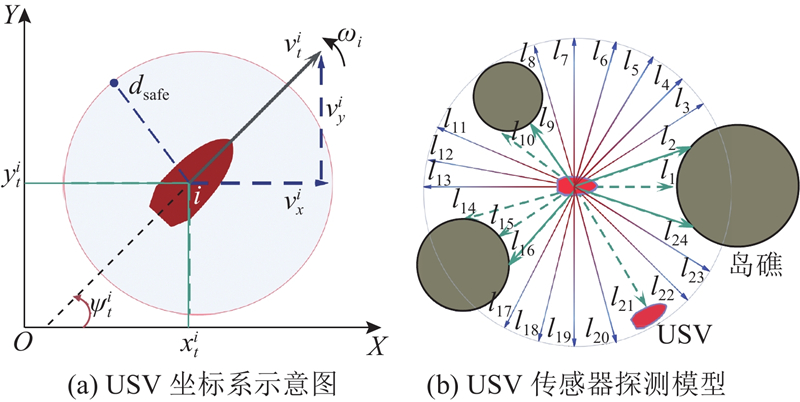
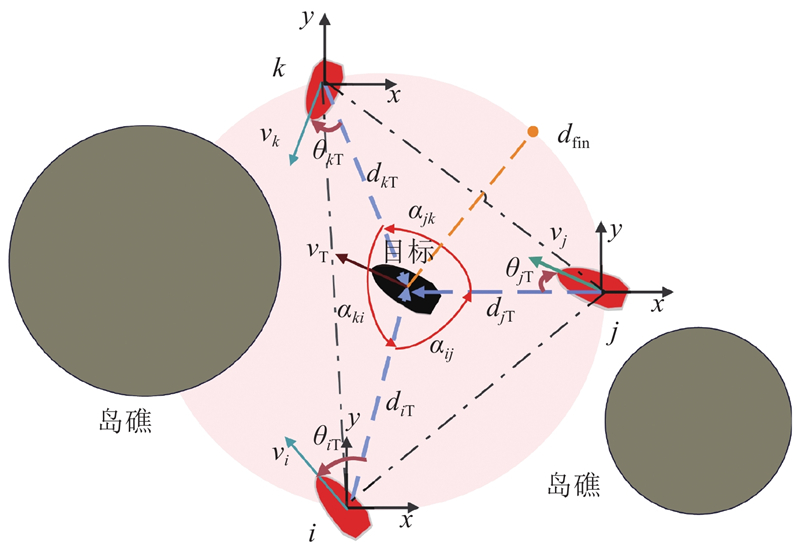
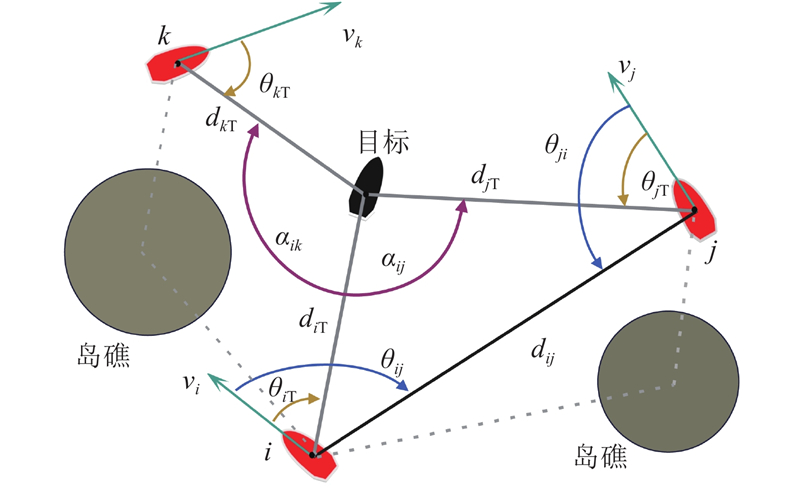
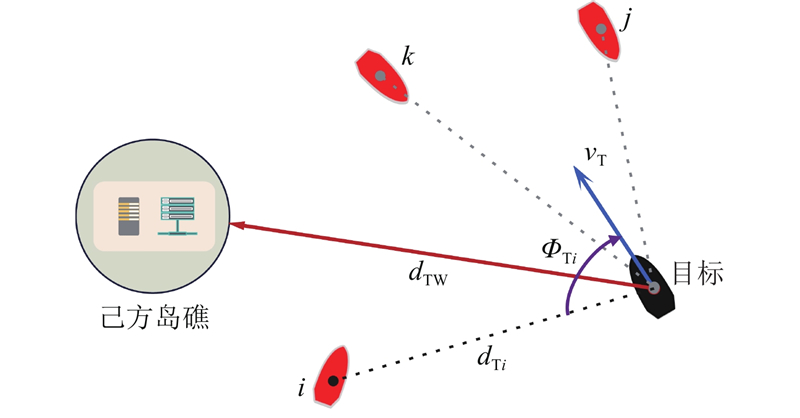
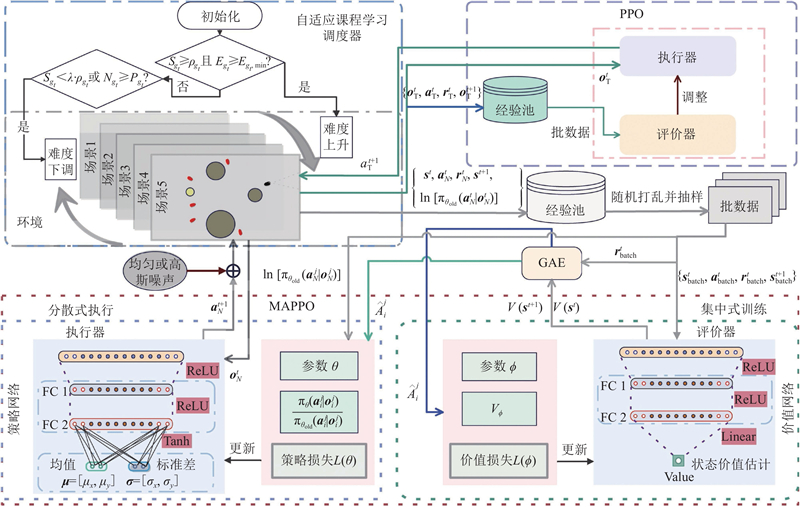
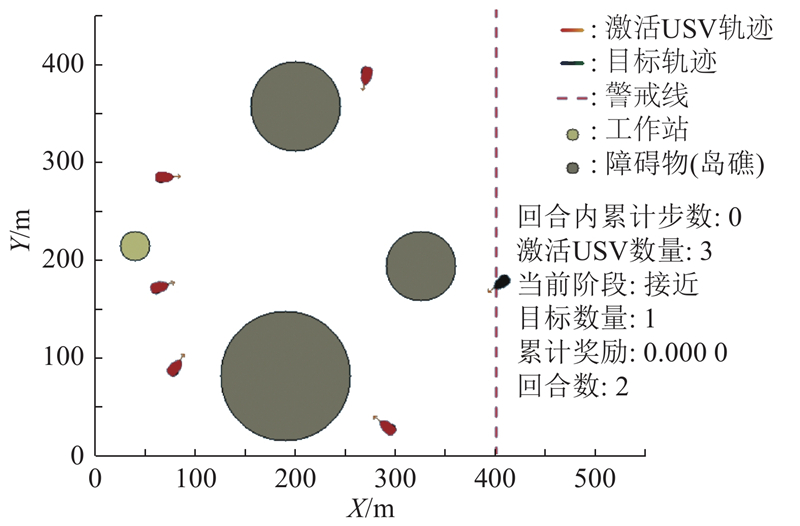
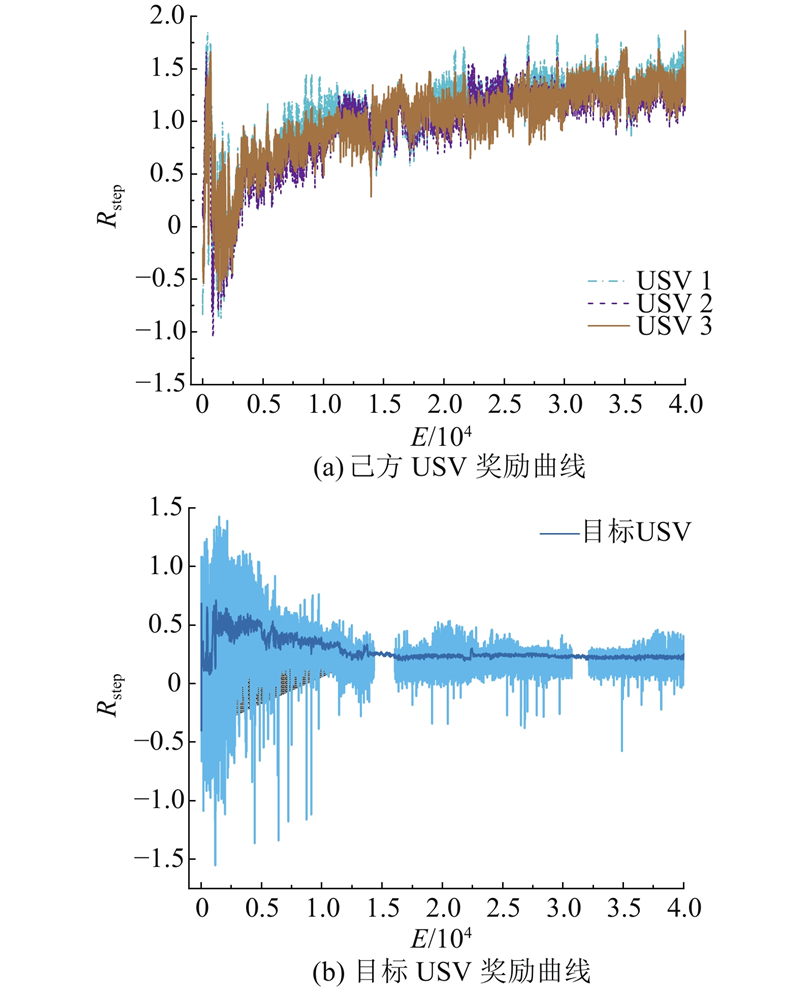
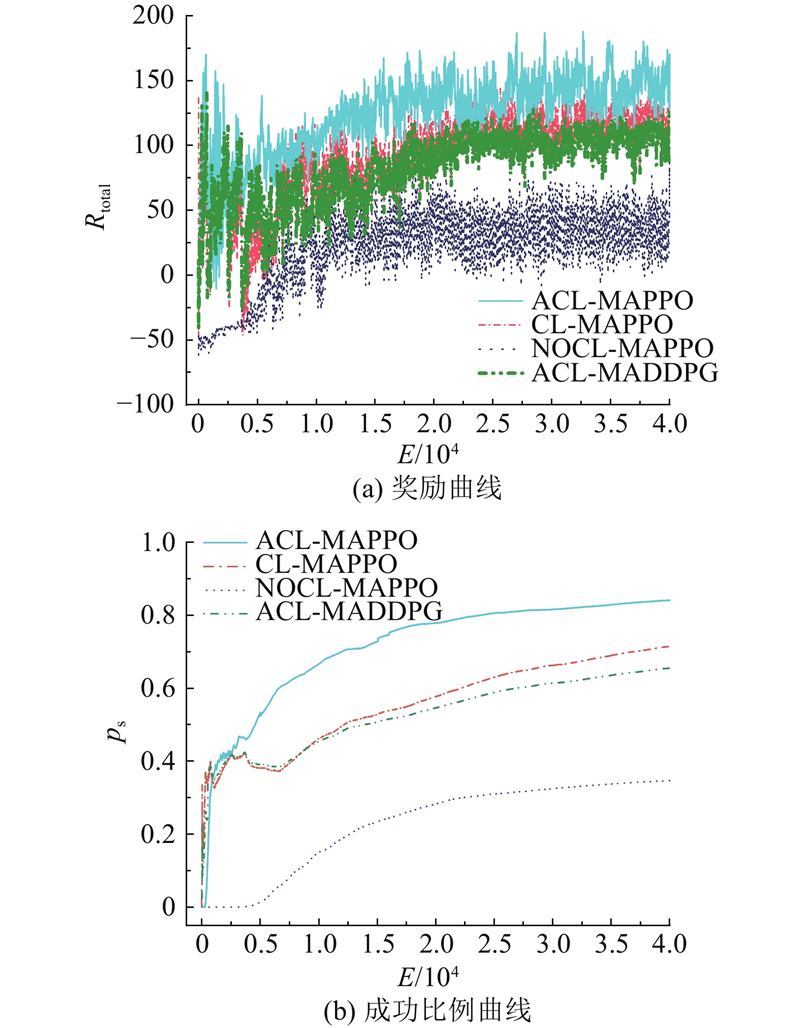
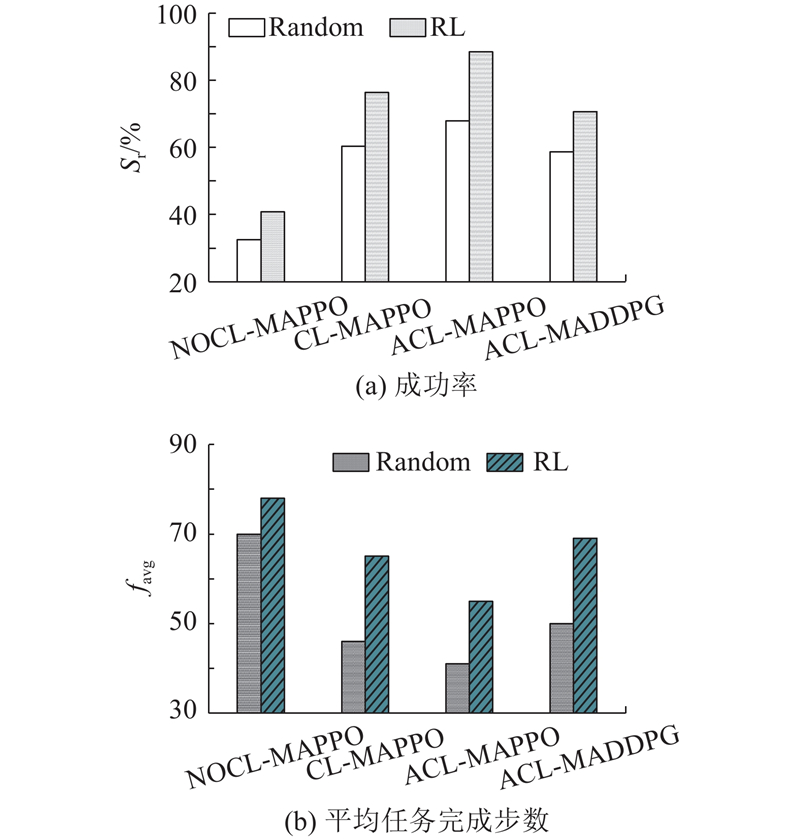
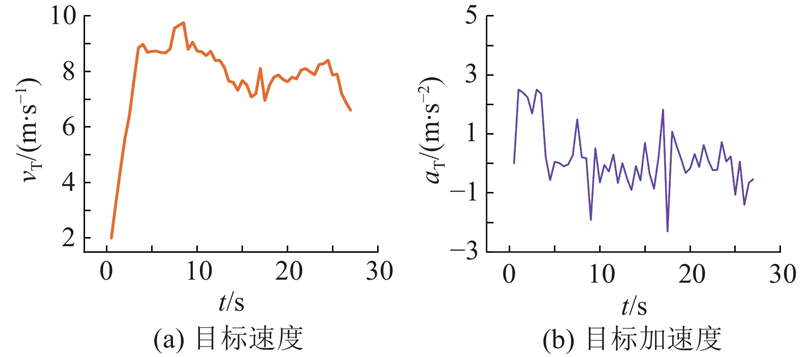
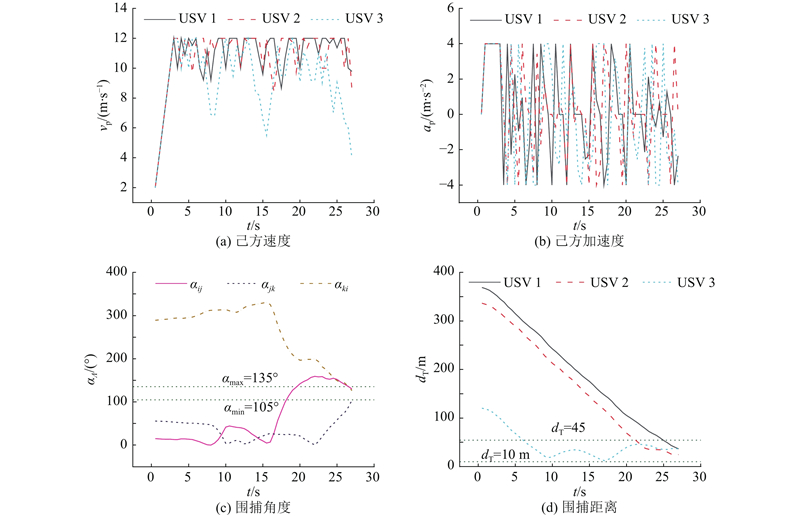
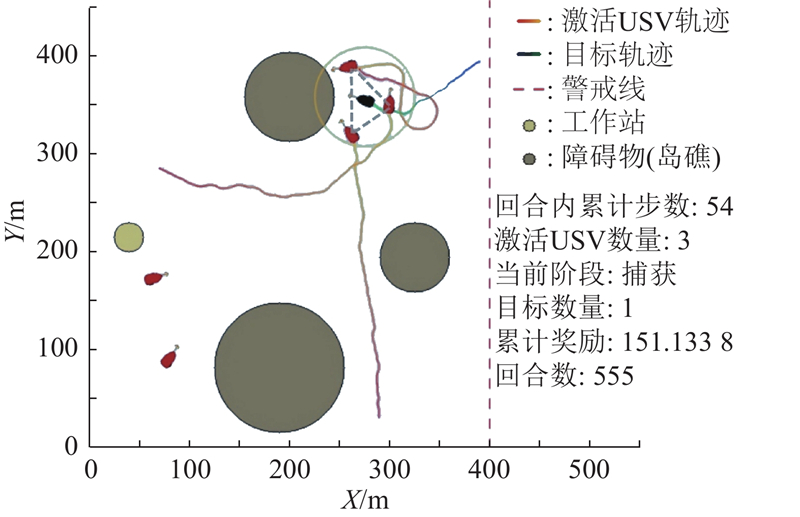
|
|
|
| 基于自适应课程强化学习的多无人艇对抗围捕决策 |
陈浪( ),刘增力,赵宣植*() ),刘增力,赵宣植*() |
| 昆明理工大学 信息工程与自动化学院,云南 昆明 650500 |
|
| Decision-making for multi-USV adversarial encirclement based on adaptive curriculum reinforcement learning |
| Lang CHEN(),Zengli LIU,Xuanzhi ZHAO*() |
| Faculty of Information Engineering and Automation, Kunming University of Science and Technology, Kunming 650500, China |
| 1 |
张家奎, 李晓东, 周河宇, 等 俄乌冲突中无人艇作战运用的分析研究[J]. 数字海洋与水下攻防, 2024, 7 (6): 616- 622
ZHANG Jiakui, LI Xiaodong, ZHOU Heyu, et al Analysis and research on operational application of unmanned surface vehicles in Russia-Ukraine conflict[J]. Digital Ocean & Underwater Warfare, 2024, 7 (6): 616- 622
|
| 2 |
梁晓龙, 杨爱武, 张佳强, 等 无人集群博弈对抗系统仿真验证及决策关键技术综述[J]. 系统仿真学报, 2024, 36 (4): 805- 816
LIANG Xiaolong, YANG Aiwu, ZHANG Jiaqiang, et al Simulation verification and decision-making key technologies of unmanned swarm game confrontation: a survey[J]. Journal of System Simulation, 2024, 36 (4): 805- 816
doi: 10.16182/j.issn1004731x.joss.23-0072
|
| 3 |
宋利飞, 徐凯凯, 史晓骞, 等 多无人艇协同围捕智能逃跑目标方法研究[J]. 中国舰船研究, 2023, 18 (1): 52- 59
SONG Lifei, XU Kaikai, SHI Xiaoqian, et al Multiple USV cooperative algorithm method for hunting intelligent escaped targets[J]. Chinese Journal of Ship Research, 2023, 18 (1): 52- 59
|
| 4 |
CHEN M, ZHU D, PANG W, et al An effective strategy for distributed unmanned underwater vehicles to encircle and capture intelligent targets[J]. IEEE Transactions on Industrial Electronics, 2024, 71 (10): 12570- 12580
doi: 10.1109/tie.2023.3342281
|
| 5 |
杨惠珍, 李建国, 吴天宇, 等 基于逃逸角的多ASV微分博弈协同围捕方法[J]. 水下无人系统学报, 2024, 32 (4): 730- 738
YANG Huizhen, LI Jianguo, WU Tianyu, et al Cooperative hunting method for multiple ASVs using differential games based on escape angle[J]. Journal of Unmanned Undersea Systems, 2024, 32 (4): 730- 738
|
| 6 |
薛雅丽, 叶金泽, 李寒雁 基于改进强化学习的多智能体追逃对抗[J]. 浙江大学学报: 工学版, 2023, 57 (8): 1479- 1486
XUE Yali, YE Jinze, LI Hanyan Multi-agent pursuit and evasion games based on improved reinforcement learning[J]. Journal of Zhejiang University: Engineering Science, 2023, 57 (8): 1479- 1486
doi: 10.3785/j.issn.1008-973X.2023.08.001
|
| 7 |
于长东, 刘新阳, 陈聪, 等 基于多智能体深度强化学习的无人艇集群博弈对抗研究[J]. 水下无人系统学报, 2024, 32 (1): 79- 86
YU Changdong, LIU Xinyang, CHEN Cong, et al Research on game confrontation of unmanned surface vehicles swarm based on multi-agent deep reinforcement learning[J]. Journal of Unmanned Undersea Systems, 2024, 32 (1): 79- 86
doi: 10.11993/j.issn.2096-3920.2023-0159
|
| 8 |
QU X, GAN W, SONG D, et al Pursuit-evasion game strategy of USV based on deep reinforcement learning in complex multi-obstacle environment[J]. Ocean Engineering, 2023, 273: 114016
doi: 10.1016/j.oceaneng.2023.114016
|
| 9 |
LI F, YIN M, WANG T, et al Distributed pursuit-evasion game of limited perception USV swarm based on multiagent proximal policy optimization[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2024, 54 (10): 6435- 6446
doi: 10.1109/TSMC.2024.3429467
|
| 10 |
LI B, WANG J, SONG C, et al Multi-UAV roundup strategy method based on deep reinforcement learning CEL-MADDPG algorithm[J]. Expert Systems with Applications, 2024, 245: 123018
doi: 10.1016/j.eswa.2023.123018
|
| 11 |
XIA J, LUO Y, LIU Z, et al Cooperative multi-target hunting by unmanned surface vehicles based on multi-agent reinforcement learning[J]. Defence Technology, 2023, 29: 80- 94
doi: 10.1016/j.dt.2022.09.014
|
| 12 |
HOU Y, HAN G, ZHANG F, et al Distributional soft actor-critic-based multi-AUV cooperative pursuit for maritime security protection[J]. IEEE Transactions on Intelligent Transportation Systems, 2024, 25 (6): 6049- 6060
doi: 10.1109/TITS.2023.3341034
|
| 13 |
苏震, 张钊, 陈聪, 等 基于深度强化学习的无人艇集群博弈对抗[J]. 兵器装备工程学报, 2022, 43 (9): 9- 14
SU Zhen, ZHANG Zhao, CHEN Cong, et al Deep reinforcement learning based swarm game confrontation of unmanned surface vehicles[J]. Journal of Ordnance Equipment Engineering, 2022, 43 (9): 9- 14
|
| 14 |
符小卫, 王辉, 徐哲 基于DE-MADDPG的多无人机协同追捕策略[J]. 航空学报, 2022, 43 (5):
FU Xiaowei, WANG Hui, XU Zhe Cooperative pursuit strategy for multi-UAVs based on DE-MADDPG algorithm[J]. Acta Aeronautica et Astronautica Sinica, 2022, 43 (5):
|
| 15 |
GAN W, QU X, SONG D, et al Multi-USV cooperative chasing strategy based on obstacles assistance and deep reinforcement learning[J]. IEEE Transactions on Automation Science and Engineering, 2024, 21 (4): 5895- 5910
doi: 10.1109/TASE.2023.3319510
|
| 16 |
孙懿豪, 闫超, 相晓嘉, 等 基于分层强化学习的多无人机协同围捕方法[J]. 控制理论与应用, 2025, 42 (1): 96- 108
SUN Yihao, YAN Chao, XIANG Xiaojia, et al Multi-UAV collaborative pursuit method via hierarchical reinforcement learning[J]. Control Theory & Applications, 2025, 42 (1): 96- 108
doi: 10.7641/CTA.2024.30439
|
| 17 |
曲星儒, 江雨泽, 龙飞飞, 等 基于阶段诱导学习的多无人艇协同目标围捕策略[J]. 中国舰船研究, 2025, 20 (1): 162- 171
QU Xingru, JIANG Yuze, LONG Feifei, et al Stage-induced learning-based cooperative target hunting strategy for multiple unmanned surface vehicles[J]. Chinese Journal of Ship Research, 2025, 20 (1): 162- 171
doi: 10.19693/j.issn.1673-3185.04030
|
| 18 |
苏牧青, 王寅, 濮锐敏, 等 基于强化学习的多无人车协同围捕方法[J]. 工程科学学报, 2024, 46 (7): 1237- 1250
SU Muqing, WANG Yin, PU Ruimin, et al Cooperative encirclement method for multiple unmanned ground vehicles based on reinforcement learning[J]. Chinese Journal of Engineering, 2024, 46 (7): 1237- 1250
doi: 10.13374/j.issn2095-9389.2023.09.15.004
|
| 19 |
ZHOU W, LI J, ZHANG Q Joint communication and action learning in multi-target tracking of UAV swarms with deep reinforcement learning[J]. Drones, 2022, 6 (11): 339
doi: 10.3390/drones6110339
|
| 20 |
符小卫, 徐哲, 朱金冬, 等 基于PER-MATD3的多无人机攻防对抗机动决策[J]. 航空学报, 2023, 44 (7): 327083
FU Xiaowei, XU Zhe, ZHU Jindong, et al Maneuvering decision-making of multi-UAV attack-defence confrontation based on PER-MATD3[J]. Acta Aeronautica et Astronautica Sinica, 2023, 44 (7): 327083
|
| 21 |
严锐驰, 李帅, 王晨, 等 基于自博弈强化学习的异构无人机集群协同对抗决策方法[J]. 中国科学: 信息科学, 2024, 54 (7): 1709- 1729
YAN Ruichi, LI Shuai, WANG Chen, et al Cooperative decision-making for heterogeneous UAV swarm confrontation based on self-play reinforcement learning[J]. Scientia Sinica Informationis, 2024, 54 (7): 1709- 1729
doi: 10.1360/SSI-2023-0267
|
| 22 |
夏家伟, 朱旭芳, 张建强, 等 基于多智能体强化学习的无人艇协同围捕方法[J]. 控制与决策, 2023, 38 (5): 1438- 1447
XIA Jiawei, ZHU Xufang, ZHANG Jianqiang, et al Research on cooperative hunting method of unmanned surface vehicle based on multi-agent reinforcement learning[J]. Control and Decision, 2023, 38 (5): 1438- 1447
doi: 10.13195/j.kzyjc.2022.0564
|
| 23 |
WU C, YU W, LIAO W, et al Deep reinforcement learning with intrinsic curiosity module based trajectory tracking control for USV[J]. Ocean Engineering, 2024, 308: 118342
doi: 10.1016/j.oceaneng.2024.118342
|
| 24 |
YU C, VELU A, VINITSKY E, et al. The surprising effectiveness of PPO in cooperative, multi-agent games [EB/OL]. (2022-11-04) [2025-06-22]. https://arxiv.org/abs/2103.01955.
|
| 25 |
SCHULMAN J, MORITZ P, LEVINE S, et al. High-dimensional continuous control using generalized advantage estimation [EB/OL]. (2018-10-20) [2025-06-22]. https://arxiv.org/abs/1506.02438.
|
| 26 |
任璐, 柯亚男, 柳文章, 等 基于优势函数输入扰动的多无人艇协同策略优化方法[J]. 自动化学报, 2025, 51 (4): 824- 834
REN Lu, KE Yanan, LIU Wenzhang, et al Multi-USVs cooperative policy optimization method based on disturbed input of advantage function[J]. Acta Automatica Sinica, 2025, 51 (4): 824- 834
doi: 10.16383/j.aas.c240453
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|