[1]
WU S, DU C, CHEN H, et al Road extraction from very high resolution images using weakly labeled OpenStreetMap centerline
[J]. International Journal of Geo-Information , 2019 , 8 (11 ): 478
DOI:10.3390/ijgi8110478
[本文引用: 1]
[2]
CLAUSSMANN L, REVILLOUD M, GRUYER D, et al A review of motion planning for highway autonomous driving
[J]. IEEE Transactions on Intelligent Transportation Systems , 2020 , 21 (5 ): 1826 - 1848
DOI:10.1109/TITS.2019.2913998
[本文引用: 1]
[3]
YIN W, QIAN M, WANG L, et al Road extraction from satellite images with iterative cross-task feature enhancement
[J]. Neurocomputing , 2022 , 506 : 300 - 310
DOI:10.1016/j.neucom.2022.07.086
[本文引用: 1]
[4]
MA Y, WU H, WANG L, et al Remote sensing big data computing: challenges and opportunities
[J]. Future Generation Computer Systems , 2015 , 51 : 47 - 60
DOI:10.1016/j.future.2014.10.029
[本文引用: 1]
[5]
刘春娟, 乔泽, 闫浩文, 等 基于多尺度互注意力的遥感图像语义分割网络
[J]. 浙江大学学报: 工学版 , 2023 , 57 (7 ): 1335 - 1344
[本文引用: 1]
LIU Chunjuan, QIAO Ze, YAN Haowen, et al Semantic segmentation network for remote sensing image based on multi-scale mutual attention
[J]. Journal of Zhejiang University: Engineering Science , 2023 , 57 (7 ): 1335 - 1344
[本文引用: 1]
[6]
BADRINARAYANAN V, KENDALL A, CIPOLLA R SegNet: a deep convolutional encoder-decoder architecture for image segmentation
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 39 (12 ): 2481 - 2495
DOI:10.1109/TPAMI.2016.2644615
[本文引用: 2]
[7]
DAI J, ZHU T, ZHANG Y, et al Lane-level road extraction from high-resolution optical satellite images
[J]. Remote Sensing , 2019 , 11 (22 ): 2672
DOI:10.3390/rs11222672
[本文引用: 1]
[8]
CHEN L, ZHU Q, XIE X, et al Road extraction from VHR remote-sensing imagery via object segmentation constrained by Gabor features
[J]. ISPRS International Journal of Geo-Information , 2018 , 7 (9 ): 362
DOI:10.3390/ijgi7090362
[本文引用: 1]
[9]
陈智超, 焦海宁, 杨杰, 等 基于改进MobileNet v2的垃圾图像分类算法
[J]. 浙江大学学报: 工学版 , 2021 , 55 (8 ): 1490 - 1499
[本文引用: 3]
CHEN Zhichao, JIAO Haining, YANG Jie, et al Garbage image classification algorithm based on improved MobileNet v2
[J]. Journal of Zhejiang University: Engineering Science , 2021 , 55 (8 ): 1490 - 1499
[本文引用: 3]
[10]
HOWARD A, SANDLER M, CHEN B, et al. Searching for MobileNetV3 [C]// Proceedings of the IEEE International Conference on Computer Vision . Seoul: IEEE, 2019: 1314-1324.
[本文引用: 2]
[11]
HE K , ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770-778.
[本文引用: 2]
[12]
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: transformers for image recognition at scale [EB/OL]. (2021-06-03) [2023-08-05]. https://arxiv.org/pdf/2010.11929.pdf.
[本文引用: 1]
[13]
MEHTA S, RASTEGARI M. MobileViT: light-weight, general-purpose, and mobile-friendly vision Transformer [EB/OL]. (2022-03-04) [2023-08-05]. https://arxiv.org/pdf/2110.02178.pdf.
[本文引用: 1]
[14]
SHELHAMER E, LONG J, DARRELL T Fully convolutional networks for semantic segmentation
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 39 (4 ): 640 - 651
DOI:10.1109/TPAMI.2016.2572683
[本文引用: 1]
[15]
DU B, ZHAO Z, HU X, et al Landslide susceptibility prediction based on image semantic segmentation
[J]. Computers and Geosciences , 2021 , 155 : 104860
DOI:10.1016/j.cageo.2021.104860
[本文引用: 2]
[16]
ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 6230-6239.
[本文引用: 3]
[17]
PAN H, HONG Y, SUN W, et al Deep dual-resolution networks for real-time and accurate semantic segmentation of traffic scenes
[J]. IEEE Transactions on Intelligent Transportation Systems , 2023 , 24 (3 ): 3448 - 3460
DOI:10.1109/TITS.2022.3228042
[本文引用: 2]
[18]
FAN M, LAI S, HUANG J, et al. Rethinking BiSeNet for real-time semantic segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 9711-9720.
[本文引用: 2]
[19]
YU C, GAO C, WANG J, et al BiSeNet V2: bilateral network with guided aggregation for real-time semantic segmentation
[J]. International Journal of Computer Vision , 2021 , 129 (11 ): 3051 - 3068
[本文引用: 2]
[20]
XU J, XIONG Z, BHATTACHARYYA, et al. PIDNet: a real-time semantic segmentation network inspired by PID controllers [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . [S. l. ]: IEEE, 2023: 19529-19539.
[本文引用: 2]
[21]
ZHOU L, ZHANG C, WU M. D-LinkNet: LinkNet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 192-196.
[本文引用: 1]
[22]
ZHU Q, ZHANG Y, WANG L, et al A global context-aware and batch-independent network for road extraction from VHR satellite imagery
[J]. ISPRS Journal of Photogrammetry and Remote Sensing , 2021 , 175 : 353 - 365
DOI:10.1016/j.isprsjprs.2021.03.016
[本文引用: 5]
[23]
DIAKOGIANNIS F, WALDNER F, CACCETTA P, et al ResUNet-a: a deep learning framework for semantic segmentation of remotely sensed data
[J]. ISPRS Journal of Photogrammetry and Remote Sensing , 2020 , 162 : 94 - 114
DOI:10.1016/j.isprsjprs.2020.01.013
[本文引用: 1]
[24]
吴仁哲, 蔡嘉伦, 刘国祥, 等 针对高分影像的RDU-Net乡村路网提取方法
[J]. 遥感信息 , 2021 , 36 (1 ): 29 - 36
[本文引用: 1]
WU Renzhe, CAI Jialun, LIU Guoxiang, et al Rural road network extraction for high resolution imagery using RDU-Net deep learning method
[J]. Remote Sensing Information , 2021 , 36 (1 ): 29 - 36
[本文引用: 1]
[25]
LI J, SUN B, LI S, et al Semisupervised semantic segmentation of remote sensing images with consistency self-training
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2022 , 60 : 1 - 11
[本文引用: 1]
[26]
YOU Z, WANG J, CHEN S, et al FMWDCT: foreground mixup into weighted dual-network cross training for semisupervised remote sensing road extraction
[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , 2022 , 15 : 5570 - 5579
DOI:10.1109/JSTARS.2022.3188025
[本文引用: 1]
[27]
SONG J, LI J, CHEN H, et al MapGen-GAN: a fast translator for remote sensing image to map via unsupervised adversarial learning
[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , 2021 , 14 : 2341 - 2357
DOI:10.1109/JSTARS.2021.3049905
[本文引用: 1]
[28]
YANG Y, ZHOU L SRP-YOLOX: an improved deep convolutional neural network for automated via detection
[J]. Microelectronics Reliability , 2023 , 147 : 115069
DOI:10.1016/j.microrel.2023.115069
[本文引用: 2]
[29]
SHI M, XIE F, YANG J, et al Cutout with patch-loss augmentation for improving generative adversarial networks against instability
[J]. Computer Vision and Image Understanding , 2023 , 234 : 103761
DOI:10.1016/j.cviu.2023.103761
[本文引用: 1]
[30]
YUN S, HAN D, CHEN S, et al. CutMix: regularization strategy to train strong classifiers with localizable features [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Seoul: IEEE, 2021: 6022-6031.
[本文引用: 1]
[31]
HE K, ZHANG X, REN S, et al Spatial pyramid pooling in deep convolutional networks for visual recognition
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2015 , 37 (9 ): 1904 - 1916
DOI:10.1109/TPAMI.2015.2389824
[本文引用: 1]
Road extraction from very high resolution images using weakly labeled OpenStreetMap centerline
1
2019
... 随着经济水平的提升和城市化进程的加快,城市路网体系日益庞大,道路提取是城市规划和决策的重要环节之一[1 -2 ] . 现有的道路提取方法主要依赖于手工标注,存在工作量大和效率低的问题[3 ] . ...
A review of motion planning for highway autonomous driving
1
2020
... 随着经济水平的提升和城市化进程的加快,城市路网体系日益庞大,道路提取是城市规划和决策的重要环节之一[1 -2 ] . 现有的道路提取方法主要依赖于手工标注,存在工作量大和效率低的问题[3 ] . ...
Road extraction from satellite images with iterative cross-task feature enhancement
1
2022
... 随着经济水平的提升和城市化进程的加快,城市路网体系日益庞大,道路提取是城市规划和决策的重要环节之一[1 -2 ] . 现有的道路提取方法主要依赖于手工标注,存在工作量大和效率低的问题[3 ] . ...
Remote sensing big data computing: challenges and opportunities
1
2015
... 随着诸多对地观测项目的实施,遥感图像取得了飞速发展[4 ] . 此外,语义分割技术[5 -6 ] 可以基于图像区分目标和背景,为道路自动提取提供技术支撑. 传统的语义分割方法大多先基于手工算子进行提取特征,再通过模板匹配或边缘检测捕获道路区域[7 -8 ] . 手工算子的选择需要丰富的先验知识,道路提取效果往往不佳. 基于深度学习的方法遵循编码器-解码器结构[6 ] ,可以通过学习的方式更新参数. 编码器用于提取图像的高级特征,大多为通用特征提取模型,例如基于卷积神经网络的MobileNet[9 -10 ] 和ResNet[11 ] 、基于视觉Transformer的Vision Transformer[12 ] 和MobileViT[13 ] . 解码器用于捕获不同层次的特征,提高特征利用率,实现像素分类. FCN[14 ] 基于全卷积神经网络实现语义分割,通过2个连续的卷积层实现像素分类. DeepLab V3[15 ] 在解码器中通过不同大小的空洞卷积捕获多尺度特征. 类似地,PSPNet[16 ] 和DDRNet[17 ] 基于不同大小的池化层提取多尺度特征,有效提升了分割性能. STDC[18 ] 、BiseNet V2[19 ] 和PIDNet[20 ] 使用多分支结构聚合不同层次的信息,在实时性和分割精度方面具有不错的表现. ...
基于多尺度互注意力的遥感图像语义分割网络
1
2023
... 随着诸多对地观测项目的实施,遥感图像取得了飞速发展[4 ] . 此外,语义分割技术[5 -6 ] 可以基于图像区分目标和背景,为道路自动提取提供技术支撑. 传统的语义分割方法大多先基于手工算子进行提取特征,再通过模板匹配或边缘检测捕获道路区域[7 -8 ] . 手工算子的选择需要丰富的先验知识,道路提取效果往往不佳. 基于深度学习的方法遵循编码器-解码器结构[6 ] ,可以通过学习的方式更新参数. 编码器用于提取图像的高级特征,大多为通用特征提取模型,例如基于卷积神经网络的MobileNet[9 -10 ] 和ResNet[11 ] 、基于视觉Transformer的Vision Transformer[12 ] 和MobileViT[13 ] . 解码器用于捕获不同层次的特征,提高特征利用率,实现像素分类. FCN[14 ] 基于全卷积神经网络实现语义分割,通过2个连续的卷积层实现像素分类. DeepLab V3[15 ] 在解码器中通过不同大小的空洞卷积捕获多尺度特征. 类似地,PSPNet[16 ] 和DDRNet[17 ] 基于不同大小的池化层提取多尺度特征,有效提升了分割性能. STDC[18 ] 、BiseNet V2[19 ] 和PIDNet[20 ] 使用多分支结构聚合不同层次的信息,在实时性和分割精度方面具有不错的表现. ...
基于多尺度互注意力的遥感图像语义分割网络
1
2023
... 随着诸多对地观测项目的实施,遥感图像取得了飞速发展[4 ] . 此外,语义分割技术[5 -6 ] 可以基于图像区分目标和背景,为道路自动提取提供技术支撑. 传统的语义分割方法大多先基于手工算子进行提取特征,再通过模板匹配或边缘检测捕获道路区域[7 -8 ] . 手工算子的选择需要丰富的先验知识,道路提取效果往往不佳. 基于深度学习的方法遵循编码器-解码器结构[6 ] ,可以通过学习的方式更新参数. 编码器用于提取图像的高级特征,大多为通用特征提取模型,例如基于卷积神经网络的MobileNet[9 -10 ] 和ResNet[11 ] 、基于视觉Transformer的Vision Transformer[12 ] 和MobileViT[13 ] . 解码器用于捕获不同层次的特征,提高特征利用率,实现像素分类. FCN[14 ] 基于全卷积神经网络实现语义分割,通过2个连续的卷积层实现像素分类. DeepLab V3[15 ] 在解码器中通过不同大小的空洞卷积捕获多尺度特征. 类似地,PSPNet[16 ] 和DDRNet[17 ] 基于不同大小的池化层提取多尺度特征,有效提升了分割性能. STDC[18 ] 、BiseNet V2[19 ] 和PIDNet[20 ] 使用多分支结构聚合不同层次的信息,在实时性和分割精度方面具有不错的表现. ...
SegNet: a deep convolutional encoder-decoder architecture for image segmentation
2
2017
... 随着诸多对地观测项目的实施,遥感图像取得了飞速发展[4 ] . 此外,语义分割技术[5 -6 ] 可以基于图像区分目标和背景,为道路自动提取提供技术支撑. 传统的语义分割方法大多先基于手工算子进行提取特征,再通过模板匹配或边缘检测捕获道路区域[7 -8 ] . 手工算子的选择需要丰富的先验知识,道路提取效果往往不佳. 基于深度学习的方法遵循编码器-解码器结构[6 ] ,可以通过学习的方式更新参数. 编码器用于提取图像的高级特征,大多为通用特征提取模型,例如基于卷积神经网络的MobileNet[9 -10 ] 和ResNet[11 ] 、基于视觉Transformer的Vision Transformer[12 ] 和MobileViT[13 ] . 解码器用于捕获不同层次的特征,提高特征利用率,实现像素分类. FCN[14 ] 基于全卷积神经网络实现语义分割,通过2个连续的卷积层实现像素分类. DeepLab V3[15 ] 在解码器中通过不同大小的空洞卷积捕获多尺度特征. 类似地,PSPNet[16 ] 和DDRNet[17 ] 基于不同大小的池化层提取多尺度特征,有效提升了分割性能. STDC[18 ] 、BiseNet V2[19 ] 和PIDNet[20 ] 使用多分支结构聚合不同层次的信息,在实时性和分割精度方面具有不错的表现. ...
... [6 ],可以通过学习的方式更新参数. 编码器用于提取图像的高级特征,大多为通用特征提取模型,例如基于卷积神经网络的MobileNet[9 -10 ] 和ResNet[11 ] 、基于视觉Transformer的Vision Transformer[12 ] 和MobileViT[13 ] . 解码器用于捕获不同层次的特征,提高特征利用率,实现像素分类. FCN[14 ] 基于全卷积神经网络实现语义分割,通过2个连续的卷积层实现像素分类. DeepLab V3[15 ] 在解码器中通过不同大小的空洞卷积捕获多尺度特征. 类似地,PSPNet[16 ] 和DDRNet[17 ] 基于不同大小的池化层提取多尺度特征,有效提升了分割性能. STDC[18 ] 、BiseNet V2[19 ] 和PIDNet[20 ] 使用多分支结构聚合不同层次的信息,在实时性和分割精度方面具有不错的表现. ...
Lane-level road extraction from high-resolution optical satellite images
1
2019
... 随着诸多对地观测项目的实施,遥感图像取得了飞速发展[4 ] . 此外,语义分割技术[5 -6 ] 可以基于图像区分目标和背景,为道路自动提取提供技术支撑. 传统的语义分割方法大多先基于手工算子进行提取特征,再通过模板匹配或边缘检测捕获道路区域[7 -8 ] . 手工算子的选择需要丰富的先验知识,道路提取效果往往不佳. 基于深度学习的方法遵循编码器-解码器结构[6 ] ,可以通过学习的方式更新参数. 编码器用于提取图像的高级特征,大多为通用特征提取模型,例如基于卷积神经网络的MobileNet[9 -10 ] 和ResNet[11 ] 、基于视觉Transformer的Vision Transformer[12 ] 和MobileViT[13 ] . 解码器用于捕获不同层次的特征,提高特征利用率,实现像素分类. FCN[14 ] 基于全卷积神经网络实现语义分割,通过2个连续的卷积层实现像素分类. DeepLab V3[15 ] 在解码器中通过不同大小的空洞卷积捕获多尺度特征. 类似地,PSPNet[16 ] 和DDRNet[17 ] 基于不同大小的池化层提取多尺度特征,有效提升了分割性能. STDC[18 ] 、BiseNet V2[19 ] 和PIDNet[20 ] 使用多分支结构聚合不同层次的信息,在实时性和分割精度方面具有不错的表现. ...
Road extraction from VHR remote-sensing imagery via object segmentation constrained by Gabor features
1
2018
... 随着诸多对地观测项目的实施,遥感图像取得了飞速发展[4 ] . 此外,语义分割技术[5 -6 ] 可以基于图像区分目标和背景,为道路自动提取提供技术支撑. 传统的语义分割方法大多先基于手工算子进行提取特征,再通过模板匹配或边缘检测捕获道路区域[7 -8 ] . 手工算子的选择需要丰富的先验知识,道路提取效果往往不佳. 基于深度学习的方法遵循编码器-解码器结构[6 ] ,可以通过学习的方式更新参数. 编码器用于提取图像的高级特征,大多为通用特征提取模型,例如基于卷积神经网络的MobileNet[9 -10 ] 和ResNet[11 ] 、基于视觉Transformer的Vision Transformer[12 ] 和MobileViT[13 ] . 解码器用于捕获不同层次的特征,提高特征利用率,实现像素分类. FCN[14 ] 基于全卷积神经网络实现语义分割,通过2个连续的卷积层实现像素分类. DeepLab V3[15 ] 在解码器中通过不同大小的空洞卷积捕获多尺度特征. 类似地,PSPNet[16 ] 和DDRNet[17 ] 基于不同大小的池化层提取多尺度特征,有效提升了分割性能. STDC[18 ] 、BiseNet V2[19 ] 和PIDNet[20 ] 使用多分支结构聚合不同层次的信息,在实时性和分割精度方面具有不错的表现. ...
基于改进MobileNet v2的垃圾图像分类算法
3
2021
... 随着诸多对地观测项目的实施,遥感图像取得了飞速发展[4 ] . 此外,语义分割技术[5 -6 ] 可以基于图像区分目标和背景,为道路自动提取提供技术支撑. 传统的语义分割方法大多先基于手工算子进行提取特征,再通过模板匹配或边缘检测捕获道路区域[7 -8 ] . 手工算子的选择需要丰富的先验知识,道路提取效果往往不佳. 基于深度学习的方法遵循编码器-解码器结构[6 ] ,可以通过学习的方式更新参数. 编码器用于提取图像的高级特征,大多为通用特征提取模型,例如基于卷积神经网络的MobileNet[9 -10 ] 和ResNet[11 ] 、基于视觉Transformer的Vision Transformer[12 ] 和MobileViT[13 ] . 解码器用于捕获不同层次的特征,提高特征利用率,实现像素分类. FCN[14 ] 基于全卷积神经网络实现语义分割,通过2个连续的卷积层实现像素分类. DeepLab V3[15 ] 在解码器中通过不同大小的空洞卷积捕获多尺度特征. 类似地,PSPNet[16 ] 和DDRNet[17 ] 基于不同大小的池化层提取多尺度特征,有效提升了分割性能. STDC[18 ] 、BiseNet V2[19 ] 和PIDNet[20 ] 使用多分支结构聚合不同层次的信息,在实时性和分割精度方面具有不错的表现. ...
... 在轻量级城市路网的提取任务中,编码器需要从输入图像中提取高级上下文信息,这要求编码器具有丰富的特征提取能力,并且保持轻量性. 选择了目前先进的MobileViT作为编码器,可以有效利用卷积神经网络的空间偏置特点和Transformer的全局信息处理能力,有效地加强特征提取性能. 在结构上,MobileViT由多个MV2模块和MobileViT模块堆叠而成,MV2模块是MobileNet V2[9 ] 提出的轻量级倒残差瓶颈单元,MobileViT模块是轻量、高效的视觉Transformer,核心部件如图2 所示. 图2 (a)中,e 为扩张系数. 图2 (b)中,输入X d×k ,Q K V k ×d h h ,d = d h h . ...
... Comparison of RoadViT and mainstream models on different datasets
Tab.3 模型 P /106 FLOPs/109 R IoU /% CHN6-CUG DeepGlobe数据集 PSPNet[16 ] (ResNet18[11 ] ) 12.92 67.51 57.1 57.7 DeepLab V3[15 ] (ResNet18) 13.60 85.97 57.6 58.6 PSPNet(MobileNet V2[9 ] ) 2.65 10.72 55.3 54.5 DeepLab V3(MobileNet V2) 3.23 22.61 53.6 55.4 LRASPP[10 ] 3.22 1.98 51.1 51.1 BiseNet V2[19 ] 3.62 12.80 56.4 51.8 STDC[18 ] 14.23 23.51 60.7 54.6 DDRNet[17 ] 20.15 17.87 61.0 54.8 PIDNet[20 ] 7.62 5.89 60.0 52.6 RoadViT 1.25 1.18 57.0 52.3 RoadViT-m 2.35 3.02 58.7 53.7 RoadViT-l 5.97 6.01 59.7 54.3 D-LinkNet[22 ] — — 55.7 — HsgNet[22 ] — — 57.7 —
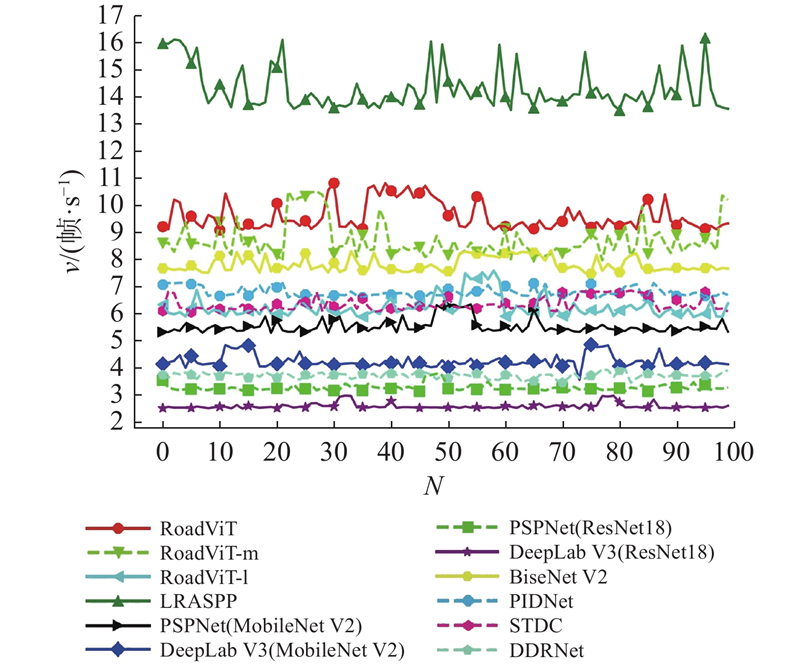
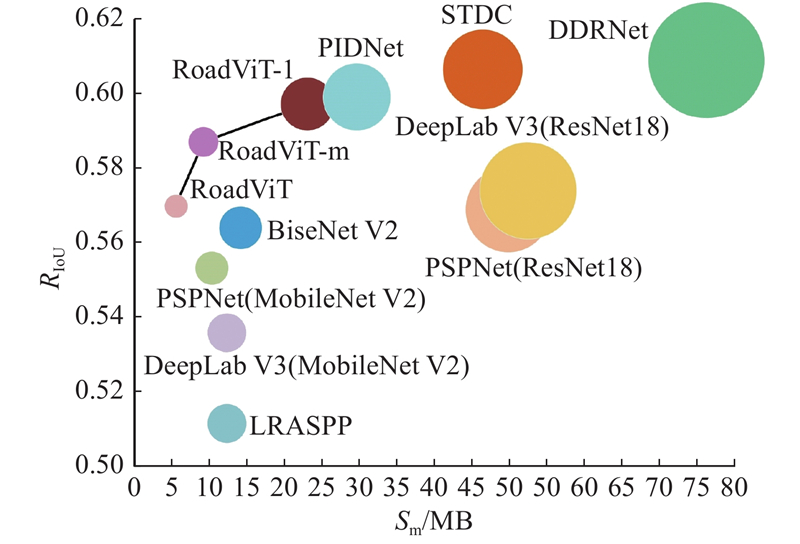
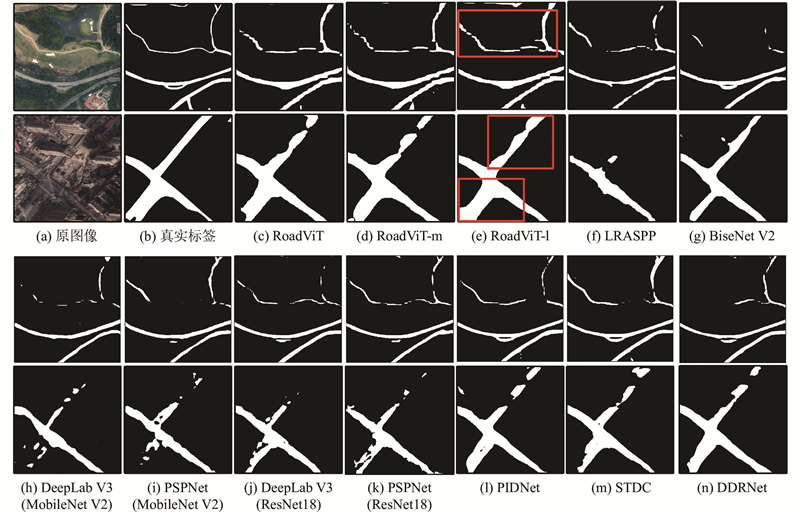
3.3.1. CHN6-CUG数据集 从表3 可知,RoadViT在保证轻量的前提下,R IoU 达到57.0%,参数量和FLOPs仅分别为1.25 × 106 和1.18 × 109 . 相比于轻量级模型LRASPP、DeepLab V3(MobileNet V2)和PSPNet(MobileNet V2)与大型模型D-LinkNet,RoadViT在模型的轻量性和精度上都更具优势. RoadViT的精度优于轻量级模型BiseNet V2,但参数量和FLOPs仅分别为BiseNet V2的34.5%和9.2%. 随着模型复杂度的增大,RoadViT-m和RoadViT-l的性能随之提升,R IoU 分别为58.7%和59.7%. DeepLab V3(ResNet18)和PSPNet(ResNet18)通过大型模型Resnet18实现特征提取,有效提升了分割性能,但具有繁多的参数和昂贵的计算开销. 相比之下,RoadViT-m的精度优于HsgNet、PSPNet(ResNet18)和DeepLab V3(ResNet18),但参数量仅分别为后两者的18.1%和17.3%,FLOPs分别为后两者的4.5%和3.5%. 与STDC和DDRNet相比,RoadViT-l的精度分别降低了约1%和1.3%,但具有更低的模型复杂度,参数量分别为它们的42%和30%,FLOPs分别为它们的26%和34%,有利于实时提取城市道路. RoadViT-l与PIDNet的计算复杂度相近,尽管RoadViT-l的精度略低,但参数量仅为PIDNet的78.3%. 综合考虑模型的轻量性和分割性能,RoadViT是兼顾模型复杂度和精度的城市道路提取模型,可以应用于持续工作的机载设备和资源有限的场景,对城市路网建设具有积极意义. ...
基于改进MobileNet v2的垃圾图像分类算法
3
2021
... 随着诸多对地观测项目的实施,遥感图像取得了飞速发展[4 ] . 此外,语义分割技术[5 -6 ] 可以基于图像区分目标和背景,为道路自动提取提供技术支撑. 传统的语义分割方法大多先基于手工算子进行提取特征,再通过模板匹配或边缘检测捕获道路区域[7 -8 ] . 手工算子的选择需要丰富的先验知识,道路提取效果往往不佳. 基于深度学习的方法遵循编码器-解码器结构[6 ] ,可以通过学习的方式更新参数. 编码器用于提取图像的高级特征,大多为通用特征提取模型,例如基于卷积神经网络的MobileNet[9 -10 ] 和ResNet[11 ] 、基于视觉Transformer的Vision Transformer[12 ] 和MobileViT[13 ] . 解码器用于捕获不同层次的特征,提高特征利用率,实现像素分类. FCN[14 ] 基于全卷积神经网络实现语义分割,通过2个连续的卷积层实现像素分类. DeepLab V3[15 ] 在解码器中通过不同大小的空洞卷积捕获多尺度特征. 类似地,PSPNet[16 ] 和DDRNet[17 ] 基于不同大小的池化层提取多尺度特征,有效提升了分割性能. STDC[18 ] 、BiseNet V2[19 ] 和PIDNet[20 ] 使用多分支结构聚合不同层次的信息,在实时性和分割精度方面具有不错的表现. ...
... 在轻量级城市路网的提取任务中,编码器需要从输入图像中提取高级上下文信息,这要求编码器具有丰富的特征提取能力,并且保持轻量性. 选择了目前先进的MobileViT作为编码器,可以有效利用卷积神经网络的空间偏置特点和Transformer的全局信息处理能力,有效地加强特征提取性能. 在结构上,MobileViT由多个MV2模块和MobileViT模块堆叠而成,MV2模块是MobileNet V2[9 ] 提出的轻量级倒残差瓶颈单元,MobileViT模块是轻量、高效的视觉Transformer,核心部件如图2 所示. 图2 (a)中,e 为扩张系数. 图2 (b)中,输入X d×k ,Q K V k ×d h h ,d = d h h . ...
... Comparison of RoadViT and mainstream models on different datasets
Tab.3 模型 P /106 FLOPs/109 R IoU /% CHN6-CUG DeepGlobe数据集 PSPNet[16 ] (ResNet18[11 ] ) 12.92 67.51 57.1 57.7 DeepLab V3[15 ] (ResNet18) 13.60 85.97 57.6 58.6 PSPNet(MobileNet V2[9 ] ) 2.65 10.72 55.3 54.5 DeepLab V3(MobileNet V2) 3.23 22.61 53.6 55.4 LRASPP[10 ] 3.22 1.98 51.1 51.1 BiseNet V2[19 ] 3.62 12.80 56.4 51.8 STDC[18 ] 14.23 23.51 60.7 54.6 DDRNet[17 ] 20.15 17.87 61.0 54.8 PIDNet[20 ] 7.62 5.89 60.0 52.6 RoadViT 1.25 1.18 57.0 52.3 RoadViT-m 2.35 3.02 58.7 53.7 RoadViT-l 5.97 6.01 59.7 54.3 D-LinkNet[22 ] — — 55.7 — HsgNet[22 ] — — 57.7 —
3.3.1. CHN6-CUG数据集 从表3 可知,RoadViT在保证轻量的前提下,R IoU 达到57.0%,参数量和FLOPs仅分别为1.25 × 106 和1.18 × 109 . 相比于轻量级模型LRASPP、DeepLab V3(MobileNet V2)和PSPNet(MobileNet V2)与大型模型D-LinkNet,RoadViT在模型的轻量性和精度上都更具优势. RoadViT的精度优于轻量级模型BiseNet V2,但参数量和FLOPs仅分别为BiseNet V2的34.5%和9.2%. 随着模型复杂度的增大,RoadViT-m和RoadViT-l的性能随之提升,R IoU 分别为58.7%和59.7%. DeepLab V3(ResNet18)和PSPNet(ResNet18)通过大型模型Resnet18实现特征提取,有效提升了分割性能,但具有繁多的参数和昂贵的计算开销. 相比之下,RoadViT-m的精度优于HsgNet、PSPNet(ResNet18)和DeepLab V3(ResNet18),但参数量仅分别为后两者的18.1%和17.3%,FLOPs分别为后两者的4.5%和3.5%. 与STDC和DDRNet相比,RoadViT-l的精度分别降低了约1%和1.3%,但具有更低的模型复杂度,参数量分别为它们的42%和30%,FLOPs分别为它们的26%和34%,有利于实时提取城市道路. RoadViT-l与PIDNet的计算复杂度相近,尽管RoadViT-l的精度略低,但参数量仅为PIDNet的78.3%. 综合考虑模型的轻量性和分割性能,RoadViT是兼顾模型复杂度和精度的城市道路提取模型,可以应用于持续工作的机载设备和资源有限的场景,对城市路网建设具有积极意义. ...
2
... 随着诸多对地观测项目的实施,遥感图像取得了飞速发展[4 ] . 此外,语义分割技术[5 -6 ] 可以基于图像区分目标和背景,为道路自动提取提供技术支撑. 传统的语义分割方法大多先基于手工算子进行提取特征,再通过模板匹配或边缘检测捕获道路区域[7 -8 ] . 手工算子的选择需要丰富的先验知识,道路提取效果往往不佳. 基于深度学习的方法遵循编码器-解码器结构[6 ] ,可以通过学习的方式更新参数. 编码器用于提取图像的高级特征,大多为通用特征提取模型,例如基于卷积神经网络的MobileNet[9 -10 ] 和ResNet[11 ] 、基于视觉Transformer的Vision Transformer[12 ] 和MobileViT[13 ] . 解码器用于捕获不同层次的特征,提高特征利用率,实现像素分类. FCN[14 ] 基于全卷积神经网络实现语义分割,通过2个连续的卷积层实现像素分类. DeepLab V3[15 ] 在解码器中通过不同大小的空洞卷积捕获多尺度特征. 类似地,PSPNet[16 ] 和DDRNet[17 ] 基于不同大小的池化层提取多尺度特征,有效提升了分割性能. STDC[18 ] 、BiseNet V2[19 ] 和PIDNet[20 ] 使用多分支结构聚合不同层次的信息,在实时性和分割精度方面具有不错的表现. ...
... Comparison of RoadViT and mainstream models on different datasets
Tab.3 模型 P /106 FLOPs/109 R IoU /% CHN6-CUG DeepGlobe数据集 PSPNet[16 ] (ResNet18[11 ] ) 12.92 67.51 57.1 57.7 DeepLab V3[15 ] (ResNet18) 13.60 85.97 57.6 58.6 PSPNet(MobileNet V2[9 ] ) 2.65 10.72 55.3 54.5 DeepLab V3(MobileNet V2) 3.23 22.61 53.6 55.4 LRASPP[10 ] 3.22 1.98 51.1 51.1 BiseNet V2[19 ] 3.62 12.80 56.4 51.8 STDC[18 ] 14.23 23.51 60.7 54.6 DDRNet[17 ] 20.15 17.87 61.0 54.8 PIDNet[20 ] 7.62 5.89 60.0 52.6 RoadViT 1.25 1.18 57.0 52.3 RoadViT-m 2.35 3.02 58.7 53.7 RoadViT-l 5.97 6.01 59.7 54.3 D-LinkNet[22 ] — — 55.7 — HsgNet[22 ] — — 57.7 —
3.3.1. CHN6-CUG数据集 从表3 可知,RoadViT在保证轻量的前提下,R IoU 达到57.0%,参数量和FLOPs仅分别为1.25 × 106 和1.18 × 109 . 相比于轻量级模型LRASPP、DeepLab V3(MobileNet V2)和PSPNet(MobileNet V2)与大型模型D-LinkNet,RoadViT在模型的轻量性和精度上都更具优势. RoadViT的精度优于轻量级模型BiseNet V2,但参数量和FLOPs仅分别为BiseNet V2的34.5%和9.2%. 随着模型复杂度的增大,RoadViT-m和RoadViT-l的性能随之提升,R IoU 分别为58.7%和59.7%. DeepLab V3(ResNet18)和PSPNet(ResNet18)通过大型模型Resnet18实现特征提取,有效提升了分割性能,但具有繁多的参数和昂贵的计算开销. 相比之下,RoadViT-m的精度优于HsgNet、PSPNet(ResNet18)和DeepLab V3(ResNet18),但参数量仅分别为后两者的18.1%和17.3%,FLOPs分别为后两者的4.5%和3.5%. 与STDC和DDRNet相比,RoadViT-l的精度分别降低了约1%和1.3%,但具有更低的模型复杂度,参数量分别为它们的42%和30%,FLOPs分别为它们的26%和34%,有利于实时提取城市道路. RoadViT-l与PIDNet的计算复杂度相近,尽管RoadViT-l的精度略低,但参数量仅为PIDNet的78.3%. 综合考虑模型的轻量性和分割性能,RoadViT是兼顾模型复杂度和精度的城市道路提取模型,可以应用于持续工作的机载设备和资源有限的场景,对城市路网建设具有积极意义. ...
2
... 随着诸多对地观测项目的实施,遥感图像取得了飞速发展[4 ] . 此外,语义分割技术[5 -6 ] 可以基于图像区分目标和背景,为道路自动提取提供技术支撑. 传统的语义分割方法大多先基于手工算子进行提取特征,再通过模板匹配或边缘检测捕获道路区域[7 -8 ] . 手工算子的选择需要丰富的先验知识,道路提取效果往往不佳. 基于深度学习的方法遵循编码器-解码器结构[6 ] ,可以通过学习的方式更新参数. 编码器用于提取图像的高级特征,大多为通用特征提取模型,例如基于卷积神经网络的MobileNet[9 -10 ] 和ResNet[11 ] 、基于视觉Transformer的Vision Transformer[12 ] 和MobileViT[13 ] . 解码器用于捕获不同层次的特征,提高特征利用率,实现像素分类. FCN[14 ] 基于全卷积神经网络实现语义分割,通过2个连续的卷积层实现像素分类. DeepLab V3[15 ] 在解码器中通过不同大小的空洞卷积捕获多尺度特征. 类似地,PSPNet[16 ] 和DDRNet[17 ] 基于不同大小的池化层提取多尺度特征,有效提升了分割性能. STDC[18 ] 、BiseNet V2[19 ] 和PIDNet[20 ] 使用多分支结构聚合不同层次的信息,在实时性和分割精度方面具有不错的表现. ...
... Comparison of RoadViT and mainstream models on different datasets
Tab.3 模型 P /106 FLOPs/109 R IoU /% CHN6-CUG DeepGlobe数据集 PSPNet[16 ] (ResNet18[11 ] ) 12.92 67.51 57.1 57.7 DeepLab V3[15 ] (ResNet18) 13.60 85.97 57.6 58.6 PSPNet(MobileNet V2[9 ] ) 2.65 10.72 55.3 54.5 DeepLab V3(MobileNet V2) 3.23 22.61 53.6 55.4 LRASPP[10 ] 3.22 1.98 51.1 51.1 BiseNet V2[19 ] 3.62 12.80 56.4 51.8 STDC[18 ] 14.23 23.51 60.7 54.6 DDRNet[17 ] 20.15 17.87 61.0 54.8 PIDNet[20 ] 7.62 5.89 60.0 52.6 RoadViT 1.25 1.18 57.0 52.3 RoadViT-m 2.35 3.02 58.7 53.7 RoadViT-l 5.97 6.01 59.7 54.3 D-LinkNet[22 ] — — 55.7 — HsgNet[22 ] — — 57.7 —
3.3.1. CHN6-CUG数据集 从表3 可知,RoadViT在保证轻量的前提下,R IoU 达到57.0%,参数量和FLOPs仅分别为1.25 × 106 和1.18 × 109 . 相比于轻量级模型LRASPP、DeepLab V3(MobileNet V2)和PSPNet(MobileNet V2)与大型模型D-LinkNet,RoadViT在模型的轻量性和精度上都更具优势. RoadViT的精度优于轻量级模型BiseNet V2,但参数量和FLOPs仅分别为BiseNet V2的34.5%和9.2%. 随着模型复杂度的增大,RoadViT-m和RoadViT-l的性能随之提升,R IoU 分别为58.7%和59.7%. DeepLab V3(ResNet18)和PSPNet(ResNet18)通过大型模型Resnet18实现特征提取,有效提升了分割性能,但具有繁多的参数和昂贵的计算开销. 相比之下,RoadViT-m的精度优于HsgNet、PSPNet(ResNet18)和DeepLab V3(ResNet18),但参数量仅分别为后两者的18.1%和17.3%,FLOPs分别为后两者的4.5%和3.5%. 与STDC和DDRNet相比,RoadViT-l的精度分别降低了约1%和1.3%,但具有更低的模型复杂度,参数量分别为它们的42%和30%,FLOPs分别为它们的26%和34%,有利于实时提取城市道路. RoadViT-l与PIDNet的计算复杂度相近,尽管RoadViT-l的精度略低,但参数量仅为PIDNet的78.3%. 综合考虑模型的轻量性和分割性能,RoadViT是兼顾模型复杂度和精度的城市道路提取模型,可以应用于持续工作的机载设备和资源有限的场景,对城市路网建设具有积极意义. ...
1
... 随着诸多对地观测项目的实施,遥感图像取得了飞速发展[4 ] . 此外,语义分割技术[5 -6 ] 可以基于图像区分目标和背景,为道路自动提取提供技术支撑. 传统的语义分割方法大多先基于手工算子进行提取特征,再通过模板匹配或边缘检测捕获道路区域[7 -8 ] . 手工算子的选择需要丰富的先验知识,道路提取效果往往不佳. 基于深度学习的方法遵循编码器-解码器结构[6 ] ,可以通过学习的方式更新参数. 编码器用于提取图像的高级特征,大多为通用特征提取模型,例如基于卷积神经网络的MobileNet[9 -10 ] 和ResNet[11 ] 、基于视觉Transformer的Vision Transformer[12 ] 和MobileViT[13 ] . 解码器用于捕获不同层次的特征,提高特征利用率,实现像素分类. FCN[14 ] 基于全卷积神经网络实现语义分割,通过2个连续的卷积层实现像素分类. DeepLab V3[15 ] 在解码器中通过不同大小的空洞卷积捕获多尺度特征. 类似地,PSPNet[16 ] 和DDRNet[17 ] 基于不同大小的池化层提取多尺度特征,有效提升了分割性能. STDC[18 ] 、BiseNet V2[19 ] 和PIDNet[20 ] 使用多分支结构聚合不同层次的信息,在实时性和分割精度方面具有不错的表现. ...
1
... 随着诸多对地观测项目的实施,遥感图像取得了飞速发展[4 ] . 此外,语义分割技术[5 -6 ] 可以基于图像区分目标和背景,为道路自动提取提供技术支撑. 传统的语义分割方法大多先基于手工算子进行提取特征,再通过模板匹配或边缘检测捕获道路区域[7 -8 ] . 手工算子的选择需要丰富的先验知识,道路提取效果往往不佳. 基于深度学习的方法遵循编码器-解码器结构[6 ] ,可以通过学习的方式更新参数. 编码器用于提取图像的高级特征,大多为通用特征提取模型,例如基于卷积神经网络的MobileNet[9 -10 ] 和ResNet[11 ] 、基于视觉Transformer的Vision Transformer[12 ] 和MobileViT[13 ] . 解码器用于捕获不同层次的特征,提高特征利用率,实现像素分类. FCN[14 ] 基于全卷积神经网络实现语义分割,通过2个连续的卷积层实现像素分类. DeepLab V3[15 ] 在解码器中通过不同大小的空洞卷积捕获多尺度特征. 类似地,PSPNet[16 ] 和DDRNet[17 ] 基于不同大小的池化层提取多尺度特征,有效提升了分割性能. STDC[18 ] 、BiseNet V2[19 ] 和PIDNet[20 ] 使用多分支结构聚合不同层次的信息,在实时性和分割精度方面具有不错的表现. ...
Fully convolutional networks for semantic segmentation
1
2017
... 随着诸多对地观测项目的实施,遥感图像取得了飞速发展[4 ] . 此外,语义分割技术[5 -6 ] 可以基于图像区分目标和背景,为道路自动提取提供技术支撑. 传统的语义分割方法大多先基于手工算子进行提取特征,再通过模板匹配或边缘检测捕获道路区域[7 -8 ] . 手工算子的选择需要丰富的先验知识,道路提取效果往往不佳. 基于深度学习的方法遵循编码器-解码器结构[6 ] ,可以通过学习的方式更新参数. 编码器用于提取图像的高级特征,大多为通用特征提取模型,例如基于卷积神经网络的MobileNet[9 -10 ] 和ResNet[11 ] 、基于视觉Transformer的Vision Transformer[12 ] 和MobileViT[13 ] . 解码器用于捕获不同层次的特征,提高特征利用率,实现像素分类. FCN[14 ] 基于全卷积神经网络实现语义分割,通过2个连续的卷积层实现像素分类. DeepLab V3[15 ] 在解码器中通过不同大小的空洞卷积捕获多尺度特征. 类似地,PSPNet[16 ] 和DDRNet[17 ] 基于不同大小的池化层提取多尺度特征,有效提升了分割性能. STDC[18 ] 、BiseNet V2[19 ] 和PIDNet[20 ] 使用多分支结构聚合不同层次的信息,在实时性和分割精度方面具有不错的表现. ...
Landslide susceptibility prediction based on image semantic segmentation
2
2021
... 随着诸多对地观测项目的实施,遥感图像取得了飞速发展[4 ] . 此外,语义分割技术[5 -6 ] 可以基于图像区分目标和背景,为道路自动提取提供技术支撑. 传统的语义分割方法大多先基于手工算子进行提取特征,再通过模板匹配或边缘检测捕获道路区域[7 -8 ] . 手工算子的选择需要丰富的先验知识,道路提取效果往往不佳. 基于深度学习的方法遵循编码器-解码器结构[6 ] ,可以通过学习的方式更新参数. 编码器用于提取图像的高级特征,大多为通用特征提取模型,例如基于卷积神经网络的MobileNet[9 -10 ] 和ResNet[11 ] 、基于视觉Transformer的Vision Transformer[12 ] 和MobileViT[13 ] . 解码器用于捕获不同层次的特征,提高特征利用率,实现像素分类. FCN[14 ] 基于全卷积神经网络实现语义分割,通过2个连续的卷积层实现像素分类. DeepLab V3[15 ] 在解码器中通过不同大小的空洞卷积捕获多尺度特征. 类似地,PSPNet[16 ] 和DDRNet[17 ] 基于不同大小的池化层提取多尺度特征,有效提升了分割性能. STDC[18 ] 、BiseNet V2[19 ] 和PIDNet[20 ] 使用多分支结构聚合不同层次的信息,在实时性和分割精度方面具有不错的表现. ...
... Comparison of RoadViT and mainstream models on different datasets
Tab.3 模型 P /106 FLOPs/109 R IoU /% CHN6-CUG DeepGlobe数据集 PSPNet[16 ] (ResNet18[11 ] ) 12.92 67.51 57.1 57.7 DeepLab V3[15 ] (ResNet18) 13.60 85.97 57.6 58.6 PSPNet(MobileNet V2[9 ] ) 2.65 10.72 55.3 54.5 DeepLab V3(MobileNet V2) 3.23 22.61 53.6 55.4 LRASPP[10 ] 3.22 1.98 51.1 51.1 BiseNet V2[19 ] 3.62 12.80 56.4 51.8 STDC[18 ] 14.23 23.51 60.7 54.6 DDRNet[17 ] 20.15 17.87 61.0 54.8 PIDNet[20 ] 7.62 5.89 60.0 52.6 RoadViT 1.25 1.18 57.0 52.3 RoadViT-m 2.35 3.02 58.7 53.7 RoadViT-l 5.97 6.01 59.7 54.3 D-LinkNet[22 ] — — 55.7 — HsgNet[22 ] — — 57.7 —
3.3.1. CHN6-CUG数据集 从表3 可知,RoadViT在保证轻量的前提下,R IoU 达到57.0%,参数量和FLOPs仅分别为1.25 × 106 和1.18 × 109 . 相比于轻量级模型LRASPP、DeepLab V3(MobileNet V2)和PSPNet(MobileNet V2)与大型模型D-LinkNet,RoadViT在模型的轻量性和精度上都更具优势. RoadViT的精度优于轻量级模型BiseNet V2,但参数量和FLOPs仅分别为BiseNet V2的34.5%和9.2%. 随着模型复杂度的增大,RoadViT-m和RoadViT-l的性能随之提升,R IoU 分别为58.7%和59.7%. DeepLab V3(ResNet18)和PSPNet(ResNet18)通过大型模型Resnet18实现特征提取,有效提升了分割性能,但具有繁多的参数和昂贵的计算开销. 相比之下,RoadViT-m的精度优于HsgNet、PSPNet(ResNet18)和DeepLab V3(ResNet18),但参数量仅分别为后两者的18.1%和17.3%,FLOPs分别为后两者的4.5%和3.5%. 与STDC和DDRNet相比,RoadViT-l的精度分别降低了约1%和1.3%,但具有更低的模型复杂度,参数量分别为它们的42%和30%,FLOPs分别为它们的26%和34%,有利于实时提取城市道路. RoadViT-l与PIDNet的计算复杂度相近,尽管RoadViT-l的精度略低,但参数量仅为PIDNet的78.3%. 综合考虑模型的轻量性和分割性能,RoadViT是兼顾模型复杂度和精度的城市道路提取模型,可以应用于持续工作的机载设备和资源有限的场景,对城市路网建设具有积极意义. ...
3
... 随着诸多对地观测项目的实施,遥感图像取得了飞速发展[4 ] . 此外,语义分割技术[5 -6 ] 可以基于图像区分目标和背景,为道路自动提取提供技术支撑. 传统的语义分割方法大多先基于手工算子进行提取特征,再通过模板匹配或边缘检测捕获道路区域[7 -8 ] . 手工算子的选择需要丰富的先验知识,道路提取效果往往不佳. 基于深度学习的方法遵循编码器-解码器结构[6 ] ,可以通过学习的方式更新参数. 编码器用于提取图像的高级特征,大多为通用特征提取模型,例如基于卷积神经网络的MobileNet[9 -10 ] 和ResNet[11 ] 、基于视觉Transformer的Vision Transformer[12 ] 和MobileViT[13 ] . 解码器用于捕获不同层次的特征,提高特征利用率,实现像素分类. FCN[14 ] 基于全卷积神经网络实现语义分割,通过2个连续的卷积层实现像素分类. DeepLab V3[15 ] 在解码器中通过不同大小的空洞卷积捕获多尺度特征. 类似地,PSPNet[16 ] 和DDRNet[17 ] 基于不同大小的池化层提取多尺度特征,有效提升了分割性能. STDC[18 ] 、BiseNet V2[19 ] 和PIDNet[20 ] 使用多分支结构聚合不同层次的信息,在实时性和分割精度方面具有不错的表现. ...
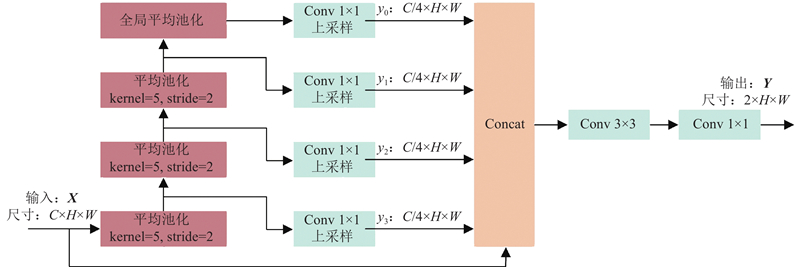
... 在语义分割任务中,解码器需要还原高级上下文信息,以预测每个像素的概率分布. 卷积神经网络的实际感受野远小于理论感受野,使得基于卷积神经网络的语义分割模型无法捕获足够的上下文信息[16 ] . 设计金字塔解码器,通过串行多个平均池化实现下采样和多尺度信息捕获,有效提升模型的感受野和上下文信息的利用率,结构如图3 所示. 通过池化核为5和步长为2的平均池化实现串行下采样,捕获多尺度上下文信息,通过全局平均池化获取全局上下文信息. 使用1×1卷积实现信息融合和通道压缩,经过双线性插值将特征图上采样至输入尺寸. 在通道维度将多尺度特征进行拼接,通过跳跃连接维持高级上下文信息的权重. 通过3×3卷积和1×1卷积,实现信息融合和像素类别的概率分布生成. ...
... Comparison of RoadViT and mainstream models on different datasets
Tab.3 模型 P /106 FLOPs/109 R IoU /% CHN6-CUG DeepGlobe数据集 PSPNet[16 ] (ResNet18[11 ] ) 12.92 67.51 57.1 57.7 DeepLab V3[15 ] (ResNet18) 13.60 85.97 57.6 58.6 PSPNet(MobileNet V2[9 ] ) 2.65 10.72 55.3 54.5 DeepLab V3(MobileNet V2) 3.23 22.61 53.6 55.4 LRASPP[10 ] 3.22 1.98 51.1 51.1 BiseNet V2[19 ] 3.62 12.80 56.4 51.8 STDC[18 ] 14.23 23.51 60.7 54.6 DDRNet[17 ] 20.15 17.87 61.0 54.8 PIDNet[20 ] 7.62 5.89 60.0 52.6 RoadViT 1.25 1.18 57.0 52.3 RoadViT-m 2.35 3.02 58.7 53.7 RoadViT-l 5.97 6.01 59.7 54.3 D-LinkNet[22 ] — — 55.7 — HsgNet[22 ] — — 57.7 —
3.3.1. CHN6-CUG数据集 从表3 可知,RoadViT在保证轻量的前提下,R IoU 达到57.0%,参数量和FLOPs仅分别为1.25 × 106 和1.18 × 109 . 相比于轻量级模型LRASPP、DeepLab V3(MobileNet V2)和PSPNet(MobileNet V2)与大型模型D-LinkNet,RoadViT在模型的轻量性和精度上都更具优势. RoadViT的精度优于轻量级模型BiseNet V2,但参数量和FLOPs仅分别为BiseNet V2的34.5%和9.2%. 随着模型复杂度的增大,RoadViT-m和RoadViT-l的性能随之提升,R IoU 分别为58.7%和59.7%. DeepLab V3(ResNet18)和PSPNet(ResNet18)通过大型模型Resnet18实现特征提取,有效提升了分割性能,但具有繁多的参数和昂贵的计算开销. 相比之下,RoadViT-m的精度优于HsgNet、PSPNet(ResNet18)和DeepLab V3(ResNet18),但参数量仅分别为后两者的18.1%和17.3%,FLOPs分别为后两者的4.5%和3.5%. 与STDC和DDRNet相比,RoadViT-l的精度分别降低了约1%和1.3%,但具有更低的模型复杂度,参数量分别为它们的42%和30%,FLOPs分别为它们的26%和34%,有利于实时提取城市道路. RoadViT-l与PIDNet的计算复杂度相近,尽管RoadViT-l的精度略低,但参数量仅为PIDNet的78.3%. 综合考虑模型的轻量性和分割性能,RoadViT是兼顾模型复杂度和精度的城市道路提取模型,可以应用于持续工作的机载设备和资源有限的场景,对城市路网建设具有积极意义. ...
Deep dual-resolution networks for real-time and accurate semantic segmentation of traffic scenes
2
2023
... 随着诸多对地观测项目的实施,遥感图像取得了飞速发展[4 ] . 此外,语义分割技术[5 -6 ] 可以基于图像区分目标和背景,为道路自动提取提供技术支撑. 传统的语义分割方法大多先基于手工算子进行提取特征,再通过模板匹配或边缘检测捕获道路区域[7 -8 ] . 手工算子的选择需要丰富的先验知识,道路提取效果往往不佳. 基于深度学习的方法遵循编码器-解码器结构[6 ] ,可以通过学习的方式更新参数. 编码器用于提取图像的高级特征,大多为通用特征提取模型,例如基于卷积神经网络的MobileNet[9 -10 ] 和ResNet[11 ] 、基于视觉Transformer的Vision Transformer[12 ] 和MobileViT[13 ] . 解码器用于捕获不同层次的特征,提高特征利用率,实现像素分类. FCN[14 ] 基于全卷积神经网络实现语义分割,通过2个连续的卷积层实现像素分类. DeepLab V3[15 ] 在解码器中通过不同大小的空洞卷积捕获多尺度特征. 类似地,PSPNet[16 ] 和DDRNet[17 ] 基于不同大小的池化层提取多尺度特征,有效提升了分割性能. STDC[18 ] 、BiseNet V2[19 ] 和PIDNet[20 ] 使用多分支结构聚合不同层次的信息,在实时性和分割精度方面具有不错的表现. ...
... Comparison of RoadViT and mainstream models on different datasets
Tab.3 模型 P /106 FLOPs/109 R IoU /% CHN6-CUG DeepGlobe数据集 PSPNet[16 ] (ResNet18[11 ] ) 12.92 67.51 57.1 57.7 DeepLab V3[15 ] (ResNet18) 13.60 85.97 57.6 58.6 PSPNet(MobileNet V2[9 ] ) 2.65 10.72 55.3 54.5 DeepLab V3(MobileNet V2) 3.23 22.61 53.6 55.4 LRASPP[10 ] 3.22 1.98 51.1 51.1 BiseNet V2[19 ] 3.62 12.80 56.4 51.8 STDC[18 ] 14.23 23.51 60.7 54.6 DDRNet[17 ] 20.15 17.87 61.0 54.8 PIDNet[20 ] 7.62 5.89 60.0 52.6 RoadViT 1.25 1.18 57.0 52.3 RoadViT-m 2.35 3.02 58.7 53.7 RoadViT-l 5.97 6.01 59.7 54.3 D-LinkNet[22 ] — — 55.7 — HsgNet[22 ] — — 57.7 —
3.3.1. CHN6-CUG数据集 从表3 可知,RoadViT在保证轻量的前提下,R IoU 达到57.0%,参数量和FLOPs仅分别为1.25 × 106 和1.18 × 109 . 相比于轻量级模型LRASPP、DeepLab V3(MobileNet V2)和PSPNet(MobileNet V2)与大型模型D-LinkNet,RoadViT在模型的轻量性和精度上都更具优势. RoadViT的精度优于轻量级模型BiseNet V2,但参数量和FLOPs仅分别为BiseNet V2的34.5%和9.2%. 随着模型复杂度的增大,RoadViT-m和RoadViT-l的性能随之提升,R IoU 分别为58.7%和59.7%. DeepLab V3(ResNet18)和PSPNet(ResNet18)通过大型模型Resnet18实现特征提取,有效提升了分割性能,但具有繁多的参数和昂贵的计算开销. 相比之下,RoadViT-m的精度优于HsgNet、PSPNet(ResNet18)和DeepLab V3(ResNet18),但参数量仅分别为后两者的18.1%和17.3%,FLOPs分别为后两者的4.5%和3.5%. 与STDC和DDRNet相比,RoadViT-l的精度分别降低了约1%和1.3%,但具有更低的模型复杂度,参数量分别为它们的42%和30%,FLOPs分别为它们的26%和34%,有利于实时提取城市道路. RoadViT-l与PIDNet的计算复杂度相近,尽管RoadViT-l的精度略低,但参数量仅为PIDNet的78.3%. 综合考虑模型的轻量性和分割性能,RoadViT是兼顾模型复杂度和精度的城市道路提取模型,可以应用于持续工作的机载设备和资源有限的场景,对城市路网建设具有积极意义. ...
2
... 随着诸多对地观测项目的实施,遥感图像取得了飞速发展[4 ] . 此外,语义分割技术[5 -6 ] 可以基于图像区分目标和背景,为道路自动提取提供技术支撑. 传统的语义分割方法大多先基于手工算子进行提取特征,再通过模板匹配或边缘检测捕获道路区域[7 -8 ] . 手工算子的选择需要丰富的先验知识,道路提取效果往往不佳. 基于深度学习的方法遵循编码器-解码器结构[6 ] ,可以通过学习的方式更新参数. 编码器用于提取图像的高级特征,大多为通用特征提取模型,例如基于卷积神经网络的MobileNet[9 -10 ] 和ResNet[11 ] 、基于视觉Transformer的Vision Transformer[12 ] 和MobileViT[13 ] . 解码器用于捕获不同层次的特征,提高特征利用率,实现像素分类. FCN[14 ] 基于全卷积神经网络实现语义分割,通过2个连续的卷积层实现像素分类. DeepLab V3[15 ] 在解码器中通过不同大小的空洞卷积捕获多尺度特征. 类似地,PSPNet[16 ] 和DDRNet[17 ] 基于不同大小的池化层提取多尺度特征,有效提升了分割性能. STDC[18 ] 、BiseNet V2[19 ] 和PIDNet[20 ] 使用多分支结构聚合不同层次的信息,在实时性和分割精度方面具有不错的表现. ...
... Comparison of RoadViT and mainstream models on different datasets
Tab.3 模型 P /106 FLOPs/109 R IoU /% CHN6-CUG DeepGlobe数据集 PSPNet[16 ] (ResNet18[11 ] ) 12.92 67.51 57.1 57.7 DeepLab V3[15 ] (ResNet18) 13.60 85.97 57.6 58.6 PSPNet(MobileNet V2[9 ] ) 2.65 10.72 55.3 54.5 DeepLab V3(MobileNet V2) 3.23 22.61 53.6 55.4 LRASPP[10 ] 3.22 1.98 51.1 51.1 BiseNet V2[19 ] 3.62 12.80 56.4 51.8 STDC[18 ] 14.23 23.51 60.7 54.6 DDRNet[17 ] 20.15 17.87 61.0 54.8 PIDNet[20 ] 7.62 5.89 60.0 52.6 RoadViT 1.25 1.18 57.0 52.3 RoadViT-m 2.35 3.02 58.7 53.7 RoadViT-l 5.97 6.01 59.7 54.3 D-LinkNet[22 ] — — 55.7 — HsgNet[22 ] — — 57.7 —
3.3.1. CHN6-CUG数据集 从表3 可知,RoadViT在保证轻量的前提下,R IoU 达到57.0%,参数量和FLOPs仅分别为1.25 × 106 和1.18 × 109 . 相比于轻量级模型LRASPP、DeepLab V3(MobileNet V2)和PSPNet(MobileNet V2)与大型模型D-LinkNet,RoadViT在模型的轻量性和精度上都更具优势. RoadViT的精度优于轻量级模型BiseNet V2,但参数量和FLOPs仅分别为BiseNet V2的34.5%和9.2%. 随着模型复杂度的增大,RoadViT-m和RoadViT-l的性能随之提升,R IoU 分别为58.7%和59.7%. DeepLab V3(ResNet18)和PSPNet(ResNet18)通过大型模型Resnet18实现特征提取,有效提升了分割性能,但具有繁多的参数和昂贵的计算开销. 相比之下,RoadViT-m的精度优于HsgNet、PSPNet(ResNet18)和DeepLab V3(ResNet18),但参数量仅分别为后两者的18.1%和17.3%,FLOPs分别为后两者的4.5%和3.5%. 与STDC和DDRNet相比,RoadViT-l的精度分别降低了约1%和1.3%,但具有更低的模型复杂度,参数量分别为它们的42%和30%,FLOPs分别为它们的26%和34%,有利于实时提取城市道路. RoadViT-l与PIDNet的计算复杂度相近,尽管RoadViT-l的精度略低,但参数量仅为PIDNet的78.3%. 综合考虑模型的轻量性和分割性能,RoadViT是兼顾模型复杂度和精度的城市道路提取模型,可以应用于持续工作的机载设备和资源有限的场景,对城市路网建设具有积极意义. ...
BiSeNet V2: bilateral network with guided aggregation for real-time semantic segmentation
2
2021
... 随着诸多对地观测项目的实施,遥感图像取得了飞速发展[4 ] . 此外,语义分割技术[5 -6 ] 可以基于图像区分目标和背景,为道路自动提取提供技术支撑. 传统的语义分割方法大多先基于手工算子进行提取特征,再通过模板匹配或边缘检测捕获道路区域[7 -8 ] . 手工算子的选择需要丰富的先验知识,道路提取效果往往不佳. 基于深度学习的方法遵循编码器-解码器结构[6 ] ,可以通过学习的方式更新参数. 编码器用于提取图像的高级特征,大多为通用特征提取模型,例如基于卷积神经网络的MobileNet[9 -10 ] 和ResNet[11 ] 、基于视觉Transformer的Vision Transformer[12 ] 和MobileViT[13 ] . 解码器用于捕获不同层次的特征,提高特征利用率,实现像素分类. FCN[14 ] 基于全卷积神经网络实现语义分割,通过2个连续的卷积层实现像素分类. DeepLab V3[15 ] 在解码器中通过不同大小的空洞卷积捕获多尺度特征. 类似地,PSPNet[16 ] 和DDRNet[17 ] 基于不同大小的池化层提取多尺度特征,有效提升了分割性能. STDC[18 ] 、BiseNet V2[19 ] 和PIDNet[20 ] 使用多分支结构聚合不同层次的信息,在实时性和分割精度方面具有不错的表现. ...
... Comparison of RoadViT and mainstream models on different datasets
Tab.3 模型 P /106 FLOPs/109 R IoU /% CHN6-CUG DeepGlobe数据集 PSPNet[16 ] (ResNet18[11 ] ) 12.92 67.51 57.1 57.7 DeepLab V3[15 ] (ResNet18) 13.60 85.97 57.6 58.6 PSPNet(MobileNet V2[9 ] ) 2.65 10.72 55.3 54.5 DeepLab V3(MobileNet V2) 3.23 22.61 53.6 55.4 LRASPP[10 ] 3.22 1.98 51.1 51.1 BiseNet V2[19 ] 3.62 12.80 56.4 51.8 STDC[18 ] 14.23 23.51 60.7 54.6 DDRNet[17 ] 20.15 17.87 61.0 54.8 PIDNet[20 ] 7.62 5.89 60.0 52.6 RoadViT 1.25 1.18 57.0 52.3 RoadViT-m 2.35 3.02 58.7 53.7 RoadViT-l 5.97 6.01 59.7 54.3 D-LinkNet[22 ] — — 55.7 — HsgNet[22 ] — — 57.7 —
3.3.1. CHN6-CUG数据集 从表3 可知,RoadViT在保证轻量的前提下,R IoU 达到57.0%,参数量和FLOPs仅分别为1.25 × 106 和1.18 × 109 . 相比于轻量级模型LRASPP、DeepLab V3(MobileNet V2)和PSPNet(MobileNet V2)与大型模型D-LinkNet,RoadViT在模型的轻量性和精度上都更具优势. RoadViT的精度优于轻量级模型BiseNet V2,但参数量和FLOPs仅分别为BiseNet V2的34.5%和9.2%. 随着模型复杂度的增大,RoadViT-m和RoadViT-l的性能随之提升,R IoU 分别为58.7%和59.7%. DeepLab V3(ResNet18)和PSPNet(ResNet18)通过大型模型Resnet18实现特征提取,有效提升了分割性能,但具有繁多的参数和昂贵的计算开销. 相比之下,RoadViT-m的精度优于HsgNet、PSPNet(ResNet18)和DeepLab V3(ResNet18),但参数量仅分别为后两者的18.1%和17.3%,FLOPs分别为后两者的4.5%和3.5%. 与STDC和DDRNet相比,RoadViT-l的精度分别降低了约1%和1.3%,但具有更低的模型复杂度,参数量分别为它们的42%和30%,FLOPs分别为它们的26%和34%,有利于实时提取城市道路. RoadViT-l与PIDNet的计算复杂度相近,尽管RoadViT-l的精度略低,但参数量仅为PIDNet的78.3%. 综合考虑模型的轻量性和分割性能,RoadViT是兼顾模型复杂度和精度的城市道路提取模型,可以应用于持续工作的机载设备和资源有限的场景,对城市路网建设具有积极意义. ...
2
... 随着诸多对地观测项目的实施,遥感图像取得了飞速发展[4 ] . 此外,语义分割技术[5 -6 ] 可以基于图像区分目标和背景,为道路自动提取提供技术支撑. 传统的语义分割方法大多先基于手工算子进行提取特征,再通过模板匹配或边缘检测捕获道路区域[7 -8 ] . 手工算子的选择需要丰富的先验知识,道路提取效果往往不佳. 基于深度学习的方法遵循编码器-解码器结构[6 ] ,可以通过学习的方式更新参数. 编码器用于提取图像的高级特征,大多为通用特征提取模型,例如基于卷积神经网络的MobileNet[9 -10 ] 和ResNet[11 ] 、基于视觉Transformer的Vision Transformer[12 ] 和MobileViT[13 ] . 解码器用于捕获不同层次的特征,提高特征利用率,实现像素分类. FCN[14 ] 基于全卷积神经网络实现语义分割,通过2个连续的卷积层实现像素分类. DeepLab V3[15 ] 在解码器中通过不同大小的空洞卷积捕获多尺度特征. 类似地,PSPNet[16 ] 和DDRNet[17 ] 基于不同大小的池化层提取多尺度特征,有效提升了分割性能. STDC[18 ] 、BiseNet V2[19 ] 和PIDNet[20 ] 使用多分支结构聚合不同层次的信息,在实时性和分割精度方面具有不错的表现. ...
... Comparison of RoadViT and mainstream models on different datasets
Tab.3 模型 P /106 FLOPs/109 R IoU /% CHN6-CUG DeepGlobe数据集 PSPNet[16 ] (ResNet18[11 ] ) 12.92 67.51 57.1 57.7 DeepLab V3[15 ] (ResNet18) 13.60 85.97 57.6 58.6 PSPNet(MobileNet V2[9 ] ) 2.65 10.72 55.3 54.5 DeepLab V3(MobileNet V2) 3.23 22.61 53.6 55.4 LRASPP[10 ] 3.22 1.98 51.1 51.1 BiseNet V2[19 ] 3.62 12.80 56.4 51.8 STDC[18 ] 14.23 23.51 60.7 54.6 DDRNet[17 ] 20.15 17.87 61.0 54.8 PIDNet[20 ] 7.62 5.89 60.0 52.6 RoadViT 1.25 1.18 57.0 52.3 RoadViT-m 2.35 3.02 58.7 53.7 RoadViT-l 5.97 6.01 59.7 54.3 D-LinkNet[22 ] — — 55.7 — HsgNet[22 ] — — 57.7 —
3.3.1. CHN6-CUG数据集 从表3 可知,RoadViT在保证轻量的前提下,R IoU 达到57.0%,参数量和FLOPs仅分别为1.25 × 106 和1.18 × 109 . 相比于轻量级模型LRASPP、DeepLab V3(MobileNet V2)和PSPNet(MobileNet V2)与大型模型D-LinkNet,RoadViT在模型的轻量性和精度上都更具优势. RoadViT的精度优于轻量级模型BiseNet V2,但参数量和FLOPs仅分别为BiseNet V2的34.5%和9.2%. 随着模型复杂度的增大,RoadViT-m和RoadViT-l的性能随之提升,R IoU 分别为58.7%和59.7%. DeepLab V3(ResNet18)和PSPNet(ResNet18)通过大型模型Resnet18实现特征提取,有效提升了分割性能,但具有繁多的参数和昂贵的计算开销. 相比之下,RoadViT-m的精度优于HsgNet、PSPNet(ResNet18)和DeepLab V3(ResNet18),但参数量仅分别为后两者的18.1%和17.3%,FLOPs分别为后两者的4.5%和3.5%. 与STDC和DDRNet相比,RoadViT-l的精度分别降低了约1%和1.3%,但具有更低的模型复杂度,参数量分别为它们的42%和30%,FLOPs分别为它们的26%和34%,有利于实时提取城市道路. RoadViT-l与PIDNet的计算复杂度相近,尽管RoadViT-l的精度略低,但参数量仅为PIDNet的78.3%. 综合考虑模型的轻量性和分割性能,RoadViT是兼顾模型复杂度和精度的城市道路提取模型,可以应用于持续工作的机载设备和资源有限的场景,对城市路网建设具有积极意义. ...
1
... 众多研究人员将语义分割技术应用于道路自动提取领域. Zhou等[21 -22 ] 使用大型模型作为编码器,设计多分支并行结构和全局上文模块处理不同层次的特征. Diakogiannis等[23 -24 ] 分别通过空洞卷积和深化模型结构优化编码器的特征提取能力,使用损失函数缓解道路类别和背景类别的不均衡矛盾. 这些研究基于全监督方式训练模型,实现了可靠的分割精度. 一些研究人员引入半监督和无监督的方式,实现道路提取. Li等[25 -26 ] 通过自训练方式优化语义分割模型,为无标注数据生成伪标签,再将其用于模型训练. Song等[27 ] 将遥感图像转换为通用地图,从通用地图中实现道路提取. 这些研究探索了未标注数据的有效应用,但精度普遍低于全监督方式. 上述研究使用大型模型实现特征提取,在解码器中通过复杂的模块利用特征信息,提升道路提取精度,但不利于模型的实时推理. ...
A global context-aware and batch-independent network for road extraction from VHR satellite imagery
5
2021
... 众多研究人员将语义分割技术应用于道路自动提取领域. Zhou等[21 -22 ] 使用大型模型作为编码器,设计多分支并行结构和全局上文模块处理不同层次的特征. Diakogiannis等[23 -24 ] 分别通过空洞卷积和深化模型结构优化编码器的特征提取能力,使用损失函数缓解道路类别和背景类别的不均衡矛盾. 这些研究基于全监督方式训练模型,实现了可靠的分割精度. 一些研究人员引入半监督和无监督的方式,实现道路提取. Li等[25 -26 ] 通过自训练方式优化语义分割模型,为无标注数据生成伪标签,再将其用于模型训练. Song等[27 ] 将遥感图像转换为通用地图,从通用地图中实现道路提取. 这些研究探索了未标注数据的有效应用,但精度普遍低于全监督方式. 上述研究使用大型模型实现特征提取,在解码器中通过复杂的模块利用特征信息,提升道路提取精度,但不利于模型的实时推理. ...
... CHN6-CUG[22 ] 是中国城市道路遥感影像数据集,图像数据来源于北京、上海、武汉、深圳、香港和澳门6个城市,图像的空间分辨率为50 cm/像素. CHN6-CUG包含4 511张大小为512×512像素的标记图像,其中3 608张用于模型训练,903张用于测试. ...
... DeepGlobe道路提取数据集[22 ] 包含6226张1 024×1 024像素的卫星遥感图像和标签,每幅图像的空间分辨率为50 cm/像素. 图像包含城市、郊区和乡村的道路,来源于泰国、印度和印度尼西亚,其中4 980张用于模型训练,1 246张用于测试. ...
... Comparison of RoadViT and mainstream models on different datasets
Tab.3 模型 P /106 FLOPs/109 R IoU /% CHN6-CUG DeepGlobe数据集 PSPNet[16 ] (ResNet18[11 ] ) 12.92 67.51 57.1 57.7 DeepLab V3[15 ] (ResNet18) 13.60 85.97 57.6 58.6 PSPNet(MobileNet V2[9 ] ) 2.65 10.72 55.3 54.5 DeepLab V3(MobileNet V2) 3.23 22.61 53.6 55.4 LRASPP[10 ] 3.22 1.98 51.1 51.1 BiseNet V2[19 ] 3.62 12.80 56.4 51.8 STDC[18 ] 14.23 23.51 60.7 54.6 DDRNet[17 ] 20.15 17.87 61.0 54.8 PIDNet[20 ] 7.62 5.89 60.0 52.6 RoadViT 1.25 1.18 57.0 52.3 RoadViT-m 2.35 3.02 58.7 53.7 RoadViT-l 5.97 6.01 59.7 54.3 D-LinkNet[22 ] — — 55.7 — HsgNet[22 ] — — 57.7 —
3.3.1. CHN6-CUG数据集 从表3 可知,RoadViT在保证轻量的前提下,R IoU 达到57.0%,参数量和FLOPs仅分别为1.25 × 106 和1.18 × 109 . 相比于轻量级模型LRASPP、DeepLab V3(MobileNet V2)和PSPNet(MobileNet V2)与大型模型D-LinkNet,RoadViT在模型的轻量性和精度上都更具优势. RoadViT的精度优于轻量级模型BiseNet V2,但参数量和FLOPs仅分别为BiseNet V2的34.5%和9.2%. 随着模型复杂度的增大,RoadViT-m和RoadViT-l的性能随之提升,R IoU 分别为58.7%和59.7%. DeepLab V3(ResNet18)和PSPNet(ResNet18)通过大型模型Resnet18实现特征提取,有效提升了分割性能,但具有繁多的参数和昂贵的计算开销. 相比之下,RoadViT-m的精度优于HsgNet、PSPNet(ResNet18)和DeepLab V3(ResNet18),但参数量仅分别为后两者的18.1%和17.3%,FLOPs分别为后两者的4.5%和3.5%. 与STDC和DDRNet相比,RoadViT-l的精度分别降低了约1%和1.3%,但具有更低的模型复杂度,参数量分别为它们的42%和30%,FLOPs分别为它们的26%和34%,有利于实时提取城市道路. RoadViT-l与PIDNet的计算复杂度相近,尽管RoadViT-l的精度略低,但参数量仅为PIDNet的78.3%. 综合考虑模型的轻量性和分割性能,RoadViT是兼顾模型复杂度和精度的城市道路提取模型,可以应用于持续工作的机载设备和资源有限的场景,对城市路网建设具有积极意义. ...
... [
22 ]
— — 57.7 — 3.3.1. CHN6-CUG数据集 从表3 可知,RoadViT在保证轻量的前提下,R IoU 达到57.0%,参数量和FLOPs仅分别为1.25 × 106 和1.18 × 109 . 相比于轻量级模型LRASPP、DeepLab V3(MobileNet V2)和PSPNet(MobileNet V2)与大型模型D-LinkNet,RoadViT在模型的轻量性和精度上都更具优势. RoadViT的精度优于轻量级模型BiseNet V2,但参数量和FLOPs仅分别为BiseNet V2的34.5%和9.2%. 随着模型复杂度的增大,RoadViT-m和RoadViT-l的性能随之提升,R IoU 分别为58.7%和59.7%. DeepLab V3(ResNet18)和PSPNet(ResNet18)通过大型模型Resnet18实现特征提取,有效提升了分割性能,但具有繁多的参数和昂贵的计算开销. 相比之下,RoadViT-m的精度优于HsgNet、PSPNet(ResNet18)和DeepLab V3(ResNet18),但参数量仅分别为后两者的18.1%和17.3%,FLOPs分别为后两者的4.5%和3.5%. 与STDC和DDRNet相比,RoadViT-l的精度分别降低了约1%和1.3%,但具有更低的模型复杂度,参数量分别为它们的42%和30%,FLOPs分别为它们的26%和34%,有利于实时提取城市道路. RoadViT-l与PIDNet的计算复杂度相近,尽管RoadViT-l的精度略低,但参数量仅为PIDNet的78.3%. 综合考虑模型的轻量性和分割性能,RoadViT是兼顾模型复杂度和精度的城市道路提取模型,可以应用于持续工作的机载设备和资源有限的场景,对城市路网建设具有积极意义. ...
ResUNet-a: a deep learning framework for semantic segmentation of remotely sensed data
1
2020
... 众多研究人员将语义分割技术应用于道路自动提取领域. Zhou等[21 -22 ] 使用大型模型作为编码器,设计多分支并行结构和全局上文模块处理不同层次的特征. Diakogiannis等[23 -24 ] 分别通过空洞卷积和深化模型结构优化编码器的特征提取能力,使用损失函数缓解道路类别和背景类别的不均衡矛盾. 这些研究基于全监督方式训练模型,实现了可靠的分割精度. 一些研究人员引入半监督和无监督的方式,实现道路提取. Li等[25 -26 ] 通过自训练方式优化语义分割模型,为无标注数据生成伪标签,再将其用于模型训练. Song等[27 ] 将遥感图像转换为通用地图,从通用地图中实现道路提取. 这些研究探索了未标注数据的有效应用,但精度普遍低于全监督方式. 上述研究使用大型模型实现特征提取,在解码器中通过复杂的模块利用特征信息,提升道路提取精度,但不利于模型的实时推理. ...
针对高分影像的RDU-Net乡村路网提取方法
1
2021
... 众多研究人员将语义分割技术应用于道路自动提取领域. Zhou等[21 -22 ] 使用大型模型作为编码器,设计多分支并行结构和全局上文模块处理不同层次的特征. Diakogiannis等[23 -24 ] 分别通过空洞卷积和深化模型结构优化编码器的特征提取能力,使用损失函数缓解道路类别和背景类别的不均衡矛盾. 这些研究基于全监督方式训练模型,实现了可靠的分割精度. 一些研究人员引入半监督和无监督的方式,实现道路提取. Li等[25 -26 ] 通过自训练方式优化语义分割模型,为无标注数据生成伪标签,再将其用于模型训练. Song等[27 ] 将遥感图像转换为通用地图,从通用地图中实现道路提取. 这些研究探索了未标注数据的有效应用,但精度普遍低于全监督方式. 上述研究使用大型模型实现特征提取,在解码器中通过复杂的模块利用特征信息,提升道路提取精度,但不利于模型的实时推理. ...
针对高分影像的RDU-Net乡村路网提取方法
1
2021
... 众多研究人员将语义分割技术应用于道路自动提取领域. Zhou等[21 -22 ] 使用大型模型作为编码器,设计多分支并行结构和全局上文模块处理不同层次的特征. Diakogiannis等[23 -24 ] 分别通过空洞卷积和深化模型结构优化编码器的特征提取能力,使用损失函数缓解道路类别和背景类别的不均衡矛盾. 这些研究基于全监督方式训练模型,实现了可靠的分割精度. 一些研究人员引入半监督和无监督的方式,实现道路提取. Li等[25 -26 ] 通过自训练方式优化语义分割模型,为无标注数据生成伪标签,再将其用于模型训练. Song等[27 ] 将遥感图像转换为通用地图,从通用地图中实现道路提取. 这些研究探索了未标注数据的有效应用,但精度普遍低于全监督方式. 上述研究使用大型模型实现特征提取,在解码器中通过复杂的模块利用特征信息,提升道路提取精度,但不利于模型的实时推理. ...
Semisupervised semantic segmentation of remote sensing images with consistency self-training
1
2022
... 众多研究人员将语义分割技术应用于道路自动提取领域. Zhou等[21 -22 ] 使用大型模型作为编码器,设计多分支并行结构和全局上文模块处理不同层次的特征. Diakogiannis等[23 -24 ] 分别通过空洞卷积和深化模型结构优化编码器的特征提取能力,使用损失函数缓解道路类别和背景类别的不均衡矛盾. 这些研究基于全监督方式训练模型,实现了可靠的分割精度. 一些研究人员引入半监督和无监督的方式,实现道路提取. Li等[25 -26 ] 通过自训练方式优化语义分割模型,为无标注数据生成伪标签,再将其用于模型训练. Song等[27 ] 将遥感图像转换为通用地图,从通用地图中实现道路提取. 这些研究探索了未标注数据的有效应用,但精度普遍低于全监督方式. 上述研究使用大型模型实现特征提取,在解码器中通过复杂的模块利用特征信息,提升道路提取精度,但不利于模型的实时推理. ...
FMWDCT: foreground mixup into weighted dual-network cross training for semisupervised remote sensing road extraction
1
2022
... 众多研究人员将语义分割技术应用于道路自动提取领域. Zhou等[21 -22 ] 使用大型模型作为编码器,设计多分支并行结构和全局上文模块处理不同层次的特征. Diakogiannis等[23 -24 ] 分别通过空洞卷积和深化模型结构优化编码器的特征提取能力,使用损失函数缓解道路类别和背景类别的不均衡矛盾. 这些研究基于全监督方式训练模型,实现了可靠的分割精度. 一些研究人员引入半监督和无监督的方式,实现道路提取. Li等[25 -26 ] 通过自训练方式优化语义分割模型,为无标注数据生成伪标签,再将其用于模型训练. Song等[27 ] 将遥感图像转换为通用地图,从通用地图中实现道路提取. 这些研究探索了未标注数据的有效应用,但精度普遍低于全监督方式. 上述研究使用大型模型实现特征提取,在解码器中通过复杂的模块利用特征信息,提升道路提取精度,但不利于模型的实时推理. ...
MapGen-GAN: a fast translator for remote sensing image to map via unsupervised adversarial learning
1
2021
... 众多研究人员将语义分割技术应用于道路自动提取领域. Zhou等[21 -22 ] 使用大型模型作为编码器,设计多分支并行结构和全局上文模块处理不同层次的特征. Diakogiannis等[23 -24 ] 分别通过空洞卷积和深化模型结构优化编码器的特征提取能力,使用损失函数缓解道路类别和背景类别的不均衡矛盾. 这些研究基于全监督方式训练模型,实现了可靠的分割精度. 一些研究人员引入半监督和无监督的方式,实现道路提取. Li等[25 -26 ] 通过自训练方式优化语义分割模型,为无标注数据生成伪标签,再将其用于模型训练. Song等[27 ] 将遥感图像转换为通用地图,从通用地图中实现道路提取. 这些研究探索了未标注数据的有效应用,但精度普遍低于全监督方式. 上述研究使用大型模型实现特征提取,在解码器中通过复杂的模块利用特征信息,提升道路提取精度,但不利于模型的实时推理. ...
SRP-YOLOX: an improved deep convolutional neural network for automated via detection
2
2023
... 综合上述分析,本文提出轻量级城市道路提取模型RoadViT. 在编码器中,通过轻量级模型MobileViT编码特征,有效引入Transformer实现全局信息建模. 在解码器中,提出金字塔解码器提取多尺度特征,适应不同大小的道路区域. 结合Mosaic[28 ] 与多尺度缩放和随机裁剪实现数据增强,获取精细多样的图像数据. 针对遥感图像中道路类别和背景类别不平衡的问题,设计动态加权损失函数. ...
... 遥感影像是精细化和高空间分辨率的图像,分辨率越高的图像可以为模型提供更精细的特征,但会造成训练成本的急剧上升. 直接将图像缩放至低分辨率会造成信息损失,不利于城市路网的精准提取. 通过多尺度缩放和随机裁剪策略降低分辨率,有效维持了遥感图像的精细化特征. 引入Mosaic[28 ] 实现多图像混合,构建多样的图像数据提升模型性能,过程如图5 所示. 图中,α 为多尺度缩放因子. 将输入图像按随机比例进行放大,生成更精细的遥感影像. 通过随机裁剪,生成尺寸一致、但位置不同的图像. 随机选取3张图像进行多尺度缩放和随机裁剪,将这4张图像通过随机混合. 输出图像被用于模型训练,有效获取了更精细和多样的图像数据. ...
Cutout with patch-loss augmentation for improving generative adversarial networks against instability
1
2023
... 为了验证本文使用技术的有效性,将其和一些通用技术进行对比,结果如表1 所示. 为了对比各种数据增强方式对模型性能的提升,在CHN6-CUG数据集上,使用MobileViT+FCNHead作为基础模型进行实验. FCNHead是简洁的解码器,由2个连续的卷积层构成. 可见,使用Cutout[29 ] 随机擦除部分图像后,模型精度提升了0.3%. Cutmix[30 ] 通过混合图像实现数据增强,模型精度显著提升了1.1%,这表明利用混合图像的方式有利于构建多样的图像数据. 通过Mosaic混合多张图像,模型精度提升了2.3%. 引入多尺度缩放和随机裁剪,获取更精细的图像信息,精度提升了4.6%,这表明更丰富的图像信息可以提升分割性能. 结合Mosaic与多尺度缩放和随机裁剪,构建精细、多样的图像数据,模型精度提升了5%. 现有的SPP[31 ] (spatial pyramid pooling)通过并行不同大小的最大池化操作捕获多尺度特征,有效提升了1.9%的精度,但并行拼接特征会显著增加参数量和FLOPs. 提出的金字塔解码器串行相同大小的平均池化操作,有效捕获了不同尺度的局部信息和全局信息,通过卷积操作调节不同层次信息的权重. 在使用金字塔解码器后,模型参数量和FLOPs仅分别为使用SPP的65%和62%,但精度提升了0.9%. 为了验证多头注意力机制(MHA)可以实现全局信息建模,有效增强模型的特征提取性能,引入去除MHA的MobileViT进行实验. 在去除MHA后,模型的参数量和FLOPs显著降低,但卷积神经网络仅具有局部信息建模的能力,不利于全局的道路提取,分割精度为41.5%. ...
1
... 为了验证本文使用技术的有效性,将其和一些通用技术进行对比,结果如表1 所示. 为了对比各种数据增强方式对模型性能的提升,在CHN6-CUG数据集上,使用MobileViT+FCNHead作为基础模型进行实验. FCNHead是简洁的解码器,由2个连续的卷积层构成. 可见,使用Cutout[29 ] 随机擦除部分图像后,模型精度提升了0.3%. Cutmix[30 ] 通过混合图像实现数据增强,模型精度显著提升了1.1%,这表明利用混合图像的方式有利于构建多样的图像数据. 通过Mosaic混合多张图像,模型精度提升了2.3%. 引入多尺度缩放和随机裁剪,获取更精细的图像信息,精度提升了4.6%,这表明更丰富的图像信息可以提升分割性能. 结合Mosaic与多尺度缩放和随机裁剪,构建精细、多样的图像数据,模型精度提升了5%. 现有的SPP[31 ] (spatial pyramid pooling)通过并行不同大小的最大池化操作捕获多尺度特征,有效提升了1.9%的精度,但并行拼接特征会显著增加参数量和FLOPs. 提出的金字塔解码器串行相同大小的平均池化操作,有效捕获了不同尺度的局部信息和全局信息,通过卷积操作调节不同层次信息的权重. 在使用金字塔解码器后,模型参数量和FLOPs仅分别为使用SPP的65%和62%,但精度提升了0.9%. 为了验证多头注意力机制(MHA)可以实现全局信息建模,有效增强模型的特征提取性能,引入去除MHA的MobileViT进行实验. 在去除MHA后,模型的参数量和FLOPs显著降低,但卷积神经网络仅具有局部信息建模的能力,不利于全局的道路提取,分割精度为41.5%. ...
Spatial pyramid pooling in deep convolutional networks for visual recognition
1
2015
... 为了验证本文使用技术的有效性,将其和一些通用技术进行对比,结果如表1 所示. 为了对比各种数据增强方式对模型性能的提升,在CHN6-CUG数据集上,使用MobileViT+FCNHead作为基础模型进行实验. FCNHead是简洁的解码器,由2个连续的卷积层构成. 可见,使用Cutout[29 ] 随机擦除部分图像后,模型精度提升了0.3%. Cutmix[30 ] 通过混合图像实现数据增强,模型精度显著提升了1.1%,这表明利用混合图像的方式有利于构建多样的图像数据. 通过Mosaic混合多张图像,模型精度提升了2.3%. 引入多尺度缩放和随机裁剪,获取更精细的图像信息,精度提升了4.6%,这表明更丰富的图像信息可以提升分割性能. 结合Mosaic与多尺度缩放和随机裁剪,构建精细、多样的图像数据,模型精度提升了5%. 现有的SPP[31 ] (spatial pyramid pooling)通过并行不同大小的最大池化操作捕获多尺度特征,有效提升了1.9%的精度,但并行拼接特征会显著增加参数量和FLOPs. 提出的金字塔解码器串行相同大小的平均池化操作,有效捕获了不同尺度的局部信息和全局信息,通过卷积操作调节不同层次信息的权重. 在使用金字塔解码器后,模型参数量和FLOPs仅分别为使用SPP的65%和62%,但精度提升了0.9%. 为了验证多头注意力机制(MHA)可以实现全局信息建模,有效增强模型的特征提取性能,引入去除MHA的MobileViT进行实验. 在去除MHA后,模型的参数量和FLOPs显著降低,但卷积神经网络仅具有局部信息建模的能力,不利于全局的道路提取,分割精度为41.5%. ...







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}