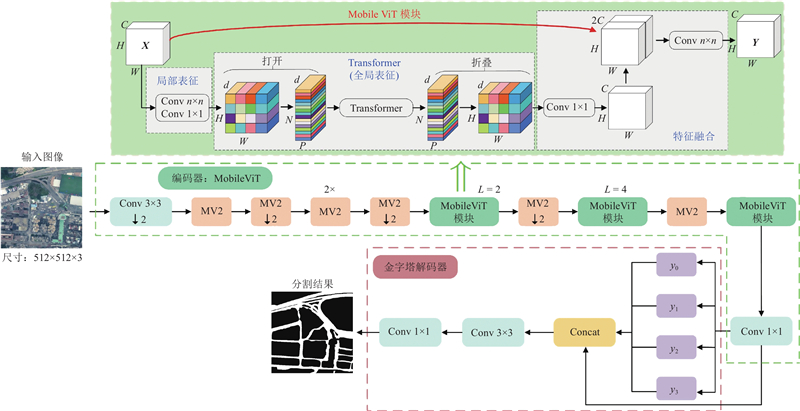
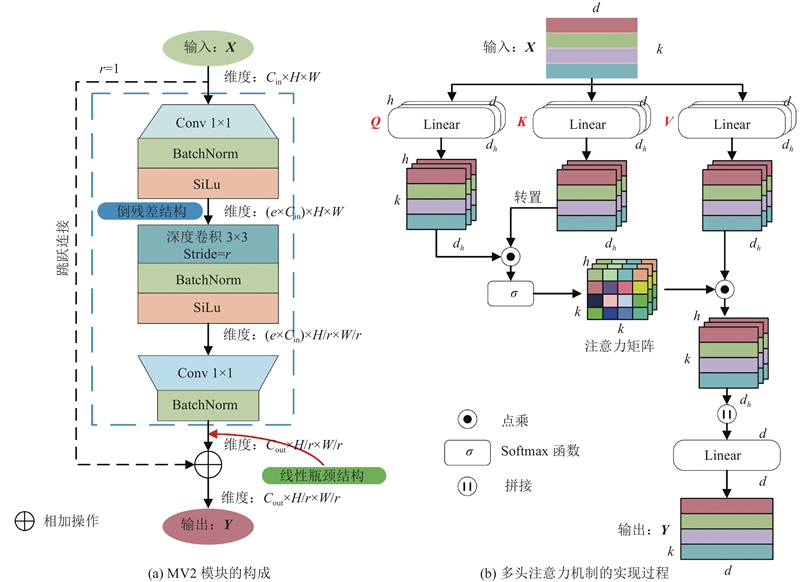
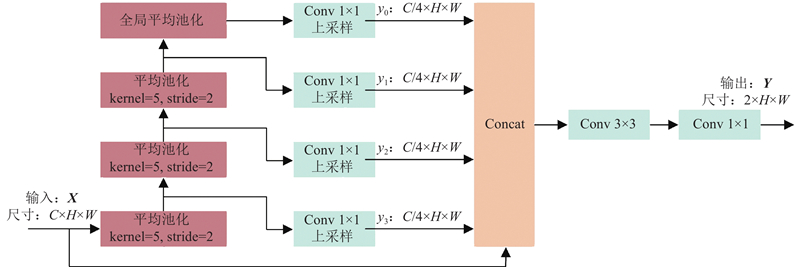
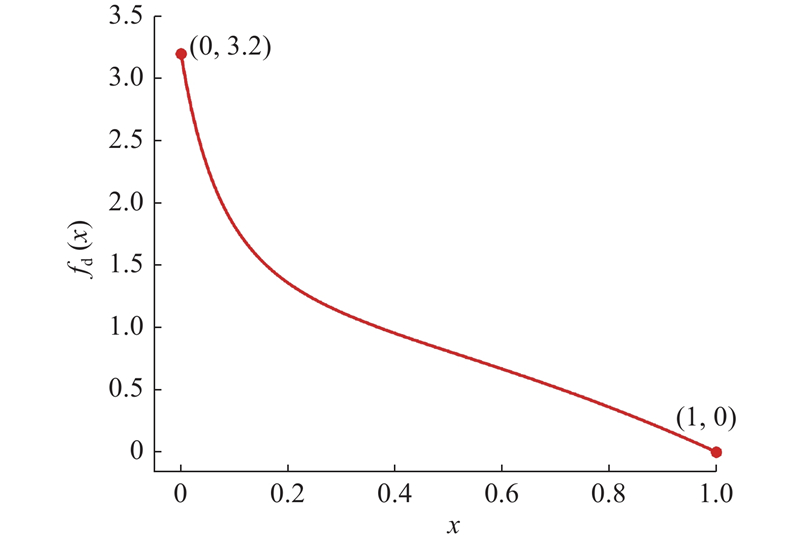
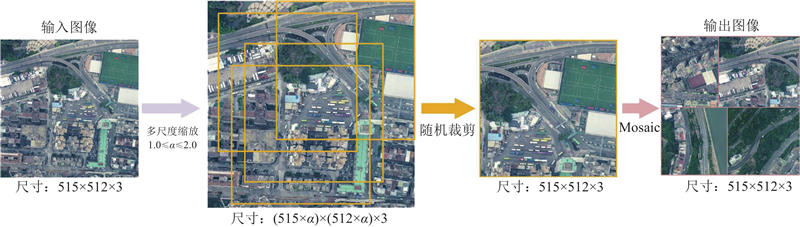
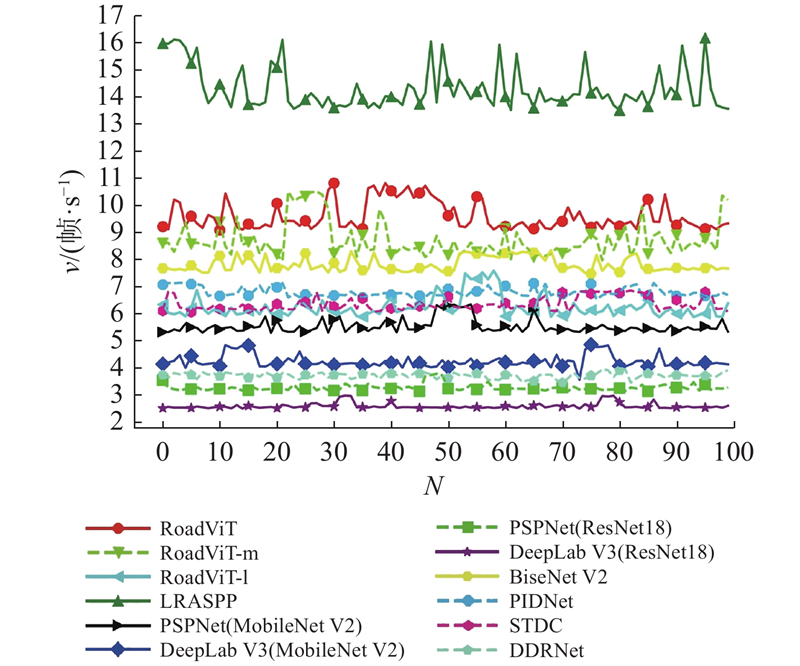
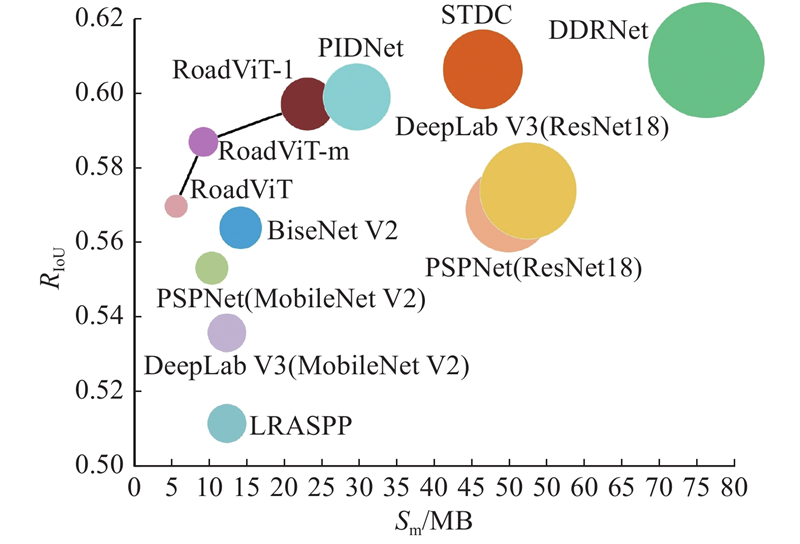
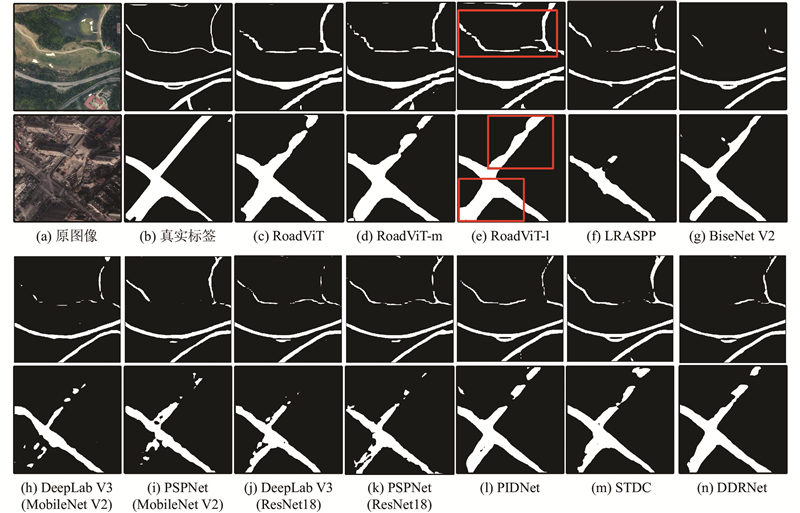
| 计算机技术 |
|

|
|
|
| 基于轻量级Transformer的城市路网提取方法 |
冯志成1,2( ),杨杰1,2,*(),陈智超1,2 ),杨杰1,2,*(),陈智超1,2 |
1. 江西理工大学 电气工程与自动化学院,江西 赣州 341000
2. 江西省磁悬浮技术重点实验室,江西 赣州 341000 |
|
| Urban road network extraction method based on lightweight Transformer |
| Zhicheng FENG1,2(),Jie YANG1,2,*(),Zhichao CHEN1,2 |
1. School of Electrical Engineering and Automation, Jiangxi University of Science and Technology, Ganzhou 341000, China
2. Jiangxi Provincial Key Laboratory of Maglev Technology, Ganzhou 341000, China |
| 1 |
WU S, DU C, CHEN H, et al Road extraction from very high resolution images using weakly labeled OpenStreetMap centerline[J]. International Journal of Geo-Information, 2019, 8 (11): 478
doi: 10.3390/ijgi8110478
|
| 2 |
CLAUSSMANN L, REVILLOUD M, GRUYER D, et al A review of motion planning for highway autonomous driving[J]. IEEE Transactions on Intelligent Transportation Systems, 2020, 21 (5): 1826- 1848
doi: 10.1109/TITS.2019.2913998
|
| 3 |
YIN W, QIAN M, WANG L, et al Road extraction from satellite images with iterative cross-task feature enhancement[J]. Neurocomputing, 2022, 506: 300- 310
doi: 10.1016/j.neucom.2022.07.086
|
| 4 |
MA Y, WU H, WANG L, et al Remote sensing big data computing: challenges and opportunities[J]. Future Generation Computer Systems, 2015, 51: 47- 60
doi: 10.1016/j.future.2014.10.029
|
| 5 |
刘春娟, 乔泽, 闫浩文, 等 基于多尺度互注意力的遥感图像语义分割网络[J]. 浙江大学学报: 工学版, 2023, 57 (7): 1335- 1344
LIU Chunjuan, QIAO Ze, YAN Haowen, et al Semantic segmentation network for remote sensing image based on multi-scale mutual attention[J]. Journal of Zhejiang University: Engineering Science, 2023, 57 (7): 1335- 1344
|
| 6 |
BADRINARAYANAN V, KENDALL A, CIPOLLA R SegNet: a deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39 (12): 2481- 2495
doi: 10.1109/TPAMI.2016.2644615
|
| 7 |
DAI J, ZHU T, ZHANG Y, et al Lane-level road extraction from high-resolution optical satellite images[J]. Remote Sensing, 2019, 11 (22): 2672
doi: 10.3390/rs11222672
|
| 8 |
CHEN L, ZHU Q, XIE X, et al Road extraction from VHR remote-sensing imagery via object segmentation constrained by Gabor features[J]. ISPRS International Journal of Geo-Information, 2018, 7 (9): 362
doi: 10.3390/ijgi7090362
|
| 9 |
陈智超, 焦海宁, 杨杰, 等 基于改进MobileNet v2的垃圾图像分类算法[J]. 浙江大学学报: 工学版, 2021, 55 (8): 1490- 1499
CHEN Zhichao, JIAO Haining, YANG Jie, et al Garbage image classification algorithm based on improved MobileNet v2[J]. Journal of Zhejiang University: Engineering Science, 2021, 55 (8): 1490- 1499
|
| 10 |
HOWARD A, SANDLER M, CHEN B, et al. Searching for MobileNetV3 [C]// Proceedings of the IEEE International Conference on Computer Vision. Seoul: IEEE, 2019: 1314-1324.
|
| 11 |
HE K , ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778.
|
| 12 |
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: transformers for image recognition at scale [EB/OL]. (2021-06-03) [2023-08-05]. https://arxiv.org/pdf/2010.11929.pdf.
|
| 13 |
MEHTA S, RASTEGARI M. MobileViT: light-weight, general-purpose, and mobile-friendly vision Transformer [EB/OL]. (2022-03-04) [2023-08-05]. https://arxiv.org/pdf/2110.02178.pdf.
|
| 14 |
SHELHAMER E, LONG J, DARRELL T Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39 (4): 640- 651
doi: 10.1109/TPAMI.2016.2572683
|
| 15 |
DU B, ZHAO Z, HU X, et al Landslide susceptibility prediction based on image semantic segmentation[J]. Computers and Geosciences, 2021, 155: 104860
doi: 10.1016/j.cageo.2021.104860
|
| 16 |
ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 6230-6239.
|
| 17 |
PAN H, HONG Y, SUN W, et al Deep dual-resolution networks for real-time and accurate semantic segmentation of traffic scenes[J]. IEEE Transactions on Intelligent Transportation Systems, 2023, 24 (3): 3448- 3460
doi: 10.1109/TITS.2022.3228042
|
| 18 |
FAN M, LAI S, HUANG J, et al. Rethinking BiSeNet for real-time semantic segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 9711-9720.
|
| 19 |
YU C, GAO C, WANG J, et al BiSeNet V2: bilateral network with guided aggregation for real-time semantic segmentation[J]. International Journal of Computer Vision, 2021, 129 (11): 3051- 3068
|
| 20 |
XU J, XIONG Z, BHATTACHARYYA, et al. PIDNet: a real-time semantic segmentation network inspired by PID controllers [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. [S. l. ]: IEEE, 2023: 19529-19539.
|
| 21 |
ZHOU L, ZHANG C, WU M. D-LinkNet: LinkNet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 192-196.
|
| 22 |
ZHU Q, ZHANG Y, WANG L, et al A global context-aware and batch-independent network for road extraction from VHR satellite imagery[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2021, 175: 353- 365
doi: 10.1016/j.isprsjprs.2021.03.016
|
| 23 |
DIAKOGIANNIS F, WALDNER F, CACCETTA P, et al ResUNet-a: a deep learning framework for semantic segmentation of remotely sensed data[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2020, 162: 94- 114
doi: 10.1016/j.isprsjprs.2020.01.013
|
| 24 |
吴仁哲, 蔡嘉伦, 刘国祥, 等 针对高分影像的RDU-Net乡村路网提取方法[J]. 遥感信息, 2021, 36 (1): 29- 36
WU Renzhe, CAI Jialun, LIU Guoxiang, et al Rural road network extraction for high resolution imagery using RDU-Net deep learning method[J]. Remote Sensing Information, 2021, 36 (1): 29- 36
|
| 25 |
LI J, SUN B, LI S, et al Semisupervised semantic segmentation of remote sensing images with consistency self-training[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 1- 11
|
| 26 |
YOU Z, WANG J, CHEN S, et al FMWDCT: foreground mixup into weighted dual-network cross training for semisupervised remote sensing road extraction[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2022, 15: 5570- 5579
doi: 10.1109/JSTARS.2022.3188025
|
| 27 |
SONG J, LI J, CHEN H, et al MapGen-GAN: a fast translator for remote sensing image to map via unsupervised adversarial learning[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2021, 14: 2341- 2357
doi: 10.1109/JSTARS.2021.3049905
|
| 28 |
YANG Y, ZHOU L SRP-YOLOX: an improved deep convolutional neural network for automated via detection[J]. Microelectronics Reliability, 2023, 147: 115069
doi: 10.1016/j.microrel.2023.115069
|
| 29 |
SHI M, XIE F, YANG J, et al Cutout with patch-loss augmentation for improving generative adversarial networks against instability[J]. Computer Vision and Image Understanding, 2023, 234: 103761
doi: 10.1016/j.cviu.2023.103761
|
| 30 |
YUN S, HAN D, CHEN S, et al. CutMix: regularization strategy to train strong classifiers with localizable features [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Seoul: IEEE, 2021: 6022-6031.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|