[1]
WU J, CAI N, CHEN W, et al Automatic detection of hardhats worn by construction personnel: a deep learning approach and benchmark dataset
[J]. Automation in Construction , 2019 , 106 : 102894
DOI:10.1016/j.autcon.2019.102894
[本文引用: 1]
[2]
NATH N D, BEHZADAN A H, PAAL S G Deep learning for site safety: real-time detection of personal protective equipment
[J]. Automation in Construction , 2020 , 112 : 103085
DOI:10.1016/j.autcon.2020.103085
[本文引用: 1]
[3]
GUO Y, XU Y, LI S Dense construction vehicle detection based on orientation-aware feature fusion convolutional neural network
[J]. Automation in Construction , 2020 , 112 : 103124
DOI:10.1016/j.autcon.2020.103124
[本文引用: 1]
[4]
LI Y, LU Y, CHEN J A deep learning approach for real-time rebar counting on the construction site based on YOLOv3 detector
[J]. Automation in Construction , 2021 , 124 : 103602
DOI:10.1016/j.autcon.2021.103602
[本文引用: 1]
[5]
徐守坤, 倪楚涵, 吉晨晨, 等 一种基于安全帽佩戴检测的图像描述方法研究
[J]. 小型微型计算机系统 , 2020 , 41 (4 ): 812 - 819
DOI:10.3969/j.issn.1000-1220.2020.04.025
[本文引用: 1]
XU Shou-kun, NI Chu-han, JI Chen-chen, et al Research on image caption method based on safety helmet wearing detection
[J]. Journal of Chinese Computer Systems , 2020 , 41 (4 ): 812 - 819
DOI:10.3969/j.issn.1000-1220.2020.04.025
[本文引用: 1]
[6]
BANG S, KIM H Context-based information generation for managing UAV-acquired data using image captioning
[J]. Automation in Construction , 2020 , 112 : 103116
DOI:10.1016/j.autcon.2020.103116
[本文引用: 1]
[7]
LIU H, WANG G, HUANG T, et al Manifesting construction activity scenes via image captioning
[J]. Automation in Construction , 2020 , 119 : 103334
DOI:10.1016/j.autcon.2020.103334
[本文引用: 1]
[8]
XU K, BA J L, KIROS R, et al. Show, attend and tell: neural image caption generation with visual attention [C]// International Conference on Machine Learning. Cambridge: MIT, 2015: 2048-2057.
[本文引用: 2]
[9]
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [C]// European Conference on Computer Vision . Berlin: Springer, 2014: 740-755.
[本文引用: 1]
[10]
HODOSH M, YOUNG P, HOCKENMAIER J Framing image description as a ranking task: data, models and evaluation metrics
[J]. Journal of Artificial Intelligence Research , 2013 , 47 : 853 - 899
DOI:10.1613/jair.3994
[本文引用: 1]
[11]
YOUNG P, LAI A, HODOSH M, et al From image descriptions to visual denotations: new similarity metrics for semantic inference over event descriptions
[J]. Transactions of the Association for Computational Linguistics , 2014 , 2 : 67 - 78
DOI:10.1162/tacl_a_00166
[本文引用: 1]
[12]
DUTTA A, ZISSERMAN A. The VIA annotation software for images, audio and video [EB/OL]. (2019-04-24)[2021-04-08]. https://arxiv.org/abs/1904.10699.
[本文引用: 1]
[13]
PAPINENI K, ROUKOS S, WARD T, et al. BLEU: a method for automatic evaluation of machine translation [C]// Annual Meeting on Association for Computational Linguistics . Stroudsburg: ACL, 2002: 311-318.
[本文引用: 1]
[14]
BANERJEE S, LAVIE A. METEOR: an automatic metric for MT evaluation with improved correlation with human judgments [C]// ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization . Stroudsburg: ACL, 2005: 65-72.
[本文引用: 1]
[15]
LIN C Y. ROUGE: a package for automatic evaluation of summaries[C]// ACL Workshop on Text Summarization Branches Out . Stroudsburg: ACL, 2004: 74-81.
[本文引用: 1]
[16]
VEDANTAM R, ZITNICK C L, PARIKH D. CIDEr: consensus-based image description evaluation [C]// IEEE Conference on Computer Vision and Pattern Recognition. Los Alamitos: IEEE, 2015: 4566-4575.
[本文引用: 1]
[17]
VINYALS O, TOSHEV A, BENGIO S, et al. Show and tell: a neural image caption generator [C]// IEEE Conference on Computer Vision and Pattern Recognition . Los Alamitos: IEEE, 2015: 3156-3164.
[本文引用: 2]
[18]
LU J, XIONG C, PARIKH D, et al. Knowing when to look: adaptive attention via a visual sentinel for image captioning [C]// IEEE Conference on Computer Vision and Pattern Recognition . Los Alamitos: IEEE, 2017: 3242-3250.
[本文引用: 2]
[19]
RENNIE S J, MARCHERET E, MROUEH Y, et al. Self-critical sequence training for image captioning [C]// IEEE Conference on Computer Vision and Pattern Recognition . Los Alamitos: IEEE, 2017: 1179-1195.
[本文引用: 2]
[20]
ANDERSON P, HE X, BUEHLER C, et al. Bottom-up and top-down attention for image captioning and visual question answering [C]// IEEE Conference on Computer Vision and Pattern Recognition . Los Alamitos: IEEE, 2018: 6077-6086.
[本文引用: 2]
Automatic detection of hardhats worn by construction personnel: a deep learning approach and benchmark dataset
1
2019
... 目前关于建筑施工场景的研究主要侧重于采用目标检测方法对施工场景中的目标进行检测和识别,如个人防护设备穿戴检测[1 -2 ] 、施工车辆检测[3 ] 、钢筋检测和计数[4 ] 等,而关于施工场景的图像描述的研究较为匮乏. 徐守坤等[5 ] 提出一种规则和模板相结合的安全帽佩戴图像描述生成方法,可以生成施工场景中工人佩戴安全帽的描述语句,但其聚焦的施工场景较为单一,仅研究工人佩戴安全帽场景,未充分考虑工人绑钢筋、浇筑混凝土及砌砖等多个常见的施工场景,且所采用的规则和模板法存在描述语句结构相对固定、多样性不足、句子语义流畅性较差的缺陷. Bang等[6 ] 采用密集描述网络对无人机收集的施工图像进行描述,可以生成施工图像中关于目标区域的文本描述,但该方法只关注施工图像中目标区域的局部信息,未能捕获和感知施工场景的全局信息,无法生成关于施工场景全局信息的文本描述. 此外,采用无人机以俯视的角度收集施工图像,存在施工场景细粒度信息难以挖掘、图像描述难度大的缺陷. Liu等[7 ] 采用图像描述方法对建筑施工活动进行研究,可以生成与施工场景活动相关的文本描述,但其所研究的施工活动较少,仅限于5种施工活动,且未充分考虑光线不佳、夜间施工、远距离小目标、密集目标等复杂环境下的施工场景,存在一定的局限性. ...
Deep learning for site safety: real-time detection of personal protective equipment
1
2020
... 目前关于建筑施工场景的研究主要侧重于采用目标检测方法对施工场景中的目标进行检测和识别,如个人防护设备穿戴检测[1 -2 ] 、施工车辆检测[3 ] 、钢筋检测和计数[4 ] 等,而关于施工场景的图像描述的研究较为匮乏. 徐守坤等[5 ] 提出一种规则和模板相结合的安全帽佩戴图像描述生成方法,可以生成施工场景中工人佩戴安全帽的描述语句,但其聚焦的施工场景较为单一,仅研究工人佩戴安全帽场景,未充分考虑工人绑钢筋、浇筑混凝土及砌砖等多个常见的施工场景,且所采用的规则和模板法存在描述语句结构相对固定、多样性不足、句子语义流畅性较差的缺陷. Bang等[6 ] 采用密集描述网络对无人机收集的施工图像进行描述,可以生成施工图像中关于目标区域的文本描述,但该方法只关注施工图像中目标区域的局部信息,未能捕获和感知施工场景的全局信息,无法生成关于施工场景全局信息的文本描述. 此外,采用无人机以俯视的角度收集施工图像,存在施工场景细粒度信息难以挖掘、图像描述难度大的缺陷. Liu等[7 ] 采用图像描述方法对建筑施工活动进行研究,可以生成与施工场景活动相关的文本描述,但其所研究的施工活动较少,仅限于5种施工活动,且未充分考虑光线不佳、夜间施工、远距离小目标、密集目标等复杂环境下的施工场景,存在一定的局限性. ...
Dense construction vehicle detection based on orientation-aware feature fusion convolutional neural network
1
2020
... 目前关于建筑施工场景的研究主要侧重于采用目标检测方法对施工场景中的目标进行检测和识别,如个人防护设备穿戴检测[1 -2 ] 、施工车辆检测[3 ] 、钢筋检测和计数[4 ] 等,而关于施工场景的图像描述的研究较为匮乏. 徐守坤等[5 ] 提出一种规则和模板相结合的安全帽佩戴图像描述生成方法,可以生成施工场景中工人佩戴安全帽的描述语句,但其聚焦的施工场景较为单一,仅研究工人佩戴安全帽场景,未充分考虑工人绑钢筋、浇筑混凝土及砌砖等多个常见的施工场景,且所采用的规则和模板法存在描述语句结构相对固定、多样性不足、句子语义流畅性较差的缺陷. Bang等[6 ] 采用密集描述网络对无人机收集的施工图像进行描述,可以生成施工图像中关于目标区域的文本描述,但该方法只关注施工图像中目标区域的局部信息,未能捕获和感知施工场景的全局信息,无法生成关于施工场景全局信息的文本描述. 此外,采用无人机以俯视的角度收集施工图像,存在施工场景细粒度信息难以挖掘、图像描述难度大的缺陷. Liu等[7 ] 采用图像描述方法对建筑施工活动进行研究,可以生成与施工场景活动相关的文本描述,但其所研究的施工活动较少,仅限于5种施工活动,且未充分考虑光线不佳、夜间施工、远距离小目标、密集目标等复杂环境下的施工场景,存在一定的局限性. ...
A deep learning approach for real-time rebar counting on the construction site based on YOLOv3 detector
1
2021
... 目前关于建筑施工场景的研究主要侧重于采用目标检测方法对施工场景中的目标进行检测和识别,如个人防护设备穿戴检测[1 -2 ] 、施工车辆检测[3 ] 、钢筋检测和计数[4 ] 等,而关于施工场景的图像描述的研究较为匮乏. 徐守坤等[5 ] 提出一种规则和模板相结合的安全帽佩戴图像描述生成方法,可以生成施工场景中工人佩戴安全帽的描述语句,但其聚焦的施工场景较为单一,仅研究工人佩戴安全帽场景,未充分考虑工人绑钢筋、浇筑混凝土及砌砖等多个常见的施工场景,且所采用的规则和模板法存在描述语句结构相对固定、多样性不足、句子语义流畅性较差的缺陷. Bang等[6 ] 采用密集描述网络对无人机收集的施工图像进行描述,可以生成施工图像中关于目标区域的文本描述,但该方法只关注施工图像中目标区域的局部信息,未能捕获和感知施工场景的全局信息,无法生成关于施工场景全局信息的文本描述. 此外,采用无人机以俯视的角度收集施工图像,存在施工场景细粒度信息难以挖掘、图像描述难度大的缺陷. Liu等[7 ] 采用图像描述方法对建筑施工活动进行研究,可以生成与施工场景活动相关的文本描述,但其所研究的施工活动较少,仅限于5种施工活动,且未充分考虑光线不佳、夜间施工、远距离小目标、密集目标等复杂环境下的施工场景,存在一定的局限性. ...
一种基于安全帽佩戴检测的图像描述方法研究
1
2020
... 目前关于建筑施工场景的研究主要侧重于采用目标检测方法对施工场景中的目标进行检测和识别,如个人防护设备穿戴检测[1 -2 ] 、施工车辆检测[3 ] 、钢筋检测和计数[4 ] 等,而关于施工场景的图像描述的研究较为匮乏. 徐守坤等[5 ] 提出一种规则和模板相结合的安全帽佩戴图像描述生成方法,可以生成施工场景中工人佩戴安全帽的描述语句,但其聚焦的施工场景较为单一,仅研究工人佩戴安全帽场景,未充分考虑工人绑钢筋、浇筑混凝土及砌砖等多个常见的施工场景,且所采用的规则和模板法存在描述语句结构相对固定、多样性不足、句子语义流畅性较差的缺陷. Bang等[6 ] 采用密集描述网络对无人机收集的施工图像进行描述,可以生成施工图像中关于目标区域的文本描述,但该方法只关注施工图像中目标区域的局部信息,未能捕获和感知施工场景的全局信息,无法生成关于施工场景全局信息的文本描述. 此外,采用无人机以俯视的角度收集施工图像,存在施工场景细粒度信息难以挖掘、图像描述难度大的缺陷. Liu等[7 ] 采用图像描述方法对建筑施工活动进行研究,可以生成与施工场景活动相关的文本描述,但其所研究的施工活动较少,仅限于5种施工活动,且未充分考虑光线不佳、夜间施工、远距离小目标、密集目标等复杂环境下的施工场景,存在一定的局限性. ...
一种基于安全帽佩戴检测的图像描述方法研究
1
2020
... 目前关于建筑施工场景的研究主要侧重于采用目标检测方法对施工场景中的目标进行检测和识别,如个人防护设备穿戴检测[1 -2 ] 、施工车辆检测[3 ] 、钢筋检测和计数[4 ] 等,而关于施工场景的图像描述的研究较为匮乏. 徐守坤等[5 ] 提出一种规则和模板相结合的安全帽佩戴图像描述生成方法,可以生成施工场景中工人佩戴安全帽的描述语句,但其聚焦的施工场景较为单一,仅研究工人佩戴安全帽场景,未充分考虑工人绑钢筋、浇筑混凝土及砌砖等多个常见的施工场景,且所采用的规则和模板法存在描述语句结构相对固定、多样性不足、句子语义流畅性较差的缺陷. Bang等[6 ] 采用密集描述网络对无人机收集的施工图像进行描述,可以生成施工图像中关于目标区域的文本描述,但该方法只关注施工图像中目标区域的局部信息,未能捕获和感知施工场景的全局信息,无法生成关于施工场景全局信息的文本描述. 此外,采用无人机以俯视的角度收集施工图像,存在施工场景细粒度信息难以挖掘、图像描述难度大的缺陷. Liu等[7 ] 采用图像描述方法对建筑施工活动进行研究,可以生成与施工场景活动相关的文本描述,但其所研究的施工活动较少,仅限于5种施工活动,且未充分考虑光线不佳、夜间施工、远距离小目标、密集目标等复杂环境下的施工场景,存在一定的局限性. ...
Context-based information generation for managing UAV-acquired data using image captioning
1
2020
... 目前关于建筑施工场景的研究主要侧重于采用目标检测方法对施工场景中的目标进行检测和识别,如个人防护设备穿戴检测[1 -2 ] 、施工车辆检测[3 ] 、钢筋检测和计数[4 ] 等,而关于施工场景的图像描述的研究较为匮乏. 徐守坤等[5 ] 提出一种规则和模板相结合的安全帽佩戴图像描述生成方法,可以生成施工场景中工人佩戴安全帽的描述语句,但其聚焦的施工场景较为单一,仅研究工人佩戴安全帽场景,未充分考虑工人绑钢筋、浇筑混凝土及砌砖等多个常见的施工场景,且所采用的规则和模板法存在描述语句结构相对固定、多样性不足、句子语义流畅性较差的缺陷. Bang等[6 ] 采用密集描述网络对无人机收集的施工图像进行描述,可以生成施工图像中关于目标区域的文本描述,但该方法只关注施工图像中目标区域的局部信息,未能捕获和感知施工场景的全局信息,无法生成关于施工场景全局信息的文本描述. 此外,采用无人机以俯视的角度收集施工图像,存在施工场景细粒度信息难以挖掘、图像描述难度大的缺陷. Liu等[7 ] 采用图像描述方法对建筑施工活动进行研究,可以生成与施工场景活动相关的文本描述,但其所研究的施工活动较少,仅限于5种施工活动,且未充分考虑光线不佳、夜间施工、远距离小目标、密集目标等复杂环境下的施工场景,存在一定的局限性. ...
Manifesting construction activity scenes via image captioning
1
2020
... 目前关于建筑施工场景的研究主要侧重于采用目标检测方法对施工场景中的目标进行检测和识别,如个人防护设备穿戴检测[1 -2 ] 、施工车辆检测[3 ] 、钢筋检测和计数[4 ] 等,而关于施工场景的图像描述的研究较为匮乏. 徐守坤等[5 ] 提出一种规则和模板相结合的安全帽佩戴图像描述生成方法,可以生成施工场景中工人佩戴安全帽的描述语句,但其聚焦的施工场景较为单一,仅研究工人佩戴安全帽场景,未充分考虑工人绑钢筋、浇筑混凝土及砌砖等多个常见的施工场景,且所采用的规则和模板法存在描述语句结构相对固定、多样性不足、句子语义流畅性较差的缺陷. Bang等[6 ] 采用密集描述网络对无人机收集的施工图像进行描述,可以生成施工图像中关于目标区域的文本描述,但该方法只关注施工图像中目标区域的局部信息,未能捕获和感知施工场景的全局信息,无法生成关于施工场景全局信息的文本描述. 此外,采用无人机以俯视的角度收集施工图像,存在施工场景细粒度信息难以挖掘、图像描述难度大的缺陷. Liu等[7 ] 采用图像描述方法对建筑施工活动进行研究,可以生成与施工场景活动相关的文本描述,但其所研究的施工活动较少,仅限于5种施工活动,且未充分考虑光线不佳、夜间施工、远距离小目标、密集目标等复杂环境下的施工场景,存在一定的局限性. ...
2
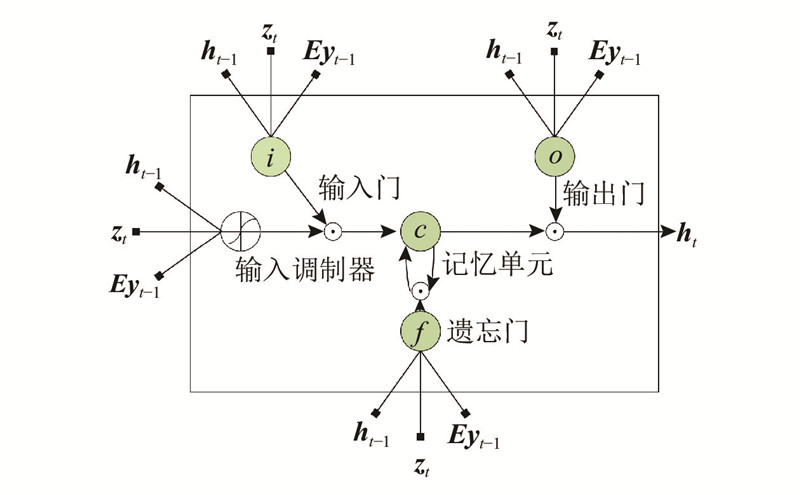
... 本研究针对上述施工场景图像描述研究中存在的不足与难点,提出基于注意力机制和编码-解码架构的施工场景图像描述方法. 采用卷积神经网络构建编码器,对输入图像进行特征提取;利用长短时记忆网络LSTM搭建解码器,提取句子内部单词之间的句法特征;引入注意力机制[8 ] ,重点关注显著性强的特征,抑制显著性弱的及其他冗余和噪声特征信息. 为了验证所提方法的有效性,构建了一个基于施工场景的图像描述数据集,该数据集数据量丰富,覆盖了10种常见的施工场景,并且包含远距离小目标、密集目标、夜间施工、光线不佳等多种复杂施工环境,能够较为完备地反映施工现场真实场景的情况. ...
... 施工现场环境复杂,存在多种噪声及冗余信息的干扰,为了增强模型对显著信息的关注,提升描述准确性,将注意力机制[8 ] 引入解码器. 注意力是一种权重参数分配的机制,通过计算输入信息的重要性分布,协助模型重点关注显著性强的信息,抑制显著性弱的及其他冗余和噪声信息,在大量信息中快速捕捉到当前最需要的信息,减少无用信息的干扰,提升描述结果的准确性. 如图3 所示为注意力机制的可视化效果图. 图中,深红色区域表示显著性强的特征区域. 由图3 (a)可以看出,注意力机制通过对图像特征进行筛选,将注意力聚焦在2辆挖掘机的特征区域上,抑制其他无关的特征信息,增强模型对施工目标的捕获和感知能力. 由图3 (b)可以看出,注意力机制将注意力聚焦在工人和手推车的特征区域上,增强模型对施工场景的感知与理解. ...
1
... 为了实现施工场景图像描述的任务,须采用大量的数据对图像描述模型进行训练,使其充分学习到图像特征与单词语义特征间的映射关系. 当前图像描述任务通常采用公开的COCO[9 ] 和Flickr[10 -11 ] 数据集作为基准数据集对模型进行训练和验证,但COCO和Flickr数据集描述的场景大多为日常生活场景,无法满足施工场景图像描述任务的需求. 由于当前尚无用于施工场景的图像描述数据集,须构建一个基于施工场景的图像描述数据集. ...
Framing image description as a ranking task: data, models and evaluation metrics
1
2013
... 为了实现施工场景图像描述的任务,须采用大量的数据对图像描述模型进行训练,使其充分学习到图像特征与单词语义特征间的映射关系. 当前图像描述任务通常采用公开的COCO[9 ] 和Flickr[10 -11 ] 数据集作为基准数据集对模型进行训练和验证,但COCO和Flickr数据集描述的场景大多为日常生活场景,无法满足施工场景图像描述任务的需求. 由于当前尚无用于施工场景的图像描述数据集,须构建一个基于施工场景的图像描述数据集. ...
From image descriptions to visual denotations: new similarity metrics for semantic inference over event descriptions
1
2014
... 为了实现施工场景图像描述的任务,须采用大量的数据对图像描述模型进行训练,使其充分学习到图像特征与单词语义特征间的映射关系. 当前图像描述任务通常采用公开的COCO[9 ] 和Flickr[10 -11 ] 数据集作为基准数据集对模型进行训练和验证,但COCO和Flickr数据集描述的场景大多为日常生活场景,无法满足施工场景图像描述任务的需求. 由于当前尚无用于施工场景的图像描述数据集,须构建一个基于施工场景的图像描述数据集. ...
1
... 为了构建施工场景图像描述数据集,首先根据施工现场常见的施工活动,选择10种施工场景作为研究对象,如表1 所示. 其次通过现场采集、从公共数据集中选取和网上爬取的方式共收集1200张施工图像,每种施工场景下的图像数量如表1 所示. 同时编写Python脚本获取每张图像的名称及尺寸信息. 最后采用VIA标注软件[12 ] 对收集到的施工图像进行标注,根据施工图像的场景内容赋予每张图像5个描述语句,描述语句的部分示例如图4 所示. 在标注完成后以json的格式存储标注信息. 所构建的数据集数据量丰富,覆盖了10种常见的施工场景,并且包含远距离小目标、密集目标、夜间施工、光线不佳等多种复杂施工环境,能够较为完备地反映施工现场真实场景的情况. 随机选取数据集中60%的图像作为训练集,剩余的40%作为测试集. ...
1
... 为了评价模型的描述性能,采用图像描述任务中常用的BLEU[13 ] 、METEOR[14 ] 、ROUGE_L[15 ] 、CIDEr[16 ] 作为评价指标,评价指标分数越高,表示模型的描述结果越准确. BLEU分为BLEU-1、BLEU-2、BLEU-3和BLEU-4,通过计算待评价句子和参考句子之间的匹配度,评价描述结果的准确性. METEOR通过计算待评价句子和参考句子之间单精度和单字召回率的加权调和平均来进行评价. ROUGE_L通过度量待评价句子和参考句子之间最长公共子序列的相似度来评价生成语句的质量. CIDEr通过计算待评价句子和参考句子之间的余弦距离,来衡量两者之间的相似度. ...
1
... 为了评价模型的描述性能,采用图像描述任务中常用的BLEU[13 ] 、METEOR[14 ] 、ROUGE_L[15 ] 、CIDEr[16 ] 作为评价指标,评价指标分数越高,表示模型的描述结果越准确. BLEU分为BLEU-1、BLEU-2、BLEU-3和BLEU-4,通过计算待评价句子和参考句子之间的匹配度,评价描述结果的准确性. METEOR通过计算待评价句子和参考句子之间单精度和单字召回率的加权调和平均来进行评价. ROUGE_L通过度量待评价句子和参考句子之间最长公共子序列的相似度来评价生成语句的质量. CIDEr通过计算待评价句子和参考句子之间的余弦距离,来衡量两者之间的相似度. ...
1
... 为了评价模型的描述性能,采用图像描述任务中常用的BLEU[13 ] 、METEOR[14 ] 、ROUGE_L[15 ] 、CIDEr[16 ] 作为评价指标,评价指标分数越高,表示模型的描述结果越准确. BLEU分为BLEU-1、BLEU-2、BLEU-3和BLEU-4,通过计算待评价句子和参考句子之间的匹配度,评价描述结果的准确性. METEOR通过计算待评价句子和参考句子之间单精度和单字召回率的加权调和平均来进行评价. ROUGE_L通过度量待评价句子和参考句子之间最长公共子序列的相似度来评价生成语句的质量. CIDEr通过计算待评价句子和参考句子之间的余弦距离,来衡量两者之间的相似度. ...
1
... 为了评价模型的描述性能,采用图像描述任务中常用的BLEU[13 ] 、METEOR[14 ] 、ROUGE_L[15 ] 、CIDEr[16 ] 作为评价指标,评价指标分数越高,表示模型的描述结果越准确. BLEU分为BLEU-1、BLEU-2、BLEU-3和BLEU-4,通过计算待评价句子和参考句子之间的匹配度,评价描述结果的准确性. METEOR通过计算待评价句子和参考句子之间单精度和单字召回率的加权调和平均来进行评价. ROUGE_L通过度量待评价句子和参考句子之间最长公共子序列的相似度来评价生成语句的质量. CIDEr通过计算待评价句子和参考句子之间的余弦距离,来衡量两者之间的相似度. ...
2
... 由表2 可知,所提出的模型在施工图像描述测试集中取得了较高的精度,其BLEU-1、BLEU-2、BLEU-3、BLEU-4、METEOR、ROUGE_L、CIDEr指标得分分别为0.783、0.608、0.469、0.357、0.293、0.586、0.962,较NIC[17 ] 、Adaptive[18 ] 、Self-critic[19 ] 、Up-down[20 ] 模型均有提升,充分验证了本研究所提出模型的有效性. 究其原因,编码部分采用具有强大空间感知能力的ResNet-101对输入的施工图像进行特征提取,捕获了大量的区域特征、颜色特征、纹理特征等视觉特征,以及关于场景信息、目标交互关系信息、环境信息等更深层次的语义信息,使模型充分感知与理解视觉和语义的交叉特征. 同时,模型采用LSTM网络搭建解码器,动态地选择图像特征,提取句子内部单词之间的句法特征、单词位置编码信息,捕捉和学习图像特征与单词语义特征之间的联系及映射关系. 此外,为了提升描述结果的准确性,通过引入注意力机制使模型重点关注显著性强的特征,抑制显著性弱的特征,摒弃其他冗余和噪声特征,增强模型对施工场景的感知和理解,减少关键信息的丢失. ...
... Experiment results of different methods in image caption data set of construction scene
Tab.2 方法 主干网络 BLEU-1 BLEU-2 BLEU-3 BLEU-4 METEOR ROUGE_L CIDEr NIC[17 ] VGG-16 0.725 0.542 0.386 0.295 0.248 0.531 0.854 Adaptive[18 ] VGG-16 0.738 0.556 0.403 0.319 0.259 0.545 0.887 Self-critic[19 ] ResNet-101 0.751 0.573 0.437 0.332 0.266 0.558 0.913 Up-down[20 ] ResNet-101 0.764 0.587 0.455 0.344 0.271 0.572 0.946 本研究方法 ResNet-101 0.783 0.608 0.469 0.357 0.293 0.586 0.962
表 3 消融实验结果 ...
2
... 由表2 可知,所提出的模型在施工图像描述测试集中取得了较高的精度,其BLEU-1、BLEU-2、BLEU-3、BLEU-4、METEOR、ROUGE_L、CIDEr指标得分分别为0.783、0.608、0.469、0.357、0.293、0.586、0.962,较NIC[17 ] 、Adaptive[18 ] 、Self-critic[19 ] 、Up-down[20 ] 模型均有提升,充分验证了本研究所提出模型的有效性. 究其原因,编码部分采用具有强大空间感知能力的ResNet-101对输入的施工图像进行特征提取,捕获了大量的区域特征、颜色特征、纹理特征等视觉特征,以及关于场景信息、目标交互关系信息、环境信息等更深层次的语义信息,使模型充分感知与理解视觉和语义的交叉特征. 同时,模型采用LSTM网络搭建解码器,动态地选择图像特征,提取句子内部单词之间的句法特征、单词位置编码信息,捕捉和学习图像特征与单词语义特征之间的联系及映射关系. 此外,为了提升描述结果的准确性,通过引入注意力机制使模型重点关注显著性强的特征,抑制显著性弱的特征,摒弃其他冗余和噪声特征,增强模型对施工场景的感知和理解,减少关键信息的丢失. ...
... Experiment results of different methods in image caption data set of construction scene
Tab.2 方法 主干网络 BLEU-1 BLEU-2 BLEU-3 BLEU-4 METEOR ROUGE_L CIDEr NIC[17 ] VGG-16 0.725 0.542 0.386 0.295 0.248 0.531 0.854 Adaptive[18 ] VGG-16 0.738 0.556 0.403 0.319 0.259 0.545 0.887 Self-critic[19 ] ResNet-101 0.751 0.573 0.437 0.332 0.266 0.558 0.913 Up-down[20 ] ResNet-101 0.764 0.587 0.455 0.344 0.271 0.572 0.946 本研究方法 ResNet-101 0.783 0.608 0.469 0.357 0.293 0.586 0.962
表 3 消融实验结果 ...
2
... 由表2 可知,所提出的模型在施工图像描述测试集中取得了较高的精度,其BLEU-1、BLEU-2、BLEU-3、BLEU-4、METEOR、ROUGE_L、CIDEr指标得分分别为0.783、0.608、0.469、0.357、0.293、0.586、0.962,较NIC[17 ] 、Adaptive[18 ] 、Self-critic[19 ] 、Up-down[20 ] 模型均有提升,充分验证了本研究所提出模型的有效性. 究其原因,编码部分采用具有强大空间感知能力的ResNet-101对输入的施工图像进行特征提取,捕获了大量的区域特征、颜色特征、纹理特征等视觉特征,以及关于场景信息、目标交互关系信息、环境信息等更深层次的语义信息,使模型充分感知与理解视觉和语义的交叉特征. 同时,模型采用LSTM网络搭建解码器,动态地选择图像特征,提取句子内部单词之间的句法特征、单词位置编码信息,捕捉和学习图像特征与单词语义特征之间的联系及映射关系. 此外,为了提升描述结果的准确性,通过引入注意力机制使模型重点关注显著性强的特征,抑制显著性弱的特征,摒弃其他冗余和噪声特征,增强模型对施工场景的感知和理解,减少关键信息的丢失. ...
... Experiment results of different methods in image caption data set of construction scene
Tab.2 方法 主干网络 BLEU-1 BLEU-2 BLEU-3 BLEU-4 METEOR ROUGE_L CIDEr NIC[17 ] VGG-16 0.725 0.542 0.386 0.295 0.248 0.531 0.854 Adaptive[18 ] VGG-16 0.738 0.556 0.403 0.319 0.259 0.545 0.887 Self-critic[19 ] ResNet-101 0.751 0.573 0.437 0.332 0.266 0.558 0.913 Up-down[20 ] ResNet-101 0.764 0.587 0.455 0.344 0.271 0.572 0.946 本研究方法 ResNet-101 0.783 0.608 0.469 0.357 0.293 0.586 0.962
表 3 消融实验结果 ...
2
... 由表2 可知,所提出的模型在施工图像描述测试集中取得了较高的精度,其BLEU-1、BLEU-2、BLEU-3、BLEU-4、METEOR、ROUGE_L、CIDEr指标得分分别为0.783、0.608、0.469、0.357、0.293、0.586、0.962,较NIC[17 ] 、Adaptive[18 ] 、Self-critic[19 ] 、Up-down[20 ] 模型均有提升,充分验证了本研究所提出模型的有效性. 究其原因,编码部分采用具有强大空间感知能力的ResNet-101对输入的施工图像进行特征提取,捕获了大量的区域特征、颜色特征、纹理特征等视觉特征,以及关于场景信息、目标交互关系信息、环境信息等更深层次的语义信息,使模型充分感知与理解视觉和语义的交叉特征. 同时,模型采用LSTM网络搭建解码器,动态地选择图像特征,提取句子内部单词之间的句法特征、单词位置编码信息,捕捉和学习图像特征与单词语义特征之间的联系及映射关系. 此外,为了提升描述结果的准确性,通过引入注意力机制使模型重点关注显著性强的特征,抑制显著性弱的特征,摒弃其他冗余和噪声特征,增强模型对施工场景的感知和理解,减少关键信息的丢失. ...
... Experiment results of different methods in image caption data set of construction scene
Tab.2 方法 主干网络 BLEU-1 BLEU-2 BLEU-3 BLEU-4 METEOR ROUGE_L CIDEr NIC[17 ] VGG-16 0.725 0.542 0.386 0.295 0.248 0.531 0.854 Adaptive[18 ] VGG-16 0.738 0.556 0.403 0.319 0.259 0.545 0.887 Self-critic[19 ] ResNet-101 0.751 0.573 0.437 0.332 0.266 0.558 0.913 Up-down[20 ] ResNet-101 0.764 0.587 0.455 0.344 0.271 0.572 0.946 本研究方法 ResNet-101 0.783 0.608 0.469 0.357 0.293 0.586 0.962
表 3 消融实验结果 ...









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}