

针对多无人艇围捕问题,宋利飞等[3]利用改进势点法与匈牙利算法动态分配目标点,并结合阿波罗尼奥斯圆,缩紧对目标的包围区域. Chen等[4]提出基于分布式拍卖的任务分配机制,采用量子粒子群优化算法来优化初始包围圈;经仿真验证,该算法提升了围捕效率. 杨惠珍等[5]基于几何关系分析自主水面无人艇(autonomous surface vehicle, ASV)协同围捕中的目标逃逸因素,结合微分博弈与粒子群优化(particle swarm optimization, PSO)算法来求解最优策略. 然而,传统的基于规则或优化理论的方法在处理此类高度动态、不确定性强的对抗博弈问题时,往往面临模型构建复杂、泛化能力不足等挑战.
随着人工智能技术的快速发展,多智能体强化学习(multi-agent reinforcement learning, MARL)凭借其在复杂决策问题中通过与环境交互进行端到端学习的强大能力[6],为解决多无人艇智能决策问题提供了新的范式. 于长东等[7]采用多智能体深度确定性策略梯度(multi-agent deep deterministic policy gradient, MADDPG)算法来解决无人艇群博弈对抗下的协同围捕决策问题,并通过3对1和6对2仿真实验验证了模型的有效性. Qu等[8]提出面向多种随机场景的对抗进化博弈训练方法,并结合课程学习技术,使双方在对抗训练中不断优化决策模型,提升了模型的追逃和避障能力. Li等[9]结合多智能体近端策略优化(multi-agent proximal policy optimization, MAPPO)算法与新型速度控制机制,并引入课程学习技术,验证了该方法在策略收敛和捕获效率上具有显著优势. Li等[10]提出基于课程经验学习的CEL-MADDPG算法,将多无人机围捕任务分为3个子任务,以提高模型学习效率. Xia等[11]提出基于分布式部分可观测马尔可夫决策过程的多智能体近端策略优化算法,用于解决无边界、无障碍约束的围捕问题. Hou等[12]结合分布式软演员-评论家算法与课程学习技术,以应对传统追捕方法在复杂水下环境中的局限性. 苏震等[13]针对无人艇集群在无障碍物作战区域内的动态博弈对抗问题,采用基于双评价网络改进的深度确定性策略梯度算法,并验证了算法的有效性. 符小卫等[14]提出解耦的MADDPG算法,并在无障碍物的环境中验证了无人机对高速逃跑目标的围捕有效性. Gan等[15]提出基于课程式深度强化学习的障碍物辅助多USV协同追逐框架,有效提高了追逐效率. 然而,上述研究仍然存在场景简单化、训练与学习效率低、奖励稀疏、泛化性差等问题;尤其是在敌我双方均为学习型智能体的复杂对抗场景中,这些问题更为突出.
针对上述问题,面向无人艇多对一围捕对抗任务,构建包含多岛礁与动态目标等复杂元素的仿真环境,在状态空间建模过程中融合自身、邻居、目标和障碍物等多源信息并进行归一化处理. 针对围捕任务的对抗性,设计多尺度奖励函数,以缓解奖励稀疏问题. 提出基于自适应课程学习(adaptive curriculum learning, ACL)和MAPPO算法的围捕决策方法,在集中式训练、分散式执行的框架中,动态调整训练环境的复杂度和动作探索的噪声强度. 与基准方法相比,所提方法能够有效提升围捕成功率,缩短平均任务完成时间和平均围捕路径长度,并降低碰撞次数. 此外,该方法在不同环境复杂度和目标策略下均表现出良好的泛化能力与对抗适应性.
1. 模型建立
图 1
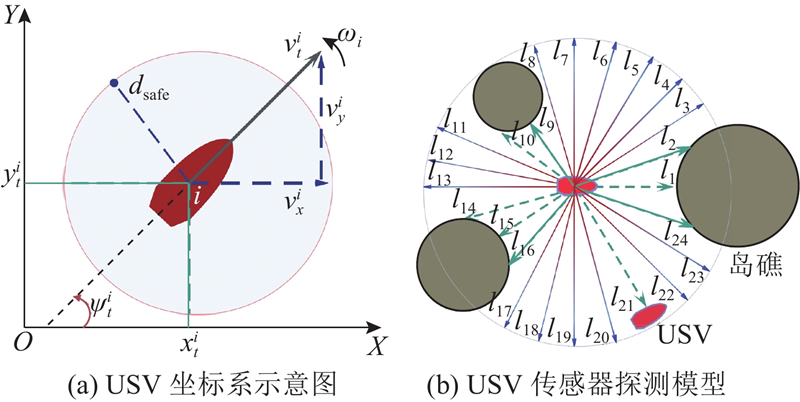
式中:
2. 问题描述与约束条件
2.1. 问题描述
构建二维海域作战仿真环境,场景中分布有若干岛礁作为障碍物,并设有1处包含工作站的己方岛礁. 由多艘USV组成的己方团队执行协同围捕任务. 在任务开始时,系统根据目标USV的初始位置动态选择距离目标最近的3艘USV,将其激活,使其承担主动追捕任务,其余USV处于待命状态;这样不仅减少了任务完成时间,而且避免了资源浪费. 己方的作战目标是通过多艇协同形成有效的包围态势,在距离、角度和朝向约束下成功拦截目标;而目标USV需要规避围捕、突破防线并攻击己方岛礁.
综上,如图2所示,考虑USV的欠驱动性,为了确保在多障碍物场景中让目标无过大的逃脱空隙并保持严谨的合围态势,在3围1的仿真实验中,定义围捕成功的约束条件:
图 2
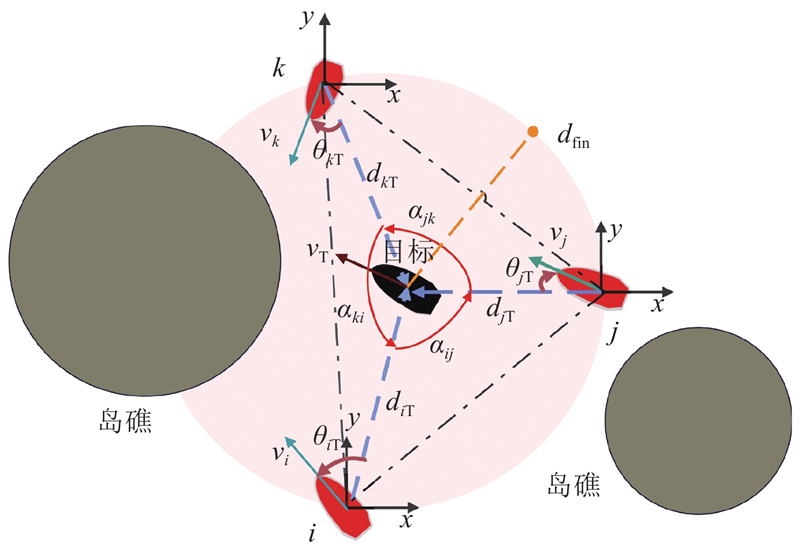
图 2 围捕成功的约束条件示意图
Fig.2 Schematic diagram of constraints for successful encirclement
式中:I为己方USV,i、j、k为3艘己方USV的编号;
2.2. 任务终止条件
为了更加贴合真实的军事化作战场景,规定对抗过程中须满足以下约束条件:1)双方任意USV若超出作战范围,则当前任务回合结束;2)若己方USV之间发生碰撞,则当前任务回合结束;3)若双方任意USV与障碍物发生碰撞,则当前任务回合结束.
3. 对抗围捕决策方法
3.1. 部分可观测马尔可夫决策过程
己方USV的决策过程可以使用分布式部分可观测马尔可夫决策过程(partially observable Markov decision process, Dec-POMDP)来定义[19]. 在Dec-POMDP中,每个智能体只能获得局部的观测信息,而无法获得全局的状态信息. 在每一时间步,每个智能体根据其局部观测信息做出行动决策,且所有智能体通过执行联合动作来刷新环境状态.
将Dec-POMDP定义为
在Dec-POMDP框架下,每个智能体根据各自的策略
式中:
3.2. 状态空间设计
3.2.1. 己方USV的状态空间设计
每个USV都带有传感器,负责检测和获取观测信息. 己方USV的观测模型如图3所示. 现有的大多数研究在设计状态空间时未对其进行归一化处理[20-21],从而导致训练不稳定以及智能体学习困难. 因此,以场景边界为参考范围将位置特征归一化至[−1.0,1.0],基于最大速度将速度特征归一化至[−1.0,1.0],基于场景对角线长度将距离特征归一化至[0, 1.0],再分别以最大角度
图 3
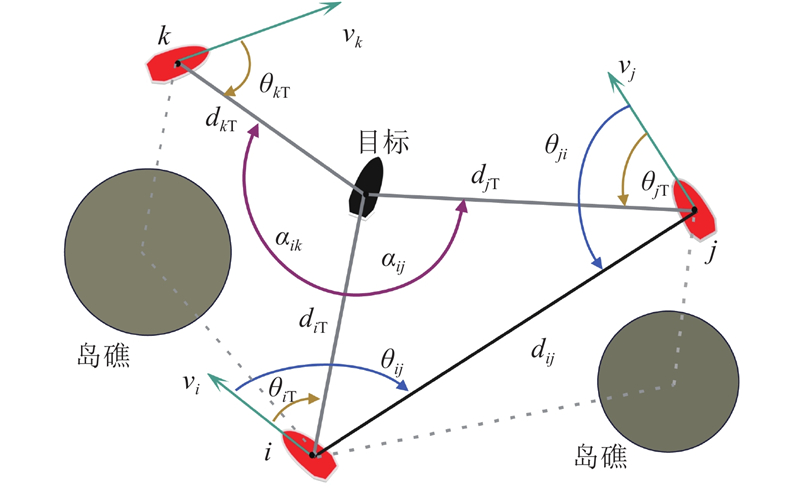
式中:
协同观测信息向量、测距传感器和自身的观测信息向量分别为
式中:
全局状态s由参与围捕任务的各艘USV的局部观测向量拼接而成,其表达式为
3.2.2. 目标USV的状态空间设计
目标USV的观测模型如图4所示,其归一化观测信息向量为
图 4
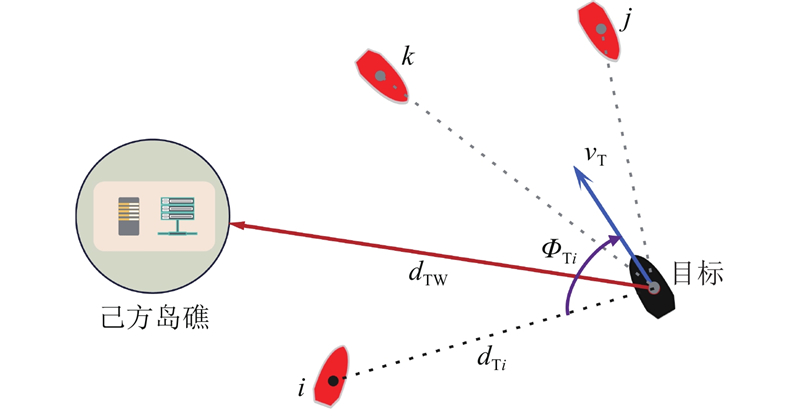
式中:
艇身搭载的测距传感器观测到的信息向量为
3.3. 动作空间设计
式中:
3.4. 双方奖励函数设计
3.4.1. 己方USV的奖励函数设计
为了确保所有追捕目标的USV都可以保持高速状态并抵达目标附近,同时能够围绕目标形成均匀分布的包围态势,并避免消极掉队行为,定义距离奖励函数、围捕角度奖励函数、速度奖励函数和协同奖励函数,分别为
式中:
为了确保USV始终在有效区域内活动,在防止碰撞的同时不过度抑制探索行为,定义惩罚函数为
式中:
USV在每个时间步获得固定的耗时惩罚
式中:
3.4.2. 目标USV的奖励函数设计
目标的总奖励由5个部分组成:接近工作站奖励、躲避奖励、碰撞惩罚、时间步惩罚以及工作站到达奖励. 其中,时间步惩罚
接近工作站奖励和躲避奖励的表达式分别为
式中:
碰撞惩罚由3个子项组成,取其中最严重的惩罚,表达式为
3.5. 自适应课程学习-多智能体近端策略优化算法
ACL-MAPPO算法的训练架构如图5所示. 自适应课程调度器通过动态调整环境难度,实现高效且具备环境适应性的智能体训练. 在每轮训练结束后,调度器统计当前难度下滑动窗口的成功率,若成功率高于设定的阈值且训练回合数满足最小要求,则提升场景难度;若成功率低于降级阈值,则降低场景难度;若己方USV在长时间内获得的平均奖励值无明显提升,则触发降级信号,从而避免策略陷入局部最优. 环境难度更新的核心表达式为
图 5
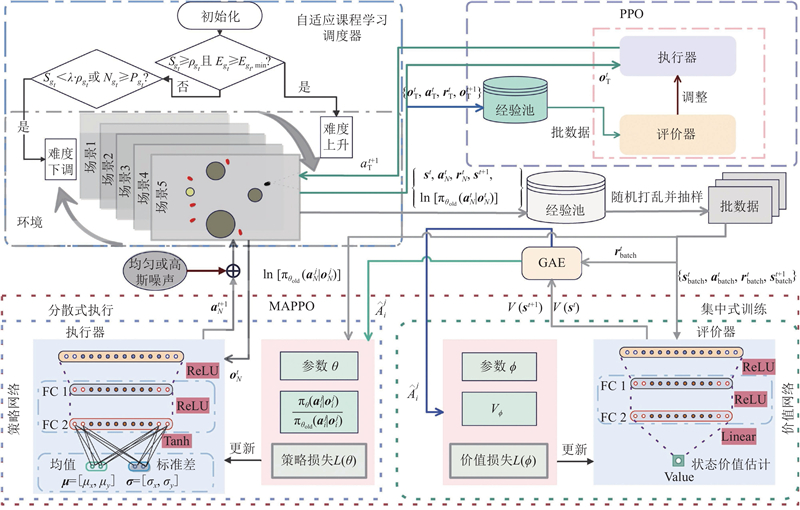
图 5 自适应课程学习-多智能体近端策略优化算法训练架构
Fig.5 Training architecture of ACL-MAPPO algorithm
式中:
己方USV的策略训练采用MAPPO算法,该算法是在线策略(on-policy)算法[24]. 与离线式多智能体强化学习算法如MADDPG算法相比,MAPPO无须在训练之前收集大量经验数据. 此外,MAPPO限制了策略熵和策略更新程度,从而提高了算法的稳定性和性能. 如图5所示,MAPPO采用集中式训练、分散式执行的训练框架:每个USV根据当前时刻的局部观测量
式中:B为批次大小,N为己方参与围捕的USV数量,
评价器中的价值网络采用时间差分算法来最小化损失函数,同时使用价值裁剪操作来增强稳定性,进而更新神经网络参数. 其损失函数为
式中:
采用广义优势估计(generalized advantage estimation, GAE)方法[25]来计算评估USV的动作优劣程度,表示为
式中:
在训练过程中,MAPPO经验池负责收集已激活的己方所有USV执行任务时的联合观测数据
为了提升己方USV在不同课程阶段的探索能力,设计随课程难度进行动态调整的动作噪声调节机制[26]来模拟海洋扰动,并结合策略网络通过抽样得到的动作,具体表达式为
式中:
4. 仿真实验与结果分析
4.1. 仿真环境构建与参数设置
实验程序基于Python 3.10.15编写. 采用OpenCV(CV2)构建二维战场环境,调用OpenAI Gym库的空间类对USV的状态空间和动作空间进行初始化处理,并基于Pytorch 1.4.1框架实现神经网络的构建和训练. 硬件配置为NVIDIA GeForce RTX GPU
图 6
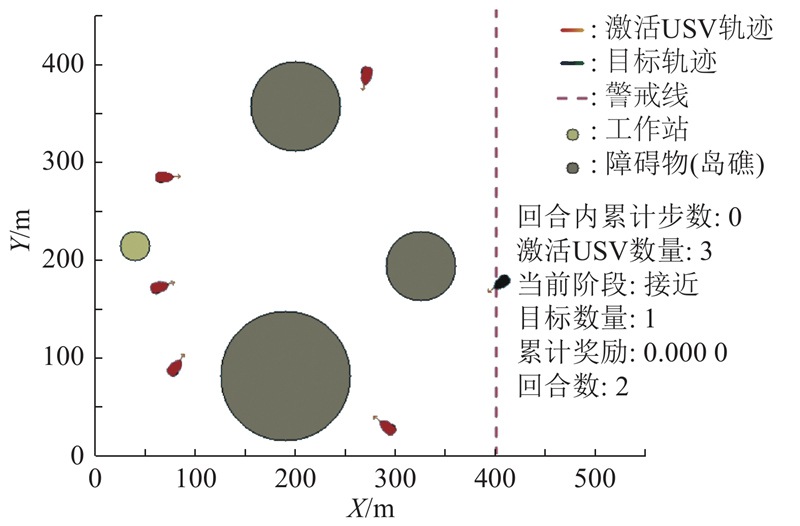
图 6 最高难度的二维作战仿真场景
Fig.6 Two-dimensional combat simulation scenario with highest difficulty
实验环境及各USV的关键参数设定如下:仿真环境为二维连续的矩形区域,其在X轴上的最大范围设定为0~550 m,在Y轴上的最大范围设定为0~450 m,时间步长为0.5 s,每个回合的最大步数为300. 场景中包含5艘己方USV和1艘目标USV. 己方每艘USV的初始速度vo=1 m/s,最大速度vmax=12 m/s,最大角速度
自适应课程学习调度器和自适应课程学习环境的参数配置如表1、2所示. 表1中,
表 1 自适应课程学习调度器的参数配置
Tab.1
| 参数 | 数值 |
| 10 | |
| 0.75, 0.65, 0.55, 0.45, 0.40 | |
| 20, 35, 60, 70, 80 | |
| 60, 70, 80, 90, 100 |
表 2 自适应课程学习环境的参数配置
Tab.2
| 场景布局 | |||
| — | 3 | 70 | 225 |
| W | 5 | 60 | 275 |
| 7 | 55 | 315 | |
| 9 | 50 | 365 | |
| 10 | 45 | 400 |
经过多次实验和参数调整,确定算法训练的超参数. 奖励函数中各参数的设置如表3所示,MAPPO和PPO算法的超参数配置如表4所示. 其中,M为缓冲器容量,Bs为数据批次大小,lr为学习率,Tmax为每回合最大步数,Eepoch为批数据训练轮数,τclip为梯度裁剪阈值,nh为隐藏层神经元数. 特别地,根据多智能体协同学习的特点,MAPPO算法采用更大的缓冲器容量、数据批次大小、学习率、隐藏层神经元数和批数据训练轮数,同时将GAE系数设为0.95,熵正则系数
表 3 奖励函数参数设置
Tab.3
| 参数 | 数值 | 参数 | 数值 | |
| 0.01, 0.15 | 300 | |||
| 0.5, 0.1 | 0.8 | |||
| 0.5 | 0.35, 0.17, 0.28, 0.20 |
表 4 MAPPO和PPO算法的超参数设置
Tab.4
| 参数 | 数值 | |
| MAPPO | PPO | |
| M | 2 048 | 1 024 |
| Bs | 256 | 128 |
| 2×10−4 | 10−4 | |
| 0.99 | 0.99 | |
| 0.2 | 0.2 | |
| 0.95 | 0.95 | |
| 0.01 | 0.01 | |
| Tmax | 300 | 300 |
| Eepoch | 10 | 3 |
| τclip | 0.5 | — |
| nh | 2×256 | 2×128 |
最后,对实验条件作以下假设:1)己方USV皆为同构配置,即所有USV的性能参数完全一致,且在训练阶段,己方USV之间能够相互通信并共享目标位置信息;2)实验中的仿真环境为有界区域,同时为了确保存在可行的解决方案,仅考虑己方USV最大速度高于目标USV最大速度的围捕对抗情况.
4.2. 实验与结果分析
4.2.1. 方法有效性验证
为了验证基于ACL-MAPPO的无人艇对抗围捕决策方法的有效性,在多USV对抗围捕环境中进行仿真实验. 通过计算各USV在每个回合内的每步平均奖励Rstep,评估奖励变化趋势以及算法的收敛性能. 在配备NVIDIA GeForce RTX GPU
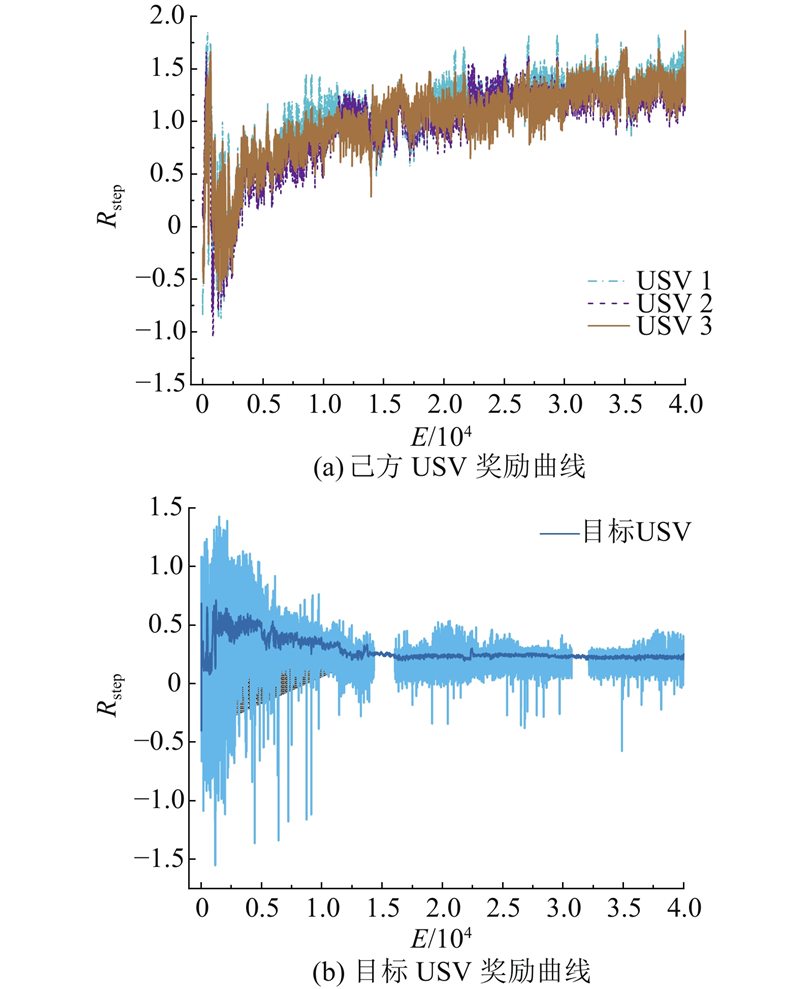
图7分别展示了己方3艘USV在训练过程中的奖励曲线以及目标USV的奖励曲线,其中E为训练的回合数. 如图7(a)所示,在初始阶段的约0~700回合内,由于场景中没有引入岛礁且目标的机动性差,各USV的奖励值持续升高. 在大约800~5 000回合内,随着难度的不断升级,各USV的奖励值波动较大且普遍较低. 在5 000~15 000回合内,各USV的奖励值逐渐上升并趋于一致,表明其逐步学会了有效的围捕和避障策略. 在训练后期,奖励值稳定收敛在1.25左右,且各USV的奖励曲线接近,说明智能体之间达成了良好的协作行为模式. 如图7(b)所示,目标USV的奖励曲线在0~2 500回合内呈现上升趋势,表明智能体在不断探索环境并逐渐学习逃跑策略. 在5 000回合后,随着围捕方USV协同能力以及追捕能力的提升,目标USV的平均奖励值下降,并且在15 000回合后趋于稳定,平均奖励值收敛在0.20左右,表明目标USV的逃避策略变得相对稳定.
图 7
4.2.2. 性能对比分析
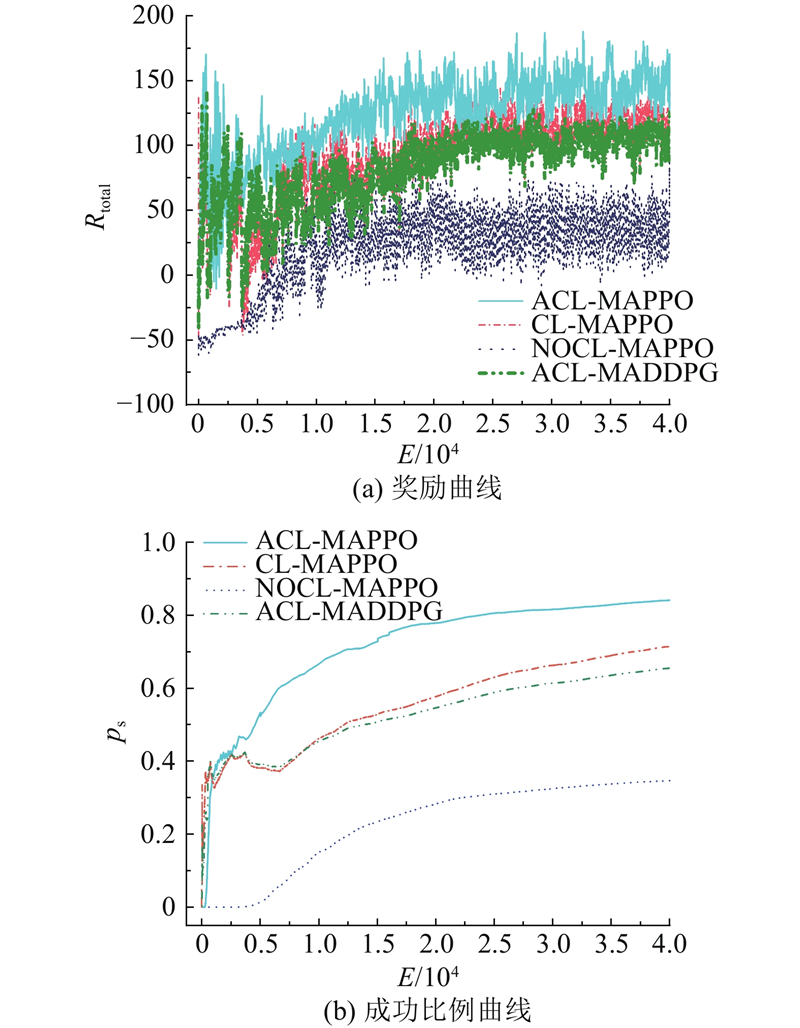
图8展示了不同算法的总奖励值(Rtotal)和训练累计成功比例(ps)随训练轮数的变化规律. 如图8(a)所示,ACL-MAPPO算法在训练初期就能够快速获得较高的奖励值,且奖励值持续增长,最终稳定收敛在145左右,显著优于其他3种算法. CL-MAPPO算法的奖励曲线虽然也呈现上升趋势,但是增速较缓,最终收敛后的奖励值低于ACL-MAPPO. ACL-MADDPG算法相较于CL-MAPPO算法,其整体获得的奖励值较低,并且增速较缓. 而NOCL-MAPPO算法的奖励曲线在整个训练过程中均处于较低水平,波动较大,说明其学习效果不佳. 如图8(b)所示,ACL-MAPPO、CL-MAPPO、NOCL-MAPPO、ACL-MADDPG算法的最高累计成功比例分别约为0.84、0.71、0.34、0.66,可见ACL-MAPPO算法的成功比例显著较高,在训练过程中增长最快,并最早达到平稳状态.
图 8
4.2.3. 分组评估与测试
在各算法训练完成后,保存策略网络权重参数. 在实际部署和测试评估中,己方USV只需要加载策略网络参数,无须加载价值网络参数,完全依赖自身的观测信息做出决策,且USV间不再进行实时通信.
为了全面评估所提ACL-MAPPO算法的性能,设计分组对比实验,分别在2种模式下测试算法性能:1)目标随机(random)运动,即采用Gym库的sample方法随机生成维度为2的动作值来驱动目标随机运动;2)目标强化学习(RL)运动,即采用由强化学习算法训练得到的策略网络来输出动作值,驱动目标完成自主运动. 在5 000回合内随机生成不同难度级别的环境进行测试,设置回合内最大步数为300,仿真时间步长为0.5 s.
各算法在2种目标运动模式下的围捕成功率(Sr)和完成任务所需的平均步数(favg)如图9所示,其中Random为随机运动模式,RL为强化学习运动模式. 由图9(a)可知,在目标强化学习运动模式下,ACL-MAPPO、CL-MAPPO、NOCL-MAPPO、ACL-MADDPG算法的围捕成功率分别约为89%、76%、41%、71%;当目标随机运动时,4种算法的成功率分别为68%、60%、33%、59%,这主要是因为目标USV缺乏规避障碍物和环境边界的能力,导致碰撞障碍物和超出边界的次数增多,从而降低了最终的围捕成功率. 尽管如此,ACL-MAPPO算法仍然取得了最高的围捕成功率. 如图9(b)所示,当面对智能目标时,ACL-MAPPO、CL-MAPPO、NOCL-MAPPO、ACL-MADDPG算法的平均任务完成步数分别为55、65、78和69. 这表明ACL-MAPPO算法能够高效地完成围捕任务,节省计算资源并提高响应速度.
图 9
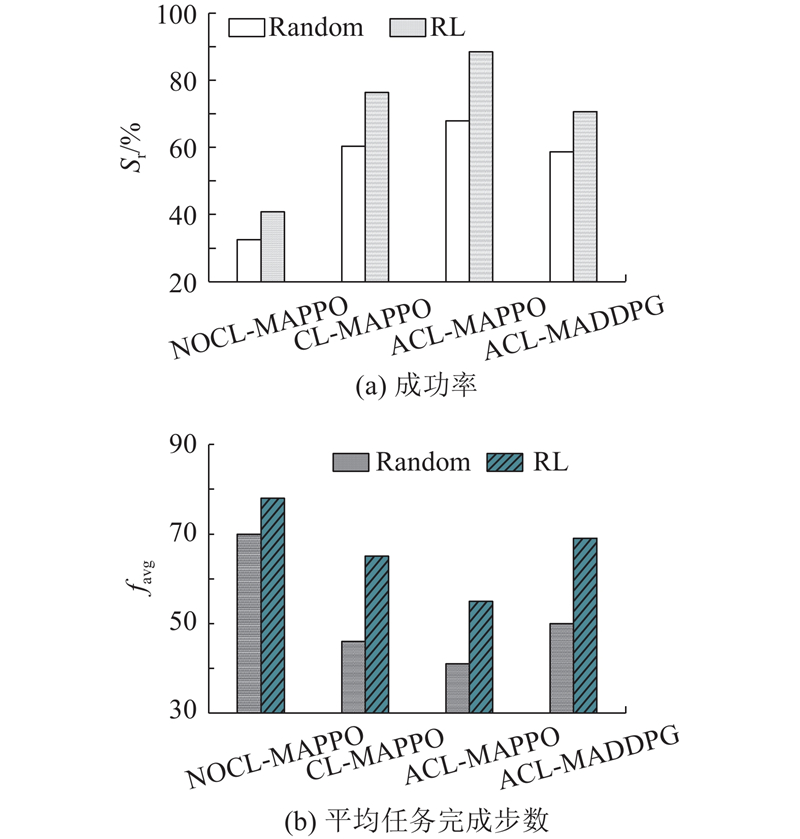
图 9 各算法在2种目标运动模式下的性能比较
Fig.9 Performance comparison of various algorithms under two target motion modes
目标USV的速度和加速度变化如图10所示,其中vT、
图 10
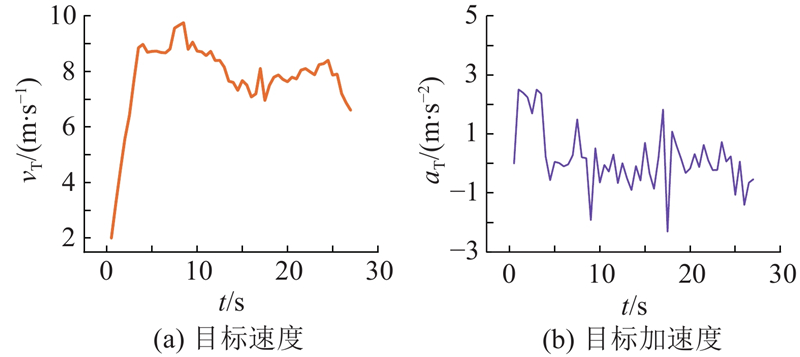
图 10 目标USV的速度与加速度变化曲线
Fig.10 Velocity and acceleration variation curves of target USV
图 11
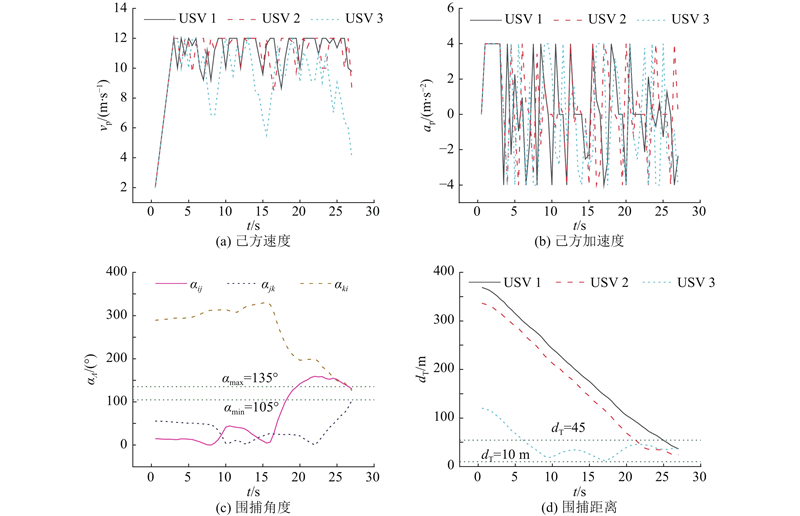
图 11 围捕过程中己方USV的参数变化曲线
Fig.11 Parameter variation curves of friendly USVs during encirclement process
图 12
各算法的性能指标对比如表5所示,其中,
表 5 各算法在2种目标策略下的性能指标对比
Tab.5
| 目标策略 | 算法 | ||||||
| RL | ACL-MAPPO | 194 | 40 | 46 | 2 | 302.324 | 55.253 |
| CL-MAPPO | 364 | 58 | 71 | 22 | 367.474 | 42.437 | |
| NOCL-MAPPO | 1 401 | 134 | 432 | 38 | 421.161 | 17.367 | |
| ACL-MADDPG | 389 | 67 | 83 | 31 | 381.193 | 40.152 | |
| Random | ACL-MAPPO | 942 | 301 | 154 | 54 | 285.391 | 37.113 |
| CL-MAPPO | 1 224 | 304 | 205 | 52 | 321.482 | 30.172 | |
| NOCL-MAPPO | 1 558 | 150 | 367 | 56 | 343.514 | 13.627 | |
| ACL-MADDPG | 1 287 | 317 | 221 | 61 | 337.643 | 25.241 |
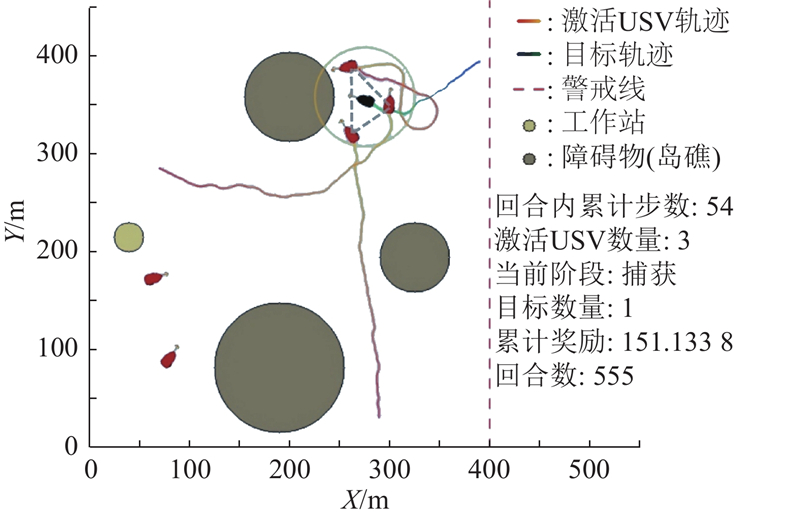
4种算法在不同目标策略下的典型围捕轨迹如图13所示. 当面对随机目标和智能目标时,如图13(b)、(e)所示,基于ACL-MAPPO的决策方法均能够实现高效且协同的围捕,3艘USV能够快速形成合围态势,有效限制了目标的机动空间. 相比之下,在智能目标场景下,如图13(c)、(d)所示,基于CL-MAPPO和ACL-MADDPG的2种决策方法虽然能够实现对目标的围捕,但是USV之间的协作性较弱,运动路径较长. 此外,在部分回合中甚至出现了USV分散、未能及时合围的现象. 尤其是在无课程学习的情况下,如图13(f)所示,当面对智能目标时,基于NOCL-MAPPO的决策方法未能形成有效的包围圈,让目标逃脱,导致围捕任务失败.
图 13
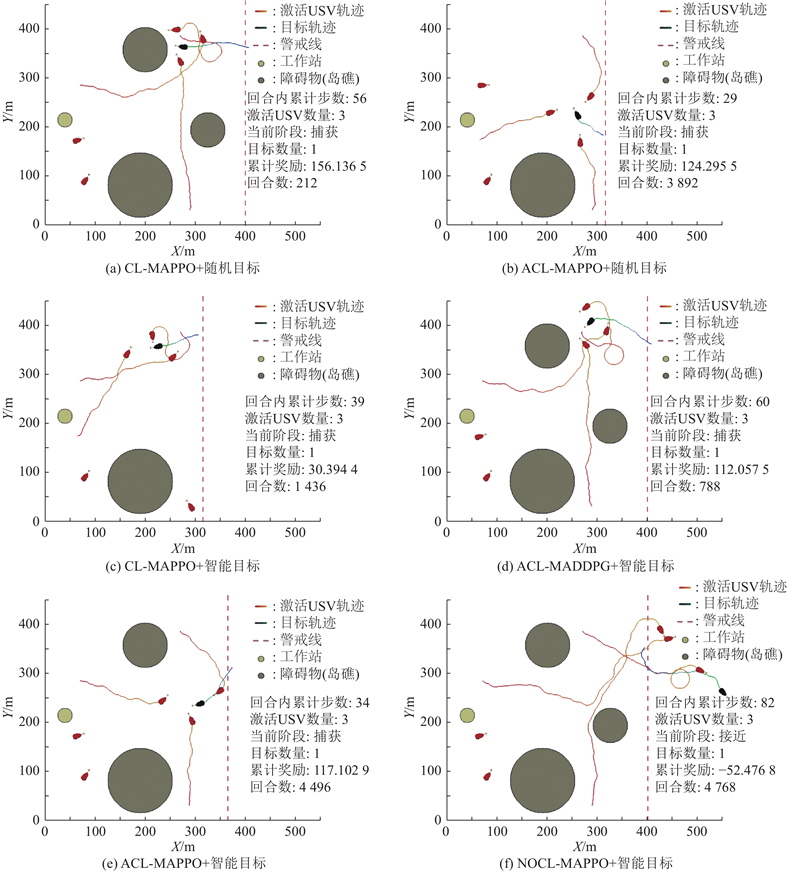
图 13 不同算法的围捕对抗仿真轨迹图
Fig.13 Simulation trajectory diagrams of encirclement and confrontation with different algorithms
5. 结 语
提出的基于ACL-MAPPO的围捕决策方法有效解决了现有方法在多无人艇协同围捕与入侵防御任务中训练效率低、奖励稀疏和泛化性差的问题. 实验结果表明,ACL-MAPPO算法在关键性能指标上均优于对比算法;当面对智能目标时,ACL-MAPPO的训练累计成功比例最高达到约0.84,高于CL-MAPPO、NOCL-MAPPO、ATCL-MADDPG算法. 在不同目标策略下,其平均捕获步数以及平均路径长度均低于3种对比算法,表明所提算法在围捕任务中更加高效. 同时,己方USV所获得的平均奖励值均高于3种对比算法,进一步展示出所提算法更优的性能. 此外,在碰撞和越界指标方面,也展现出更优的协同和避障能力.
总体而言,所提方法中基于自适应课程学习机制的训练架构在提升多智能体系统的协同性能和泛化能力方面具备有效性. 该方法为海洋多无人艇系统在复杂动态环境下的协同防御与智能对抗提供了理论与实践参考. 然而,本研究局限于多对一以及面对凸障碍物时的对抗局面. 未来将考虑多目标入侵背景下的多对多对抗场景,引入更为复杂的海洋扰动和非凸障碍物,最终将仿真模型迁移至真实场景并开展实海环境测试.
参考文献
俄乌冲突中无人艇作战运用的分析研究
[J].
Analysis and research on operational application of unmanned surface vehicles in Russia-Ukraine conflict
[J].
无人集群博弈对抗系统仿真验证及决策关键技术综述
[J].DOI:10.16182/j.issn1004731x.joss.23-0072 [本文引用: 1]
Simulation verification and decision-making key technologies of unmanned swarm game confrontation: a survey
[J].DOI:10.16182/j.issn1004731x.joss.23-0072 [本文引用: 1]
多无人艇协同围捕智能逃跑目标方法研究
[J].
Multiple USV cooperative algorithm method for hunting intelligent escaped targets
[J].
An effective strategy for distributed unmanned underwater vehicles to encircle and capture intelligent targets
[J].DOI:10.1109/tie.2023.3342281 [本文引用: 1]
基于逃逸角的多ASV微分博弈协同围捕方法
[J].
Cooperative hunting method for multiple ASVs using differential games based on escape angle
[J].
基于改进强化学习的多智能体追逃对抗
[J].DOI:10.3785/j.issn.1008-973X.2023.08.001 [本文引用: 3]
Multi-agent pursuit and evasion games based on improved reinforcement learning
[J].DOI:10.3785/j.issn.1008-973X.2023.08.001 [本文引用: 3]
基于多智能体深度强化学习的无人艇集群博弈对抗研究
[J].DOI:10.11993/j.issn.2096-3920.2023-0159 [本文引用: 2]
Research on game confrontation of unmanned surface vehicles swarm based on multi-agent deep reinforcement learning
[J].DOI:10.11993/j.issn.2096-3920.2023-0159 [本文引用: 2]
Pursuit-evasion game strategy of USV based on deep reinforcement learning in complex multi-obstacle environment
[J].DOI:10.1016/j.oceaneng.2023.114016 [本文引用: 3]
Distributed pursuit-evasion game of limited perception USV swarm based on multiagent proximal policy optimization
[J].DOI:10.1109/TSMC.2024.3429467 [本文引用: 1]
Multi-UAV roundup strategy method based on deep reinforcement learning CEL-MADDPG algorithm
[J].DOI:10.1016/j.eswa.2023.123018 [本文引用: 3]
Cooperative multi-target hunting by unmanned surface vehicles based on multi-agent reinforcement learning
[J].DOI:10.1016/j.dt.2022.09.014 [本文引用: 2]
Distributional soft actor-critic-based multi-AUV cooperative pursuit for maritime security protection
[J].DOI:10.1109/TITS.2023.3341034 [本文引用: 3]
基于深度强化学习的无人艇集群博弈对抗
[J].
Deep reinforcement learning based swarm game confrontation of unmanned surface vehicles
[J].
基于DE-MADDPG的多无人机协同追捕策略
[J].
Cooperative pursuit strategy for multi-UAVs based on DE-MADDPG algorithm
[J].
Multi-USV cooperative chasing strategy based on obstacles assistance and deep reinforcement learning
[J].DOI:10.1109/TASE.2023.3319510 [本文引用: 1]
基于分层强化学习的多无人机协同围捕方法
[J].DOI:10.7641/CTA.2024.30439 [本文引用: 1]
Multi-UAV collaborative pursuit method via hierarchical reinforcement learning
[J].DOI:10.7641/CTA.2024.30439 [本文引用: 1]
基于阶段诱导学习的多无人艇协同目标围捕策略
[J].DOI:10.19693/j.issn.1673-3185.04030 [本文引用: 1]
Stage-induced learning-based cooperative target hunting strategy for multiple unmanned surface vehicles
[J].DOI:10.19693/j.issn.1673-3185.04030 [本文引用: 1]
基于强化学习的多无人车协同围捕方法
[J].DOI:10.13374/j.issn2095-9389.2023.09.15.004 [本文引用: 1]
Cooperative encirclement method for multiple unmanned ground vehicles based on reinforcement learning
[J].DOI:10.13374/j.issn2095-9389.2023.09.15.004 [本文引用: 1]
Joint communication and action learning in multi-target tracking of UAV swarms with deep reinforcement learning
[J].DOI:10.3390/drones6110339 [本文引用: 1]
基于PER-MATD3的多无人机攻防对抗机动决策
[J].
Maneuvering decision-making of multi-UAV attack-defence confrontation based on PER-MATD3
[J].
基于自博弈强化学习的异构无人机集群协同对抗决策方法
[J].DOI:10.1360/SSI-2023-0267 [本文引用: 1]
Cooperative decision-making for heterogeneous UAV swarm confrontation based on self-play reinforcement learning
[J].DOI:10.1360/SSI-2023-0267 [本文引用: 1]
基于多智能体强化学习的无人艇协同围捕方法
[J].DOI:10.13195/j.kzyjc.2022.0564 [本文引用: 2]
Research on cooperative hunting method of unmanned surface vehicle based on multi-agent reinforcement learning
[J].DOI:10.13195/j.kzyjc.2022.0564 [本文引用: 2]
Deep reinforcement learning with intrinsic curiosity module based trajectory tracking control for USV
[J].DOI:10.1016/j.oceaneng.2024.118342 [本文引用: 1]
基于优势函数输入扰动的多无人艇协同策略优化方法
[J].DOI:10.16383/j.aas.c240453 [本文引用: 1]
Multi-USVs cooperative policy optimization method based on disturbed input of advantage function
[J].DOI:10.16383/j.aas.c240453 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}