| 计算机与控制工程 |
|


|
|
|
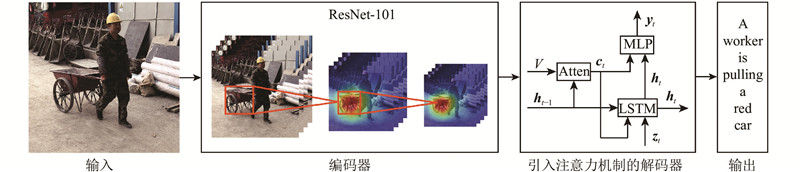
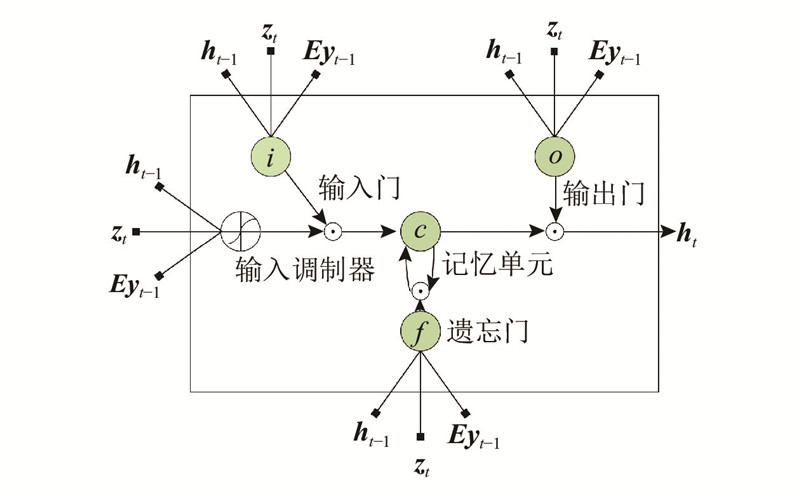
| 基于注意力机制和编码-解码架构的施工场景图像描述方法 |
农元君( ),王俊杰*(),陈红,孙文涵,耿慧,李书悦 ),王俊杰*(),陈红,孙文涵,耿慧,李书悦 |
| 中国海洋大学 工程学院,山东 青岛 266100 |
|
| A image caption method of construction scene based on attention mechanism and encoding-decoding architecture |
| Yuan-jun NONG(),Jun-jie WANG*(),Hong CHEN,Wen-han SUN,Hui GENG,Shu-yue LI |
| School of Engineering, Ocean University of China, Qingdao 266100, China |
引用本文:
农元君,王俊杰,陈红,孙文涵,耿慧,李书悦. 基于注意力机制和编码-解码架构的施工场景图像描述方法[J]. 浙江大学学报(工学版), 2022, 56(2): 236-244.
Yuan-jun NONG,Jun-jie WANG,Hong CHEN,Wen-han SUN,Hui GENG,Shu-yue LI. A image caption method of construction scene based on attention mechanism and encoding-decoding architecture. Journal of ZheJiang University (Engineering Science), 2022, 56(2): 236-244.
链接本文:
https://www.zjujournals.com/eng/CN/10.3785/j.issn.1008-973X.2022.02.003
或
https://www.zjujournals.com/eng/CN/Y2022/V56/I2/236
|
| 1 |
WU J, CAI N, CHEN W, et al Automatic detection of hardhats worn by construction personnel: a deep learning approach and benchmark dataset[J]. Automation in Construction, 2019, 106: 102894
doi: 10.1016/j.autcon.2019.102894
|
| 2 |
NATH N D, BEHZADAN A H, PAAL S G Deep learning for site safety: real-time detection of personal protective equipment[J]. Automation in Construction, 2020, 112: 103085
doi: 10.1016/j.autcon.2020.103085
|
| 3 |
GUO Y, XU Y, LI S Dense construction vehicle detection based on orientation-aware feature fusion convolutional neural network[J]. Automation in Construction, 2020, 112: 103124
doi: 10.1016/j.autcon.2020.103124
|
| 4 |
LI Y, LU Y, CHEN J A deep learning approach for real-time rebar counting on the construction site based on YOLOv3 detector[J]. Automation in Construction, 2021, 124: 103602
doi: 10.1016/j.autcon.2021.103602
|
| 5 |
徐守坤, 倪楚涵, 吉晨晨, 等 一种基于安全帽佩戴检测的图像描述方法研究[J]. 小型微型计算机系统, 2020, 41 (4): 812- 819
XU Shou-kun, NI Chu-han, JI Chen-chen, et al Research on image caption method based on safety helmet wearing detection[J]. Journal of Chinese Computer Systems, 2020, 41 (4): 812- 819
doi: 10.3969/j.issn.1000-1220.2020.04.025
|
| 6 |
BANG S, KIM H Context-based information generation for managing UAV-acquired data using image captioning[J]. Automation in Construction, 2020, 112: 103116
doi: 10.1016/j.autcon.2020.103116
|
| 7 |
LIU H, WANG G, HUANG T, et al Manifesting construction activity scenes via image captioning[J]. Automation in Construction, 2020, 119: 103334
doi: 10.1016/j.autcon.2020.103334
|
| 8 |
XU K, BA J L, KIROS R, et al. Show, attend and tell: neural image caption generation with visual attention [C]// International Conference on Machine Learning. Cambridge: MIT, 2015: 2048-2057.
|
| 9 |
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [C]// European Conference on Computer Vision. Berlin: Springer, 2014: 740-755.
|
| 10 |
HODOSH M, YOUNG P, HOCKENMAIER J Framing image description as a ranking task: data, models and evaluation metrics[J]. Journal of Artificial Intelligence Research, 2013, 47: 853- 899
doi: 10.1613/jair.3994
|
| 11 |
YOUNG P, LAI A, HODOSH M, et al From image descriptions to visual denotations: new similarity metrics for semantic inference over event descriptions[J]. Transactions of the Association for Computational Linguistics, 2014, 2: 67- 78
doi: 10.1162/tacl_a_00166
|
| 12 |
DUTTA A, ZISSERMAN A. The VIA annotation software for images, audio and video [EB/OL]. (2019-04-24)[2021-04-08]. https://arxiv.org/abs/1904.10699.
|
| 13 |
PAPINENI K, ROUKOS S, WARD T, et al. BLEU: a method for automatic evaluation of machine translation [C]// Annual Meeting on Association for Computational Linguistics. Stroudsburg: ACL, 2002: 311-318.
|
| 14 |
BANERJEE S, LAVIE A. METEOR: an automatic metric for MT evaluation with improved correlation with human judgments [C]// ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. Stroudsburg: ACL, 2005: 65-72.
|
| 15 |
LIN C Y. ROUGE: a package for automatic evaluation of summaries[C]// ACL Workshop on Text Summarization Branches Out. Stroudsburg: ACL, 2004: 74-81.
|
| 16 |
VEDANTAM R, ZITNICK C L, PARIKH D. CIDEr: consensus-based image description evaluation [C]// IEEE Conference on Computer Vision and Pattern Recognition. Los Alamitos: IEEE, 2015: 4566-4575.
|
| 17 |
VINYALS O, TOSHEV A, BENGIO S, et al. Show and tell: a neural image caption generator [C]// IEEE Conference on Computer Vision and Pattern Recognition. Los Alamitos: IEEE, 2015: 3156-3164.
|
| 18 |
LU J, XIONG C, PARIKH D, et al. Knowing when to look: adaptive attention via a visual sentinel for image captioning [C]// IEEE Conference on Computer Vision and Pattern Recognition. Los Alamitos: IEEE, 2017: 3242-3250.
|
| 19 |
RENNIE S J, MARCHERET E, MROUEH Y, et al. Self-critical sequence training for image captioning [C]// IEEE Conference on Computer Vision and Pattern Recognition. Los Alamitos: IEEE, 2017: 1179-1195.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|