Shanghai Jiao Tong University, Shanghai 200240, China |
|
|
|
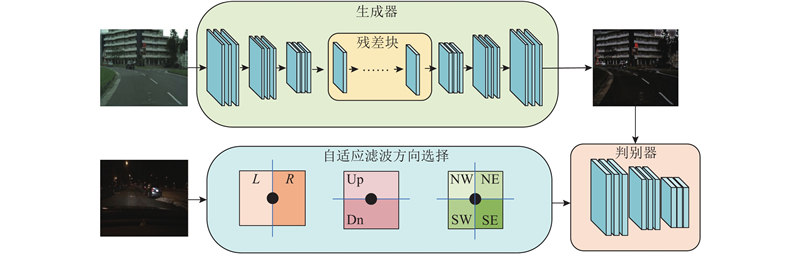
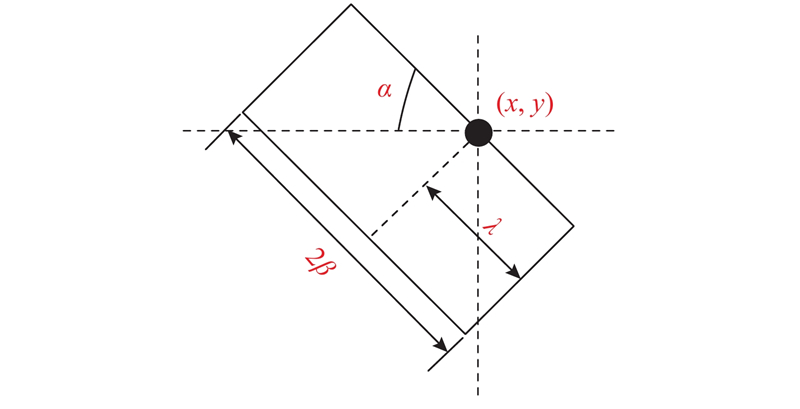
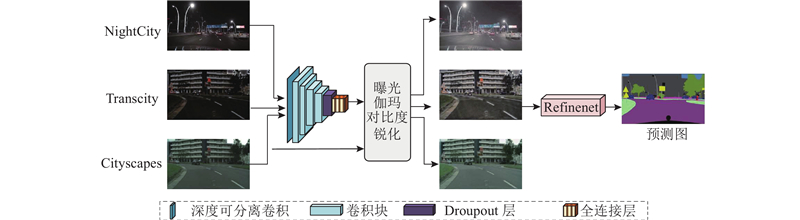
Abstract The semantic segmentation method Trans-nightSeg was proposed aiming at the issues of low brightness and lack of annotated semantic segmentation dataset in nighttime road scenes. The annotated daytime road scene semantic segmentation dataset Cityscapes was converted into low-light road scene images by TransCartoonGAN, which shared the same semantic segmentation annotation, thereby enriching the nighttime road scene dataset. The result together with the real road scene dataset was used as input of N-Refinenet. The N-Refinenet network introduced a low-light image adaptive enhancement network to improve the semantic segmentation performance of the nighttime road scene. Depth-separable convolution was used instead of normal convolution in order to reduce the computational complexity. The experimental results show that the mean intersection over union (mIoU) of the proposed algorithm on the Dark Zurich-test dataset and Nighttime Driving-test dataset reaches 56.0% and 56.6%, respectively, outperforming other semantic segmentation algorithms for nighttime road scene.
|
|
Received: 29 June 2023
Published: 23 January 2024
|
|
|
| Fund: 国家自然科学基金资助项目(61972157,62106268);河南省科技攻关项目(212102210097);上海市科技创新行动计划人工智能科技支撑项目(21511101200);江苏省“双创博士”人才资助项目(JSSCBS20211220) |
基于Trans-nightSeg的夜间道路场景语义分割方法
针对夜间道路场景图像亮度低及缺乏带标注的夜间道路场景语义分割数据集的问题,提出夜间道路场景语义分割方法Trans-nightSeg. 使用TransCartoonGAN,将带标注的白天道路场景语义分割数据集Cityscapes转换为低光条件下的道路场景图像,两者共用同一个语义分割标注,丰富夜间道路场景数据集. 将该结果和真实的道路场景数据集一并作为N-Refinenet的输入,N-Refinenet网络引入了低光图像自适应增强网络,提高夜间道路场景的语义分割性能. 该网络采用深度可分离卷积替代普通的卷积,降低了计算量. 实验结果表明,所提算法在Dark Zurich-test和Nighttime Driving-test数据集上的平均交并比(mIoU)分别达到56.0%和56.6%,优于其他的夜间道路场景语义分割算法.
关键词:
图像增强,
语义分割,
生成对抗网络(GAN),
风格转换,
道路场景
|
|
| [1] |
CORDTS M, OMRAN M, RAMOS S, et al. The Cityscapes dataset for semantic urban scene understanding [C]// IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 3213-3223.
|
|
|
| [2] |
SAKARIDIS C, DAI D, GOOL L V. ACDC: the adverse conditions dataset with correspondences for semantic driving scene understanding [C]// IEEE International Conference on Computer Vision. Montreal: IEEE, 2021: 10765-10775.
|
|
|
| [3] |
GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al Generative adversarial networks[J]. Communications of the ACM, 2020, 63 (11): 139- 144
doi: 10.1145/3422622
|
|
|
| [4] |
REED S, AKATA Z, YAN X, et al. Generative adversarial text to image synthesis [C]// International Conference on Machine Learning. New York: PMLR, 2016: 1060-1069.
|
|
|
| [5] |
YEH R, CHEN C, LIM T Y, et al. Semantic image inpainting with perceptual and contextual losses [EB/OL]. [2016-07-26]. https://arxiv.org/abs/1607.07539.
|
|
|
| [6] |
LEDIG C, THEIS L, HUSZAR F, et al. Photo-realistic single image super-resolution using a generative adversarial network [C]// IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 4681-4690.
|
|
|
| [7] |
ISOLA P, ZHU J Y, ZHOU T, et al. Image-to-image translation with conditional adversarial networks [C]// IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 1125-1134.
|
|
|
| [8] |
KARACAN L, AKATA Z, ERDEM A, et al. Learning to generate images of outdoor scenes from attributes and semantic layouts [EB/OL]. [2016-12-01]. https://arxiv.org/abs/1612.00215.
|
|
|
| [9] |
ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks [C]// IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 2223-2232.
|
|
|
| [10] |
WANG H, CHEN Y, CAI Y, et al SFNet-N: an improved SFNet algorithm for semantic segmentation of low-light autonomous driving road scenes[J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23 (11): 21405- 21417
doi: 10.1109/TITS.2022.3177615
|
|
|
| [11] |
CHEN Y, LAI Y K, LIU Y J. Cartoongan: generative adversarial networks for photo cartoonization [C]// IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 9465-9474.
|
|
|
| [12] |
YIN H, GONG Y, QIU G. Side window filtering [C]// IEEE Conference on Computer Vision and Pattern Recognition. Los Angeles: IEEE, 2019: 8758-8766.
|
|
|
| [13] |
SHELHAMER E, LONG J, DARRELL T Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39 (4): 640- 651
doi: 10.1109/TPAMI.2016.2572683
|
|
|
| [14] |
LIN G, MILAN A, SHEN C, et al. Refinenet: multi-path refinement networks for high-resolution semantic segmentation [C]// IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 1925-1934.
|
|
|
| [15] |
BIJELIC M, GRUBER T, RITTER W. Benchmarking image sensors under adverse weather conditions for autonomous driving [C]// IEEE Intelligent Vehicles Symposium. Changshu: IEEE, 2018: 1773-1779.
|
|
|
| [16] |
WULFMEIER M, BEWLEY A, POSNER I. Addressing appearance change in outdoor robotics with adversarial domain adaptation [C] // IEEE International Conference on Intelligent Robots and Systems. Vancouver: IEEE, 2017: 1551-1558.
|
|
|
| [17] |
DAI D, GOOL L V. Dark model adaptation: semantic image segmentation from daytime to nighttime [C]// IEEE International Conference on Intelligent Transportation Systems. Hawaii: IEEE, 2018: 3819-3824.
|
|
|
| [18] |
SAKARIDIS C, DAI D, GOOL L V. Guided curriculum model adaptation and uncertainty-aware evaluation for semantic nighttime image segmentation [C]// IEEE International Conference on Computer Vision. Seoul: IEEE, 2019: 7374-7383.
|
|
|
| [19] |
SAKARIDIS C, DAI D, GOOL L V Map-guided curriculum domain adaptation and uncertainty-aware evaluation for semantic nighttime image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44 (6): 3139- 3153
doi: 10.1109/TPAMI.2020.3045882
|
|
|
| [20] |
XU Q, MA Y, WU J, et al. CDAda: a curriculum do-main adaptation for nighttime semantic segmentation[C]// IEEE International Conference on Computer Vision. Montreal: IEEE, 2021: 2962-2971.
|
|
|
| [21] |
ROMERA E, BERGASA L M, YANG K, et al. Bridging the day and night domain gap for semantic segmentation [C]// IEEE Intelligent Vehicles Symposium. Paris: IEEE, 2019: 1312-1318.
|
|
|
| [22] |
SUN L, WANG K, YANG K, et al. See clearer at night: towards robust nighttime semantic segmentation through day-night image conversion [C]// Artificial Intelligence and Machine Learning in Defense Applications. Bellingham: SPIE, 2019, 11169: 77-89.
|
|
|
| [23] |
WU X, WU Z, GUO H, et al. Dannet: a one-stage domain adaptation network for unsupervised nighttime semantic segmentation [C]// IEEE Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 15769-15778.
|
|
|
| [24] |
WU X, WU Z, JU L, et al A one-stage domain adaptation network with image alignment for unsupervised nighttime semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45 (1): 58- 72
doi: 10.1109/TPAMI.2021.3138829
|
|
|
| [25] |
HU Y, HU H, XU C, et al Exposure: a white-box photo post-processing framework[J]. ACM Transactions on Graphics, 2018, 37 (2): 26.1- 26.17
|
|
|
| [26] |
CHOLLET F. Xception: deep learning with depthwise separable convolutions [C]// IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 1251-1258.
|
|
|
| [27] |
HOWARD A G, ZHU M, CHEN B, et al. Mobilenets: efficient convolutional neural networks for mobile vis-ion applications [EB/OL]. [2017-04-17]. https://arxiv.org/abs/1704.04861.
|
|
|
| [28] |
TAN X, XU K, CAO Y, et al Nighttime scene parsing with a large real dataset[J]. IEEE Transactions on Image Processing, 2021, (30): 9085- 9098
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|